Большая часть моего доклада будет посвящена теории, но будут даже практические кейсы, я покажу несколько вариантов оптимизации кода. В конце концов, мы тут все 1С-ники, мы увидим 1С-ный код.

Расскажу сначала немного о себе.
- я уже 19 лет работаю с продуктами 1С;
- долгое время проработал на должности руководителя ИТ в Юг-авто, и получил там очень большой опыт, которым с вами поделюсь;
- в настоящее время занимаю должность руководителя сектора по автоматизации отчетности МСФО в розничной аптечной сети Магнит.
На примере этих работодателей я и получил весь этот опыт, который постараюсь вам сегодня донести.

Расскажу немного о своих работодателях, чтобы образовать у вас какое-то понятие – в каком случае действительно нужна Highload-оптимизация.
Все знают Магнит:
- 25 лет на рынке,
- 20 тысяч магазинов,
- тысяча аптек,
- своя логистика, свое производство – много чего своего, и значительная часть из этого автоматизирована на программных продуктах 1С.
Когда я туда пришел, я удивился – это действительно десятки терабайт баз под управлением 1С, и миллиарды записей в журнале проводок.

Второй пример – Юг-Авто, сеть дилерских центров на юге России.
Тоже распределенная сеть. Пример интересен тем, как можно поддерживать работу большого количества пользователей на системах, которые для этого не предназначены – это легаси (устаревшие системы).
Практика
Практические кейсы, о которых я сегодня хочу рассказать, возникли в результате опыта работы на трех проектах:
-
Первый проект – это «Аптеки Магнит». Все аптеки Магнита работают на программном продукте 1С «Управление аптечной сетью». Это – отраслевка, тиражная коробка, построенная на «Управление торговлей 11», естественно, с доработками, которые нужны для аптечников.
-
Следующий пример – это МСФО Магнит, все это собирается в 1С:Консолидацию КОРП. В отличие от практически коробочного решения в «Управлении аптеками» здесь было сделано очень большое количество доработок, которые были предназначены именно для обеспечения достаточного уровня производительности, для обработки такого огромного объема данными. Удивительно, но консолидация всей информации действительно стекается в базу 1С и там дальше после этого уже передается на следующий уровень обработки.
-
И последний пример будет скорее обзорный – Юг-Авто имеет в эксплуатации большое количество продуктов 1С от Документооборота до Управление торговлей 10.3. Что делать с этими продуктами, чтобы они могли выдерживать работу несколько сотен пользователей, я тоже вкратце расскажу. Насколько сложно было заставить 7.7 выдерживать более сотни пользователей, столь же тяжело заставлять систему, не предназначенного для этого объема для того, чтобы они потянули несколько сотен пользователей.
Метрики

Когда заходим на проект и вообще начинаем задумываться над оптимизацией, нам нужно получить какую-то числовую оценку текущей ситуации, чтобы в дальнейшем отслеживать то, что мы делаем – идет в плюс, в минус или же мы ничего не добились. Это называется «метрики».
Снимаем метрики на начало проекта, отслеживаем в ходе всего проекта оптимизации и, самое главное, в конце концов нужно когда-нибудь остановиться с оптимизацией. Когда приходит время отчитываться – мы отчитываемся, показываем разницу в показателях, говорим, что стало лучше. Если все согласны – здорово. Если пользователей по-прежнему что-то не устраивает, и они продолжают утверждать, что все до сих пор тормозит, значит, нужно дальше оптимизировать – продлевать проект, расширять бюджет, продлевать работу.
К чему же должна приводить оптимизация?
-
Прежде всего, естественно, это снижение нагрузки на оборудование. 1С редко тормозит просто так – как правило, это происходит из-за увеличения нагрузки на клиентские машины, на сервер 1С:Предприятие либо на СУБД. Оптимизируем – повышаем производительность.
-
Следующее – это снижение времени отклика на какие-то операции, которые у нас есть в системе. Либо на конкретную пользовательскую операцию, либо, возможно, на веб-сервис.
-
Естественно, должен повышаться коэффициент APDEX – это интегральный показатель удовлетворенности пользователей скоростью системы. Чем выше – тем лучше. Идеальный показатель принимается равным единице, но это практически недостижимо. Входишь на проект с показателем APDEX равным 0,1-0,2, выходишь с показателем 0,8 – отлично, значит, мы не просто так потрудились.
-
И возможно, самое важное, но самое сложное для восприятия – это количество инцидентов, связанных с производительностью системы, когда пользователи жалуются, что у них там тормозит, висит. Когда мы снижаем количество инцидентов, связанных с производительностью, автоматически повышается стабильность системы, потому что платформа 1С очень плохо себя ведет, если у вас процессор загружен на 100%, не хватает места на tempdb, переполняется журнал транзакций – это все практически всегда приводит к перезагрузке сервера 1С, к значит, к снижению стабильности.
Разный Highload

После того, как мы определились с метриками, после этого мы выбираем стратегию. Дело в том, что Highload – это общее понятие высокой нагрузки на систему. Она может возникать по самым разным причинам
-
Простейшая самая известная – это большое количество пользователей. Какие метрики следует снимать в этом случае? Естественно, нагрузка на оборудование, чтобы понимать, есть ли какой-то запас по увеличению количества пользователей либо эффективности работы пользователей. И снимаем метрику по APDEX – стали ли пользователи довольнее или нет.
-
Второй возможный вариант – когда система обрабатывает множество идентичных или очень похожих транзакций. Когда у нас есть какой-нибудь сервис, в который мы заливаем огромный поток данных (биллинговая система или АСУ ТП), тогда нам необходимо повысить количество транзакций, которые система сможет переварить в секунду. Цель достижима, метрика есть. Можно над ней работать.
-
Бывают ситуации, когда в 1С действительно нужно обработать большое количество данных. Для bigdata, когда у нас есть какие-то неструктурированные данные, из которых нужно сделать неочевидные выводы, 1С не предназначена. Если же нужно обработать большую таблицу проводок, то такие ситуации действительно бывают. В этом случае считаем время отклика (время выполнения этой операции) путем снятия замера до и после оптимизации. И потом проверяем – насколько стало лучше.
-
Legacy-системы. С ними тяжелее всего, потому что в них практически нет метрик. Что можно сделать? Посмотреть нагрузку на систему – насколько у нас железо загружено. И количество инцидентов посчитать – насколько часто пользователи у нас обращаются за какой-нибудь ерундой.
Выскажу очень спорный, но, тем не менее, правдивый тезис:
«1С – это решение, обеспечивающее высокую производительность»
Сразу скажу, что это относится только к современным решениям, построенным на «1С:ERP» либо «1С:Документооборот», а не «Бухгалтерия 1.6» или что-нибудь со времен 7.7.
Почему я могу это сказать? Потому что во время всех своих проектов мы гораздо чаще сталкиваемся с ситуациями, не связанными именно с платформой 1С или типовыми решениями. Гораздо чаще проблемы возникают в других местах, с которыми мы можем справиться, мы можем эти проблемы устранить.
Влияние на производительность
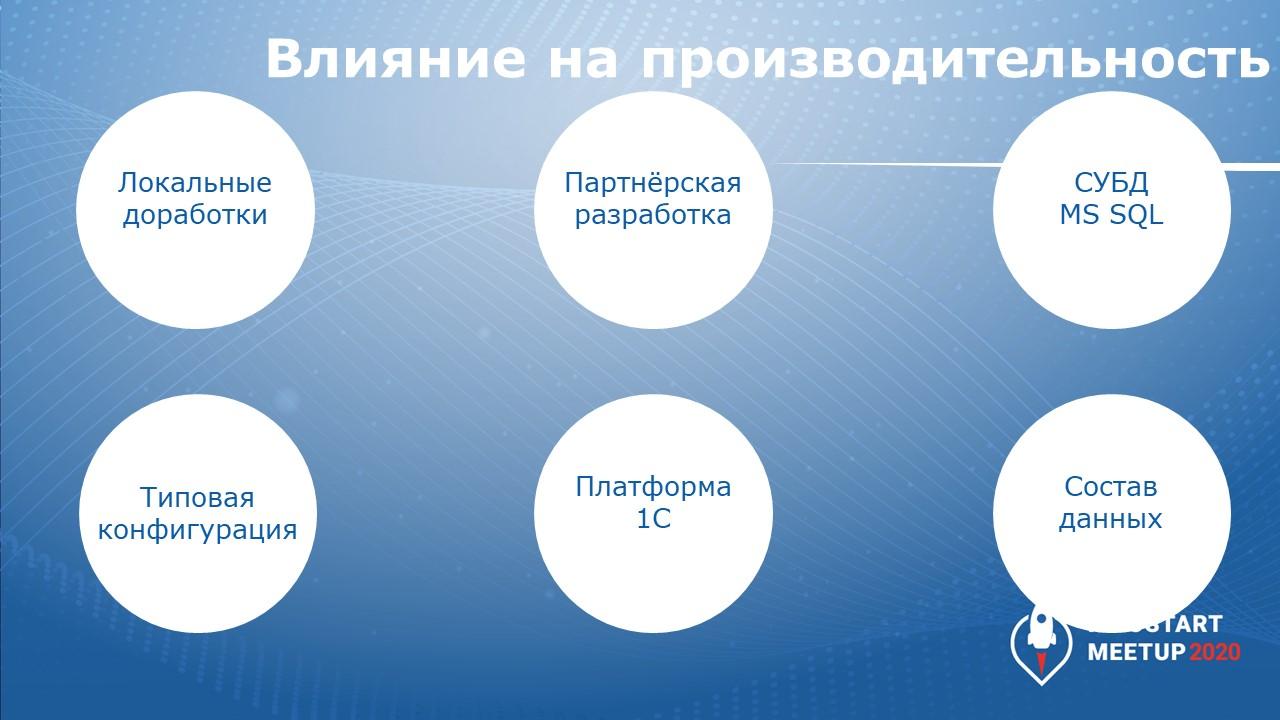
В чем же бывают проблемы? Сразу скажу, что здесь я никаким образом не описываю проблемы, возникающие из-за неправильной работы железа, отсутствия настройки планов обслуживания СУБД или нехватки памяти – это все очевидно, тривиально, на этом заострять внимание не буду.
С чем чаще всего бывают проблемы?
-
Удивительно, но это локальные доработки – то, что сделано нами на конкретных предприятиях. Зачастую это использование нестандартным образом функциональности, которая заложена в 1С.
-
Очень часто проблемы с партнерскими решениями – отраслевые решения либо какие-то специфические доработки, сделанные партнерами (даже в коробках – коробка ни о чем не говорит, ничего не гарантирует)
-
Часто проблемы возникают на уровне MS SQL – приходится этим заниматься, оптимизировать, какие-то ситуации разбирать. Готовых решений здесь не бывает. Но тем не менее, MS SQL часто подкидывает нам проблем.
-
Типовая конфигурация тоже иногда (но гораздо реже, чем все остальное) имеет какие-то проблемы. Редко, но бывает.
-
Очень редко – проблемы в платформе. В большинстве случаев платформа отрабатывает хорошо. Разве что мы не умеем ее «готовить».
-
По поводу «готовить» я имею в виду состав данных, которые есть в конкретной вашей базе. Это одна из самых главных и самых часто встречаемых причин, влияющих на производительность. Потому что если у вас не закрыты регистры накопления себестоимости, если вы в ERP ввели 20-30 тысяч направлений деятельности, вам ничего не поможет – только закрывать регистры, правильно настраивать логику системы или же пересматривать подход к использованию тех или иных решений, которые предлагает нам фирма «1С».
Как видите, есть большое количество факторов, которые влияют на производительность системы. Это приводит к тому, что каждый проект по оптимизации – уникален. Нельзя сказать, что какое-то там решение, которое мы сделали в одном месте – оптимизировали код, мы молодцы, в другое место приходишь, запускаешь, и там оно не будет также производительно работать.
Потому что влияют различные версии SQL-сервера, разные локальные доработки, набор данных. Даже вроде бы вычищаешь план выполнения запроса, переписываешь – все отлично работает. Садишься на соседний сервер, а бывает даже на боевой сервер переносишь с тестового, и там все работает совсем по-другому, поэтому фактически, оптимизация производительности под Highload – это индивидуальная доработка, причем, не только на платформе 1С. Такой же проблемой страдает любая другая информационная система – оптимизация всегда выполняется под конкретный проект.
Практические кейсы оптимизации. Отчет о розничных продажах УТ11

В качестве примера мой первый практический кейс. Это кусок типового кода – заполнение «Отчета о розничных продажах». Это не проведение, а именно заполнение, создание. Поступила задача оптимизировать этот блок, он выполнялся недостаточно производительно, долго. Сняли замеры производительности конфигуратором, вывели этот запрос.
Казалось бы, элементарный запрос, который обращается к временной таблице «ЧекиККМ», и фильтрует по ней выборку из табличной части «Серии» документа «ЧекККМ». Этот запрос выполнялся 28 секунд, хотя в самой табличной части серий содержалось всего лишь несколько сотен записей – ерунда.
В чем была проблема? СУБД MS SQL восприняла этот запрос не в качестве отбора по ссылке из табличной части, а она сделала слияние всей огромной табличной части ЧекиККМ.Серии с нашими 300 записей, при том что в этой табличной части несколько десятков миллионов записей.
Это возникало из-за того, что поле «Ссылка» во временной таблице «ЧекиККМ» было полем составного типа. При передаче такого запроса в SQL он преобразовывался в CASE-операцию, не воспринимая условие как прямое сравнение, а выполняя более очевидную для него функцию слияния.
Метод решения – мы убрали поле составного типа из временной таблицы «ЧекиККМ». Теперь в каждой временной таблице только лишь один тип значения в этом поле. Время выполнения сократилось с 28 секунд до 0.4 секунды. Это примерно в 60 раз. Мы зарегистрировали эту ошибку в 1С. В ERP 2.5.5 будет исправление по этой теме.
Также в рамках расследования этого инцидента фирма «1С» зарегистрировала ошибку в платформе и в платформе 8.3.17 блок про оптимизацию – это как раз связан с тем, что запрос преобразовывался в CASE-операцию. Они исправили и платформу и типовую конфигурацию.
Фирма «1С» достаточно оперативно реагирует на те обращения, которые мы пишем, и делает вывод из проблем производительности, которые возникают. Естественно, фирме «1С» интересно делать свою коробку более масштабируемой, более производительной.
Влияние версии SQL Server

Мы пробовали запустить тот же самый запрос на более старой версии SQL-сервера. Изначально тестировали на платформе 8.3.15+SQL 2016, попробовали запустить на MS SQL 2012 сервере, подумали – ну как-то это же работает у всех, страна большая, должно работать. Оказалось, что на MS SQL2012 все это работает еще хуже – на эту операцию уходило 100 секунд.
Простая смена SQL-сервера без оптимизации кода могла увеличить производительность этого куска запроса почти в 4 раза. Поэтому обновляйте версии SQL-серверов, обновляйте версии платформы. Но аккуратно и осторожно, потому что могут всплыть всякие проблемы.
В SQL-сервере, обращаю внимание, есть не только версия самой программы SQL-сервера, есть уровень совместимости.
Если вы внаглую на 2012-м сервере воткнете 2019, этого недостаточно, нужно сменить уровень совместимости. Но это все нужно обязательно тестировать, потому что всплыть может в самом неожиданном месте.
По поводу актуализации редакций.
-
По производительности сервера ниже 2012 я вам ничего сказать не могу, но если у вас версия моложе, чем 2014 – если у вас 2008, 2012 сервер – вам однозначно нужно обновляться.
-
2014 сервере гораздо лучше СУБД понимает сложность выполнения запроса и исходя из этого подбирает план выполнения.
-
2016-й сервер будет гораздо лучше нагружать ваш процессор на сервере.
-
2017-й сервер будет гораздо лучше использовать оперативную память на сервере, гораздо реже СУБД будет обращаться к tempDB, к жесткому диску. Обновляйте версии до актуального состояния.
Инструменты

Какие инструменты мы используем для того, чтобы оптимизировать? Ничего странного, ничего страшного, ничего фантастически дорогого.
-
С помощью Zabbix собираем статистику нагрузки на оборудование. Бесплатный инструмент, быстро настраивается.
-
С помощью MS SQL Server Management studio – мы выполняем запросы, которые показывают топ-нагрузки на оборудование в разрезе конкретных запросов. Смотрим, какой запрос дает нагрузку, смотрим план выполнения этого запроса, там же можно понять, какой пользователь выполняет этот запрос.
-
APDEX – я про него уже говорил
-
1С:ЦУП (1С:Центр управления производительностью) мы используем достаточно редко, потому что на больших объемах техжурнала он просто умирает. Если мы собираем за полчаса техжурнал, он обрабатывается неделю. Блокировки – да, мы там смотрим
Все эти инструменты нам нужны для анализа статистических данных.
Теперь непосредственно инструментарий, который у нас используется.
-
Самое простое и очевидное – конфигуратор. Замер производительности, когда мы сделали замер производительности, по крайней мере, становится понятно, какие строчки кода, какие запросы у нас радикально влияют на производительность. Метод решения выявляется именно оттуда.
-
Если проблема с запросом – тогда запускаем профайлер и снимаем трейс, трейс открываем в Studio и смотрим, что там такого нехорошего, перестраиваем.
-
Метод решения – естественно, подключаем свое мышление, и пытаемся адаптировать. В 1С у нас очень ограниченный язык программирования на MS SQL. Поэтому приходится какими-то обходными путями заставлять СУБД делать то, что мы хотим.
-
Никаких готовых ответов в интернете по оптимизации 1С на больших объемах данных вы, скорее всего, не найдете. Есть какие-то общие концепты, но готового решения нет.
Практические кейсы оптимизации. Много пользователей

Переходим к практическим кейсам. В «1С:Управление аптечной сетью» у нас большое пользователей (несколько тысяч человек) в онлайне заводит документы, при этом данные загружаются и выгружаются регламентными заданиями в большом количестве потоков.
-
В таких условиях возникает невоспроизводимая нагрузка, которая проявляется самым разнообразным образом. И если мы спросим пользователя: «Что ты такого сделал, что у нас из-за тебя упал сервер?» он в большинстве случаев ответит что-то невразумительное: «Я что-то там нажал, после чего все погасло». И даже если он закроет программу, запрос все равно продолжит выполняться на сервере, и пока вы не удалите его сеанс принудительно, система продолжит «висеть». Метод решения – снимаем зависший сеанс, смотрим в MS SQL Management Studio, какой запрос у нас выполняется, смотрим его план, пытаемся воспроизвести параметры, которые были в него переданы. И таким образом вылавливаем ситуацию. Естественно, это все не просто, не дешево и не быстро.
-
RLS – кто-то их любит, кто-то не любит, но без них жить невозможно. В свежей БСП появился производительный режим RLS. Советую вам попробовать, может быть, с ним будет лучше.
-
Еще одна из проблем – это отсутствие обратной связи. Когда у вас большое количество пользователей, то, скорее всего, есть какая-нибудь служба поддержки. Но поскольку вы находитесь где-нибудь на четвертой линии, а то и вообще работаете внешними консультантами, то информация о том, что что-то стало не так, дойдет до вас очень нескоро. Тут остается опять же, самостоятельно мониторить тот же самый Zabbix, если с сервером действительно происходит что-то печальное, вы это увидите в метриках.
Практические кейсы оптимизации. Много транзакций

Там же в «Аптеках» мы столкнулись с еще одной особенностью – обработка большого количества транзакций (в сети аптек Магнит ежесекундно проводится несколько чеков ККМ – за 10 секунд в системе прибавляется 30-40 чеков).
В чем преимущество этой ситуации? То, что вы можете конкретную операцию чуть ли не до блеска вычистить.
При этом проблема – минимальнейший сбой, который вы допустите и все эти чеки выстроятся в бесконечную очередь, которую вы никогда не сможете разрулить. Поэтому изменения вносятся очень аккуратно.
Проект по оптимизации аптек Магнит у нас до сих пор идет, скорее всего, это бесконечная вещь, но расчеты показывают, что по результатам проведенных оптимизационных мероприятий емкость системы увеличится раз в 10. То же самое оборудование позволит обслуживать примерно в 10 раз больше пользователей. Фактически, это ключевой показатель системы.
Оптимизация таких проектов – это дело индивидуальное, точечное и заказное. Оно требует очень высокой квалификации сотрудников. Если вы запускаете какое-нибудь обновление релиза, и в этом релизе отсутствует какой-нибудь индекс, то система может деградировать до ужасного состояния, и вы потратите кучу времени, чтобы ее поднять.
Поэтому при большой нагрузке нужно очень грамотно и квалифицировано вносить изменения – применять тестирование и аудировать качество кода (аудировать те изменения, которая вносятся).
Практические кейсы оптимизации. Сегменты номенклатуры

На слайде показан один из интересных примеров запроса (это кусок кода из отраслевого коробочного решения) – как видите, здесь есть какая-то временная таблица, которая соединяется с типовым регистром НоменклатураСегмента.
Простейший код. Он у нас выполнялся несколько секунд. Для аптеки это недопустимо много.
Посмотрели план выполнения – оказалось, что проблема в том, что в УТ было 4 колонки – Номенклатура, Склад, Характеристика и Серия. Причем, Номенклатур и Характеристик гораздо меньше, чем строк в этой таблице. А нас интересовали именно различные сегменты, которые есть в этой таблице.

Метод решения – переписать код и сделать вложенный запрос, где мы выбираем прямо из этой временной таблицы РАЗЛИЧНЫЕ Номенклатура, Характеристика. И после этого уже производим слияние с регистром сведений НоменклатураСегмента.
Это приводит к тому, что СУБД выбирает различные позиции из маленькой таблицы, а не после перемножения этих больших сущностей. На наших данных ускорение было более чем в два раза.
Мелочь, но приятно.
Практические кейсы оптимизации. Много данных

Мой следующий практический кейс – миллионы строк в одном документе.
Этот пример касается конфигурации 1С:Консолидация, куда мы консолидировали данные для МСФО. Там достаточно легкая конфигурация по объему – небольшое количество алгоритмов, но очень много данных. Поэтому каждую операцию мы оптимизировали до идеального состояния. По результатам проекта время выполнения тяжелых операций сократилось с 8 часов примерно до 20-30 минут.
Если мы говорим про обработку больших данных, то 20-30 минут это тоже может быть очень быстро, если смотреть, с чего начинали.
Практические кейсы оптимизации. Legacy-системы

И последний кейс – поддержка устаревающих систем.
Здесь скорее обзорно скажу, что проблемы возникают, если мы пытаемся запихнуть вот такую нагрузку в систему, которая не умеет работать с большим количеством данных либо пользователей.
Что с этим делать? Только лишь опрашивать пользователей – где у них возникают проблемы и точечно их устранять. И кроме точечного устранения проблем мониторим нагрузку на СУБД, потому что именно она составляет наибольшую часть нагрузки.
Техники ускорения

Тема оптимизации бесконечная и всеобъемлющая, но если собрать вместе техники ускорения их получится не так много:
-
Первый способ оптимизации – это отсечь лишнее (чтобы СУБД или 1С не выполняла что-то лишнее). Был практический пример, когда у нас один кусок кода выполнялся во время проведения документа четыре раза. Привели к тому, что он стал выполняться один раз вместо четырех. Ускорилось проведение на 30%. Когда сделали так, чтобы этот кусок кода не выполнял лишние операции, его выполнение ускорилось еще в 20 раз. Итого, время проведения сократилось в два раза.

-
Обработка не в СУБД. Я часто встречаю пример, как на слайде – когда данные выгружаются из запроса в промежуточную таблицу значений, чтобы передать их в другой запрос. Так делать не нужно. Если эта таблица значений вам на сервере 1С не нужна, не выгружайте ее из запроса – сохраняйте все во временных таблицах и передавайте их в другой запрос непосредственно через менеджер временных таблиц.
-
По поводу «Убрать ненужные индексы» можно говорить очень долго и упорно – не один день даже говорить. Вкратце – убивайте лишние индексы, добавляйте те, которые вам нужны. Это очень важно, это полностью меняет работу всей системы.

-
И напоследок, самая последняя особенность – это ускорение производительности за счет использования циклов в одну строку. Я в это не верил, но это действительно так. Первый кусок кода работает медленнее, чем второй кусок кода в пять с лишним раз.
*************
Данная статья написана по итогам доклада (видео), прочитанного на INFOSTART MEETUP Krasnodar.

Вступайте в нашу телеграмм-группу Инфостарт