Меня зовут Евгений Винниченко, я работаю в компании WiseAdvice на должности замруководителя отделом ИТ. WiseAdvice – группа компаний: есть франчайзи 1С, бухгалтерский аутсорсинг, патентно-адвокатское бюро. Я это рассказываю для того, чтобы слушатели поняли: стек задач, которые приходится решать, находится в разных предметных областях.
О теме доклада
В рамках доклада пройдемся по жизненному циклу практической задачи, рассмотрим все крутые повороты, в которые попадала задача, заглянем под капот.
История тривиальная. Нашей компании как аутсорсеру бухгалтерских услуг приходится загружать выписки с банковских счетов клиенту в 1С. При этом мы хотим, чтобы наши бухгалтера на эту ежедневную задачу тратили как можно меньше времени.
Следовательно, постановка задачи была сформулирована примерно так: Мы хотим автоматически разносить банковскую выписку с минимальными трудозатратами для бухгалтеров.
На первых итерациях мы пытались это сделать исключительно на 1С, но сложность механизма по подбору данных перешла все допустимые границы.
Причина сложности – основная информация о поступившем платеже находится в назначении платежа, по которому бухгалтера заполняют внутреннюю аналитику учета. Назначение платежа и в нашей задаче становится основой для принятия решений по дополнительным аналитикам.
Наш мини-алгоритм авторазноски был простым. Нам нужно найти ранее разнесенный документ с таким же или наиболее похожим назначением платежа и взять данные из найденного документа как основу для разнесения текущего документа.
Первая итерация
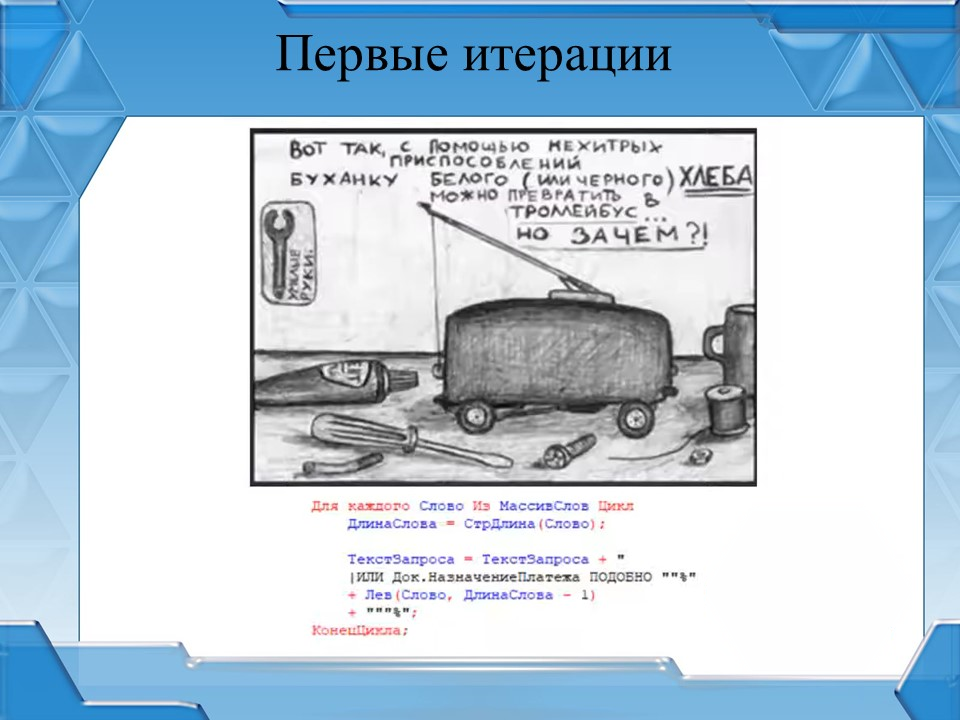
Так как первичный стек технологий у нас был 1С, то в голову сходу приходит решение: разбить назначение платежа на слова и пытаться искать основу для разнесения по словам.
Первая итерация показала, что наш русский язык действительно великий, и его ничем не измерить. Доля успешно разнесенных новых документов при таком подходе – 30-40%. Хороший результат, но этого недостаточно, чтобы помочь нашим бухгалтерам выполнять рутинную задачу по разнесению выписок.
Команда, которая занималась разработкой, восприняла это как провал и попыталась доработать механизм. После нескольких итераций разработки мы поняли, что не знаем ничего лучше конструкций ПОДОБНО в языке запросов 1С. Итоговый результат использовал эту конструкцию везде.
На слайде как раз представлен один из вариантов использования этой конструкции для поиска слов в назначении платежа.
Расстояние Левенштейна
А потом один из участников команды услышал о такой метрике как расстояние Левенштейна.
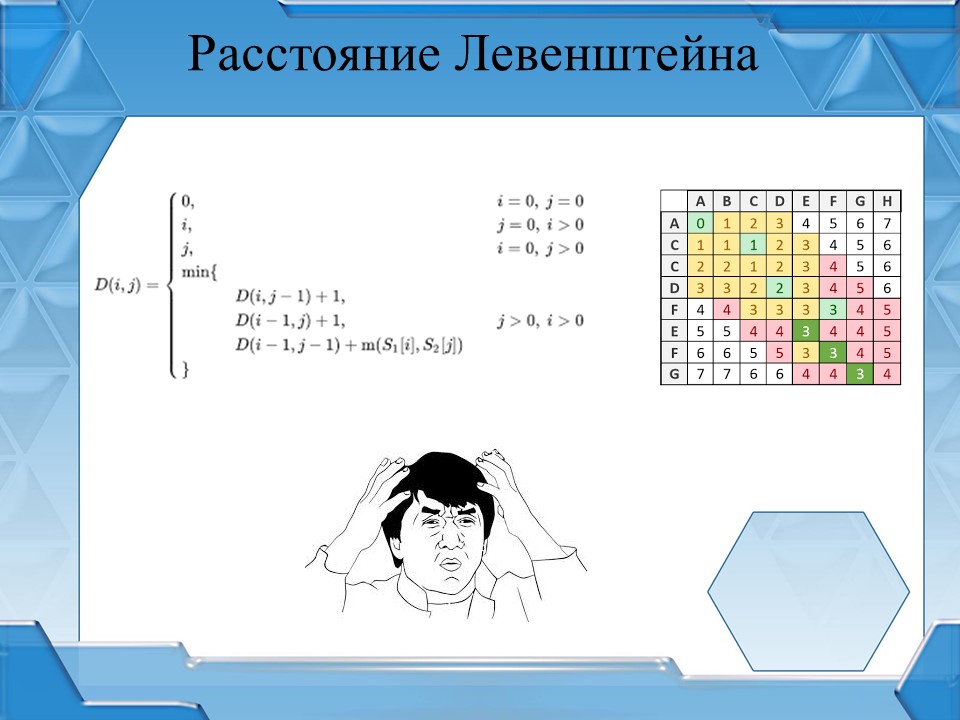
Расстояние Левенштейна – это метрика, которая показывает разность между двумя последовательностями символов. Определяется как количество односимвольных операций вставки, удаления либо замены, необходимых для превращения одной последовательности символов в другую. Чем меньше расстояние Левенштейна, тем более похожи две последовательности символов.
В Яндекcе, Гугле, во всех поисковых движках высчитывается расстояние Левенштейна. На его основе выдается рекомендация тем же Гуглом, когда мы в поисковом запросе делаем опечатку.
На слайде показана общая формула для нахождения расстояния Левенштейна.
Команда, которая занималась задачей по автоматическому разнесению банковских выписок, сначала хотела реализовать эту формулу в языке 1С.
Но перед началом разработки один пытливый ум решил поискать, может, существует уже изобретенный «велосипед», который можно использовать в стеке 1С. И, оказалось, что программного обеспечения, где считается расстояние Левенштейна, достаточно много. Например, есть библиотека для Python, которая выполняет данные расчеты.
Но более интересным с нашей точки зрения стало то, что в Elasticsearch есть API, которое умеет выдавать нужные нам рекомендации.
Elasticsearch
Elasticsearch – поисковый движок, основным назначением которого является полнотекстовый поиск. У нас в компании он используется для хранения не1С-ных логов и для поиска контактов при работе с телефонией. То есть, компетенции для работы с Elasticsearch у нас существуют.
Но в каждую бочку по ложке дегтя. Elasticsearch – монстр, который пожирает дисковое пространство. Когда-то у нас была задача анализировать в Elasticsearch журнал регистрации 1С целиком. При этом размер файлов базы Elasticsearch становился в 5 раз больше, чем размер исходных журналов регистрации.
Понятно, что скорость поиска той или иной записи в журнале регистрации, которая загружена в Elasticsearch, была несоизмерима со скоростью поиска просто в журнале регистраций. Но все-таки 5 раз…
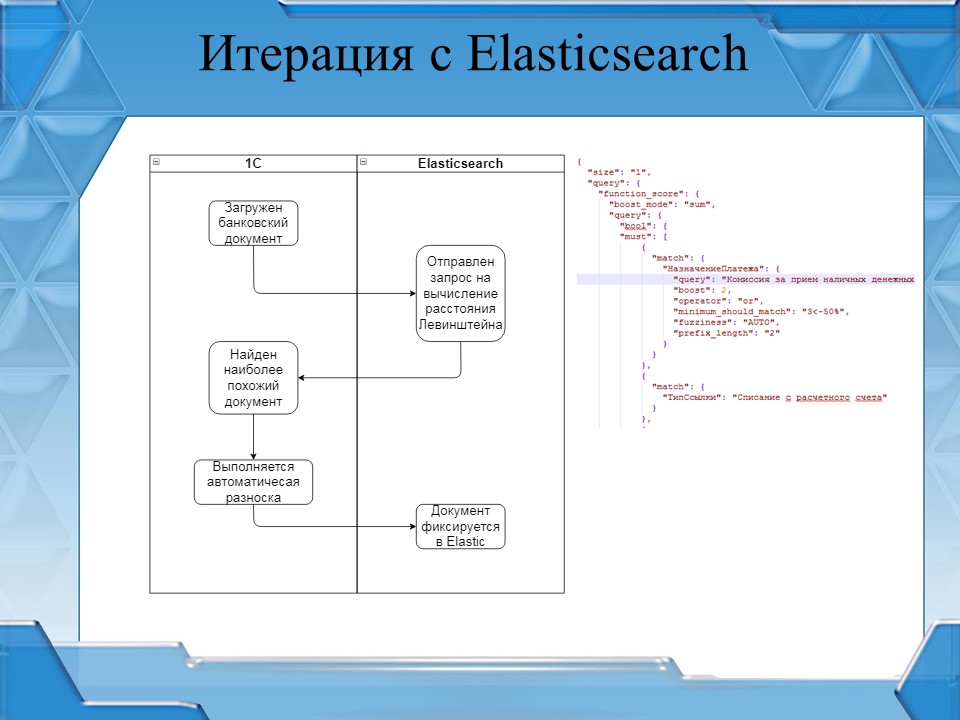
Вернемся к целевой задаче. Напомню, что мы автоматизируем авторазноску банковских выписок в базах клиента.
Чтобы Elasticsearch посчитал расстояние Левенштейна, ему нужны данные. Мы создали индекс под каждого клиента (по сути, под каждую базу) и наполнили данными проведенных документов.
Итоговая модель работы алгоритма такова:
-
Алгоритм автоматического разнесения банковских выписок обращается к движку Elasticsearch для получения ранее проведенного документа с наиболее похожим назначением платежа.
-
Если алгоритм успешно обработан, реквизиты документа заполняются на основе ранее проведенных документов, и документ проводится.
-
Такие же проведенные документы отправляются в Elasticsearch для формирования корректной работы механизма в дальнейшем. Таким образом, мы пополняем данные, которые улучшат работу нашего механизма от документа к документу. С каждым проведенным документом механизм работает все продуктивнее.
-
Документы, которые алгоритм не смог корректно обработать, заполняются все так же руками. Такие документы тоже отправляются в Elasticsearch для пополнения индекса.
На слайде представлен фрагмент запроса, который отправляется в Elasticsearch.
При использовании Elasticsearch КПД нашего механизма вырос до 60-70%.
Дальше пошли индивидуальные правила заполнения для клиентов, поставщиков, комиссии, регулярных платежей в органы. Но это уже совсем другая история.
Целевое КПД достигнуто, внутри корпоративной сети все работает. Но есть нюанс: наши клиенты могут хоститься не только на наших серверах, но и на своих. Значит, механизм должен работать через интернет.
По правилам информационной безопасности и здравого смысла публиковать Elasticsearch в интернет мы не можем, поэтому для таких задач мы используем MULE ESB.
MULE ESB
MULE ESB, он же «ослик» – программное обеспечение семейства ESB (сервисная шина предприятия). Основное назначение шин как класса – интегрировать все со всем с минимальными трудозатратами.
Например, в рамках какого-то сервиса на вход принимается информация в JSON, а источник, который отдает эту информацию, отдает ее в формате XML. Шина возьмет на себя преобразование JSON в XML и выполнит конечную отправку данных.
Авторы MULE ESB неслучайно выбрали для своего ПО такое имя, они реально закладывают в это имя значение «осла», так как MULE ESB берет на себя большую разработческую нагрузку, тем самым облегчая разработчику жизнь.
Для MULE ESB существует много коннекторов, с помощью которых можно экономить время разработки. Справа на слайде представлены виды коннекторов, которые я взял из публичного Anypoint Exchange.
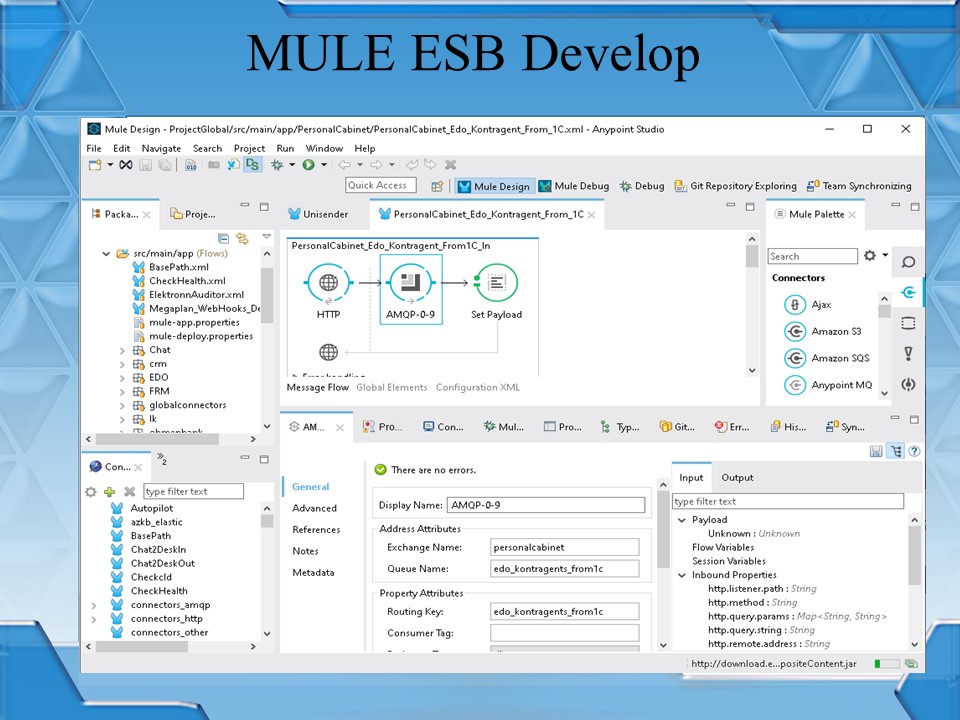
Разработка для MULE ESB ведется в специальной IDE Anypoint Studio: по сути, это как конфигуратор в 1С.
Исходный код MULE ESB – это xml-файлы, в которых прописаны алгоритмы обработки, называемые Flow (потоки).
Anypoint Studio позволяет:
-
вести разработку через графический интерфейс;
-
работать с системами контроля версий;
-
отлаживать проекты с точками останова, с просмотром полученным данных и так далее.

У нас в компании существует корпоративный GitLab. На слайде показано, как выглядит процесс деплоя готового проекта для MULE ESB.
-
разработчик делает проект на локальном компе в локальном репозитории;
-
готовый проект помещается из контура разработчика в тестовый репозиторий;
-
тестовый MULE ESB обновляет свою конфигурацию из тестового репозитория;
-
и если тестовый MULE ESB успешно запустился, и не произошло критических ошибок деплоя, то конфигурация из тестового репозитория переезжает в продакшн-репозиторий (по сути, это две отдельные ветки одного и того же репозитория);
-
а рабочий экземпляр забирает уже конфигурацию из продакшен-репозитория
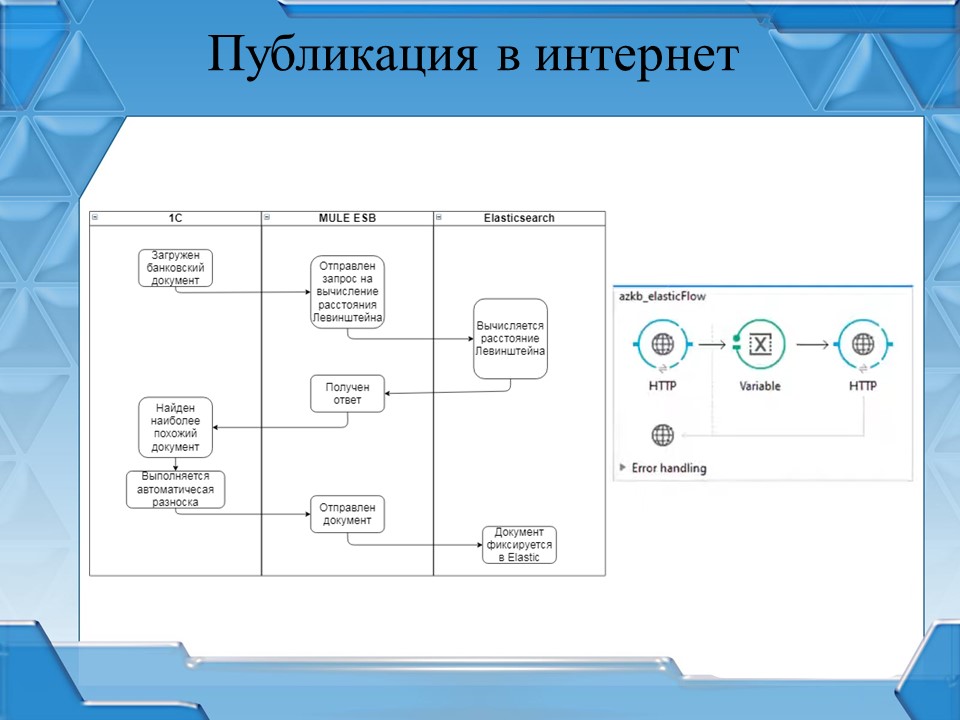
Вернемся к целевой задаче. Нам нужно реализовать механизм автоматической разноски банковских выписок через интернет. Публикуем сервис Elasticsearch на MULE ESB, и наш сервис становится доступным через интернет.
Так как целевое КПД по работе с Elasticsearch было достигнуто ранее, задачу считаем выполненной.
Справа на слайде видно, как эта публикация выглядит в Anypoint Studio – всего лишь три кружочка.

Но проходит время, и чем больше клиентов подключают наш сервис авторазноски документов, тем больше растет нагрузка на Elasticsearch. В один момент сервер Elasticsearch перестал справляться с потоком запросов и завис.
Справиться с этой проблемой можно двумя способами – либо увеличить железо для Elasticsearch, либо реализовать балансировщик нагрузки.
Мы пошли по второму пути и реализовали балансировщик нагрузки – разработали его на базе менеджера очередей RabbitMQ и Redis, который, по сути, является кэшем.
RabbitMQ и Redis
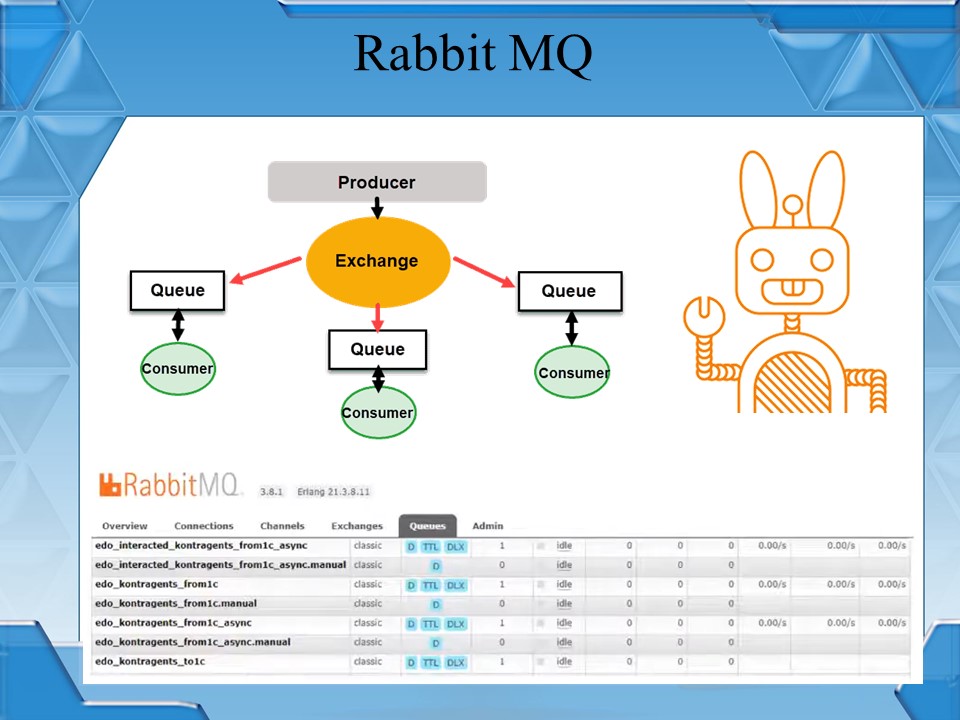
RabbitMQ, он же «кролик» – это программный брокер сообщений на основе стандарта AMQP.
В рамках «кролика» существует три основных объекта::
-
очередь – Queue
-
точка обмена – Exchange
-
и получатель – Consumer.
В «кролик» сообщения отправляются не прямо в очередь, а в «точку обмена» – «точка обмена» через связь с очередью отправляет сообщения в саму очередь, по сути, выполняет функцию маршрутизации.
Получатель сообщения или подписчик (Consumer) вычитывает сообщения из очереди и выполняет его обработку.
Давайте попробуем посмотреть на RabbitMQ глазами простого одинэсника. Если прийти к разработчику и сказать, что нужно поэтапно обрабатывать какие-то сообщения в 1С, то получим регистр сведений «ОчередьСообщений». У меня на одном из предыдущих мест работы в рамках одной информационной базы было 4 или 5 разных регистров очередей, которые возникли из-за того, что задачи делали разные разработчики. Я не говорю, что это плохой подход: он работает, я сам когда-то такие регистры делал.
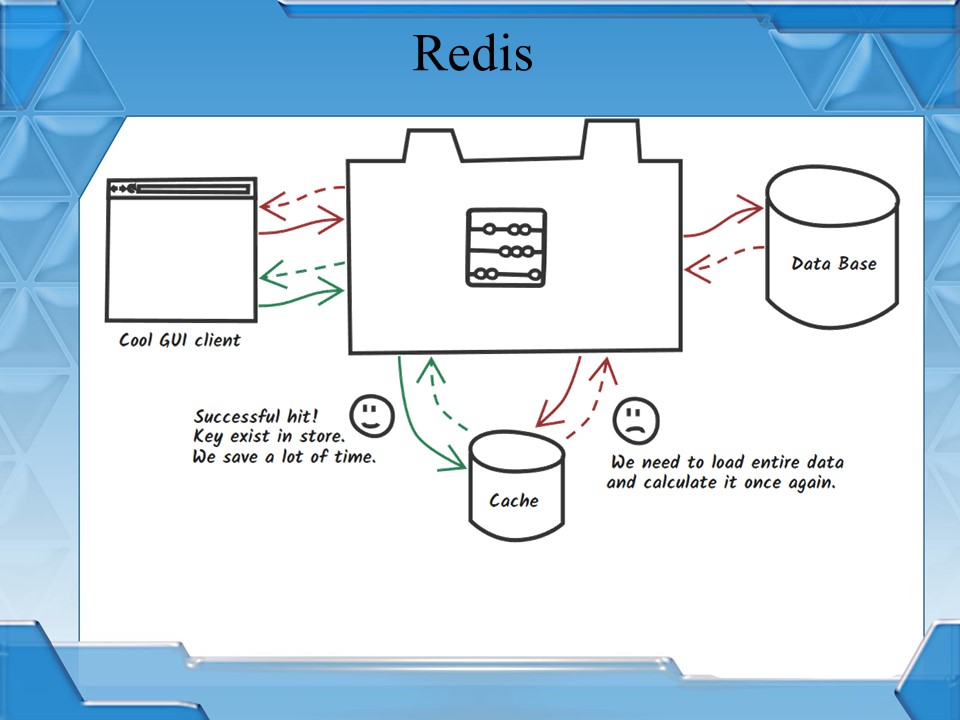
Перейдем к Redis, он же «редиска». Если Redis описать одним словом – это кэш. Если рассматривать подробнее, то это – NoSQL-ная база данных, которая работает со структурами типа «ключ-значение». Если говорить в терминологии 1С, то это – Новый Структура() или Новый Соответствие().
Отличительная особенность «редиски» – все данные находятся в оперативной памяти, что позволяет получать значения по ключу практически мгновенно, потому что отсутствуют реальные обращения к файловой системе.

Снова вернемся к целевой задаче – нам нужно реализовать балансировщик, чтобы наш сервис работал стабильно.
Сначала замечу, что раньше запрос от клиента отправлялся синхронно:
-
в 1С формировался запрос;
-
запрос отправлялся в MULE ESB;
-
MULE ESB отправлял запрос сразу в Elasticsearch;
-
а 1С все еще ждала результата.
Если Elasticsearch по той или иной причине не возвращал результат – механизм автоматической разноски падал. Поэтому мы решили переделать синхронный механизм работы на асинхронный.
Итоговая схема работы
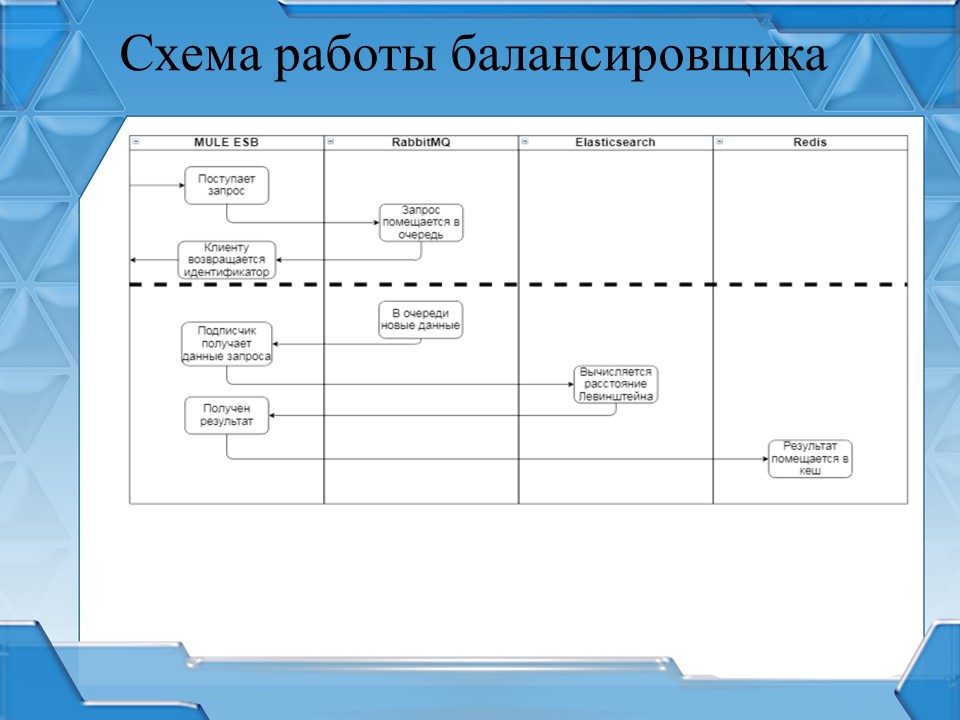
Итоговая схема работы механизма по автоматической разноске банковских выписок стала следующей:
-
в 1С формируется запрос;
-
он отправляется в MULE ESB;
-
MULE ESB кладет запрос в RabbitMQ, а в 1С возвращает идентификатор запроса, который был присвоен в рамках MULE;
-
в MULE ESB реализован отдельный подписчик RabbitMQ, который берет сообщения из очереди и отправляет в Elasticsearch на обработку, дожидаясь результата;
-
результат обработки помещается в Redis с ключом, равным идентификатору, который был присвоен запросу;
-
клиентская база 1С периодически опрашивает MULE ESB по идентификатору запроса;
-
как только в Redis появляется значение для данного идентификатора, значение возвращается в клиентскую базу 1С, и алгоритм автоматической разноски продолжает свою работу.
По сути, мы просто переделали механизм обработки данных с синхрона на асинхрон. Но наш сервис перестал падать, так как обрабатывает запросы в несколько потоков.
Подведем итоги. Механизм работает штатно, дорабатывать ни на одной стороне почти ничего не пришлось.
Мы заплатили небольшим увеличением длительности работы механизма – если раньше документ обрабатывался 5-7 секунд, то после переделки с учетом ожидания обработка одного документа составила 12-15 секунд. Приемлемый результат с учетом того, что все операции происходят в фоновом режиме.
Валидация запросов
В один из моментов к нам пришло понимание: сервис реализован, доступен через интернет, а авторизации на сервисе мы не сделали.
По сути, бухгалтеров это уже не касается, они спокойно могут переключить свое внимание на другие задачи, но тут на сцене появляются аккаунт-менеджеры. Наша CRM-система тоже построена на 1С, и аккаунты хотели из CRM управлять доступностью сервиса по автоматической разноске.
Сразу скажу, что в дальнейшем мы масштабировали эту авторизацию на все остальные публичные сервисы у нас в компании.
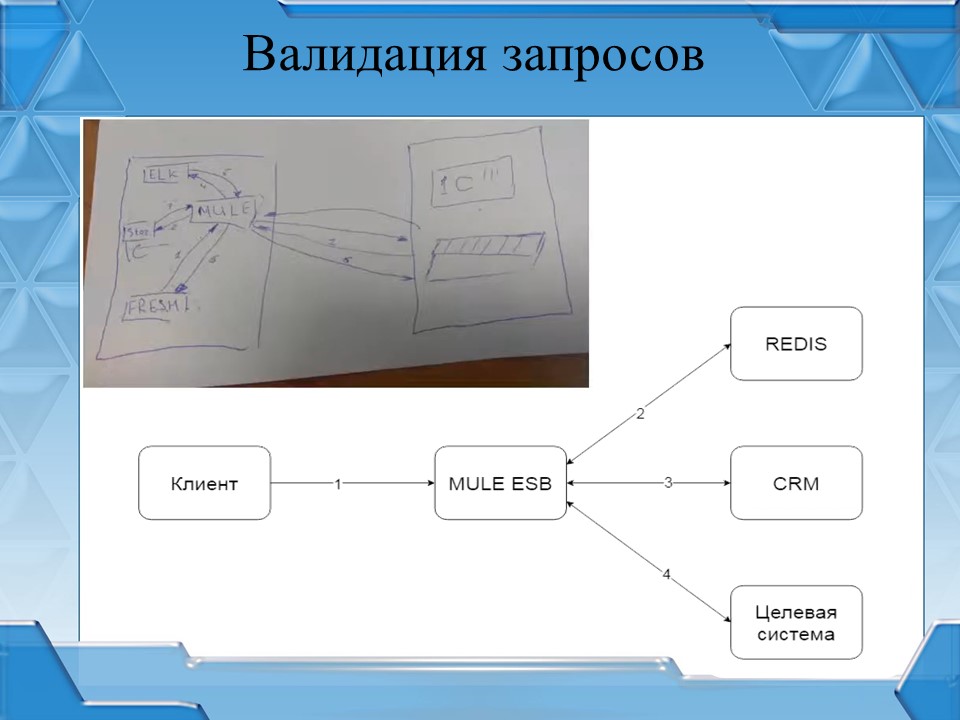
Есть еще один нюанс: авторизоваться должен был не клиент, а база клиента, поэтому мы отказались от базовой авторизации в сервисе. Данный механизм авторизации мы внутри называем валидацией запросов.
На слайде представлена схема первой итерации этого механизма, которая была нарисована на бумажке.
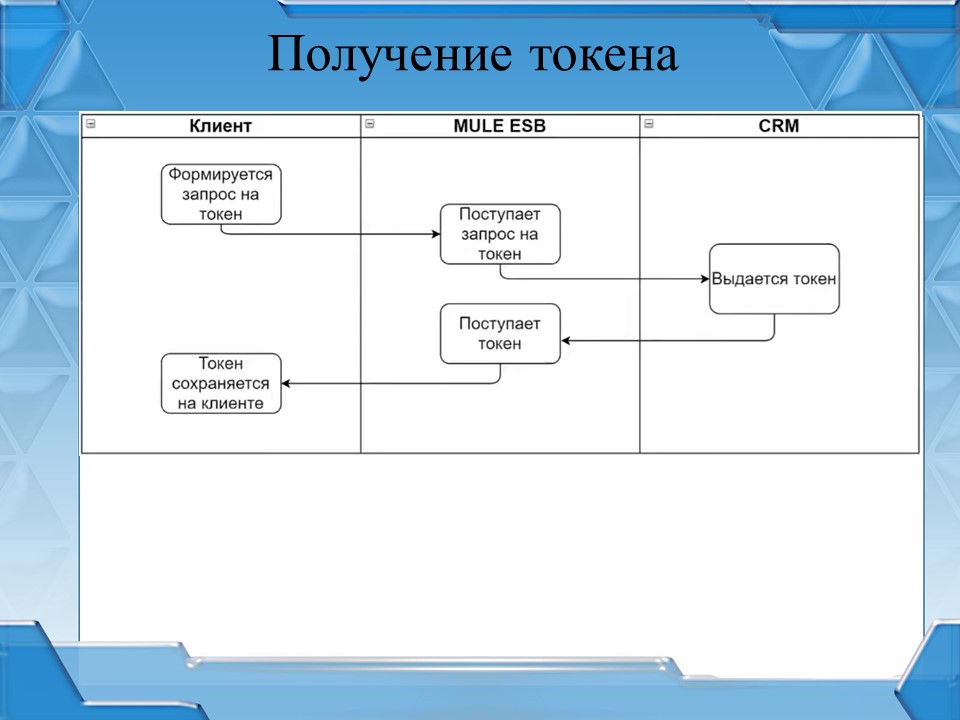
Сама валидация запросов состоит из двух частей: получения токена доступа и проверка токена доступа при выполнении запроса.
Рассмотрим механизм получения токена – как он реализован.
-
Сначала в нашей внутренней CRM аккаунт-менеджерами для определенных клиентов открывается так называемый «канал на получение клиентом токена».
-
Клиент обращается в MULE ESB за получением токена, передавая информацию о себе как о клиенте (как минимум, ИНН и КПП) и информацию о своей базе.
-
А шина в синхронном вызове запрашивает токен у CRM, передавая туда эту информацию.
-
Если в CRM «канал на получение токена» открыт, токен генерируется и возвращается в MULE. Если канал не открыт – токен не генерируется.
-
Если токен возвращается – шина возвращает информацию клиенту и клиент у себя в базе сохраняет выданный токен.
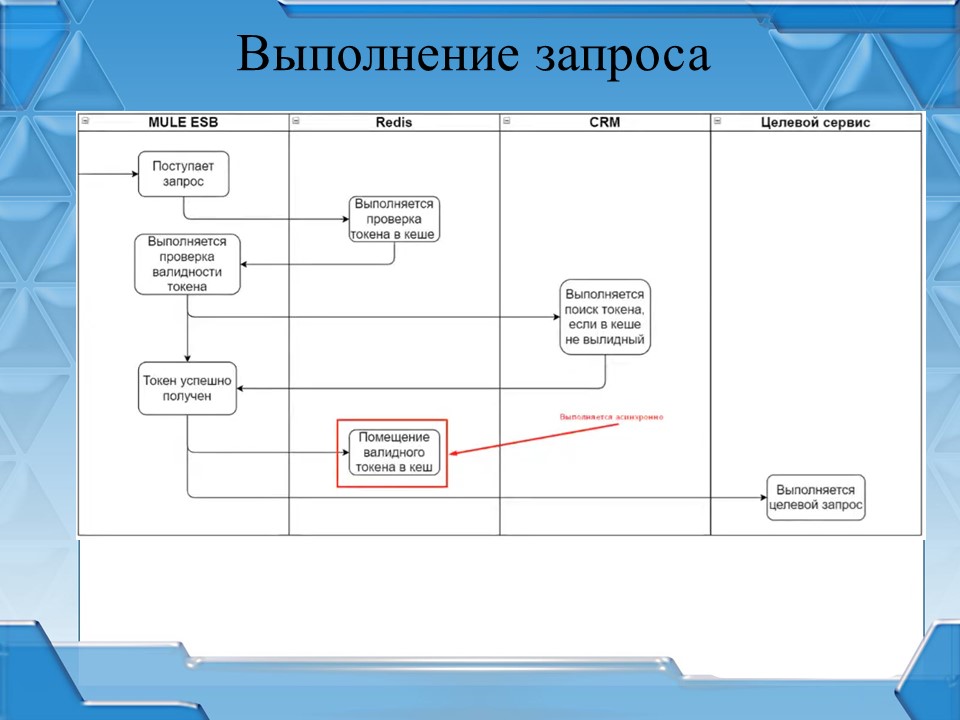
Сама валидация запросов происходит по другому алгоритму.
-
Приходит абсолютно любой запрос в шину, если он подключен к системе валидации. Из запроса получается токен.
-
Потом идем в Redis и проверяем, есть ли такой токен на доступ к нашему сервису.
-
Если в Redis такого токена нет – проверяем в CRM.
-
Если в CRM мы получили разрешение на доступ к сервису – сохраняем его в Redis для кеширования дальнейших обращений и маршрутизируем запрос на целевой сервис, к которому реально обратился клиент.
Токены живут порядка 20-30 минут, поэтому самым длительным выполняется первый запрос, который касается нашей CRM, так как она реализована на базе 1С, а потом затраты на валидацию запроса – 0,010-0,015 секунд.
Итоговая схема
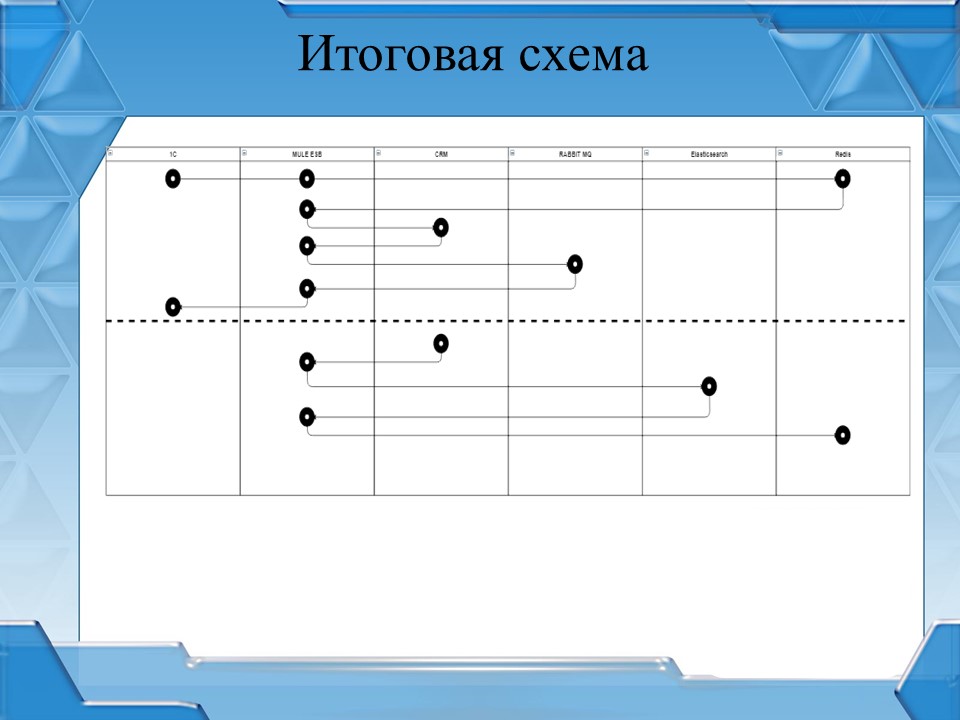
На слайде я постарался уместить всю логику работы сервиса по автоматической разноске банковских выписок вместе с валидацией запроса.
-
Сначала выполняется валидация запроса, при успехе данные помещаются в RabbitMQ,
-
MULE в асинхронном режиме обращается к Elastic, получает результат работы,
-
одинэсный клиент обращается в MULE для получения результата обработки с интервалом в 5 секунд.
На схеме выглядит сложно: куча точек и разных систем, но работает быстро. С точки зрения 1С – это пара строчек кода: выполнить запрос, реализовать цикл с ожиданием и опросить.
Я преднамеренно не выносил в доклад данные о логировании, чтобы не нагромождать картинки. Но скажу, что абсолютно все ошибки на любом этапе работы механизма отправляются в специальные индексы Elastic, а в асинхронном режиме – через RabbitMQ. Если появится такая возможность, я расскажу об этом в другой раз.
Особенности «зоопарка» разных систем (почему не свой «велосипед» на 1С)
Система получилась обширной, использует разное программное обеспечение. Но основа – MULE ESB. С помощью MULE ESB получается в короткие сроки реализовывать сервисы, которые покрывают потребности нашего бизнеса, особенно в интеграционных вопросах и в период, когда требования меняются 5 раз на день.
В ИТ вообще все меняется молниеносно – сегодня один стек технологий, завтра новый. Существует узкоспециализированное программное обеспечение для решения тех или иных задач. Иногда нужно вытаскивать голову из песочницы 1С и смотреть по сторонам.
Вы спросите, разве нельзя было реализовать этот «зоопарк» через 1С? Пять лет назад, когда я делал первую интеграцию с мобильным приложением, я так и сделал. Но это было менее эффективно, особенно, если говорить про интеграционные моменты.
У многокомпонентного подхода тоже есть недостатки: этот «зоопарк» нужно поддерживать, нужны специалисты, мониторинг, администраторы, которые понимают хотя бы 50% из этого зоопарка. Все эти сервисы мониторит Zabbix в том числе RabbitMQ, который информирует в Telegram при возникновении проблем.
«Зоопарк» или одна система – это такой же холивар, как монолит vs микросервисы. Идеальное решение где-то посередине.
Вопросы
Что значит «ослик обновляет конфигурацию в продакшен»? Имеется в виду конфигурация в 1С или что-то в гитлабе?
Имеется в виду конфигурация MULE ESB – она у нее, по сути, такая же, как у 1С. Выглядит как xml-файлики. И как раз эта конфигурация и обновляется в продакшен MULE ESB посредством GitLab, которая используется как система контроля версий. Когда появляется новая версия, MULE ESB забирает себе новую версию конфигурации и обновляет у себя конфигурацию. Это не касается 1С.
Сколько было RPS до балансировки и сколько стало держать RPS после оптимизации?
Я могу сказать только в клиентах. У нас проблемы начали возникать на обработке ежедневных документов для 40 клиентов. После балансировки мы смогли количество клиентов увеличить в два раза. И пока проблем с этим больше нет – они возникают, но больше из-за инфраструктурных внутренних проблем, а не из-за проблем самого Elasticsearch.
Нельзя ли применить машинное обучение для решения определенной части данной задачи?
Можно. И это наша следующая итерация, которая сейчас уже в работе. На текущий момент у нас действительно уже в работе машинное обучение, с его помощью мы сможем поднять процент автоматической разноски с 70% хотя бы до 95. Мы стремимся именно к этому.
За счет того, что посередине применяется RabbitMQ и MULE ESB, эти компоненты в принципе можно заменять один на другой. Можно вытащить из розетки этот компонент поиска по Elasticsearch по скорингу в Elasticsearch и воткнуть туда какой-нибудь веб-сервис с искусственным интеллектом. А все остальное переписывать не придется – оно сохранит свои интерфейсы и будет точно так же работать. В этом тоже своя прелесть есть. Поэтому адаптировать это к машинному обучению может быть очень просто – вытащить один «умный компонент» и вставить вместо него другой, а все остальные оставить как есть. Это одно из преимуществ MULE ESB как «шины предприятия».
Почему RabbitMQ, а не Kafka?
MULE ESB все равно, с кем коннектиться – AMQP-коннектор там без привязки к программному обеспечению. Выбрали RabbitMQ, потому что было больше информации о том, как его применить в сфере 1С.
Почему Redis, а не Memcached?
Потому что у MULE ESB свой собственный встроенный Memcached, но он не подпадает под OpenSource, он за деньги. Купить MULE ESB в рамках России невозможно, он стоит каких-то космических денег. А Redis – это Open Source-решение и там есть коннектор, который можно поставить. Это вопрос экономической целесообразности.
Сколько стоит MULE ESB?
Два года назад мы оценивали, сколько стоит приобрести платформу Anypoint Studio с публикацией онлайн – это все работает только через подписку, купить целиком экземпляр нельзя, а подписка стоит порядка 40 тысяч долларов в год. Сам по себе MULE ESB – бесплатен. Нам достаточно бесплатной части MULE ESB, он работает стабильно, падений нет. Поэтому по деньгам MULE ESB нам обошелся бесплатно. Мы за него никаких денег не платили. Если смотреть в рамках каких-то других шин, то я в своей жизни работал с еще двумя шинами – это WSO2 и Zato. WSO2 – это шина чисто на Java, без какого-то юзерфрендли-интерфейса, разработчику только кодом писать, у Zato почти то же самое. А у MULE ESB все те же самые возможности, только графический интерфейс позволяет буквально в пару кликов разворачивать новые сервисы, маршрутизировать их и спокойно использовать. По крайней мере, порог входа для 1С-ников намного ниже, чем во все остальные.
*************
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "Интеграционные решения в 1С".

Вступайте в нашу телеграмм-группу Инфостарт