
Многие слышали сказку про Золушку.
В ней есть злая мачеха, которая регулярно нагружает Золушку однообразной работой – например, заставляет ее перебирать и сортировать крупу.
Кроме мачехи в сказке есть противные сестры, которые подначивают Золушку и саботируют ее работу. Но если бы они помогли Золушке – вклинились в процесс перебора и сортировки – ее задачи были бы решены быстрее.
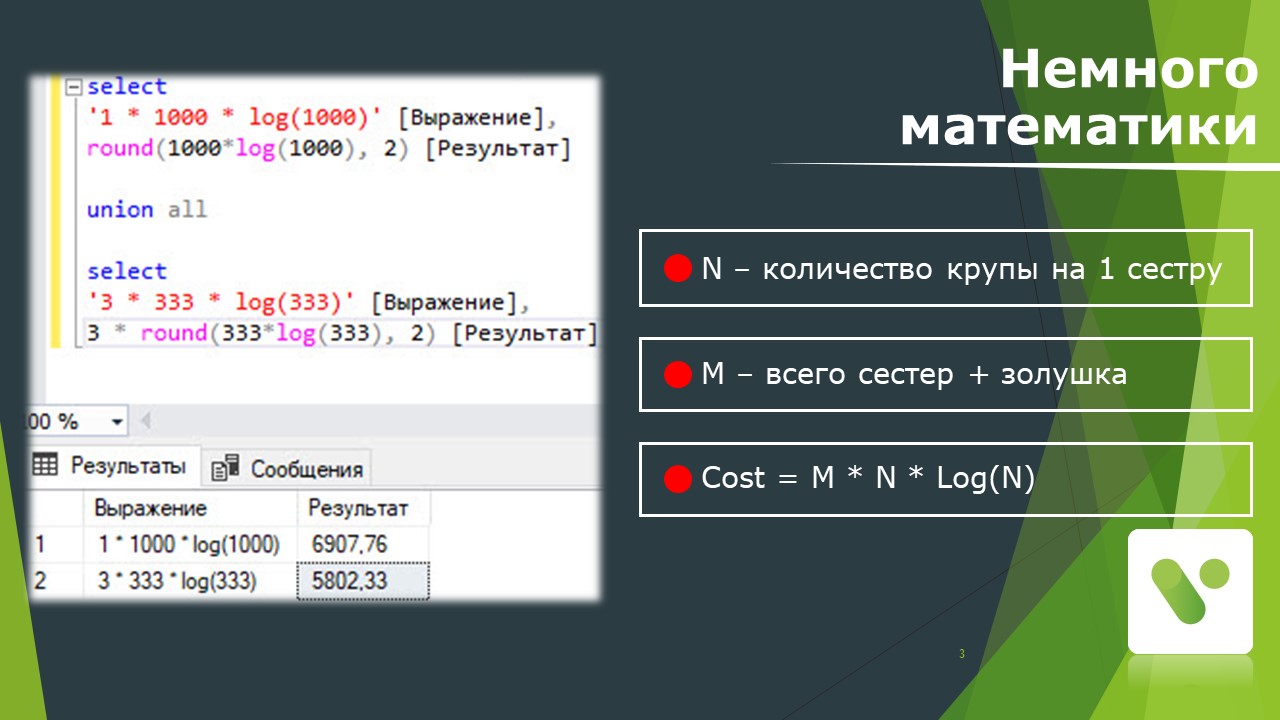
Есть даже математическая формула, которая показывает зависимость сложности задачи сортировки от количества работников, которые занимаются сортировкой, и порций, которые они сортируют.
Cost = M * N * Log(N)
Согласно этой формуле, чем больше работников, тем задачу по сортировке выполнить проще.
Но если бы сестры помогали, а не мешали Золушке выполнять ее работу, в сказке не было бы счастливого конца.
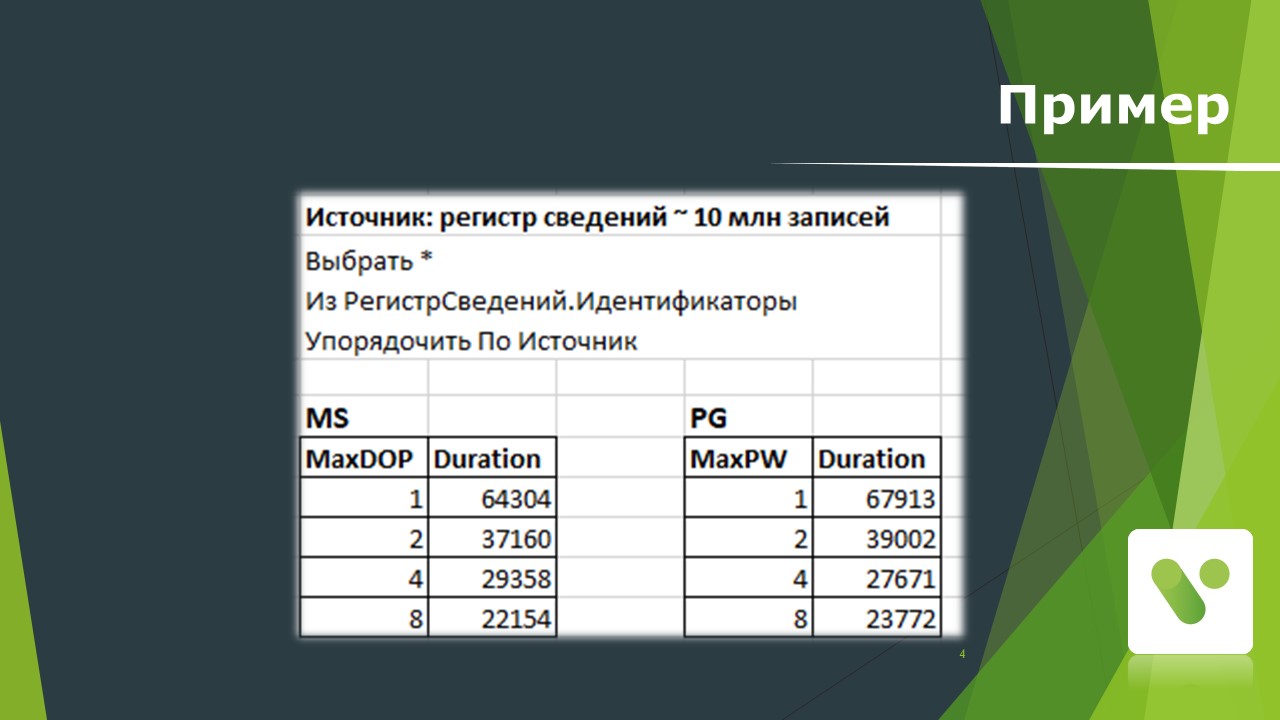
Небольшой пример из жизни: у нас есть MS SQL и есть PostgreSQL. Нужно выполнить запрос – прочитать 10 млн записей из регистра сведений.
При включенном параллелизме, когда мы постоянно наращиваем настройку по количеству процессов, которые обрабатывают задания, время обработки значительно сокращается.
Значения в примере приведены для идеальных условий – они соответствуют ситуации, когда мы зашли в базу в монопольном режиме (в базе больше никого из пользователей нет) и сформировали запрос, а потом увеличили MaxDOP (или количество воркеров на Postgres) и получили результат, который нас устраивает.

Однако большинство компаний, от среднего до крупного бизнеса, почему-то ведут себя как Золушка – не используют параллелизм:
-
на MS SQL у них установлен MaxDOP=1 (максимальная степень параллелизма равна единице, т.е. параллелизм не используется) либо стоит сильно завышенное значение cost threshold for parallelism (настройки порога стоимости для параллелизма);
-
а на PostgreSQL стоит нулевое количество воркеров для обработки узла
max_parallel_workwrs_per_gather = 0.
Почему так происходит? Почему бы не включить параллелизм? Чтобы понять, как это происходит, нужно заглянуть под капот и узнать, как выглядит механизм параллелизма на СУБД MS SQL и PostgreSQL.
План доклада

Не хотелось бы устраивать жаркой битвы между СУБД MS SQL и PostgreSQL, потому что использование той или иной СУБД – выбор каждого, надо использовать ту СУБД, которую хорошо знаешь.
Поэтому попробуем рассмотреть особенности использования параллелизма в обоих СУБД. Но поскольку время у нас ограничено, а тема параллелизма достаточно широкая, будем брать только ключевые вещи:
-
я покажу, что влияет на параллельное выполнение запросов;
-
какие настройки в MS SQL и Postgres включают параллелизм;
-
покажу примеры использования параллелизма;
-
и подведем итоги.
Что заставило меня разобраться с настройками параллелизма

Когда я пришел в компанию на последнем месте работы, меня сразу потянуло заглянуть в настройки СУБД.
К этому были следующие предпосылки:
-
По факту, в компании отсутствовал DBA, при том, что компания большая, на рынке уже давно, в базе 110 одновременно работающих пользователей.
-
Второй момент – с регламентами обслуживания на СУБД все было очень грустно – они просто не успевали выполняться во время технологического окна, которое составляло порядка 4-6 часов. У нас на тот момент было три базы размером около 150 Гб. Вроде не очень много, но почему-то регламенты в них не доходили до финала и завершались с ошибками.
-
Самое страшное – во время работы пользователей была колоссальная нагрузка на ЦПУ – порядка 93%. И это при том, что одновременно работало не так много пользователей (порядка 110) плюс крутилось небольшое число фоновых заданий, которые выполняли определенную работу.

Такая нагрузка на ЦПУ меня насторожила, и я решил проверить гипотезу, связанную с простоем, нехваткой процессорного времени.
-
Первым делом я заглянул в настройки СУБД – как ни крути, там все просто. Я сразу обратил внимание на первичные настройки по памяти, по процессорам (affinity mask) и определенные дополнительные настройки. Как раз в дополнительных настройках было выставлено MaxDOP = 0 (использовать все доступные процессоры).
-
Второе – в момент пика нагрузки я запустил скрипт, который показан на слайде:
select max([runnable_tasks_count]) as [runnable_tasks_count]
from sys.dm_os_schedulers
where scheduler_id<255;
и посмотрел количество ожидающих исполнителей, которые ждут исполнения задания. Это количество варьировалось от 10 до 15 и больше – это тревожный признак, который означал, что для выполнения определенных инструкций операторов запроса процессы, которые их выполняют, находились в режиме ожидания. -
Количество ожиданий CXPACKET было в сотни раз больше, чем любых других. Я чуть позже расскажу, что такое ожидание CXPACKET, когда мы на примерах будем смотреть положительное и отрицательное влияние параллелизма.

Виновники были выявлены быстро – в топ-листе самых долгих запросов по CPU Time и Duration оказались запросы внутри фоновых заданий.
Был еще один момент, который подсказывал, что параллелизм был чрезмерным: CPU Time было значительно больше Duration. CPU Time – это суммарное время, которое складывается из времени каждого ядра, которое выполняет инструкцию запроса.
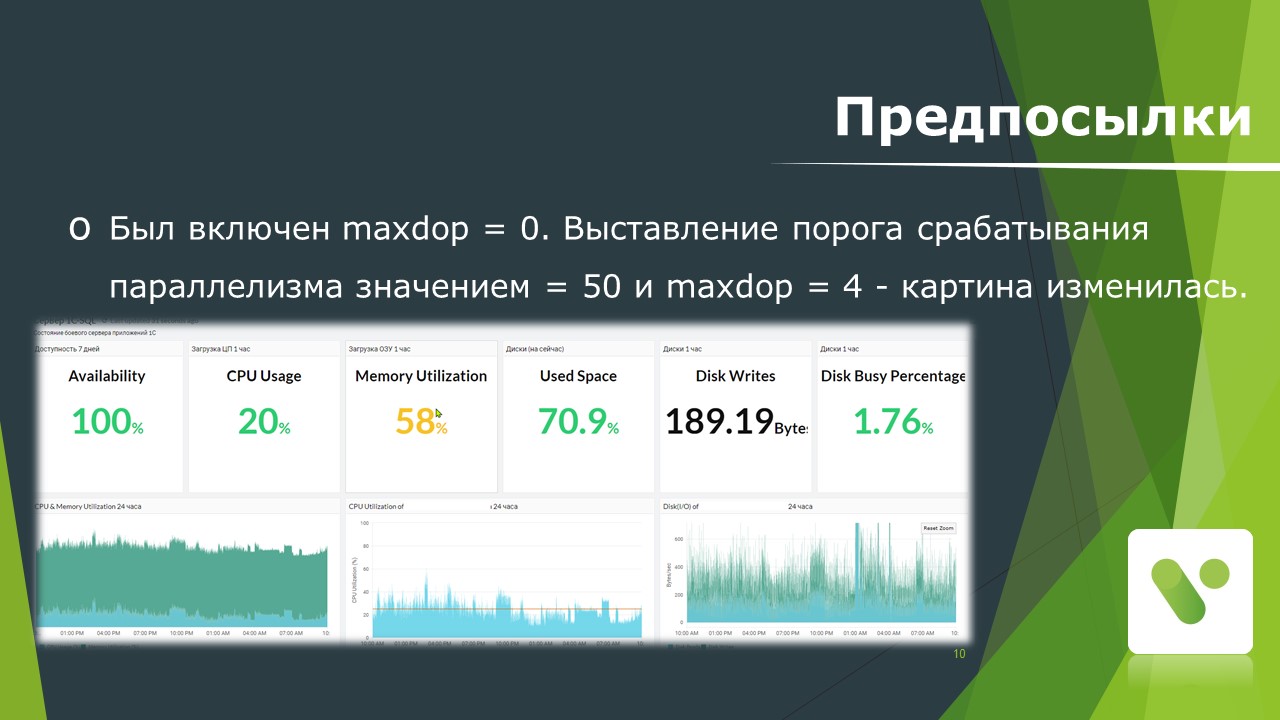
Проблема была решена комплексно:
-
Первое, что бросилось в глаза – была проблема с непопаданием в индексы, поэтому мы применили рефакторинг запросов, которые использовались в фоновом задании.
-
Второй момент – очень сильно тянуло выставить MaxDOP=1, но это было для меня слишком просто, поэтому я принял решение чуть-чуть завысить значение cost threshold for parallelism (порога срабатывания параллелизма) до 50 и ограничил MaxDOP до 4.
Картина значительно изменилась, стало гораздо лучше. Это можно увидеть на графике.

Со временем у нас появился Postgres – мы начали использовать эту СУБД для «Системы взаимодействия» и других баз, которые не являются базами 1С. Мы решили разделить:
-
MS SQL у нас используется для баз 1С,
-
Postgres – для неких агрегированных баз, которые используются для внешних источников данных. Об этом я рассказывал в докладе на июньском митапе Инфостарта.
Мы решили разделить «мух от котлет»: 1С – это одна область, а Postgres – это другая область. Это дает нам определенный профит: мы можем использовать запросы, которые заточены для Postgres – например, обращаться к данным и индексам, которые хранятся в формате json.
На Postgres у нас затюнены запросы, и в принципе, нет большой многопользовательской нагрузки, но, тем не менее, мы там используем параллелизм.
Есть некоторые вещи, на которые мы натыкались, и это я тоже продемонстрирую на примерах.
Немного истории

По-хорошему, параллелизм есть и в MS SQL, и в Postgres. Но в MS SQL параллелизм появился в 1998 году, в PostgreSQL – в 2016 году, разница в возрасте составляет 18 лет.
Характер поведения параллелизма в MS SQL и в Postgres разнится.
-
Если в MS SQL параллелизм включается на каждый чих – любой запрос с небольшой оценкой стоимости начинает параллелиться.
-
В Postgres в настройках по умолчанию они более мягкие – включено два воркера на узел, действует высокий порог срабатывания, параллелиться будет не каждый запрос.
Настройки для параллелизма в MS SQL

В MS SQL у нас есть две ключевые настройки:
-
MaxDOP (max degree of parallelism) – количество процессов, которые запускаются при обработке команды;
-
cost threshold for parallelism – стоимостная оценка, при которой оптимизатор запросов начинает анализировать предварительный план в случае обычного запуска и параллелизма, и выбирает, что ему выгоднее использовать.
Ключевая особенность MS SQL в том, что для применения настроек не нужно перезапускать какие-либо службы, можно использовать скрипт:
EXEC sp_configure 'show advanced options', 1; GO RECONFIGURE WITH OVERRIDE;
GO EXEC sp_configure 'max degree of parallelism', 16;
GO RECONFIGURE WITH OVERRIDE; GO
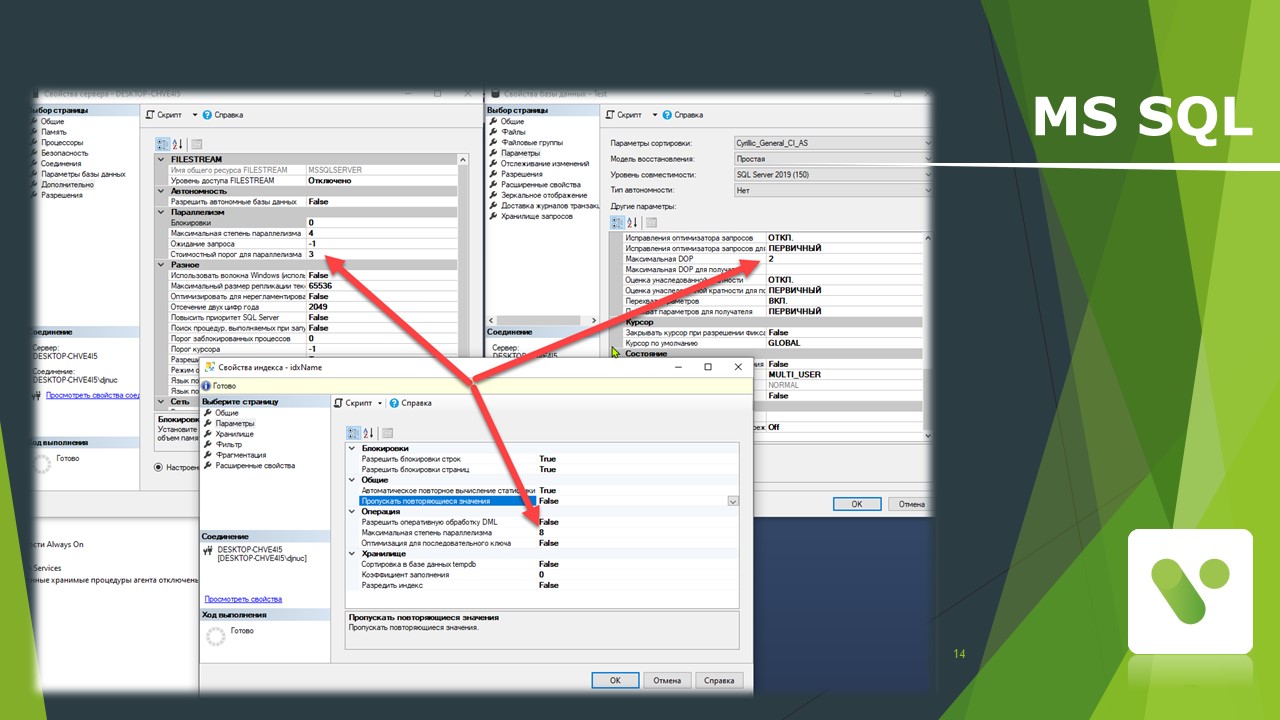
Еще небольшая особенность – мы можем задавать MaxDOP не только для СУБД в целом, мы можем указывать MaxDOP для конкретной базы и для индекса.
Настройку, которая приведена на слайде, следует читать как: я буду использовать указанную степень параллелизма, но не более, чем указано в глобальной настройке.
Обратите внимание на возможность выставления MaxDOP для индекса – это очень крутая штука, которую можно использовать в работе.
Настройки для параллелизма в PostgreSQL

В Postgres настроек немного больше, но не все нужно трогать. Есть ключевые настройки.
-
max_parallel_workers_per_gather – количество воркеров, которые запускаются на узел. Это основополагающая настройка, если вы ее выставите в ноль, параллелизм не будет отрабатывать, будет работать один процесс, один оператор. Когда оптимизатор запросов принимает решение, что для запроса нужно применять параллелизм, он смотрит на этот параметр и определяет, сколько ему нужно воркеров, чтобы выполнить этот оператор запроса.
-
Затем оптимизатор проверяет параметр max_parallel_workers – смотрит, сколько всего может выполняться параллельных воркеров, а в конце – параметр max_worker_processes (сколько воркеров в системе доступно). Исходя из этой комбинации, у нас будет запущен параллелизм или не будет.
-
parallel_setup_cost (parallel_tuple_cost) – стоимостная оценка, при которой стартует параллелизм. О том, как эта оценка высчитывается: есть неплохое видео от Олега Иванова с конференции HighLoad. Там все достаточно хорошо объяснено.
-
min_parallel_table_scan_size (min_parallel_index_scan_size) – параметры, связанные со сканированием таблиц и индекса. Опираясь на них тоже будет определяться: нужно нам запускать параллелизм или нет.
-
По умолчанию для параметра min_parallel_table_scan_size стоит 8 МБ. Если размер таблицы гораздо больше – например, если при скане таблицы будет затрачено 24 МБ на выборку (там идет кратность 3), будет подключаться дополнительный воркер на то, чтобы обработать этот участок.
-
Для параметра min_parallel_index_scan_size значение гораздо меньше: 512 килобайт, но там все зависит от страниц – при перечислении 64 страниц мы это значение превысим, будет также подключаться дополнительный воркер, который обеспечит параллельную обработку.
-
-
Параметром enable_parallel_append мы можем включить параллелизм для соединения двух запросов операцией «ОБЪЕДИНИТЬ» или «ОБЪЕДИНИТЬ ВСЕ». Если этот параметр отключен, конструкции такого вида на Postgres не будут параллелиться. По умолчанию, включен (установлен в ON).
-
enable_parallel_hash – параллельная сборка по хэшу. По умолчанию тоже включен (установлено значение ON).
-
Есть параметр force_parallel_mode – сейчас всегда по умолчанию в OFF. Его можно принудительно включить в ON, и оптимизатор запросов будет вести себя по-другому – он будет на каждый чих пытаться все распараллелить, почти все операции будут уходить в параллелизм. Данную настройку ни в коем случае нельзя включать на продакте, потому что будут проблемы поведения – в параллелизме все-таки есть определенные минусы, о которых я чуть позже расскажу.
Применяются настройки либо перезапуском службы:
service postgresql restart
Либо можно применять команду alter system, где указать определенное количество воркеров на узел и перезагрузить конфигурацию:
alter system set max_parallel_workers_per_gather=N;
select * from pg_reload_conf();
Что параллелится и не параллелится в MS

В MS хорошо параллелятся:
-
Сканы индексов и таблиц, если используется дополнительная последующая агрегация – например, подсчет количества COUNT() с группировкой GROUP BY (СГРУППИРОВАТЬ ПО).
-
Объединение запросов – операторы ОБЪЕДИНИТЬ и ОБЪЕДИНИТЬ ВСЕ параллелятся достаточно хорошо.
-
Реструктуризация базы данных. Начиная с 8.3.11 был изменен механизм в платформе, когда мы не создаем новую таблицу, перенося туда данные, а просто говорим alter table и формируем новую структуру колонок и делаем rebuild index. В этом случае проверяем себя: есть профит: 60-69%, но точно есть.
-
Группировка наборами и конструкция «ВЫРАЗИТЬ» тоже достаточно хорошо параллелятся на MS SQL.
-
Формирование временных таблиц (операция ПОМЕСТИТЬ ВТ) на MS SQL параллелится, но в PostgreSQL есть свои особенности: он там не параллелится.
-
Соединение таблиц.
-
Хорошо параллелится соединение двух отсортированных наборов таблиц, которые получены из покрывающих индексов.
-
На удивление хорошо параллелятся вложенные запросы, если имеет место наследование индексов.
-

Из того, что не параллелится – таких ситуаций на MS SQL значительно меньше.
-
При использовании конструкции TOP в некоторых случаях параллелизм может отключаться.
-
Сканирование без агрегации не параллелится и на MS SQL, и на Postgres, потому что проще выбрать все из таблицы, просканировав ее, чем разбивать все на определенные потоки, и потом собирать их.
-
Автоматический режим блокировок (SERIALIZABLE) тоже отключает полностью параллелизм.
Что параллелится и не параллелится в Postgres

В Postgres количество операторов и конструкций, которые параллелятся, немного меньше. Здесь практически то же самое, что в MS SQL:
-
сканы индексов таблиц с последующей агрегацией;
-
объединения запросов;
-
соединение таблиц, особенно merge join;
-
реструктуризация базы данных 2.0 – тоже есть профит, при включенном параллелизме наблюдается положительный эффект. Причем, если говорить о битве MS SQL и PostgreSQL, разница по времени небольшая – если оценивать процентное соотношение, если в MS SQL мы выходили на 60-69%, то в Postgres 60-62% – это достаточно неплохо.

Что, к сожалению, не параллелится в PostgreSQL:
-
группировка наборами;
-
использование конструкции «ВЫРАЗИТЬ» в запросе;
-
сканирование без агрегации;
-
временные таблицы (использование ПОМЕСТИТЬ ВТ) – грусть и печаль. Они не параллелятся – не знаю, почему. На MS SQL это хорошо работает, возможно, позже это введут и в Postgres.
-
полное внешнее соединение;
-
режим автоматических блокировок (SERIALIZABLE) тоже полностью отключает параллелизм на СУБД в конкретном запросе.
Инструментарий

Хочу показать несколько примеров, связанных с параллелизмом, и посмотреть все это в контексте определенных инструментов.
Запросы я буду показывать на MS SQL и PostgreSQL, но поскольку у меня всего одна лицензия, я не буду одновременно запускать два клиентских контекста:
-
запросы к MS SQL я буду выполнять из профайлера – мы будем обращаться к конкретной базе и считывать данные из таблиц 1С;
-
а вот запросы в PostgreSQL мы будем вызывать из контекста 1С.
В случае с MS SQL мы можем:
-
мониторить план запроса через Profiler или Extended Events;
-
анализировать количество ожиданий CXPACKET;
-
писать определенные скрипты, которые получают топы запросов 1С, и сравнивать для них CPU Time с Duration.
Все это нужно смотреть в совокупности с включенным параллелизмом или отключенным. Если профита по Duration нет, то, по сути, у вас нагружаются ядра, а никакого выхлопа от этого всего нет
Анализ параллелизма с помощью Profiler для MS SQL
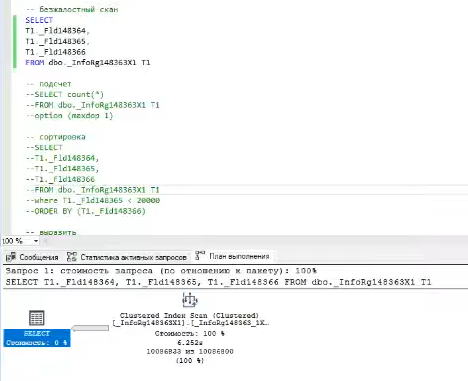
Сканирование таблиц без агрегации – напомню, что оно не параллелится: проще прочесть таблицу полностью, чем запускать параллельность. Это видно по статистике активных запросов и по плану выполнения – был прочитан полностью индекс и все выбрано из него.
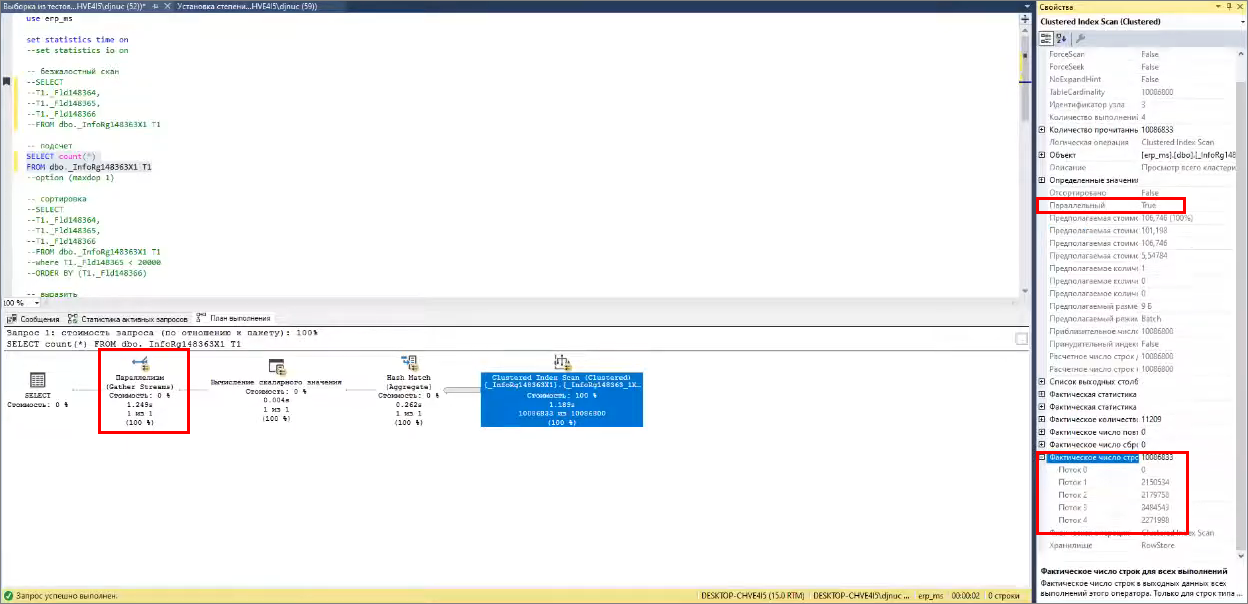
Подсчет количества записей: мы выбираем все записи и применяем агрегацию – функцию count(*) . В этом случае можно наблюдать, что у нас включается параллелизм – это видно по статистике активных запросов и по плану выполнения
План запросов в MS SQL, который использует параллелизм, отличается:
-
во-первых, появляется оператор Gather – ярлычок со стрелочками, который указывает на включение параллелизма,
-
во-вторых, в окне свойств видно, что оператор Clustered Index Scan будет выполняться параллельно (Параллельный – True)
-
в-третьих, можно раскрыть фактическое число строк, которое было выбрано, и увидеть, что оно было распределено по потокам – плюс-минус порции равны. Обратите внимание, что включен MaxDOP=4, но у нас используется 5 потоков. Нулевой поток используется для того, чтобы собирать все данные и подавать правильные команды на операторы – это следящий поток.
Механика получения данных справа налево ничем не отличается от непараллельных запросов, у нас лишь добавляется оператор Gather, который объединяет информацию со всех потоков и передает ее на клиентский контекст.
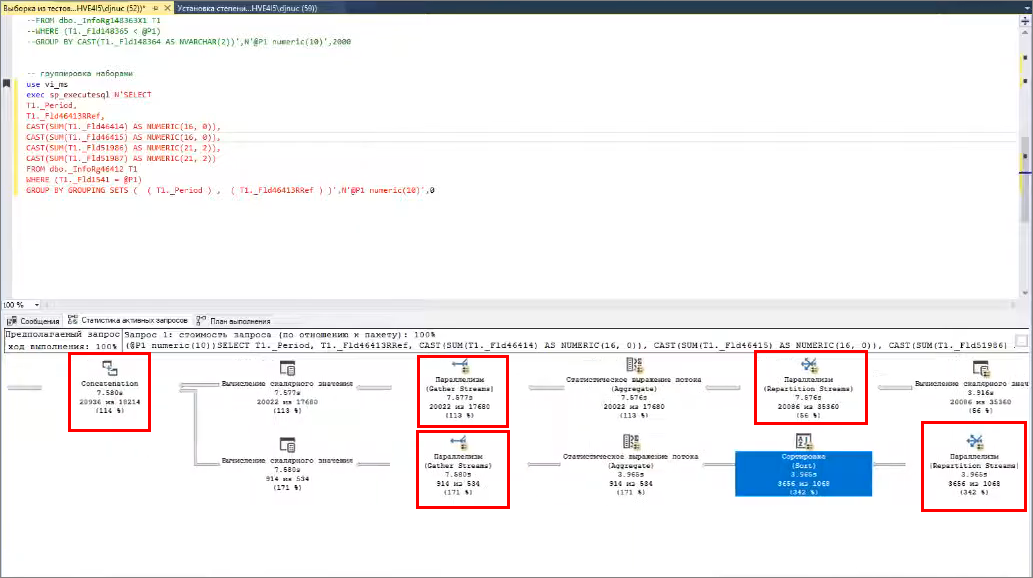
Группировка по наборам (операция СГРУППИРОВАТЬ ПО ГРУППИРУЮЩИМ НАБОРАМ – GROUPING SETS) – здесь используется больше операторов параллелизма.
-
Сначала происходит выборка, она распределяется по потокам. Затем она попадает на оператор параллелилизма Repartition Streams – это оператор пераспределения, который может сохранять сортировку. Он перераспределяет выборку по потокам таким образом, чтобы они потом могли эффективно сортироваться и агрегироваться.
-
Далее вызывается оператор параллелизма Gather – это самый распространенный оператор, который собирает данные.
-
И в дальнейшем происходит объединение двух группирующих наборов (оператор Concatenation) – результат выдается на клиентский контекст.
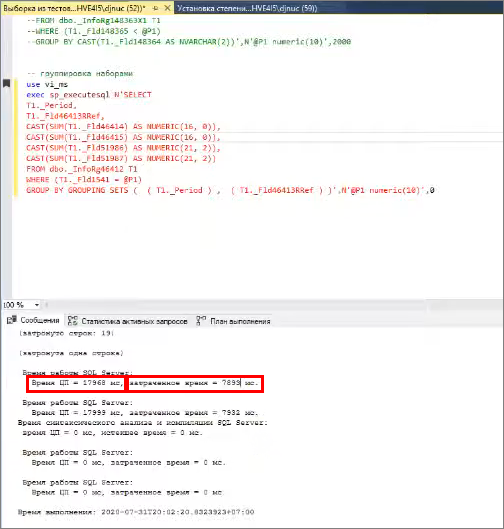
Топ запросов по Duration и CPU Time, где CPU Time >>> Duration
Как еще можно определить, что у нас все выполнялось параллельно?
Если мы посмотрим время работы ЦП, то при параллельном выполнении оно будет значительно больше, чем время, затраченное на выполнение запроса. Напомню, что в качестве времени ЦП здесь подсчитывается суммарное время процессов, которые были выполнены для конкретного оператора.
При использовании Extended Events подход такой же, как и с Profiler – мы можем собрать определенные метрики по Duration и CPU Time и определить, использовался ли параллелизм для конкретного запроса или нет.
По комбинации этих двух параметров можно сопоставить, во сколько раз CPU Time превышает Duration при включенном параллелизме и поиграть с параллелизмом.
Можно сделать грубо: поставить MaxDOP=1, собрать метрики и посмотреть, если Duration отличается незначительно, то профита от параллелизма нет.
Количество ожиданий CXPACKET
Как еще понять, есть ли у нас проблемы с параллелизмом? Можно проанализировать количество ожиданий CXPACKET. Статистику по этому ожиданию можно получить из представления DMV sys.dm_exec_requests – об этом рассказано в статье на Хабре.
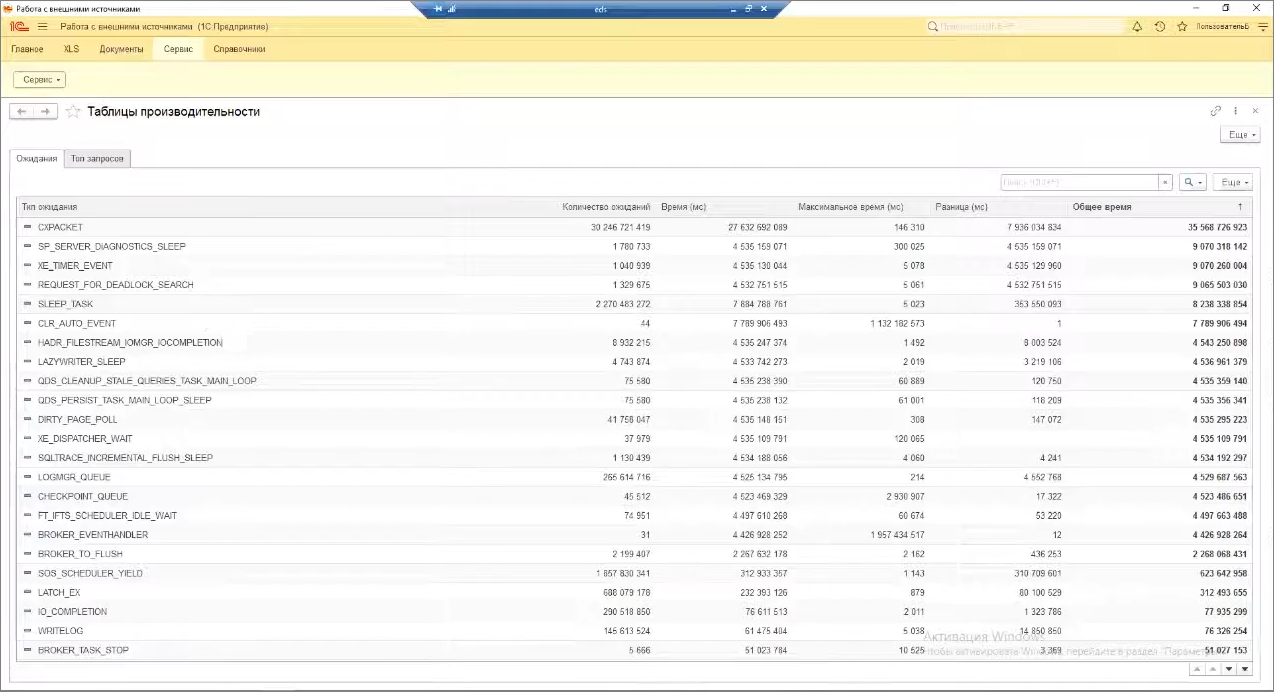
Как это выглядит на примере? У меня есть база, где собрана статистика по ожиданиям. Здесь как раз можно увидеть данные кейса с чрезмерным параллелизмом, который я разбирал, когда пришел в компанию – как видите, количество ожиданий CXPACKET здесь в сотни раз больше, чем любых других ожиданий.
Обычно проверяется, насколько CXPACKET коррелирует с другими ожиданиями. Например, с PAGEIOLATCH_XX – ожиданием на чтение страниц в буфер. Если длительности этих двух типов ожиданий находятся рядом друг с другом, значит, у нас есть процессы, которые ждут своей очереди на выполнение – ждут страницы для чтения, чтобы считать их в буферный пул. Это с большой долей вероятности говорит о том, что настроены слишком мягкие значения для параллелизма – он пытается включиться везде, занять все ядра по каждому чиху.
При условии, что и 1С, и СУБД крутятся на одном сервере, начинается определенная борьба за ресурс. Если используется Windows – он как-то сможет разрулить ситуацию, но если Linux – не знаю, насколько гибко это работает.
На что ориентироваться при настройке параллелизма для MS SQL
Количество ожиданий CXPACKET нужно уменьшать. Как это можно сделать?
-
На MS SQL можно выставить MaxDOP=1 (отключить параллелизм)
-
Или, если вы все-таки жаждете использовать параллелизм, поиграйтесь с параметром cost threshold for parallelism (настройка порога стоимости для параллелизма). Его можно завысить на максимальное значение (например, выставить 100) и постепенно уменьшать, наблюдая за статистикой – она накапливается с момента последнего перезапуска сервера (или службы).
Если количество ожиданий CXPACKET приближено к такому же значению при MaxDOP=1, то можно оставить текущие настройки параллелизма – при реструктуризации базы данных у вас будет включаться параллелизм, а на мелкие и средние запросы он включаться не будет. Это приведет к тому, что у вас будут свободные ядра для выполнения других задач.
Для включения плана запроса в PostgreSQL– модуль auto_explain
Для мониторинга того, есть ли профит от включения параллелизма в PostgreSQL, можно включать модули, которые идут в комплекте с ним. Например, auto_explain – онлайн-сбор логов. И pg_stat_statements.
Но если вы так делаете, у вас логи значительно возрастут, на каждую параллельную ветку кусочек запроса будет писаться в лог, поэтому, если вы включаете это на продакшне, будьте готовы, что у вас закончится место на жестком диске.
Анализ параллелизма с помощью чтения плана запроса для PostgreSQL
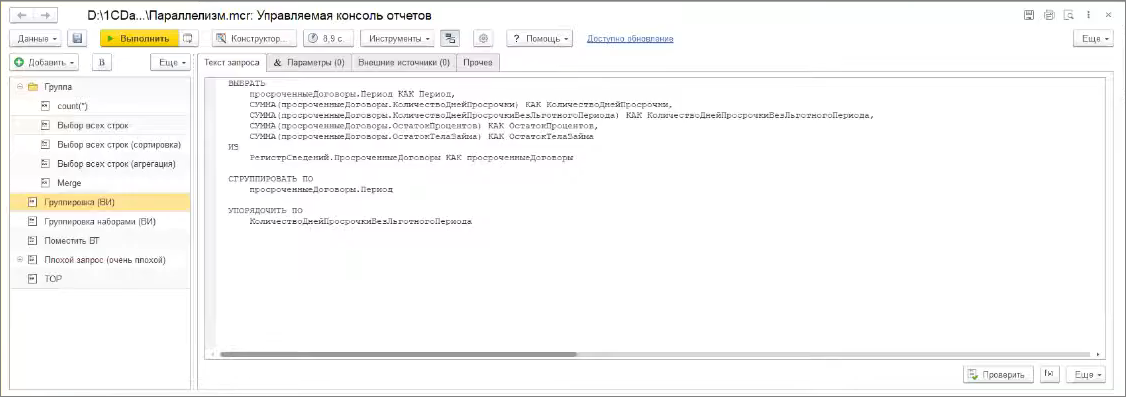
Рассмотрим ситуацию с параллелизмом в PostgreSQL на базе 1С.
Мы выполним запрос для выборки с агрегацией, посмотрим, как это отражается в плане запроса – рассмотрим отличия плана запроса для PostgreSQL от MS SQL и посмотрим с помощью инструментов, есть ли профит от использования параллелизма.
Запрос выполняется достаточно долго, потому что в этом регистре сведений, напомню, 10 млн записей.
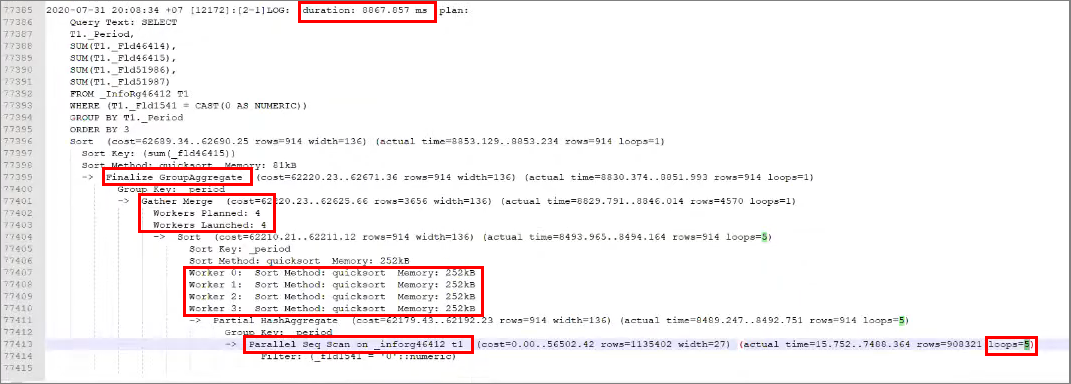
Анализировать план я буду в Notepad++ – я им всегда пользуюсь, читая планы запросы Postgres.
Конечно, есть специальные визуализаторы – например, хорошо себя зарекомендовал сервис https://explain.tensor.ru/ от СБИС (он же Тензор). Но в принципе, текстовая составляющая плана запроса для многих ясна – планы запросов читаются с конца на начало.
Какие моменты здесь говорят о параллелизме.
-
Здесь у нас полное параллельное сканирование таблицы Parallel Seq Scan. Ему выделено 4 воркера и 5 выполнений (loops = 5).
-
Здесь также есть нулевой поток, которые координирует данные, поступающие ему от параллельных процессов, следит, чтобы все собралось в узле Gather Merge – вы видите, что это сортируется в памяти и происходит сборка.
-
Мы видим количество запланированных воркеров на выполнение данного задания – Workers Planned;
-
И есть количество физически запущенных воркеров – Workers Launched.
-
И дальнейшее агрегирование – Finalize GroupAggregate.
Как можно понять, есть ли у нас проблемы при включении параллелизма на Postgres? Подход такой же, как на MS SQL – смотрим на суммарное время выполнения запроса Duration, отключаем параллелизм, выполняем запрос и снова смотрим Duration. Если значения почти не отличаются, то эффекта нет.
Выборка из представления pg_stat_statements, где total_time-blk_read_time < 0
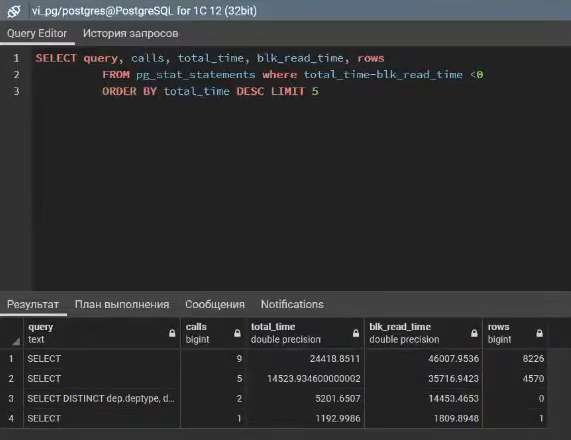
Другой момент – можем использовать представление pg_stat_statements и фильтровать из него запросы, для которых получается минусовое значение total_time-blk_read_time – суммарное время выполнения минус время ожидания на чтение блоков. При параллелизме это значение с большой долей вероятности может уходить в ноль.
Такой простенькой конструкцией можно отловить запросы, выполненные параллельно, посмотреть их total_time. Если он будет незначительно отличаться при включенном и отключенном параллелизме, тут нужно подумать, стоит ли использовать параллелизм.
Проблема временных таблиц в PostgreSQL
Хочу рассказать про момент, связанный с временными таблицами – это особенно касается типовых конфигураций – ERP, Бухгалтерия и т.д.
Если у вас на MS SQL был включен параллелизм, и запросы работали идеально, но как только перевели на Postgres – начались проблемы. Здесь могла выстрелить ключевая особенность – временные таблицы в PostgreSQL не включают параллелизм.
Типовые решения часто используют конструкции с помещением во временные таблицы. Особенно это касается блока ЗУП в ERP и конфигурацию «Бухгалтерия предприятия».
Если у вас запросы на MS SQL выполнялись за 3 секунды, а на Postgres обрабатывают 5 секунд, пользователи заметят разницу, и ничего хорошего не будет. По сути, у вас включен параллелизм на Postgres, вы хотите, чтобы все работало, как на MS SQL, но такого не будет, запросы будут выполняться медленнее.
Ложка дегтя

К чему еще может привести включенный параллелизм:
-
Чем больше пользователей работает при включенном параллелизме, тем больше ядер будет задействовано. Будет нехватка процессорного времени.
-
Одновременно будет использоваться больше памяти, потому что есть нулевой поток, который все собирает, ему нужны ресурсы и память. Иногда лучше параллелизм в таких случаях не использовать.
-
Если у вас неактуальная статистика, параллелизм может сразу «провалиться» – начать включаться там, где он не нужен. Неактуальная статистика ведет к неверной оценке, когда оптимизатор запросов будет пытаться распараллелить выполнение выборки, но профита от этого не будет.
-
Включение логирование в PostgreSQL – это как раз модуль auto_explain. Если включаем, будьте готовы, что логи вырастут.
-
При включенном параллелизме время выполнения запросов будет варьироваться – все очень зависит от количества свободных ресурсов. Один и тот же запрос может в один момент при параллелизме выполняться минуту, в другой момент – две минуты. Эта вариация вносит некую хаотичность, которую сложно отследить.
-
В некоторых версиях платформы, более старых, и на более старых версиях СУБД возникали дедлоки при параллелизме – это описано в статье на ИТС. Слава Богу, сейчас такого нет, но об этом можно почитать. В этом случае нужно однозначно включать MaxDOP=1, и проблема уйдет.
Рекомендации

Если вы все-таки решили использовать параллелизм на MS SQL или на PostgreSQL, делайте это аккуратно.
-
Определенные сложные регламентные операции, у которых высокая оценка выполнения, мы делаем в технологическое окно, отведенное под операции 1С. Там у нас включается паралеллизм, и все прекрасно выполняется.
-
На проде мы завышаем значения cost threshold for parallelism в MS SQL – это тоже делается скриптом (так же, как включается MaxDOP), и у нас нет негативного эффекта от параллелизма. Да, некоторые запросы пробивает, но в целом наблюдается стабильное поведение системы.
-
Если используете PostgreSQL, то может быть вообще нет смысла трогать конфигурационный файл postgresql.conf в части асинхронного поведения. Потому что там достаточно мягкие настройки параллелизма и не все запросы будут пробиваться на параллелизм.
-
Используйте мониторинг, ведь ресурсы памяти и процессора ограничены, и при параллельном поведении могут быть непредсказуемые варианты.
-
Если используйте параллелизм, включайте голову, делайте это с умом.
Использованные источники
-
Скрипты «правильной» фрагментации https://ola.hallengren.com/downloads.html
-
Включение онлайн-формирования плана запросов на PostgreSQL https://postgrespro.ru/docs/postgrespro/12/auto-explain
-
Параллелизм MS https://youtu.be/H_UrnBK7l74
-
Параллелизм PG https://youtu.be/jWIOZzezbb8
-
Сервис анализа планов запросов для PostgreSQL https://explain.tensor.ru/
-
Настройка параметра MaxDOP для MS SQL https://its.1c.ru/db/metod8dev/content/5945/hdoc
-
Как определяется COST в PostgreSQL https://youtu.be/hOjaIO5qi3E
Вопросы
Вы уже сказали, что если ядер не много, а пользователей много, включать параллелизм не нужно, потому что система не будет это использовать – все потоки будут распределены на пользователей плюс всегда бывают ситуации нагрузки. Поэтому, чтобы упростить управляемость системы, фирма «1С» не рекомендует включать параллелизм. При этом существуют определенные кейсы, в которых параллелизм очень хорошо себя проявляет. В каких случаях параллелизм все-таки стоит включать?
Если у вас большие регламентные ночные операции, там можно включать параллелизм. Пользователей в этот момент работает немного, их там вообще может не быть. Соответственно, здесь все отрабатывает прекрасно.
Если у вас какие-то плохо работающие запросы, есть смысл заняться этими запросами и не доводить до того, чтобы они уходили в параллелизм.
Еще хороший подход, если вы организуете параллелизм на уровне учетной системы. Например, вы можете передать какую-то обработку фоновым заданиям – получаете порции, раскидываете по фоновым, они у вас что-то крутят и вместе это собирают. Это дает понятный и предсказуемый результат.
А если мы включаем параллелизм на уровне СУБД – результат может быть непредсказуем. Потому что мы передаем на СУБД, то MS SQL – это черный ящик, мы не знаем, будет он включать параллелизм или нет. С PostgreSQL та же самая история.
Чтобы быть более-менее уверенным, что у нас выполнится и будет с этого какой-то профит, лучше по возможности применять алгоритмы обработки в учетной системе. Это топорно, но чем проще, тем лучше.
Если вы все-таки включили параллелизм и надеетесь, что у вас все будет хорошо, вы должны быть уверены в том, что в вашей учетной системе хотя бы 90% запросов адекватные – что у вас все нормально со статистикой, что у вас хватает ядер, что ваши подрядчики написали запросы хорошо. Тогда во включении параллелизма есть смысл.
Почему может расти CXPACKET?
CXPACKET есть всегда, он всегда в топе. Даже если вы не используете параллелизм, у вас всегда есть ожидания, потому что чем больше пользователей, тем больше исполнителей для выполнения заданий запросов используется. И все они пытаются считать определенные страницы – ждут своей очереди выполнения. Как раз это ожидание и говорит о том, что есть исполнители, которые ждут своего часа выполнения. В случае с параллелизмом это значение просто выше ожидания. И опять же, там нужно смотреть в совокупности с другими типами ожиданий – например, с PAGEIOLATCH_XX, с ожиданием на чтение страниц.
Анализировали ли вы влияние параллелизма на множественные вставки в таблицы с большим количеством данных – дает ли параллелизм какой-то профит при этом или нет?
При вставке в таблицы никакого параллелизма не используется. Единственный момент, когда он может использоваться помимо оператора SELECT – при CREATE INDEX – там включается параллелизм, и он хорошо работает на той же реструктуризации, реиндексации. В случае INSERT, DELETE, UPDATE у вас параллелизм не включается. Параллелизм гарантированно сработает, если вы делаете SELECT с агрегацией данных, при этом на PostgreSQL, если вы помещаете данные во временные таблицы, параллелизм работать не будет. Никакие другие операции с СУБД кроме SELECT отношения к параллелизму не имеют.
*************
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "PostgreSQL VS Microsoft SQL".

Вступайте в нашу телеграмм-группу Инфостарт