Есть такой фильм – «Вид на жительство». В нем Жерар Депардье играет французского мигранта, который всяческими уловками пытается обосноваться в Америке и получить там вид на жительство. Он даже женится на коренной американке, но что-то все время идет не так. В итоге все заканчивается хорошо, но остается осадочек.
Такой же осадочек у меня вызывает ситуация с внешними источниками данных в платформе 1С.

Инструмент прикольный, задачи с его помощью можно решать интересные. Казалось бы, бери, добавляй в расширение и решай, что хочешь. Но нет:
-
Использовать внешние источники в расширениях нельзя, их можно добавлять только в основную конфигурацию.
-
Внешние источники данных существуют только на управляемых формах.
-
И серьезный апдейт этого механизма был в последний раз на релизе платформы 8.3.8.
Все это вызывает вопрос: а инструмент-то вообще живой? Может, им и не пользоваться, считывать таблицы с помощью ADO?

Давайте посмотрим на облако тегов сайта Зазеркалья. Оно строится по частоте запросов пользователей. Там нет ни слова про ВИДы, и это печально.
Но с другой стороны, не все так плохо. Этот инструмент особо не нужен малому и среднему бизнесу, но очень хорошо зарекомендовал себя в Enterprise и КОРП-сегменте. И действительно там есть задачи, которые можно решать с помощью него.
В докладе я не буду пересказывать все, что есть на сайте ИТС и в синтаксис-помощнике – это вы можете посмотреть сами и сделать какие-либо выводы.
И я не буду рассказывать про историю появления внешних источников и как это работает.
Но я хочу:
-
показать вам практические кейсы и примеры, как мы это применяем в работе;
-
натолкнуть вас на определенные мысли – подкинуть идей, как вы можете применять это у себя;
-
рассказать о подводных камнях и нюансах, с которыми мы столкнулись, используя внешние источники данных, как мы эти подводные камни обходили и какие из этого сделали выводы.
Области применения

Я вижу три области применения внешних источников
-
Работа с файловыми источниками
-
Работа с СУБД
-
Работа с аналитическими кубами – OLAP
OLAP у нас особо не взлетел. Ближе к концу доклада расскажу – почему. Но другие области мы используем, особенно работу с СУБД.
Работа с файловыми источниками
Давайте начнем с файловых источников.
Какой профит от считывания таблиц Excel с помощью ВИДов? Есть два жирных плюса, которые перекрывают все остальные минусы.
-
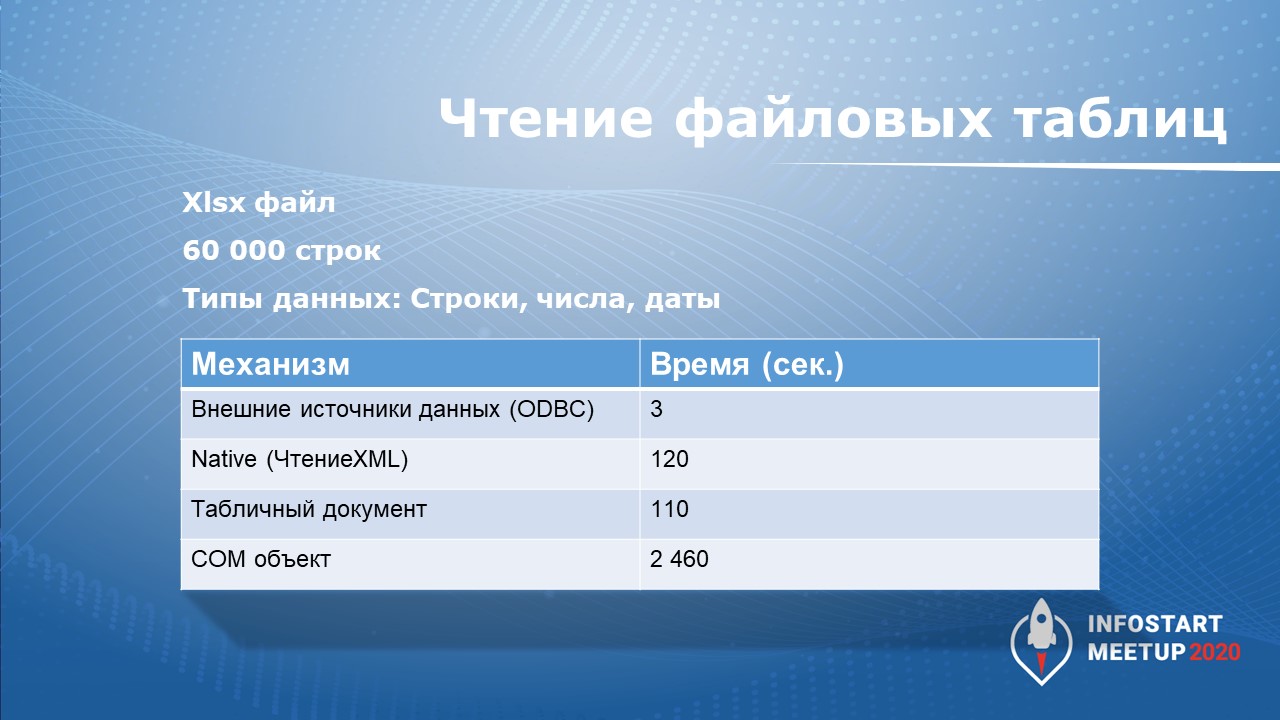
Первый момент – это скорость. Какой бы инструмент вы не использовали: нативное чтение через XML, табличный документ или чтение через COM-объект Excel – вы не добьетесь такой скорости как при использовании внешних источников данных.
-
Второй момент – мы можем обращаться к таблицам Excel с помощью языка запросов 1С. Этот симбиоз дает положительный опыт.
Давайте покажу на примере, как это работает.
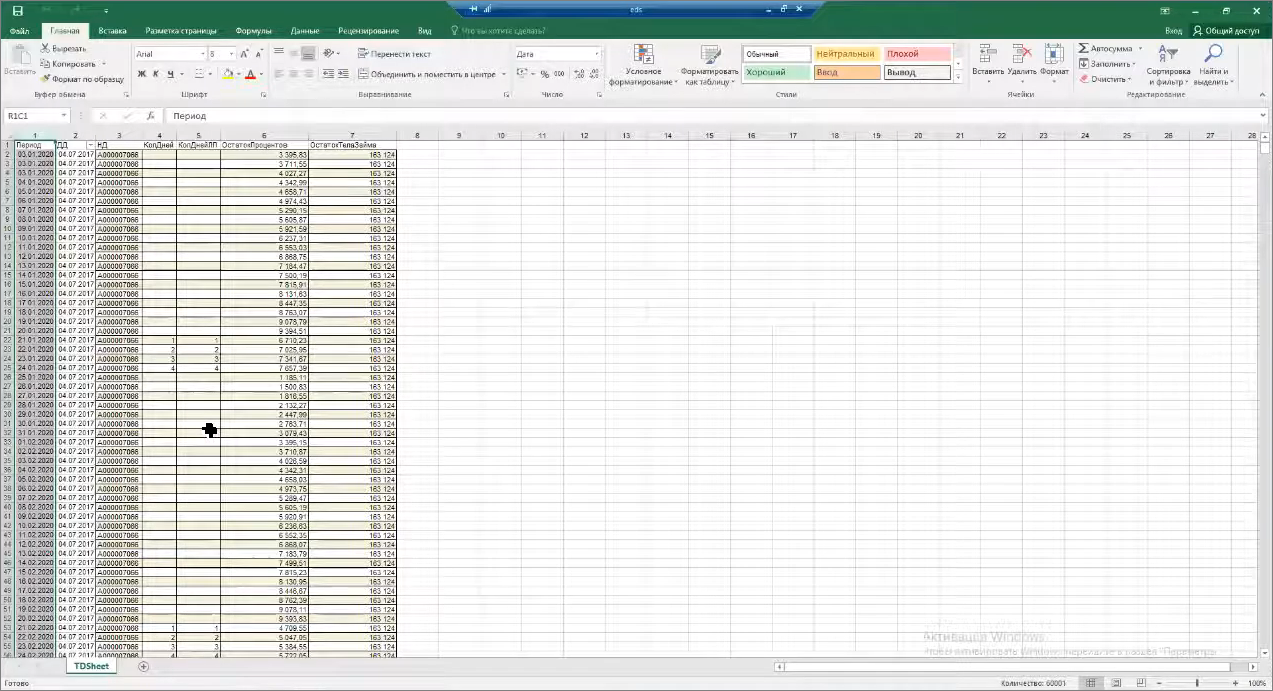
У нас есть обезличенный файлик с данными о просрочке за три года. Здесь, конечно, не реальные данные. В этом файле 60 тысяч строчек. Чтение через COM-объект займет более 40 минут, для нас это вообще не вариант.
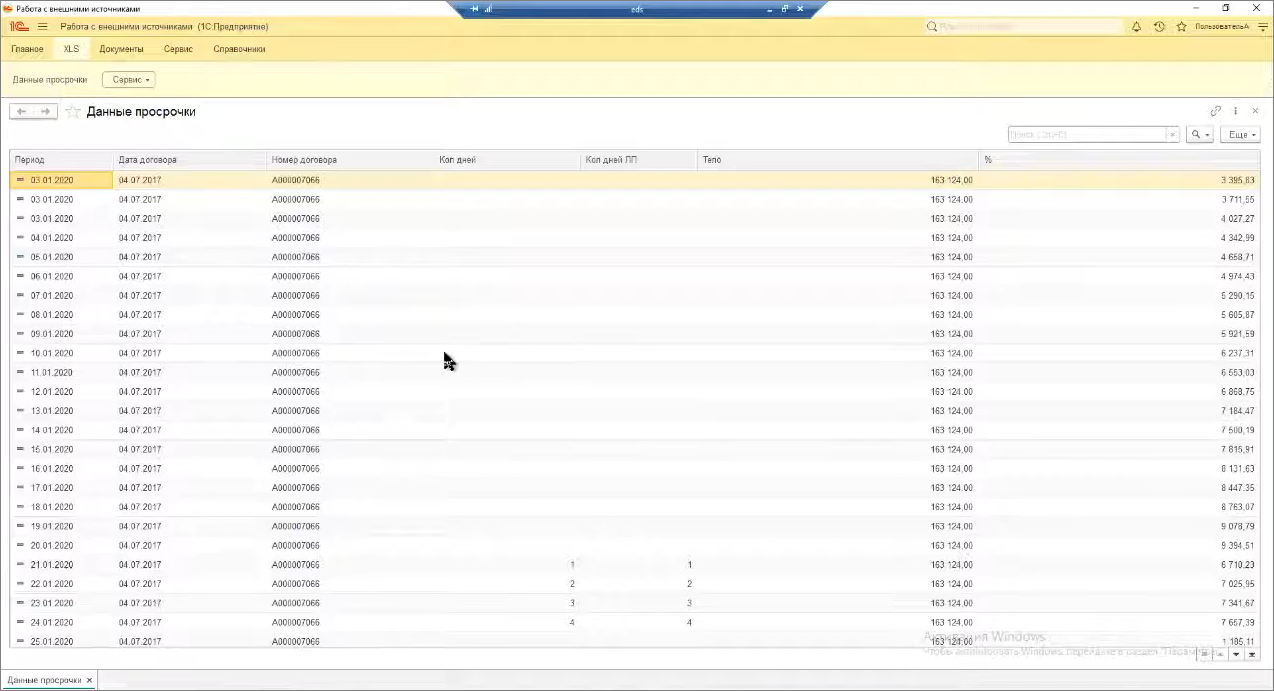
Небольшая демонстрационная конфигурация. Открываем динамический список с данными просрочки, которые выводятся из таблицы внешнего источника, связанного с Excel – все считывается за секунду.
Фишка в динамическом списке, который умеет порционно подгружать данные из таблиц, которые ему подают на вход. Не все, но в части Excel он это умеет делать – по 45-60 строк в порции он подгружает, и мы можем пролистывать список без задержек. Другое дело, что нет смысла выводить в динамические списки 60 тысяч строк – я просто показал скорость работы.
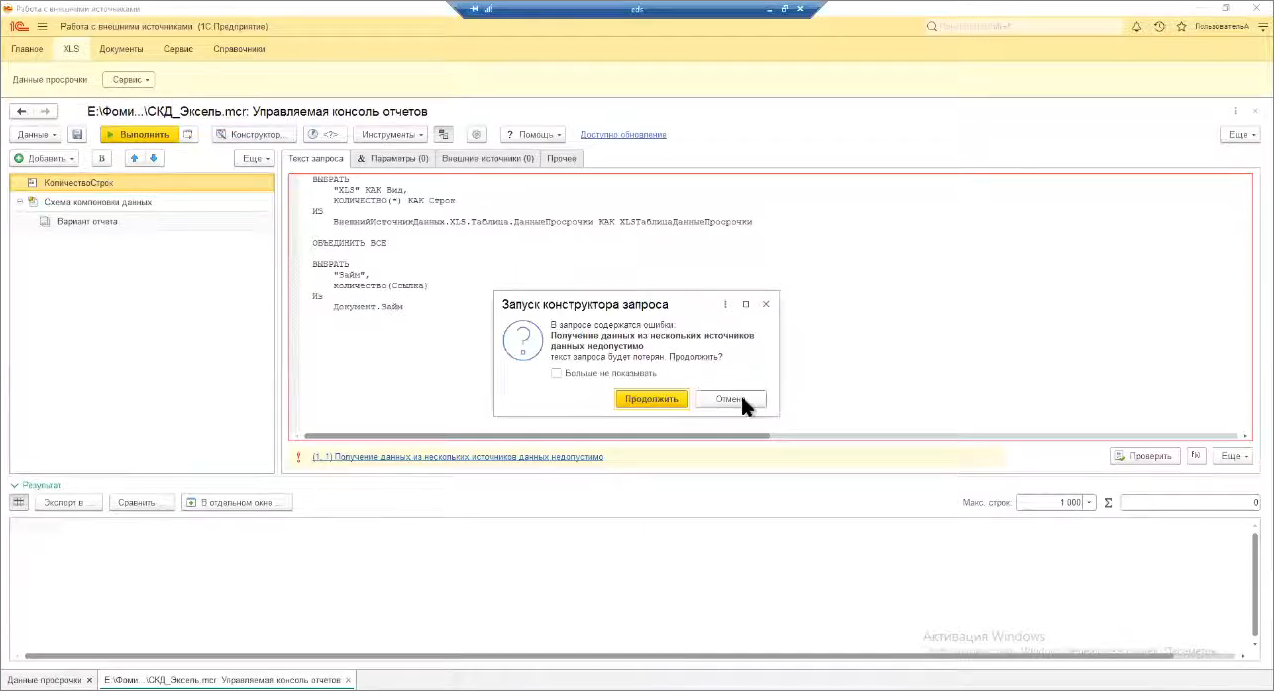
Ложка дёгтя в том, что мы не можем в рамках одного запроса объединить данные внешних источников и таблиц 1С. Открываем консоль запросов – здесь есть простенький запрос, где мы считываем данные из Excel-таблицы и пытаемся их объединить со списком документов. Этот запрос не выполнится вообще никогда, что бы вы ни сделали – даже конструктор не откроется.
Почему так происходит? Когда запрос выполняется – он транслируется на СУБД. А дальше механизмы СУБД подбирают оптимальный план выполнения этого запроса и производят определенные выборки.
Но в случае внешнего источника данных СУБД при построении плана запроса не может заранее понять, что ей надо прочесть Excel или обратиться к таблицам PostgreSQL, сделать какие-то соединения, выгодные для СУБД, и потом это транслировать на пользователя. Поэтому на уровне платформы это залочено – об этом нужно помнить. Это такой маленький подводный камень.
Есть костыльные методы, когда мы можем внешние источники считывать в промежуточную таблицу значений, и потом эту таблицу значений подавать на вход другого запроса. Но я не сторонник костылей. Мне больше по душе метод использования схемы компоновки данных.
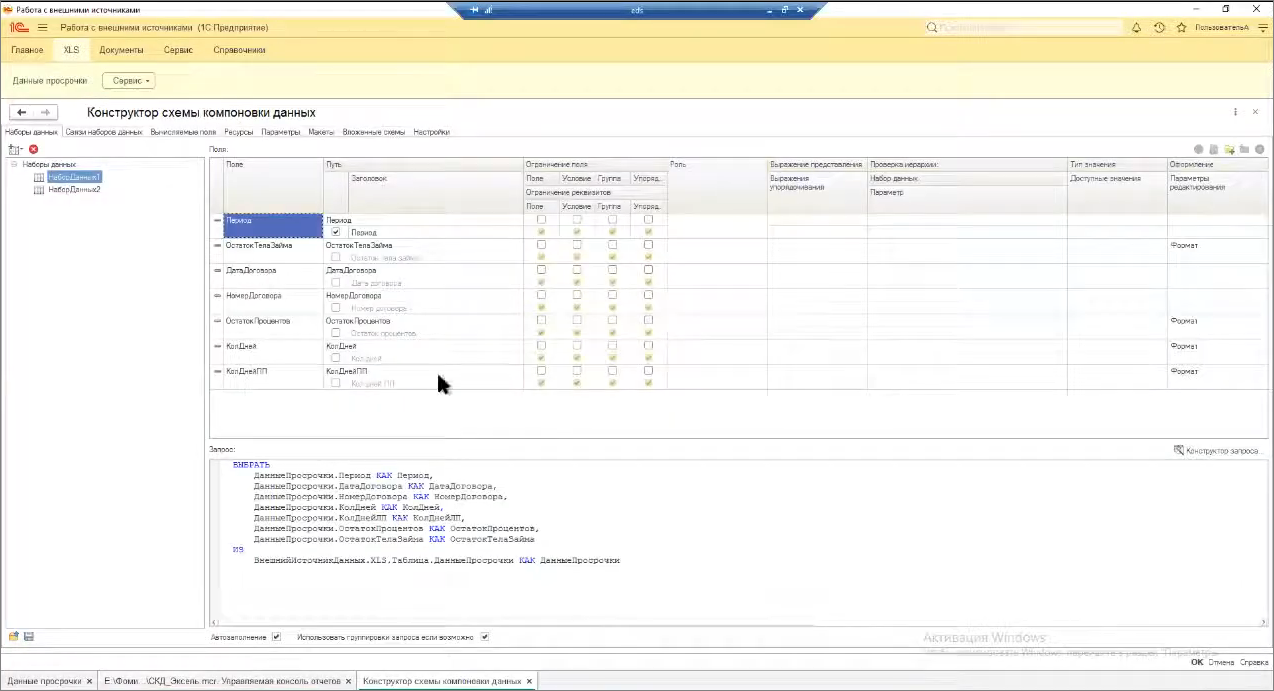
В схеме компоновки данных мы можем спокойно использовать несколько наборов:
-
в первом наборе считывать таблицу Excel;
-
а в следующем – обратиться к документам 1С.
Мы можем их соединить по определенному полю, сформировать выборку.
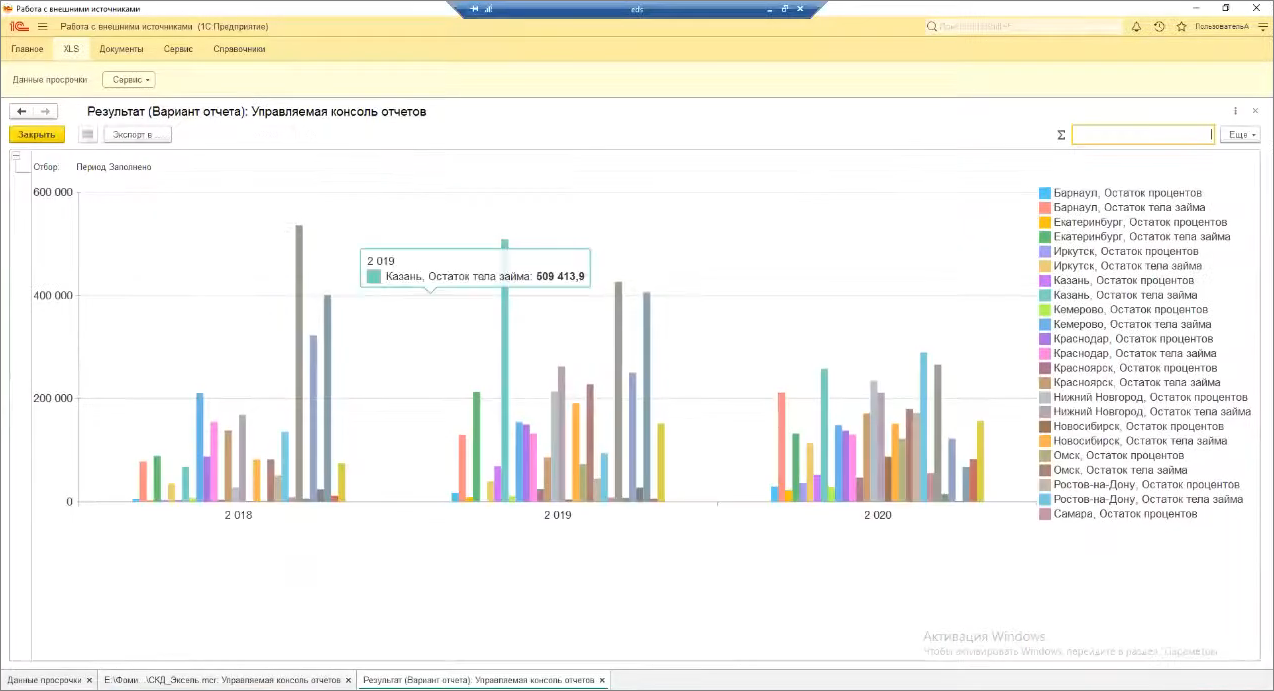
В итоге получим вариант отчета, сформированный за пару секунд: например, анализ по просрочке за последние три года в разрезе регионов. Считывание 60 тыс.строк заняло 1-2 секунды.
Фича крутая, ее можно применять как один из способов реализации, если вам приходится считывать данные из Excel, консолидировать их с данными из базы, потом это презентовать руководству.

Расскажу небольшую предысторию – мы хотели сделать такую консолидацию, собирая из файлов, которые есть у регионов, и объединяя все это в общую отчетность. У нас не вышло из-за ограничений, которые содержат внешние источники данных.
-
Первое ограничение заключается в том, что в одну единицу времени внешний источник может работать только с одним файлом Excel.
-
Второе ограничение – внешний источник требователен к типу данных «Дата» . Если у вас одна из колонок содержит все значения типа «Дата», но одно из них задано, например, строкой, у вас файл целиком не прочитается, возникнет ошибка, и вся ваша отчетность встанет колом.
Поэтому мы пошли по другому пути: отказались от Excel и все делаем в 1С. Это правильно и хорошо.
Зачем же тогда я вам все это показываю, если говорю, что мы в работе отказались от Excel? На самом деле, мы используем чтение из Excel с помощью внешних источников, но для других целей:
-
Мы загружаем с сайта Центробанка различную статистику в файлах Excel, считываем ее с помощью внешних источников и в дальнейшем используем ее для определенных прогнозов по регионам – строим некую модель выхода на рынки.
-
Также используем считывание из Excel во внешние источники данных, чтобы рассчитывать различные экономические показатели займов.
Несколько идей, как применять ВИДы у себя:
-
Если вы малый или средний бизнес, у вас много поставщиков, они вас закидывают прайсами – не храните прайсы в базе данных, не захламляйте ее, а используйте подход с внешними источниками. Например, вы можете открыть данные прайса с помощью внешнего источника и применить к ним какую-то бизнес-логику – например, сформировать заказы поставщику.
-
Другой момент – если у вас много свободного времени, вы можете организовать чтение логов 1С с помощью внешних источников. Придется повозиться, настроить секционирование на каждое событие, сделать настройку на все поля каждого события. Я не энтузиаст, это непросто, но задача реализуемая. Вы можете попробовать, мне кажется, никто этого раньше не делал .
-
Мне больше по душе область взаимодействия внешних источников данных с различными СУБД. Здесь вы можете считывать данные, записывать данные в таблицы СУБД, использовать хранимые процедуры, функции и все, что душа пожелает.
Работа с СУБД

Мы используем несколько направлений взаимодействия с СУБД через внешние источники – они представлены на слайде. Сейчас расскажу о каждом из них подробнее
Организация базы логов
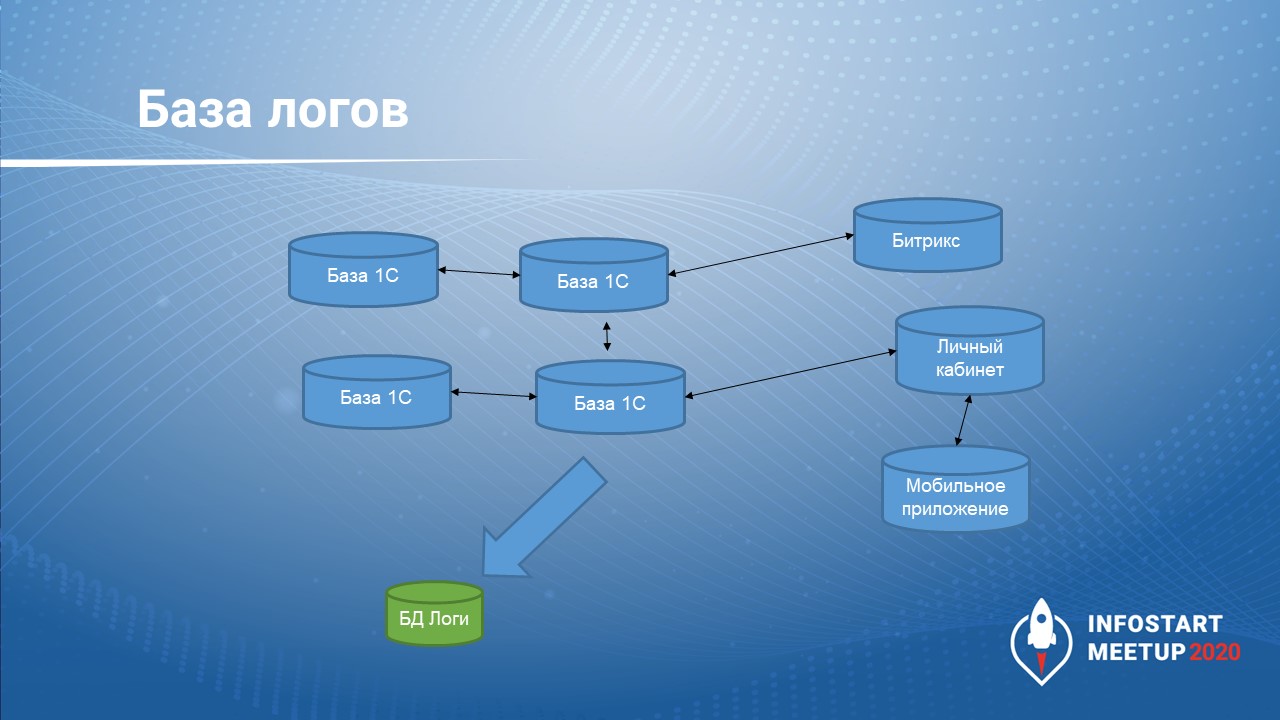
Первое направление, которое мы используем – организация базы логов.
Основной принцип здесь: не мусори там, где живешь. В нашем ИТ-ландшафте множество систем, и не все они на базе 1С. Они обмениваются друг с другом по различным интеграционным шинам. Нам важно понимать, в какой момент времени и что пошло не так.
Если мы будем хранить логи в каждой базе 1С, или в других системах, или на файловых ресурсах, то собрать, проанализировать и получить полную картинку мы не сможем.
На наш взгляд, правильный подход – использовать для логов какую-то отдельную базу. Мы называем это «база рядышком», куда мы можем складывать все логи, добавлять к ним метрики, ставить временной штамп. Если возникает потребность – мы можем с помощью небольших запросов сопоставить связи по метрикам и понять, при каких входных параметрах, в какой точке входа началась проблема, и к чему она привела.
База телефонии

Другое направление – база телефонии.
Здесь у нас тоже используется «база рядышком», где хранятся нормализованные данные, которые получены из основной базы.
В качестве мастер-системы для телефонии у нас используется Oktell. Напрашивается вопрос – зачем использовать внешние источники, если Oktell может напрямую считывать данные 1С, обращаясь к таблицам СУБД или делать кастомные запросы через COM-объекты?
-
На мой взгляд, архитектура типового решения 1С и структура таблиц базы заточена под бизнес-задачи именно прикладного решения 1С, но не заточена под потребности внешнего продукта – 1С не знает, что там Oktell пытается получить из нее какие-то данные.
-
Поэтому мы реализовали рядышком нормализованную базу и складируем туда с какой-то периодичностью либо по событиям какие-то данные. А Oktell их спокойно забирает.
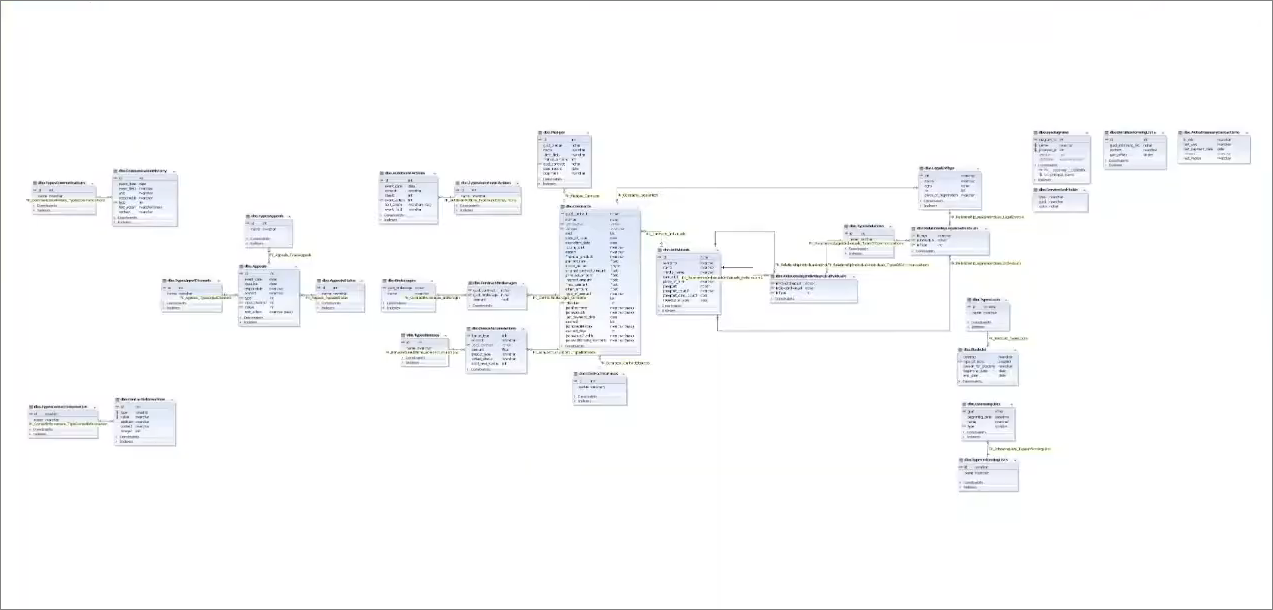
Покажу, как у нас примерно выглядит структура этой нормализованной базы по телефонии. Все вы, возможно, сталкивались с ER-диаграммами. Вот небольшая диаграмма нашей базы – здесь основные таблицы, все нормализовано и понятно.
Но если мы построим ER-диаграмму любого типового решения 1С, она будет строиться час и более, а во-вторых, этот процесс напоминает процесс призыва сатаны. Либо не построится, либо построится, но воспользоваться ей будет нельзя.

Поскольку для данных по телефонии используется нормализованная база, возникает резонный вопрос с актуальностью информации.
Поскольку основной потребитель телефонии – колл-центр, а это не всегда люди-операторы, чаще всего это роботы, механизмы автоинформирования, то представьте ситуацию. Заемщик час назад погасил кредит, он перед нами чист, но в нормализованной базе данных информация несвежая, обновления нет – робот начинает человека долбить, что он должник. У нас в стране люди и так микрофинансовые организации не очень любят, зачем подливать масла в огонь.
Поэтому мы выбрали два пути, как поставлять информацию в нормализованную базу с помощью внешних источников данных.
-
Первый путь – событийный обмен. При любом платеже от клиента формируется слепок информации: по его задолженности, просрочке. У внешних источников основная фишка во взаимодействии с СУБД, если это небольшие порции данных на запись – скорость. Мы напрямую пишем в таблицы и информация быстро обновляется.
-
Второй момент – инкрементный обмен. Почему инкрементный, а не полный? Полный обмен выгружает сотни тысяч записей, мы не влезем в технологическое окно. Инкрементный обмен позволяет выгружать только изменения.
-
Выгрузка изменений у нас реализована с помощью Hash-сумм, которые формируются из совокупности значений на стороне 1С – все значения контактной информации в сумме склеиваются и получается Hash.
-
На стороне нашей нормализованной базы есть служебная таблица, которая хранит в себе эти Hash-значения. При ежедневной выгрузке, сопоставляя Hash, мы понимаем, что изменилось.
-
Мы здесь сознательно не пошли по пути планов обменов, потому что планы обменов – это конкретные ссылки, объекты, а у нас это определенные сводные сущности в виде снимков, истории по заемщикам, по займам, по контактной информации. Тем более планы обмена создают паразитную нагрузку в части блокировок, когда мы пытаемся выбрать изменения и выгрузить их. Это важный существенный момент.
База бюро кредитных историй

Третья «база рядышком» – база бюро кредитных историй.
Мы, как участники финансового рынка, обязаны подчиняться требованиям регулятора, назовем его Центробанком.
-
Первое требование заключается в том, что мы должны ежедневно выгружать в бюро кредитных историй информацию по действующим и закрытым займам. Все это нас приводит к тому, что за неделю в БКИ выгружается 1,5 миллиона строк.
-
Другое требование регулятора – мы должны эту информацию хранить у себя и при необходимости предоставлять в виде определенных отчетов.
-
Наши внутренние службы контроля тоже просят предоставлять им информацию для разбора определенных ситуаций.
Если мы будем это все хранить внутри базы 1С, мы получим необслуживаемую, 10Тб базу.
Другой момент – эти данные хоть и запрашиваются, но редко. Хранение ради хранения – спорный момент.
Поэтому мы тоже организовали «базу рядышком», но столкнулись с несколькими подводными камнями.
Подводные камни «базы рядышком»
Первый камень прилетел нам в лоб, когда мы пытались писать большие наборы данных через проведение документов.
Мы столкнулись с тем, что платформа 1С ограничивает количество строк в наборе записей, который можно записать на СУБД с помощью внешнего источника данных. В старых версиях платформы до 8.3.15 это ограничение – 50 тысяч строк. В 8.3.15 его увеличили до 200 тысяч. В 8.3.17, по слухам, это ограничение убрали, но момент существенный.
С чем было связано такое ограничение со стороны платформы? При небольшом количестве записей (до тысячи) идут простые insert’ы в таблицу. Если записей больше тысячи, сначала на стороне СУБД формируется временная таблица, и потом начинается insert с этой временной таблицы. Это вызывает потери во времени и излишнюю нагрузку на СУБД. Я так думаю, что ограничение на количество записей связано с этим.

Другой момент связан с транзакциями. Транзакции для внешних источников живут своей жизнью. Если мы в обработке проведения столкнемся с ошибкой или у нас будет отказ в проведении транзакции, записи в нашу базу все равно попадут. Это не совсем логично, ведь теряется целостность, да и зачем это фиксировать, если мы отменяем.
Мы пошли по другому пути – применили отложенное проведение во внешней базе.
В основной базе данные у нас проводятся, формируют свое движение, исходя из бизнес-логики. А в нашу «базу рядышком» информация попадает с помощью рег. заданий, которые выбирают необходимые данные порциями, формируют пул фоновых заданий и все это спокойно записывают.
Но здесь мы столкнулись со вторым подводным камнем – блокировки.
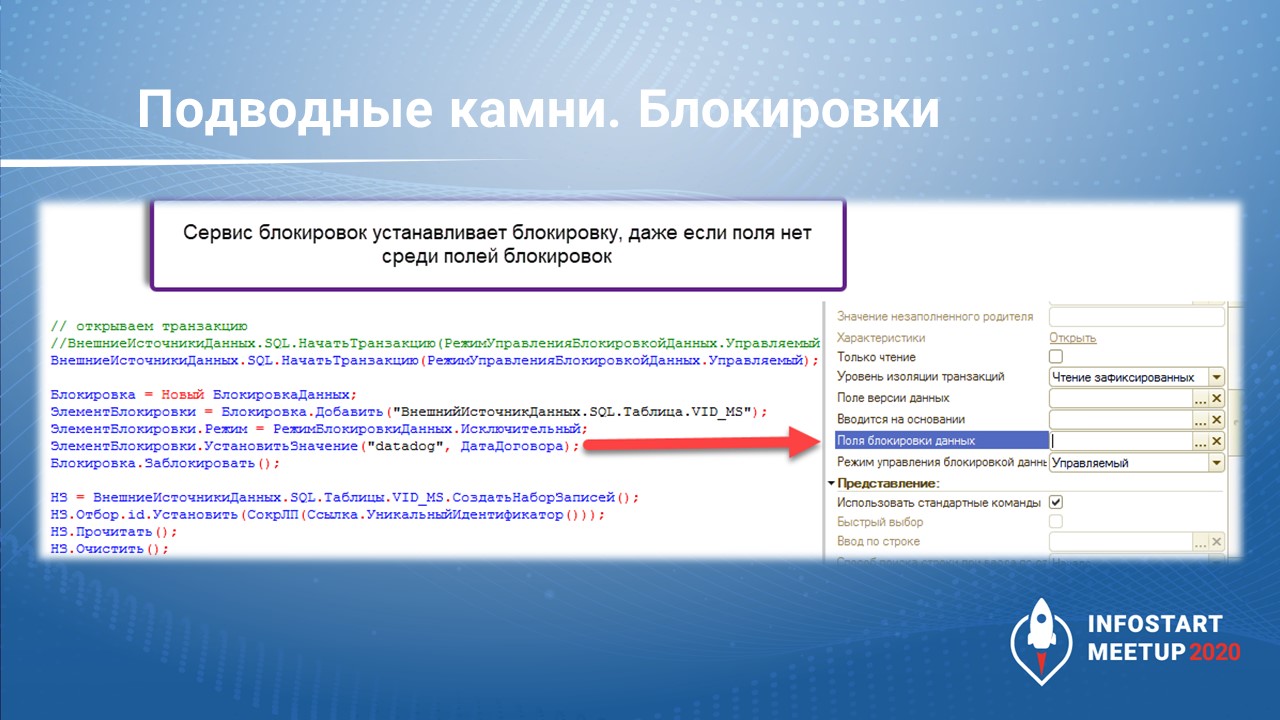
Блокировки – это маленький подводный камень, но неприятный.
Внешние источники данных могут работать как в режиме управляемых блокировок, так и автоматических.
В палитре свойств есть «Поля блокировки данных» – здесь мы устанавливаем, по каким полям у нас возможны блокировки для набора записей. Но эта штука не работает.
Неважно, что мы напишем в объекте Новый БлокировкаДанных, какие мы установим значения полей блокировок. Мы можем поставить управляемую блокировку и добавить туда все, что угодно, но это никак не будет коррелировать с тем, что добавлено в «Поля блокировки данных». Проверяли на 8.3.17 – такая же история.
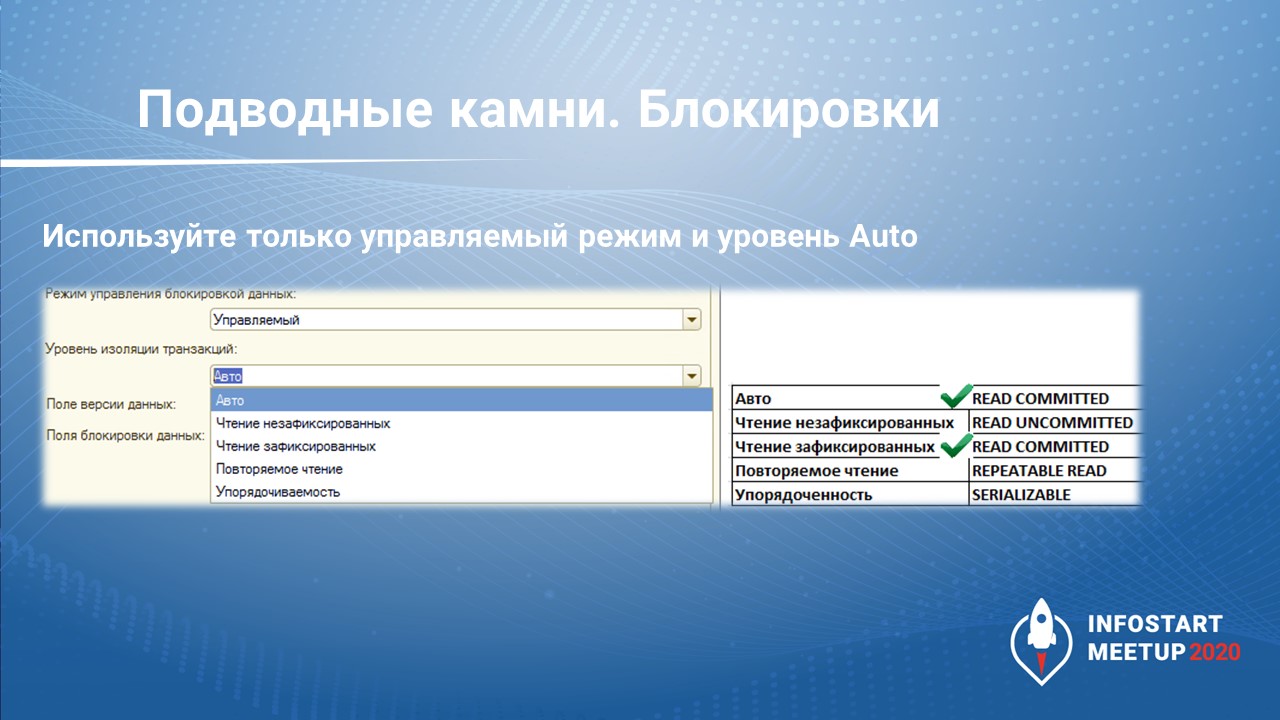
Если вы оставите «Уровень изоляции транзакций» – «Авто», это чревато.
Здесь все зависит от СУБД – какой режим изоляции будет в СУБД, таким он будет и для изоляции управляемых блокировок. Это логично, но не всегда очевидно, на ИТС этой информации нет.
На MS SQL по умолчанию уровень изоляции – READ COMMITTED, и все работает, только не забудьте включить READ COMMITTED SNAPSHOT.
В PostgreSQL тоже все нормально, но в случае с другими СУБД нужно индивидуально смотреть.
Вариант «Упорядоченность» – то же самое, что и режим автоматических блокировок, SERIALIZABLE.

Третий камушек был болезненным, угодил в живот.
На первый взгляд, безобидная конструкция, но если на этапе проектирования «базы рядышком» не было сформировано никаких индексов, а мы поставим управляемую блокировку и попытаемся одновременно провести два документа в разных сеансах, то столкнемся с проблемой.

Параметр «Время ожидания блокировки данных» нас не спасет, потому что на СУБД не будет отправлено значение параметра SET LOCK_TIMEOUT, а значит, будет использоваться значение по умолчанию (-1). В результате второй сеанс будет бесконечно ждать, пока не освободится ресурс первого сеанса.
В случае, если все спроектировано правильно, и покрывающий индекс есть, таких проблем не будет.

Поэтому, если делаете «базу рядышком»:
-
используйте инструменты СУБД – помощники создания индексов, database-диаграммы;
-
обязательно включайте READ COMMITTED SNAPSHOT (режим изоляции снимков);
-
не формируйте записи внешних источников внутри документа, лучше используйте отдельные рег. задания.
Мониторинг – T-SQL, dmv

Проблемы расследуем с помощью тех. журнала, мониторим события:
-
TTIMEOUT
-
TLOCK
-
TDEADLOCK
-
и обязательно событие EDS для внешних источников – любая проблема с управляемыми блокировками коррелирует с событиями EDS, это очень важно.
В качестве инструментария используем:
-
для MS SQL – представления DMV
-
для PostgreSQL – pg_stat_statements, pg_locks.
Взаимодействие с другими базами 1С

С точки зрения чтения – никогда не считывайте данные из других баз 1С с помощью внешних источников данных. Для этого есть нормальные инструменты: EnterpriseData, «Конвертация данных», HTTP-сервисы, OData, на крайний случай COM-чтение.

Что касается записи данных с помощью внешних источников в базы 1С, то здесь – легко потерять, сложно восстановить. Особенно, если у вас нет бэкапа. Не применяйте это никогда.
OLAP-интеграция

Третья сфера применения внешних источников данных – OLAP-интеграция.
Здесь я расскажу немного о нашей компании.
-
Мы 7 лет на рынке и представлены в 14 регионах. У нас не займы до зарплаты, а займы под ПТС, поэтому средний чек гораздо выше.
-
Требования к аналитическим отчетам достаточно высокие, могут меняться несколько раз за день. А у внешнего источника данных есть ограничение, которое заключается в том, что если мы захотим добавить изменения в аналитику, нам придется добавлять это в конфигуратор, в дерево конфигурации. Это делает динамическое обновление невозможным, и это некий стоп-фактор.
-
Другой момент в том, что мы агрегируем данные из других систем: ЯндексМетрика, Google Analytics. В этом плане от внешних источников мы отказались. Тем не менее, вы можете их попробовать, они неплохо работают с сервисами аналитики MS SQL.

Здесь для аналитических отчетов у нас есть своя разработка на Python и свой разработчик.

Но мы очень ждем релиза 1С:Аналитики. Там тоже есть внешние источники, которые используются для агрегации данных со всяких метрик, нас это впечатлило, и мы будем это использовать.
Краткие итоги

На слайде представлены плюсы внешних источников данных. Несмотря на всю неоднозначность, это достаточно актуальный и современный инструмент, который грех не использовать на своих задачах.
-
Удобно использовать «базы рядышком», чтобы не захламлять и не загружать свои базы 1С.
-
При проектировании этой архитектуры вы получите мощный скилл – это плюс семь шагов к 1С:Эксперту.
-
Скорость записи и считывания из Excel сделана хорошо.

Минусы озвучивать не буду, их можно спокойно пережить, если кое-где применить костыли и пересмотреть подходы к разработке.
Не бойтесь внешних источников, инструмент интересный, не дайте этому инструменту умереть.
Вопросы:
Вы показывали в консоли запросов, что нельзя объединить данные базы с данными внешнего источника данных, а можно ли поместить во временную таблицу и там соединить?
Нет, так не получится. Временная таблица в рамках одного запроса формирует временную таблицу на СУБД. А так как мы считываем из Excel, там никакой временной таблицы нет. Здесь лучший выход – это формирование выборки и выгрузка ее в таблицу значений. А потом эту таблицу значений можно передать на вход другого запроса.
Мы использовали внешние источники данных для хранения прайса – миллионы строк в базе MS SQL. Но столкнулись с тем, что работа через внешние источники оказалась значительно медленнее, чем через COM-объекты. Это была платформа 8.3.12. Изменилось ли что-нибудь в последних версиях?
Есть значительное ускорение. Тем более, если вы храните данные внутри СУБД – все зависит от режима работы СУБД, включен ли у вас READ COMMITTED SNAPSHOT, были ли параллельно записи какие-то. Надо смотреть.
Вы отслеживаете изменения с помощью Hash. Но Hash – это же набор данных. Если Hash поменялся, вы передаете весь объект на обмен?
Мы вначале обращаемся к нашей нормализованной базе, к таблице, где хранятся хэши. Этот запрос длится буквально одну-две секунды. Мы получили список хэшей, совместили с нашими хэшами и на отклонении понимаем, что нам нужно выгрузить.
У вас Hash считается по пяти полям. Если одно поле поменялось, нужно гнать в обмен весь объект, все пять полей?
Да, мы гоним все пять полей, но, по сути, мы сразу пытаемся сделать все красиво и правильно. У нас в этих данных, которые перегоняются, нет большого объема. У нас все уже в определенном нормализованном виде. И все происходит достаточно быстро.
Вы говорили, что вызывать транзакцию в обработке проведения плохо, потому что 1С не позволяет при записи во внешний источник откатывать транзакции?
Не совсем так, я говорил, что если в обработке проведения будет откат, то транзакция, которая существует для внешнего источника, все равно закроется, запись произойдет. Получается нарушение целостности. И вообще это некрасивая практика – вызывать в обработке проведения любых внешних сервисов. Поэтому используйте регзадания, в любом количестве потоков формируйте.
Чтение в 3 секунды – это весь файл Excel в 65 тысяч строк прочитался или это 45 строк динамического списка?
Это чтение всего файла.
Вы говорили, что используете Google Analitytics, Яндекс.Метрику, но это все плохо сочетается с внешними источниками.
Да, именно поэтому мы используем собственную разработку на Python. А после полноценного выхода 1С:Аналитики мы планируем перейти на нее.
Но в 1С:Аналитике же тоже чудес не будет?
Да, мы там уже некоторые вещи прощупали, но, тем не менее, ее разработчики сейчас идут навстречу и отмечают в бэклоге какие-то пожелания от пользователей беты. Я думаю, что поначалу будут какие-то подводные камни, но мы же не ищем простых путей, и любим интересные задачи.
Но в 1С:Аналитике же сейчас нет готовой функциональности, которая заменит ваш скрипт?
Главное преимущество 1С:Аналитики в том, что все эти необходимые измерения можно подтягивать практически в онлайне, используя конструктор – не придется в конфигурацию добавлять эти измерения. выгонять пользователей из базы и т.д.
Т.е. проблема не в том, что внешние источники не позволяют получить данные, а в том, что для изменения аналитики внешнего источника приходится выгонять пользователей, потому что нельзя динамически обновить базу?
Да.
*************
Данная статья написана по итогам доклада (видео), прочитанного на INFOSTART MEETUP Новосибирск.


Вступайте в нашу телеграмм-группу Инфостарт