Сразу напишу вопросы, которые в статье не будут рассматриваться:
1. Разбор и отладка правил конвертации
2. Отладка фоновых заданий.
3. Отладка асинхронных вызовов.
Здесь если начать описывать данный процесс, то получится статья о том, как они работают... А смысла писать давно описанное нет. Для меня пп. 2 и 3 это обычный код, который разбирается в других кейсах.
Кейс 5. Как разобрать и доработать запрос.
Здесь стоит написать, что каждый запрос решает какую-то задачу (сценарий). Иногда мы его знаем, но чаще всего ведём доработку чужого кода и чужих запросов лишь на догадках. Это плохо, конечно! Но сроки часто жмут, и разбираться со всей задачей некогда, иногда необходимо внести локальные изменения в запрос.
Сначала необходимо классифицировать задачи, которые требуют изменения запросов:
1. Запрос выдает не все данные, которые необходимы. Бывает, эта задача звучит так: Раньше работало нормально, а сейчас неверный результат заполнения чего-нибудь (документа, отчета, обработки).
2. Нужно добавить "несколько полей".
3. Нужно, чтобы попадала и вот такая-то информация (в документ, движения, отчет, обработку).
4. Оптимизация работы запроса.
5. Нужно к существующему запросу добавить добавленный регистр(ы).
Возможно, есть ещё какие-то сценарии доработки... Но главное - понять, какие шаги помогут разобраться в запросе!
1. Главное, что следует помнить, результат запроса - это таблица. Получилась эта таблица из других таблиц. Это означает, что при работе с запросами должна быть ассоциация работы с Excel. Ведь с Excel многие умеют работать! Например, условия запроса ни что иное как фильтр, который Вы наверняка с лёгкостью сможете накладывать в Excel.
2. Если таблицы большие (много колонок и много строк), представить себе результат запроса в голове очень сложно! Это должно мотивировать информацию либо записывать, либо распечатывать, либо сохранять в Excel и анализировать данные там. Конечно призыв печатать таблицы в 10 тыс и более записей можно поднять на смех... Это помогает, если запрос сложный, но его результатом является 100-200 записей. Такие данные вполне помещаются на 2х А4. Я использую сохранение данных в Excel и через наложение фильтров (включается Данные->Фильтры->Автофильтр) принимаю решение, какие данные из этой таблицы мне нужны, и какие отборы требуется наложить (или связи, если присоединяем к другой таблице).
ВАЖНО: Не пытайтесь в голове представить, как выглядит результат запроса! Обязательно его выводите одним из предложенных ниже способов. Никогда Вы не сможете осознать, как отработали все связи, условия, как выглядят поля, которые получены через оператор ВЫБОР...КОГДА.
3. Выгрузить данные в таблицу можно следующими способами:
а. Если у Вас есть переменная с типом РезультаЗапроса, то нажмите Shift+F9 и напишите РезультатЗапроса.Выгрузить(). Результатом будет таблица значений.
б. Если у Вас есть переменная с типом ВыборкаИзРезультатаЗапроса, то написать нужно Выборка.Владелец().Выгрузить(). Функция Владелец() вернет РезультатЗапроса, Выгрузить() вернет таблицу значений.
Эти 2 способа помогут, если Вы работаете НЕ с временными таблицами, а с результирующим запросом.
Если необходимо посмотреть данные временной таблицы, можно воспользоваться одним из способов... Но здесь требуется обязательно использование объекта МенеджерВременныхТаблиц.
в. У менеджера временных таблиц есть свойство Таблицы. Когда Вы его просмотрите. то увидите что нумерация идёт с нуля. Чтоб посмотреть временную таблицу, нам требуется знать её номер!
Далее необходимо нажать Shift+F9 и написать текст:
Запрос.МенеджерВременныхТаблиц.Таблицы[<НомерТаблицы>].ПолучитьДанные().Выгрузить().
На эту тему есть отдельные статьи, сильно расписывать не буду.
г. Написать простой запрос для получения таблицы из результата запроса:
Функция ПолучитьВТ(МенеджерВТ, ИмяВТ, Сортировка = "") Экспорт
// Создаем новый запрос и назначаем переданный
// менеджер временных таблиц. В тексте запроса
// указываем получение всех данных из врем. таб.
Запрос = Новый Запрос;
Запрос.МенеджерВременныхТаблиц = МенеджерВТ;
Запрос.Текст = "ВЫБРАТЬ
| *
|ИЗ
| " + ИмяВТ + " КАК ВТ";
// Результат запроса возвращаем в качестве таблицы
// значений для удобного просмотра. В случае
// возникновения ошибки возвращаем ее описание
Если ЗначениеЗаполнено(Сортировка) Тогда
Запрос.Текст = Запрос.Текст + "
|
|УПОРЯДОЧИТЬ ПО
|" + Сортировка;
КонецЕсли;
Попытка
Возврат Запрос.Выполнить().Выгрузить();
Исключение
Возврат "Ошибка получения временной таблицы: "
+ ОписаниеОшибки();
КонецПопытки;
КонецФункции
Советую таблицу сохранить как печатную форму. Это можно сделать в отладчике через Shift+F9, у Вас должен быть тип ТаблицаЗначений. Потом F2 - показать значение. Когда откроется таблица справа вверху есть пиктограмма "Вывести список". Выбираем список нужных полей и жмём ОК. После закрытия формы просмотра результатов увидим заполненный данными запроса макет в конфигураторе.
4. Если данные получаются из регистров, обязательно нужно зайти в используемые регистры и посмотреть на массив данных, который участвует в запросе. Если регистров несколько - смотрим все!
В результате описанных действий мы получили некоторую визуализацию данных. Следующая задача - разобраться с условиями и связями, которые влияют на попадание записей в результирующий запрос. Наверняка возникает вопрос: и что я должен увидеть в регистрах? Ответ очень прост: какие измерение, ресурсы, реквизиты заполнены и, главное, какими значениями. Здесь важно выполнить некоторый анализ данных. Со временем некоторые поля регистра становятся не используемыми и не заполняются данными. Например, В ЗУПе есть интервальные регистры. Так вот "ПустойИнтервал" уже не используется, т.к. изменился принцип создания записей в этих регистрах и пустых интервалов не стало! Это можно увидеть только зайдя в регистр. Т.к. смотря на него в конфигураторе сразу возникает желание написать условие "НЕ ПустойИнтервал". На самом деле это условие ничем не поможет, т.к. поле больше не используется!
Как известно, условия накладываются в следующей последовательности:
-- Сначала в параметрах виртуальных таблиц (если они используются в запросе)
-- Далее в связях между таблицами. Связи определяют, какие данные будут присоединены к основной таблице запроса.
-- В последнюю очередь работают условия в блоке после слова "ГДЕ". ВАЖНО: Эти условия накладываются уже на результат запроса, т.е. после объединения таблиц.
5. Прежде чем разобраться с условиями и связями, опишу способ сравнения результата запроса до изменения с результатом после изменения. Любую таблицу в 1С как в пользовательском режиме, так и в конфигураторе можно сохранить, например, в *.mxl. Как получить таблицу чуть выше описал.
Так вот, нужно перед изменением запроса запустить отладчик, и получить результат выполнения запроса до Ваших изменений. Полученную таблицу сохраняем с указанным расширением.
Далее вносим какие-то изменения в запрос, запускаем отладчик, и получаем таблицу уже после Ваших изменений. Полученную таблицу также сохраняем в *.mxl.
Далее в 1С есть специальный пункт меню Файл->Сравнить файлы. В первый выбираем до изменений, во второй после, поле "Как" заполняем значением "Табличный документ". Жмём ОК и увидим разницу. Советую проверять эту разницу как можно детальней, т.е. как можно больше строк проанализировать и понять правильность их изменения. Часто бывает так, что неверная запись в запросе имеет 4-х значный порядковый номер! Если записей очень много (более 10 тыс.) советую пролистать на середину, там проверить пару тысяч записей, потом в конец и с конца проверить пару тысяч записей. Это позволит найти все ошибки в результате выполнения доработанного запроса.
6. Обратим внимание на главную таблицу запроса. В блоке соединений она слева и в тексте запроса и в конструкторе запросов. Если данные выбираются не из физической таблицы и не из временной, а из виртуальной таблицы, на это нужно обратить особое внимание. Виртуальные таблицы нигде не хранятся. Как известно, они формируются платформой в момент исполнения запроса. Состав записей в этой таблице зависит от параметров виртуальной таблицы. Чтоб разобраться какие данные она выдаёт нужно сделать 3 действия:
а. Написать (скопировать) отдельный запрос с теми же параметрами без соединений с другими таблицами и без блока условий "ГДЕ". Результат запроса просматриваем и анализируем как описано выше. Это позволит понять, как выглядит главная таблица запроса без всяких дополнений.
б. Стереть в скопированном запросе параметры виртуальных таблиц. Стереть нужно все кроме периода. Так Вы увидите какие записи отфильтрованы параметрами виртуальных таблиц.
в. Почитать в статье об используемой виртуальной таблице! Сделать это надо сразу! Несмотря на то, что я написал последним пунктом. Ибо если Вы не знаете назначение таблицы, только чудо может Вам помочь написать или исправить написанный запрос!
7. Теперь тем же способом изучим влияние условий в секции "ГДЕ" на результат запроса. Иногда условия настолько сложны и их так много, что даже опытным разработчикам не очевидно, какое из условий удаляет из результата нужную запись. В такой ситуации делаем следующие действия:
а. Комментируем все условия и смотрим на "грязный" результат запроса. Убеждаемся, что в нём есть нужные записи.
б. Начинаем по одному условию включать в работу запроса. на каждом шаге проверяем, не пропали ли нужные записи.
в. Как только в результате включения одного из условий пропали записи - вот именно его Вам нужно внимательно изучить и постараться аккуратно дописать. Результат контролировать описанным выше способом через сравнение файлов.
8. Осталось проанализировать соединения. Самое простое соединение - ЛЕВОЕ. Причина в том, что левое соединение не уменьшает количество записей. НО! Если в связях задать недостаточное количество условий, то количество записей может увеличиться. Поиск дублей это одна из задач, с которой сталкиваются разработчики. Самый простой способ дописать "РАЗЛИЧНЫЕ" после слова "ВЫБРАТЬ". Но способ костыльный и не всегда спасает! Поэтому надо разбираться в соединениях! Вот какие действия нужно предпринять:
а. Не просто так исходно упомянул ЛЕВОЕ СОЕДИНЕНИЕ. Это соединение означает, что к основной таблице присоединяются все записи правой таблицы, которые удовлетворяют условиям связи. Как уже упомянул ранее, одной записи левой таблицы могут соответствовать несколько записей правой таблицы. Количество записей результирующей таблицы будет увеличено на количество дублей. В большинстве случаев, дубли являются ошибкой. Дубли будут, т.к. мы из правой таблицы берём не все поля, а лишь несколько.
б. При возникновении дублей необходимо проанализировать отдельно правую таблицу. Нужно попробовать найти ещё одно поле для связи, чтоб устранить дубли.
в. Если это не получается, советую воспользоваться группировкой результата запроса. Она уберёт лишние записи. По влиянию на результат запроса конструкция "ВЫБРАТЬ РАЗЛИЧНЫЕ" и "СГРУППИРОВАТЬ ПО" совпадают, если группировку сделать по всем полям запроса. НО! Группировка позволяет к некоторым полям применять агрегатные функции. Это может быть полезно с точки зрения результата и показывает, что запрос был осознанно написан автором. Выбор различных чаще показывает нежелание разбираться в запросе и костыльный вариант решения задачи.
г. Как разобраться с другими видами соединений? Разберём ВНУТРЕННЕЕ СОЕДИНЕНИЕ. Это соединение предназначено для фильтрации данных. Многие не профи разработчики его используют повсеместно вместо условий в конструкции "ГДЕ". Такое использование часто на практике приводит к потере нужных записей. Связано это с тем, что мы не можем спрогнозировать мысленно как отработает соединение на всех записях запроса. Возникает эта проблема при больших размерах таблиц. Как минимум для проверки таких запросов рекомендую использовать ЛЕВОЕ СОЕДИНЕНИЕ, а лишние записи фильтровать условием НЕ ЕСТЬ NULL. Причём сначала нужно увидеть результат соединения, проверить много записей (как описано выше), а потом уже накладывать условие. Часто именно в результате такой проверки и придумываются условия, которые нужно наложить.
ВАЖНО: Если условия накладывать в связях и использовать ВНУТРЕННЕЕ СОЕДИНЕНИЕ, Вы не увидите, какие записи исключаются из результата запроса. Использование этого соединения оправдано для небольших таблиц, когда точно известно какие записи есть в каждой из таблиц и какие записи будут исключены. Если принято решение использовать этот вид соединения, необходимо проверять его через ЛЕВОЕ СОЕДИНЕНИЕ с условием НЕ ЕСТЬ NULL.
Замена внутреннего соединения на левое помимо проверки обычно позволяет и разобраться в таком запросе. Начинают отображаться скрываемые записи и через сравнение таблиц можно увидеть что поменялось.
9. Осталось разобраться с конструкциями ПОЛНОЕ СОЕДИНЕНИЕ и ОБЪЕДИНИТЬ ВСЕ. Рассмотрю эти конструкции вместе, т.к. обе конструкции приводят к появлению лишних записей и нужно крайне аккуратно ими пользоваться. Более того, конструкция ПОЛНОЕ СОЕДИНЕНИЕ помимо того что они лишние, создаёт их с полями со значением NULL. Рассмотрим действия, которые с одной стороны помогут разобраться в запросе, а с другой не наделать ошибок при использовании этих конструкций. Вот что важно знать:
а. Конструкцию ПОЛНОЕ СОЕДИНЕНИЕ использовать как можно реже, когда нет возможности решить задачу по-другому.
б. Не путать эти конструкции между собой! Соединение предназначено для схлопывания совпадающих по условиям связей записей и добавления записей из обеих таблиц, которые не соответствуют условиям связи. При использовании соединения нам неважно, сколько полей в соединяемых таблицах! Мы берем только необходимые нам поля и всё. Например, есть 2 таблицы по 200 записей. 150 записей по условиям связи совпали. Это значит, что в результате запроса будет 250 записей.
в. Вторая конструкция предназначена для объединения таблиц с однотипной информацией. Более того, количество и тип значения полей в объединяемых запросах должны совпадать. Количество должно совпадать обязательно, а тип значения желательно! Здесь нет никаких условий уже. Если взять те же таблицы по 200 записей, то итоговое количество записей будет 400. Если в конструкторе запроса в одном из запросов не указать значение поля, автоматически подставится значение NULL. Следовательно, если видите в тексте объединяемого запроса NULL необходимо задуматься, вдруг это ошибка и данное поле можно заменить на нормальное значение. Если в первом запросе поле примитивного типа, значит необходимо заменить на пустое значение примитивного типа. (Ложь, 0, "", Дата(1,1,1,0,0,0)). Если далее поля будут суммироваться, то хотя бы ошибки не будет.
г. Если использовать конструкцию "ОБЪЕДИНИТЬ" без слова "ВСЕ", то в запрос не будут добавлены дублирующие записи. Дубли в данном случае проверяются по всем полям. Как понять, какой вариант использовать? Если у Вас есть 2 таблицы из разных источников с ценами номенклатуры, то дубли с одинаковой ценой никому не нужны! Если у Вас есть 2 таблицы с остатками по номенклатуре, то одинаковые остатки мы в итоге должны просуммировать, убирать дублирующие записи нельзя. Призываю использовать эту конструкцию осознанно в зависимости от решаемой задачи. Всегда нужно помнить о дублирующихся записях и понимать, будут ли они мешать. При доработке запросов необходимо разобраться в этом вопросе. Ответ на этот вопрос поможет выявить сценарии работы. Сам стараюсь слово "ВСЕ" использовать как можно реже, во избежание лишних записей и ошибок!
д. Если в запросе с "ОБЪЕДИНИТЬ ВСЕ" много объединяемых запросов, то понять, из какого запроса запись, очень сложно! Это является проблемой, когда в получившейся таблице есть неверные или лишние записи. Чтоб это исправить, необходимо понять, какой из объединяемых запросов выдал эту запись. Для этого необходимо добавить во все запросы первым поле "НомерЗапроса". Т.е. добавить строку "1 КАК НомерЗапроса,". В результирующем запросе можно будет понять, какие записи из какого запроса попали. Далее уже можно будет разобрать отдельный запрос, как это описано выше. Смотрим на условия, соединения, изучаем исходные таблицы и т.д.
е. Как уже писал, при использовании "ПОЛНОЕ СОЕДИНЕНИЕ" могут появиться в некоторых полях значения NULL. Это значение появится в двух случаях:
-- Если в правой таблице по условиям связи не находится записи, то все поля, получаемые из правой таблицы будут иметь значение NULL. Необходимо воспользоваться функцией ЕСТЬNULL и продумать, чем заменить значение NULL.
-- Если запись попадает из правой таблицы, то все поля, которые берутся из левой таблицы, будут иметь значение NULL.
ВАЖНО:
Из этого следует, что ВСЕ поля запроса при использовании "ПОЛНОЕ СОЕДИНЕНИЕ" должны быть обработаны с помощью функции ЕСТЬNULL. При разборе чужих запросов часто сталкиваюсь с ошибками из-за того, что эту функцию не используют.
Та же проблема есть при использовании "ЛЕВОЕ СОЕДИНЕНИЕ". Все поля из правой таблицы должны быть обработаны функцией ЕСТЬNULL.
Т.к. при использовании "ВНУТРЕННЕЕ СОЕДИНЕНИЕ" попадают только записи, которые есть в обеих таблицах, значение NULL появиться в запросе не может! Значит использовать функцию ЕСТЬNULL на всякий случай не нужно! Это уже будет выглядеть как непонимание работы соединений.
Некоторые приёмы, для облегчения разбора запросов:
1. Запрос необходимо разбирать "с конца". Не нужно пытаться понять весь запрос, особенно если он огромен и текст запроса собирается динамически в 15 модулях! Ваша задача - найти место требующее доработки. Для этого с конца просматриваем таблицы запроса, анализируем их описанными выше способами. Как только определили нужное место - остальные таблицы не смотрим даже ради интереса! Не нужно терять зря время.
2. Посмотрите, где используется результат запроса? Его используют обычно так:
-- Для заполнения таблиц/табличных частей
-- Для формирования движений
-- Для проверки правильности каких-то данных
-- Запросы для заполнения отчетов и регламентированной отчетности.
Когда понимаешь, куда ложатся данные запроса, становится немного легче в этом разбираться.
3. Проверяйте в отладчике каждую временную таблицу или каждый написанный запрос. Это позволит вовремя заметить ошибку, устранить её сразу и далее написать верные запросы. Если пропустить ошибку и обнаружить её через пару недель, то будете заново разбираться в своём же запросе!
4. Если текст запроса собирается в разных процедурах, найдите место, где он уже собран полностью, и через Shift+F9 посмотрите полный текст запроса. Рекомендую его скопировать и закинуть в конструктор запросов. Далее последовательно открывайте отладчиком временные таблицы и анализируйте запрос, который их получает.
5. Найти место, где формируется текст нужного Вам запроса, можно через поиск по всем текстам. В строку поиска нужно написать либо название временной таблицы, либо одно из условий запроса или связи, которое Вам кажется уникальным.
Осталось рассмотреть особенности разбора запроса для его оптимизации.
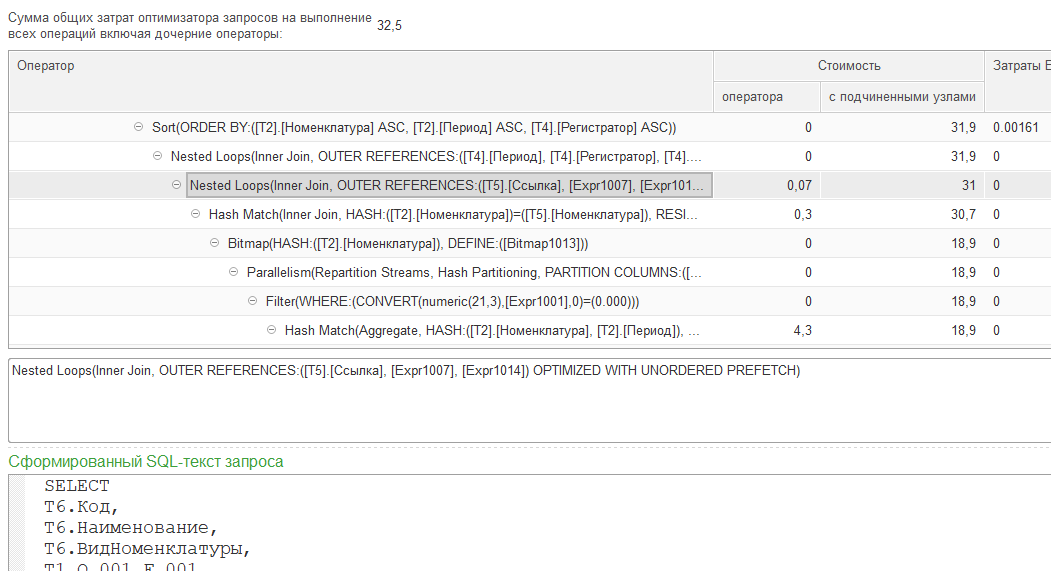
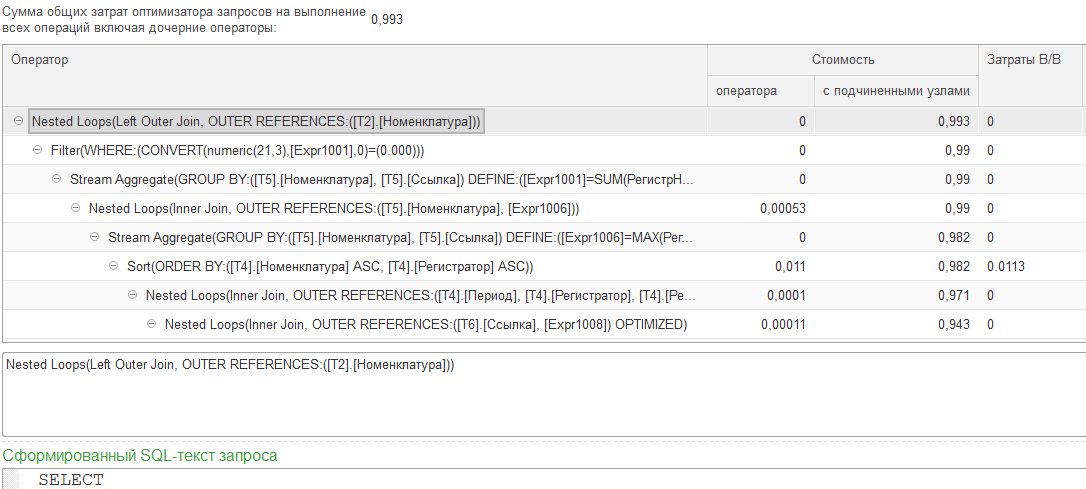
1. Конечно, самым идеальным вариантом будет анализ плана запроса! НО! Этим механизмом далеко не все владеют! Поэтому рассматривать его не будем в данной статье, это уже много раз описано в других статьях. Расскажу о вполне очевидных моментах, для которых не требуется быть экспертом по технологическим вопросам.
2. Одним из очевидных моментов является использование вложенных запросов. На эту тему есть и стандарт разработки, много статей написано почему это лучше не делать. Коротко - выбирается неоптимальный план выполнения запроса. Сам стараюсь это не использовать совсем. Если кто-то использует то вот несколько советов:
-- Старайтесь во вложенном запросе не обращаться к физическим либо виртуальным таблицам, т.е. к базе данных. Желательно обращаться к временным таблицам
-- Если есть потребность обратиться во вложенном запросе к физической таблице - желательно, чтоб эта таблица была маленькой, до 1000 записей. Например, справочник Организации, Подразделения, Склады и т.д.
-- При обращении ко временным таблицам, также желательно, чтоб размер временной таблицы во вложенном запросе был минимален. Не нужно регистр ЦеныНоменклатуры помещать во временную таблицу и обращаться к ней во вложенном запросе. Скорей всего план выполнения запроса будет не оптимален.
3. При использовании виртуальных таблиц остаточного регистра накопления не нужно без надобности использовать таблицу ОстаткиИОбороты. Её формирование занимает некоторое время, даже если использованы отборы в параметрах виртуальных таблиц.
4. Есть простые правила при наложении условий и связей:
-- Не использовать конструкцию ИЛИ в условиях и связях если используются физические или виртуальные таблицы. Конструкция ИЛИ отключает использование индексов.
-- Условия и связи должны накладываться по индексированным полям. Вам необходимо контролировать, чтоб условия использовали индексы по порядку. Т.е. если у регистра 3 измерения, а в условии/связи использовать только первое и третье, то всё равно произойдёт полное сканирование таблицы. Необходимо такой запрос разбить на 2. На эту тему есть отдельный стандарт разработки, прошу ознакомиться.
-- При использовании временных таблиц с количеством записей более 10 тыс. оправдано индексирование полей временной таблицы, которые используются в связях и условиях.
5. Старайтесь не использовать разыменовывание полей. Если необходимо вытащить поля справочника Организации, то можно не делать ЛЕВОЕ СОЕДИНЕНИЕ, т.к. присоединяемая таблица маленькая. Вряд ли возникнут сложности с таким запросом. Но если необходимо вытащить поля справочников Номенклатура, Сотрудники и т.п. обязательно добавлять таблицу справочника в запрос и связывать по Ссылке левым соединением.
6. Отдельно напишу, что разыменовывание полей составного типа может привести к сильному замедлению работы, в каких-то случаях даже к серьёзным тормозам всего сервера! Делать так ЗАПРЕЩЕНО! Необходимо присоединять нужную таблицу левым соединением.
7. При использовании виртуальных таблиц регистра накопления не рекомендуется просто так указывать периодичность Регистратор и Запись. Это должно быть обосновано условием решаемой задачи. Расчет итогов происходит по бОльшему количеству записей, что не добавляет скорости.
Наверное есть ещё какие-то ситуации, в которых нужно оптимизировать запросы... Описал самые критичные случаи. Есть главное правило: соблюдайте стандарты разработки 1С и проблем в коде у Вас не будет. Для запросов это правило работает где-то в 90% случаев. Но на больших объёмах данных бывают ситуации когда лучше нарушить стандарт, чтоб запрос работал быстрее. Этот кейс рассматривать не стану, т.к. нарушать правила надо осознанно и очень аккуратно!
Уверен, что проделав действия, описанные в этом кейсе, запрос будет успешно разобран на составляющие, оптимизирован и доработан, как Вам необходимо в соответствии с заданием.
Остальные части доступны по ссылкам:
Часть 1. Общие вопросы. Доработка чужого кода. Code review.
Часть 2. Доработка типовой конфигурации. Обновление доработанной типовой конфигурации.
Часть 4. Программный интерфейс. Исправление чужих доработок.
Добавляйте себе в избранное, ставьте "+". Статья разрабатывалась 1,5 месяца, а опыт копился 18 лет!
Также напомню о своих предыдущих публикациях, в особенности про статью об архитекторе. Текст статьи полностью переработан, сглажены углы. Будет интересно, даже если уже читали. Вот ссылки:
1. Кто такой архитектор. Редакция 2!
2. Пример работы с файлами odt в клиент-серверной модели работы
Вступайте в нашу телеграмм-группу Инфостарт