








Источник https://www.alexdebrie.com/posts/dynamodb-one-to-many/, Примечание: объединения = соединения = JOIN
Делаю для лучшего понимания применимости связки Yandex Serverless + Yandex Database (Document API, совместим с Amazon DynamoDB) для небольших проектов, которые попадают в бесплатную тарификацию.
DynamoDB иногда считается простым хранилищем значений ключей, но ничто не может быть дальше от истины. DynamoDB может обрабатывать сложные шаблоны доступа, от высокореляционных моделей данных до данных временных рядов или даже геопространственных данных.
В этом посте мы увидим, как моделировать отношения "один ко многим" в DynamoDB. Отношения "один ко многим" лежат в основе почти всех приложений. В DynamoDB у вас есть несколько различных вариантов представления отношений "один ко многим".
Мы рассмотрим основы отношений "один ко многим", затем рассмотрим пять различных стратегий моделирования отношений "один ко многим" в DynamoDB.
Основы отношений "один ко многим"
Отношение "один ко многим" возникает, когда конкретный объект является владельцем или источником для нескольких подобъектов. Несколько примеров включают:
- Рабочее место: В одном офисе будет работать много сотрудников; у одного менеджера может быть много прямых подчиненных.
- Электронная коммерция: один клиент может делать несколько заказов с течением времени; один заказ может состоять из нескольких товаров.
- Учетные записи программного обеспечения как услуги (SaaS): Организация приобретет подписку на SaaS; несколько пользователей будут принадлежать одной организации.
При использовании отношений "один ко многим" возникает одна основная проблема: как мне получить информацию о родительском объекте при извлечении одного или нескольких связанных объектов?
В реляционной базе данных, по сути, есть один способ сделать это — использовать внешний ключ в одной таблице для ссылки на запись в другой таблице и использовать SQL объединения во время запроса для объединения двух таблиц.
В DynamoDB нет объединений. Вместо этого существует ряд стратегий для отношений "один ко многим", и выбранный вами подход будет зависеть от ваших потребностей.
В этом посте мы рассмотрим пять стратегий моделирования отношений "один ко многим" с помощью DynamoDB:
- Денормализация с использованием сложного атрибута
- Денормализация путем дублирования данных
- Составной первичный ключ + действие API запроса
- Вторичный индекс + действие API запроса
- Составные ключи сортировки с иерархическими данными
Ниже мы подробно рассмотрим каждую стратегию — когда вы бы ее использовали, когда бы вы ее не использовали, и приведем пример. В конце поста приводится краткое описание пяти стратегий и время выбора каждой из них.
Денормализация с использованием сложного атрибута
Нормализация базы данных является ключевым компонентом моделирования реляционных баз данных и одной из самых сложных привычек, от которых нужно отказаться при переходе на DynamoDB.
Вы можете прочитать основы нормализации в другом месте, но есть ряд областей, где денормализация полезна с помощью DynamoDB.
Первый способ, которым мы будем использовать денормализацию с помощью DynamoDB, - это наличие атрибута, который использует сложный тип данных, такой как список или карта. Это нарушает первый принцип нормализации базы данных: чтобы перейти в первую нормальную форму, каждое значение атрибута должно быть атомарным. Его нельзя разбивать дальше.
Давайте посмотрим на это на примере. Представьте, что у нас есть сайт электронной коммерции, где есть организации-клиенты, которые представляют людей, создавших учетную запись на нашем сайте. У одного Клиента может быть несколько почтовых адресов, по которым он может отправлять товары. Возможно, у меня есть один адрес для моего дома, другой адрес для моего рабочего места и третий адрес для моих родителей (пережиток того времени, когда я отправил им запоздалый подарок на годовщину).
В реляционной базе данных вы бы смоделировали это с помощью двух таблиц, используя внешний ключ для соединения таблиц вместе следующим образом:

Обратите внимание, что каждая запись в таблице "Addresses" содержит "CustomerId", который идентифицирует "Клиента", которому принадлежит этот "Адрес". Вы можете использовать операцию соединения, чтобы следовать указателю на запись и находить информацию о Клиенте.
DynamoDB работает по-другому. Поскольку соединений нет, нам нужно найти другой способ сбора данных из двух разных типов объектов. В этом примере мы можем добавить атрибут "MailingAddresses" к нашему элементу "Клиент". Этот атрибут представляет собой карту и содержит все адреса для данного клиента:
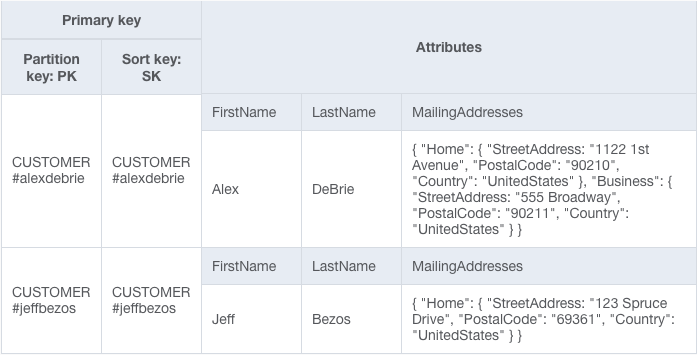
Поскольку "MailingAddresses" содержат несколько значений, запись в таблице больше не является атомарной и, таким образом, нарушает принципы первой нормальной формы.
Есть два фактора, которые следует учитывать при принятии решения о том, следует ли обрабатывать отношение "один ко многим" путем денормализации с помощью сложного атрибута:
- Есть ли у вас какие-либо шаблоны доступа, основанные на значениях в сложном атрибуте?
Весь доступ к данным в DynamoDB осуществляется через первичные ключи и вторичные индексы. Вы не можете использовать сложный атрибут, такой как список или карта, в первичном ключе. Таким образом, вы не сможете выполнять запросы на основе значений в сложном атрибуте.
В нашем примере у нас нет никаких шаблонов доступа, таких как “Поиск клиента по его или ее почтовому адресу”. Все использование атрибута "MailingAddress" будет осуществляться в контексте Клиента, например, для отображения сохраненных адресов на странице оформления заказа. Учитывая эти потребности, для нас вполне нормально сохранить их в сложном атрибуте.
- Является ли объем данных в сложном атрибуте неограниченным?
Объем одного элемента DynamoDB не может превышать 400 КБ данных. Если объем данных, содержащихся в вашем сложном атрибуте, потенциально неограничен, он не будет хорошо подходить для денормализации и хранения вместе в одном элементе.
В этом примере для нашего приложения разумно установить ограничения на количество почтовых адресов, которые может хранить клиент. Максимум 20 адресов должны удовлетворять почти всем вариантам использования и избегать проблем с ограничением в 400 КБ.
Но вы могли бы представить себе другие места, где отношение "один ко многим" может быть неограниченным. Например, в нашем приложении для электронной коммерции есть концепция Заказов и товаров для заказов. Поскольку в Заказе может быть неограниченное количество Позиций Заказа (вы же не хотите сообщать своим клиентам о максимальном количестве позиций, которые они могут заказать!), Имеет смысл разделять Позиции Заказа отдельно от Заказов.
Если ответ на любой из вышеприведенных вопросов “Да”, то денормализация со сложным атрибутом не подходит для моделирования этого отношения "один ко многим".
Денормализация путем дублирования данных
В описанной выше стратегии мы денормализовали наши данные, используя сложный атрибут. Это нарушало принципы первой нормальной формы для реляционного моделирования. В рамках этой стратегии мы продолжим наш крестовый поход против нормализации.
Здесь мы нарушим принципы второй нормальной формы, дублируя данные по нескольким элементам.
Во всех базах данных каждая запись однозначно идентифицируется каким-либо ключом. В реляционной базе данных это может быть автоматически увеличивающийся первичный ключ. В DynamoDB это первичный ключ.
Чтобы перейти ко второй нормальной форме, каждый неключевой атрибут должен зависеть от всего ключа. Это сбивающий с толку способ сказать, что данные не должны дублироваться в нескольких записях. Если данные дублируются, их следует вынести в отдельную таблицу. Каждая запись, использующая эти данные, должна ссылаться на них через ссылку на внешний ключ.
Представьте, что у нас есть приложение, содержащее книги и авторов. У каждой книги есть Автор, и у каждого Автора есть некоторая биографическая информация, такая как его имя и год рождения. В реляционной базе данных мы бы смоделировали данные следующим образом:
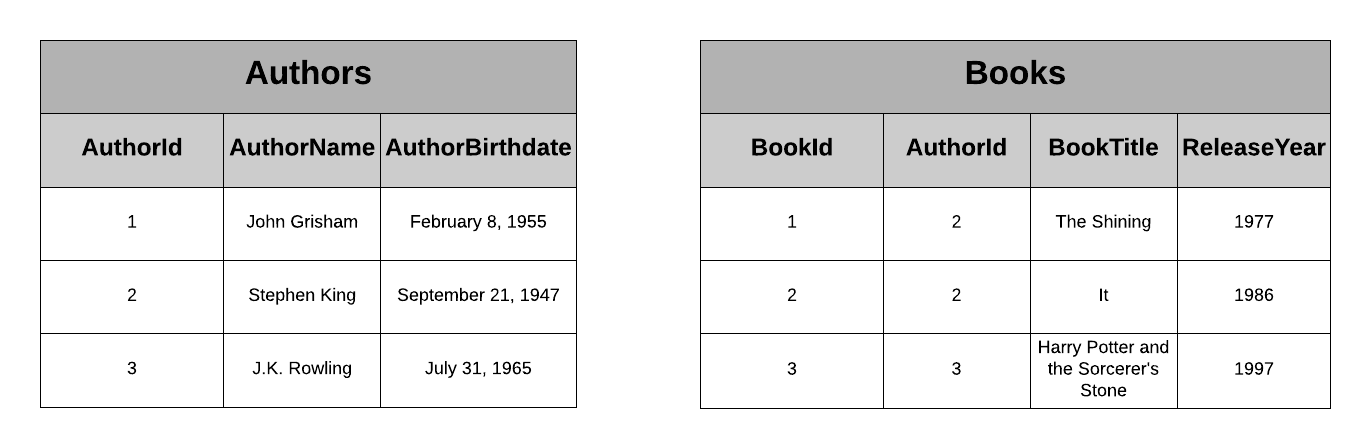
Примечание: На самом деле у книги может быть несколько авторов. Для упрощения этого примера мы предполагаем, что у каждой книги ровно один автор.
Это работает в реляционной базе данных, поскольку вы можете объединить эти две таблицы во время запроса, чтобы включить биографическую информацию автора при получении подробной информации о книге.
Но у нас нет объединений в DynamoDB. Итак, как мы можем решить эту проблему? Мы можем проигнорировать правила второй нормальной формы и включить биографическую информацию автора в каждый элемент Книги, как показано ниже.
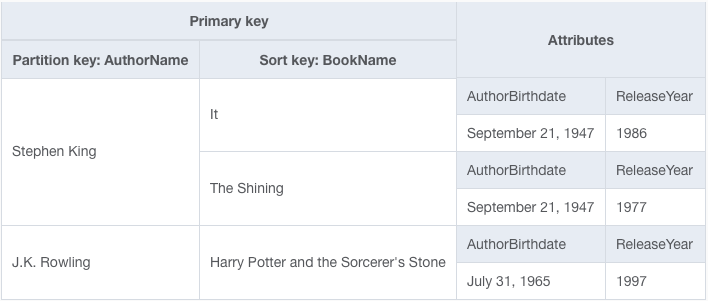
Обратите внимание, что существует несколько книг, содержащих биографическую информацию об авторе Стивене Кинге. Поскольку эта информация не изменится, мы можем сохранить ее непосредственно в самом элементе Книги. Всякий раз, когда мы извлекаем Книгу, мы также получаем информацию о родительском элементе Автора.
Есть два основных вопроса, которые вы должны задать при рассмотрении этой стратегии:
- Является ли дублируемая информация неизменяемой?
- Если данные действительно меняются, то как часто они меняются и сколько элементов содержат дублирующуюся информацию?
В нашем примере выше мы продублировали биографическую информацию, которая вряд ли изменится. Поскольку он по сути неизменяем, его можно дублировать, не беспокоясь о проблемах с согласованностью при изменении этих данных.
Даже если данные, которые вы дублируете, действительно изменяются, вы все равно можете решить их дублировать. Важными факторами, которые следует учитывать, являются частота изменения данных и количество элементов, содержащих дублирующуюся информацию.
Если данные меняются довольно редко и денормализованные элементы считываются часто, возможно, будет нормально дублировать, чтобы сэкономить деньги на всех этих последующих чтениях. Когда дублированные данные действительно изменятся, вам нужно будет поработать над тем, чтобы убедиться, что они изменены во всех этих элементах.
Что приводит нас ко второму фактору — сколько элементов содержат дублированные данные. Если вы продублировали данные только по трем элементам, может быть легко найти и обновить эти элементы при изменении данных. Если эти данные копируются между тысячами элементов, обнаружение и обновление каждого из этих элементов может оказаться настоящей рутиной, и вы подвергаетесь большему риску несоответствия данных.
По сути, вы уравновешиваете преимущества дублирования (в виде более быстрого чтения) с затратами на обновление данных. Затраты на обновление данных включают оба вышеперечисленных фактора. Если затраты на любой из вышеперечисленных факторов невелики, то почти любая выгода того стоит. Если затраты высоки, то верно обратное.
Составной первичный ключ + действие API запроса
Следующая стратегия моделирования отношений "один ко многим" - и, вероятно, наиболее распространенный способ - заключается в использовании составного первичного ключа плюс API запроса для извлечения объекта и связанных с ним подобъектов.
Ключевым понятием в DynamoDB является понятие коллекций элементов. Коллекции элементов - это все элементы таблицы или вторичного индекса, которые используют один и тот же ключ раздела. При использовании действия Query API вы можете извлекать несколько элементов из одной коллекции элементов. Это может включать элементы разных типов, что дает вам поведение, подобное объединению, с гораздо лучшими характеристиками производительности.
Давайте воспользуемся одним из примеров из начала этого раздела. В приложении SaaS организации будут регистрировать учетные записи. Затем несколько пользователей будут принадлежать к Организации и пользоваться преимуществами подписки.
Поскольку мы будем включать разные типы элементов в одну и ту же таблицу, у нас не будет значимых имен атрибутов для атрибутов в нашем первичном ключе. Скорее всего, мы будем использовать общие имена атрибутов, такие как PK (первичный ключ) и SK (сортировочный ключ), для нашего первичного ключа.
В нашей таблице есть два типа элементов — Организации и Пользователи. Шаблоны для значений PK и SK следующие:
|
PK | SK | |
|---|---|---|---|
| Organizations | ORG#<OrgName> | METADATA#<OrgName> | |
| Users | ORG#<OrgName> | User#<UserName> |
В таблице ниже приведены некоторые примеры элементов:
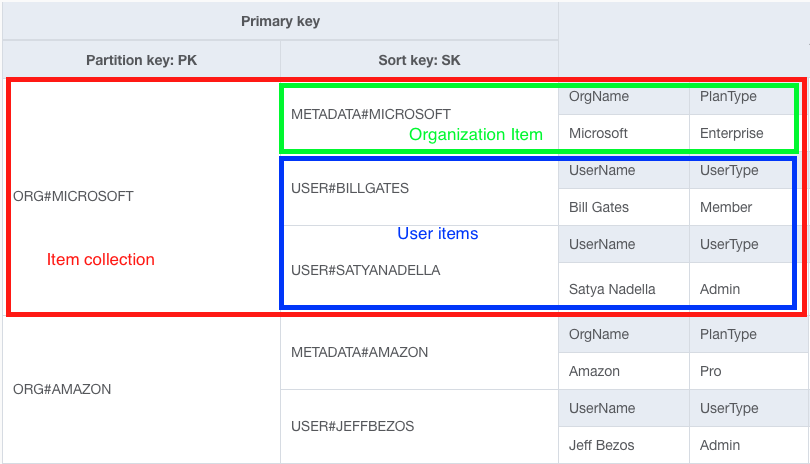
В эту таблицу мы добавили пять элементов — два элемента организации для Microsoft и Amazon и три элемента пользователя для Билла Гейтса, Сатьи Наделлы и Джеффа Безоса.
Красным выделена коллекция элементов для элементов с ключом раздела ORG#MICROSOFT. Обратите внимание, что в этой коллекции есть два разных типа элементов. Зеленым цветом обозначен тип элемента организации в этой коллекции элементов, а синим - тип элемента пользователя в этой коллекции элементов.
Такая конструкция первичного ключа упрощает решение четырех шаблонов доступа:
- Получить организацию. Используйте вызов GetItem API и название организации, чтобы сделать запрос для элемента с PK ORG#<OrgName> и SK METADATA#<OrgName>.
- Получить Организацию и всех пользователей внутри Организации. Используйте действие API запроса с выражением ключевого условия PK = ORG#<OrgName>. Это позволит получить Организацию и всех пользователей в ней, поскольку все они имеют один и тот же ключ раздела.
- Получить только пользователей внутри Организации. Используйте действие API запроса с выражением ключевого условия PK = ORG#<OrgName> AND begins_with(SK, "USER#"). Использование функции begins_with() позволяет нам извлекать только пользователей, не извлекая также объект Организации.
- Получить конкретного пользователя. Если вы знаете как название организации, так и имя пользователя Пользователя, вы можете использовать вызов GetItem API с PK ORG#<OrgName> и SK USER#<Username> для извлечения элемента User.
Хотя все четыре из этих шаблонов доступа могут быть полезны, второй шаблон доступа — Получение организации и всех пользователей внутри Организации — наиболее интересен для этого обсуждения отношений "один ко многим". Обратите внимание, как мы эмулируем операцию объединения в SQL, размещая родительский объект (Организацию) в той же коллекции элементов, что и связанные объекты (Пользователи). Мы предварительно объединяем наши данные, объединяя их во время записи.
Это довольно распространенный способ моделирования отношений "один ко многим", который будет работать в ряде ситуаций.
Вторичный индекс + действие API запроса
Аналогичный шаблон для отношений "один ко многим" заключается в использовании глобального вторичного индекса и API запросов для извлечения многих. Этот шаблон почти такой же, как и предыдущий, но в нем используется вторичный индекс, а не первичные ключи в основной таблице.
Возможно, вам придется использовать этот шаблон вместо предыдущего шаблона, поскольку первичные ключи в вашей таблице зарезервированы для другой цели. Это может быть какая-то конкретная цель записи, например, для обеспечения уникальности определенного свойства, или это может быть связано с тем, что у вас есть иерархические данные с несколькими уровнями.
Для последней ситуации давайте вернемся к нашему последнему примеру. Представьте, что в вашем SaaS-приложении каждый пользователь может создавать и сохранять различные объекты. Если бы это был Google Диск, это мог бы быть документ. Если бы это был Zendesk, это мог бы быть билет. Если бы это была Typeform, это могла бы быть Форма.
Давайте воспользуемся примером Zendesk и воспользуемся билетом. В наших случаях предположим, что каждый билет идентифицируется идентификатором, представляющим собой комбинацию метки времени плюс случайный хэш-суффикс. Кроме того, каждый билет принадлежит определенному Пользователю в Организации.
Если бы мы хотели найти все билеты, принадлежащие определенному пользователю, мы могли бы попытаться чередовать их с существующим форматом таблицы из предыдущей стратегии следующим образом:
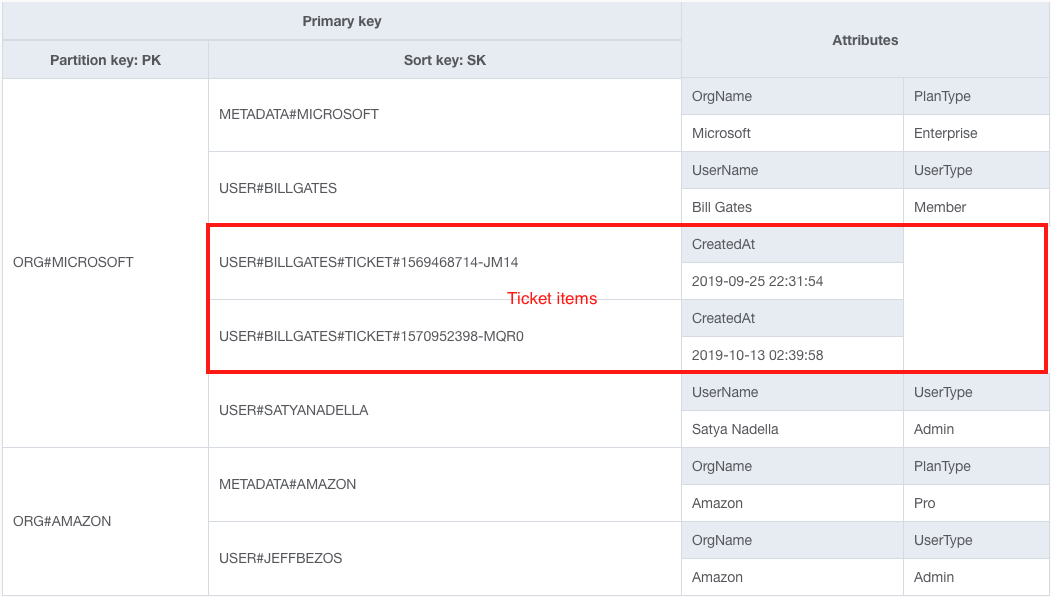
Обратите внимание на два новых элемента билета, выделенных красным цветом.
Проблема заключается в том, что это действительно мешает моим предыдущим вариантам использования. Если я хочу получить "Организацию" и всех ее "Пользователей", я также получаю кучу "Билетов". И поскольку "Билеты", вероятно, значительно превысят количество "Пользователей", я буду извлекать много бесполезных данных и выполнять несколько запросов на разбивку на страницы для обработки нашего первоначального варианта использования.
Вместо этого давайте попробуем что-нибудь другое. Мы сделаем три вещи:
- Мы смоделируем наши элементы билетов так, чтобы они находились в отдельной коллекции элементов в главной таблице. Для значений PK и SK мы будем использовать шаблон TICKET#<TicketID>, который позволит осуществлять прямой поиск элемента билета.
- Создайте глобальный вторичный индекс с именем GSI1, ключами которого являются GSI1PK и GSI1SK.
- Как для нашего билета, так и для пользовательских элементов добавьте значения для GSI1PK и GSI1SK. Для обоих элементов значением атрибута GSI1PK будет ORG#<OrgName>#USER#<UserName>.
Для элемента "Пользователь" значением GSI1SK будет USER#<UserName>.
Для элемента "Билет" значением GSI1SK будет БИЛЕТ#<TicketID>.
Теперь наша базовая таблица выглядит следующим образом:
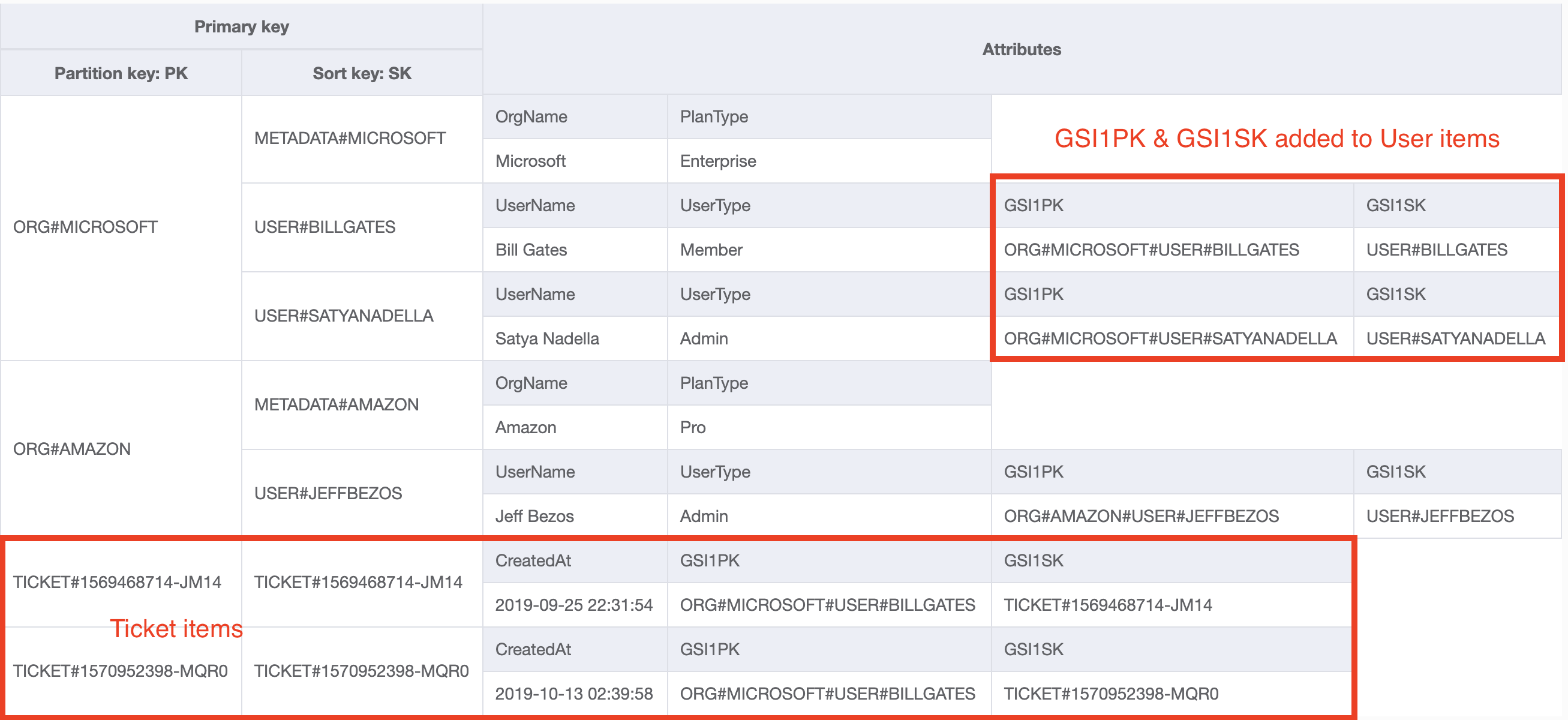
Обратите внимание, что элементы наших билетов больше не чередуются с их родительскими пользователями в базовой таблице. Кроме того, пользовательские элементы теперь имеют дополнительные атрибуты GSI1PK и GSI1SK, которые будут использоваться для индексации.
Если мы посмотрим на наш вторичный индекс GSI 1, мы увидим следующее:
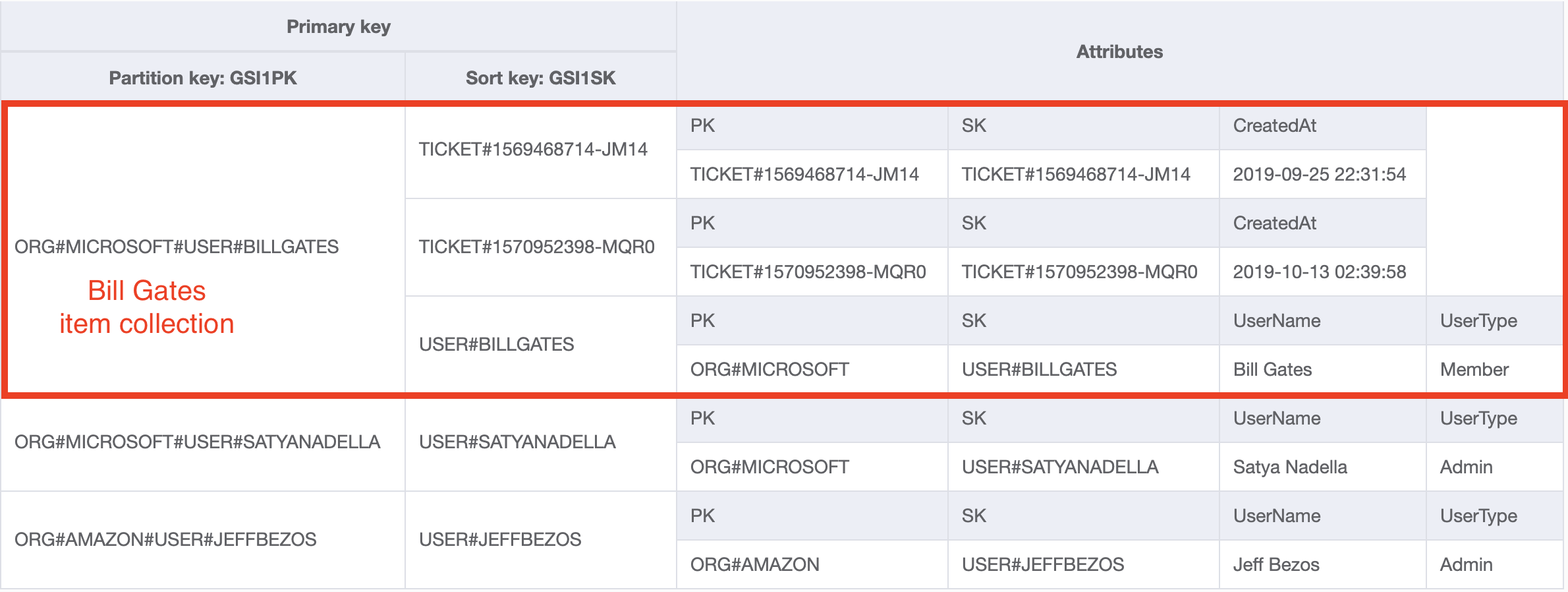
Этот вторичный индекс содержит коллекцию элементов, содержащую как пользовательский элемент, так и все элементы пользовательского билета. Это позволяет использовать те же шаблоны доступа, которые мы обсуждали в предыдущем разделе.
Последнее замечание, прежде чем двигаться дальше — обратите внимание, что я структурировал его так, чтобы элемент "Пользователь" был последним элементом в разделе. Это происходит потому, что "Билеты" сортируются по метке времени. Вполне вероятно, что я захочу получить пользователя и самые последние билеты пользователя, а не самые старые билеты. Таким образом, я упорядочиваю его так, чтобы пользователь находился в конце коллекции элементов, и я могу использовать свойство ScanIndexForward=False, чтобы указать, что DynamoDB должен начинаться с конца коллекции элементов и считываться в обратном направлении.
Составные ключи сортировки с иерархическими данными
В последних двух стратегиях мы видели некоторые данные с несколькими уровнями иерархии — у Организации есть пользователи, которые создают заявки. Но что, если у вас более двух уровней иерархии? Вы не хотите продолжать добавлять вторичные индексы, чтобы включить произвольные уровни выборки по всей вашей иерархии.
Распространенным примером в этой области являются данные, основанные на местоположении. Давайте продолжим нашу тему рабочего места и представим, что вы отслеживаете все местоположения Starbucks по всему миру. Вы хотите иметь возможность фильтровать местоположения Starbucks на произвольных географических уровнях — по стране, штату, городу или почтовому индексу.
Мы могли бы решить эту проблему, используя составной ключ сортировки. Этот термин немного сбивает с толку, потому что мы используем составной первичный ключ в нашей таблице. Термин составной ключ сортировки означает, что мы будем объединять множество свойств в нашем ключе сортировки, чтобы обеспечить различную степень детализации поиска.
Давайте посмотрим, как это выглядит в таблице. Ниже приведены несколько пунктов:
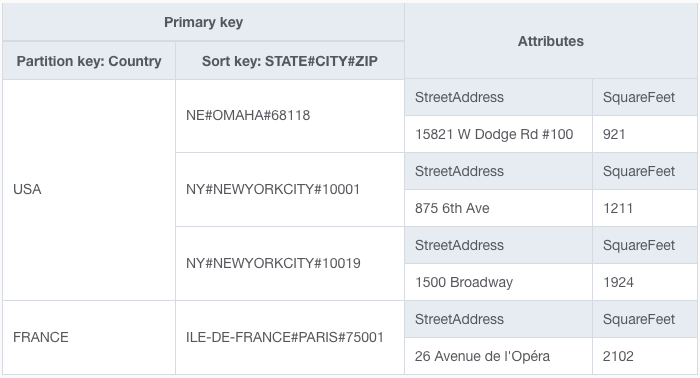
В нашей таблице ключом раздела является страна, в которой находится Starbucks. Для ключа сортировки мы включаем штат, город и почтовый индекс, причем каждый уровень разделяется символом #. С помощью этого шаблона мы можем выполнять поиск на четырех уровнях детализации, используя только наш первичный ключ!
Паттерны таковы:
- Найдите все местоположения в данной стране. Используйте запрос с выражением ключевого условия PK = <Country>, где страна - это та страна, которую вы хотите.
- Найдите все местоположения в данной стране и штате. Используйте запрос с выражением условия PK = <Country> AND begins_with(SK, '<State>#').
- Найдите все местоположения в данной стране, штате и городе. Используйте запрос с выражением условия PK = <Country> AND begins_with(SK, '<State>#<City>').
- Найдите все местоположения в данной стране, штате, городе и почтовом индексе. Используйте запрос с выражением условия PK = <Country> AND begins_with(SK, '<State>#<City>#<ZipCode>').
Этот составной шаблон ключа сортировки не будет работать для всех сценариев, но он может быть отличным в правильной ситуации. Это работает лучше всего, когда:
- У вас есть много уровней иерархии (> 2), и у вас есть шаблоны доступа для разных уровней внутри иерархии.
- При поиске на определенном уровне иерархии вам нужны все подпункты этого уровня, а не только элементы этого уровня.
Например, вспомните наш пример SaaS при обсуждении стратегий первичного ключа и вторичного индекса. При поиске на одном уровне иерархии — найти всех пользователей — мы не хотели углубляться в иерархию, чтобы найти все билеты для каждого пользователя. В этом случае составной ключ сортировки вернет много посторонних элементов.
Если вам нужно подробное пошаговое руководство по этому примеру, я написал полный пример Starbucks на DynamoDBGuide.com.
Вывод
В этом посте мы обсудили пять различных стратегий, которые вы можете реализовать при моделировании данных в соотношении "один ко многим" с помощью DynamoDB. Эти стратегии кратко изложены в таблице ниже.
| Стратегия | Примечание | Соответствующие примеры |
|---|---|---|
| Денормализация с использованием сложного атрибута | Хорош, когда вложенные объекты ограничены и к ним нет прямого доступа | Почтовые адреса пользователей |
| Денормализация путем дублирования данных | Хорошо, когда дублируемые данные являются неизменяемыми или нечасто изменяющимися | Книги и Авторы; Фильмы и Роли |
| Первичный ключ + API запросов | Наиболее распространенный. Подходит для шаблонов множественного доступа к двум типам сущностей. | Большинство отношений "один ко многим" |
| Вторичный индекс + API запросов, аналогичный стратегии первичного ключа. | Хорош, когда первичный ключ нужен для чего-то другого. | Большинство отношений "один ко многим" |
| Составной ключ сортировки | Подходит для очень иерархичных данных, где вам нужно выполнять поиск на нескольких уровнях иерархии | Места расположения Starbucks |
Учитывайте свои потребности при моделировании отношений "один ко многим" и определите, какая стратегия лучше всего подходит для вашей ситуации.
Вступайте в нашу телеграмм-группу Инфостарт