Этот скрипт взят отсюда. Там же есть примеры использования, описания процедур и их параметров, а также другая связанная информация.
USE [SQLServerMaintenance]
GO
CREATE TABLE [dbo].[MaintenanceActionsLog](
[Id] [bigint] IDENTITY(1,1) NOT NULL,
[Period] [datetime2](0) NOT NULL,
[TableName] [nvarchar](255) NOT NULL,
[IndexName] [nvarchar](255) NOT NULL,
[Operation] [nvarchar](100) NOT NULL,
[RunDate] [datetime2](0) NOT NULL,
[StartDate] [datetime2](0) NOT NULL,
[FinishDate] [datetime2](0) NULL,
[DatabaseName] [nvarchar](500) NOT NULL,
[UseOnlineRebuild] [bit] NOT NULL,
[Comment] [nvarchar](255) NOT NULL,
[IndexFragmentation] [float] NOT NULL,
[RowModCtr] [bigint] NOT NULL,
[SQLCommand] [nvarchar](max) NOT NULL,
CONSTRAINT [PK__Maintena__3214EC074E078F4E] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 90) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
CREATE VIEW [dbo].[v_CommonStatsByDay]
AS
SELECT
CAST([RunDate] AS DATE) AS "День",
COUNT(DISTINCT [TableName]) AS "Кол-во таблиц, для объектов которых выполнено обслуживание",
COUNT(DISTINCT [IndexName]) AS "Количество индексов, для объектов которых выполнено обслуживание",
SUM(CASE
WHEN [Operation] LIKE '%STAT%'
THEN 1
ELSE 0
END) AS "Обновлено статистик",
SUM(CASE
WHEN [Operation] LIKE '%INDEX%'
THEN 1
ELSE 0
END) AS "Обслужено индексов"
FROM [SQLServerMaintenance].[dbo].[MaintenanceActionsLog]
GROUP BY CAST([RunDate] AS DATE)
GO
CREATE TABLE [dbo].[ConnectionsStatistic](
[id] [int] IDENTITY(1,1) NOT NULL,
[Period] [datetime2](7) NOT NULL,
[InstanceName] [nvarchar](255) NULL,
[QueryText] [nvarchar](max) NULL,
[RowCountSize] [bigint] NULL,
[SessionId] [bigint] NULL,
[Status] [nvarchar](255) NULL,
[Command] [nvarchar](255) NULL,
[CPU] [bigint] NULL,
[TotalElapsedTime] [bigint] NULL,
[StartTime] [datetime2](7) NULL,
[DatabaseName] [nvarchar](255) NULL,
[BlockingSessionId] [bigint] NULL,
[WaitType] [nvarchar](255) NULL,
[WaitTime] [bigint] NULL,
[WaitResource] [nvarchar](255) NULL,
[OpenTransactionCount] [bigint] NULL,
[Reads] [bigint] NULL,
[Writes] [bigint] NULL,
[LogicalReads] [bigint] NULL,
[GrantedQueryMemory] [bigint] NULL,
[UserName] [nvarchar](255) NULL,
CONSTRAINT [PK_ConnectionsStatistic] PRIMARY KEY CLUSTERED
(
[id] ASC,
[Period] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 90) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
CREATE TABLE [dbo].[DatabaseObjectsState](
[Id] [bigint] IDENTITY(1,1) NOT NULL,
[Period] [datetime2](0) NOT NULL,
[DatabaseName] [nvarchar](150) NOT NULL,
[TableName] [nvarchar](250) NOT NULL,
[Object] [nvarchar](250) NOT NULL,
[PageCount] [bigint] NOT NULL,
[Rowmodctr] [bigint] NOT NULL,
[AvgFragmentationPercent] [int] NOT NULL,
[OnlineRebuildSupport] [int] NOT NULL,
[Compression] [nvarchar](10) NULL,
[PartitionCount] [bigint] NULL,
CONSTRAINT [PK__DatabaseObjectsState__3214EC074E078F4E] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 90) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[DatabasesTablesStatistic](
[Period] [datetime2](7) NOT NULL,
[DatabaseName] [nvarchar](255) NOT NULL,
[SchemaName] [nvarchar](5) NOT NULL,
[TableName] [nvarchar](255) NOT NULL,
[RowCnt] [bigint] NOT NULL,
[Reserved] [bigint] NOT NULL,
[Data] [bigint] NOT NULL,
[IndexSize] [bigint] NOT NULL,
[Unused] [bigint] NOT NULL
) ON [PRIMARY]
GO
CREATE UNIQUE CLUSTERED INDEX [UK_DatabasesTablesStatistic_Period_DatabaseName_TableName] ON [dbo].[DatabasesTablesStatistic]
(
[Period] ASC,
[DatabaseName] ASC,
[SchemaName] ASC,
[TableName] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 90) ON [PRIMARY]
GO
CREATE TABLE [dbo].[MaintenanceIndexPriority](
[ID] [int] IDENTITY(1,1) NOT NULL,
[DatabaseName] [nvarchar](255) NOT NULL,
[TableName] [nvarchar](255) NOT NULL,
[IndexName] [nvarchar](255) NOT NULL,
[Priority] [int] NOT NULL,
[Exclude] [bit] NULL,
CONSTRAINT [PK_MaintenanceIndexPriority] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 90) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [UK_Table_Object_Period] ON [dbo].[DatabaseObjectsState]
(
[DatabaseName] ASC,
[TableName] ASC,
[Object] ASC,
[Period] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 90) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [UK_RunDate_Table_Index_Period_Operation] ON [dbo].[MaintenanceActionsLog]
(
[RunDate] ASC,
[DatabaseName] ASC,
[TableName] ASC,
[IndexName] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 90) ON [PRIMARY]
GO
CREATE FUNCTION [dbo].[fn_ResumableIndexMaintenanceAvailiable]()
RETURNS bit
AS
BEGIN
DECLARE @checkResult bit;
SELECT
-- Возобновляемые операции обслуживания индексов доступны со SQL Server 2017
@checkResult = CASE
WHEN CAST(SUBSTRING(CONVERT(VARCHAR(128), SERVERPROPERTY('productversion')), 0, 3) AS INT) > 13
THEN 1
ELSE 0
END
RETURN @checkResult
END
GO
CREATE PROCEDURE [dbo].[sp_AdvancedPrint]
@sql varchar(max)
AS
BEGIN
declare
@n int,
@i int = 0,
@s int = 0,
@l int;
set @n = ceiling(len(@sql) / 8000.0);
while @i < @n
begin
set @l = 8000 - charindex(char(13), reverse(substring(@sql, @s, 8000)));
print substring(@sql, @s, @l);
set @i = @i + 1;
set @s = @s + @l + 2;
end
return 0
END
GO
CREATE PROCEDURE [dbo].[sp_add_maintenance_action_log]
@TableName sysname,
@IndexName sysname,
@Operation nvarchar(100),
@RunDate datetime2(0),
@StartDate datetime2(0),
@FinishDate datetime2(0),
@DatabaseName sysname,
@UseOnlineRebuild bit,
@Comment nvarchar(255),
@IndexFragmentation float,
@RowModCtr bigint,
@SQLCommand nvarchar(max),
@MaintenanceActionLogId bigint OUTPUT
AS
BEGIN
SET NOCOUNT ON;
DECLARE @IdentityOutput TABLE ( Id bigint )
SET @TableName = REPLACE(@TableName, '[', '')
SET @TableName = REPLACE(@TableName, ']', '')
SET @IndexName = REPLACE(@IndexName, '[', '')
SET @IndexName = REPLACE(@IndexName, ']', '')
SET @DatabaseName = REPLACE(@DatabaseName, '[', '')
SET @DatabaseName = REPLACE(@DatabaseName, ']', '')
SET @RowModCtr = ISNULL(@RowModCtr,0);
SET @SQLCommand = LTRIM(RTRIM((REPLACE(REPLACE(@SQLCommand, CHAR(13), ''), CHAR(10), ''))));
INSERT INTO [dbo].[MaintenanceActionsLog]
(
[Period]
,[TableName]
,[IndexName]
,[Operation]
,[RunDate]
,[StartDate]
,[FinishDate]
,[DatabaseName]
,[UseOnlineRebuild]
,[Comment]
,[IndexFragmentation]
,[RowModCtr]
,[SQLCommand]
)
OUTPUT inserted.Id into @IdentityOutput
VALUES
(
GETDATE()
,@TableName
,@IndexName
,@Operation
,@RunDate
,@StartDate
,@FinishDate
,@DatabaseName
,@UseOnlineRebuild
,@Comment
,@IndexFragmentation
,@RowModCtr
,@SQLCommand
)
SET @MaintenanceActionLogId = (SELECT MAX(Id) FROM @IdentityOutput)
RETURN 0
END
GO
CREATE PROCEDURE [dbo].[sp_FillConnectionsStatistic]
@monitoringDatabaseName sysname = 'SQLServerMaintenance'
AS
BEGIN
SET NOCOUNT ON;
DECLARE @cmd nvarchar(max);
SET @cmd =
CAST('
SET NOCOUNT ON;
INSERT INTO [' AS nvarchar(max)) + CAST(@monitoringDatabaseName AS nvarchar(max)) + CAST('].[dbo].[ConnectionsStatistic]
([Period]
,[InstanceName]
,[QueryText]
,[RowCountSize]
,[SessionId]
,[Status]
,[Command]
,[CPU]
,[TotalElapsedTime]
,[StartTime]
,[DatabaseName]
,[BlockingSessionId]
,[WaitType]
,[WaitTime]
,[WaitResource]
,[OpenTransactionCount]
,[Reads]
,[Writes]
,[LogicalReads]
,[GrantedQueryMemory]
,[UserName]
)
SELECT
GetDate() AS [Period],
@@servername AS [HostName],
sqltext.TEXT AS [QueryText],
req.row_count AS [RowCountSize],
req.session_id AS [SessionId],
req.status AS [Status],
req.command AS [Command],
req.cpu_time AS [CPU],
req.total_elapsed_time AS [TotalElapsedTime],
req.start_time AS [StartTime],
DB_NAME(req.database_id) AS [DatabaseName],
req.blocking_session_id AS [BlockingSessionId],
req.wait_type AS [WaitType],
req.wait_time AS [WaitTime],
req.wait_resource AS [WaitResource],
req.open_transaction_count AS [OpenTransactionCount],
req.reads as [Reads],
req.reads as [Writes],
req.logical_reads as [LogicalReads],
req.granted_query_memory as [GrantedQueryMemory],
SUSER_NAME(user_id) AS [UserName]
FROM sys.dm_exec_requests req
OUTER APPLY sys.dm_exec_sql_text(sql_handle) AS sqltext
' AS nvarchar(max));
EXECUTE sp_executesql @cmd;
RETURN 0
END
GO
CREATE PROCEDURE [dbo].[sp_FillDatabaseObjectsState]
@databaseName sysname,
@monitoringDatabaseName sysname = 'SQLServerMaintenance'
AS
BEGIN
SET NOCOUNT ON;
DECLARE @msg nvarchar(max);
IF DB_ID(@databaseName) IS NULL
BEGIN
SET @msg = 'Database ' + @databaseName + ' is not exists.';
THROW 51000, @msg, 1;
RETURN -1;
END
DECLARE @cmd nvarchar(max);
SET @cmd =
CAST('USE [' AS nvarchar(max)) + CAST(@databasename AS nvarchar(max)) + CAST(']
SET NOCOUNT ON;
INSERT INTO [' AS nvarchar(max)) + CAST(@monitoringDatabaseName AS nvarchar(max)) + CAST('].[dbo].[DatabaseObjectsState](
[Period]
,[DatabaseName]
,[TableName]
,[Object]
,[PageCount]
,[Rowmodctr]
,[AvgFragmentationPercent]
,[OnlineRebuildSupport]
,[Compression]
,[PartitionCount]
)
SELECT
GETDATE() AS [Period],
''' AS nvarchar(max)) + CAST(@databasename AS nvarchar(max)) + CAST(''' AS [DatabaseName],
OBJECT_NAME(dt.[object_id]) AS [Table],
ind.name AS [Object],
MAX(CAST([page_count] AS BIGINT)) AS [page_count],
SUM(CAST([si].[rowmodctr] AS BIGINT)) AS [rowmodctr],
MAX([avg_fragmentation_in_percent]) AS [frag],
MIN(CASE WHEN objBadTypes.IndexObjectId IS NULL THEN 1 ELSE 0 END) AS [OnlineRebuildSupport],
MAX(p.data_compression_desc) AS [Compression],
MAX(p_count.[PartitionCount]) AS [PartitionCount]
FROM
sys.dm_db_index_physical_stats (
DB_ID(),
NULL,
NULL,
NULL,
N''LIMITED''
) dt
LEFT JOIN sys.partitions p
ON dt.object_id = p.object_id and p.partition_number = 1
LEFT JOIN sys.sysindexes si ON dt.object_id = si.id
LEFT JOIN (
SELECT
t.object_id AS [TableObjectId],
ind.index_id AS [IndexObjectId]
FROM
sys.indexes ind
INNER JOIN sys.index_columns ic ON ind.object_id = ic.object_id
and ind.index_id = ic.index_id
INNER JOIN sys.columns col ON ic.object_id = col.object_id
and ic.column_id = col.column_id
INNER JOIN sys.tables t ON ind.object_id = t.object_id
LEFT JOIN INFORMATION_SCHEMA.COLUMNS tbsc ON t.schema_id = SCHEMA_ID(tbsc.TABLE_SCHEMA)
AND t.name = tbsc.TABLE_NAME
LEFT JOIN sys.types tps ON col.system_type_id = tps.system_type_id
AND col.user_type_id = tps.user_type_id
WHERE
t.is_ms_shipped = 0
AND CASE WHEN ind.type_desc = ''CLUSTERED'' THEN CASE WHEN tbsc.DATA_TYPE IN (
''text'', ''ntext'', ''image'', ''FILESTREAM''
) THEN 1 ELSE 0 END ELSE CASE WHEN tps.[name] IN (
''text'', ''ntext'', ''image'', ''FILESTREAM''
) THEN 1 ELSE 0 END END > 0
GROUP BY
t.object_id,
ind.index_id
) AS objBadTypes ON objBadTypes.TableObjectId = dt.object_id
AND objBadTypes.IndexObjectId = dt.index_id
LEFT JOIN sys.indexes AS [ind]
ON dt.object_id = [ind].object_id AND dt.index_id = [ind].[index_id]
LEFT JOIN (
SELECT
object_id,
index_id,
COUNT(DISTINCT partition_number) AS [PartitionCount]
FROM sys.partitions p
GROUP BY object_id, index_id
) p_count
ON dt.object_id = p_count.object_id AND dt.index_id = p_count.index_id
WHERE
[rowmodctr] IS NOT NULL -- Исключаем служебные объекты, по которым нет изменений
AND dt.[index_id] > 0 -- игнорируем кучи (heap)
GROUP BY
dt.[object_id],
dt.[index_id],
ind.[name],
dt.[partition_number]
' AS nvarchar(max));
EXECUTE sp_executesql @cmd;
RETURN 0
END
GO
CREATE PROCEDURE [dbo].[sp_GetCurrentResumableIndexRebuilds]
@databaseName sysname
AS
BEGIN
SET NOCOUNT ON;
DECLARE @msg nvarchar(max);
IF DB_ID(@databaseName) IS NULL
BEGIN
SET @msg = 'Database ' + @databaseName + ' is not exists.';
THROW 51000, @msg, 1;
RETURN -1;
END
DECLARE @LOCAL_ResumableIndexRebuilds TABLE
(
[object_id] int,
[index_id] int,
[name] sysname,
[sql_text] nvarchar(max),
[partition_number] int,
[state] tinyint,
[state_desc] nvarchar(60),
[start_time] datetime,
[last_pause_time] datetime,
[total_execution_time] int,
[percent_complete] real,
[page_count] bigint
);
IF([dbo].[fn_ResumableIndexMaintenanceAvailiable]() > 0)
BEGIN
DECLARE @cmd nvarchar(max);
SET @cmd = CAST('
USE [' AS nvarchar(max)) + CAST(@databaseName AS nvarchar(max)) + CAST(']
SET NOCOUNT ON;
SELECT
[object_id],
[index_id],
[name],
[sql_text],
[partition_number],
[state],
[state_desc],
[start_time],
[last_pause_time],
[total_execution_time],
[percent_complete],
[page_count]
FROM sys.index_resumable_operations;
' AS nvarchar(max));
INSERT @LOCAL_ResumableIndexRebuilds
EXECUTE sp_executesql @cmd;
END
SELECT
[object_id],
[index_id],
[name],
[sql_text],
[partition_number],
[state],
[state_desc],
[start_time],
[last_pause_time],
[total_execution_time],
[percent_complete],
[page_count]
FROM @LOCAL_ResumableIndexRebuilds
END
GO
CREATE PROCEDURE [dbo].[sp_IndexMaintenance]
@databaseName sysname,
@timeFrom TIME = '00:00:00',
@timeTo TIME = '23:59:59',
@fragmentationPercentMinForMaintenance FLOAT = 10.0,
@fragmentationPercentForRebuild FLOAT = 30.0,
@maxDop int = 8,
@minIndexSizePages int = 0,
@maxIndexSizePages int = 0,
@useOnlineIndexRebuild int = 0,
@useResumableIndexRebuildIfAvailable int = 0,
@maxIndexSizeForReorganizingPages int = 6553600,
@useMonitoringDatabase bit = 1,
@monitoringDatabaseName sysname = 'SQLServerMaintenance',
@usePreparedInformationAboutObjectsStateIfExists bit = 0,
@ConditionTableName nvarchar(max) = 'LIKE ''%''',
@ConditionIndexName nvarchar(max) = 'LIKE ''%''',
@onlineRebuildAbortAfterWaitMode int = 1,
@onlineRebuildWaitMinutes int = 5,
@maxTransactionLogSizeUsagePercent int = 100,
@maxTransactionLogSizeMB bigint = 0
AS
BEGIN
SET NOCOUNT ON;
DECLARE @msg nvarchar(max),
@abortAfterWaitOnlineRebuil nvarchar(25),
@currentTransactionLogSizeUsagePercent int,
@currentTransactionLogSizeMB int,
@timeNow TIME = CAST(GETDATE() AS TIME),
@useResumableIndexRebuild bit,
@RunDate datetime = GETDATE(),
@StartDate datetime,
@FinishDate datetime,
@MaintenanceActionLogId bigint,
-- Список исключенных из обслуживания индексов.
-- Например, если они были обслужены через механизм возобновляемых перестроений,
-- еще до запуска основного обслуживания
@excludeIndexes XML;
IF(@onlineRebuildAbortAfterWaitMode = 0)
BEGIN
SET @abortAfterWaitOnlineRebuil = 'NONE'
END ELSE IF(@onlineRebuildAbortAfterWaitMode = 1)
BEGIN
SET @abortAfterWaitOnlineRebuil = 'SELF'
END ELSE IF(@onlineRebuildAbortAfterWaitMode = 2)
BEGIN
SET @abortAfterWaitOnlineRebuil = 'BLOCKERS'
END ELSE
BEGIN
SET @abortAfterWaitOnlineRebuil = 'NONE'
END
IF DB_ID(@databaseName) IS NULL
BEGIN
SET @msg = 'Database ' + @databaseName + ' is not exists.';
THROW 51000, @msg, 1;
RETURN -1;
END
-- Информация о размере лога транзакций
IF OBJECT_ID('tempdb..#tranLogInfo') IS NOT NULL
DROP TABLE #tranLogInfo;
CREATE TABLE #tranLogInfo
(
servername varchar(250) not null default @@servername,
dbname varchar(250),
logsize real,
logspace real,
stat int
)
-- Проверка процента занятого места в логе транзакций
TRUNCATE TABLE #tranLogInfo;
INSERT INTO #tranLogInfo (dbname,logsize,logspace,stat) exec('dbcc sqlperf(logspace)')
SELECT
@currentTransactionLogSizeUsagePercent = logspace,
@currentTransactionLogSizeMB = logsize * (logspace / 100)
FROM #tranLogInfo WHERE dbname = @databaseName
IF(@currentTransactionLogSizeUsagePercent >= @maxTransactionLogSizeUsagePercent)
BEGIN
-- Процент занятого места в файлах лога транзакций превышает указанный порог
RETURN 0;
END
IF(@maxTransactionLogSizeMB > 0 AND @currentTransactionLogSizeMB > @maxTransactionLogSizeMB)
BEGIN
-- Размер занятого места в файлах лога транзакций превышает указанный порог в МБ
RETURN 0;
END
-- Возобновляемое перестроение индексов
DECLARE @LOCAL_ResumableIndexRebuilds TABLE
(
[object_id] int,
[object_name] nvarchar(255),
[index_id] int,
[name] sysname,
[sql_text] nvarchar(max),
[partition_number] int,
[state] tinyint,
[state_desc] nvarchar(60),
[start_time] datetime,
[last_pause_time] datetime,
[total_execution_time] int,
[percent_complete] real,
[page_count] bigint,
[ResumeCmd] nvarchar(max)
);
-- Флаг использования возобновляемого перестроения индексов
SET @useResumableIndexRebuild =
CASE
WHEN (@useResumableIndexRebuildIfAvailable > 0) -- Передан флаг использования возобновляемого перестроения
-- Возобновляемое перестроение доступно для версии SQL Server
AND [dbo].[fn_ResumableIndexMaintenanceAvailiable]() > 0
-- Включено использование онлайн-перестроения для скрипта
AND (@useOnlineIndexRebuild = 1 -- Только онлайн-перестроение
OR @useOnlineIndexRebuild = 3) -- Для объектов где оно возможно
THEN 1
ELSE 0
END;
IF(@useResumableIndexRebuild > 0)
BEGIN
DECLARE @cmdResumableIndexRebuild nvarchar(max);
SET @cmdResumableIndexRebuild = CAST('
USE [' AS nvarchar(max)) + CAST(@databaseName AS nvarchar(max)) + CAST(']
SET NOCOUNT ON;
SELECT
[object_id],
OBJECT_NAME([object_id]) AS [TableName],
[index_id],
[name],
[sql_text],
[partition_number],
[state],
[state_desc],
[start_time],
[last_pause_time],
[total_execution_time],
[percent_complete],
[page_count],
''ALTER INDEX ['' + [name] + ''] ON ['' + OBJECT_SCHEMA_NAME([object_id]) + ''].['' + OBJECT_NAME([object_id]) + ''] RESUME'' AS [ResumeCmd]
FROM sys.index_resumable_operations
WHERE OBJECT_NAME([object_id]) ' AS nvarchar(max)) + CAST(@ConditionTableName AS nvarchar(max)) + CAST('
AND [name] ' AS nvarchar(max)) + CAST(@ConditionIndexName AS nvarchar(max)) + CAST(';
' AS nvarchar(max));
INSERT @LOCAL_ResumableIndexRebuilds
EXECUTE sp_executesql @cmdResumableIndexRebuild;
DECLARE
@objectNameResumeRebuildForIndex nvarchar(255),
@indexNameResumeRebuildForIndex nvarchar(255),
@cmdResumeRebuildForIndex nvarchar(max);
DECLARE resumableIndexRebuild_cursor CURSOR FOR
SELECT
[object_name],
[name],
[ResumeCmd]
FROM @LOCAL_ResumableIndexRebuilds
ORDER BY start_time;
OPEN resumableIndexRebuild_cursor;
FETCH NEXT FROM resumableIndexRebuild_cursor
INTO @objectNameResumeRebuildForIndex, @indexNameResumeRebuildForIndex, @cmdResumeRebuildForIndex;
WHILE @@FETCH_STATUS = 0
BEGIN
-- Проверка доступен ли запуск обслуживания в текущее время
SET @timeNow = CAST(GETDATE() AS TIME);
IF (@timeTo >= @timeFrom) BEGIN
IF(NOT (@timeFrom <= @timeNow AND @timeTo >= @timeNow))
RETURN;
END ELSE BEGIN
IF(NOT ((@timeFrom <= @timeNow AND '23:59:59' >= @timeNow)
OR (@timeTo >= @timeNow AND '00:00:00' <= @timeNow)))
RETURN;
END
-- Проверки использования лога транзакций
-- Проверка процента занятого места в логе транзакций
TRUNCATE TABLE #tranLogInfo;
INSERT INTO #tranLogInfo (dbname,logsize,logspace,stat) exec('dbcc sqlperf(logspace)')
SELECT
@currentTransactionLogSizeUsagePercent = logspace,
@currentTransactionLogSizeMB = logsize * (logspace / 100)
FROM #tranLogInfo WHERE dbname = @databaseName
IF(@currentTransactionLogSizeUsagePercent >= @maxTransactionLogSizeUsagePercent)
BEGIN
-- Процент занятого места в файлах лога транзакций превышает указанный порог
RETURN 0;
END
IF(@maxTransactionLogSizeMB > 0 AND @currentTransactionLogSizeMB > @maxTransactionLogSizeMB)
BEGIN
-- Размер занятого места в файлах лога транзакций превышает указанный порог в МБ
RETURN 0;
END
BEGIN TRY
-- Сохраняем предварительную информацию об операции обслуживания без даты завершения
IF(@useMonitoringDatabase = 1)
BEGIN
SET @StartDate = GETDATE();
EXECUTE [dbo].[sp_add_maintenance_action_log]
@objectNameResumeRebuildForIndex,
@indexNameResumeRebuildForIndex,
'REBUILD INDEX RESUME',
@RunDate,
@StartDate,
null,
@databaseName,
1, -- @UseOnlineRebuild
'',
0, -- @AvgFragmentationPercent
0, -- @RowModCtr
@cmdResumeRebuildForIndex,
@MaintenanceActionLogId OUTPUT;
END
SET @cmdResumeRebuildForIndex = CAST('
USE [' AS nvarchar(max)) + CAST(@databaseName AS nvarchar(max)) + CAST(']
SET NOCOUNT ON;
' + CAST(@cmdResumeRebuildForIndex as nvarchar(max)) + '
' AS nvarchar(max));
EXECUTE sp_executesql @cmdResumeRebuildForIndex;
SET @FinishDate = GetDate();
-- Устанавливаем фактическую дату завершения операции
IF(@useMonitoringDatabase = 1)
BEGIN
EXECUTE [dbo].[sp_set_maintenance_action_log_finish_date]
@MaintenanceActionLogId,
@FinishDate;
END
END TRY
BEGIN CATCH
IF(@MaintenanceActionLogId <> 0)
BEGIN
SET @msg = 'Error: ' + CAST(Error_message() AS NVARCHAR(500)) + ', Code: ' + CAST(Error_Number() AS NVARCHAR(500)) + ', Line: ' + CAST(Error_Line() AS NVARCHAR(500))
-- Устанавливаем текст ошибки при обслуживании индекса
-- Дата завершения при этом остается незаполненной
EXECUTE [dbo].[sp_set_maintenance_action_log_finish_date]
@MaintenanceActionLogId,
@FinishDate,
@msg;
END
END CATCH
FETCH NEXT FROM resumableIndexRebuild_cursor
INTO @objectNameResumeRebuildForIndex, @indexNameResumeRebuildForIndex, @cmdResumeRebuildForIndex;
END
CLOSE resumableIndexRebuild_cursor;
DEALLOCATE resumableIndexRebuild_cursor;
END
-- Сохраняем список индексов, для которых имеются ожидающие операции перестроения
-- Они будут исключены из основного обслуживания
SET @excludeIndexes = (SELECT
[name]
FROM @LOCAL_ResumableIndexRebuilds
FOR XML RAW, ROOT('root'));
--PRINT 'Прервано для отладки'
--RETURN 0;
DECLARE @cmd nvarchar(max);
SET @cmd =
CAST('USE [' AS nvarchar(max)) + CAST(@databasename AS nvarchar(max)) + CAST(']
SET NOCOUNT ON;
DECLARE
-- Текущее время
@timeNow TIME = CAST(GETDATE() AS TIME),
-- Текущий процент использования файла лога транзакций
@currentTransactionLogSizeUsagePercent int,
@currentTransactionLogSizeMB bigint;
-- Проверка доступен ли запуск обслуживания в текущее время
IF (@timeTo >= @timeFrom) BEGIN
IF(NOT (@timeFrom <= @timeNow AND @timeTo >= @timeNow))
RETURN;
END ELSE BEGIN
IF(NOT ((@timeFrom <= @timeNow AND ''23:59:59'' >= @timeNow)
OR (@timeTo >= @timeNow AND ''00:00:00'' <= @timeNow)))
RETURN;
END
-- Служебные переменные
DECLARE
@DBID SMALLINT = DB_ID()
,@DBNAME sysname = DB_NAME()
,@SchemaName SYSNAME
,@ObjectName SYSNAME
,@ObjectID INT
,@Priority INT
,@IndexID INT
,@IndexName SYSNAME
,@PartitionNum BIGINT
,@PartitionCount BIGINT
,@frag FLOAT
,@Command NVARCHAR(max)
,@CommandSpecial NVARCHAR(max)
,@Operation NVARCHAR(128)
,@RowModCtr BIGINT
,@AvgFragmentationPercent float
,@PageCount BIGINT
,@SQL nvarchar(max)
,@SQLSpecial nvarchar(max)
,@OnlineRebuildSupport int
,@UseOnlineRebuild int
,@StartDate datetime
,@FinishDate datetime
,@RunDate datetime = GETDATE()
,@MaintenanceActionLogId bigint;
IF OBJECT_ID(''tempdb..#MaintenanceCommands'') IS NOT NULL
DROP TABLE #MaintenanceCommands;
IF OBJECT_ID(''tempdb..#MaintenanceCommandsTemp'') IS NOT NULL
DROP TABLE #MaintenanceCommandsTemp;
CREATE TABLE #MaintenanceCommands
(
[Command] nvarchar(max),
[CommandSpecial] nvarchar(max),
[Table] nvarchar(250),
[Object] nvarchar(250),
[page_count] BIGINT,
[Rowmodctr] BIGINT,
[Avg_fragmentation_in_percent] INT,
[Operation] nvarchar(max),
[Priority] INT,
[OnlineRebuildSupport] INT,
[UseOnlineRebuild] INT,
[PartitionCount] BIGINT
)
IF OBJECT_ID(''tempdb..#tranLogInfo'') IS NOT NULL
DROP TABLE #tranLogInfo;
CREATE TABLE #tranLogInfo
(
servername varchar(250) not null default @@servername,
dbname varchar(250),
logsize real,
logspace real,
stat int
)
DECLARE @usedCacheAboutObjectsState bit = 0;
IF @usePreparedInformationAboutObjectsStateIfExists = 1
AND EXISTS(SELECT *
FROM [' AS nvarchar(max)) + CAST(@monitoringDatabaseName AS nvarchar(max)) + CAST('].[dbo].[DatabaseObjectsState]
WHERE [DatabaseName] = @databaseName
-- Информация должна быть собрана в рамках 12 часов от текущего запуска
AND [Period] BETWEEN DATEADD(hour, -12, @RunDate) AND DATEADD(hour, 12, @RunDate))
BEGIN
-- Получаем информацию через подготовленный сбор
SET @usedCacheAboutObjectsState = 1;
SELECT
OBJECT_ID(dt.[TableName]) AS [objectid]
,ind.index_id as [indexid]
,1 AS [partitionnum]
,[AvgFragmentationPercent] AS [frag]
,[PageCount] AS [page_count]
,[Rowmodctr] AS [rowmodctr]
,ISNULL(prt.[Priority], 999) AS [Priority]
,ISNULL(prt.[Exclude], 0) AS Exclude
,dt.[OnlineRebuildSupport] AS [OnlineRebuildSupport]
,dt.[PartitionCount] AS [PartitionCount]
INTO #MaintenanceCommandsTempCached
FROM [' AS nvarchar(max)) + CAST(@monitoringDatabaseName AS nvarchar(max)) + CAST('].[dbo].[DatabaseObjectsState] dt
LEFT JOIN sys.indexes ind
ON OBJECT_ID(dt.[TableName]) = ind.object_id
AND dt.[Object] = ind.[name]
LEFT JOIN [' AS nvarchar(max)) + CAST(@monitoringDatabaseName AS nvarchar(max)) + CAST('].[dbo].[MaintenanceIndexPriority] AS [prt]
ON dt.DatabaseName = prt.[DatabaseName]
AND dt.TableName = prt.TableName
AND dt.[Object] = prt.Indexname
WHERE dt.[DatabaseName] = @databaseName
AND [Period] BETWEEN DATEADD(hour, -12, @RunDate) AND DATEADD(hour, 12, @RunDate)
-- Записи от последнего получения данных за прошедшие 12 часов
AND [Period] IN (
SELECT MAX([Period])
FROM [' AS nvarchar(max)) + CAST(@monitoringDatabaseName AS nvarchar(max)) + CAST('].[dbo].[DatabaseObjectsState]
WHERE [DatabaseName] = @databaseName
AND dt.[Period] BETWEEN DATEADD(hour, -12, @RunDate) AND DATEADD(hour, 12, @RunDate))
AND [AvgFragmentationPercent] > @fragmentationPercentMinForMaintenance
AND [PageCount] > 25 -- игнорируем небольшие таблицы
-- Фильтр по мин. размеру индекса
AND (@minIndexSizePages = 0 OR [PageCount] >= @minIndexSizePages)
-- Фильтр по макс. размеру индекса
AND (@maxIndexSizePages = 0 OR [PageCount] <= @maxIndexSizePages)
-- Убираем обработку индексов, исключенных из обслуживания
AND ISNULL(prt.[Exclude], 0) = 0
-- Отбор по имени таблцы
AND dt.[TableName] ' AS nvarchar(max)) + CAST(@ConditionTableName AS nvarchar(max)) + CAST('
AND dt.[Object] ' AS nvarchar(max)) + CAST(@ConditionIndexName AS nvarchar(max)) + CAST('
AND NOT dt.[Object] IN (
SELECT
XC.value(''@name'', ''nvarchar(255)'') AS [IndexName]
FROM @excludeIndexes.nodes(''/root/row'') AS XT(XC)
)
END ELSE
BEGIN
-- Получаем информацию через анализ базы данных
SELECT
dt.[object_id] AS [objectid],
dt.index_id AS [indexid],
[partition_number] AS [partitionnum],
MAX([avg_fragmentation_in_percent]) AS [frag],
MAX(CAST([page_count] AS BIGINT)) AS [page_count],
SUM(CAST([si].[rowmodctr] AS BIGINT)) AS [rowmodctr],
MAX(
ISNULL(prt.[Priority], 999)
) AS [Priority],
MAX(
CAST(ISNULL(prt.[Exclude], 0) AS INT)
) AS [Exclude],
MIN(CASE WHEN objBadTypes.IndexObjectId IS NULL THEN 1 ELSE 0 END) AS [OnlineRebuildSupport],
MAX(p_count.[PartitionCount]) AS [PartitionCount]
INTO #MaintenanceCommandsTemp
FROM
sys.dm_db_index_physical_stats (
DB_ID(),
NULL,
NULL,
NULL,
N''LIMITED''
) dt
LEFT JOIN sys.sysindexes si ON dt.object_id = si.id
LEFT JOIN (
SELECT
t.object_id AS [TableObjectId],
ind.index_id AS [IndexObjectId]
FROM
sys.indexes ind
INNER JOIN sys.index_columns ic ON ind.object_id = ic.object_id
and ind.index_id = ic.index_id
INNER JOIN sys.columns col ON ic.object_id = col.object_id
and ic.column_id = col.column_id
INNER JOIN sys.tables t ON ind.object_id = t.object_id
LEFT JOIN INFORMATION_SCHEMA.COLUMNS tbsc ON t.schema_id = SCHEMA_ID(tbsc.TABLE_SCHEMA)
AND t.name = tbsc.TABLE_NAME
LEFT JOIN sys.types tps ON col.system_type_id = tps.system_type_id
AND col.user_type_id = tps.user_type_id
WHERE
t.is_ms_shipped = 0
AND CASE WHEN ind.type_desc = ''CLUSTERED'' THEN CASE WHEN tbsc.DATA_TYPE IN (
''text'', ''ntext'', ''image'', ''FILESTREAM''
) THEN 1 ELSE 0 END ELSE CASE WHEN tps.[name] IN (
''text'', ''ntext'', ''image'', ''FILESTREAM''
) THEN 1 ELSE 0 END END > 0
GROUP BY
t.object_id,
ind.index_id
) AS objBadTypes ON objBadTypes.TableObjectId = dt.object_id
AND objBadTypes.IndexObjectId = dt.index_id
LEFT JOIN (
SELECT
i.[object_id],
i.[index_id],
os.[Priority] AS [Priority],
os.[Exclude] AS [Exclude]
FROM sys.indexes i
left join [' AS nvarchar(max)) + CAST(@monitoringDatabaseName AS nvarchar(max)) + CAST('].[dbo].[MaintenanceIndexPriority] os
ON i.object_id = OBJECT_ID(os.TableName)
AND i.Name = os.IndexName
WHERE os.Id IS NOT NULL
and os.DatabaseName = ''' AS nvarchar(max)) + CAST(@databaseName AS nvarchar(max)) + CAST('''
) prt ON si.id = prt.[object_id]
AND dt.[index_id] = prt.[index_id]
LEFT JOIN (
SELECT
object_id,
index_id,
COUNT(DISTINCT partition_number) AS [PartitionCount]
FROM sys.partitions p
GROUP BY object_id, index_id
) p_count
ON dt.object_id = p_count.object_id AND dt.index_id = p_count.index_id
WHERE
[rowmodctr] IS NOT NULL -- Исключаем служебные объекты, по которым нет изменений
AND [avg_fragmentation_in_percent] > @fragmentationPercentMinForMaintenance
AND dt.[index_id] > 0 -- игнорируем кучи (heap)
AND [page_count] > 25 -- игнорируем небольшие таблицы
-- Фильтр по мин. размеру индекса
AND (@minIndexSizePages = 0 OR [page_count] >= @minIndexSizePages)
-- Фильтр по макс. размеру индекса
AND (@maxIndexSizePages = 0 OR [page_count] <= @maxIndexSizePages)
-- Убираем обработку индексов, исключенных из обслуживания
AND ISNULL(prt.[Exclude], 0) = 0
-- Отбор по имени таблцы
AND OBJECT_NAME(dt.[object_id]) ' AS nvarchar(max)) + CAST(@ConditionTableName AS nvarchar(max)) + CAST('
AND si.[name] ' AS nvarchar(max)) + CAST(@ConditionIndexName AS nvarchar(max)) + CAST('
AND NOT si.[name] IN (
SELECT
XC.value(''@name'', ''nvarchar(255)'') AS [IndexName]
FROM @excludeIndexes.nodes(''/root/row'') AS XT(XC)
)
GROUP BY
dt.[object_id],
dt.[index_id],
[partition_number];
END
IF(@usedCacheAboutObjectsState = 1)
BEGIN
DECLARE partitions CURSOR FOR
SELECT [objectid], [indexid], [partitionnum], [frag], [page_count], [rowmodctr], [Priority], [OnlineRebuildSupport], [PartitionCount]
FROM #MaintenanceCommandsTempCached;
END ELSE
BEGIN
DECLARE partitions CURSOR FOR
SELECT [objectid], [indexid], [partitionnum], [frag], [page_count], [rowmodctr], [Priority], [OnlineRebuildSupport], [PartitionCount]
FROM #MaintenanceCommandsTemp;
END
OPEN partitions;
WHILE (1=1)
BEGIN
FETCH NEXT FROM partitions INTO @ObjectID, @IndexID, @PartitionNum, @frag, @PageCount, @RowModCtr, @Priority, @OnlineRebuildSupport, @PartitionCount;
IF @@FETCH_STATUS < 0 BREAK;
SELECT @ObjectName = QUOTENAME([o].[name]), @SchemaName = QUOTENAME([s].[name])
FROM sys.objects AS o
JOIN sys.schemas AS s ON [s].[schema_id] = [o].[schema_id]
WHERE [o].[object_id] = @ObjectID;
SELECT @IndexName = QUOTENAME(name)
FROM sys.indexes
WHERE [object_id] = @ObjectID AND [index_id] = @IndexID;
SET @CommandSpecial = '''';
SET @Command = '''';
-- Реорганизация индекса
IF @Priority > 10 -- Приоритет обслуживания не большой
AND @frag <= @fragmentationPercentForRebuild -- Процент фрагментации небольшой
AND (@maxIndexSizeForReorganizingPages = 0 OR @PageCount <= @maxIndexSizeForReorganizingPages) BEGIN -- Таблица меньше 50 ГБ
SET @Command = N''ALTER INDEX '' + @IndexName + N'' ON '' + @SchemaName + N''.'' + @ObjectName + N'' REORGANIZE'';
SET @Operation = ''REORGANIZE INDEX''
END ELSE IF(@useOnlineIndexRebuild = 0) -- Не использовать онлайн-перестроение
BEGIN
SET @Command = N''ALTER INDEX '' + @IndexName + N'' ON '' + @SchemaName + N''.'' + @ObjectName
+ N'' REBUILD WITH (MAXDOP='' + CAST(@MaxDop AS nvarchar(10)) + '')'';
SET @Operation = ''REBUILD INDEX''
END ELSE IF (@useOnlineIndexRebuild = 1 AND @OnlineRebuildSupport = 1) -- Только с поддержкой онлайн перестроения
BEGIN
SET @CommandSpecial = N''ALTER INDEX '' + @IndexName + N'' ON '' + @SchemaName + N''.'' + @ObjectName
+ N'' REBUILD WITH (MAXDOP='' + CAST(@MaxDop AS nvarchar(10)) + '',''
+ (CASE WHEN @useResumableIndexRebuild > 0 THEN '' RESUMABLE = ON, '' ELSE '''' END)
+ '' ONLINE = ON (WAIT_AT_LOW_PRIORITY ( MAX_DURATION = ' AS nvarchar(max)) + CAST(@onlineRebuildWaitMinutes AS nvarchar(max)) + CAST(' MINUTES, ABORT_AFTER_WAIT = ' AS nvarchar(max)) + CAST(@abortAfterWaitOnlineRebuil AS nvarchar(max)) + CAST(')))'';
SET @Operation = ''REBUILD INDEX''
END ELSE IF(@useOnlineIndexRebuild = 2 AND @OnlineRebuildSupport = 0) -- Только без поддержки
BEGIN
SET @Command = N''ALTER INDEX '' + @IndexName + N'' ON '' + @SchemaName + N''.'' + @ObjectName
+ N'' REBUILD WITH (MAXDOP='' + CAST(@MaxDop AS nvarchar(10)) + '')'';
SET @Operation = ''REBUILD INDEX''
END ELSE IF(@useOnlineIndexRebuild = 3) -- Использовать онлайн перестроение где возможно
BEGIN
if(@OnlineRebuildSupport = 1)
BEGIN
SET @CommandSpecial = N''ALTER INDEX '' + @IndexName + N'' ON '' + @SchemaName + N''.'' + @ObjectName
+ N'' REBUILD WITH (MAXDOP='' + CAST(@MaxDop AS nvarchar(10)) + '',ONLINE = ON (WAIT_AT_LOW_PRIORITY ( MAX_DURATION = ' AS nvarchar(max)) + CAST(@onlineRebuildWaitMinutes AS nvarchar(max)) + CAST(' MINUTES, ABORT_AFTER_WAIT = ' AS nvarchar(max)) + CAST(@abortAfterWaitOnlineRebuil AS nvarchar(max)) + CAST(')))'';
END ELSE
BEGIN
SET @Command = N''ALTER INDEX '' + @IndexName + N'' ON '' + @SchemaName + N''.'' + @ObjectName
+ N'' REBUILD WITH (MAXDOP='' + CAST(@MaxDop AS nvarchar(10)) + '')'';
END
SET @Operation = ''REBUILD INDEX''
END
IF (@PartitionCount > 1 AND @Command <> '''')
SET @Command = @Command + N'' PARTITION='' + CAST(@PartitionNum AS nvarchar(10));
SET @Command = LTRIM(RTRIM(@Command));
SET @CommandSpecial = LTRIM(RTRIM(@CommandSpecial));
IF(LEN(@Command) > 0 OR LEN(@CommandSpecial) > 0)
BEGIN
INSERT #MaintenanceCommands
([Command], [CommandSpecial], [Table], [Object], [Rowmodctr], [Avg_fragmentation_in_percent], [Operation], [Priority], [OnlineRebuildSupport])
VALUES
(@Command, @CommandSpecial, @ObjectName, @IndexName, @RowModCtr, @frag, @Operation, @Priority, @OnlineRebuildSupport);
END
END
CLOSE partitions;
DEALLOCATE partitions;
DECLARE todo CURSOR FOR
SELECT
[Command],
[CommandSpecial],
[Table],
[Object],
[Operation],
[OnlineRebuildSupport],
[Rowmodctr],
[Avg_fragmentation_in_percent]
FROM #MaintenanceCommands
ORDER BY
[Priority],
[Rowmodctr] DESC,
[Avg_fragmentation_in_percent] DESC
OPEN todo;
WHILE 1=1
BEGIN
FETCH NEXT FROM todo INTO @SQL, @SQLSpecial, @ObjectName, @IndexName, @Operation, @OnlineRebuildSupport, @RowModCtr, @AvgFragmentationPercent;
IF @@FETCH_STATUS != 0
BREAK;
-- Проверка доступен ли запуск обслуживания в текущее время
SET @timeNow = CAST(GETDATE() AS TIME);
IF (@timeTo >= @timeFrom) BEGIN
IF(NOT (@timeFrom <= @timeNow AND @timeTo >= @timeNow))
RETURN;
END ELSE BEGIN
IF(NOT ((@timeFrom <= @timeNow AND ''23:59:59'' >= @timeNow)
OR (@timeTo >= @timeNow AND ''00:00:00'' <= @timeNow)))
RETURN;
END
-- Проверка процента занятого места в логе транзакций
TRUNCATE TABLE #tranLogInfo;
INSERT INTO #tranLogInfo (dbname,logsize,logspace,stat) exec(''dbcc sqlperf(logspace)'');
SELECT
@currentTransactionLogSizeUsagePercent = logspace,
@currentTransactionLogSizeMB = logsize * (logspace / 100)
FROM #tranLogInfo WHERE dbname = @databaseName
IF(@currentTransactionLogSizeUsagePercent >= @maxTransactionLogSizeUsagePercent)
BEGIN
-- Процент занятого места в файлах лога транзакций превышает указанный порог
RETURN;
END
IF(@maxTransactionLogSizeMB > 0 AND @currentTransactionLogSizeMB > @maxTransactionLogSizeMB)
BEGIN
-- Размер занятого места в файлах лога транзакций превышает указанный порог в МБ
RETURN;
END
SET @StartDate = GetDate();
BEGIN TRY
DECLARE @currentSQL nvarchar(max) = ''''
SET @MaintenanceActionLogId = 0
IF(@SQLSpecial = '''')
BEGIN
SET @currentSQL = @SQL
SET @UseOnlineRebuild = 0;
END ELSE
BEGIN
SET @UseOnlineRebuild = 1;
SET @currentSQL = @SQLSpecial
END
-- Сохраняем предварительную информацию об операции обслуживания без даты завершения
IF(@useMonitoringDatabase = 1)
BEGIN
EXECUTE [' AS nvarchar(max)) + CAST(@monitoringDatabaseName AS nvarchar(max)) + CAST('].[dbo].[sp_add_maintenance_action_log]
@ObjectName
,@IndexName
,@Operation
,@RunDate
,@StartDate
,null
,@DBNAME
,@UseOnlineRebuild
,''''
,@AvgFragmentationPercent
,@RowModCtr
,@currentSQL
,@MaintenanceActionLogId OUTPUT;
END
EXEC sp_executesql @currentSQL;
SET @FinishDate = GetDate();
-- Устанавливаем фактическую дату завершения операции
IF(@useMonitoringDatabase = 1)
BEGIN
EXECUTE [' AS nvarchar(max)) + CAST(@monitoringDatabaseName AS nvarchar(max)) + CAST('].[dbo].[sp_set_maintenance_action_log_finish_date]
@MaintenanceActionLogId,
@FinishDate;
END
END TRY
BEGIN CATCH
IF(@MaintenanceActionLogId <> 0)
BEGIN
DECLARE @msg nvarchar(500) = ''Error: '' + CAST(Error_message() AS NVARCHAR(500)) + '', Code: '' + CAST(Error_Number() AS NVARCHAR(500)) + '', Line: '' + CAST(Error_Line() AS NVARCHAR(500))
-- Устанавливаем текст ошибки при обслуживании индекса
-- Дата завершения при этом остается незаполненной
EXECUTE [' AS nvarchar(max)) + CAST(@monitoringDatabaseName AS nvarchar(max)) + CAST('].[dbo].[sp_set_maintenance_action_log_finish_date]
@MaintenanceActionLogId,
@FinishDate,
@msg;
END
END CATCH
END
CLOSE todo;
DEALLOCATE todo;
IF OBJECT_ID(''tempdb..#MaintenanceCommands'') IS NOT NULL
DROP TABLE #MaintenanceCommands;
IF OBJECT_ID(''tempdb..#MaintenanceCommandsTemp'') IS NOT NULL
DROP TABLE #MaintenanceCommandsTemp;
' AS nvarchar(max))
-- Для отладки. Выводит в SSMS весь текст сформированной команды
--exec [dbo].[sp_AdvancedPrint] @sql = @cmd
EXECUTE sp_executesql
@cmd,
N'@timeFrom TIME, @timeTo TIME, @fragmentationPercentForRebuild FLOAT,
@fragmentationPercentMinForMaintenance FLOAT, @maxDop int,
@minIndexSizePages int, @maxIndexSizePages int, @useOnlineIndexRebuild int,
@maxIndexSizeForReorganizingPages int,
@useMonitoringDatabase bit, @monitoringDatabaseName sysname, @usePreparedInformationAboutObjectsStateIfExists bit,
@databaseName sysname, @maxTransactionLogSizeUsagePercent int, @maxTransactionLogSizeMB bigint, @useResumableIndexRebuild bit,
@excludeIndexes XML',
@timeFrom, @timeTo, @fragmentationPercentForRebuild,
@fragmentationPercentMinForMaintenance, @maxDop,
@minIndexSizePages, @maxIndexSizePages, @useOnlineIndexRebuild,
@maxIndexSizeForReorganizingPages,
@useMonitoringDatabase, @monitoringDatabaseName, @usePreparedInformationAboutObjectsStateIfExists,
@databaseName, @maxTransactionLogSizeUsagePercent, @maxTransactionLogSizeMB, @useResumableIndexRebuild,
@excludeIndexes;
RETURN 0
END
GO
CREATE PROCEDURE [dbo].[sp_SaveDatabasesTablesStatistic]
AS
BEGIN
SET NOCOUNT ON;
SET QUOTED_IDENTIFIER ON;
IF OBJECT_ID('tempdb..#tableSizeResult') IS NOT NULL
DROP TABLE #tableSizeResult;
DECLARE @sql nvarchar(max);
SET @sql = '
SELECT
DB_NAME() AS [databaseName],
a3.name AS [schemaname],
a2.name AS [tablename],
a1.rows as row_count,
(a1.reserved + ISNULL(a4.reserved,0))* 8 AS [reserved],
a1.data * 8 AS [data],
(CASE WHEN (a1.used + ISNULL(a4.used,0)) > a1.data THEN (a1.used + ISNULL(a4.used,0)) - a1.data ELSE 0 END) * 8 AS [index_size],
(CASE WHEN (a1.reserved + ISNULL(a4.reserved,0)) > a1.used THEN (a1.reserved + ISNULL(a4.reserved,0)) - a1.used ELSE 0 END) * 8 AS [unused]
FROM
(SELECT
ps.object_id,
SUM (
CASE
WHEN (ps.index_id < 2) THEN row_count
ELSE 0
END
) AS [rows],
SUM (ps.reserved_page_count) AS reserved,
SUM (
CASE
WHEN (ps.index_id < 2) THEN (ps.in_row_data_page_count + ps.lob_used_page_count + ps.row_overflow_used_page_count)
ELSE (ps.lob_used_page_count + ps.row_overflow_used_page_count)
END
) AS data,
SUM (ps.used_page_count) AS used
FROM sys.dm_db_partition_stats ps
GROUP BY ps.object_id) AS a1
LEFT OUTER JOIN
(SELECT
it.parent_id,
SUM(ps.reserved_page_count) AS reserved,
SUM(ps.used_page_count) AS used
FROM sys.dm_db_partition_stats ps
INNER JOIN sys.internal_tables it ON (it.object_id = ps.object_id)
WHERE it.internal_type IN (202,204)
GROUP BY it.parent_id) AS a4 ON (a4.parent_id = a1.object_id)
INNER JOIN sys.all_objects a2 ON ( a1.object_id = a2.object_id )
INNER JOIN sys.schemas a3 ON (a2.schema_id = a3.schema_id)
WHERE a2.type <> N''S'' and a2.type <> N''IT''
ORDER BY reserved DESC
';
CREATE TABLE #tableSizeResult (
[DatabaseName] [nvarchar](255),
[SchemaName] [nvarchar](255),
[TableName] [nvarchar](255),
[RowCnt] bigint,
[Reserved] bigint,
[Data] bigint,
[IndexSize] bigint,
[Unused] bigint
);
DECLARE @statement nvarchar(max);
SET @statement = (
SELECT 'EXEC ' + QUOTENAME(name) + '.sys.sp_executesql @sql; '
FROM sys.databases
WHERE NOT DATABASEPROPERTYEX(name, 'UserAccess') = 'SINGLE_USER'
AND HAS_DBACCESS(name) = 1
AND state_desc = 'ONLINE'
AND NOT database_id IN (
DB_ID('tempdb'),
DB_ID('master'),
DB_ID('model'),
DB_ID('msdb')
)
FOR XML PATH(''), TYPE
).value('.','nvarchar(max)');
PRINT @statement
INSERT #tableSizeResult
EXEC sp_executesql @statement, N'@sql nvarchar(max)', @sql;
DECLARE todo CURSOR FOR
SELECT
[DatabaseName],
[SchemaName],
[TableName],
[RowCnt],
[Reserved],
[Data],
[IndexSize],
[Unused]
FROM #tableSizeResult;
DECLARE
@DatabaseName nvarchar(255),
@SchemaName nvarchar(5),
@TableName nvarchar(255),
@RowCnt bigint,
@Reserved bigint,
@Data bigint,
@IndexSize bigint,
@Unused bigint,
@currentDate datetime2(7);
OPEN todo;
WHILE 1=1
BEGIN
FETCH NEXT FROM todo INTO @DatabaseName, @SchemaName, @TableName, @RowCnt, @Reserved, @Data, @IndexSize, @Unused;
IF @@FETCH_STATUS != 0
BREAK;
SET @currentDate = GETDATE();
INSERT INTO [dbo].[DatabasesTablesStatistic]
(
[Period],
[DatabaseName],
[SchemaName],
[TableName],
[RowCnt],
[Reserved],
[Data],
[IndexSize],
[Unused]
) VALUES
(
@currentDate,
@DatabaseName,
@SchemaName,
@TableName,
@RowCnt,
@Reserved,
@Data,
@IndexSize,
@Unused
);
END
CLOSE todo;
DEALLOCATE todo;
IF OBJECT_ID('tempdb..#tableSizeResult') IS NOT NULL
DROP TABLE #tableSizeResult;
END
GO
CREATE PROCEDURE [dbo].[sp_set_maintenance_action_log_finish_date]
@MaintenanceActionLogId bigint,
@FinishDate datetime2(0),
@Comment nvarchar(255) = ''
AS
BEGIN
SET NOCOUNT ON;
UPDATE [dbo].[MaintenanceActionsLog]
SET FinishDate = @FinishDate,
Comment = @Comment
WHERE Id = @MaintenanceActionLogId
RETURN 0
END
GO
CREATE PROCEDURE [dbo].[sp_StatisticMaintenance]
@databaseName sysname,
@timeFrom TIME = '00:00:00',
@timeTo TIME = '23:59:59',
@mode int = 0,
@ConditionTableName nvarchar(max) = 'LIKE ''%''',
@useMonitoringDatabase bit = 1,
@monitoringDatabaseName sysname = 'SQLServerMaintenance'
AS
BEGIN
SET NOCOUNT ON;
IF(@mode = 0)
BEGIN
EXECUTE [dbo].[sp_StatisticMaintenance_Sampled]
@databaseName
,@timeFrom
,@timeTo
,@ConditionTableName
,@useMonitoringDatabase
,@monitoringDatabaseName
END ELSE IF(@mode = 1)
BEGIN
EXECUTE [dbo].[sp_StatisticMaintenance_Detailed]
@databaseName
,@timeFrom
,@timeTo
,@ConditionTableName
,@useMonitoringDatabase
,@monitoringDatabaseName
END
RETURN 0
END
GO
CREATE PROCEDURE [dbo].[sp_StatisticMaintenance_Detailed]
@databaseName sysname,
@timeFrom TIME = '00:00:00',
@timeTo TIME = '23:59:59',
@ConditionTableName nvarchar(max) = 'LIKE ''%''',
@useMonitoringDatabase bit = 1,
@monitoringDatabaseName sysname = 'SQLServerMaintenance'
AS
BEGIN
SET NOCOUNT ON;
DECLARE @msg nvarchar(max);
IF DB_ID(@databaseName) IS NULL
BEGIN
SET @msg = 'Database ' + @databaseName + ' is not exists.';
THROW 51000, @msg, 1;
RETURN -1;
END
DECLARE @cmd nvarchar(max);
SET @cmd =
CAST('USE [' AS nvarchar(max)) + CAST(@databasename AS nvarchar(max)) + CAST(']
SET NOCOUNT ON;
DECLARE
-- Текущее время
@timeNow TIME = CAST(GETDATE() AS TIME)
-- Начало доступного интервала времени обслуживания
-- @timeFrom TIME
-- Окончание доступного интервала времени обслуживания
-- @timeTo TIME
-- Проверка доступен ли запуск обслуживания в текущее время
IF (@timeTo >= @timeFrom) BEGIN
IF(NOT (@timeFrom <= @timeNow AND @timeTo >= @timeNow))
RETURN;
END ELSE BEGIN
IF(NOT ((@timeFrom <= @timeNow AND ''23:59:59'' >= @timeNow)
OR (@timeTo >= @timeNow AND ''00:00:00'' <= @timeNow)))
RETURN;
END
-- Служебные переменные
DECLARE
@DBID SMALLINT = DB_ID()
,@DBNAME sysname = DB_NAME()
,@TableName SYSNAME
,@IndexName SYSNAME
,@Operation NVARCHAR(128) = ''UPDATE STATISTICS''
,@RunDate DATETIME = GETDATE()
,@StartDate DATETIME
,@FinishDate DATETIME
,@SQL NVARCHAR(500)
,@RowModCtr BIGINT
,@MaintenanceActionLogId bigint;
DECLARE todo CURSOR FOR
SELECT
''
UPDATE STATISTICS ['' + SCHEMA_NAME([o].[schema_id]) + ''].['' + [o].[name] + ''] ['' + [s].[name] + '']
WITH FULLSCAN'' + CASE WHEN [s].[no_recompute] = 1 THEN '', NORECOMPUTE'' ELSE '''' END + '';''
, [o].[name]
, [s].[name] AS [stat_name],
[rowmodctr]
FROM (
SELECT
[object_id]
,[name]
,[stats_id]
,[no_recompute]
,[last_update] = STATS_DATE([object_id], [stats_id])
,[auto_created]
FROM sys.stats WITH(NOLOCK)
WHERE [is_temporary] = 0) s
LEFT JOIN sys.objects o WITH(NOLOCK)
ON [s].[object_id] = [o].[object_id]
LEFT JOIN (
SELECT
[p].[object_id]
,[p].[index_id]
,[total_pages] = SUM([a].[total_pages])
FROM sys.partitions p WITH(NOLOCK)
JOIN sys.allocation_units a WITH(NOLOCK) ON [p].[partition_id] = [a].[container_id]
GROUP BY
[p].[object_id]
,[p].[index_id]) p
ON [o].[object_id] = [p].[object_id] AND [p].[index_id] = [s].[stats_id]
LEFT JOIN sys.sysindexes si
ON [si].[id] = [s].[object_id] AND [si].[indid] = [s].[stats_id]
WHERE [o].[type] IN (''U'', ''V'')
AND [o].[is_ms_shipped] = 0
AND [rowmodctr] > 0
AND [o].[name] ' AS nvarchar(max)) + CAST(@ConditionTableName AS nvarchar(max)) + CAST('
ORDER BY [rowmodctr] DESC;
OPEN todo;
WHILE 1=1
BEGIN
FETCH NEXT FROM todo INTO @SQL, @TableName, @IndexName, @RowModCtr;
IF @@FETCH_STATUS != 0
BREAK;
-- Проверка доступен ли запуск обслуживания в текущее время
SET @timeNow = CAST(GETDATE() AS TIME);
IF (@timeTo >= @timeFrom) BEGIN
IF(NOT (@timeFrom <= @timeNow AND @timeTo >= @timeNow))
RETURN;
END ELSE BEGIN
IF(NOT ((@timeFrom <= @timeNow AND ''23:59:59'' >= @timeNow)
OR (@timeTo >= @timeNow AND ''00:00:00'' <= @timeNow)))
RETURN;
END
SET @StartDate = GetDate();
BEGIN TRY
-- Сохраняем предварительную информацию об операции обслуживания без даты завершения
IF(@useMonitoringDatabase = 1)
BEGIN
EXECUTE [' AS nvarchar(max)) + CAST(@monitoringDatabaseName AS nvarchar(max)) + CAST('].[dbo].[sp_add_maintenance_action_log]
@TableName
,@IndexName
,@Operation
,@RunDate
,@StartDate
,null
,@DBNAME
,0
,''''
,0
,@RowModCtr
,@SQL
,@MaintenanceActionLogId OUTPUT;
END
EXEC sp_executesql @SQL;
SET @FinishDate = GetDate();
-- Устанавливаем фактическую дату завершения операции
IF(@useMonitoringDatabase = 1)
BEGIN
EXECUTE [' AS nvarchar(max)) + CAST(@monitoringDatabaseName AS nvarchar(max)) + CAST('].[dbo].[sp_set_maintenance_action_log_finish_date]
@MaintenanceActionLogId,
@FinishDate;
END
END TRY
BEGIN CATCH
IF(@MaintenanceActionLogId <> 0)
BEGIN
DECLARE @msg nvarchar(500) = ''Error: '' + CAST(Error_message() AS NVARCHAR(500)) + '', Code: '' + CAST(Error_Number() AS NVARCHAR(500)) + '', Line: '' + CAST(Error_Line() AS NVARCHAR(500))
-- Устанавливаем текст ошибки при обслуживании объекта статистики
-- Дата завершения при этом остается незаполненной
EXECUTE [' AS nvarchar(max)) + CAST(@monitoringDatabaseName AS nvarchar(max)) + CAST('].[dbo].[sp_set_maintenance_action_log_finish_date]
@MaintenanceActionLogId,
@FinishDate,
@msg;
END
END CATCH
END
CLOSE todo;
DEALLOCATE todo;
' AS nvarchar(max))
EXECUTE sp_executesql
@cmd,
N'@timeFrom TIME, @timeTo TIME,
@useMonitoringDatabase bit, @monitoringDatabaseName sysname',
@timeFrom, @timeTo,
@useMonitoringDatabase, @monitoringDatabaseName;
RETURN 0
END
GO
CREATE PROCEDURE [dbo].[sp_StatisticMaintenance_Sampled]
@databaseName sysname,
@timeFrom TIME = '00:00:00',
@timeTo TIME = '23:59:59',
@ConditionTableName nvarchar(max) = 'LIKE ''%''',
@useMonitoringDatabase bit = 1,
@monitoringDatabaseName sysname = 'SQLServerMaintenance'
AS
BEGIN
SET NOCOUNT ON;
DECLARE @msg nvarchar(max);
IF DB_ID(@databaseName) IS NULL
BEGIN
SET @msg = 'Database ' + @databaseName + ' is not exists.';
THROW 51000, @msg, 1;
RETURN -1;
END
DECLARE @cmd nvarchar(max);
SET @cmd =
CAST('USE [' AS nvarchar(max)) + CAST(@databasename AS nvarchar(max)) + CAST(']
SET NOCOUNT ON;
DECLARE
-- Текущее время
@timeNow TIME = CAST(GETDATE() AS TIME)
-- Начало доступного интервала времени обслуживания
-- @timeFrom TIME
-- Окончание доступного интервала времени обслуживания
-- @timeTo TIME
-- Проверка доступен ли запуск обслуживания в текущее время
IF (@timeTo >= @timeFrom) BEGIN
IF(NOT (@timeFrom <= @timeNow AND @timeTo >= @timeNow))
RETURN;
END ELSE BEGIN
IF(NOT ((@timeFrom <= @timeNow AND ''23:59:59'' >= @timeNow)
OR (@timeTo >= @timeNow AND ''00:00:00'' <= @timeNow)))
RETURN;
END
-- Служебные переменные
DECLARE
@DBID SMALLINT = DB_ID()
,@DBNAME sysname = DB_NAME()
,@TableName SYSNAME
,@IndexName SYSNAME
,@Operation NVARCHAR(128) = ''UPDATE STATISTICS''
,@RunDate DATETIME = GETDATE()
,@StartDate DATETIME
,@FinishDate DATETIME
,@SQL NVARCHAR(500)
,@RowModCtr BIGINT
,@MaintenanceActionLogId bigint;
DECLARE @resample CHAR(8)=''NO'' -- Для включения установить значение RESAMPLE
DECLARE @dbsid VARBINARY(85)
SELECT @dbsid = owner_sid
FROM sys.databases
WHERE name = db_name()
DECLARE @exec_stmt NVARCHAR(4000)
-- "UPDATE STATISTICS [SYSNAME].[SYSNAME] [SYSNAME] WITH RESAMPLE NORECOMPUTE"
DECLARE @exec_stmt_head NVARCHAR(4000)
-- "UPDATE STATISTICS [SYSNAME].[SYSNAME] "
DECLARE @options NVARCHAR(100)
-- "RESAMPLE NORECOMPUTE"
DECLARE @index_names CURSOR
DECLARE @ind_name SYSNAME
DECLARE @ind_id INT
DECLARE @ind_rowmodctr INT
DECLARE @updated_count INT
DECLARE @skipped_count INT
DECLARE @sch_id INT
DECLARE @schema_name SYSNAME
DECLARE @table_name SYSNAME
DECLARE @table_id INT
DECLARE @table_type CHAR(2)
DECLARE @schema_table_name NVARCHAR(640)
DECLARE @compatlvl tinyINT
-- Получаем список объектов, для которых нужно обслуживание статистики
DECLARE ms_crs_tnames CURSOR LOCAL FAST_FORWARD READ_ONLY for
SELECT
name, -- Имя объекта
object_id, -- Идентификатор объекта
schema_id, -- Идентификатор схемы
type
-- Тип объекта
FROM sys.objects o
WHERE (o.type = ''U'' OR o.type = ''IT'')
AND [name] ' AS nvarchar(max)) + CAST(@ConditionTableName AS nvarchar(max)) + CAST('
-- внутренняя таблица
OPEN ms_crs_tnames
FETCH NEXT FROM ms_crs_tnames INTO @table_name, @table_id, @sch_id, @table_type
-- Определяем уровень совместимости для базы данных
SELECT @compatlvl = cmptlevel
FROM sys.sysdatabases
WHERE name = db_name()
WHILE (@@fetch_status <> -1)
BEGIN
-- Формируем полное имя объекта (схема + имя)
SELECT @schema_name = schema_name(@sch_id)
SELECT @schema_table_name = quotename(@schema_name, ''['') +''.''+ quotename(rtrim(@table_name), ''['')
-- Пропускаем таблицы, для которых отключен кластерный индекс
IF (1 = isnull((SELECT is_disabled
FROM sys.indexes
WHERE object_id = @table_id AND index_id = 1), 0))
BEGIN
FETCH NEXT FROM ms_crs_tnames INTO @table_name, @table_id, @sch_id, @table_type
CONTINUE;
END
ELSE BEGIN
-- Пропускаем локальные временные таблицы
IF ((@@fetch_status <> -2) AND (substring(@table_name, 1, 1) <> ''#''))
BEGIN
SELECT @updated_count = 0
SELECT @skipped_count = 0
-- Подготавливаем начало команды: UPDATE STATISTICS [schema].[name]
SELECT @exec_stmt_head = ''UPDATE STATISTICS '' + @schema_table_name + '' ''
-- Обходим индексы и объекты статистики для текущего объекта
-- Объекты статистики как пользовательские, так и созданные автоматически.
IF ((@table_type = ''U'') AND (1 = OBJECTPROPERTY(@table_id, ''TableIsMemoryOptimized''))) -- In-Memory OLTP
BEGIN
-- Hekaton-индексы (функциональность In-Memory OLTP) не отображаются в системном представлении sys.sysindexes,
-- Поэтому нужно использовать sys.stats для их обработки.
-- Примечание: OBJECTPROPERTY возвращает NULL для типа объекта "IT" (внутренние таблицы),
-- поэтому можно использовать это только для типа ''U'' (пользовательские таблицы)
-- Для Hekaton-индексов (функциональность In-Memory OLTP)
SET @index_names = CURSOR LOCAL FAST_FORWARD READ_ONLY for
SELECT name, stat.stats_id, modification_counter AS rowmodctr
FROM sys.stats AS stat
CROSS APPLY sys.dm_db_stats_properties(stat.object_id, stat.stats_id)
WHERE stat.object_id = @table_id AND indexproperty(stat.object_id, name, ''ishypothetical'') = 0
AND indexproperty(stat.object_id, name, ''iscolumnstore'') = 0
-- Для колоночных индексов статистика не обновляется
ORDER BY stat.stats_id
END ELSE
BEGIN
-- Для обычных таблиц
SET @index_names = CURSOR LOCAL FAST_FORWARD READ_ONLY for
SELECT name, indid, rowmodctr
FROM sys.sysindexes
WHERE id = @table_id AND indid > 0 AND indexproperty(id, name, ''ishypothetical'') = 0
AND indexproperty(id, name, ''iscolumnstore'') = 0
ORDER BY indid
END
OPEN @index_names
FETCH @index_names INTO @ind_name, @ind_id, @ind_rowmodctr
-- Если объектов статистик нет, то пропускаем
IF @@fetch_status < 0
BEGIN
FETCH NEXT FROM ms_crs_tnames INTO @table_name, @table_id, @sch_id, @table_type
CONTINUE;
END ELSE
BEGIN
WHILE @@fetch_status >= 0
BEGIN
-- Формируем имя индекса
DECLARE @ind_name_quoted NVARCHAR(258)
SELECT @ind_name_quoted = quotename(@ind_name, ''['')
SELECT @options = ''''
-- Если нет данных о накопленных изменениях или они больше 0 (количество измененных строк)
IF ((@ind_rowmodctr is null) OR (@ind_rowmodctr <> 0))
BEGIN
SELECT @exec_stmt = @exec_stmt_head + @ind_name_quoted
-- Добавляем полное сканирование (FULLSCAN) для оптимизированных в памяти таблиц, если уровень совместимости < 130
IF ((@compatlvl < 130) AND (@table_type = ''U'') AND (1 = OBJECTPROPERTY(@table_id, ''TableIsMemoryOptimized''))) -- In-Memory OLTP
SELECT @options = ''FULLSCAN''
-- add resample IF needed
ELSE IF (upper(@resample)=''RESAMPLE'')
SELECT @options = ''RESAMPLE ''
-- Для уровнея совместимости больше 90 определяем доп. параметры
IF (@compatlvl >= 90)
-- Устанавливаем параметр NORECOMPUTE, если свойство AUTOSTATS для него было установлено в OFF
IF ((SELECT no_recompute
FROM sys.stats
WHERE object_id = @table_id AND name = @ind_name) = 1)
BEGIN
IF (len(@options) > 0) SELECT @options = @options + '', NORECOMPUTE''
ELSE SELECT @options = ''NORECOMPUTE''
END
-- Добавляем сформированные параметры в команду обновления статистики
IF (len(@options) > 0)
SELECT @exec_stmt = @exec_stmt + '' WITH '' + @options
SET @StartDate = GetDate();
-- Проверка доступен ли запуск обслуживания в текущее время
SET @timeNow = CAST(GETDATE() AS TIME);
IF (@timeTo >= @timeFrom) BEGIN
IF(NOT (@timeFrom <= @timeNow AND @timeTo >= @timeNow))
RETURN;
END ELSE BEGIN
IF(NOT ((@timeFrom <= @timeNow AND ''23:59:59'' >= @timeNow)
OR (@timeTo >= @timeNow AND ''00:00:00'' <= @timeNow)))
RETURN;
END
BEGIN TRY
-- Сохраняем предварительную информацию об операции обслуживания без даты завершения
IF(@useMonitoringDatabase = 1)
BEGIN
EXECUTE [' AS nvarchar(max)) + CAST(@monitoringDatabaseName AS nvarchar(max)) + CAST('].[dbo].[sp_add_maintenance_action_log]
@table_name
,@ind_name
,@Operation
,@RunDate
,@StartDate
,null
,@DBNAME
,0
,''''
,0
,@ind_rowmodctr
,@exec_stmt
,@MaintenanceActionLogId OUTPUT;
END
EXEC sp_executesql @exec_stmt;
SET @FinishDate = GetDate();
-- Устанавливаем фактическую дату завершения операции
IF(@useMonitoringDatabase = 1)
BEGIN
EXECUTE [' AS nvarchar(max)) + CAST(@monitoringDatabaseName AS nvarchar(max)) + CAST('].[dbo].[sp_set_maintenance_action_log_finish_date]
@MaintenanceActionLogId,
@FinishDate;
END
END TRY
BEGIN CATCH
IF(@MaintenanceActionLogId <> 0)
BEGIN
DECLARE @msg nvarchar(500) = ''Error: '' + CAST(Error_message() AS NVARCHAR(500)) + '', Code: '' + CAST(Error_Number() AS NVARCHAR(500)) + '', Line: '' + CAST(Error_Line() AS NVARCHAR(500))
-- Устанавливаем текст ошибки при обслуживании объекта статистики
-- Дата завершения при этом остается незаполненной
EXECUTE [' AS nvarchar(max)) + CAST(@monitoringDatabaseName AS nvarchar(max)) + CAST('].[dbo].[sp_set_maintenance_action_log_finish_date]
@MaintenanceActionLogId,
@FinishDate,
@msg;
END
END CATCH
SELECT @updated_count = @updated_count + 1
END ELSE
BEGIN
SELECT @skipped_count = @skipped_count + 1
END
FETCH @index_names INTO @ind_name, @ind_id, @ind_rowmodctr
END
END
DEALLOCATE @index_names
END
END
FETCH NEXT FROM ms_crs_tnames INTO @table_name, @table_id, @sch_id, @table_type
END
DEALLOCATE ms_crs_tnames
' AS nvarchar(max))
EXECUTE sp_executesql
@cmd,
N'@timeFrom TIME, @timeTo TIME,
@useMonitoringDatabase bit, @monitoringDatabaseName sysname',
@timeFrom, @timeTo,
@useMonitoringDatabase, @monitoringDatabaseName;
RETURN 0
END
GO
Для актуальной версии следите за обновлениями. Также никто не мешает Вам дорабатывать эти скрипты для себя.
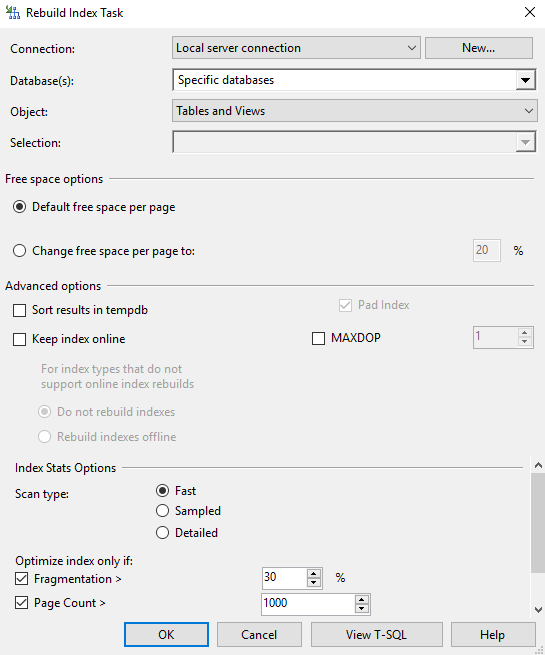
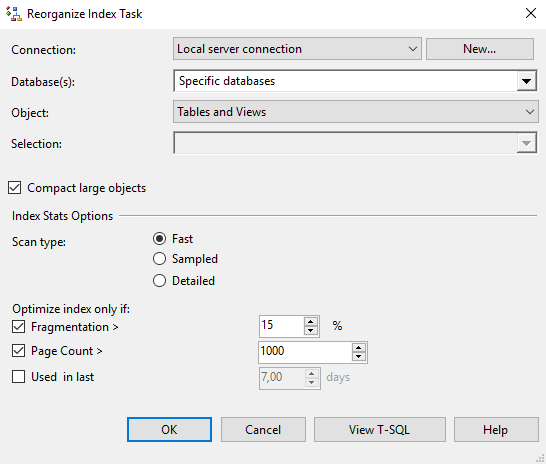
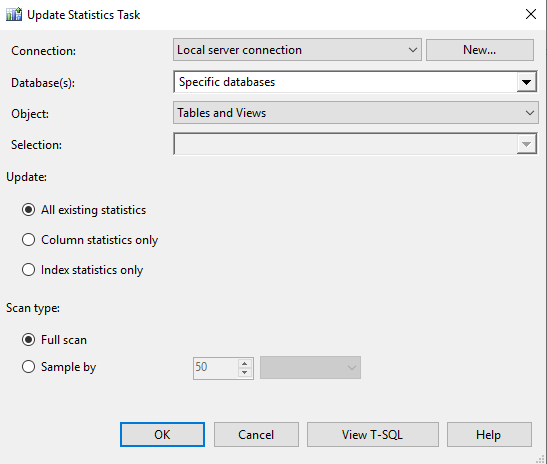
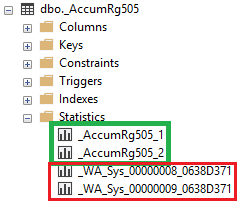










 я баз данных (индексов и статистик) поднимается достаточно часто в разных статьях, официальной документации, на форумах и так далее. Обычно дается описание процессов обслуживания, зачем они нужны и какие бывают, на что влияют. И, конечно же, как сделать настройку обслуживания. Последнее обычно преподносится на базовом уровне, но, конечно, не всегда.
я баз данных (индексов и статистик) поднимается достаточно часто в разных статьях, официальной документации, на форумах и так далее. Обычно дается описание процессов обслуживания, зачем они нужны и какие бывают, на что влияют. И, конечно же, как сделать настройку обслуживания. Последнее обычно преподносится на базовом уровне, но, конечно, не всегда.
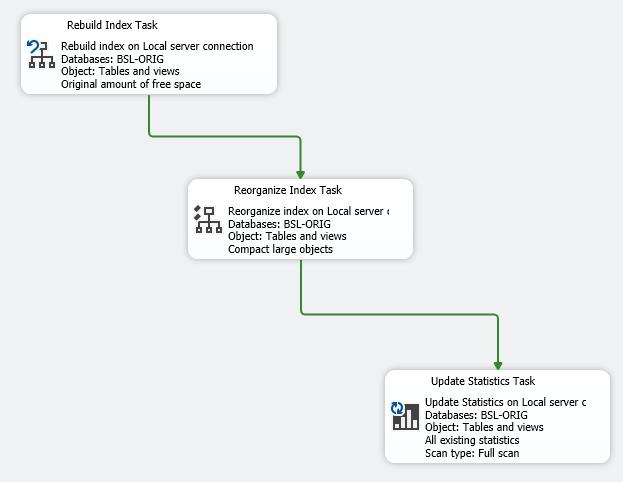 Механизм планов обслуживания базируется на "обрезанной" версии SSIS, если так можно выразиться. Для использования готовых компонентов нужно использовать именно его.
Механизм планов обслуживания базируется на "обрезанной" версии SSIS, если так можно выразиться. Для использования готовых компонентов нужно использовать именно его. Альтернативным вариантом является использование заданий (job'ов) агента SQL Server, просто указывая явно скрипты TSQL для выполнения.
Альтернативным вариантом является использование заданий (job'ов) агента SQL Server, просто указывая явно скрипты TSQL для выполнения. Так как база небольшая, то, скорее всего, весь процесс обслуживания завершится за 30-60 минут ночью и за 5-15 минут днем, а может и еще быстрее.
Так как база небольшая, то, скорее всего, весь процесс обслуживания завершится за 30-60 минут ночью и за 5-15 минут днем, а может и еще быстрее.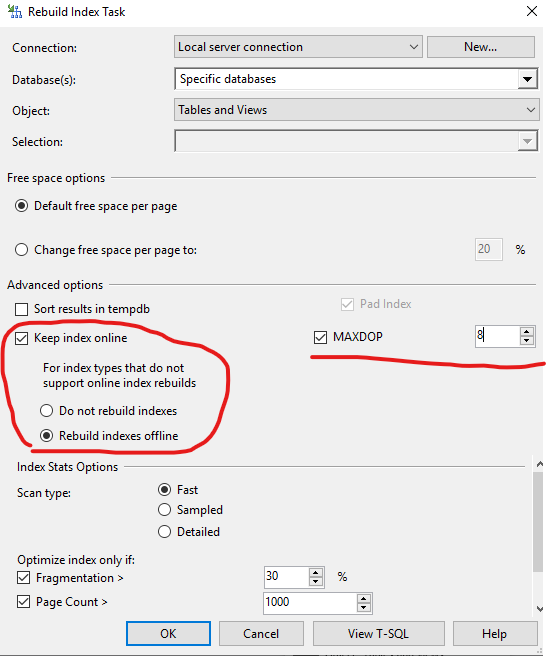
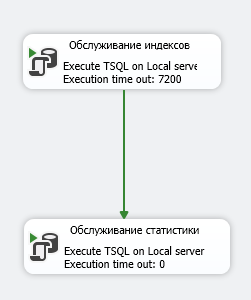 Вместо трех шагов теперь только 2, в каждом свои скрипты для выполнения операций.
Вместо трех шагов теперь только 2, в каждом свои скрипты для выполнения операций. мелких, средних и крупных баз данных.
мелких, средних и крупных баз данных. Вы будете знать обслуживался ли он онлайн, было это перестроение или реорганизация, какой процент фрагментации был на момент обслуживания, сколько записей изменилось с момента обновления статистики, какая SQL-команда использовалась, длительность операции и вообще завершилась ли операция. Операция обслуживания будет взята под полный контроль!
Вы будете знать обслуживался ли он онлайн, было это перестроение или реорганизация, какой процент фрагментации был на момент обслуживания, сколько записей изменилось с момента обновления статистики, какая SQL-команда использовалась, длительность операции и вообще завершилась ли операция. Операция обслуживания будет взята под полный контроль!
