Изначально коллеги в обсуждении ссылались на то, что состав таких индексов хорошо подходит для работы с динамическими списками (теперь я понимаю, о чем речь, но об этом чуть позже).
В чем заключалась суть вопроса? Если обращаться к ITS, то можно найти следующую информацию (рассмотрим ситуацию только на примере справочников):
Состав индексов для реквизитов справочников в режиме "с доп. упорядочиванием" (https://its.1c.ru/db/metod8dev/content/1590/hdoc):

То же самое сказано и в другой аналогичной статье ITS (https://its.1c.ru/db/pubapplied#content:336:1):

Глядя на эту информацию, возникает всего одна мысль

Ведь как мы знаем:
- Динамические списки неявно выбирают из СУБД еще и пометку удаления (для отображения картинки пометки удаления в списке, когда выбрана основная таблица для динамического списка).
- В динамический список может выбираться более одной колонки из более чем одного реквизита.
Читая документацию на ITS понимаешь, что "Индекс с доп. упорядочиванием" не может эффективно использоваться для таких целей, как минимум потому, что не включает в себя пометку удаления, как максимум потому, что не включает в состав другие реквизиты.

А давайте-ка заглянем на уровень СУБД и посмотрим, что же происходит там на самом деле.
Для начала создадим небольшую конфигурацию и добавим в неё справочник, создадим пяток реквизитов и нажмем F7.
После чего посмотрим, что же из этого получилось на уровне СУБД...
Открываем таблицу справочника вместе с её индексами и видим следующую картину:

Пока что мы видим одно... Все, как и написано в статье ITS. Соответствие реквизитов выделено черным, красным отмечены индексы и их соответствия в описании на ITS.

Давайте теперь посмотрим что же у нас с доп. упорядочиванием.
Проиндексируем один реквизит и посмотрим, какой индекс будет создан в результате этой операции:

Первое, что бросается в глаза, это окно реорганизации информации с изменениями в структуре информации конфигурации, где присутствует наш справочник...
Изменение свойства индексировать - приводит к реструктуризации! Не самих таблиц объекта, а реструктуризации индекса(ов).
Посмотрим состав нового индекса и удивимся, что он отличается от указанного в документации!
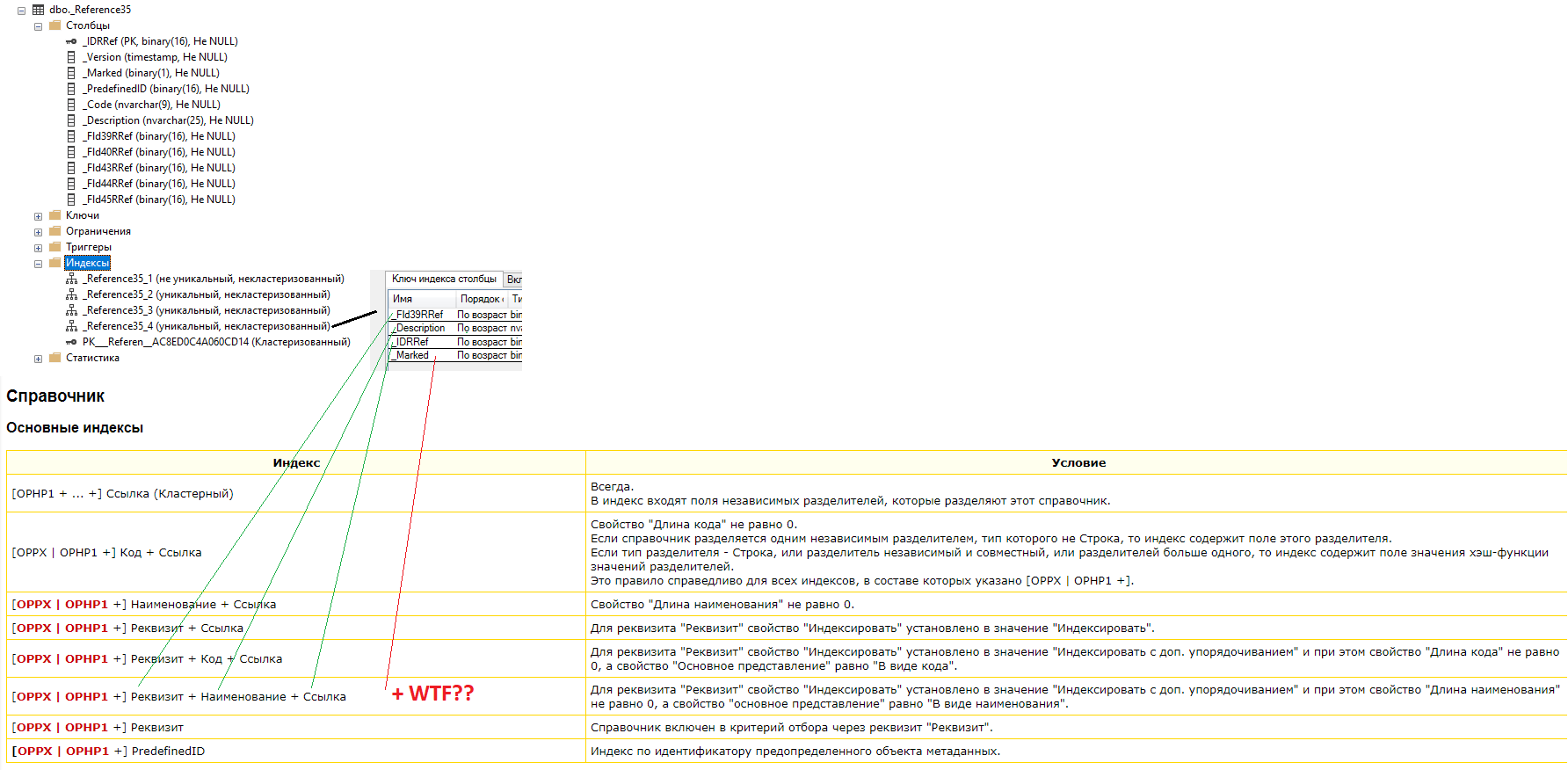
В состав индекса также добавлена "ПометкаУдаления", теперь становится более понятным, почему коллеги говорили о динамических списках... Но пока еще не до конца... Да, пометка удаления теперь присутствует и позволяет задействовать индекс при построении динамического списка... К слову, немного обо всём этом в статье https://its.1c.ru/db/metod8dev/content/2742/hdoc
А как же включение в состав индекса других реквизитов? Ведь без них эффективное использование индекса будет невозможно, если мне захочется вывести в дин. список не только этот реквизит с "доп. упорядочиванием", но и другие?
Давайте проиндексируем еще пару реквизитов и посмотрим, что из этого получится. Добавляю "Индексировать с доп. упорядочиванием" дополнительно для Реквизит2 и Реквизит3 (изначально был проиндексирован только Реквизит1):
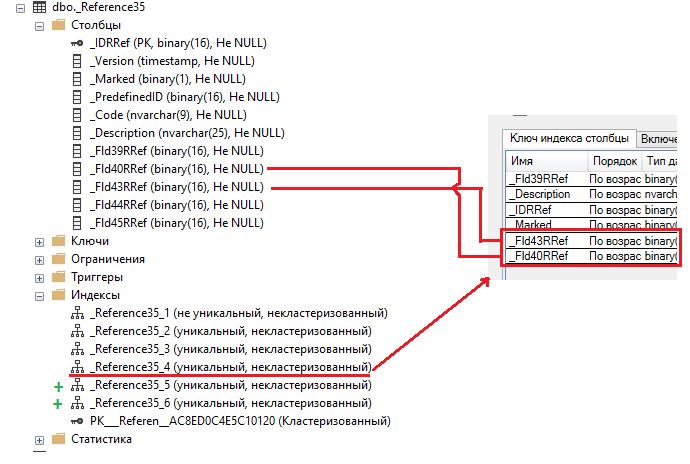
Мы видим, что состав нашего индекса поменялся, в него были добавлены два других реквизита которые так же были проиндексированы с доп. упорядочиванием! Аналогичным образом проиндексированы и два других реквизита (Реквизит2 и Реквизит3) с доп. упорядочиванием (см. два новых индекса на картинке с таблицей СУБД)!
Всегда нужно прислушиваться к чужому мнению и дополнительно анализировать самостоятельно, т.к. читая официальную документацию, делая выводы только на основании этого, отрицая мнение других опытных коллег, можно легко попасть в такую ситуацию:

Таким образом получается, что состав индексов в том же справочнике на самом деле выглядит вот так:
Справочник
Основные индексы
|
Индекс |
Условие |
|
[ОРНР1 + ... +] Ссылка (Кластерный) |
Всегда. |
|
[ОРРХ | ОРНР1 +] Код + Ссылка |
Свойство "Длина кода" не равно 0. |
|
[ОРРХ | ОРНР1 +] Наименование + Ссылка |
Свойство "Длина наименования" не равно 0. |
|
[ОРРХ | ОРНР1 +] Реквизит + Ссылка |
Для реквизита "Реквизит" свойство "Индексировать" установлено в значение "Индексировать". |
|
[ОРРХ | ОРНР1 +] Реквизит + Код + Ссылка + ПометкаУдаления [+ Все реквизиты объекта у которых свойство Индексировать установлено в "Индексировать с доп. упорядочиванием"] |
Для реквизита "Реквизит" свойство "Индексировать" установлено в значение "Индексировать с доп. упорядочиванием" и при этом свойство "Длина кода" не равно 0, а свойство "Основное представление" равно "В виде кода". |
|
[ОРРХ | ОРНР1 +] Реквизит + Наименование + Ссылка + ПометкаУдаления [+ Все реквизиты объекта у которых свойство Индексировать установлено в "Индексировать с доп. упорядочиванием"] |
Для реквизита "Реквизит" свойство "Индексировать" установлено в значение "Индексировать с доп. упорядочиванием" и при этом свойство "Длина наименования" не равно 0, а свойство "основное представление" равно "В виде наименования". |
|
[ОРРХ | ОРНР1 +] Реквизит |
Справочник включен в критерий отбора через реквизит "Реквизит". |
|
[ОРРХ | ОРНР1 +] PredefinedID |
Индекс по идентификатору предопределенного объекта метаданных. |
Путем исследования было определено, что подобным образом индексация с доп. упорядочиванием строится для реквизитов Документов, Справочники, ЖурналовДокументов и Планов видов характеристик.
Для Планов видов расчетов, Бизнес процессов, Задач и Планов счетов индексация реквизитов с доп. упорядочиванием (на текущую дату 15.06.2022) соответствует официальной документации.
Вывод №1: Когда строите тяжелые запросы или занимаетесь оптимизацией запросов, лучше отталкиваться от информации, которая была получена непосредственно из СУБД, а не из официальных или других источников (которые могли устареть).
Вывод №2: Включение или отключение свойства "Индексировать с доп. упорядочиванием" приводит к реструктуризации всех индексов для всех реквизитов объекта у которых свойство "Индексировать" точно так же выставлено в "Индексировать с доп. упорядочиванием". Это говорит о том, что для тяжелых таблиц СУБД с большим количеством записей подобные манипуляции могут занимать много времени, поскольку потребуется время на реструктуризацию всех индексов которое возрастает пропорционально числу таких реквизитов с "Доп. упорядочиванием" у объекта.
Вывод №3: Глядя на состав индексов с доп. упорядочиванием становится очевидным то, что индексировать с доп. упорядочиванием более двух реквизитов у одного и того же объекта бессмысленно, т.к. будет изменен состав всех индексов в случае изменения любого из индексов с доп. упорядочиванием. Соответственно если, например, проиндексировать с доп. упорядочиванием Реквизит1 и Реквизит2 справочника, то получим такой состав индексов, для Реквизит1 (в случае основного представления по коду) - [ОРРХ | ОРНР1 +] Реквизит + Код + Ссылка + ПометкаУдаления, Реквизит2. А для Реквизит2 (в случае основного представления по коду) - [ОРРХ | ОРНР1 +] Реквизит + Код + Ссылка + ПометкаУдаления, Реквизит1. Таким образом мы будем всегда точно знать каков состав этих двух индексов с доп. упорядочиванием.
Но все кардинально поменяется, если мы добавим индексацию с доп. упорядочиванием по третьему, четвертому и т.д. реквизитам. Поскольку мы точно не знаем состав индексов (порядок, в котором будет произведена индексация реквизитов с доп. упорядочиванием, определяется системой по неизвестному нам, произвольному алгоритму), мы не сможем эффективно использовать такие индексы. И даже если мы посмотрим состав индексов с доп. упорядочиванием на уровне СУБД, заранее выстроим алгоритм, который будет эффективно использовать этот состав индексов с доп. упорядочиванием, мы не застрахованы от ситуации, когда кто-то другой добавит еще один индекс с доп. упорядочиванием или не изменит существующий (переключит у любого реквизита свойство «Индексировать» из «Индексировать с доп. упорядочиванием» в любой другой режим) - тогда весь наш алгоритм сломается, т.к. первоначальный состав всех индексов с доп. упорядочиванием изменится, и наш запрос станет неэффективным.
Да и в целом такие индексы становятся очень громоздкими, в результате чего вопрос эффективного поиска по таким индексам ставится под сомнение.