

{kind=link}
Сразу оговорюсь, парсинг сайтов средствами 1С имеет ряд ограничений (подробно описаны в этой статье):
- Получение данных зависит от верстки самого сайта, если она поменяется - нужно будет изменять логику работы парсера.
- Парсинг осуществляется на стороне клиента 1С, используя поле HTML документа - чтобы парсер работал постоянно, нужно будет держать открытым окно клиента 1С.
Весь алгоритм работы находится в модуле формы обработки "aggregator" и его условно можно разделить на 2 части:
- Парсинг - получение данных со страниц сайта средствами поля HTML документа.
- Публикация данных об объявлениях в телеграм-канеле.
Детали реализации.
- Добавляем на форму поле HTML документа, устанавливаем обработчик ожидания на 5 секунд - с такой периодичностью будем загружать страницы, чтобы не получить блокировку со стороны сайта.
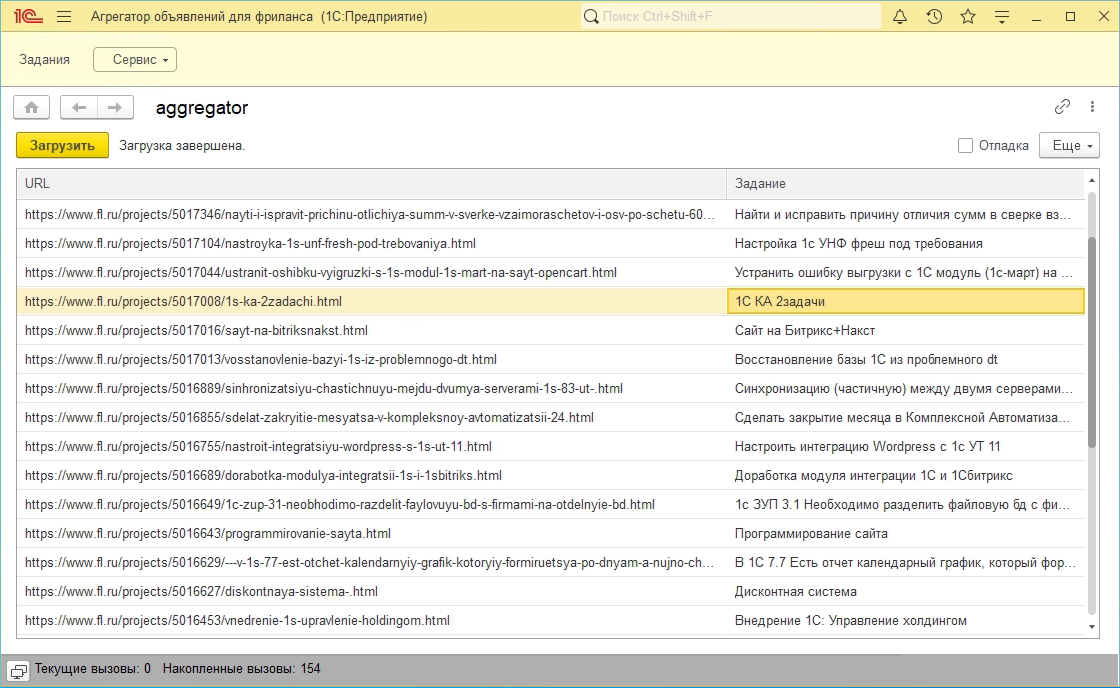
- В обработчике ожидания загружаем страницы со списком объявлений, получаем список url всех объявлений и потом загружаем каждое новое объявление.
- Загруженную страницу начинаем обрабатывать, используя css селекторы - специальные выражения, которые позволяют получить определенные элементы со страницы. Тут очень помогает dev tools браузера, формируем селекторы в нем, потом проверяем в отладчике.
Код:
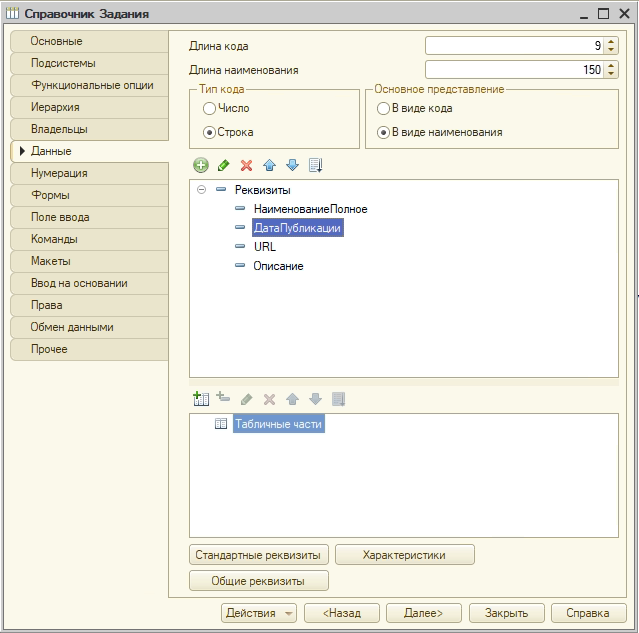
- Полученные данные записываем в специальный справочник "Задания фриланса":
Справочник:
- Публикуем данные по объявлению с помощью бота в канал телеграма. Детали создания бота и работы с api телеграм можно посмотреть тут. Сам вызов приблизительно такой:
Код:
Пример (проверено на платформе 8.3.14) сделан для парсинга одного сайта, если нужно добавить другие - это не составит особого труда.
На этом все, результат работы можно посмотреть тут.
Вступайте в нашу телеграмм-группу Инфостарт