



Простой, примитивный
Сегодня пятница (на момент создания публикации), а значит можно коснуться какой-нибудь простой темы. Например - парсинг сайтов. Публикация ориентирована больше на новичков и кто только решил посмотреть на работу поля HTML-документа.
Тема не новая и каких только материалов нет на просторах сети. Кто-то парсит через DOM, кто-то регулярками и еще длинный список способов. Мы же пойдем самым простым способом - через поле HTML-документа. Тем более с появлением поддержки WebKit возможностей для его использования прибавилось.
Рассмотрим пару простых примеров и немного коснемся ограничений.
Большие ограничения
Данный материал не подойдет, если Вы решаете следующие задачи:
- Получение и обработка данных на сервере регламентным заданием или любым другим.
- Обработка очень большого массива данных.
- Пытаетесь парсингом заменить работу через API из-за его отсутствия или недоступности.
- Вам нужен надежный способ получения данных.
В случаях же, если нужен простой и быстрый в реализации способ извлечения данных с веб-страниц, и при этом работа с инструментом будет вестись интерактивно, то использование поля HTML-документа то что нужно.
Парсинг веб-ресурсов почти всегда "зло" как по отношению к владельцу ресурса, так и в части сопровождения таких решений. Ведь стоит разметке поменяться и алгоритмы извлечения данных нужно снова менять.
Однако, иногда выхода нет. Да и использование предлагаемого подхода можно считать этичным в каком-то плане, потому что создаем всего лишь помощника работы с браузером и автоматизируем действия пользователя на веб-странице. Хотя это вопрос "холиварный".
В чем плюсы
Все очень просто:
- Использование поля HTML-документа выполняется полностью на клиенте и не требует серверных мощностей.
- Выполняется полноценная работа с веб-страницей. Например, если выполнять получение данных веб-страницы с помощью HTTP-запросов, то не всегда можно получить привычную, готовую страницу, т.к. ее содержимое может зависеть от выполняемых JavaScript-скриптов и дополнительных действий.
- Из второго плюса также можно выделить более простую работу с веб-приложением. Например, для прохождения формы аутентификации не обязательно изучать какие запросы выполняются на сервер и как выполнять обработку ответа. Вместо этого в самом браузере мы вставим значения логина и пароля в форму и просто программно нажмем кнопку "Вход".
Но эти плюсы в каком-то плане создают и ограничения использования таких подходов работы с веб-содержимым.
Далее рассмотрим пару простых примеров. Решать использовать ли такие способы для решения задач только Вам.
Добрались до примера
Два небольших примера. От простейшего к сложному (ну, почти).
Просто получаем данные
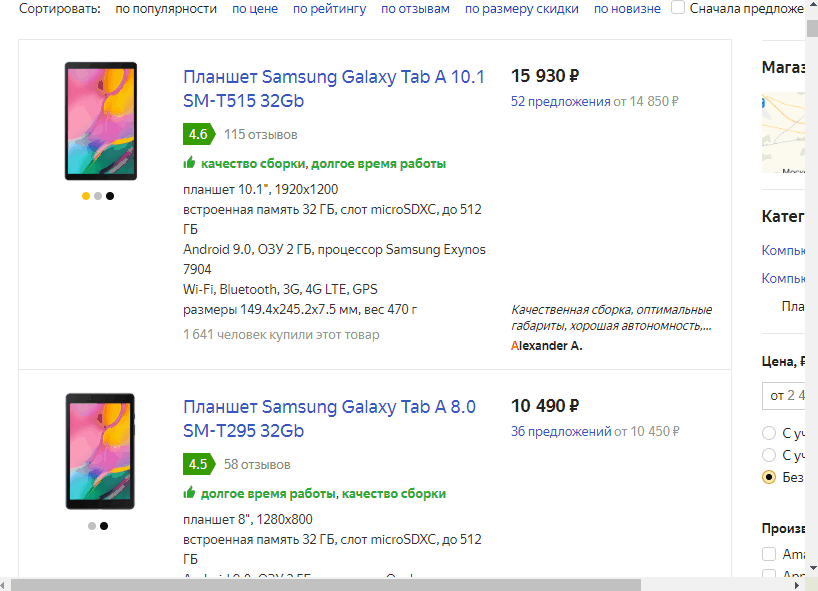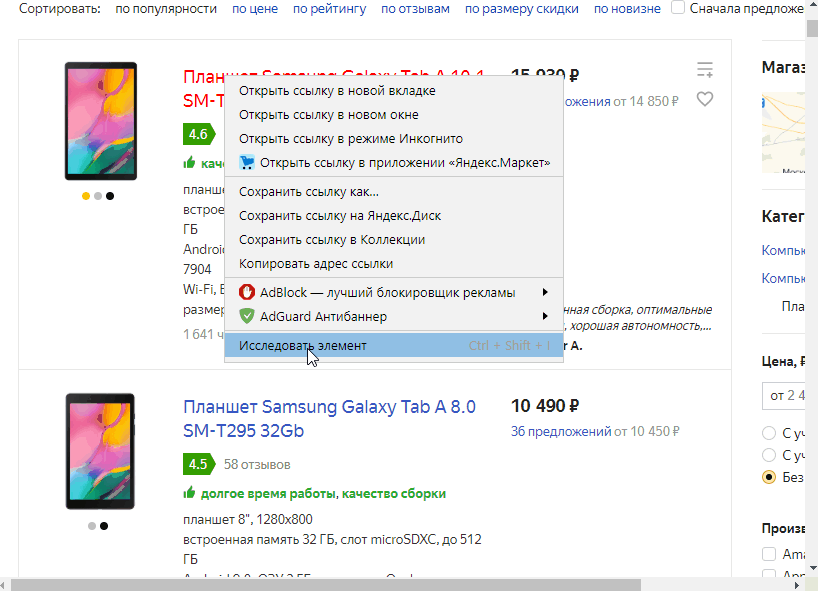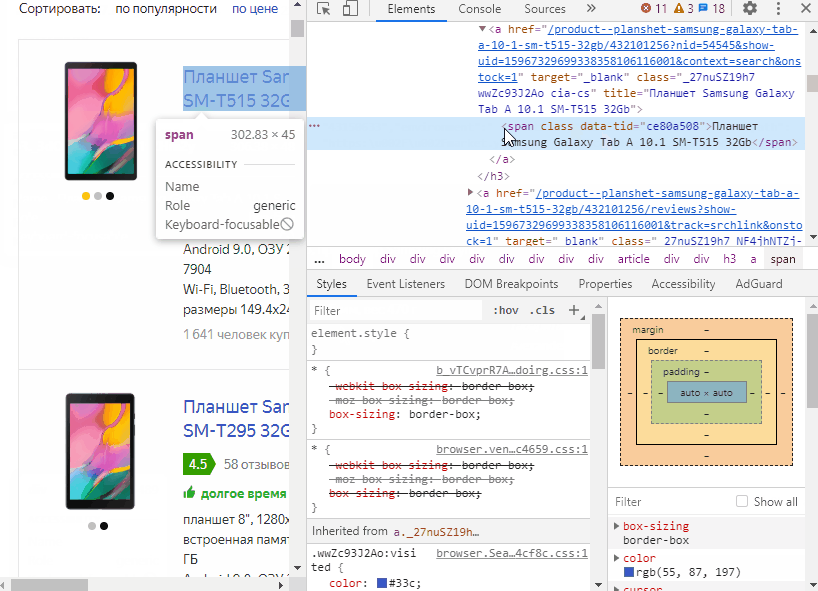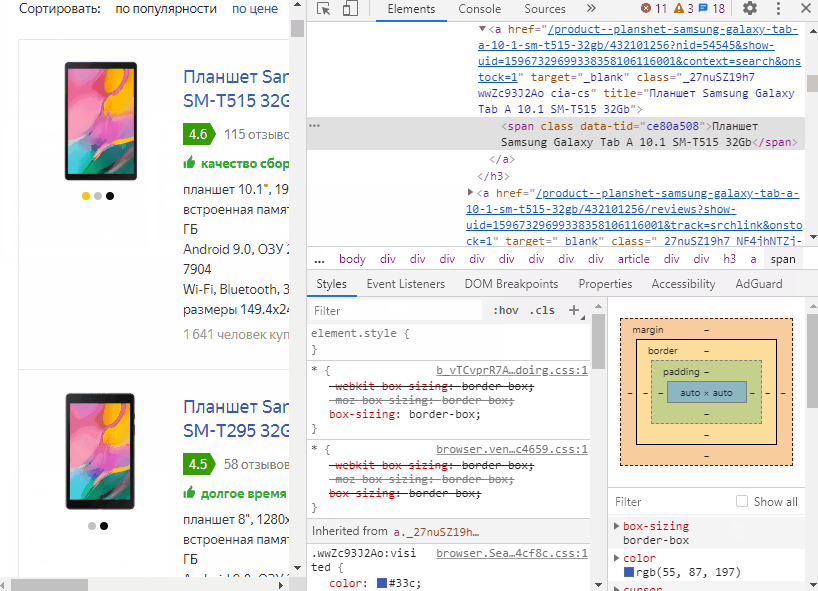
А начнем мы с простого примера по парсингу площадки Яндекс.Маркет. Да, конечно, можно было сделать пример намного проще, но тут мы сразу рассмотрим основные способы работы с HTML-документов. Давным-давно, много лет назад, что-то подобное я выкладывал в разработке "Парсер товаров Яндекс.Маркет", но обработка сейчас уже не актуальна и больше служит примером работы с HTML-документов. Код там не лучшего качества :)
Когда мы закончим реализацию примера, то получим следующее.
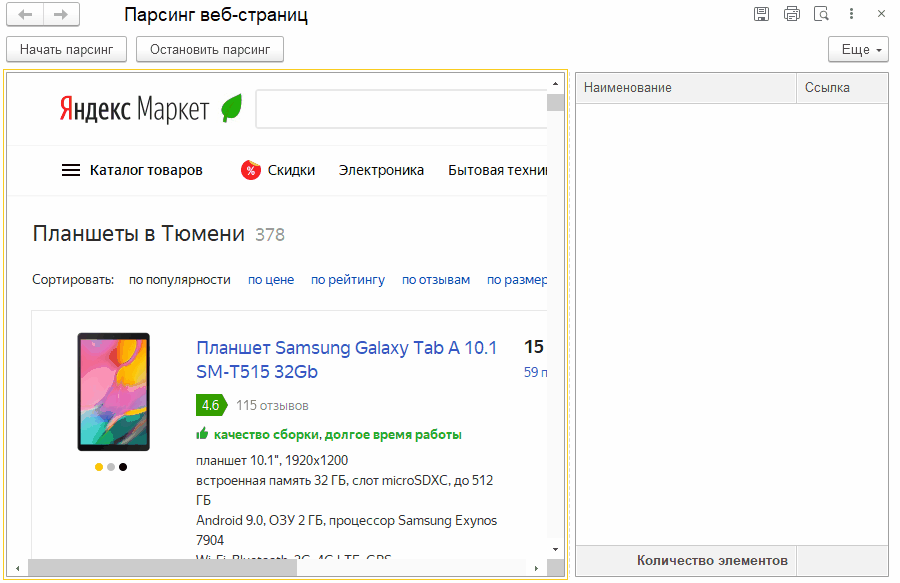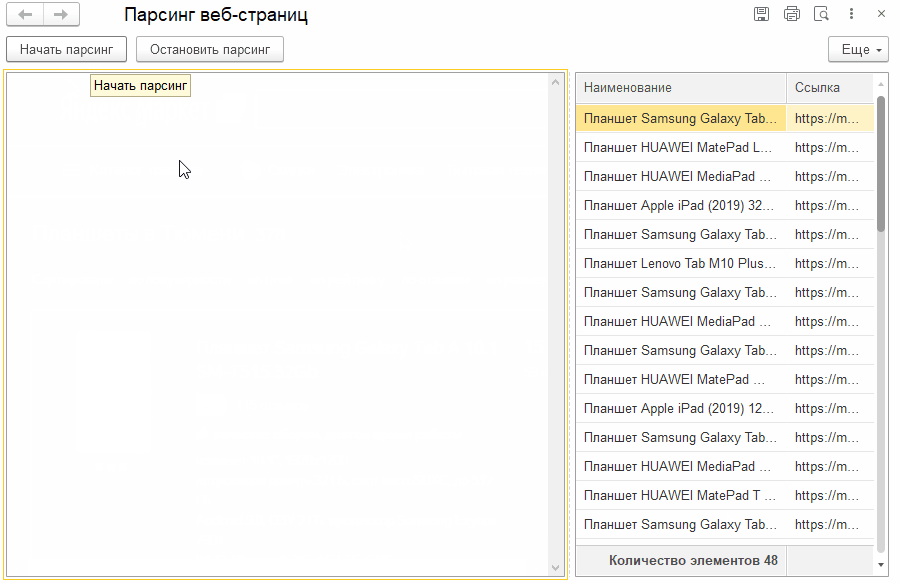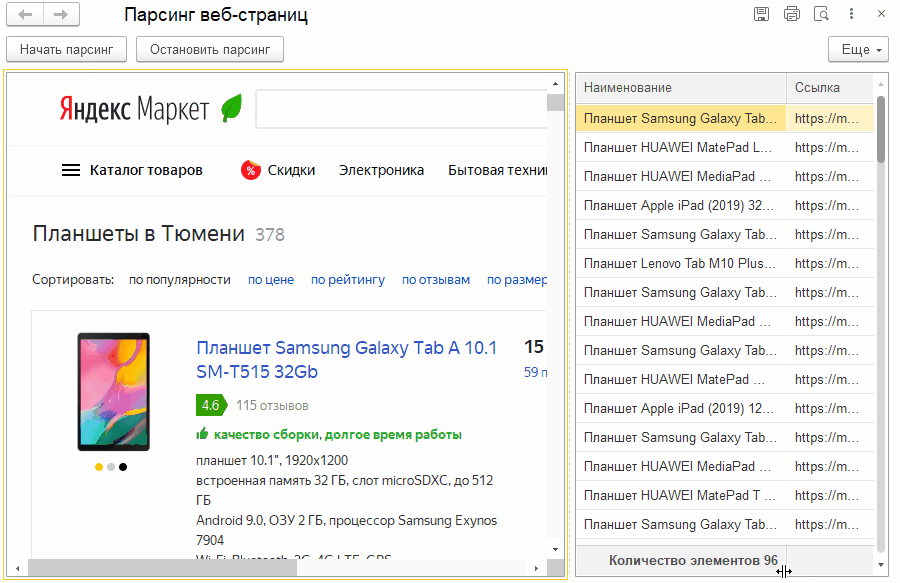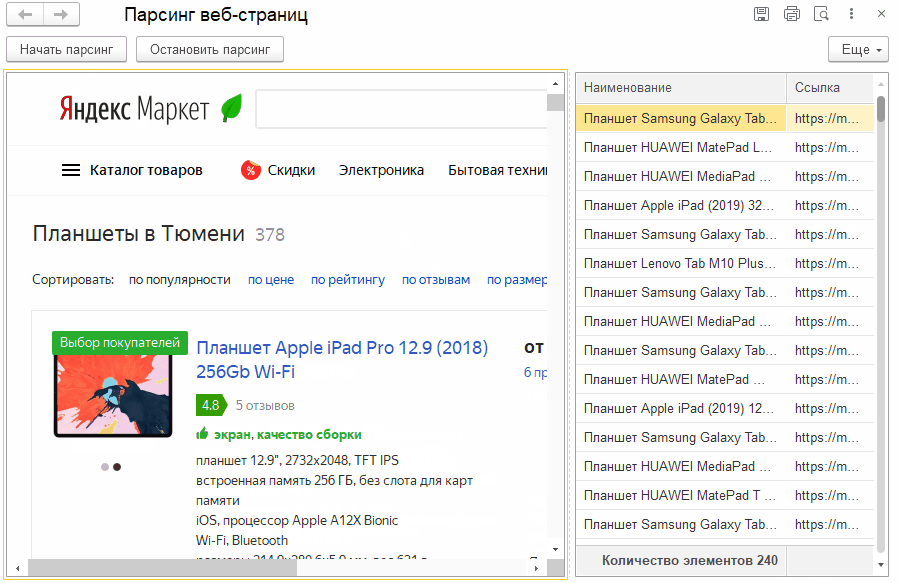 По команде "Начать парсинг" мы будем "грабить" страницы на имена товаров и ссылки на них. Да, можно получать и другие поля, но в нашем случае этого достаточно. На анимации выше видно, как увеличивается количество строк с данными в таблице формы.
По команде "Начать парсинг" мы будем "грабить" страницы на имена товаров и ссылки на них. Да, можно получать и другие поля, но в нашем случае этого достаточно. На анимации выше видно, как увеличивается количество строк с данными в таблице формы.
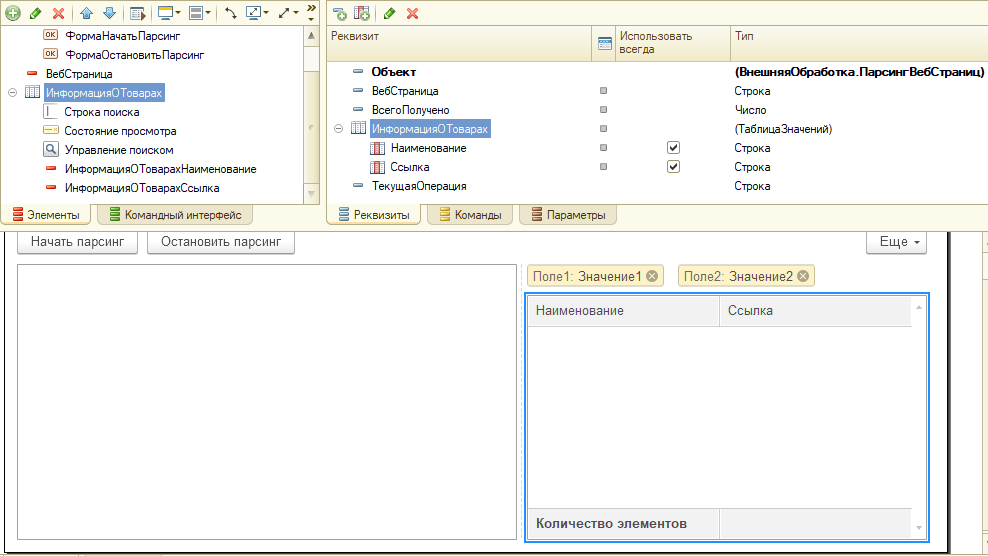
Первое что нам нужно сделать - это добавить на форму поле HTML-документа и основные реквизиты для хранения данных.
Теперь настало время кода! При создании формы установим URL по умолчанию.
#Область ОбработчикиСобытийФормы
&НаСервере
Процедура ПриСозданииНаСервере(Отказ, СтандартнаяОбработка)
ВебСтраница = "https://market.yandex.ru";
КонецПроцедуры
#КонецОбласти
Это позволит при открытии сразу же открывать нужный ресурс. Далее реализуем обработчики команд "Начать парсинг" и "Остановить парсинг".
#Область ОбработчикиКоманд
&НаКлиенте
Процедура НачатьПарсинг(Команда = Неопределено)
ТекущаяОперация = "ПарсингТоваров";
ИнформацияОТоварах.Очистить();
НомерТекущейСтраницы = ИзвлечьНомерСтраницы();
ПолученыДанные = ВыполнитьПарсингДанных();
Если ПолученыДанные Тогда
ВебСтраница = СформироватьАдресСледующейСтраницы();
КонецЕсли;
КонецПроцедуры
&НаКлиенте
Процедура ОстановитьПарсинг(Команда = Неопределено)
ТекущаяОперация = "НеАктивно"
КонецПроцедуры
#КонецОбласти
С командой "ОстановитьПарсинг" все понятно: мы просто устанавливаем имя текущей операции на "НеАктивно", чтобы парсинг не продолжался автоматически. Команда "НачатьПарсинг" устанавливаем имя текущей операции на "ПарсингТоваров" и начинает заново заполнять таблицу с данными (наименование и ссылка на товар). При этом из текущего адреса получаем номер страницы с товарами, который сохраняется в клиентской переменной модуля формы.
#Область ОписаниеПеременных
&НаКлиенте
Перем НомерТекущейСтраницы;
#КонецОбласти
Номер страницы нужен для автоматического переключения на следующие вовремя парсинга. Сам номер страницы хранится в адресной строке в виде параметра "page". Если не указан, то это первая страница.
Если данные парсинга были успешно получены, то переходим на следующую страницу с товарами и так до бесконечности. Ну, пока есть данные. Реализация бесконечного перехода по страницам достигается через событие "ДокументСформирован" поля HTML-документа. Вот такой обработчик событий был для этого сделан:
#Область ОбработчикиСобытийЭлементовФормы
&НаКлиенте
Процедура ВебСтраницаДокументСформирован(Элемент)
Если ТекущаяОперация = "ПарсингТоваров" Тогда
ПолученыДанные = ВыполнитьПарсингДанных();
Если ПолученыДанные Тогда
НомерТекущейСтраницы = ИзвлечьНомерСтраницы();
ВебСтраница = СформироватьАдресСледующейСтраницы();
Иначе
ОстановитьПарсинг();
КонецЕсли;
КонецЕсли;
КонецПроцедуры
#КонецОбласти
Если текущая операция "ПарсингТоваров", а не любая другая (вот почему команда "ОстановитьПарсинг" действительно его останавливает - просто при формирововании страницы никаких действий для продолжения не будет выполнено), то мы пытаемся "спарсить" данные со сформированной страницы. Если данные успешно получены, то актуализируем значение переменной текущей страницы и формируем адрес следующей.
Далее рассмотрим служебные процедуры работы с адресом и парсингом.
А теперь перейдем к более сложной части - извлечению данных со страницы.
Как Вы видите, все процедуры и функции выполняются на клиенте. Как упоминалось выше, работать с этим полем возможно только на клиенте, что и является основным ограничением его применения.
Конечно, данное решение не идеальное, т.к. не учитывает множества факторов и вариантов страниц Я.Маркета, но мы этого и не пытались сделать. Это лишь простейший пример для понимания как это можно реализовать. Готовой обработки не выкладываю специально, потому что если разобраться самостоятельно, то это будет намного полезней.
Проходим авторизацию
Пример парсинга мы рассмотрели, но бывают ситуации сложнее. Например, перед парсингом может понадобиться пройти аутентификацию на сайте. Например, на сайте releases.1C.ru для просмотра списка релизов, даже те, которые недоступны, необходимо пройти аутентификацию. Конечно, можно использовать HTTP-запросы, проанализировать как именно нужно эти запросы сделать и все это поведение эмулировать. А можно пройти аутентификации с помощью поля HTML-документа, не погружаясь на низкий уровень запросов.
Например, для прохождения аутентификации на том же сайте с релизами достаточно использовать такой код:
&НаКлиенте
Процедура ВходНаСайтРелизов(Команда)
Логин = "<Ваш логин>";
Пароль = "<Ваш пароль>";
// Внешний объект документа из поля HTML-документа
document = Элементы.ВебСтраница.Документ;
// Устанавливаем логин и пароль в поля ввода
document.querySelector("#username").value = Логин;
document.querySelector("#password").value = Пароль;
// Нажимакм на кнопку "Войти"
document.querySelector("#loginButton").click();
КонецПроцедуры
В режиме 1С:Предприятие выглядит это вот так.
 Все просто как никогда и никаких HTTP-Запросов. Все что нужно - это получить CSS-селекторы, получить доступ к соответствующим элементам на странице, а дальше заполнить поля и нажать на кнопку "Войти". Далее можно парсить, но все на Вашей ответственности! :)
Все просто как никогда и никаких HTTP-Запросов. Все что нужно - это получить CSS-селекторы, получить доступ к соответствующим элементам на странице, а дальше заполнить поля и нажать на кнопку "Войти". Далее можно парсить, но все на Вашей ответственности! :)
Парсинг это плохо
Повторю еще раз - парсинг веб-страниц это плохо. Для целей получения данных должен быть API, который позволит строить надежные и производительные решения. А парсинг... он до первого изменения разметки.
Все примеры здесь даны лишь в демонстрационных целях. Любое использование информации только на Вашу ответственность.
Ниже добавил ссылки на интересные и более глубокие публикации по этой теме. Если Вас интересует использование JavaScript в связке с 1С, то там Вы найдете отличные материалы для изучения этой темы.
Удачи в делах и отличного настроения!
Другие ссылки
-
Разбираемся с WebKit в 1С, на примере интеграции TinyMCE в управляемую форму в УТ 11.4
-
html + css + js в поле HTML документа 1С на примере решения задачи ханойских башен
-
HTML в новой версии 8.3.14 на примере 3-х JavaScript библиотек: AmCharts, HighCharts, DHTMLX
-
1С + PHP + JavaScript + AJAX. Основы технологий удаленного взаимодействия
-
Парсинг сайтов из 1С на примере ломбарды.рф с помощью XPATH для ДокументDOM
-
Парсинг сайта без использования встроенного браузера для начинающих
-
Парсинг (сканирование) сайта из 1С на примере сайта по криптовалюте
Авторские разработки
-
Транслятор запросов 1С в SQL - инструмент для трансляции запросов платформы 1С в SQL, а также их диагностики.
-
Просмотр и анализ структуры базы данных (отчет на СКД) - отчет для просмотра и анализа структуры базы данных с поддержкой файловых баз (ограниченный режим), а также баз на SQL Server и PostgreSQL.
-
Просмотр и анализ журнала регистрации (отчет на СКД) - отчет на базе системы компоновки данных (СКД) для просмотра записей журнала регистрации.
-
История работы пользователей (отчет на СКД) - отчет для просмотра истории работы пользователей (СКД, просмотр для любого пользователя).
-
Экспорт журнала регистрации. Набор инструментов (приложения + исходный код) - набор инструментов для экспорта данных журнала регистрации во внешние хранилища для Windows и Linux. Готовые приложения и исходный код.
-
Технические проверки данных регистров бухгалтерии (отчет на СКД) - отчет для технических проверок данных бухгалтерских регистров.
-
Путеводитель по истории релизов - отчет по истории выпуска релизов продуктов фирмы "1С" и анализа информации по обновлениям.
Вступайте в нашу телеграмм-группу Инфостарт