Меня зовут Валерий Дыков, я разработчик из компании «Первый БИТ», офис БИТ:ERP. Расскажу про наш опыт использования EDT, который уже насчитывает два года.

Вначале давайте познакомимся.
Я занимаюсь 1С с 2000-го года – начинал с простого разработчика, прошел путь до директора франчайзи, работал в фирме «1С» и последние девять лет работаю в компании «Первый БИТ».
Немного про наш офис БИТ:ERP – это будет важно для дальнейшего повествования.
-
Мы работаем по проектам, которые ведутся по двум направлениям деятельности:
-
проекты на ERP – от 100 до тысячи пользователей;
-
и коробочные продукты.
-
-
У нас есть особенности:
-
мы изначально удаленщики;
-
и мы любим использовать разные новые технологии на практике.
-

Хочу рассказать про наш опыт:
-
как мы начинали работать с EDT, и к чему это привело сейчас;
-
как мы работаем с GIT;
-
какие инструменты мы придумали, чтобы упростить работу с GIT и с EDT для наших сотрудников;
-
как мы используем автотесты, и насколько это помогает нам при работе с GIT.
-
чем все закончилось, и как у нас все выглядит сейчас.
Давайте начнем.
Начало работы с EDT. БИТ.Адаптер

EDT мы начали использовать два года назад при разработке проекта БИТ.Адаптер. Это – идеальный проект для использования EDT.
Какие у него особенности?
-
Это – коробочный продукт.
-
Он самописный, в нем даже БСП нет. И небольшой – над ним одновременно работает небольшая проектная команда из одного-двух человек.
-
Мы всегда этот проект использовали как полигон для исследований. Два года назад мы внедрили на нем BDD с использованием Vanessa Automation, начали писать и запускать автотесты. Но у нас была одна проблема – нам никогда не удавалось добиться «зеленого» мастера, потому что при использовании конфигуратора и хранилища мы вначале помещаем изменения в хранилище, а потом тестируем. И в результате получается, что тесты часто не проходят – т.е. у нас в хранилище лежит конфигурация, на которой не проходят все тесты. Переходя на EDT с использованием GIT мы хотели побороть именно эту проблему, потому что GIT позволяет класть изменения в ветки, тестировать конфигурации в ветках, а в master класть уже консистентную конфигурацию.

Я заскриншотил, как все начиналось. Вот так выглядело появление нашей первой ветки с использованием GIT в ноябре 2018 года.
Следующий шаг – БИТ.MDT

Нашим следующим шагом в сторону использования EDT был выбор коробки побольше – это был наш продукт БИТ.MDT, я про него рассказывал на секции по мобильной платформе.
- Продукт БИТ.MDT состоит из мобильной платформы и расширения для типовых конфигураций.
- Он тоже небольшой – над ним одновременно работает 5-6 человек, из которых три разработчика. Мы начинали его делать год назад «с нуля».
При использовании хранилища мы видели следующие проблемы.
-
Так как при разработке «с нуля» добавляется куча новых объектов, возникала конкуренция за корень и за эти объекты, а EDT позволяет решить эту проблему.
-
И второе – нам нужно было выпускать релизы быстро и ритмично. И исправлять ошибки – быстро и ритмично. А хранилище плохо позволяет это делать, потому что все время в хранилище находится не до конца доделанные задачи и нужно потом вырезать из них работающее – из того, что в хранилище лежит, чтобы собрать релиз.
-
Кроме этого, мы хотели сразу же предотвратить проблемы – сразу использовать на этом проекте BDD. Хотели всегда получать «зеленый мастер», а EDT это позволяет делать – мы уже на Адаптере потренировались.
Проблемы при работе в EDT

Уже на проекте MDT мы столкнулись с проблемами при использовании EDT.
Когда мы в самом начале развития проекта MDT делали расширение, которое работало только для УТ11, проблем с производительностью особых не было. И команда тогда была маленькой. Четырех ядер и 16 ГБ оперативки на машине разработчика хватало всем.
Но когда мы в рамках проекта MDT начали делать в EDT расширение для ERP и затянули в него конфигурацию ERP, таких ресурсов уже для комфортной текущей работы хватать перестало.
-
Машина разработчика для использования ERP в EDT – это 32 ГБ оперативки, 8 ядер, и то, EDT ресурсы кушает неравномерно, в некоторых сценариях он кушает все ресурсы и тормозит. Но в большинстве случаев ресурсы простаивают, мы их не утилизируем полностью.
-
Следующая особенность – мы стали подключать к разработке «старых» сотрудников с других проектов. Они оказались не такие энтузиасты, как разработчики MDT, им EDT не понравился как среда разработки – непонятны термины, непонятный GIT, непонятный интерфейс.
-
И EDT нас тоже «радовал» разными редкими, но меткими ошибками. Основные проблемы, с которыми мы сталкивались, происходили при слиянии конфигураций, потому что мы использовали ветки и часто мержили их. А EDT любит ошибаться при мержинге. В результате получается неработоспособная конфигурация, которая EDT смержила. Это проявляется не сразу, а позже, когда вы уже попробовали протестировать то, что получилось.
-
Еще одна проблема, с которой мы столкнулись – это то, что EDT при выгрузке конфигурации в базу для тестирования неожиданно по сложным условиям хочет делать полную выгрузку. Если использовать платформенный механизм частичной выгрузки, выгрузка из EDT – это минуты. А если EDT решил делать полную выгрузку, то выгрузка базы ERP целиком из EDT, чтобы собрать базу – это один час по времени. А нам нужна ритмичная разработка.
Поэтому уже на этапе разработки MDT мы придумали некие свои механизмы, которые позволили нам вести разработку из конфигуратора, используя при этом тот же репозиторий, что и разработчики, которые работают в EDT.
Предпосылки перевода разработки проектов на ERP в EDT

Следующий этап – это перевод на EDT проектов по внедрению ERP. Мы перевели их на EDT осенью прошлого года.
Я уже говорил, что у нас много проектов по внедрению ERP от 100 до 1000 пользователей. Мы в основном внедряем типовую ERP – там доработок мало.
В проектной команде у нас в среднем 7 человек, из которых 3 разработчика, параллельно работающих с кодом в EDT – до этого они так же успешно работали с хранилищем.
С переходом на EDT мы на ERP-шных проектах хотели решить следующие задачи:
-
Ускорить донесение изменений релиза до заказчика. Мы работаем по скраму, длина спринта две недели, мы хотели выпускать релизы не реже, чем раз в две недели. А лучше – каждый день.
-
И хотели сократить количество ошибок, чтобы потом их в проде не исправлять.

Я здесь специально заскриншотил, как выглядел процесс сборки релиза и переноса изменений в прод раньше, при использовании хранилища.
Был такой магический отчет, который показывает, какие задачи, лежащие в хранилище, проверены успешно или неуспешно.
И дальше нам нужно собрать релиз. За этот отчет садился очень умный человек и из той конфигурации, которая лежит в хранилище, вырезал те куски, которые тоже относятся к тем задачам, которые проверку не прошли (в которых есть ошибки), чтобы получить релиз только в работающими задачами.
Этот процесс – сложный, трудоемкий, несет в себе кучу ошибок и т.д. От этого процесса мы хотели избавиться при переходе на EDT.

Как выглядит разработка на проектах по доработке ERP (идеальный сценарий)
-
Проект начинается с дорожной карты, формируется бэклог задач. Для ведения задач мы используем Jira.
-
Дальше, как я говорил, у нас скрам. Период планирования у нас 2 недели. И раз в две недели мы должны собирать релиз.
-
Разработка по каждой задаче ведется в EDT или Конфигураторе и помещается в GIT. Jira с GIT хорошо интегрируются – если в коммитах вы указываете номера задач, то дальше из Jira вы можете подтянуть весь код, который относится к этой задаче.
-
Изменения по всем задачам помещаются в ветки, и только того, как все задачи проверены, изменения из веток переливаются в мастер. Таким образом в мастере у нас гарантировано только работающий релиз. В любой момент времени можем из мастера собирать релиз для клиента, ему передавать – сложная операция «выкрыжить все неработающее из конфигурации» не требуется.
-
Также у нас используется так называемая staging-база – это копия рабочей базы заказчика, которая обновляется из веток. На ней мы демонстрируем задачу клиенту до того, как их мержить в мастер.
-
После того как задача продемонстрирована клиенту, проверена на ветке. Из ветки делается пул-реквест и задача попадает в мастер.
-
И среда разработки у нас отделена от рабочей среды. Из мастера мы собираем cf-файл, который дальше передаем в рабочую среду и накатываем там на рабочую базу, в рабочее хранилище и т.д. – в зависимости от того, как устроено.
-
Сама разработка у нас ведется либо в EDT (мелкие задачи) либо в конфигураторе через специальные скрипты изменения помещаются в GIT.

Напомню, ради чего затевался переход на EDT
-
Это быстрые релизы (от одного релиза в две недели до нескольких релизов в день)
-
И сокращение количества привнесенных ошибок
Как выглядит процесс разработки
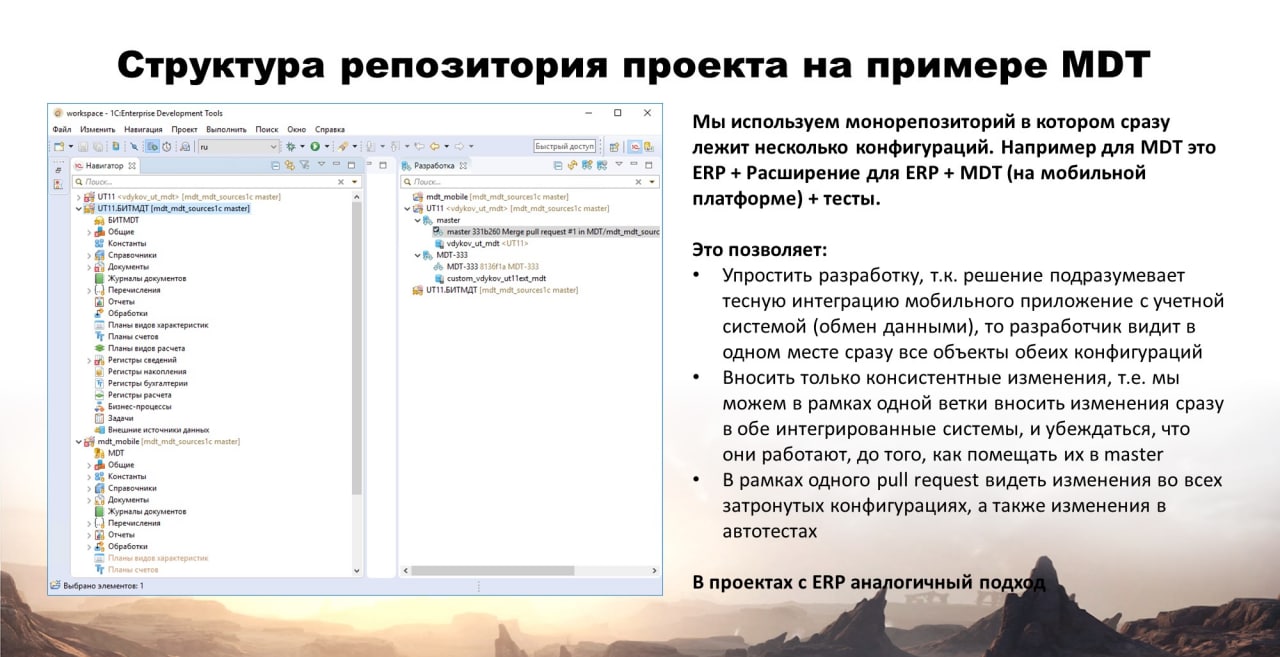
Итак, переходим дальше – как у нас выглядит структура нашего репозитория на примере проекта MDT.
Мы используем моно-репозиторий. Что это такое? У нас в одном репозитории лежит сразу несколько конфигураций. Это касается как MDT, так и других проектов. Если проект подразумевает обмен между несколькими базами и одновременную разработку нескольких конфигураций, мы все эти конфигурации кладем в один репозиторий.
Что это позволяет сделать?
-
Во-первых, упростить саму разработку. Если нужно доработать обмен данных из одной базы в другую, у тебя обе конфигурации находятся в одном интерфейсе – ты можешь сразу подправить и в одном, и в другом модуле. Исправляешь в одном контексте.
-
Также ты можешь тестировать изменения, которые касаются нескольких баз, в отдельной ветке – тестировать в этой ветке обмен и все остальное. Это позволяет делать консистентные изменения.
-
Когда ты делаешь пул-реквест, у тебя за раз в мастер попадают изменения сразу во всех конфигурациях, которые на этом проекте используются. Это очень удобно.
На слайде показан пример с проекта MDT, но на проектах ERP подход аналогичный.

Как у нас выглядит процесс разработки?
Разработчик берет очередную задачу в Jira, и дальше у него есть два пути.
-
Если задача большая, то он в EDT создает отдельную ветку с номером задачи, подключает к ней отдельную базу, и дальше у него есть один час заняться какими-нибудь другими делами пока конфигурация базы подтянется к конфигурации ветки.
-
Если задача небольшая, у нас у разработчиков есть отдельная своя ветка для текущих работ, а к ней уже подключена отдельная база. В этой ветке разработчик может быстро исправлять мелкие задачи. Он просто обновляет свою ветку из master и актуализирует изменениями свою базу разработки – как правило, это происходит достаточно часто, поэтому полное обновление базы не требуется, ждать ничего не нужно.
И как я говорил, вся разработка ведется в отдельной ветке, в master напрямую никакие изменения класть нельзя.

В процессе разработки разработчик вместе с консультантом готовит новые BDD-тесты либо адаптирует существующие:
-
Для тестирования мы используем Vanessa Automation,
-
Тесты у нас лежат в том же репозитории, где и код – соответственно, у нас в одной ветке измененные тесты и измененный код. И одним пул-реквестом мы принимаем измененные тесты и измененный код.
После того как код написан, разработчик оформляет pull request в master:
-
еще раз забирает конфигурацию из master и мержит ее в свою ветку;
-
запускает тесты;
-
и только после этого делает pull request.
Такая последовательность обязательна, она позволяет избежать мерж-конфликтов на этапе мержинга, сокращает затраты на создание и работу с пул-реквестом
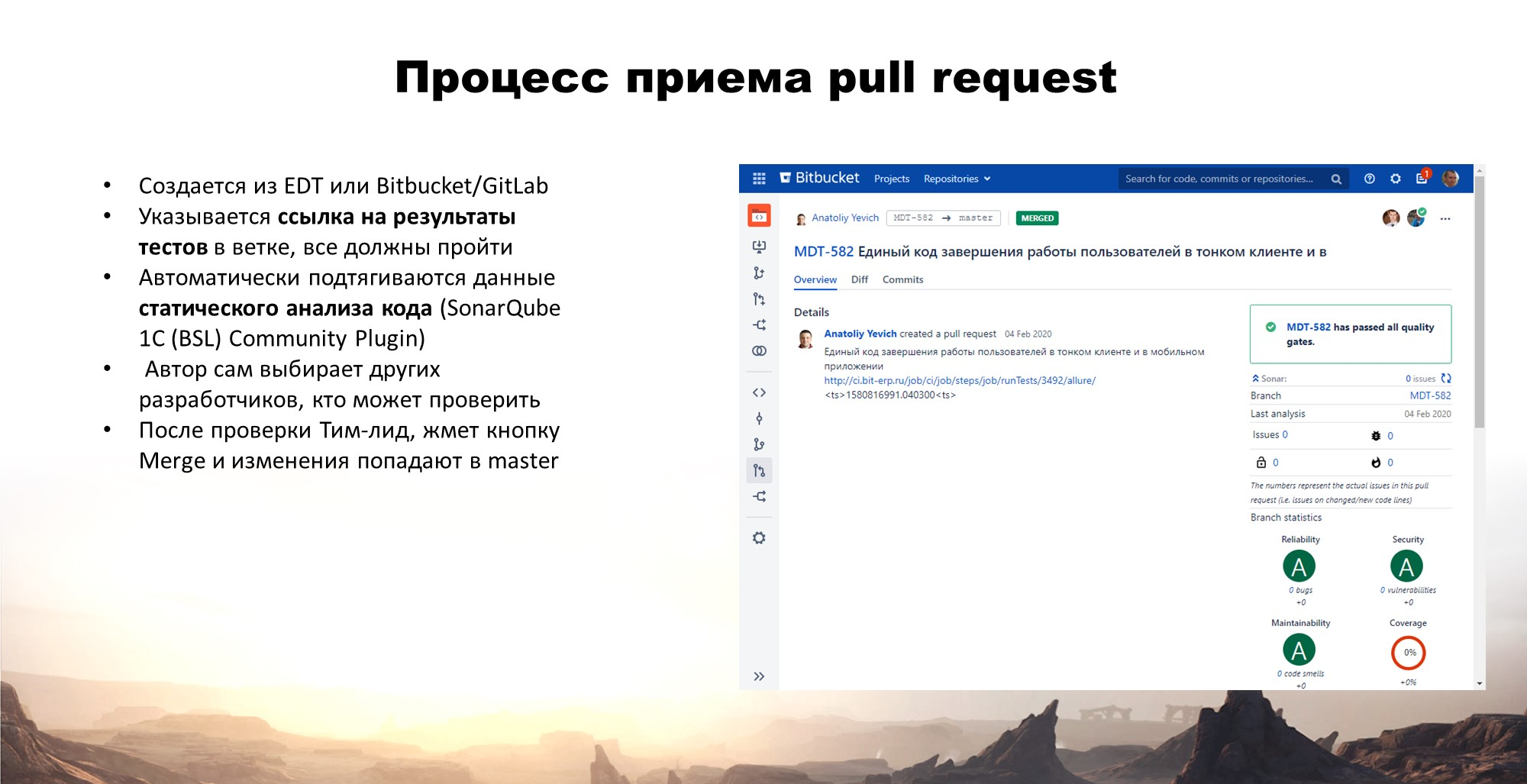
Принимается пул-реквест средствами того облачного репозитория, который вы используете.
-
Создается пул-реквест – его можно создавать сразу из EDT или из веб-интерфейса.
-
В тексте пул-реквеста мы сразу указываем ссылку на отчет Allure, который подтверждает, что тесты в этой ветке прошли. Сюда же в пул-реквест у нас также подключен SonarQube, чтобы сразу видеть ошибки в коде.
-
После проверки пул-реквеста тимлид мержит его в master.
Минусы разработки в EDT

С какими минусами, проблемами мы столкнулись, и зачем нужно сделать что-то еще.
-
Первая проблема – это то, что вносить изменения при помощи EDT получается медленнее, чем при использовании конфигуратора. В EDT очень неудобно отлаживать. Когда ты накодировал какую-то задачу и тебе нужно ее отлаживать – многократно запускать конфигурацию с мелкими изменениями – если это делать в конфигураторе, это делается достаточно быстро. А в EDT запуск отладки занимает значительно дольше времени, чем из конфигуратора. Поэтому наши разработчики стали жаловаться, что после того как ты написал задачу и ее нужно отладить с многочисленными повторными изменениями, из EDT это занимает гораздо больше времени. Но если ты разрабатываешь маленькие конфигурации, то проблемы нет – из EDT они запускаются с той же скоростью, что и из конфигуратора.
-
Дальше – про ошибки. Ошибки в EDT, связанные с мержингом, с полным обновлением – не исчезли, они так и остались. Свежий пример – в EDT 2020.6 наше решение в принципе не открывалось. Привнесли ошибку. А в EDT 2020.6.2 эту ошибку уже поправили. Т.е. ошибки EDT появляются и исчезают – в целом ситуация не сильно улучшается.
-
И обычные разработчики, которых мы привлекаем – «старые» 1С-ные разработчики – им с EDT сложно, они привыкли решать задачи клиентов, а не разбираться в новых технологиях и в EDT.
Скрипты, чтобы разрабатывать в конфигураторе, а вести разработку в GIT

Что мы сделали, чтобы решить эту проблему?
Обычная работа из EDT с GIT выглядит так: мы в EDT нажимаем кнопку «Получить изменения из GIT» и «Положить изменения в GIT». И дальше EDT все делает само – EDT фактически работает с исходным кодом как есть.
Мы сделали два скрипта, которые позволяют делать то же самое из конфигуратора. Эти два скрипта мы добавили как заявки в наш Service Desk.
Первый скрипт – поместить изменения в ветку
Что делает этот скрипт?
Разработчик разрабатывает в конфигураторе как обычно, отлаживается в конфигураторе. И хочет поместить свои изменения в GIT. Он в Service Desk запускает заявку и говорит: «Хочу поместить изменения из этой базы в эту ветку в GIT».
-
Скрипт делает копию базы – у нас базы SQL-ные, поэтому из конфигуратора выходить не нужно.
-
Из копии выгружает конфигурацию в файлы.
-
Запускает утилиту ring, которая конвертирует код в формат EDT.
-
И кладет ветку в GIT.
Таким образом, с одним и тем же репозиторием мы можем работать и из конфигуратора, и из EDT.
Часть разработчиков – молодые, модные, современные – работают в EDT, а часть разработчиков работает в конфигураторе и пользуется заявками в Service Desk
Второй парный скрипт – позволяет получить изменения из GIT в конфигуратор
Этот скрипт тоже представлен в виде заявки в Service Desk. При выполнении он:
-
получает исходный файл из GIT;
-
конвертирует с помощью утилиты ring в платформенную выгрузку;
-
забирает конфигурацию в cf;
-
и эту cf-ку отдает разработчику.
Дальше, если разработчик хочет эти изменения включить в конфигуратор в свою ветку, через Сравнение-Объединение он из этой cf эти изменения получает.
Таким образом, мы обеспечили работу с одним и тем же репозиторием – как с использованием конфигуратора, так и с использованием EDT.
Таким образом, мы можем подключать разработчиков, использующих разные инструменты при своей работе.

В каких случаях мы используем один подход, а в каких случаях – другой?
-
Новые сотрудники, которые с EDT не знакомы, которых мы привлекаем с других проектов, начинают работу с конфигуратора. А потом или переходят на EDT, или не переходят.
-
Мелкие простые задачи мы стараемся делать в EDT, потому что это сделать просто.
-
А длинные сложные задачи, которые делаются несколько дней (неделю или две недели), мы стараемся сейчас делать в конфигураторе.
-
Если в очередной версии EDT возникают какие-то проблемы, мы просто все переходим на конфигуратор и ждем, пока выйдет версия EDT, где эти проблемы исправлены. А потом часть людей возвращается назад на EDT. Т.е. мы в любой момент можем переключиться туда или сюда.
Важно отметить, что использование GIT очень хорошо сочетается с автотестами.
-
В EDT как только ты положил изменение в ветку, ты можешь автоматически их проверить и результаты приложить к пул-реквесту.
-
Наиболее эффективно работать с GIT когда ветки долго не живут – важно сразу, как только ты изменения в ветку внес, протестировать и положить в master. Потому что иначе в master успеют положить изменения другие разработчики или тебе придется тратить отдельное время, чтобы объединить твои изменения с чужими изменениями, которые там уже оказались.
-
А быстро помещать ветки в мастер позволяет как раз использование автотестов. Наши ушлые разработчики, особенно, когда изменение маленькое, вообще в режиме «1С:Предприятие» свои изменения не отлаживают. Он в EDT внес изменения в какой-то простейший модуль, положил в GIT, запустил автотесты и пошел заниматься другими задачами. Он в режиме 1С:Предприятие даже не запускал эту базу. Но автотесты прошли, все зеленое, изменения мержим в мастер.
Если вы будете делать такие скрипты у себя – на что хочу обратить внимание.
-
Желательно все кешировать. Как правило, разработчику нужно получать текущую конфигурацию из master-ветки, поэтому как только первый разработчик такой cf-ник с последним коммитом из master сформировал, мы можем сохранить его в кеше. И дальше, когда следующий разработчик захочет получитть текущую конфигурацию, мы можем сразу отдать ему готовый cf, а не формировать его заново. Это ускоряет работу с этими заявками.
Теперь о грустном – что у нас в результате получилось

Напомню, какие цели мы ставили – это ускорить выпуск релизов и сократить ошибки в продуктиве. На всех новых проектах, начиная с осени, мы попробовали использовать GIT и EDT.
С какими препятствиями мы столкнулись?
-
Когда у сотрудников появился выбор – пользоваться в качестве хранилища GIT, но кодить либо в конфигураторе, либо в EDT – выяснилось, что большинство сотрудников в качестве IDE выбрали кодить в конфигураторе. Сейчас по факту EDT использует где-то 10% наших сотрудников. А GIT используется на всех наших коробочных продуктах и только на 20% ERP-шных проектах.
-
Дальше выяснилось, что разработка с использованием GIT хорошо зашла на коробочных продуктах – там, где у нас используются автотесты. Это произошло из-за того, что нам удалось там поменять процесс разработки и выстроить его так, чтобы задачи делались быстро и ветки мержились в master быстро. У нас фактически на коробочных продуктах ветки больше 1-2 дней не живут, они попадают в master.
-
На проектах ERP так сделать не получилось, там автотестов нет, задачи проверяют пользователи, и ветки живут долго. Так как мы работаем спринтами, у нас есть план задач на спринт, на две недели. И получается так, что остается два дня до конца спринта, и большинство задач не в master, они проверяются или только что проверены пользователями. И в последние два дня всем разработчикам проекта нужно взять и смержить свои изменения в master одновременно. А что такое смержить изменения в master? Это сравнить и объединить свои доработки с теми изменениями, которые уже есть в master и потом только положить туда. Т.е. на ERP-проектах ветки живут до конца спринта, накапливается куча изменений и потом в конце спринта возникает очередь – все выстраиваются по одному, чтобы положить свои изменения в один общий мастер. Эту проблему мы пока победить не смогли.
Когда планируем сделать следующую попытку перейти в EDT в части ERP-шных проектов?
-
Первое – мы ждем, что EDT станет стабильнее и радикально быстрее работать с конфигурациями уровня ERP. Наша основная конфигурация – ERP, нам нужно, чтобы EDT стабильно и быстро работала с ERP.
-
Возможно, нам станет проще, когда разработку для ERP-шных проектов мы сможем вести только в расширениях. Сейчас расширения не поддерживают весь набор объектов, который есть в конфигурации, но если они будут поддерживать, то в принципе, работать с расширениями для ERP в EDT можно достаточно быстро, и проблем нет. EDT сохраняет только расширение – расширение, как правило, маленькое. Даже если в нем ведется много доработок по проекту, само расширение гораздо меньше, чем основная конфигурация. Поэтому если в ERP вы вносите изменения только в расширение, проблем со скоростью работы нет, в EDT работать можно.
-
И мы научимся делать эффективные автотесты, которые сможем использовать повсеместно на ERP-шных проектах.
Используйте CI/CD

Теперь немного про CI/CD и почему его важно использовать, если вы используете GIT и EDT.
-
Во-первых, это легко. У нас весь исходный код уже есть в репозитории, нам не нужно его ниоткуда брать, ниоткуда конвертировать.
-
Дальше – у нас запуск тестов сделан через отдельную заявку, тесты выполняются в отдельных базах и никак не мешают разработке. Разработчик разрабатывает в своей базе, положил изменения в ветку, запустил заявку на тестирование и все – дальше оно само где-то тестируется. Разработчика это никак от работы не отвлекает.
-
И, соответственно, при использовании автотестов можно быстро мержить ветки в master. А это является узким местом при использовании EDT и коллективной разработки. Вы можете быстро проверить свои изменения автоматически, не ожидая проверки от пользователей, и положить свои изменения в master.
-
И дополнительный бонус – EDT дает много возможностей по рефакторингу. И если у вас есть автотесты, рефакторинг гораздо проще делать, особенно в EDT, которая часто ошибается при рефакторинге. Т.е. вы что-то отрефакторили средствами EDT, запустили автотесты и убедились, что ничего не сломали. Без этого рефакторингом заниматься сложно.
Немного картинок

Покажу, как у нас это выглядит. На слайде – пример коммита, сделанного в репозиторий EDT.

Вот так выглядит наш Service Desk, из которого мы запускаем заявки.
-
Если этот коммит нужно протестировать, разработчик кладет изменения и запускает интерактивное тестирование в этой ветке.
-
Здесь же, в этом же Service Desk есть возможность получить cf-ник из GIT по команде «Собрать конфигурацию из ветки».
-
И здесь же есть заявки на помещение изменений в ветку, когда нам нужно из какой-то базы поместить изменения в ветку.
Разработчик пользуется этим Service Desk, чтобы работать с GIT. В принципе, разработчику не нужно знать ни команды работы с GIT, ни разных особенностей работы GIT. В общем случае, он пользуется конфигуратором и пользуется заявками.
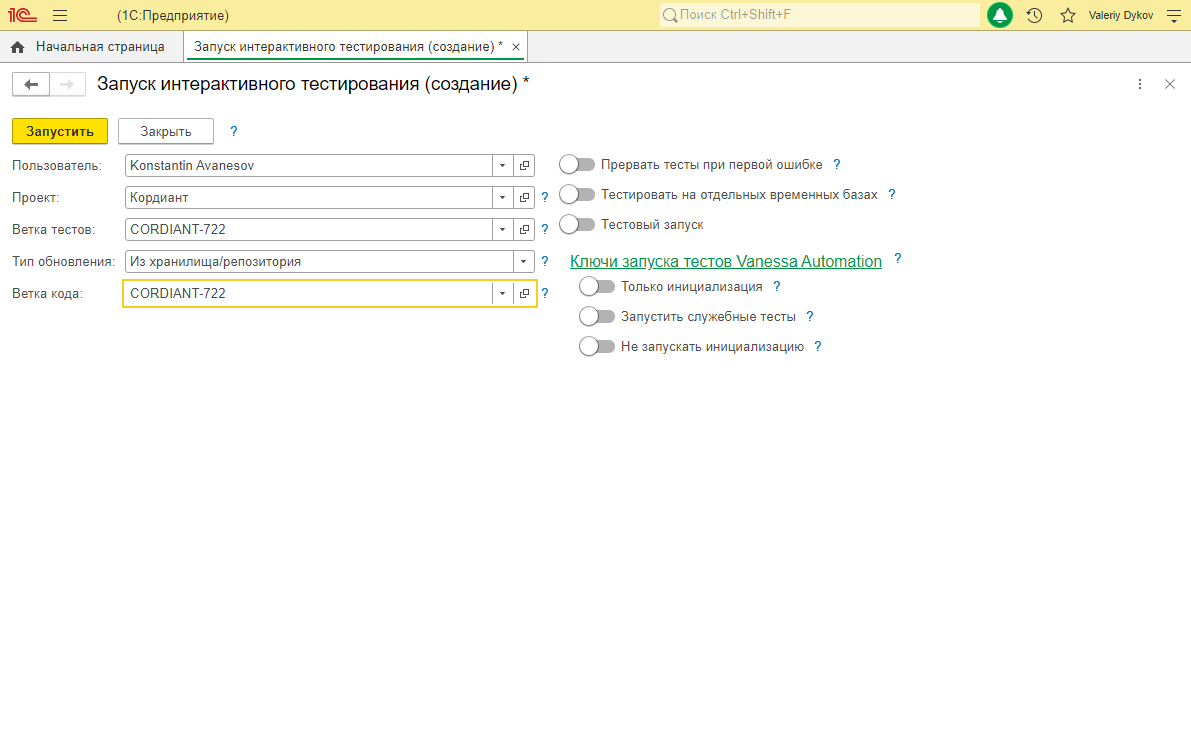
Вот так у нас выглядит заявка на запуск интерактивного тестирования.
Пользователь выбирает, по какому проекту из какой ветки взять тесты, из какой ветки взять код, и запускает тесты на копии своей базы.

В результате после того как все тесты прошли, разработчику приходит об этом сообщение. У нас все уведомления уходят через Slack – это наш основной мессенджер.

И дальше отсюда же из Slack разработчик идет в отчет Allure, находит, где именно упало, исправляет код, заново кладет его в репозиторий и заново запускает тесты. Процесс разработки в картинках выглядит таким образом.
При этом неважно, где разработчик кодит – он может это делать либо в конфигураторе, либо в EDT, но изменения все попадают в один и тот же репозиторий.
Выводы

Какие выводы можно сделать из всего этого?
-
На данный момент самый идеальный вариант для использования EDT на нашем опыте – небольшие самописные конфигурации, над которыми работает один-два, максимум три человека. В этом случае никаких проблем не будет, использовать можно, никаких сложностей, все отлично.
-
EDT можно использовать и для более крупных проектов, в том числе для ERP. Но в этом случае требуются разные ухищрения. Например, наши скрипты, которые позволяют из конфигуратора помещать изменения в репозиторий и извлекать изменения из репозитория. И прочие фишки – можно к каждой ветке привязывать отдельную информационную базу в EDT, в этом случае между ветками можно быстро переключаться, не ждать кучу времени.
-
Дальше – разработка с использованием GIT хорошо сочетается с автотестами. Во-первых, проще принимать пул-реквесты, потому что они автоматически проверены, и можно делать короткоживущие ветки, которые потом просто мержить.
-
И хорошо использовать некий свой Service Desk или некий интерфейс, куда можно спрятать всю сложность работы с GIT от разработчиков, и пользоваться просто заявками из Service Desk.
Вопросы
Почему вы использовали какой-то свой Service Desk при наличии Jira? Там же тоже есть все компоненты CI/CD.
В 2020 году еще мы использовали Service Desk в Jira Server, у нас была доработанная функциональность – доделаны эти заявки с запусками по плану и т.д. Но, как вы знаете, с 2021 года Jira стала только облачной, они больше десктопные серверные лицензии не продают. Поэтому в связи с общей политикой Jira мы решили, что мы переедем в облако, кучу кода, который был написан для старого Service Desk, выкинем и будем пользоваться простеньким 1С-ным Service Desk.
Но кроме Jira можно же использовать в GitLab компоненты CI/CD – runner и все эти моменты?
Но мы же говорим про интерфейс, с которым работают конечные разработчики – им нужно по-простому быстро что-то запустить. Конфигурация на 1С – это временное решение, связанное с тем, что мы переезжали с нашего Service Desk в Jira Server. Сделали себе по-быстрому в 1С такой же интерфейс.
*************
Данная статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2021 Post-Apocalypse.

Вступайте в нашу телеграмм-группу Инфостарт
