Символы в 1С
Типа "Символ" в 1С нет, с символами мы можем работать только в составе строки, либо как с числовым кодом таблицы Unicode.
Доступные функции работы с символами:
Символ(КодСимвола) - возвращает символ (строку) по кодовой позиции Unicode.
КодСимвола(Строка, НомерСимвола) - возвращает код символа Unicode в строке .
Простой пример:
КодСимвола = КодСимвола("Б"); // Результат: 1041
Символ = Символ(1041); // Результат: Б
Длина = СтрДлина(Символ); // Результат: 1
Код символа, который мы получили является кодовой позицией в таблице символов Unicode.
Unicode - это набор графических символов, в котором каждому символу соответствует числовой код (кодовая позиция или кодовая точка). Кодировка - это способ кодирования этого числового кода (например, UTF-16).
Каждой значимой позиции Unicode соответствует какой-то символ. Не для всех кодовых позиций определен какой-то символ, бОльшая часть позиций "пустая".
Следует различать графический символ и символ как единица текста в 1С. Графический символ - это, то что мы видим на экране монитора. Не для каждого графического символа есть кодовая позиция в таблице Unicode, некоторые графические символы могут получаться как комбинация нескольких кодовых позиций. И эти кодовые позиции будут отдельными символами (здесь речь про единицу текста) в переменной типа "Текст" или в базе данных, хотя в "пользовательском" режиме видеть мы будем только один графический символ.
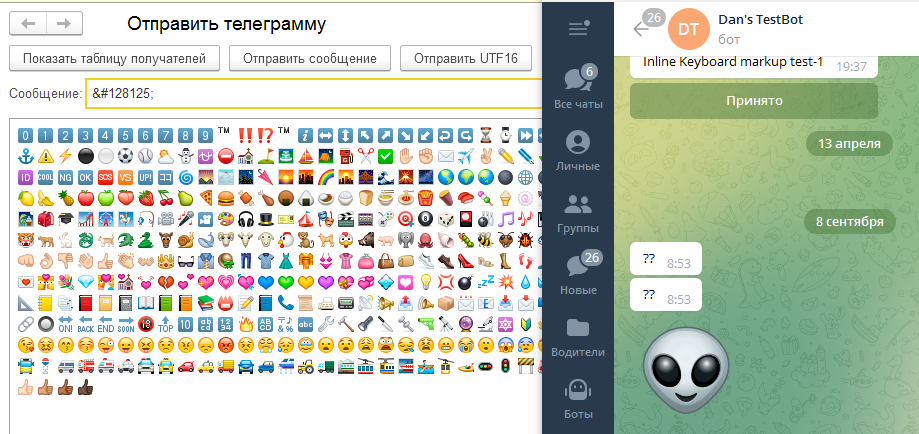
Мы можем взять любой символ из таблицы Unicode и добавить его в свою строку. Например, символ изображающий инопланетянина: 👽. Кодовая позиция, соответствующая данному символу - 1F47D. В 1С мы не пользуемся шестнадцатеричным представлением, поэтому преобразуем в десятичную: 128125. Попробуем получить символ в 1С по кодовой позиции:
Символ = Символ(128125); // Результат: <пустая строка>
Длина = СтрДлина(Символ); // Результат: 0
Не совсем тот результат, который ожидали. Дело в том, что для хранения представления кодовой позиции Unicode требуется до 4 байтов, а для работы с текстом в 1С используется кодировка UTF-16. В этой кодировке для хранения одной кодовой позиции используется либо 2, либо 4 байта.
Если хранить абсолютно любой символ как 4 байта, это достаточно затратно с точки зрения использования памяти, т.к. большинство используемых символов умещаются в базовую многоязыковую плоскость (первые 65535 символов), для которой достаточно всего 2-х байтов. И UTF-16 как раз использует для хранения частоиспользуемых символов 2 байта (кодовая единица), а если кодовое представление не умещается, то использует уже 4 байта (2 кодовых единицы). И чтобы показать, что это 4 связанных байта, а не две отдельные кодовые единицы, используют суррогатные пары. Суррогатные они потому, что их вычисляют на основании исходной кодовой позиции. Т.е. для этих пар нет соответствия в кодовой таблице.
В стандарте для этого выделили целый диапазон значений, который используется для обозначения подобных символов. Это служебные диапазоны и им не соответствуют никакие значимые символы. Диапазоны:
- 0xD800 до 0xDBFF (от 55296 до 56319) - для первой кодовой единицы (верхняя часть пары)
- 0xDC00 до 0xDFFF (от 56320 до 57343) для второй кодовой единицы (нижняя часть пары).
Если попробуем получить символ из этих диапазонов, то получим неопределенный символ, который для разных шрифтов может отображаться по-разному (пробел, знак вопроса, пустой квадратик). Этот символ будет иметь длину.
Символ = Символ(56323); // Результат: <пустой символ>;
Длина = СтрДлина(56323); // Результат: 1
Кодовая позиция нашего инопланетянина (128125) больше границы базового диапазона в 2 байта (65535) и для него нам надо вычислить суррогатную пару.
Функции получения значений суррогатной пары и обратного получения кодовой позиции:
Пара = ПолучитьСуррогатнуюПару(128125); // Результат: ВерхняяПара = 55357, НихняяПара = 56445
Позиция = ПолучитьКодовуюПозицию(Пара.ВерхняяПара, Пара.НихняяПара); // Результат: 128125
Функция ПолучитьСуррогатнуюПару(КодоваяПозиция)
Результат = Новый Структура("ВерхняяПара, НихняяПара");
Результат.ВерхняяПара = ПобитовыйСдвигВправо(КодоваяПозиция, 10) + (55296 - (ПобитовыйСдвигВправо(65536, 10)));
Результат.НихняяПара = ПобитовоеИ(КодоваяПозиция, 1023) + 56320;
Возврат Результат;
КонецФункции
функция ПолучитьКодовуюПозицию(ВерхняяЧасть, НихняяЧасть)
Возврат (ПобитовыйСдвигВлево(ВерхняяПара, 10) + НихняяПара) + (65536 - (ПобитовыйСдвигВлево(55296, 10)) - 56320);
КонецФункции
Происходит преобразование двух 16-разрядных значений в одно 21-разрядное. Программа (в нашем случае 1С), обрабатывающая такие символы, понимает, что код символа попадает в верхний или нихний диапазон суррогатного значения, и обрабатывает такой символ особым образом.
Для нашего символа с кодовой позицией 128125 пара будет такой: 55357 (верхняя часть) и 56445 (нижняя часть). Если будем использовать, например, для записи в JSON, то "\ud83d" и "\udc7d" (преобразовали в HEX и добавили "\u" вначале).
Все что нам остается, это получить оба символа и объединить в одну строку:
Символ = Символ(55357) + Символ(56445); // Результат: 👽
Длина = СтрДлина(Символ); // Результат: 2
Сообщить(Символ);
Вывод в режиме предприятия:

Обратите внимание, что строка имеет длину равную 2, но отображаются эти два символа как один.
Также следует обратить внимание, что бывают символы, которые состоят из двух кодовых точек, но при этом они не являются суррогатной парой. Например символ "й", который можно получить двумя способами:
- введя привычный нам кириллический символ "й"
- используя два символа - киррилическое "и" (1080) и "верхняя дуга" (774) (комбинируемый диакритический знак).
Символ "верхняя дуга" не смог вставить в текст, т.к. редактор инфостарта некоторые Unicode символы меняет на что-то непонятное. Так что получите их самостоятельно.
Символ = Символ(1080) + Символ (774); // Результат: й;
Длина = СтрДлина(Символ); // Результат: 2
Сообщить(Символ = "й"); // Результат: Ложь, т.к. строки различаются
Внешне выглядят эти два графических символа одинаково, но состав символов в строке разный.
В базе данных подобные значения прекрасно хранятся и обрабатываются. А редактирование строк с такими символами в пользовательском режиме ничем не отличается от обычных.
Работа со строками в 1С
Т.к. для 1С суррогатная пара и составной символ это два разных символа, то и работает она с ними по-отдельности.
СуррогатнаяПара = Символ(55357) + Символ(56445); // Результат: 👽
СоставнойСимвол = Символ(1080) + Символ (774); // Результат: й
ПервыйСимвол1 = Лев(СуррогатнаяПара, 1); // Результат: <пустой символ> (55357)
ПервыйСимвол2 = Лев(СоставнойСимвол, 1); // Результат: и (1080)
Строка = "Зелены" + СоставнойСимвол + " " + СуррогатнаяПара + " человечек"; // Результат: Зеленый 👽 человечек
// Поиск отрабатывает с учетом длины составного символа (2)
Позиция = СтрНайти(Строка, СуррогатнаяПара); // Результат: 10
// Каждый символ будет считаться разделителем, поэтому появляется лишняя пустая строка
МассивСтрок = СтрРазделить(Строка, СуррогатнаяПара); // Результат: 3 элемента
// Для обычной "и" прописаны правила преобразования в верхний регистр, поэтому все проходит хорошо
// Символ с инопланетяниным остается неизменным
СтрокаВРег = ВРег(Строка); // Результат: ЗЕЛЕНЫЙ 👽 ЧЕЛОВЕЧЕК
КодСимвола = КодСимвола(СтрокаВРег, 7); // Результат: 1048
Как и ожидалось - каждый символ учитывается отдельно. Отличий в поведении для составных символов или суррогатных пар нет.
Для СтрРазделить оба символа уже будут разделителями, поэтому надо быть с этим осторожным. В остальном каких либо различий нет. В запросах поведение схожее.
Вступайте в нашу телеграмм-группу Инфостарт