
Я – архитектор 1С.
Вообще к архитекторам у всех разное отношение. Каждый считает, что архитектор должен делать что-то свое:
-
кто-то считает, что это вообще руководитель проекта;
-
кто-то видит его релиз-инженером;
-
кто-то – руководителем программистов;
-
а мы сейчас поговорим о ситуации, когда архитектор является специалистом по производительности.
На картинке я просто привел реальные требования из вакансий на HeadHunter, чтобы вы оценили, насколько разными могут быть представления об архитекторе 1С в разных компаниях.
Как обозначить проблемы и быстро познакомиться с вверенной тебе системой

Почему «первый день»?
-
Чем с большим количеством странностей и проблем мы столкнемся в первый день, тем легче нам будет в последующем – это во-первых.
-
Во-вторых, не секрет, что между одинесниками и админами не все гладко. Антон Дорошкевич вчера говорил о том, что нужно примирить админов и одинесников – это правда. Я постоянно с этим сталкиваюсь. Даже когда говорят, что у нас все хорошо, и мы дружим, на самом деле – все плохо. Админы говорят: «Мы поставили вам сервер, делайте с ним что хотите». Одинесники говорят: «Он не настроен». Админы говорят: «Мы ничего не знаем, мы настроили его, работайте». Если мы сразу же в первый день увидим проблемы и обозначим их, они быстрее решатся.
Обычно проблемы решаются очень долго, особенно если компания крупная. Любое изменение в системе надо обосновывать. Почему-то когда админы ставили MS SQL Server инсталлятором: «Далее», «Далее», «Далее» – это никто не обосновывал. А когда в нем нужно сделать какую-то настройку – на это уже, пожалуйста, напишите документ и четко обоснуйте, что нужно сделать и зачем. Только тогда мы сделаем.
Ну ладно, окей.

Обычно архитектора 1С в курс дела вводит какой-то технический специалист, если он имеется, или руководитель. Какие данные у него нужно запросить?
-
Получаем список серверов 1С, причем всех.
-
прод, очевидно;
-
препрод или же сервер, на котором развернуты базы «минус день»;
-
и сервер, на котором развернут контур или контура для разработки.
-
-
К этим серверам потребуется доступ к терминалу – нам нужно будет зайти на него через удаленный доступ.
-
Получаем список баз 1С – рабочие, вспомогательные, тестовые. Для чего это нужно? Часто бывает такая ситуация, когда ты приходишь в организацию для аудита, и тебе говорят: «У нас ничего в разработке нет, только одна ERP». Ты заходишь, а на сервере еще 30 баз. Это нужно как раз для того, чтобы понять общую картину.
-
И получаем доступ к серверам SQL – здесь достаточно запросить доступ только к консоли для выполнения запросов. Мы с вами мастера SQL, умеем получать информацию о сервере, выполняя запросы.
-
Также немаловажно получить доступ к серверу мониторинга – не к самому серверу, а к его визуальному представлению, чтобы посмотреть, что мониторится.
-
И я сразу же обговариваю получение доступа к хранилищу 1С и к серверу исходного кода – позже расскажу, для чего.
Мониторинг

Начну с конца – мониторинг:
-
бывают ситуации, когда его совсем нет;
-
когда он есть, и он прям хороший;
-
и ситуации, когда он вроде как есть, что-то мониторится, но это не дает внятной информации о происходящих процессах.
Например, на картинке – реальный список замеров из Zabbix реального сервера 1С. Посмотрим, что у нас админы мониторят в Zabbix:
-
утилизацию CPU
-
дисковое время на C: и D:
-
свободное место на дисках C: и D:
-
свободную память,
-
ping
-
in и out сети.
Этого далеко не достаточно. Часто, когда пользователи жалуются о том, что сервер тормозит, такой мониторинг показывает, что процессор не загружен, память есть, все хорошо. Вот если бы мы хотя бы сюда добавили такой показатель, как очередь процессора – было бы нагляднее.
Расскажу реальный случай: в одной организации была настроена распределенная база на 150 узлов, и все эти 150 узлов пытались обменяться одновременно. Процессор на этом сервере был 36-ядерный и, когда эти 150 сеансов обмена успешно запускались, мониторинг показывал, что процессор не загружен. Но при этом все тормозило. И оказалось, что причина торможения – то, что сервер 1С использовался версии ПРОФ, а в ПРОФ-версии используется только 12 ядер.
Но ни один из приведенных показателей загрузку не показывал. Значение было только у счетчика очереди процессора – если все хорошо, очередь процессора у нас ничего не показывает.
Тут нет никакого секретного знания, в интернете полно информации о том, как настроить счетчики. Это может сделать любой одинесник, любой человек, у которого есть доступ.
Как пример, статья на Инфостарте, из которой я взял шаблоны настройки и их использую.
Исходный код, хранилище 1С
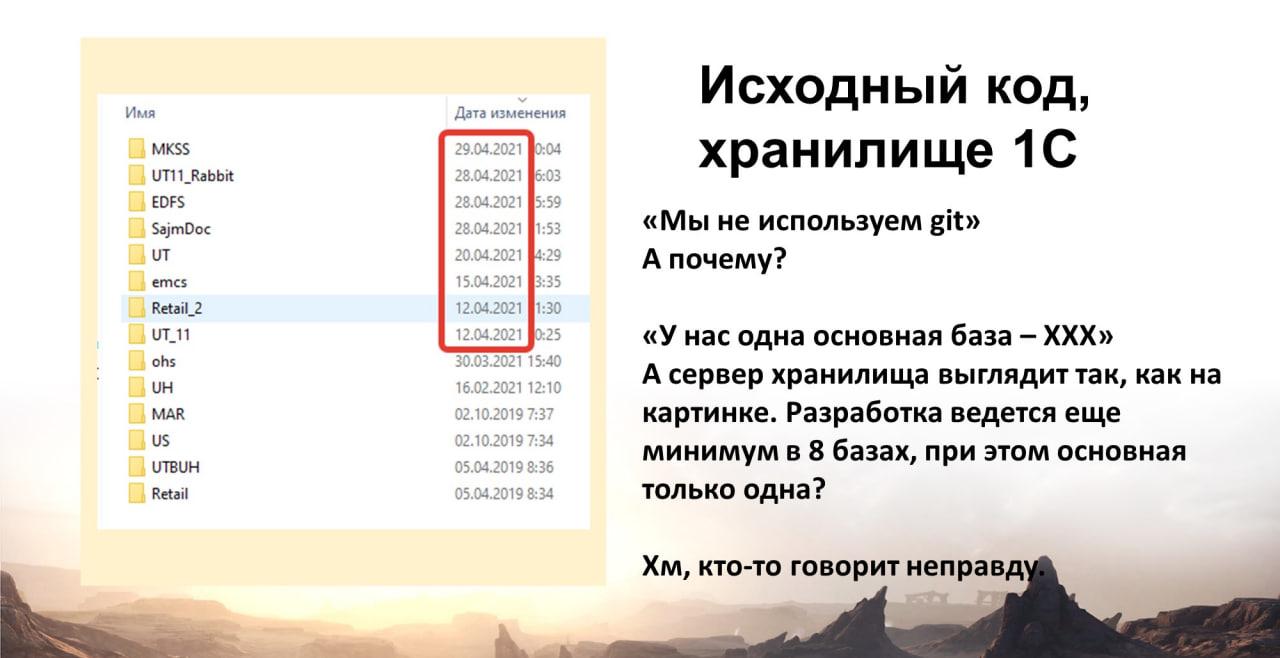
Рекомендую всем использовать выгрузку хранилища в исходный код Git – это реально очень удобно.
Я согласен, что в продуктиве это не всем заходит, не все видят необходимость. Но я как архитектор 1С уже просто не могу без этого жить. Даже если в организации так делать не принято, и своего Git-сервера нет, я чисто для себя настраиваю выгрузку из хранилища в исходный код и мониторю все изменения.
-
Один из последних примеров: как у нас обычно бывает – вчера все было хорошо, а сегодня тормозит. Внезапно в базе начались какие-то проблемы – страшные блокировки при проведении перемещения. При этом я знаю, что несколько дней назад в модуль проведения документа «Перемещение» добавили некий код. Я захожу в Git и вижу, что действительно, новый код увеличил транзакцию проведения. По технологическому журналу подтвердилось, что именно это вызвало проблемы. Дали по голове программисту, исправили код, все стало хорошо. Это – первый момент.
-
Второй момент – смотрим хранилище. На слайде список баз хранилища из организации, в которой две основных базы – УТ11 и Розница. А в хранилище почему-то больше десяти баз. Как это? У нас две основных базы, но разрабатываем мы еще кучу – так вообще бывает? Может быть эти базы со свежим временем изменения тоже важны и за ними тоже надо следить (в хорошем смысле)?
Сервер 1С. Технологический журнал. Анализ настроек сервера 1С
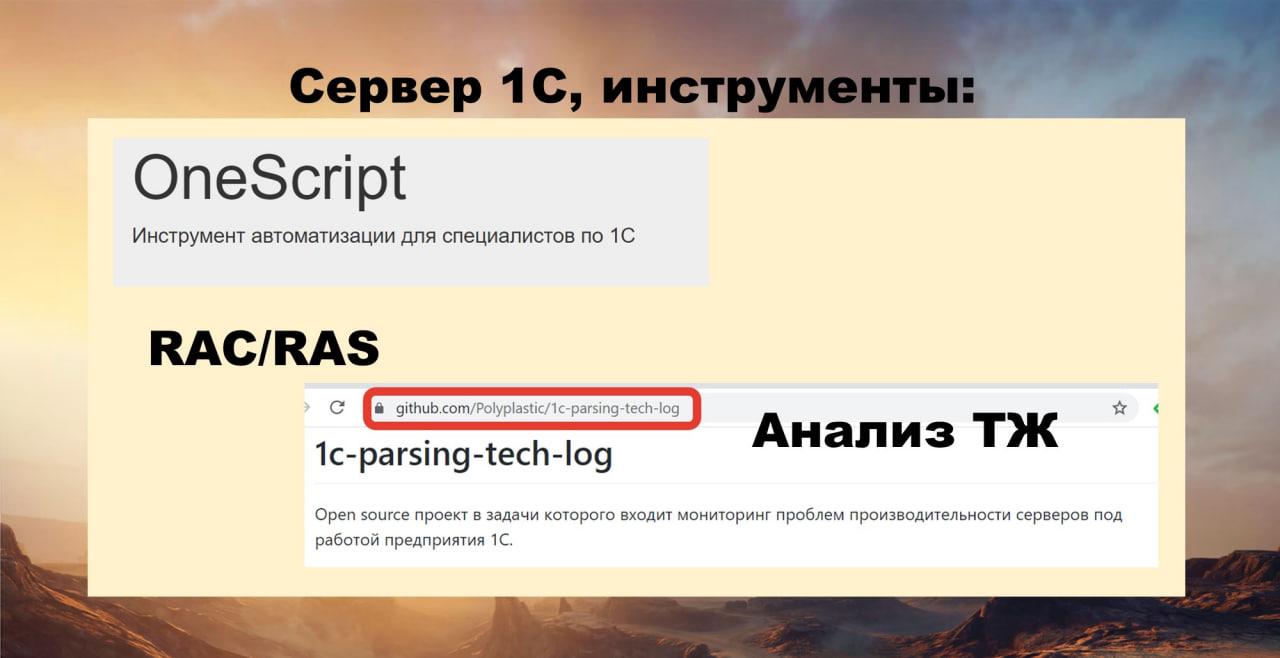
Добрались до сервера 1С. Здесь мне потребуется всего лишь три инструмента.
-
Первый – OneScript. Это движок для исполнения скриптов на языке 1С, с его помощью любой программист может написать не обработку, которая потребует 1C для своего выполнения, а скрипт произвольной сложности и выполнить его.
-
Дальше – я использую RAС / RAS. Remote Administration Server должен быть установлен на сервере 1С. Это must have. Если не установлен, его надо установить прямо сейчас. Если у вас нет доступа, прямо сейчас пишите своим админам, что надо установить. Без него вообще нельзя жить, он реально жизнь облегчает.
-
Третье, что я использую – это конфигурация «Мониторинг производительности сервера». Она начиналась как анализ техножурнала, а сейчас там можно еще и счетчики добавлять, а также использовать ее как свой сервер мониторинга.
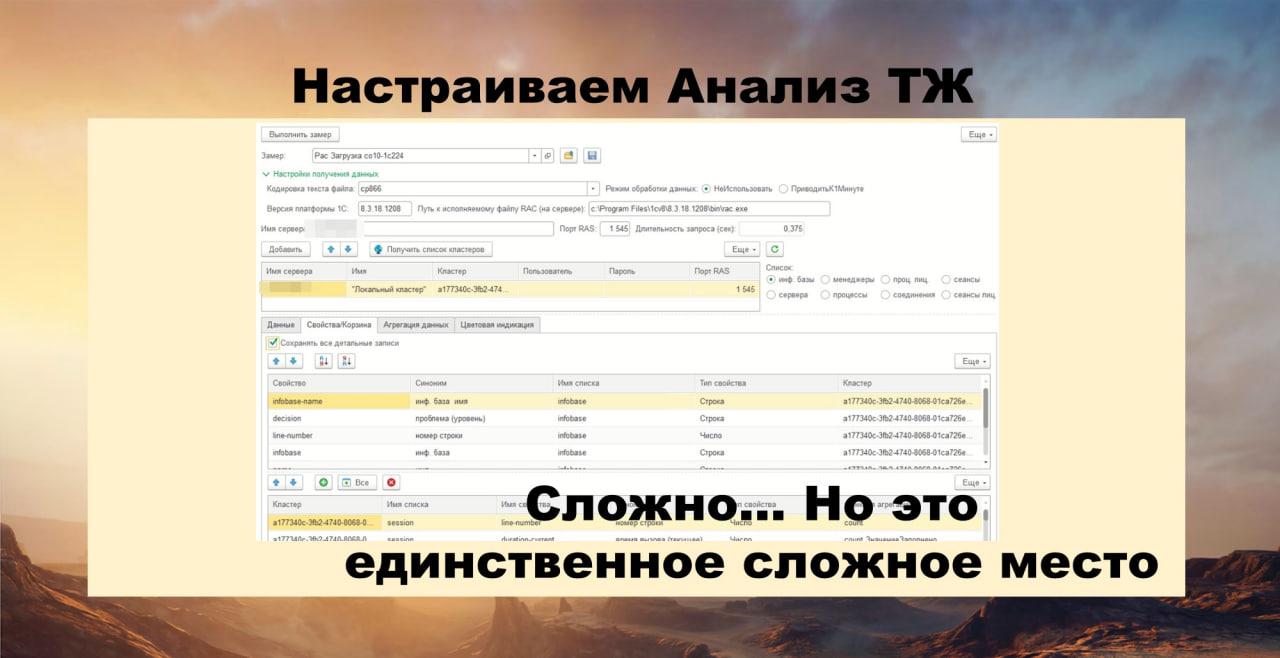
Важно, что конфигурация «Мониторинг производительности сервера» умеет загружать данные из Remote Administration Server.
Это – самое сложное место, которое потребует вложений мозга. У меня, по крайней мере, мозг взрывается, когда я настраиваю эту штуку. Еще не дошли руки до того, чтобы сделать это удобно.
А с помощью этой конфигурации мы настраиваем замер на целевом сервере – будем снимать раз в минуту показатели рабочих процессов и сеансов. Причем, мы можем настроить это просто на своем компьютере и оставить работать.
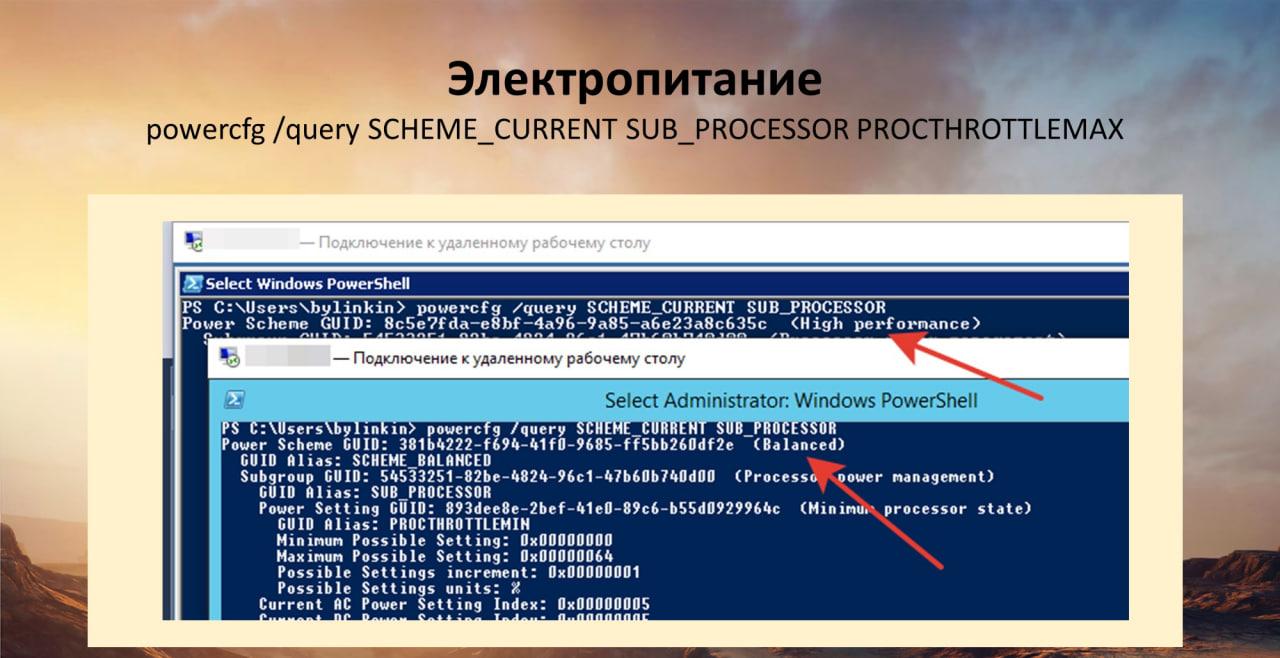
Самый больной вопрос из тех, с которыми я встречался – это электропитание.
Не забывайте настраивать на сервере электропитание на максимальную производительность. Вроде об этом на ИТС даже написано, да и админы все знают.
Команда для PowerShell, которая сразу показывает текущее электропитание:
powercfg /query SCHEME_CURRENT SUB_PROCESSOR PROCTHROTTLEMAX
На слайде показано два разных сервера в одной организации – на одном High Performance, на другом Balance. Я не знаю, почему так происходит.
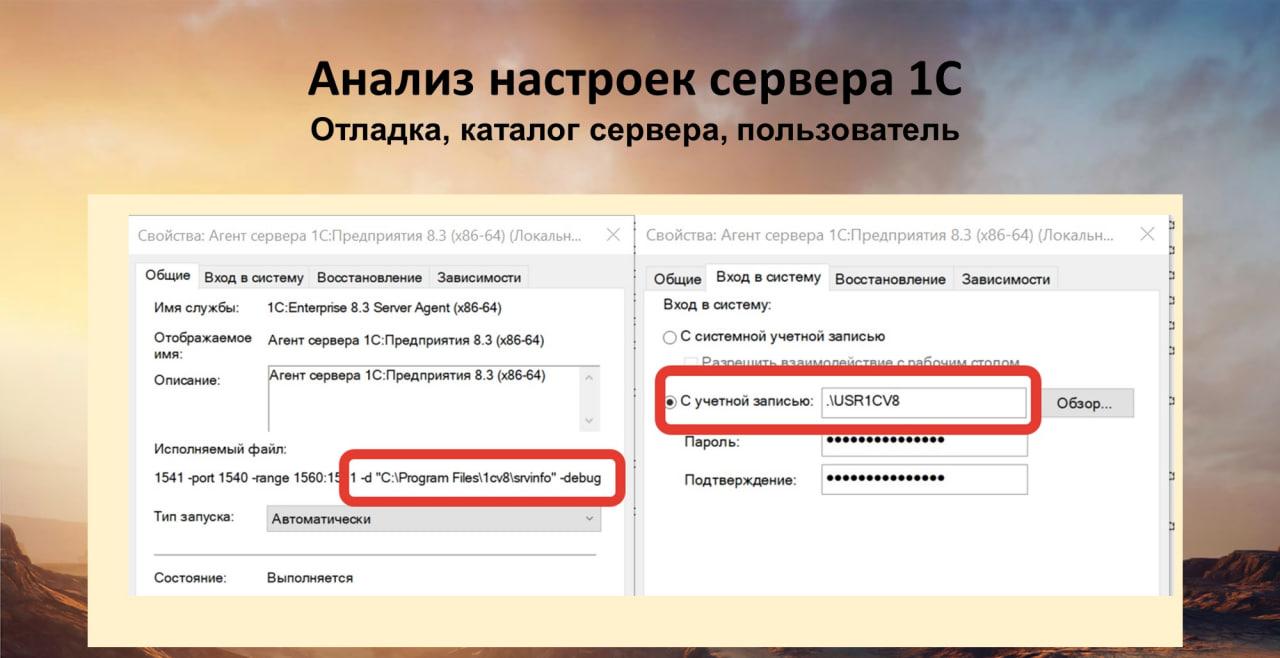
Дальше я смотрю настройки сервера 1С и баз. Я это делаю с помощью OneScript. Я подготовил слайды, в которых объясняется, как OneScript анализирует это.
Он ищет службы, установленные на сервере и анализирует флаг -d и флаг -debug.
-
Если есть флаг -debug – это вообще проблема, хотя вроде как -debug может увеличить производительность сервера 1С. Но это аварийная ситуация – нельзя включать отладку на рабочих серверах. Я думаю, каждый из вас был тем программистом, который занимался отладкой на рабочем сервере, у вас стояла отладка в каком-нибудь проведении, а все пользователи бегали и кричали, что у них ничего не работает, все тормозит. Если вы не были такими программистами, то вы были тем, кто разбирался с такой ситуацией. Я думаю, у всех это было.
-
Дальше смотрим пользователя учетной записи, под которым запущен сервер 1С. Если он запущен под системной учетной записью, это плохо. И обращайте внимание, какой пользователь там указан – локальный или доменный. Потому что если админы будут чистить пользователей домена, у нас могут возникнуть проблемы – они иногда забывают про этих пользователей.
-
Забыл сказать про флаг -d – это каталог, в котором установлены настроечные файлы баз данных сервера 1С srvinfo (сеансовые данные). Это картинка с моей тестовой базы, тут все хорошо, не ругайтесь на то, что она на диске C. Сразу отмечаем, где он находится – на том же диске, что и операционная система или в другом месте, как положено нам делать.
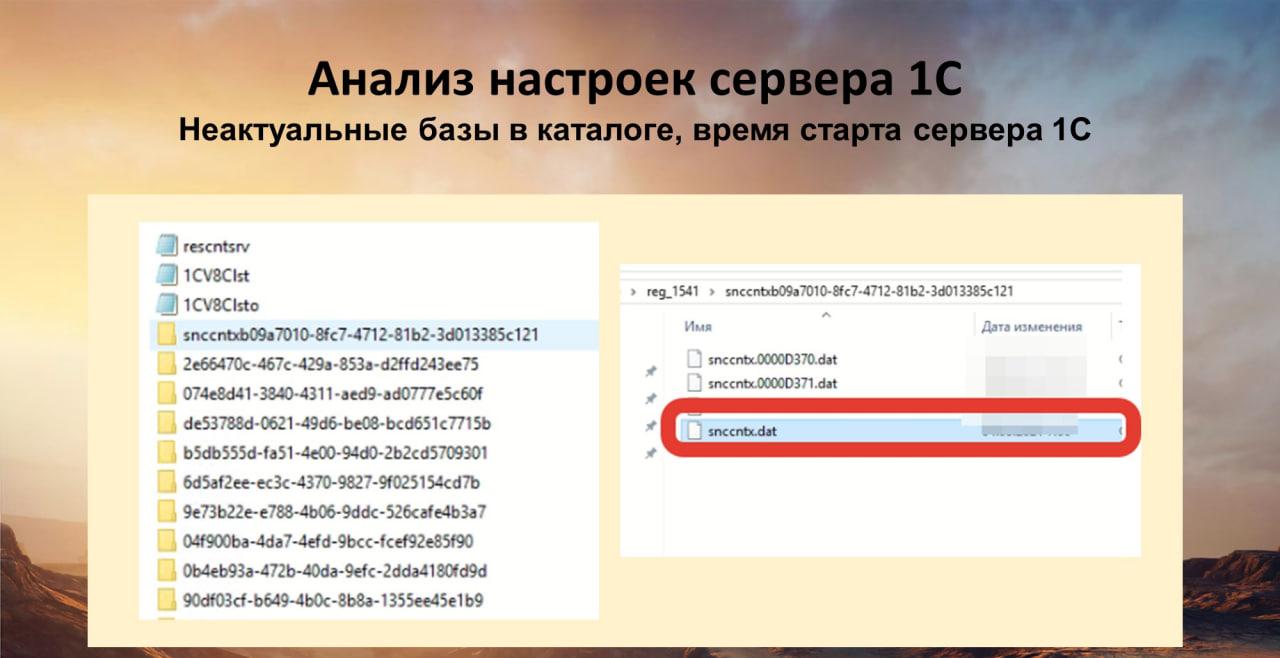
Дальше анализируем неактуальные базы в каталоге сервера 1С и время старта сервера 1С.
-
Все вы знаете, что когда мы устанавливаем базу, добавляем базу в сервер, в каталоге сервера 1С создается папка для этой базы с неким человеконечитаемым идентификатором. В этой папке хранятся настройки журнала регистрации, сам журнал регистрации, полнотекстовый поиск и что-то еще. При удалении базы этот каталог остается на месте – почему-то его никто не чистит. Я понимаю, почему 1С не чистит – там могут быть нужные данные журнала регистрации, к которым можно вернуться. Но когда мы как администраторы системы, как архитекторы принимаем решение об удалении базы, наверное, можно почистить ее и из каталога сервера. Мой скрипт смотрит базы, зарегистрированные на сервере, сравнивает их с базами, прописанными в каталоге, и выдает свое резюме – я его сейчас покажу.
-
Также я люблю смотреть дату перезапуска сервера 1С. Есть разные мнения – кто-то считает, что службу сервера 1С надо перезапускать раз в сутки, кто-то считает, что не надо. Я не буду сейчас ничего рекомендовать. Я столкнулся с ситуацией, когда каждый день в 11 часов дня пользователи жаловались, что у них возникают непонятные тормоза. Только в 11 часов дня. Я увидел, что в 11 часов дня пересоздаются рабочие процессы. И докопался до того, что в системе есть скрипт, который перезапускает сервер 1С. Но почему в 11 часов дня? Потому что так кто-то когда-то решил, а пользователи об этом не знали. Теперь я всегда вижу, во сколько последний раз перезапускался сервер 1С и могу задать вопрос: «Зачем?»
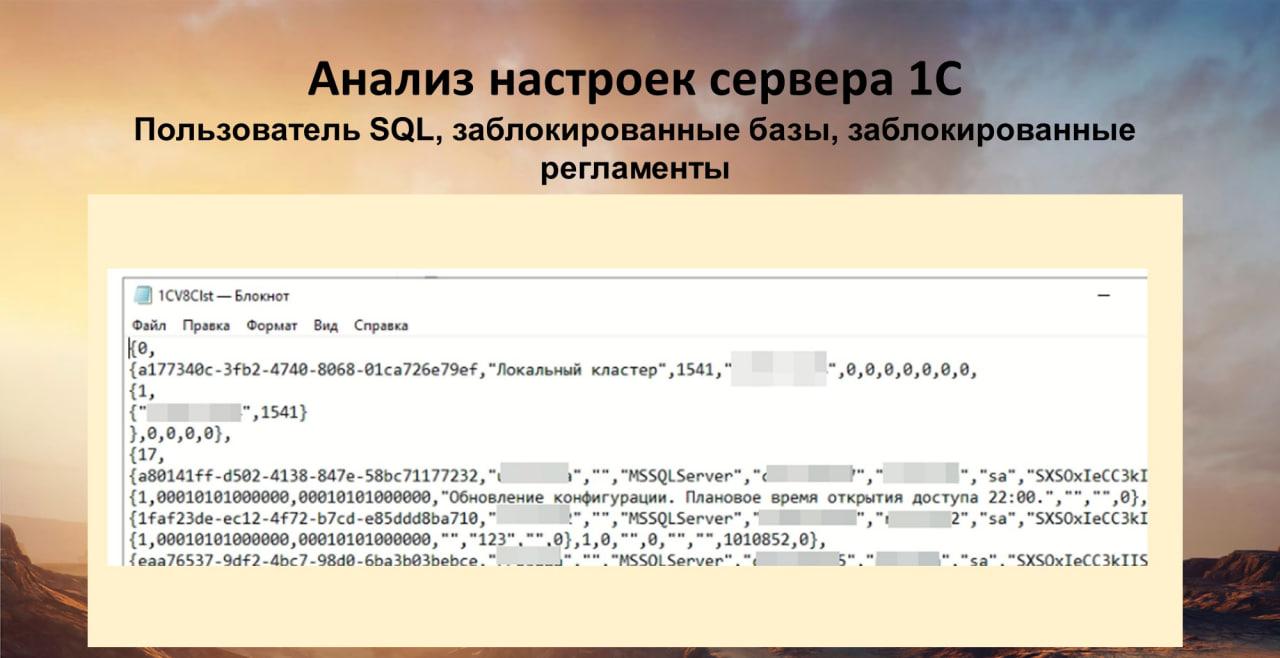
Дальше анализируем файл со списком баз 1CV8Clst.lst, из которого мы можем увидеть занимательные вещи.
-
Кроме списка зарегистрированных баз, мы в этом файле видим пользователя, под которым идет подключение к серверу SQL. К сожалению, этот пользователь почти всегда sa – я еще ни разу не видел, чтобы кто-нибудь указывал другого пользователя. Наверное, это очень тяжело. Хотя полезно – даже на ИТС пишут, что для каждой базы нужно заводить своего пользователя на SQL. Вы когда будете с запросами разбираться, хотя бы по пользователю увидите, к какой базе принадлежит запрос. Есть и другие способы анализа, но это поможет в жизни. Это не просто так, не говоря уже о безопасности.
-
Также я из этого файла вижу, у каких баз заблокированы регламенты, у каких заблокирован вход пользователей. И тут же сразу же возникает вопрос: «А почему на рабочем сервере у нас три базы, у которых все заблокировано? Может, это не рабочие базы?» Я не говорю, что это плохо, это надо просто знать и задавать вопросы, чтобы потом не было неожиданностей.
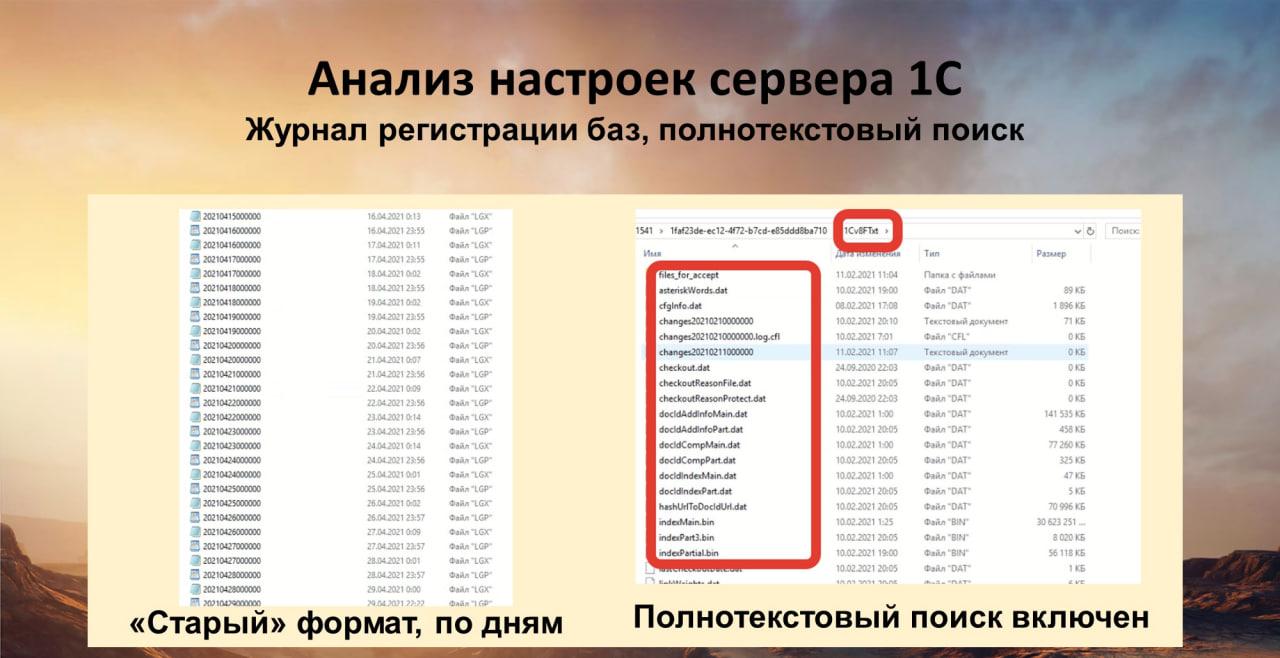
В каталоге настроек сервера можно проверять дополнительно следующие параметры:
- Настройки журнала регистрации у базы данных. Для крупных баз 1С рекомендуют оставлять так называемый старый формат журнала регистрации. В любом случае его надо резать по дням, а то и по часам. Так реально система работает быстрее – не на запись данных, но поиск в журнале регистрации легче проходит.
- Также смотрим индекс полнотекстового поиска. Он вообще есть или нет? Если он есть, значит им нужно заниматься. Когда индекс вроде как есть, но регламент его перезаполнения не работает, возникают проблемы. И тогда спрашивается – а зачем он нужен? Может быть он и не нужен совсем? В любом случае, если кто-то когда-то решил, что мы используем индекс, его нужно контролировать.
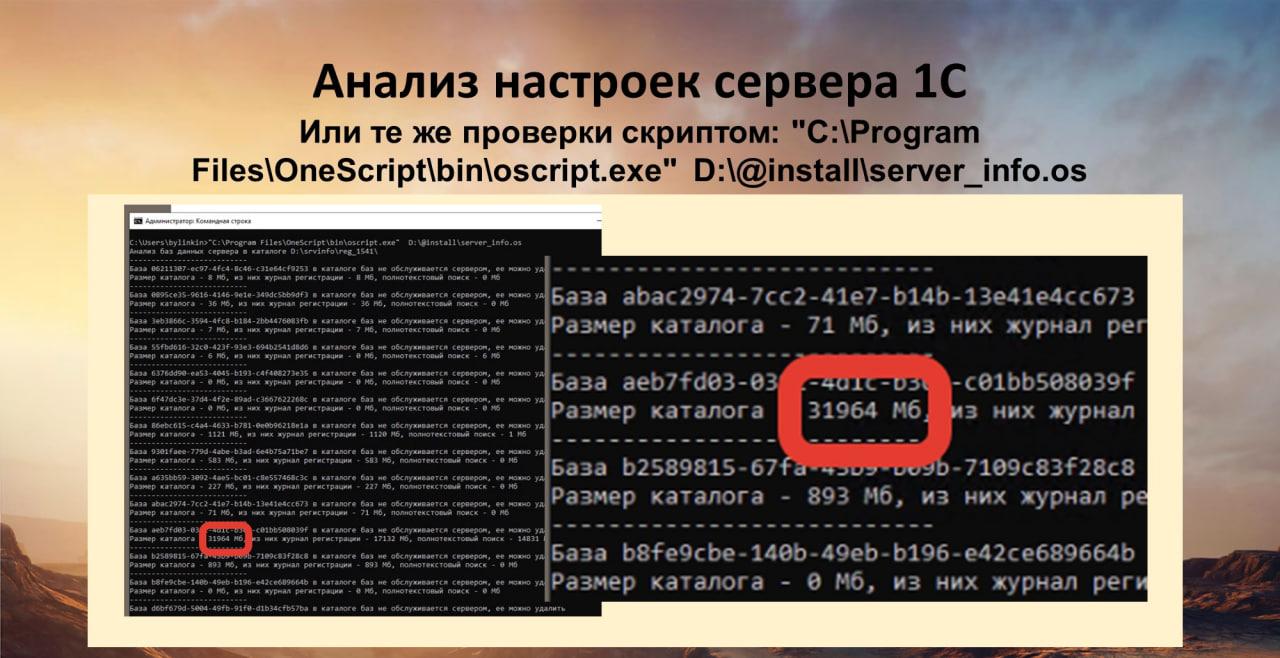
Неиспользуемые базы на сервере ищет скрипт, написанный на православном OneScript.
Я его недавно запустил на реальном рабочем сервере, который еще не анализировал. И он мне выдал большой список каталогов от удаленных баз.
Меня особенно удивила одна из баз, каталог у которой – 32 гигабайта. Представляете, на дорогом серверном быстром SSD-диске просто так лежит32 гигабайта. При том, что эта база уже никогда не будет использоваться. Ее удалили и забыли.
А потом кто-то включит технологический журнал, место у нас съестся и все встанет. Мы будем удивляться, почему так.
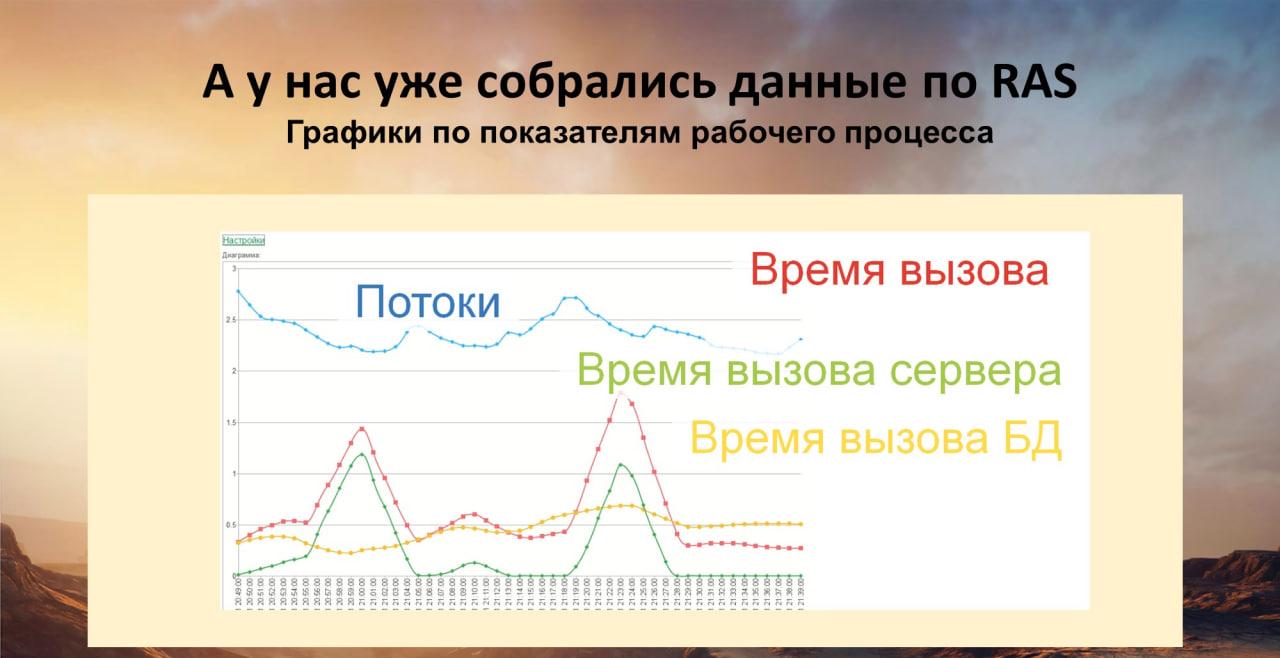
Когда у нас немного собрались данные показателей рабочих процессов с RAS, я их люблю смотреть в следующем графике.
В данном случае рабочий процесс один, потому что используется сервер версии ПРОФ. И на этом графике очень удобно выводить показатели:
-
количество потоков;
-
время вызова;
-
время вызова сервера;
-
и время вызова базы данных.
Я вижу, что этот сервер загружен не очень сильно – у него в среднем между двумя и тремя потоками. Но есть какие-то явные проблемы.
Вы кстати смотрели в настройки рабочих процессов на своих серверах? Вы можете сказать, какие у вас средние показатели времени отклика? Это вообще очень любопытное занятие.
Если вывести такой график и мониторить его, то кроме анализа техножурнала и всего такого, мы можем вот так вот опосредованно видеть, когда система тормозит, когда реально время вызова увеличивается.
И так мы можем еще видеть, что у тормозов есть причина – либо виноват сервер 1С, он что-то долго считает, либо виновата БД, она долго отвечает.
Посмотрите на этот график:
-
зеленый – это время вызова сервера;
-
а желтый – это время вызова базы данных
Я вижу, что тут время вызова базы данных аномально высокое – 0,5 секунды. Причем, у нее есть пики. Нужно разбираться.
В данном конкретном случае я знаю, что не то – как раз в это время почему-то были запущены регламенты обслуживания базы данных, причем сразу всем скопом.
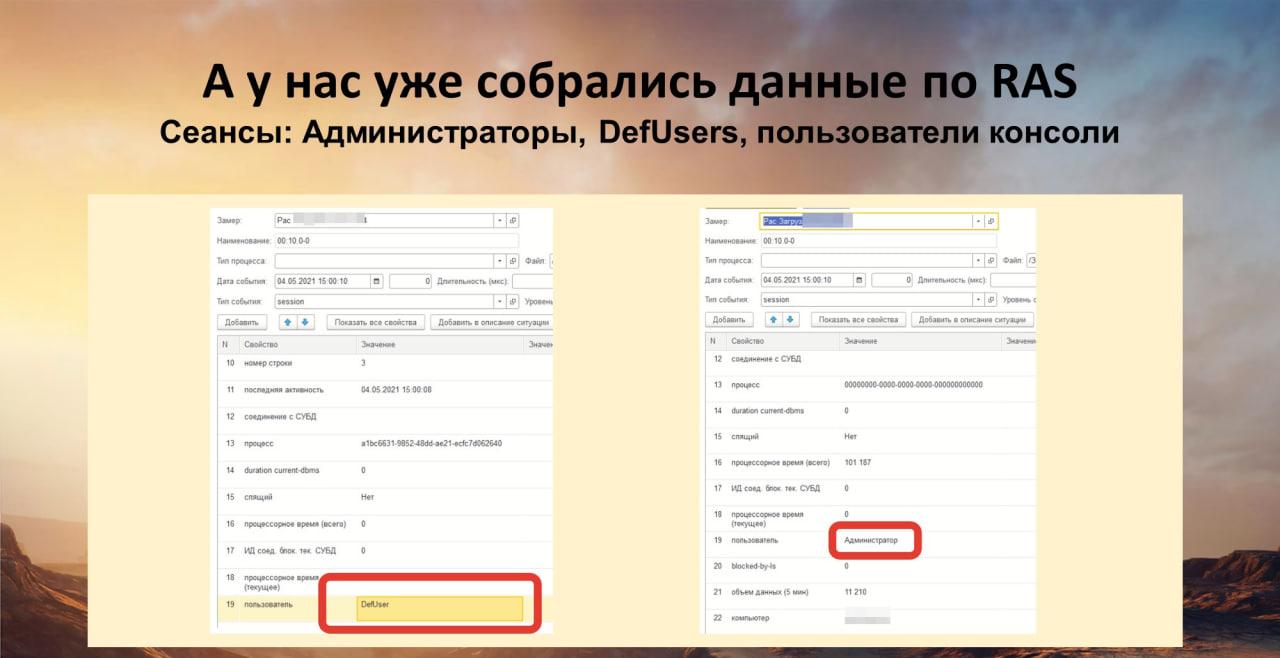
Так как у нас собираются данные по сеансам, я смотрю три вещи.
-
Количество абстрактных администраторов типа Админ, Администратор, administrator и admin. Когда у вас в базе 20-30 администраторов – это не очень хорошо. Это значит, что реальные люди заходят не под своими именами, а под администраторами. Конечно, в случае возникновения какой-то проблемы мы найдем, кто виноват – по номеру сеанса вычислим, по журналу регистрации, с какого компьютера заходил человек и все такое. Но лучше этого избежать и убрать эти абстрактные учетки вообще – обязать всех заходить под своими пользователями.
-
Также я смотрю количество Defusers. Это вообще боль. Все регламенты должны иметь четкого, понятного пользователя со своим именем. Так очень просто будет разобраться, что это за регламент, не заходя в журнал регистрации.
-
Еще я смотрю количество пользователей консоли – многие до сих пор ей пользуются. несмотря на то, что есть Remote Administration Server. Если много пользователей консоли, это значит, что каждый из них может в любой момент сделать kill юзера. Так себе.

В том, что я рассказал, нет ничего особенного – все это описано на ИТС. Надо его просто читать и следовать его рекомендациям.
-
Настройка рабочих серверов с платформой – https://its.1c.ru/db/metod8dev/content/5908/hdoc
-
Чек-лист по настройке рабочих серверов – https://its.1c.ru/db/metod8dev#content:5899:hdoc
Просто распечатываем, даем админам, даем себе и прямо следуем всем пунктам, что там указаны.
Анализ MS SQL
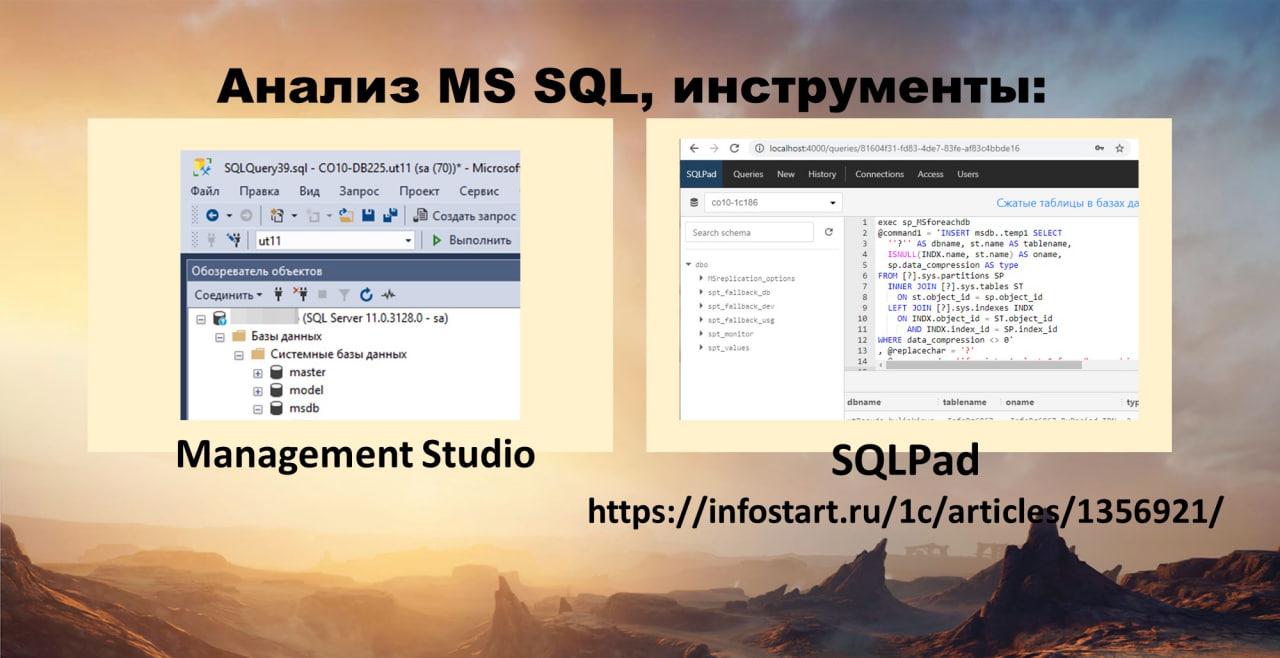
Дошли до SQL. Средства анализа:
-
Стандартный Management Studio MS SQL
-
Или я использую SQLPath – веб-приложение, которое поднимается в докере. Я могу развернуть его у себя на компе, и подсовываю ему уже заранее заготовленный список запросов. Потом просто в нем настраиваю в нем доступ к серверу, который анализирую, и выполняю запросы, не копируя их ниоткуда, а просто выбирая их из списка. В статье Инфостарте я описываю, как с ним работать.
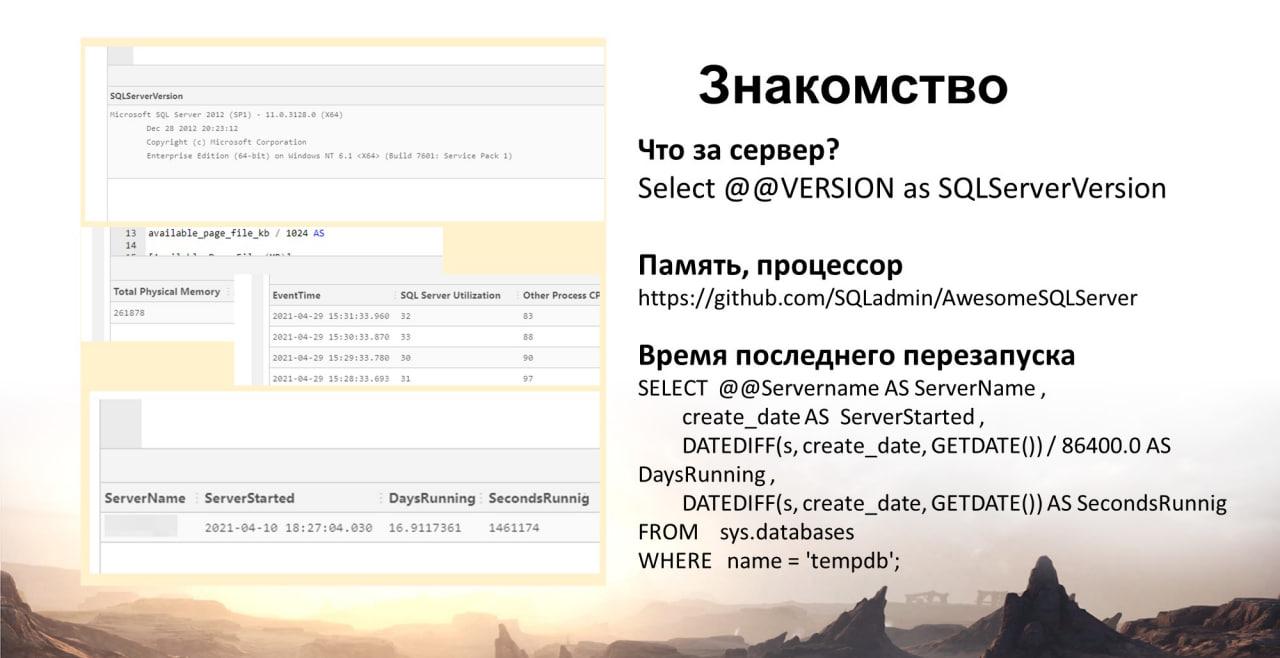
На слайде показаны запросы, из которых мы можем определить:
Версию сервера:
Select @@VERSION as SQLServerVersion
Время последнего перезапуска:
SELECT @@Servername AS ServerName ,
create_date AS ServerStarted ,
DATEDIFF(s, create_date, GETDATE()) / 86400.0 AS DaysRunning ,
DATEDIFF(s, create_date, GETDATE()) AS SecondsRunnig
FROM sys.databases
WHERE name = 'tempdb';
MS SQL дает нам очень многое. Можно не иметь доступ к железу, все данные прочитать через запросы.

Что с базами? Опять же, выполняем запрос:
SELECT d.name, d.database_id, d.create_date, d.is_auto_update_stats_on, d.is_auto_update_stats_async_on
FROM sys.databases d
ORDER BY database_id
Получаем список баз – оказывается, на рабочем сервере, на котором у нас было заявлено 2 рабочих базы, у нас куча баз, какая-то ut11_skladtest. Ну что за тест? Серьезно?
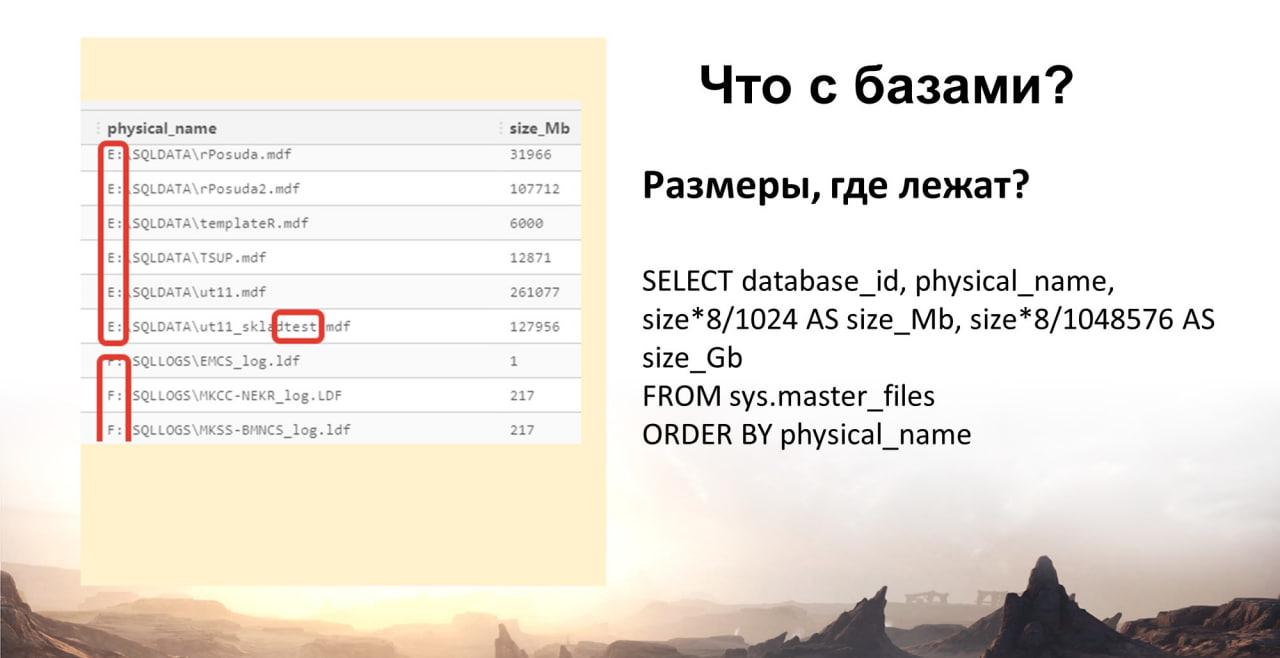
Где лежат базы и какие у них размеры, покажет запрос:
SELECT database_id, physical_name, size*8/1024 AS size_Mb, size*8/1048576 AS size_Gb
FROM sys.master_files
ORDER BY physical_name
Смотрим результаты:
-
Здесь все отлично – я вижу, что файлы базы данных лежат на одном диске, логи на другом. Все отлично.
-
Ну и размеры я сразу вижу и оцениваю, с чем мне предстоит бороться.

TempDB. Чтобы узнать количество используемых TempDB нужно выполнить запрос:
SELECT name, physical_name
FROM sys.master_files
WHERE database_id = DB_ID('tempdb')
Когда устанавливаешь сервер, он по умолчанию создает один TempDB. А на ИТС написано, что надо 4 минимум создавать.
В доках Майкрософта есть формула, по которой надо рассчитывать количество TempDB в зависимости от количества ядер. Говорят, что так работает быстрее.

Чтобы узнать, обслуживаются ли вообще базы, нужно выполнить следующий запрос:
SELECT
mp.name AS [MTX Plan Name],
msp.subplan_name AS [Sub Plan Name],
mpl.start_time AS [JobStart],
mpl.end_time AS [JobEnd],
DATEDIFF ( mi , mpl.start_time , mpl.end_time ) AS [Minutes],
mpl.succeeded AS [JobSucceeded]
FROM
msdb.dbo.sysmaintplan_plans mp
INNER JOIN msdb.dbo.sysmaintplan_subplans msp ON mp.id = msp.plan_id
INNER JOIN msdb.dbo.sysmaintplan_log mpl ON msp.subplan_id = mpl.subplan_id
where mpl.start_time > DATEADD (wk ,-1 , CURRENT_TIMESTAMP )
ORDER By mpl.start_time
Он показывает планы обслуживания и их логи.
Здесь я вижу «Reorganize Index ut11», «Update Statistics ut11», «Rebuild Index ut11» и Update Statistics для еще одной базы. Бэкапов не вижу. Ну ладно, может бэкапы делаются не планами обслуживания, а сторонними средствами.

Проверяю бэкапы запросом:
SELECT
mp.name AS [MTX Plan Name],
msp.subplan_name AS [Sub Plan Name],
mpl.start_time AS [JobStart],
mpl.end_time AS [JobEnd],
DATEDIFF ( mi , mpl.start_time , mpl.end_time ) AS [Minutes],
mpl.succeeded AS [JobSucceeded]
FROM
msdb.dbo.sysmaintplan_plans mp
INNER JOIN msdb.dbo.sysmaintplan_subplans msp ON mp.id = msp.plan_id
INNER JOIN msdb.dbo.sysmaintplan_log mpl ON msp.subplan_id = mpl.subplan_id
where mpl.start_time > DATEADD (wk ,-1 , CURRENT_TIMESTAMP )
ORDER By mpl.start_time
Да, бэкапы делаются, все хорошо. В этот раз меня не подвели, есть бэкапы.

Что со сжатием?
К сжатию у всех отношение разное, я его советую использовать. Используется сжатие в базах или нет, можно посмотреть запросом:
SELECT
''?'' AS dbname, st.name AS tablename,
ISNULL(INDX.name, st.name) AS oname,
sp.data_compression AS type
FROM [?].sys.partitions SP
INNER JOIN [?].sys.tables ST
ON st.object_id = sp.object_id
LEFT JOIN [?].sys.indexes INDX
ON INDX.object_id = ST.object_id
AND INDX.index_id = SP.index_id
WHERE data_compression <> 0
У меня не используется.
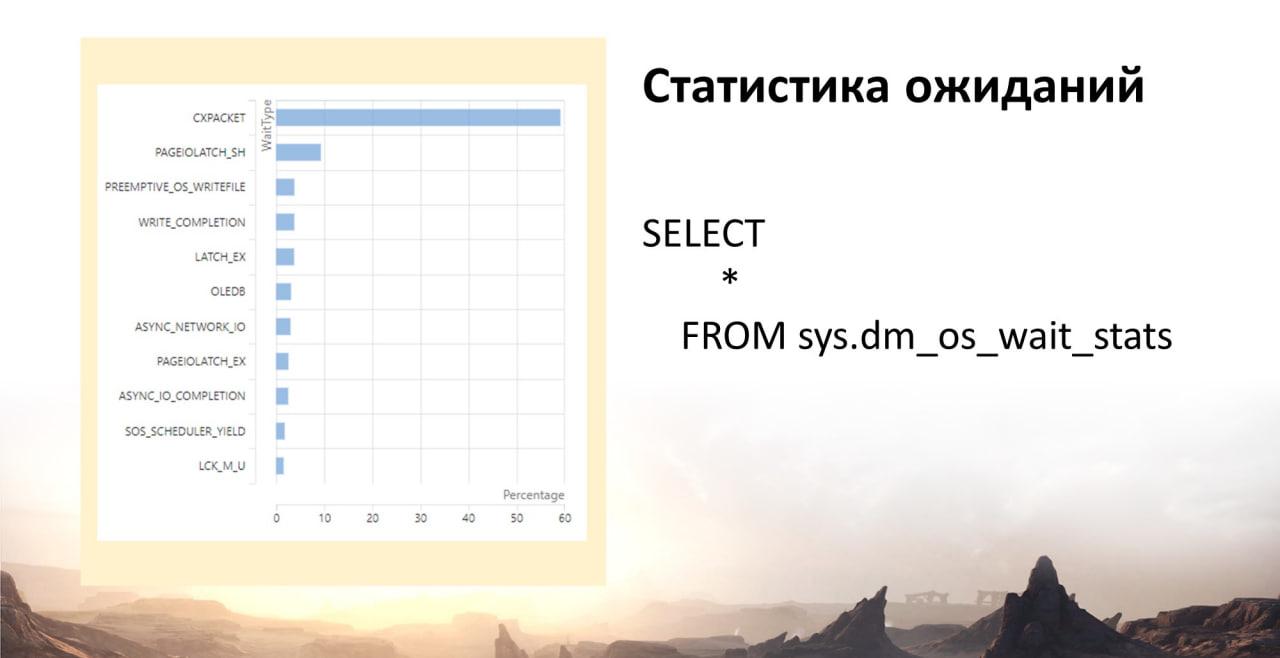
Статистика ожиданий.
SELECT * FROM sys.dm_os_wait_stats
MS SQL ведет логи и статистику своих запросов и ожиданий, которые возникают в ходе запросов. Я вижу, что у меня есть проблемы с дисковой подсистемой PAGEIOLATCH_SH CXPACKET.
Скриптов для просмотра ожиданий очень много. Brentozar и еще какие-то. Информации по ним очень много, вообще без проблем найдете. Но вот CXPACKET меня волнует. Почему?
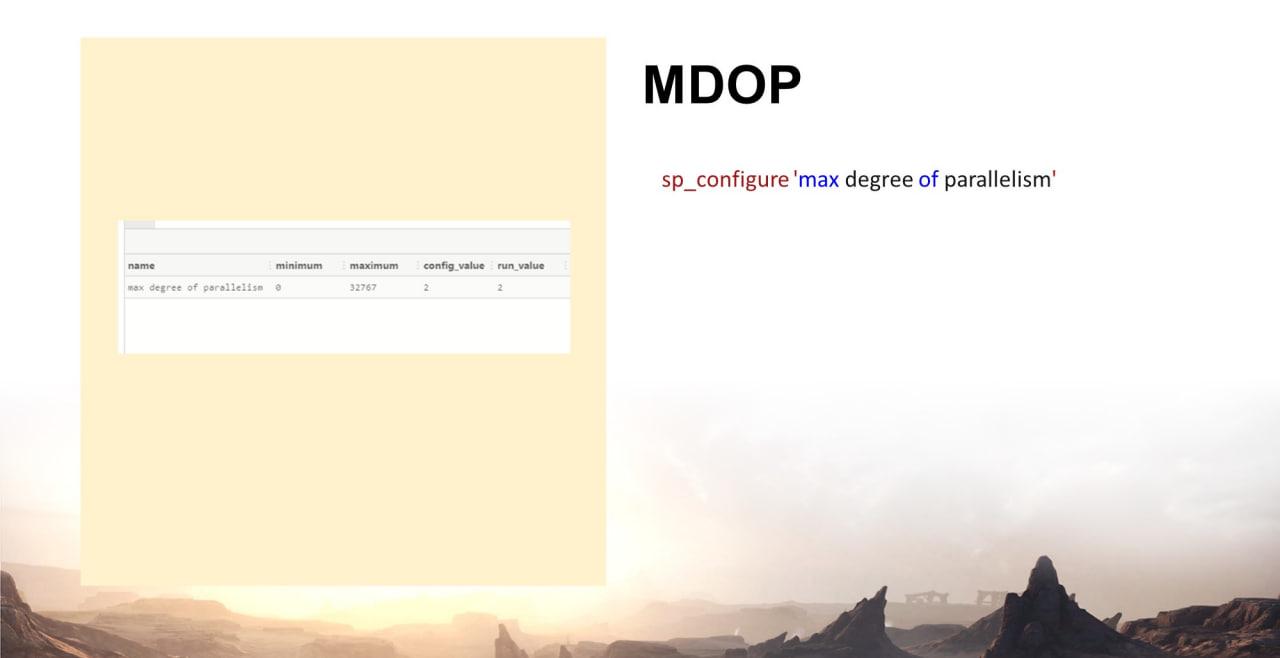
Потому что я смотрю MDOP – Max Degree of Parallelism.
sp_configure 'max degree of parallelism'
У сервера, который не настроен, MDOP равен нулю. Это проблема. Потому что 1С говорит о том, что MDOP должен быть равен единице. Но настоящие архитекторы 1С с этим не соглашаются и говорят о том, что его надо настраивать в зависимости от вашей конкретной ситуации. У меня, например, в данном случае стоит значение 2.

Проверяем нагрузку на процессор и диск в разрезе баз. Из sys.dm_exec_query_stats смотрим на статистику.
SELECT * FROM sys.dm_exec_query_stats
Это текущая статистика за последний час на момент измерения.
У меня здесь видно, что две какие-то базы дают почти одинаковую нагрузку. Это хорошо. А остальные базы, которые на этом сервере фигурируют, как видно, не используются, но они могут использоваться потом.

Тут тоже нет никакого тайного знания. Это все написано на ИТС.
-
Настройки Microsoft SQL Server для работы с 1С:Предприятие – https://its.1c.ru/db/metod8dev/content/5904/hdoc
-
Регламентные операции на уровне СУБД для MS SQL Server – https://its.1c.ru/db/metod8dev#content:5837:hdoc
Читайте и применяйте.
Регулярно проверяем настройки. Автоматизируем проверки

Мы это делаем не только в первый день.
В первый день мы делаем для того, чтобы понять, с чем мы столкнемся. Но эти проверки надо делать регулярно, потому что настройки могут меняться.
Электропитание, например, почему-то же меняется. Я верю, что админы, когда сервера настраивают первоначально, все выставляют в максимальную производительность. Может быть обновление им как-то подгаживает.
Поэтому настройки надо регулярно проверять.

Для автоматизации подобных проверок я видел только одно решение, но оно сейчас в замороженном виде. «Серебряная пуля» его когда-то начинала делать, но подморозила.
Это, опять же, набор скриптов на OneScript. Причем сделан очень классно. Я его только глазами видел.
Есть некий исполнитель проверок, который натравливается на папку с отдельными файликами, в которых описаны проверки. Он их исполняет и выдает какое-то резюме – что хорошо, что плохо.
Это самое главное, потому что при написании проверки в ее код нужно заложить еще и оценку – хорошо это или плохо. И желательно указывать ссылку на документацию.
Надеюсь, в «Серебряной пуле» этот проект не похоронили.

Итоги:
-
Все сами проверяем своими глазами, никому не верим.
-
Соблюдаем рекомендации от вендора.
-
И регулярно проверяем настройки.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2021 Post-Apocalypse.

Вступайте в нашу телеграмм-группу Инфостарт