
Obsidian - это локальная база знаний, одна из самых дружесвенных из всех, что я на текущий попробовал. Сама база это просто папка на диске с файлами в формате Markdown. Такой сопособ хранения отлично дружит с Git. Так же она расширяется плагинами на подобии VS Code. Одна в ней была проблемма. При способности подсвечивать синтаксис на разных языках, нет в ней подсветки 1с. После изучения вопроса, я выяснил что для подсветки используется библиотека CodeMirror и уже есть реализованный для 1с модуль. Спасибо Сергею Кудашкину и Александра Колесникову на https://github.com/sikuda/codemirror-1C нашел то, что мне было нужно.
Сейчас по шагам распишу, что нужно делать. Все плагины, которые вы устанавливаете, устанавливаются непосредсвенно в папку с вашей базой знаний, или хранилищем в терминологии obsidian. Нужный нам плагин лежит в папке <ваша база знаний>\.obsidian\plugins\cm-editor-syntax-highlight-obsidian\
Поменять необходимо всего 1 файл main.js в двух местах. Нужно в перечисления модулей добавить наш модуль. Привожу пример кода:
CodeMirror.modeInfo = [
...
{name: "BSL", mime: "text/x-bsl", mode: "bsl", ext: ["bsl"],alias: ["1s","1c"]},
...
]
И собственно сам модуль:
createCommonjsModule(function (module, exports) {
// CodeMirror, copyright (c) by Marijn Haverbeke and others
// for 1C - http://code1c.sikuda.ru/
// Distributed under an MIT license: http://codemirror.net/LICENSE
(function(mod) {
mod(codemirror);
})(function(CodeMirror) {
"use strict";
CodeMirror.defineMode("bsl", function(conf, parserConf) {
var ERRORCLASS = 'error';
function wordRegexp(words) {
return new RegExp("^((" + words.join(")|(") + "))([ ;\\/\\n\\t]|$)", "i"); //\\b \\W //[^$A-Za-z0-9А-ЯЁа-яё_]
}
var singleOperators = new RegExp("^[\\+\\-\\*/%&<>=]");
var singleDelimiters = new RegExp("^[\\(\\)\\[\\]\\{\\},:=;\\.]");
var doubleOperators = new RegExp("^((<>)|(<=)|(>=))");
var identifiers = new RegExp("^[_A-Za-zА-ЯЁа-яё][_A-Za-z0-9А-ЯЁа-яё]*");
var openingKeywords = ['если', 'if', 'пока', 'while', 'для', 'for', 'процедура', 'procedure', 'функция', 'function', 'попытка', 'try'];
var middleKeywords = ['иначе', 'else', 'иначеесли', 'elsif', 'исключение', 'except'];
var doubleClosing = wordRegexp(['конецесли', 'endif', 'конеццикла', 'enddo', 'конецпроцедуры', 'endprocedure', 'конецфункции', 'endfunction', 'конецпопытки', 'endtry']);
var endKeywords = ['loop'];
var operatorKeywords = ['and', 'or', 'not', 'xor', 'in'];
var commonKeywords = ['новый', 'new', 'каждого', 'each', 'из', 'from', 'цикл', 'do', 'или', 'or', 'не', 'not', 'ложь', 'false', 'истина', 'true', 'и','and', 'возврат', 'return', 'тогда', 'then', 'экспорт', 'export', 'неопределено', 'undefined', 'продолжить', 'continue', 'прервать', 'break', 'перейти', 'goto', 'по', 'to' , 'null'];
var commontypes = ['перем', 'var', 'знач', 'val'];
var wordOperators = wordRegexp(operatorKeywords);
var keywords = wordRegexp(commonKeywords);
var types = wordRegexp(commontypes);
var stringPrefixes = '"';
var stringNewLine = '|';
var opening = wordRegexp(openingKeywords);
var middle = wordRegexp(middleKeywords);
var closing = wordRegexp(endKeywords);
var doOpening = wordRegexp(['do', 'пока']);
var indentInfo = null;
CodeMirror.registerHelper("hintWords", "bsl", openingKeywords.concat(middleKeywords).concat(endKeywords).concat(operatorKeywords).concat(commonKeywords).concat(commontypes));
//CodeMirror.registerHelper("hint", "1c", openingKeywords.concat(middleKeywords).concat(endKeywords).concat(operatorKeywords).concat(commonKeywords).concat(commontypes));
function indent(_stream, state) {
state.currentIndent++;
}
function dedent(_stream, state) {
state.currentIndent--;
}
// tokenizers
function tokenBase(stream, state) {
if (stream.eatSpace()) {
return null;
}
var ch = stream.peek();
// Handle Comments
if (ch === "/") {
var ch_next = stream.string.charAt(stream.pos+1) || undefined;
if (ch_next === "/") {
stream.skipToEnd();
return "comment";
}
}
//handle meta - &OnClient or #If
if (ch === "&" || ch === "#") {
stream.skipToEnd();
return "meta";
}
//~nameLabel
if (ch === "~"){
stream.next();
stream.match(identifiers);
return 'label';
}
// Handle Number Literals
if (stream.match(/^\.?[0-9]{1,}/i, false)) {
var floatLiteral = false;
// Floats
if (stream.match(/^\d*\.\d+F?/i)) { floatLiteral = true; }
else if (stream.match(/^\d+\.\d*F?/)) { floatLiteral = true; }
else if (stream.match(/^\.\d+F?/)) { floatLiteral = true; }
if (floatLiteral) {
// Float literals may be "imaginary"
stream.eat(/J/i);
return 'number';
}
// Integers
var intLiteral = false;
// Hex
if (stream.match(/^&H[0-9a-f]+/i)) { intLiteral = true; }
// Octal
else if (stream.match(/^&O[0-7]+/i)) { intLiteral = true; }
// Decimal
else if (stream.match(/^[0-9]\d*F?/)) {
// Decimal literals may be "imaginary"
stream.eat(/J/i);
// TODO - Can you have imaginary longs?
intLiteral = true;
}
// Zero by itself with no other piece of number.
else if (stream.match(/^0(?![\dx])/i)) { intLiteral = true; }
if (intLiteral) {
// Integer literals may be "long"
stream.eat(/L/i);
return 'number';
}
}
// Handle Strings
if (stream.match(stringPrefixes)) {
state.tokenize = tokenStringFactory(stringPrefixes);
return state.tokenize(stream, state);
}
if (stream.match(stringNewLine)) {
state.tokenize = tokenStringFactory(stringPrefixes);
return state.tokenize(stream, state);
}
if (stream.match(doubleOperators)
|| stream.match(singleOperators)
|| stream.match(wordOperators)) {
return 'operator';
}
if (stream.match(singleDelimiters)) {
return 'delimiter';
}
if (stream.match(doOpening)) {
indent(stream,state);
state.doInCurrentLine = true;
return 'keyword';
}
if (stream.match(opening)) {
if (! state.doInCurrentLine)
indent(stream,state);
else
state.doInCurrentLine = false;
return 'keyword';
}
if (stream.match(middle)) {
return 'keyword';
}
if (stream.match(doubleClosing)) {
//dedent(stream,state);
dedent(stream,state);
return 'keyword';
}
if (stream.match(closing)) {
dedent(stream,state);
return 'keyword';
}
if (stream.match(types)) {
return 'keyword';
}
if (stream.match(keywords)) {
return 'keyword';
}
if (stream.match(identifiers)) {
return 'variable';
}
// Handle non-detected items
stream.next();
return ERRORCLASS;
}
function tokenStringFactory(delimiter) {
var singleline = delimiter.length == 1;
var OUTCLASS = 'string';
return function(stream, state) {
while (!stream.eol()) {
stream.eatWhile(/[^'"]/);
if (stream.match(delimiter)) {
state.tokenize = tokenBase;
return OUTCLASS;
} else {
stream.eat(/['"]/);
}
}
if (singleline) {
if (parserConf.singleLineStringErrors) {
return ERRORCLASS;
} else {
state.tokenize = tokenBase;
}
}
return OUTCLASS;
};
}
function tokenLexer(stream, state) {
var style = state.tokenize(stream, state);
var current = stream.current();
var delimiter_index = '[({'.indexOf(current);
if (delimiter_index !== -1) {
indent(stream, state );
}
if (indentInfo === 'dedent') {
if (dedent(stream, state)) {
return ERRORCLASS;
}
}
delimiter_index = '])}'.indexOf(current);
if (delimiter_index !== -1) {
if (dedent(stream, state)) {
return ERRORCLASS;
}
}
return style;
}
var external = {
electricChars:"dDpPtTfFeE ",
startState: function() {
return {
tokenize: tokenBase,
lastToken: null,
currentIndent: 0,
nextLineIndent: 0,
doInCurrentLine: false
};
},
token: function(stream, state) {
if (stream.sol()) {
state.currentIndent += state.nextLineIndent;
state.nextLineIndent = 0;
state.doInCurrentLine = 0;
}
var style = tokenLexer(stream, state);
state.lastToken = {style:style, content: stream.current()};
return style;
},
indent: function(state, textAfter) {
var trueText = textAfter.replace(/^\s+|\s+$/g, '') ;
if (trueText.match(closing) || trueText.match(doubleClosing) || trueText.match(middle)) return conf.indentUnit*(state.currentIndent-1);
if(state.currentIndent < 0) return 0;
return state.currentIndent * conf.indentUnit;
},
lineComment: "'"
};
return external;
});
CodeMirror.defineMIME("text/x-bsl", "bsl");
});
});
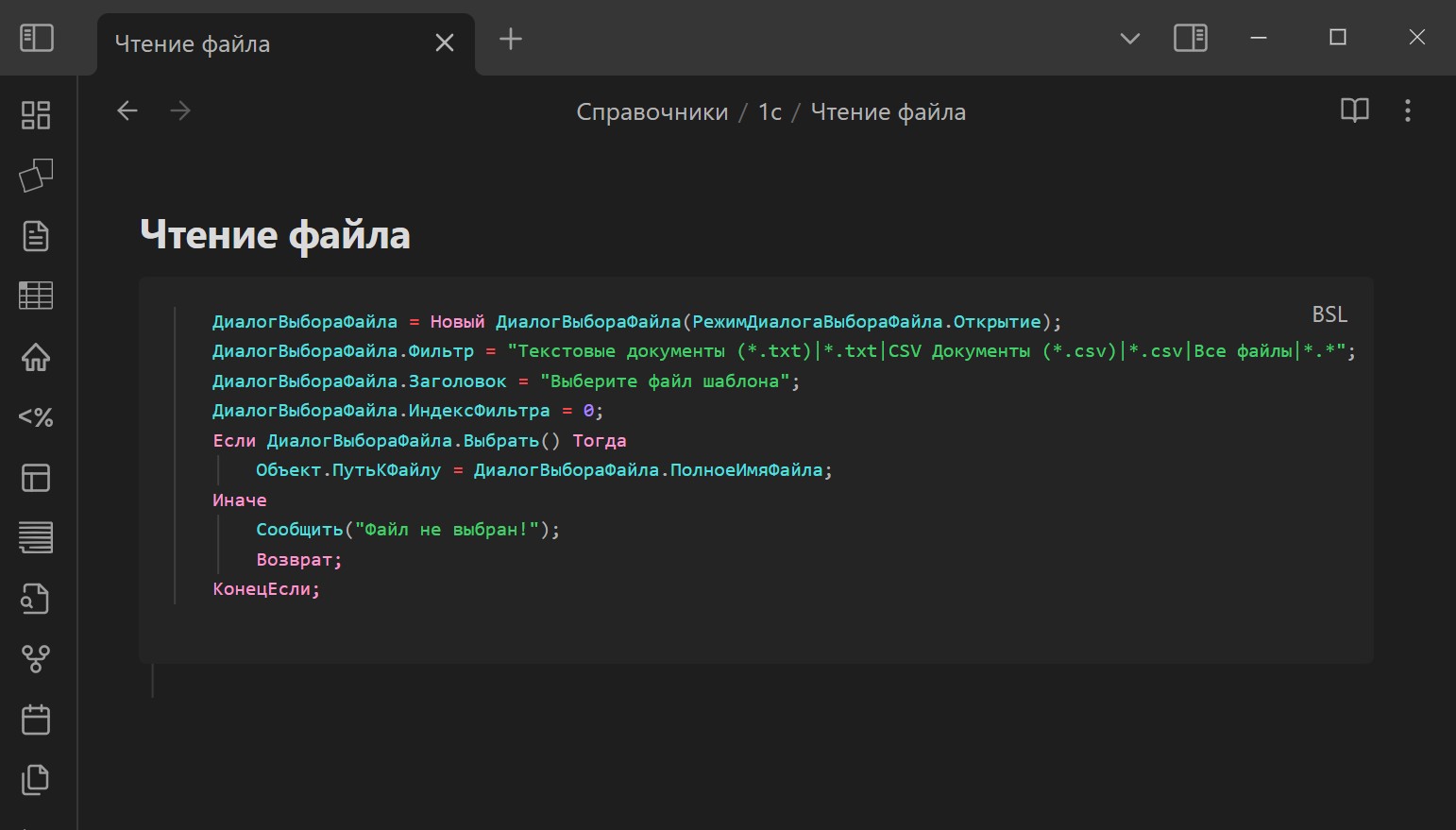
Сохраняем, перезапускаем программу. И вуаля, теперь у нас код на любимом языке тоже разноцветный.
Для тех кому лениво заниматся кописастом, прилагаю файлик исправленного модуля.
Вступайте в нашу телеграмм-группу Инфостарт


{kind=link}