
Я директор по продуктам школы Systems.Education. Мы занимаемся обучением аналитиков и проектировщиков систем.
Обучением системных аналитиков я занимаюсь уже более 10 лет, а в индустрии работаю больше 25 лет.
В декабре 2022 года я написал статью на habr.com про разработку требований на ChatGPT. И сейчас расскажу о том, как можно применить ChatGPT в работе бизнес и системного аналитика.
Единственный момент: я никогда не работал с продуктами 1С и никогда не создавал решения на базе продуктов 1С, поэтому примеры, которые будут в докладе, почти никак не связаны с 1С. Но думаю, вы все равно сможете найти им применение в своей деятельности.

В своем докладе я расскажу:
-
как выглядит процесс работы системного аналитика – что он делает и какие артефакты он создает;
-
откуда взялась тема искусственного интеллекта;
-
как можно применить ИИ для анализа предметной области, спецификации требований, построения моделей и диаграмм;
-
дам несколько советов и расскажу, что нас ждет дальше.
Процесс работы аналитика

В процессе анализа мы всегда идем:
-
от известного к новому, потому что обычно мы создаем что-то новое или меняем какие-то процессы;
-
от общего к частному – от большой картины к частным решениям и где-то даже доходим до кода;
-
от деятельности людей – мы автоматизируем то, что люди делают в своих бизнес-процессах – идем к средствам автоматизации.
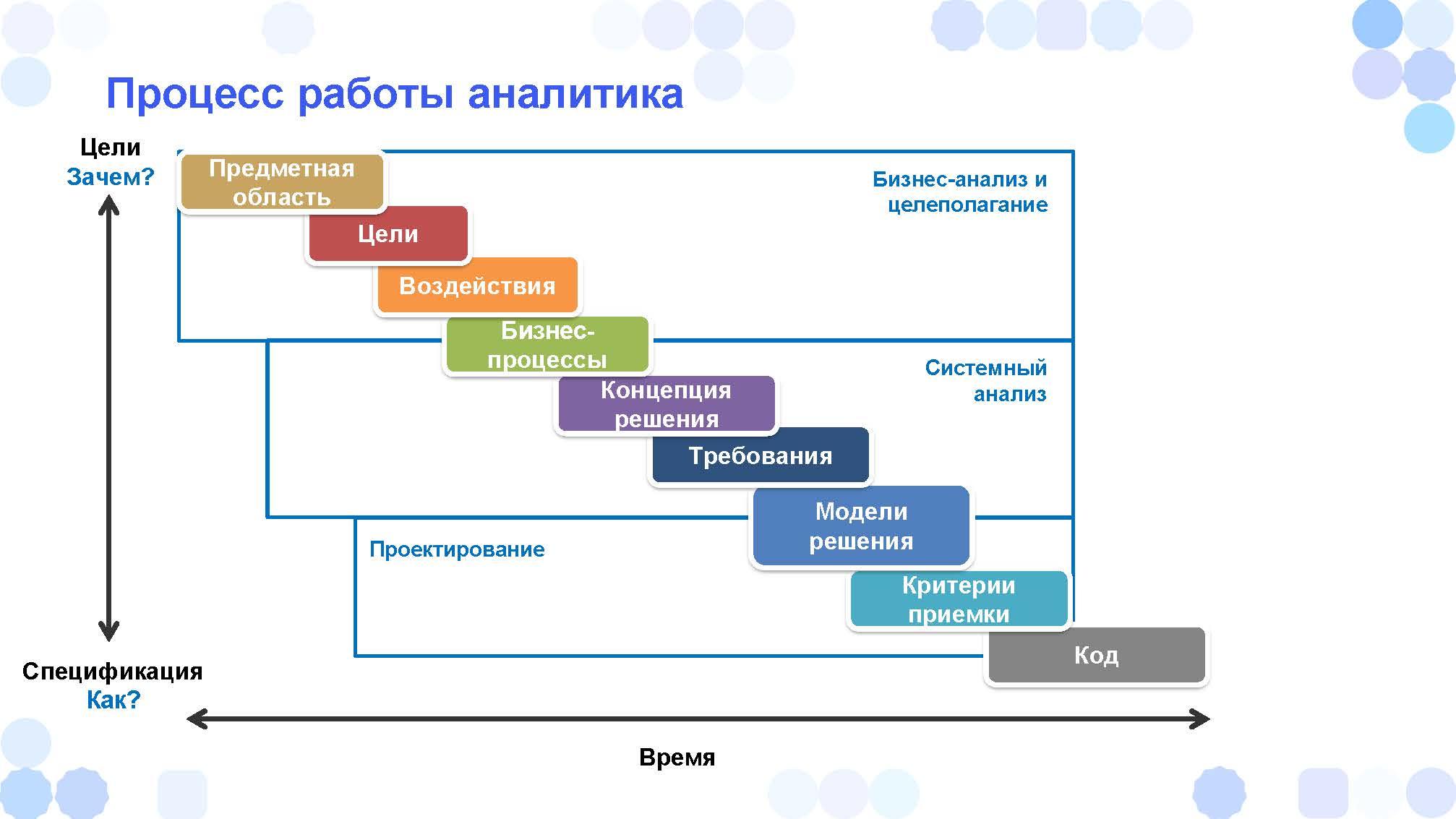
Если процесс работы аналитика представить в виде диаграммы, мы должны понять:
-
что у нас в принципе происходит – какую предметную область мы изучаем и пытаемся автоматизировать;
-
какие цели стоят – мы должны с бизнесом совместно проработать и выявить, потому что бизнес не всегда может до конца сформулировать, что он хочет;
-
какие воздействия мы можем оказать;
-
дальше мы описываем бизнес-процессы;
-
предлагаем концепцию решения – как мы меняем бизнес-процессы, если требуется, и какие из них автоматизируем;
-
далее бизнес-анализ закончился, начался системный анализ – мы разрабатываем требования к информационной системе;
-
предлагаем модели решения – как мы реализуем эти требования в системе;
-
критерии приемки – как будем проверять, что требования удовлетворены;
-
в итоге все это доходит до кода.
Давайте посмотрим, что может нам предложить искусственный интеллект на каждом из этапов.

Здесь на слайде показаны типичные задачи аналитика, возникающие в процессе этой работы:
-
разобраться в предметной области
-
предложить цели проекта;
-
предложить воздействия – как мы можем повлиять на деятельность, чтобы достичь цели;
-
построить модель бизнес-процессов;
-
сформулировать требования и т.д.
Чем может помочь искусственный интеллект

В искусственном интеллекте (далее ИИ) есть много разных направлений, и одно из них – это генерация текстов.
Почти все артефакты, которые создает аналитик – это тексты. И ИИ эти тексты может генерировать.
Началось все еще с 1980-х годов, но тогда это выглядело как исследование – никто не предполагал, что это можно будет применять в реальности.
И в 2017 году произошла практически революция в генерации текстов посредством искусственного интеллекта. Началось все с Google.

Я не буду сейчас погружаться в какие-то суровые технические детали – расскажу обзорно: оттуда взялся ChatGPT:
-
В 2017 году Google предложил архитектуру нейросетей «Трансформер», но, как это часто бывает, тот, кто предложил технологию, не смог до конца ею воспользоваться.
-
В 2018-м году эту идею взяла на вооружение компания OpenAI, которая создала на ее основе технологию GPT (Generative Pre-trained Transformer).
-
Сначала у OpenAI была модель просто GPT, потом в 2019 году они выпустили GPT-2. Эта модель просто продолжала текст – вы даете какой-то кусочек текста, и она дописывает вам этот текст так, словно его дописывает человек. Результат работы GPT-2 выглядел довольно тревожно – настолько, что OpenAI побоялись выпускать эту модель публично, они решили, что это убьет журналистику, маркетинг, социальные сети и все на свете. Емкость модели GPT-2 была всего 1,5 миллиарда параметров.
-
В 2020 году вышла GPT-3, у которой было уже 175 миллиардов параметров – это уже больше, чем нейронов в мозгеу человека.
-
На основе GPT-3 натренировали еще несколько моделей. В частности, одна из них не просто продолжала текст, который вы вводите, а выполняла инструкции. Так называемая InstructGPT. Вы говорите InstructGPT: «Придумай стихотворение на тему конференции аналитиков». И она вам пишет стихотворение. «Напиши код на таком-то языке» – она пишет код. Это семейство моделей называется GPT-3.5 – это не следующая версия, а натренированная GPT-3. Натренированы они были в 2021 году.
-
И на основе GPT-3.5 в 2022 году уже появился ChatGPT, который прогремел. Фактически, это просто удобный интерфейс к модели GPT-3.5.
Удивительно, что несмотря на то, что фактически GPT-3,5 был уже почти два года доступен в виде программного интерфейса, в виде API – никто про него в 2021-2022 году не слышал.
Но как только появился интерфейс, в который человек может заходить, давать нейросети задания и сразу получать ответ в браузере, случилось то, что случилось.
ChatGPT на данный момент является самым быстрорастущим проектом:
-
1 млн. пользователей за 5 дней;
-
100 млн. пользователей за два месяца.
Его популярность выросла быстрее, чем все, что было создано до этого. Быстрее любой соцсети и т.д.
Как работает ChatGPT

ChatGPT – это статистическая модель. Его иногда называют stochastic parrot– «статистический попугай», потому что он не понимает, что говорит.
-
У него огромная база, и он статистически вычисляет, какое слово должно стоять следующим на основе предыдущего ввода. Причем, этим следующим необязательно будет именно слово – иногда это части слов. Именно эти слова или части слов представляют собой токены.
-
Токен – это основная валюта ChatGPT. Если вы покупаете API, вы платите за количество токенов, которые использовали.
-
На английском токены – это практически целые слова, на русском это не так. Дело в том, что обучающая выборка на 92% содержала слова на английском языке, а на русском всего 0,18% – русский язык ChatGPT знает по случайности.
-
Он ничего не знает о событиях после 2021 года, и он не продолжает учиться – его научили один раз, и теперь его знания зафиксированы(прим. ред. доклад от 26 мая 2023 года – сейчас уже не так, OpenAI обновила модель новыми фактическими знаниями). -
До недавнего времени он не умел ходить в интернет за новой информацией, но буквально на днях OpenAI объявил, что в приложении есть плагин, который позволяет ему ходить в интернет и узнавать что-то новое.
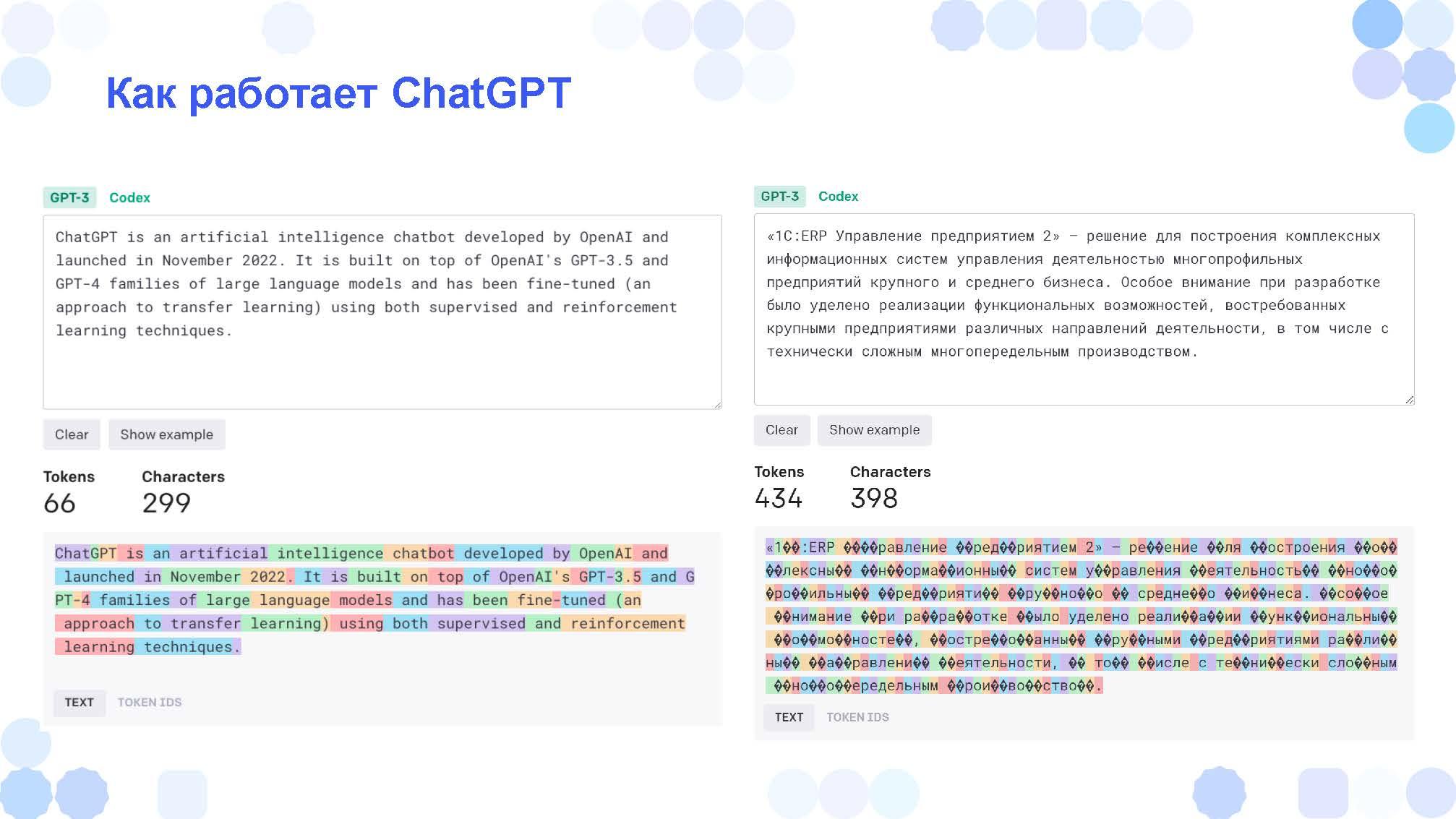
На слайде показано, как текст разбивается на те самые токены.
В примере на английском – здесь почти целые слова.
А в примере на русском он чуть ли не побуквенно генерирует, поэтому на вывод ответов на русском языке тратится существенно больше токенов:
-
66 токенов на почти 300 символов на английском;
-
и 434 токена на почти 400 символов на русском.
Тем не менее по-русски он говорит хорошо.

Как же разговаривать с ChatGPT?
-
С ним можно просто разговаривать, как с человеком. Он натренирован на то, чтобы поддерживать диалог. Именно это и производит такое большое впечатление.
-
Можно не просто попросить его с вами разговаривать, а попросить его выступить в какой-то роли – он умеет играть роль.
-
Его, как и человека, можно в разговоре подводить к какому-то результату. Например, вы ему сначала говорите: «Вспомни, что такое “требования”, и в каких видах их можно записывать. Хорошо. А теперь напиши требование» и т.д. Не кидаете ему сразу какой-то запрос, а подводите к идее через цепочку запросов (промптов).
-
Можно попросить его объяснить, почему он использовал именно такую логику.
-
Можно давать ему пример и просить сделать по образцу – это не всегда получается, но иногда получается.
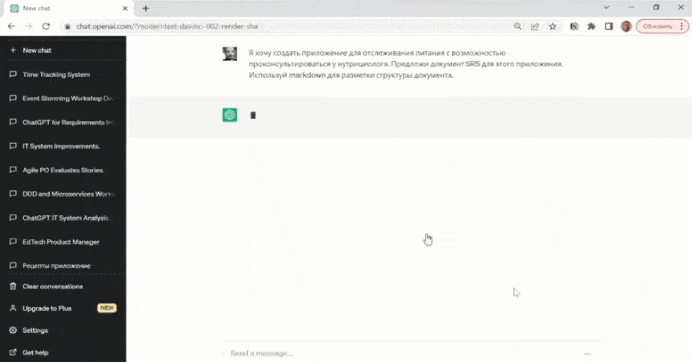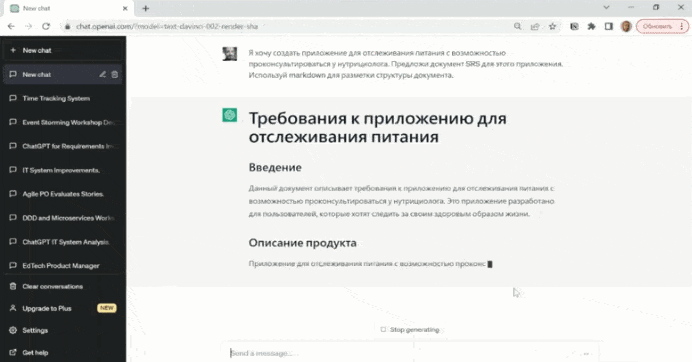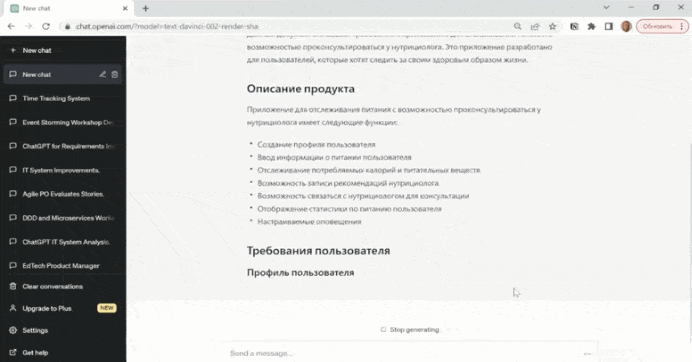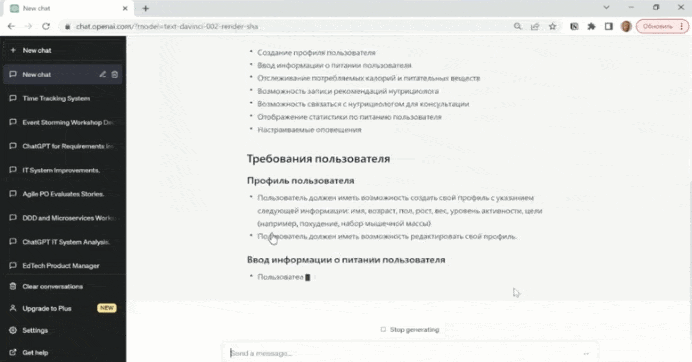
На слайде – пример, как выглядит диалог в ChatGPT.
Он выдает результат не сразу целиком, а печатает. Мне кажется, что эта картинка по значимости для человечества сравнима с фильмом братьев Люмьер «Прибытие поезда». Раньше можно было бесконечно смотреть на то, как горит огонь, течет вода, а теперь бесконечно можно смотреть на то, как ChatGPT печатает вам ответ.
На самом деле он довольно медленно печатает, поэтому далее я буду показывать только скриншоты с результатом.

Что важно учесть:
-
В запросе хорошо бы подсказать ChatGPT, в каком виде мы ожидаем ответ. Если мы не конкретизируем, он придумает формат согласно своей статистике. В этом случае результат может быть неожиданный – совсем не то, что мы ожидаем.
-
Запрос лучше делать на английском.
-
Если что-то не так, можно попросить исправить, сказать: «Ты здесь ошибся», он скажет: «Извините, действительно ошибся, может вот так подойдет?» Вплоть до того, что он может исправлять ошибки в программном коде.
-
Если какая-то сложная задача, то у ChatGPT есть токены и есть окно контекста. На предыдущих слайдах было указано: на запрос и на ответ у ChatGPT дается около 8000 токенов – это то, что он помнит из вашего диалога, плюс его ответ. Это не очень много, примерно две страницы, поэтому очень большие ответы он не может давать и очень большие документы на вход тоже не может получать. Надо нарезать: брать кусочки и из кусочков потом конструировать ответ, разбивать задачу на несколько.
-
Он не умеет рисовать – это текстовая модель. Чтобы сгенерировать какую-то диаграмму, вам нужно задействовать какой-то сервис типа PlantUML, Mermaid.js, GraphViz, который по тексту строит диаграмму.
-
И очень важный момент: результат идентичных запросов не будет одинаковым. Несмотря на то, что это статистическая модель, там есть случайность – он может по-разному отвечать. Даже те промпты, которые я вам дам, могут у вас не сработать по какой-то причине из-за внутренних свойств модели. Можно попробовать несколько раз – он в разное время будет по-разному отвечать на запрос. Поэтому Prompt Engineering (генерация промптов) – это немного искусство.
Разбираемся с предметной областью и проблемами бизнеса

Разберемся с предметной областью и проблемами бизнеса.
Я взял абстрактную тему – прошу ChatGPT выступить в качестве бизнес-консультанта. Есть медицинский центр «Клиника здоровья», который в период COVID терпит потери до 30% общего дохода, потому что врачи болеют, и срываются приемы. Нужно предложить варианты решения проблемы.
Во-первых, это реальный кейс, во-вторых, мы это даем нашим студентам, чтобы они с этим разобрались. Посмотрим, как с этим разберется ChatGPT.
ChatGPT говорит, что готов и предлагает варианты решения проблемы: усилить меры безопасности, ввести телемедицину и т.д.
Ок, мы собираемся создавать IT-решение, развивать телемедицину. Давайте его спросим: «Как развить телемедицину?»

Ответ ChatGPT:
-
определите цели и задачи;
-
разработайте стратегию;
-
создайте инфраструктуру;
-
разработайте программное обеспечение;
-
разработайте интеграцию…
Вполне нормальные ответы, которые мог бы дать и достаточно опытный эксперт.

Далее выбираем цель: хотим сократить затраты на лечение и снизить риск заболеваний медицинского персонала. Просим составить план.
Ответ ChatGPT:
-
Определить целевую аудиторию;
-
Оценить доступность оборудования;
-
Провести обучение медицинского персонала – об этом, кстати, часто забывают. Обратите внимание, ChatGPT здесь советует учитывать не только технические аспекты, но и вопросы этики и конфиденциальности информации. Это интересно. Он периодически выдает такие вещи, про которые с первого раза и не вспомнишь. Мы все сфокусированы на ИТ-решениях, а ChatGPT в этом смысле мыслит более широко.
-
Предлагает провести пилотный проект – не сразу внедрять, а провести пилот. Умный.

Спрашиваем его конкретику: Телемедицина же, наверное, регулируется. Какие есть стандарты, связанные с телемедициной?
И здесь начинается такая штука, которая называется галлюцинация.
Когда вы хотите спросить не какой-то общедоступный и общепонятный вопрос из общего представления о деятельности людей, а что-то конкретное: конкретную книгу, конкретный стандарт, какой-то конкретный закон, то ChatGPT вам ответит, но он это придумает.
Сработает статистика, будет очень похоже на название, как на слайде: ГОСТ такой-то, Р ИСО, придумает федеральные законы таким же образом, постановления правительства и т.д.
Где-то он попал, а все остальное – фантазии. Поэтому доверять ChatGPT в фактологии не стоит. Он – модель общего назначения. (прим. ред. доклад от 26 мая 2023 года – сейчас с этим тоже стало лучше, но, конечно, галлюцинации тоже встречаются).

Хорошо. Далее мы просим ChatGPT сформулировать цель проекта.
Он сформулировал нормально, но слишком обще – если вкратце, то: «За все хорошее, против всего плохого».

Наводим его на мысль. Мы хотим снизить заболеваемость. Он говорит: «Ок, хорошо, я переформулирую».
ChatGPT суперотзывчивый. Он может сказать нет – я чуть позже скажу, когда. Но если вы его просите, он готов все делать, как вы хотите: переформулировать, добавлять и т.д.

Снова наводим его на мысль, что цели вообще-то формулируются по SMART. Спрашиваем, что это такое. Он в курсе.

Теперь просим переформулировать цель проекта по критериям SMART. И вот у него появилось «…на 30% в течение первого года» – ограничил по времени и добавил измеримость. Молодец, соображает.

Что еще можно сделать в плане выявления бизнес-проблемы?
Можно подготовиться к интервью со стейкхолдером. На слайде примеры трех промптов:
-
сначала широкий;
-
потом уточняющий;
-
потом еще более уточняющий – когда мы сужаемся до одного бизнес-процесса. Сначала ChatGPT нам выдаст общую канву, а потом можно идти вглубь, делать drill down: выбираем один бизнес-процесс и спрашиваем уже дальше только по нему.

Ну и навскидку другой пример – система подготовки учебного контента для какой-то онлайн-школы: «Поговори с человеком, который не знаком с нюансами IT и выясни у него бизнес-процессы».
Он спрашивает про бизнес-процессы,
-
С какими проблемами вы сталкиваетесь;
-
Какие вопросы безопасности и конфиденциальности вы считаете наиболее важными для вашей работы – такое тоже не вдруг вспомнишь;
-
Мне понравился вот этот вопрос: «Как вы представляете себе план внедрения нашей платформы?» А то ж обычно никак не представляют. Мы софт сделали, отдали и все – дальше ничего, с нас взятки гладки. А это может быть самое сложное.
Дальше можно спрашивать про каждый пункт, он будет генерировать дополнительные вопросы, а можно попросить ChatGPT сыграть роль стейкхолдера и попробовать ответить на эти вопросы тоже. Получается система сама в себе.

Может предложить еще несколько вопросов. Например, поддержка и обслуживание, интеграции.
Выявляем бизнес-процессы и формулируем функциональные требования к системе

Мы разобрались с предметной областью, провели интервью. Теперь давайте посмотрим на бизнес-процессы поглубже и сформулируем функциональные требования к системе.
Бизнес-процессы мы обычно рисуем. ChatGPT рисовать не умеет, но он умеет писать код. Например, он может выдать код BPMN-диаграммы в виде XML.
Мы этот XML сохраняем как файл, загружаем в ту же Comunda и получаем примерно такую штуку:
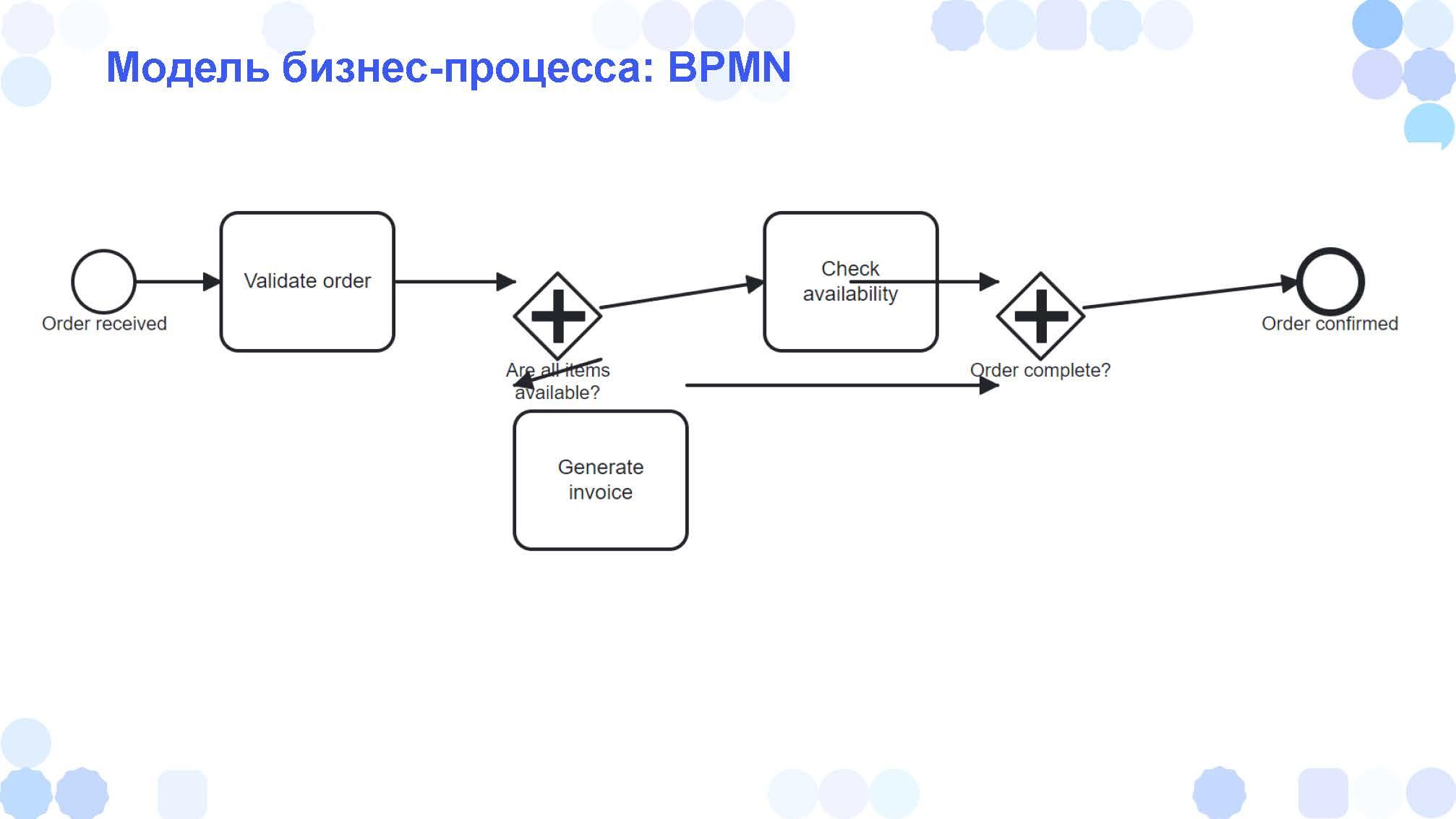
Ну немножко разъехалось. Хотя у меня ребята порадовались: «Какой молодец, нарисовал так, как это в жизни будет происходить».
Если вы игрались с Midjourney или с другими нейросетями, генерирующими изображения – они часто по 7-8 пальцев рисуют, по три руки, у ChatGPT примерно такая же проблема – он схемы не умеет рисовать.
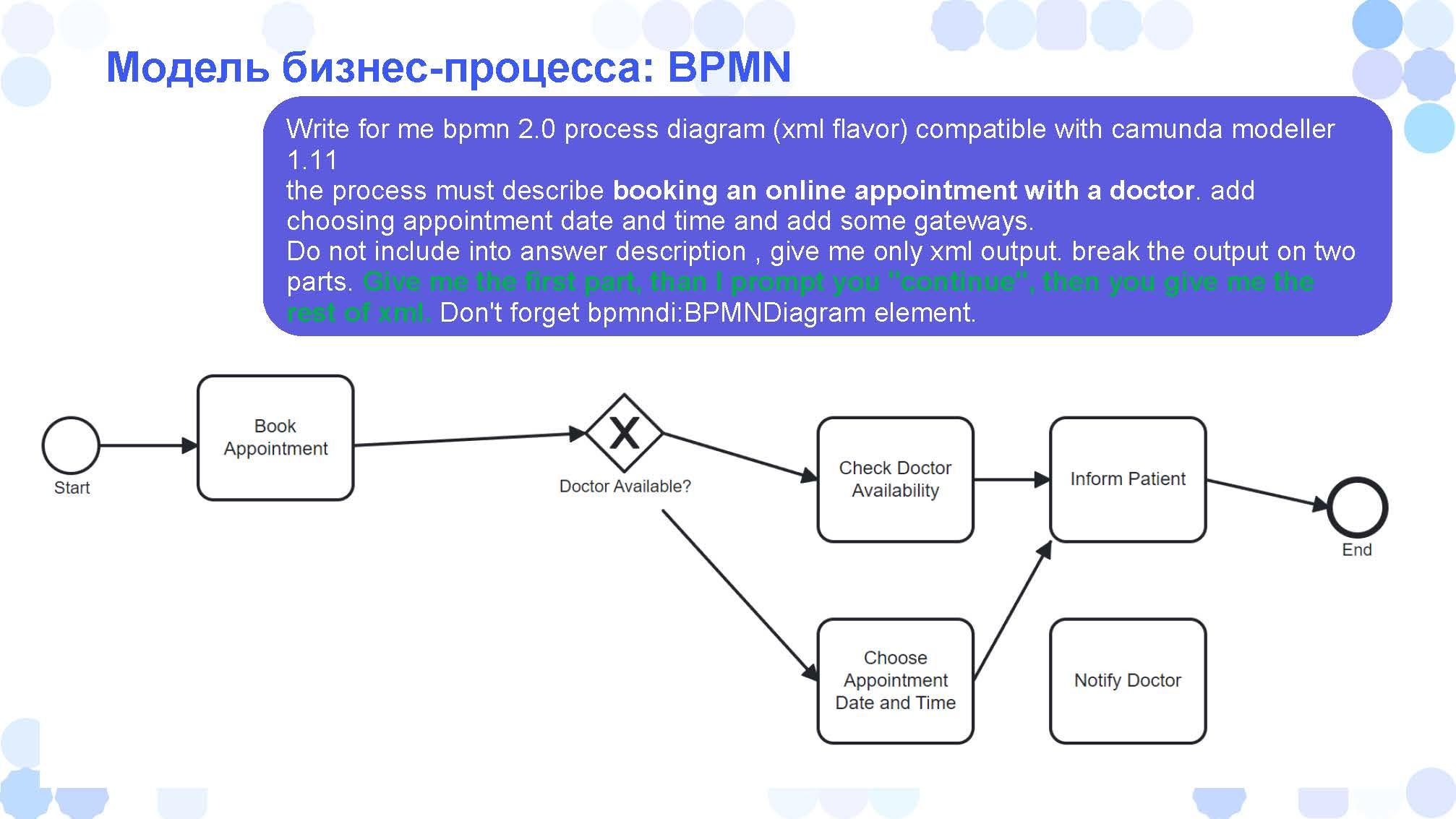
Здесь получилось чуть получше, но все равно не все корректно – процесс «Запись на прием к врачу» отдельный, без стрелок вообще. Сложно.
Почему сложно?
-
Во-первых, сам BPMN так устроен, что даже в виде XML там нужно указать точные координаты – откуда и куда каждая стрелочка приходит. А у ChatGPT с математикой все плохо, он теми же самыми токенами пытается генерировать числа. Он не понимает, что такое число. Для него число – это кусочек строки текста, и он наиболее вероятные туда подставляет числа. Поэтому с ориентацией в пространстве у него не очень хорошо. К сожалению, нет никакого хорошего инструмента, чтобы нарисовать BPMN-диаграмму, не указывая конкретных чисел.
-
Плюс – за счет того, что это XML, он очень избыточный, там много дополнительных элементов, и все токены тратятся на XML-теги. Поэтому редко какой процесс вы сможете описать одним выводом – обычно придется делать все в несколько этапов. Поэтому не будем его BPMN-ом мучить.
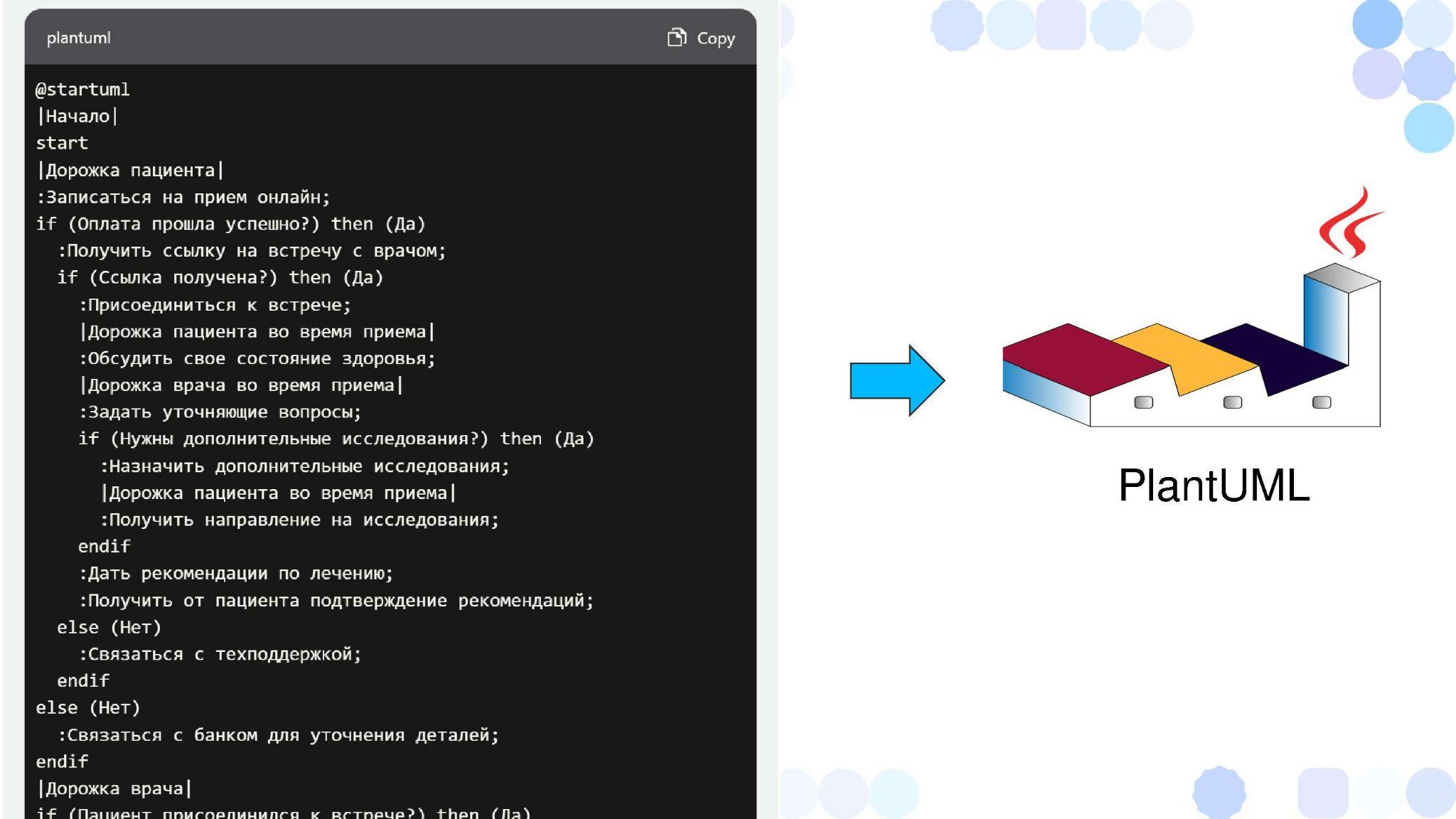
Вместо этого мы можем его попросить нарисовать не BPMN, а Activity Diagram из UML, используя нотацию PlantUML.
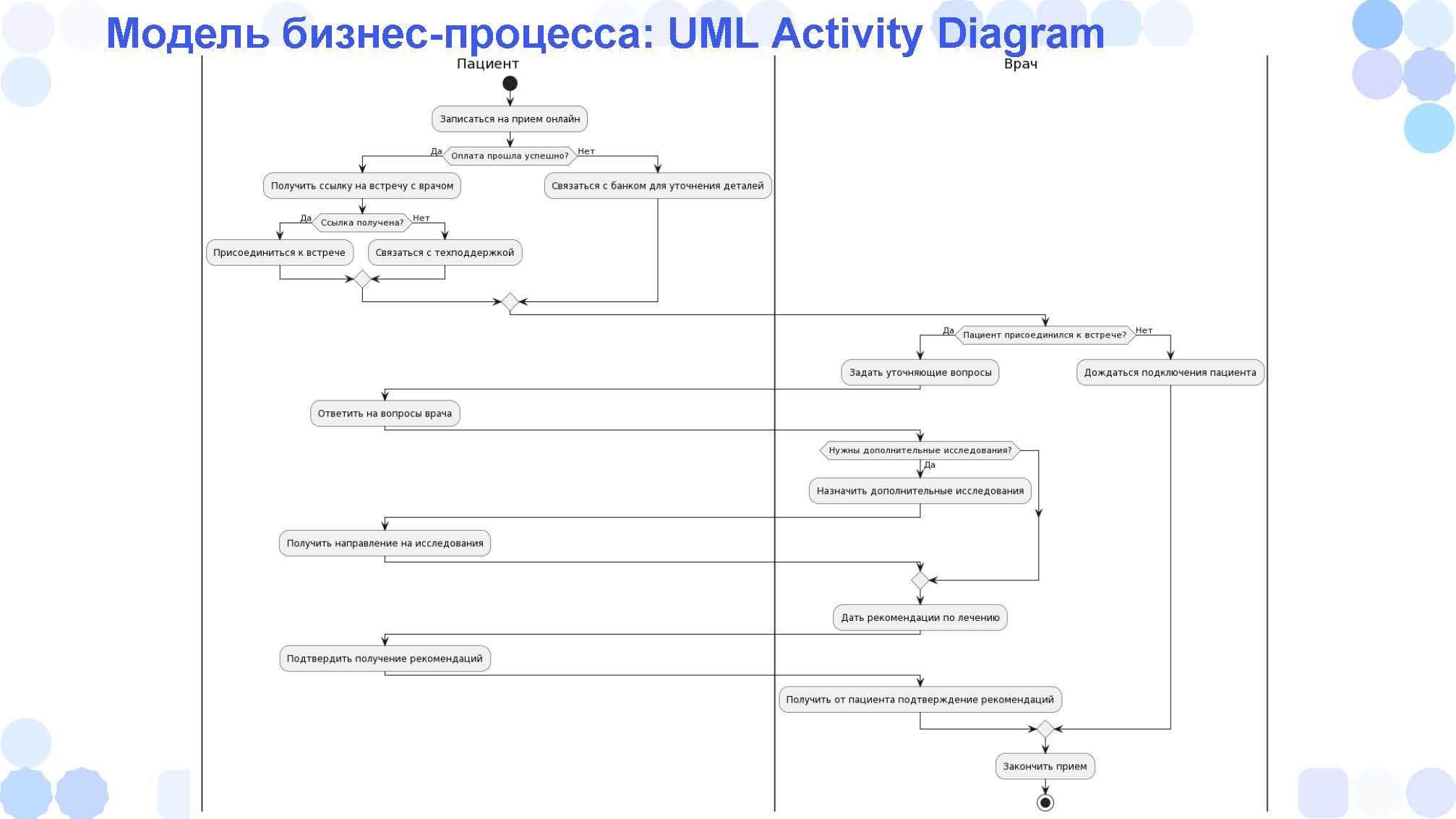
Это попроще, потому что в PlantUML не XML, и ChatGPT более-менее это рисует.

С бизнес-процессами не очень задалось, давайте теперь попросим ChatGPT написать, например, пользовательские истории (user story).
Функциональные требования можно оформлять в разных вариантах:
-
пользовательскими историями;
-
через Use Cases;
-
можно классическими требованиями: «Система должна делать то и это».
ChatGPT в принципе все это знает и умеет, ему не надо объяснять, как писать User Story. Он пишет: «Я как пользователь хочу создать то и то».
На слайде показано, как ChatGPT генерирует пользовательские истории к приложению для отслеживания питания, с возможностью проконсультироваться у нутрициолога.
Я специально беру немного разные системы, чтобы показать, что ChatGPT ориентируется в разных областях.

Мы можем попросить ChatGPT сделать карту пользовательских историй, User Story Map, чтобы создавалось целостное представление о процессе, и пользовательские истории были записаны в отношении каждого отдельного шага этого процесса.
Мы даем ему несколько промптов, говорим это вывести в таблицу.
Он выводит таблицу – мы ее копируем, вставляем, например, в Miro или через API можно загрузить в систему учета задач типа Trello или Jira.

В Miro вставляем таблицу как стикеры, поворачиваем и у нас получается User Story Map в виде стикеров в Miro с разбивкой по релизам. А дальше начинаем перетаскивать – как мы обычно с User Story Map работаем.

Use cases – если нам нужно более детально спроектировать взаимодействие пользователя с системой. .
ChatGPT описывает пользовательские сценарии точно так же: сначала список, а потом мы просим описать каждый конкретно – и он пошел по структуре Use Case.

Здесь Use Case – проконсультироваться с нутрициологом. ChatGPT пишет:
-
Какие здесь есть действующие лица.
-
Предусловия: система должна иметь информацию, пользователь должен иметь доступ.
-
Триггер – процесс начинается с того, что пользователь выбирает функцию.

Основной сценарий:
-
пользователь запускает приложение;
-
пользователь выбирает день и время консультации;
-
система проверяет доступность и т.д.
Честно говоря, я бы здесь как преподаватель придрался бы к формулировкам этого Use Case, потому что не должно быть «если», должно быть что «система удостоверяется» и т.д. Но в первом приближении нормально, меня устроит.

Еще у Use Case есть альтернативные сценарии – что может пойти не так. На слайде просто вывод модели – то, что она генерирует.

ChatGPT может сгенерировать техническое задание сразу в виде документа – насколько ему хватит токенов, он все это сгенерирует.
Правильно или неправильно – про это можно долго спорить, но это хорошее подспорье. Вы уже не пишете все с нуля, а просто проверяете за ним. Где-то что-то убираете, где-то что-то добавляете, и ваша работа за счет этого ускоряется.
Модели системы: данные, состояние, последовательность

Переходим к моделям системы. Требования мы собрали, давайте подумаем про реализацию: как система может выглядеть и что мы можем придумать.
Что еще может делать ChatGPT: мы можем дать этой машине какой-то текст и дать задание что-то с этим текстом сделать.
Обычно мысль не идет дальше какой-то суммаризации, например: «Вот тебе текст, выдай его содержимое на один абзац».
Можно сделать хитрее: попросить ChatGPT выписать все объекты из текста и построить диаграмму объектов. Именно такой анализ я прошу делать студентов на наших курсах, и ChatGPT с этим справляется

Даем ChatGPT какой-то текст – главное, что он должен вмещаться в один промпт.
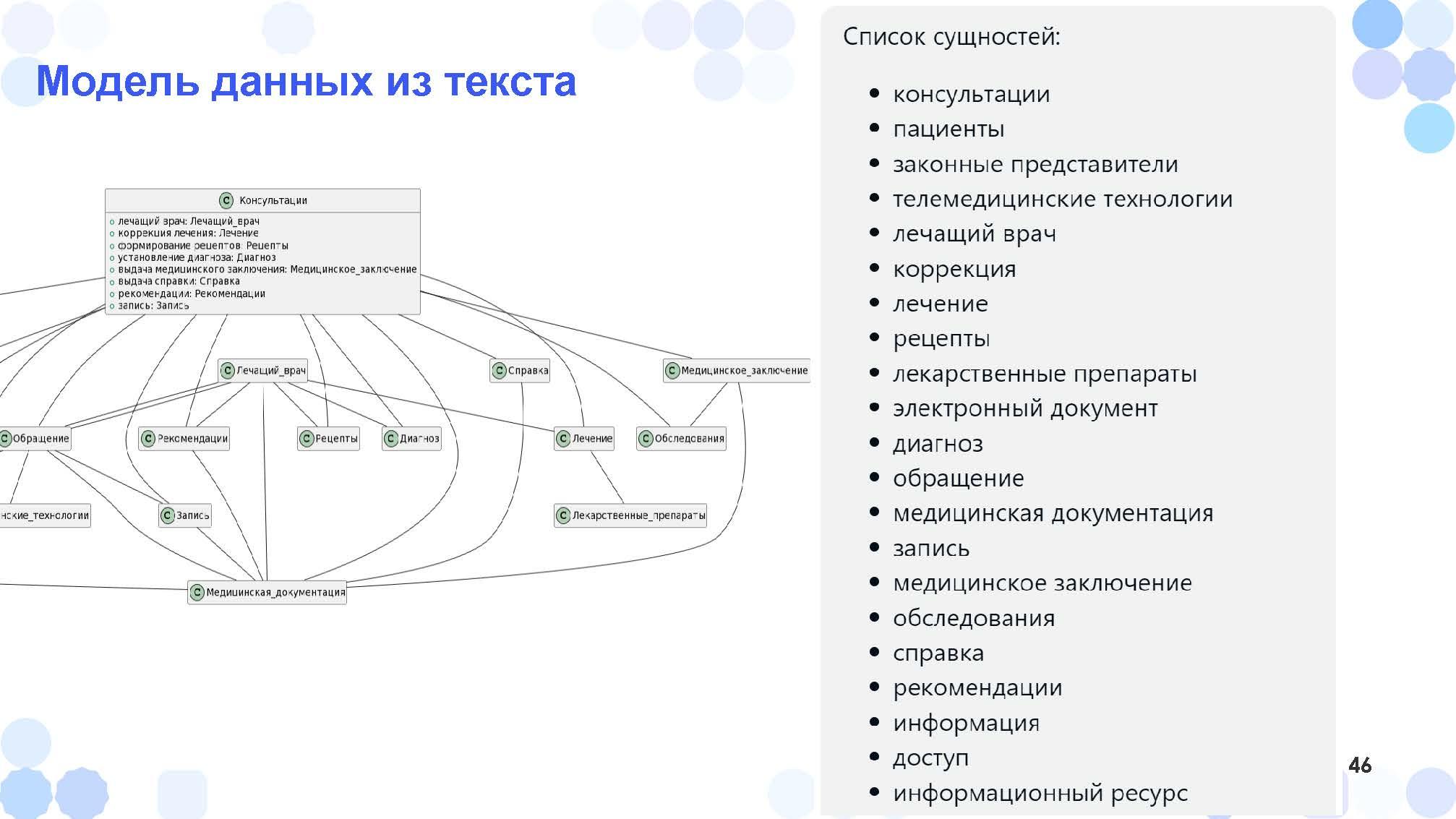
ChatGPT его читает и делает из него:
-
во-первых, список функций;
-
во-вторых, PlantUML делает из него уже диаграмму классов – то есть связи из текста он тоже может вытащить.
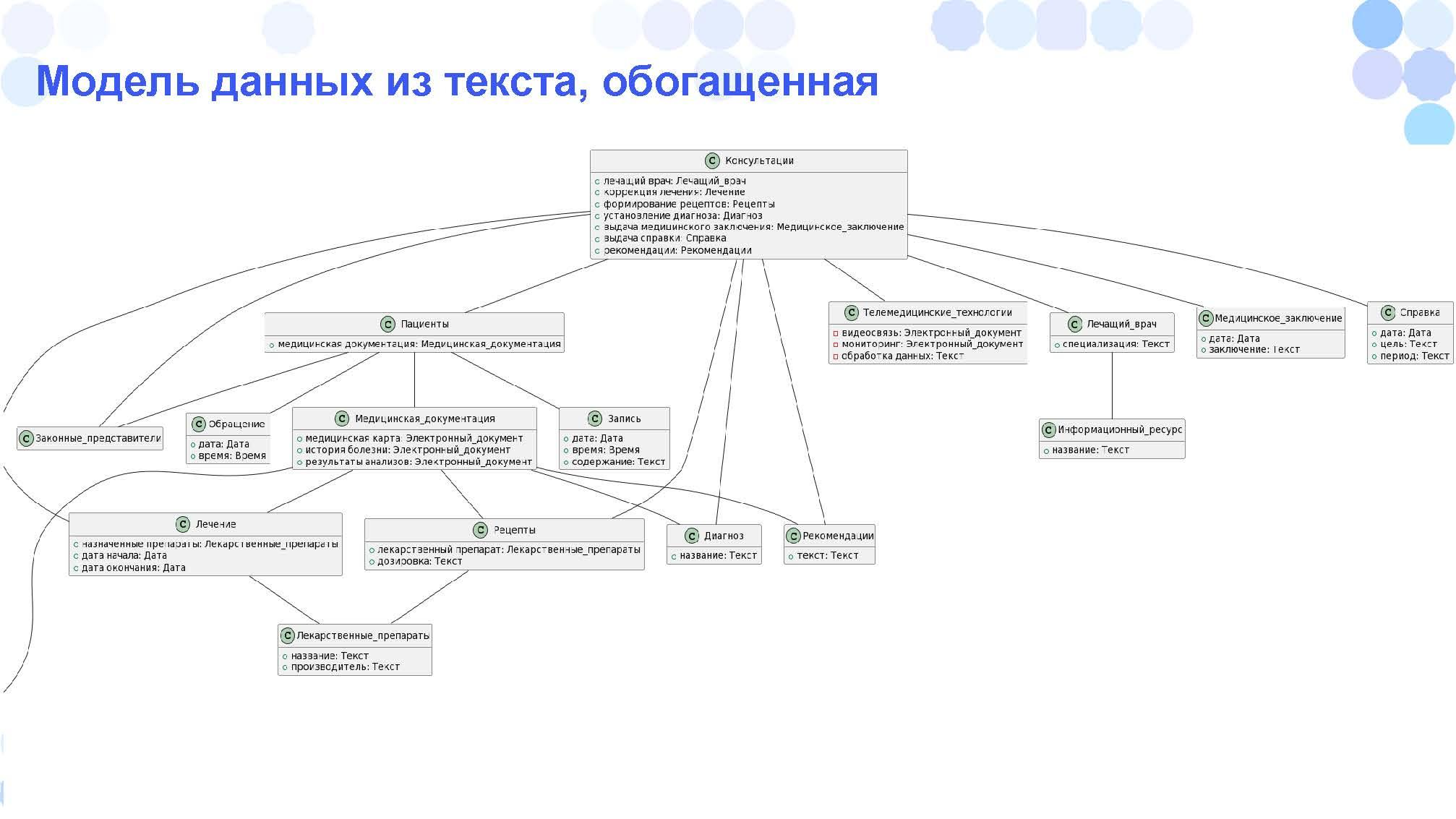
Если вторым запросом его попросить: «Добавь дополнительные атрибуты для этих объектов, как ты считаешь нужным.» – ChatGPT добавляет.
Опять же, с этим можно работать, это уже хорошая заготовка, чтобы идти дальше.

Если текст не вмещается в один промпт, есть хитрый прием. Можем задать два промпта подряд. Говорим ChatGPT: «Сначала я дам тебе начало текста. Ты скажи, когда ты его загрузишь в себя, я дам тебе вторую часть. И когда будешь выдавать мне результат, ты их склей». Эта схема работает.
Если у нас кусок текста, кода или еще чего-то еще слишком большое, чтобы уместилось в один промпт, можно попытаться задать этот текст для ChatGPT двумя промптами.
Точно так же работает и с выдачей. Если он не справляется выдать за один ответ BPMN, диаграмму или другой текст, можно ему сказать: «Дай мне первую часть этого текста в одном ответе. Потом я тебе напишу слово “Продолжай” и дай мне продолжение этого текста».
За три раза так сделать получается не всегда, ChatGPT иногда теряет контекст: окно уходит, и он забывает, о чем мы его просили. Но иногда получается.
Поскольку это недетермиринованная модель, у нее присутствует нестабильность работы, поэтому здесь есть место для некоторых экспериментов. Сегодня не получилось, попробовали немного поменять промпт, и может получиться в другой раз.
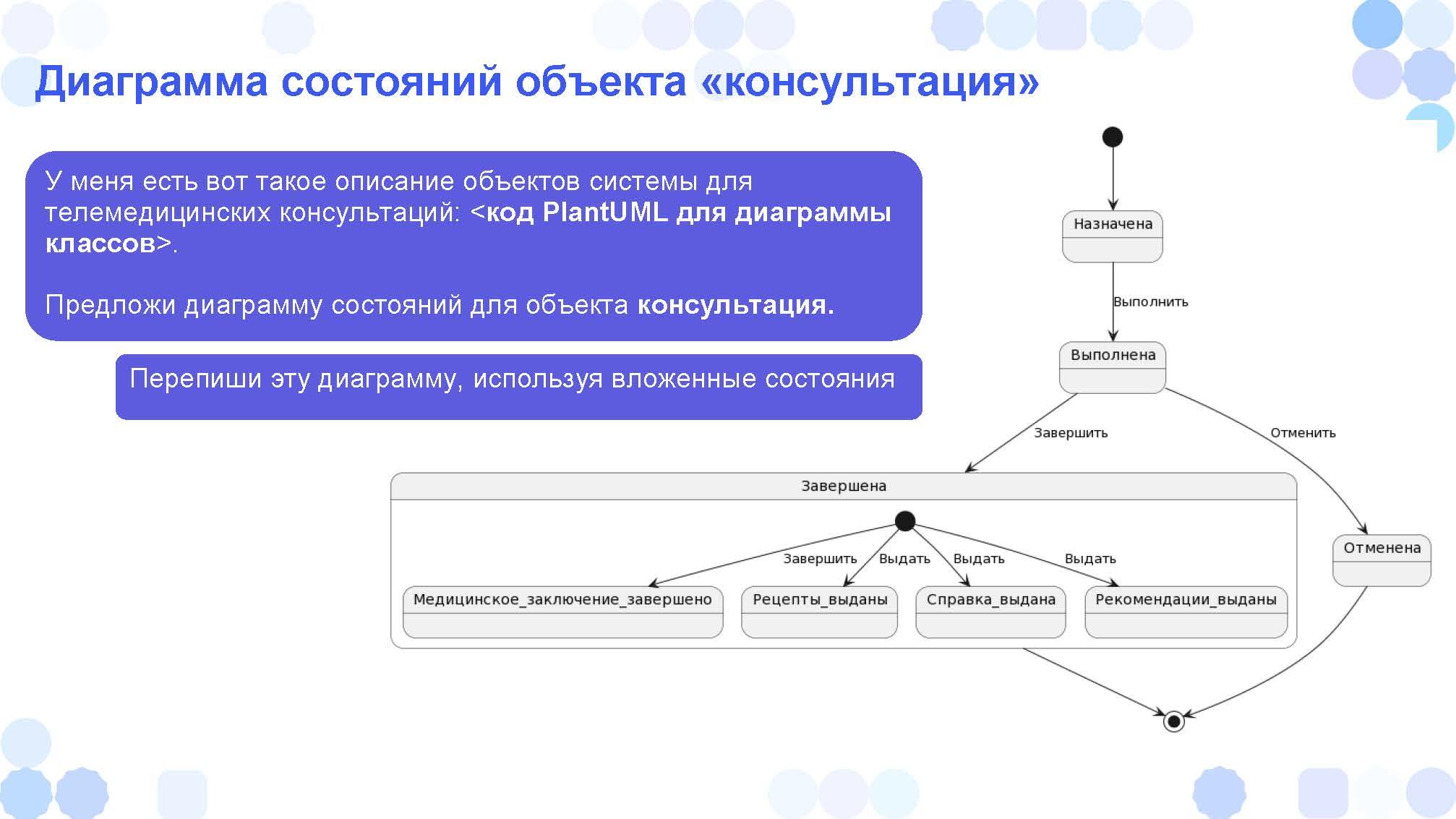
С помощью диаграмм мы описываем нашу предметную область с разных сторон:
-
Через бизнес-процессы описали – что у нас происходит, и что люди делают;
-
Через объекты описали – в случае с 1С наиболее часто это те самые учетные регистры, где вы учитываете какую-то информацию.
-
Еще можно попросить ChatGPT написать диаграмму состояний. Если какой-то объект имеет различные состояния – такое очень часто бывает в системах: как правило, есть одна заявка или документ, и можно представить почти всю работу системы через переход состояний этого центрального объекта. Их тоже можно здесь рисовать и делать их достаточно сложными, в том числе вложенными.
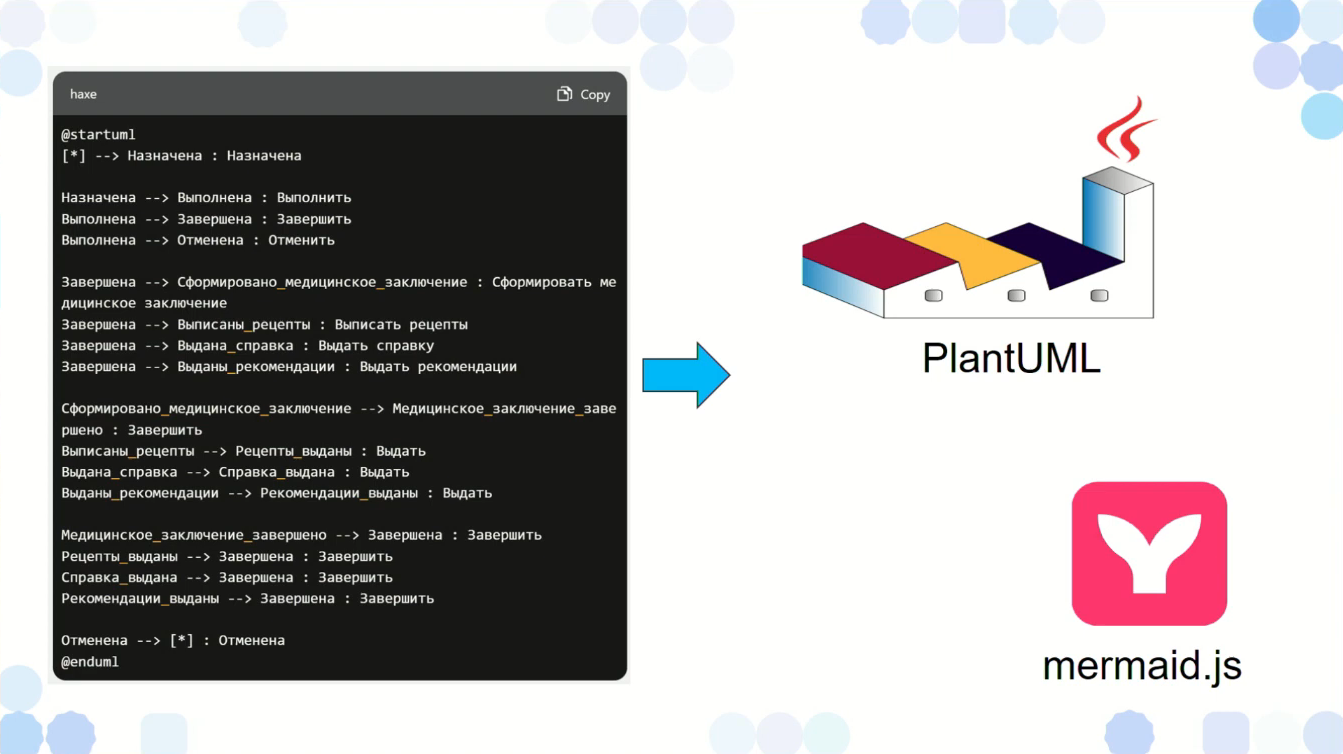
По запросу ChatGPT выдает текст на PlantUML – в случае на слайде это как раз будет модель состояний.
Мы копируем полученный текст, вставляем его в PlantUML (или в аналогичный сервис mermaid.js) и получаем на выходе изображение.
Часто бывает, что внутри этого кода есть какая-то ошибка: либо ChatGPT его как-то неправильно сгенерировал, либо он где-то не то слово подставил. Просить ChatGPT найти и исправить эту ошибку иногда может быть мучительным процессом. Он будет пытаться, у него не будет получаться, он так попробует, сяк попробует…
Поэтому я делаю на него скидку – просто вставляю результат его генерации в PlantUML и оцениваю результат. Если где-то есть ошибка, я сам исправляю. Когда проблема в одной-двух строчках, мне проще самому исправить, чем заставлять искусственный интеллект искать ошибку. Так бывает, и к этому нужно быть готовым.
Когда ChatGPT сгенерирует вам кусок текста, достаточно что-то в нем поправить, где-то что-то скопировать и перенести. Все равно это происходит быстрее, чем писать вручную.
А здесь у вас получается совместная работа: вы не отдаете полностью искусственному интеллекту на откуп всю генерацию всех аналитических артефактов. Вы – художник, а он – подмастерье: он грунтует холст, что-то дорисовывает, а вы потом рукой мастера делаете пару взмахов, и возникает шедевр.
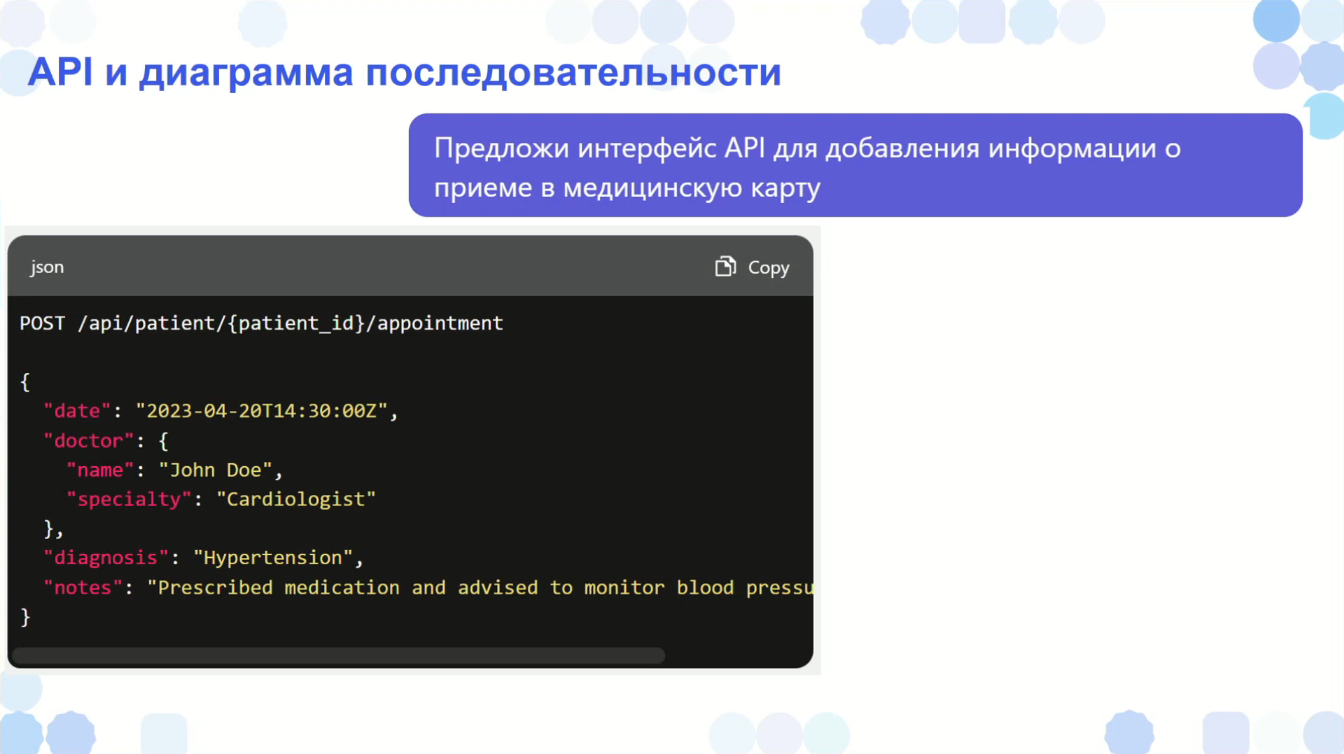
Продолжаем все дальше спускаться по этим ступенькам к уровню кода. Диаграмма последовательности и программные интерфейсы.
ChatGPT может придумать интерфейсы, например «добавление информации в медицинскую карту». Притом это полный запрос – я больше ничего не говорил. А он сам придумал, что здесь еще могут быть какие-то примеры, вставляет и показывает их.
Дальше с ним можно поговорить о том, что должно быть в медицинской карте, и как она должна быть устроена.
Сейчас здесь в ответе один endpoint, но можно дальше его можно попросить сгенерировать всю спецификацию для Swagger, если вы им пользуетесь.
Скорее всего, это нужно будет сделать в несколько приемов, потому что вся спецификация получится достаточно длинной.
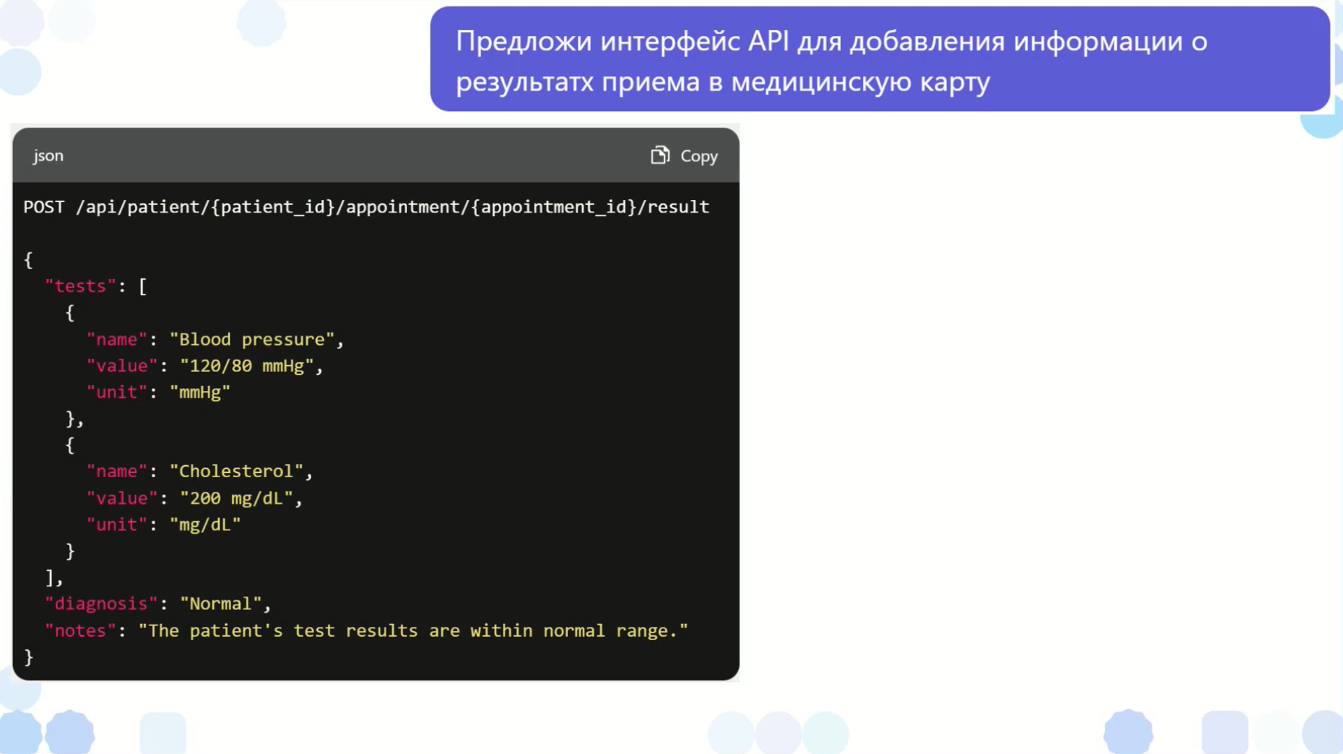
Здесь он показывает, как будет выглядеть спецификация для результатов приема.
ChatGPT понимает, как конструируется endpoint в REST API. Как вы видите, здесь в названиях endpoint-ов нет глаголов, только различные ресурсы.
В этом смысле он иногда действует лучше, чем какие-нибудь аналитики, которые пишут в названиях endpoint-ов API глаголы, а не используют классический REST-подход.
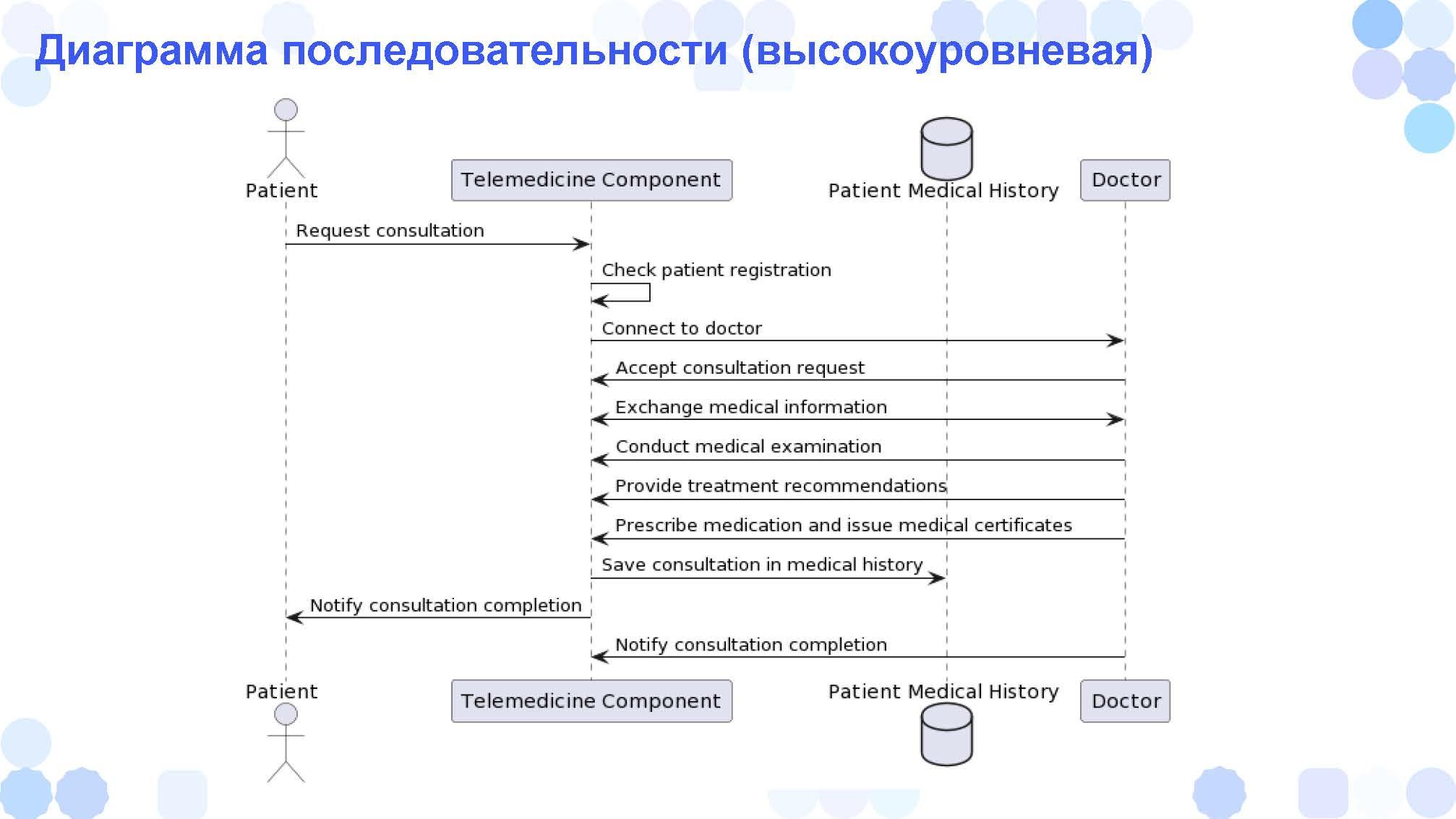
Когда у нас речь заходит о взаимодействии систем, это взаимодействие хорошо показывать в виде sequence-диаграммы – диаграммы последовательности из UML.
Если делать анализ статистики запросов, на текущий момент sequence-диаграммы из UML самые популярные, потому что тема интеграций в принципе востребована и популярна. Вы можете никакие другие диаграммы не использовать, но sequence вы обязаны уметь рисовать.
У CHatGPT получилась достаточно высокоуровневая диаграмма последовательности – описан весь процесс приема у врача, причем довольно странновато.
Можем попросить ее детализировать.

Например, мы можем просто описать ему на естественном языке, как устроен прием у врача. Неважно откуда мы этот текст взяли – может из интервью, может из какого-то документа.
Даем текст и говорим: «А теперь эту последовательность изобрази, пожалуйста, в виде sequence-диаграммы на языке UML».
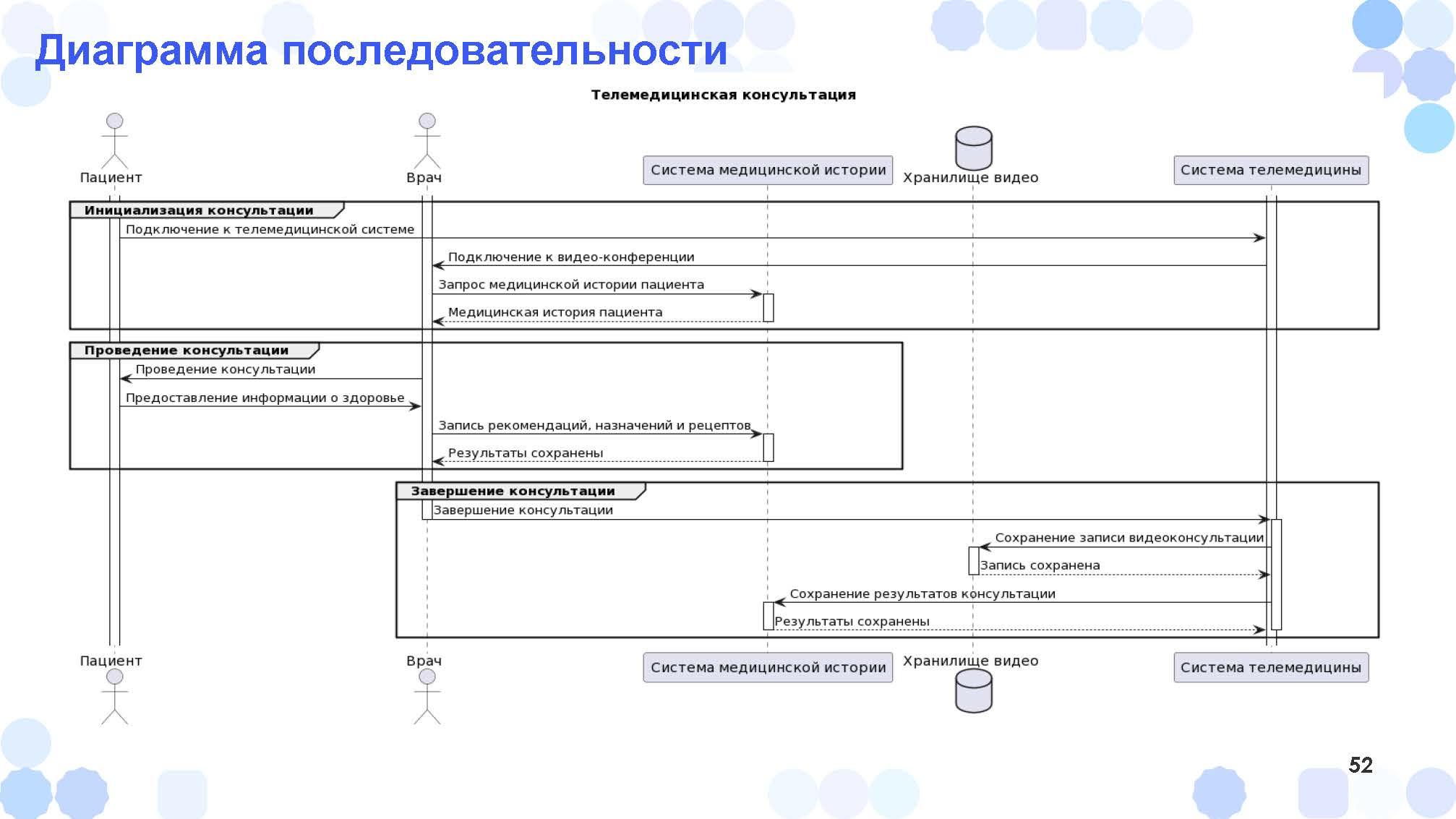
Здесь диаграмма последовательности получилась даже сложнее. Здесь проявляется эффект неожиданности: мы не говорили, что какие-то действия нужно объединять. А ChatGPT сам решил их объединить в пакеты:
-
инициализация консультации,
-
проведение консультации,
-
завершение консультации.
Можно написать ему конкретно: «Пакеты не используй!» или наоборот: «Используй пакеты, разбей этот процесс, сгруппируй взаимодействие на какие-то части».
Здесь есть небольшая хитрость – когда ChatGPT выдает результат, с ним потом можно работать, как с заготовкой. В исходном UML на месте «Хранилища видео» был прямоугольник – я посмотрел, как в PlantUML прямоугольник заменить на бочонок (чтобы это было хранилище), и поменял в тексте.
Получается, что работа с диаграммами после ChatGPT сводится к добавлениям отдельных штрихов.

У вас в экосистеме 1С есть очень классная штука – Vanessa Automation. В ней можно написать BDD-сценарии проверки и запустить их. А она автоматически будет проверять функциональность и даже генерировать видеоинструкции.
Штука отличная. Я всем рассказываю: «Вы думаете, что в 1С все плохо? А там есть ТАКОЕ!» И люди, которые никогда с этим не сталкивались, у них глаза становятся круглые, и они спрашивают: «И видеоинструкции еще?! Ничего себе!»
И если вы видели BDD-сценарий, он представляет собой текстовый файл в определенном формате (given, when, then и т.п.). ChatGPT его отлично генерирует.
Вы даете описание какого-то процесса, какой-то функции, фичи, требования. Если вам нужно это сделать конкретно под 1С, можете написать: «Используй при этом такие-то существительные», которые Vanessa Automation потом автоматически распознает, и он сгенерирует вам этот BDD-сценарий.
Реверс инжиниринг

Использование ChatGPT – это тоже очень хорошее подспорье для реверс инжиниринга.
Ему на вход можно подать функцию/процедуру и попросить объяснить, что она делает. В том числе (я пробовал специально) на языке, который используется в 1С.

По виду функции он может объяснить, что здесь происходит человеческим языком.
Это касается и запросов и непосредственно кода.

Подаем запрос – он расшифровывает запрос.

В обратную сторону он тоже может. Вы человеческим языком ему пишете: «Сделай мне запрос остатков со склада, отбери товары таких-то поставщиков» – он напишет.
Языков программирования он знает много. Если у вас стоит задача взять какую-то существующую систему не на 1С, и сделать постановку требований для реализации ее на 1С, он может вам помочь.
Если вы доберетесь до скриптов, которые есть в исходной системе, он объяснит вам, например, что делает этот SQL-запрос или что делает эта функция.
Вы можете описать ему экранную форму: «На этой экранной форме находятся такие-то поля» или дать html-код экранной формы. Он создаст вам текстовое описание экранной формы и попытается предположить – что эта экранная форма делает, какой процесс она автоматизирует.
Заключение

Как можно применять ChatGPT:
-
Можно прорабатывать требования и использовать результат как некий шаблон, чек-лист или подсказку.
-
Можно переводить текст в диаграммы. Как вы видели он берет кусок текста на естественном языке, рисует диаграмму, а можно попробовать наоборот;
-
Можно раскрывать объем – по короткому описанию генерировать набор функций, набор пользовательских историй или набор Use Cases.
-
Можно вычленять из текста какие-то структурированные данные, например, набор объектов, последовательность действий, описание бизнес-процессов, состав ролей пользователей.
-
Можно использовать для написания заготовок кода, требований.
-
Можно использовать для реверс инжиниринга – чтобы он описал какую-то существующую функцию на человеческом языке.

Часто возникает вопрос: что с безопасностью?
-
ChatGPT сохраняет все ваши запросы, но не присоединяет их в свою модель. По умолчанию другие пользователи ваши запросы не увидят, но их могут увидеть инженеры OpenAI. Они это анализируют в обезличенном виде, как-то перемалывают и делают файн-тюнинг этой модели, но они это могут увидеть.
-
Если вы получаете доступ через API – не через ChatGPT, а GPT-3.5, ваши данные никому не доступны. Уровень их сохранения такой же, как если бы вы использовали какой-то облачный сервис.
-
Сейчас другие компании тоже начали эту технологию догонять – Google уже выпустил свою модель.
-
Также очень активно развивается Open source-движение, которое позволяет эту модель, может быть не такую крутую, как ChatGPT, поставить себе и натренировать ее самостоятельно. Если вас очень сильно волнует безопасность, вы можете поставить ее непосредственно на ваших серверах – никто к ней доступа не получит.
Все это развивается очень активно, и я думаю, что в ближайшие годы мы много интересного увидим на основе этих технологий.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции "Анализ & Управление в ИТ-проектах".
