












Если вы еще не знакомы с Github Actions, то начать лучше с первой статьи по теме:
Особенности национального Workflow: Github Actions и OneScript
Иначе многое может быть непонятно
 Если вы еще не знакомы с Github Actions, то начать лучше с первой статьи по теме:
Если вы еще не знакомы с Github Actions, то начать лучше с первой статьи по теме:
В прошлый раз мы рассмотрели, что такое Github Actions и создали самый простой Workflow, который устанавливал OneScript и, с его помощью, выводил в консоль "Привет мир" - он состоял из одной работы и всего нескольких шагов. Это, разумеется, не предел - сейчас мы разберем, как сделать из одиночных работ полноценный многошаговый процесс, передавать между этими процессами информацию, а по итогу получить некоторый завершенный результат
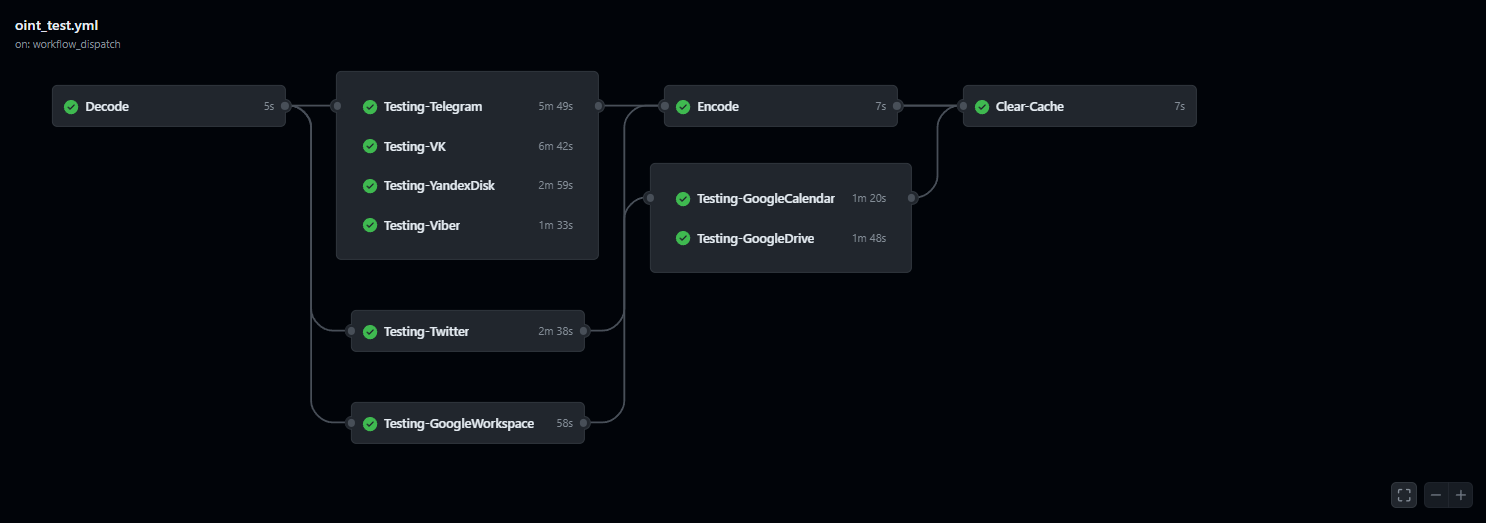
Процесс тестирования OneScript версии Открытого пакета интеграций, например
Вернемся к нашему yml-файлу из прошлой статьи:
name: Test
on:
workflow_dispatch:
jobs:
RunOneScript:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: otymko/setup-onescript@v1.4
with:
version: 1.9.0
- name: Запускаем OneScript
run: oscript ./workflow.os
Как мы помним, тут есть одна работа - RunOneScript, которая состоит из 3-х простых шагов
- Неименованного шага использования стандартного действия для доступа к репозиторию (checkout)
- Неименованного шага использования действия от otymko для установки OneScript
- Именованного шага запуска скрипта из файла workflow.os, который лежит у нас в репозитории
Пришло время добавить сюда второе действие. Для этого на том же уровне табуляции, (табуляция в yml крайне важна) что и RunOneScript, необходимо ввести название новой работы и заполнить её содержимое
name: Test
on:
workflow_dispatch:
jobs:
RunOneScript:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: otymko/setup-onescript@v1.4
with:
version: 1.9.0
- name: Запускаем OneScript
run: oscript ./workflow.os
MySecondJob:
runs-on: ubuntu-latest
steps:
- name: Шаг из второго действия
run: echo "Это второе действие"
Запустим и взглянем на схему выполнения

Работы объединены в одну группу. Это означает, что каждая из них выполняется параллельно - независимо от степени выполнения другой.
Такой вариант имеет право на жизнь, однако куда чаще различные работы необходимо выполнять не параллельно, а друг за другом - последовательно. Для этого в GA существует блок needs
needs принимает массив работ, завершение которых необходимо для запуск текущей. Добавим в работу MySecondJob подобную зависимость от RunOneScript
name: Test
on:
workflow_dispatch:
jobs:
RunOneScript:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: otymko/setup-onescript@v1.4
with:
version: 1.9.0
- name: Запускаем OneScript
run: oscript ./workflow.os
MySecondJob:
runs-on: ubuntu-latest
needs: ["RunOneScript"] # При зависимости от одной работы допустимо указание и без квадратных скобок
steps:
- name: Шаг из второго действия
run: echo "Это второе действие"
Теперь наша схема выглядит следующим образом

Выполнение работы MySecondJob начнется только после успешного выполнения RunOneScript. Однако, помимо указания порядка запуска работ, мы можем указать дополнительные условия, выполнение которых будет регламентировать, запуститься ли вообще следующая работа или нет
Делается это при помощи оператора if. Он может принимать любые переменные среды и сравнивать их с указанными значениями - как условие "если" в любых других языках программирования. Отдельного внимания (ввиду наиболее частого использования) тут заслуживают специальные, служебные переменные, отвечающие за статус выполнения предыдущей работы. К ним относятся:
- ${{ always() }} - несмотря ни на что
- ${{ cancelled() }} - если workflow был остановлен вручную
- ${{ failure() }} - если предыдущая работа была завершена с ошибкой
- ${{ success() }} - если предыдущая работа была завершена успешно
С полной документацией по условиям можно ознакомиться тут, отметим лишь, что:
- if можно применять не только к работам, но и к шагам. По умолчанию, если какой-либо шаг завершается с ошибкой, то выполнение работы не продолжается. Избежать этого можно подобным образом:
... - name: Выполнить Шаг 1 if: ${{ cancelled() }} == false run: echo "Шаг 1" - name: Выполнить Шаг 2 if: ${{ cancelled() }} == false run: echo "Шаг 2" ...Вне зависимости от результата выполнения Шага 1, Шаг 2 начнет свое выполнение следом
-
Важно различать always() и !cancelled() (cancelled() = false). В отличии от !cancelled(), allways() продолжит свое выполнение, даже если вы попытаетесь прервать рабочий процесс вручную
Подправим наш yml файл - добавим условие ${{ cancelled() }} == false второму шагу, а в первом намеренно вызовем ошибку
name: Test
on:
workflow_dispatch:
jobs:
RunOneScript:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: otymko/setup-onescript@v1.4
with:
version: 1.9.0
- name: Запускаем OneScript
run: oscript ./workflow.os
- name: Вызываем ошибку
run: |
echo Ошибка!
exit 5
MySecondJob:
runs-on: ubuntu-latest
needs: ["RunOneScript"]
if: ${{ cancelled() }} == false
steps:
- name: Шаг из второго действия
run: echo "Это второе действие"
Теперь запустим

Вторая работа выполнилась, несмотря на ошибку в первой, как мы и ожидали. Теперь, пожалуй, перейдем к чему-нибудь более близком реальной жизни
Сереты и кэш
Одной из важных задач, как правило поручаемых GA, является запуск тестирования. В простых случаях мы можем ограничиться ручным указанием тестовых данных прямо в файле workflow (или даже захардкодить их внутрь тестов). Однако, часто встречается ситуация, когда открытый показ и хранение данных невозможны. И тут у нас есть два пути:
- Если данные - простые строчные переменные, не требующие обновления после выполнения тестирования, то можно использовать секреты репозитория
- В тех случаях, когда информации много или операции с ней проще выполнять как с набором данных в отдельном файле (например, json), то нам поможет шифрование посредством gpg
Разберем оба пункта, но начнем с простого - с секретов
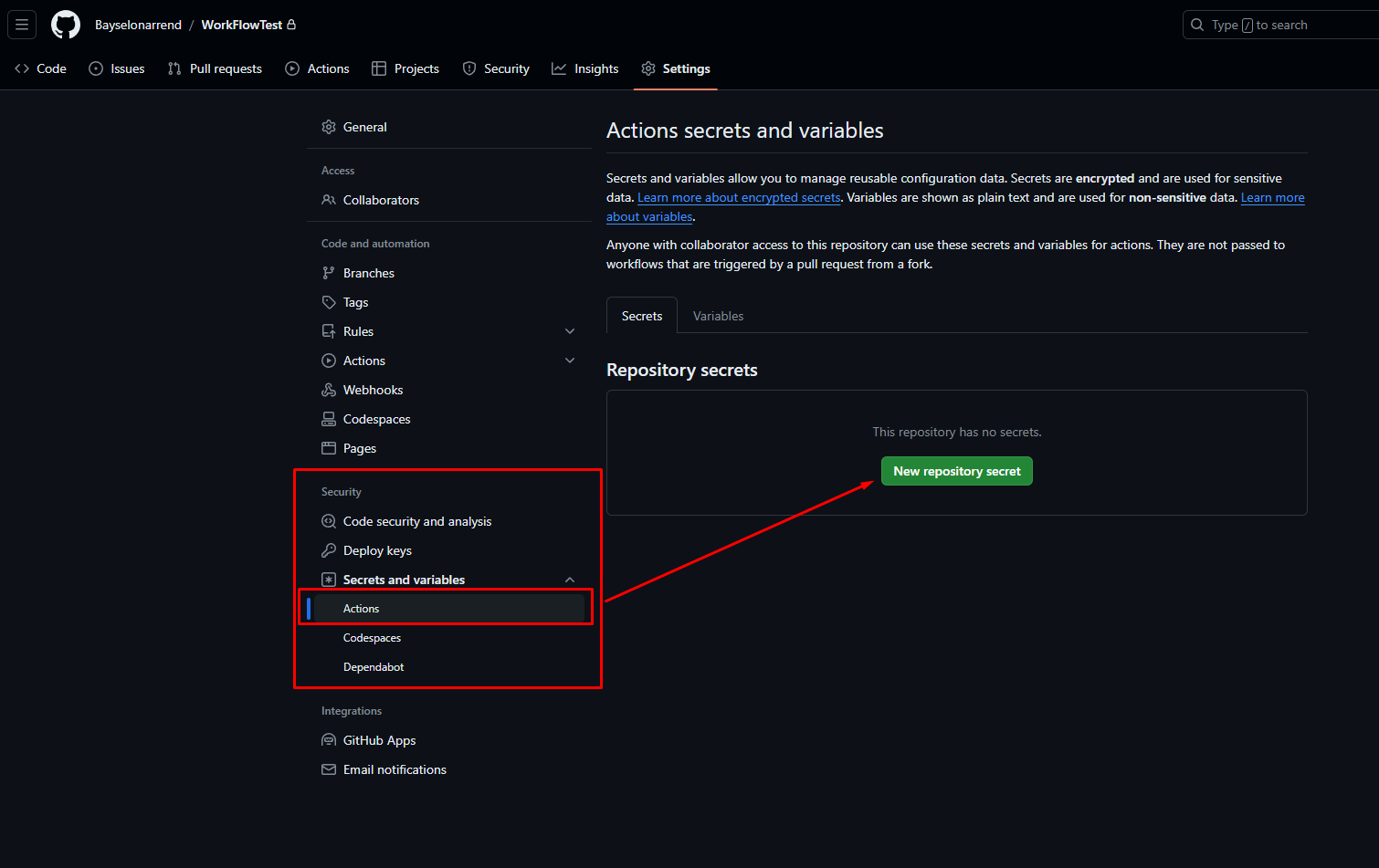
Секреты репозитория позволяют хранить пары ключ-значение в качестве настроек вашего проекта. Они крайне просты в использовании - вам достаточно лишь зайти в настройки -> пункт Secrets and variables -> Actions и нажать New repository secret
Там можно выбрать имя секрета и его значение
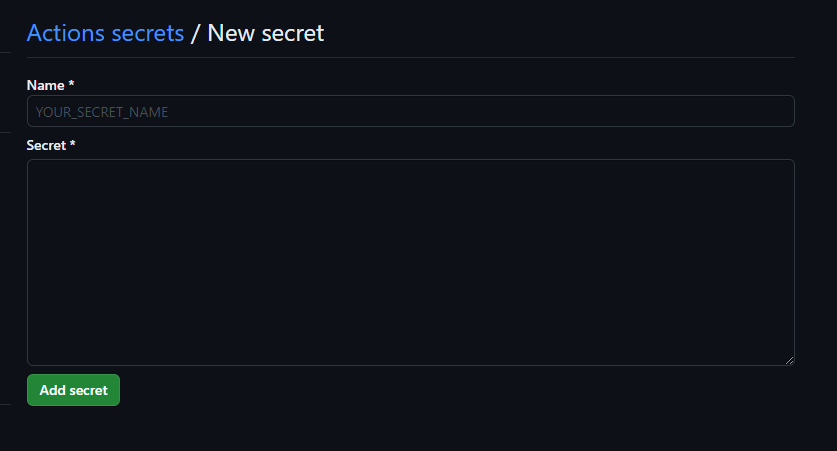
После данной процедуры, сохраненный секрет будет доступен как переменная окружения в любых ваших GA процессах
${{ secrets.ИМЯСЕКРЕТА}}
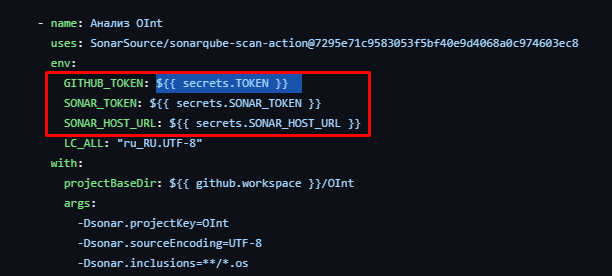
Тут ничего сложного нет. Куда интереснее случаи, когда данных много, они - динамические, или же приложение вообще может работать только с файлами. Принцип построения процесса в данном случае таков:
- Формируется файл (на локальном компьютере, просто у себя), который будет содержать все необходимые данные в формате json (можно любой, но под json есть готовые инструменты)
- Этот файл шифруется при помощи gpg (GNU Privacy Guard). Он есть как под Linux (по умолчанию), так и под Windows (gpg4win)
Использование именно gpg для нас оправдано, в первую очередь, наличием его установленным из коробки в линуксовых окружениях GA
Пример команды для шифрования (проверено на Powershell и Bash)gpg --batch --symmetric --cipher-algo AES256 --passphrase="Ваша секретная фраза" vash_file.json - Секретную фразу, используемую при шифровании, необходимо поместить в секреты репозитория, как мы рассматривали это ранее
- Зашифрованный файл отправляется в репозиторий (Не отправьте случайно обычный, а если не используете в проекте другие json файлы - лучше добавьте *.json в gitignore! Зашифрованный файл должен иметь расширение .gpg)
Имея зашифрованный файл и ключ для расшифровки в секретах репозитория, можно приступать к построению workflow - я создам полностью новый yml файл. Вводные данные такие: секретный файл называется super_secret_data.json.gpg, а секрет с секретной фразой - ENC_JSON
Так выглядит наш новый файл с первой работой - Decode
name: DecodeEncode
on:
workflow_dispatch:
jobs:
Decode:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Расшифруем файл
run: gpg --quiet --batch --yes --decrypt --passphrase="${{ secrets.ENC_JSON }}" --output ./super_secret_data.json ./super_secret_data.json.gpg
Отдельно команда баша для расшифровки файла:
gpg --quiet --batch --yes --decrypt --passphrase="${{ secrets.ENC_JSON }}" --output ./super_secret_data.json ./super_secret_data.json.gpg
В результате данного действия в нашем репозитории (локальном на машине GA, не в публичном доступе) оказывается расшифрованный json файл. Мы можем использовать его прямо здесь, а можем отправить в новую работу. Второй вариант особенно актуален, когда работ, использующих одни и те же данные, несколько. Как это сделать?
Для переноса данных между работами используется кэш. В одной работе мы его записываем, а в последующих - читаем. Допишем в нашу работу Decode запись кэша
name: DecodeEncode
on:
workflow_dispatch:
jobs:
Decode:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Расшифруем файл
run: gpg --quiet --batch --yes --decrypt --passphrase="${{ secrets.ENC_JSON }}" --output ./super_secret_data.json ./super_secret_data.json.gpg
- name: Запишем тестовые данные в кэш
uses: actions/cache/save@v3
with:
key: test-data
path: ./super_secret_data.json
Для записи используется actions/cache/save, где в качестве параметров указываются ключ, по которому мы сможем в дальнейшем получить данные, а также путь, файлы которого мы кэшируем. В нашем случае, это super_secret_data.json. Добавим вторую работу, которая будет данный кэш получать:
name: DecodeEncode
on:
workflow_dispatch:
jobs:
Decode:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Расшифруем файл
run: gpg --quiet --batch --yes --decrypt --passphrase="${{ secrets.ENC_JSON }}" --output ./super_secret_data.json ./super_secret_data.json.gpg
- name: Запишем тестовые данные в кэш
uses: actions/cache/save@v3
with:
key: test-data
path: ./super_secret_data.json
Read:
needs: ["Decode"]
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Получим тестовые данные из кэша
uses: actions/cache/restore@v3
with:
key: test-data
path: ./super_secret_data.json
Для получения используется actions/cache/restore
На данном этапе мы можем использовать данные нашего файла в своих целях. Если это тестирование на OneScript, то, скорее всего, ввод данных будет осуществляться одним из 2-х вариантов:
- В тестах захардкожен относительный путь к файлу
- Данные принимаются аргументами командной строки
В первом случае никаких дополнительных действий не требуется - файл в папке у нас уже есть. Для второго же случая, существует очень хороший сторонний action - rgarcia-phi/json-to-variables
Данный action автоматически устанавливает все значения из json-файла в качестве переменных среды. При этом, указав параметр masked, все вытащенные значения (включая их дальнейшее использование уже в наших обработчиках) будут маскироваться звездочками
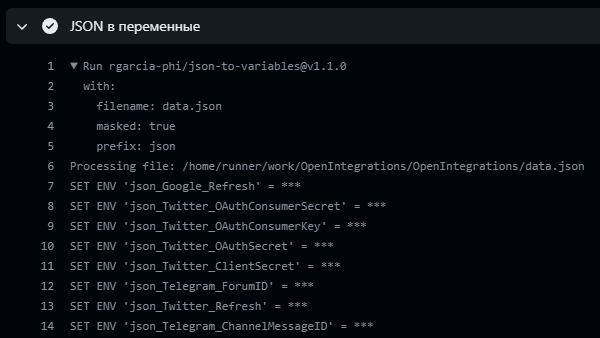
Добавим подобное и в наш файл. Для наглядности, не будем маскировать значения, а выведем их в echo:
name: DecodeEncode
on:
workflow_dispatch:
jobs:
Decode:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Расшифруем файл
run: gpg --quiet --batch --yes --decrypt --passphrase="${{ secrets.ENC_JSON }}" --output ./super_secret_data.json ./super_secret_data.json.gpg
- name: Запишем тестовые данные в кэш
uses: actions/cache/save@v3
with:
key: test-data
path: ./super_secret_data.json
Read:
needs: ["Decode"]
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Получим тестовые данные из кэша
uses: actions/cache/restore@v3
with:
key: test-data
path: ./super_secret_data.json
- name: JSON в переменные
uses: rgarcia-phi/json-to-variables@v1.1.0
with:
filename: 'super_secret_data.json'
masked: false # !!! Установите true, если данные секретны !!!
- name: Вывод значений
run: |
echo "${{ env.json_Secret1 }}"
echo "${{ env.json_Secret2 }}"
Переменные определяются как ${{ env.префикс_ПолеИзJson }}. Префикс по умолчанию - json, но его можно поменять через with, как на скриншоте выше
Важно. Кириллические имена полей не работают и приводят к исключениям
Посмотрим на результат:
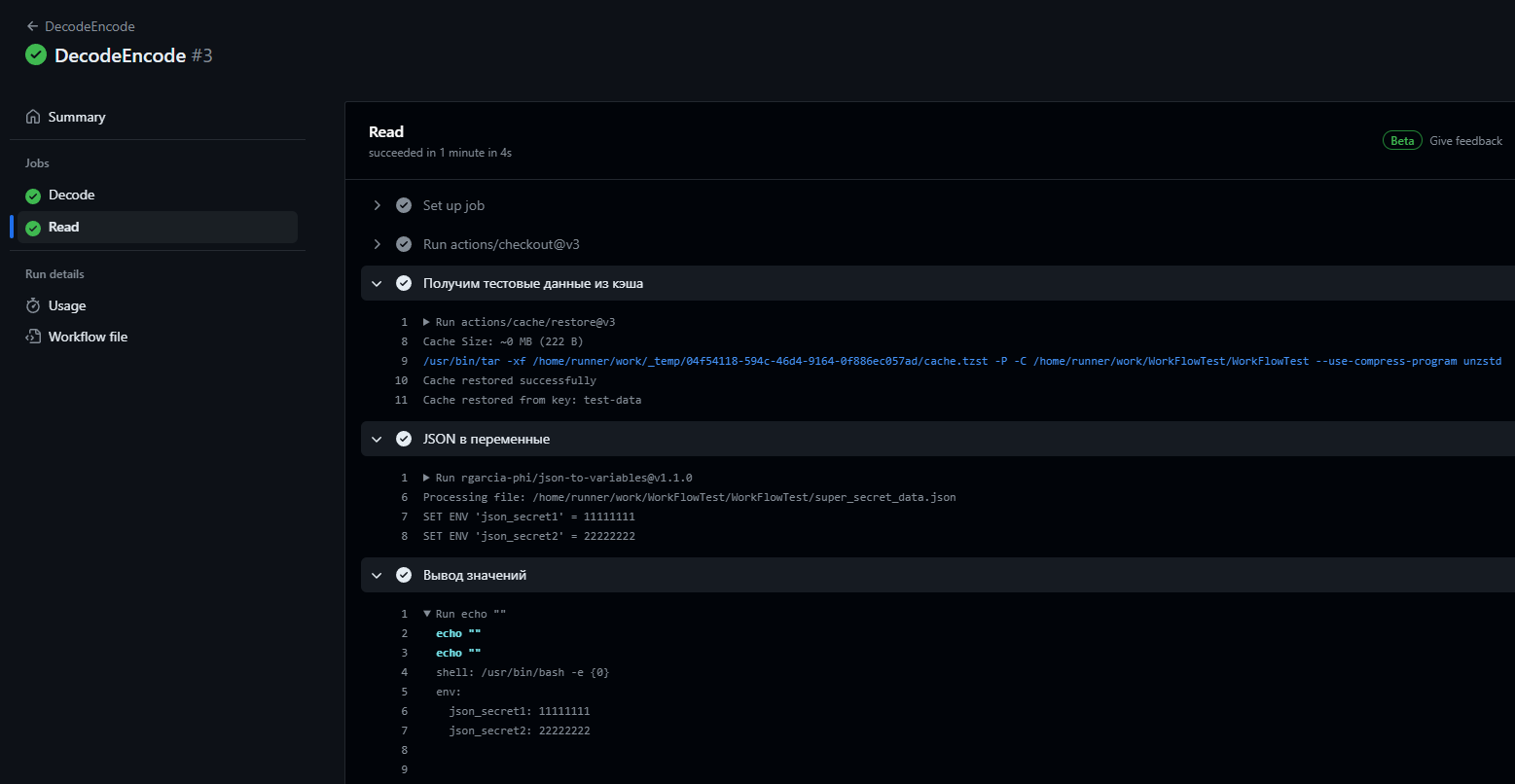
Все отработало правильно: расшифрованные данные были получены из кэша, установлены как переменные и выведены в консоль
Помимо стандартного использования полученных данных - для работы с объектами внутри репозитория, подобные методы найдут место и в суровом 1С-way DevOps'е: записать в файлы или секреты адреса и пароли баз, после чего дергать их по http? Почему бы и нет
Если данные были изменены в процессе работы (например, обновились какие-нибудь временные токены), то их необходимо будет записать обратно. Добавим для этого третью работу в наш workflow:
name: DecodeEncode
on:
workflow_dispatch:
jobs:
Decode:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Расшифруем файл
run: gpg --quiet --batch --yes --decrypt --passphrase="${{ secrets.ENC_JSON }}" --output ./super_secret_data.json ./super_secret_data.json.gpg
- name: Запишем тестовые данные в кэш
uses: actions/cache/save@v3
with:
key: test-data
path: ./super_secret_data.json
Read:
needs: ["Decode"]
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Получим тестовые данные из кэша
uses: actions/cache/restore@v3
with:
key: test-data
path: ./super_secret_data.json
- name: JSON в переменные
uses: rgarcia-phi/json-to-variables@v1.1.0
with:
filename: 'super_secret_data.json'
masked: false # !!! Установите true, если данные секретны !!!
- name: Вывод значений
run: |
echo "${{ env.json_Secret1 }}"
echo "${{ env.json_Secret2 }}"
- name: Запишем измененные данные в кэш
uses: actions/cache/save@v3
with:
key: test-data_new
path: ./super_secret_data.json
Encode:
runs-on: ubuntu-latest
needs: ["Read"]
if: ${{ always() }}
permissions:
contents: write
steps:
- uses: actions/checkout@v2
- name: Получим тестовые данные из кэша
uses: actions/cache/restore@v3
with:
key: test-data_new
path: ./super_secret_data.json
- name: Зашифровать данные обратно
run: |
rm -f ./super_secret_data.json.gpg
gpg --batch --symmetric --cipher-algo AES256 --passphrase="${{ secrets.ENC_JSON }}" super_secret_data.json
rm -f ./super_secret_data.json
- name: Записать данные
uses: stefanzweifel/git-auto-commit-action@v5
Что особенного мы тут видим?
Во-первых, это if: ${{ always() }}, так как данные должны быть сохранены обратно в любом случае, а также permissions: contents: write - разрешение на запись для action'а автокоммита, который сохранит наши изменения в репозиторий
Во-вторых, важно не забывать удалять незашифрованные файлы, если их нет в .gitignore
В-третьих, и, наверное, как самое главное - в работе Read мы записываем измененные данные под новым именем - test-data_new, под которым, собственно, потом их и получаем в Encode
Тут кроется важный момент работы с кэшем
Дело в том, что изначальное предназначение кэша не столько в подобной передаче пользовательских данных из одной работы в другую, сколько в предоставлении возможности сохранять различные зависимости без необходимости их установки каждый раз: это у нас тут все просто, но во всяких node.js установка необходимых пакетов из package.json может занимать большую часть всего времени рабочего процесса. А ведь окружение при каждом запуске абсолютно чистое!
В связи с этим, кэш не удаляется самостоятельно при завершении работы и не позволяет перезаписывать себя по ключу - он не под это заточен. Но обойти это можно - двумя способами:
- Использовать генерируемые данные в ключе: случайные символы, текущую дату и пр.
- Чистить кэш после завершения работы
Если ваши тестовые данные не изменяются со временем, то вам это использовать не нужно. Но уже даже в случае нашего рабочего процесса из примера, при втором запуске все пойдет не так:
- При первом запуске, мы расшифровали данные и записали в кэш
- Изменили их и записали под другим ключом
- Зашифровали обратно и поместили в репозиторий
- При втором запуске мы расшифровываем измененные ранее данные и пытаемся их поместить в кэш
- Кэш с данным ключом уже существует, но в нем устаревшие данные. А заменить их новыми нельзя

Перейдем к решению. С первым вариантом все понятно - можно просто генерировать уникальное имя кэша. Но это как-то не круто. Лучше добавим еще один шаг после шифрования - очистку кэша:
name: DecodeEncode
on:
workflow_dispatch:
jobs:
Decode:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Расшифруем файл
run: gpg --quiet --batch --yes --decrypt --passphrase="${{ secrets.ENC_JSON }}" --output ./super_secret_data.json ./super_secret_data.json.gpg
- name: Запишем тестовые данные в кэш
uses: actions/cache/save@v3
with:
key: test-data
path: ./super_secret_data.json
Read:
needs: ["Decode"]
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Получим тестовые данные из кэша
uses: actions/cache/restore@v3
with:
key: test-data
path: ./super_secret_data.json
- name: JSON в переменные
uses: rgarcia-phi/json-to-variables@v1.1.0
with:
filename: 'super_secret_data.json'
masked: false # !!! Установите true, если данные секретны !!!
- name: Вывод значений
run: |
echo "${{ env.json_Secret1 }}"
echo "${{ env.json_Secret2 }}"
- name: Запишем измененные данные в кэш
uses: actions/cache/save@v3
with:
key: test-data_new
path: ./super_secret_data.json
Encode:
runs-on: ubuntu-latest
needs: ["Read"]
if: ${{ always() }}
permissions:
contents: write
steps:
- uses: actions/checkout@v2
- name: Получим тестовые данные из кэша
uses: actions/cache/restore@v3
with:
key: test-data_new
path: ./super_secret_data.json
- name: Зашифровать данные обратно
run: |
rm -f ./super_secret_data.json.gpg
gpg --batch --symmetric --cipher-algo AES256 --passphrase="$ENC_JSON" super_secret_data.json
rm -f ./super_secret_data.json
env:
ENC_JSON: ${{ secrets.ENC_JSON }}
- name: Записать данные
uses: stefanzweifel/git-auto-commit-action@v5
Clear-Cache:
runs-on: ubuntu-latest
needs: [Encode]
if: ${{ always() }}
steps:
- name: Очистка test-data
run: |
curl -L \
-X DELETE \
-H "Accept: application/vnd.github+json" \
-H "Authorization: Bearer ${{ secrets.TOKEN }}" \
-H "X-GitHub-Api-Version: 2022-11-28" \
"https://api.github.com/repos/Bayselonarrend/OpenIntegrations/actions/caches?key=test-data"
- name: Очистка кэша test-data_new
run: |
curl -L \
-X DELETE \
-H "Accept: application/vnd.github+json" \
-H "Authorization: Bearer ${{ secrets.TOKEN }}" \
-H "X-GitHub-Api-Version: 2022-11-28" \
"https://api.github.com/repos/Bayselonarrend/OpenIntegrations/actions/caches?key=test-data_new"
Делается это при помощи банальных http-запросов через curl. Ключ кэша указывается в конце URL и единственное, что вам тут еще необходимо - токен Github в секретах для авторизации запросов. Получить его можно в настройках аккаунта Github, перейдя по пункту Developer Settings (ссылка)
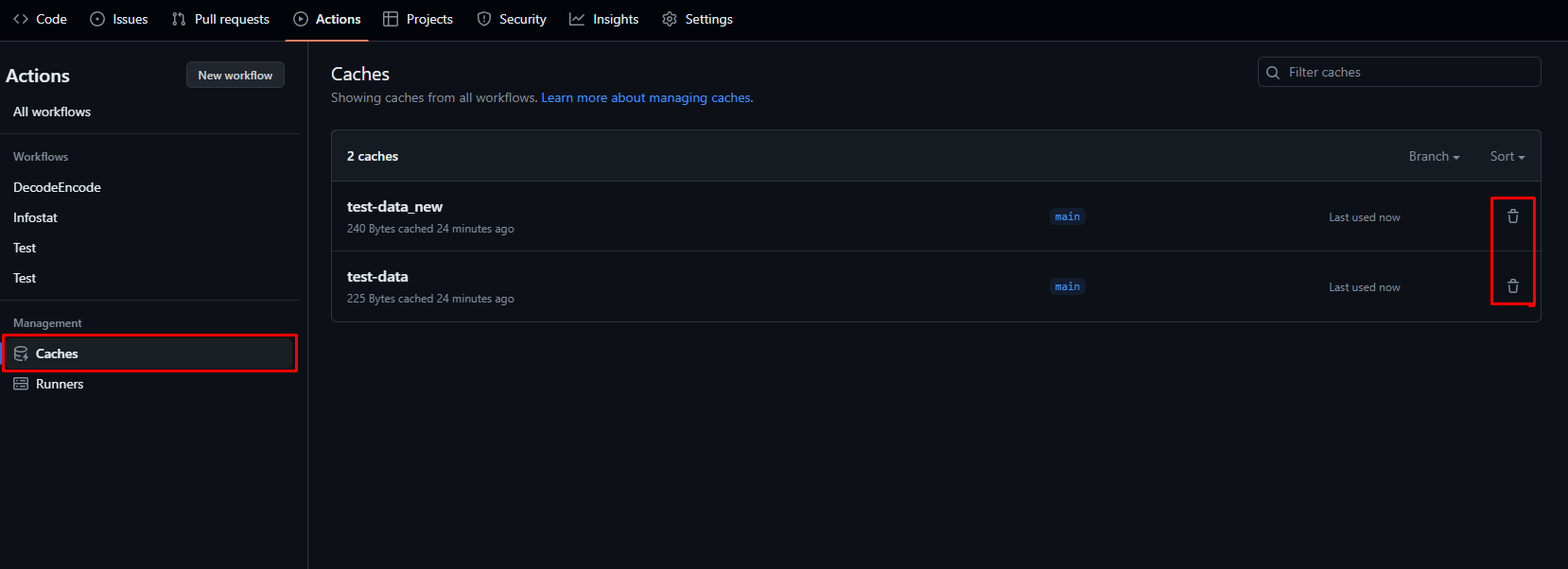
На крайний случай посмотреть список кэшей и удалить их руками можно на вкладке Actions -> Caches
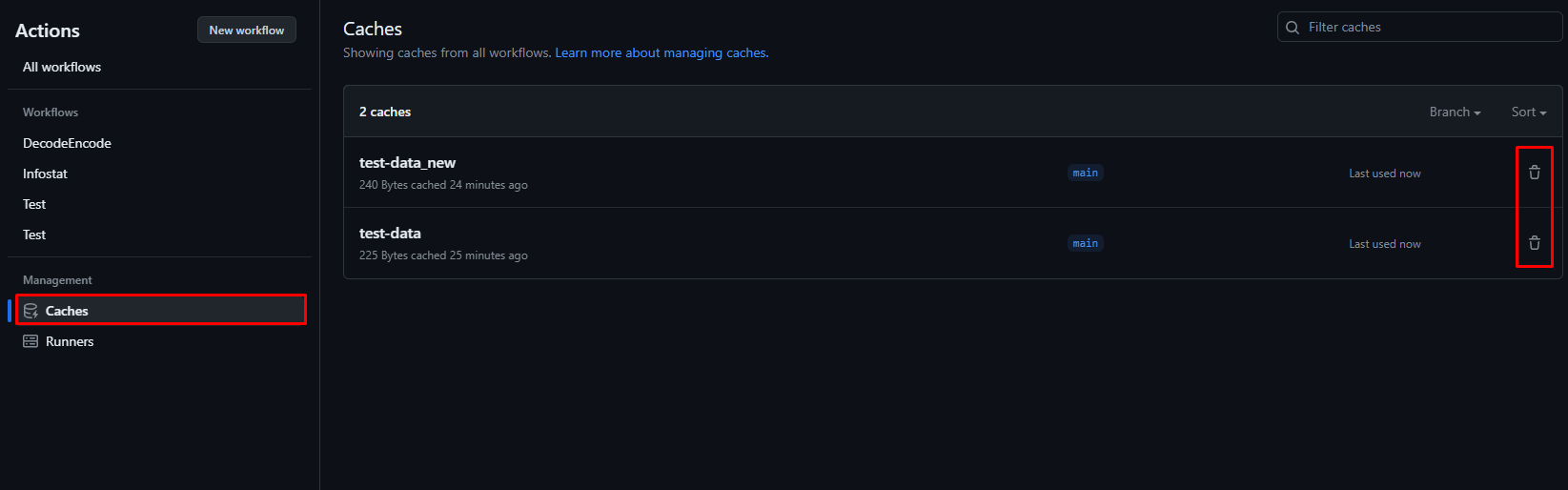
Неиспользуемые кэши удаляются автоматически спустя 7 дней
Артефакты
С кэшем разобрались - его можно записывать, читать и он хранится на Github вплоть до 7 дней без повторного использования
Механизм, который мы сейчас рассмотрим, во многом похож на кэш - он также позволяет записывать и передавать данные между работами, но служит для иных целей - это механизм артефактов
Артефакты - это файлы, производимые как результат деятельности рабочего процесса. Это могут быть логи, собранные бинарники или просто любые другие объекты, которые могут представлять для вас интерес. Их ключевым отличием от кэша является возможность скачивания со страницы процесса:

Так, например, вы можете создать рабочий процесс сборки и тестирования приложения (на том же OneScript), в результате которого получить исполняемый файл для релиза. Так это сейчас, хотя еще и в процессе разработки, происходит в ОПИ. Сюда же в тему и precommit1c - можно собирать файлы обработок/отчетов из исходников. Возможно, разберу это отдельно.
Помимо возможности скачивания руками, артефакты обладают возможностью быть переданными из одной работы в другую, но, несмотря на отсутствие проблем с очисткой, как у кэша, использовать их для передачи секретных данных нельзя - скачать артефакт может любой желающий, попавший на страницу выполнения workflow (если репозиторий публичный, конечно же)
Так выглядит step записи артефакта:
- name: Записать артефакт
uses: actions/upload-artifact@v4
with:
name: my-artifact-name
path: ./my_cool_app.exe
А так - чтения:
- name: Скачать артефакт с исполняемым файлом
uses: actions/download-artifact@v4
with:
name: my-artifact-name
Ничего сложного. Больше про них и рассказать особо нечего
Полезные ссылки
Кроме тех вещей, о которых рассказано в статье, есть и другие решения, которые могут быть интересны при использовании Github Actions в сфере 1С/OS
- Actions для 1С - это набор OS скриптов, которые предоставляют готовые решения для работы со многими популярными (и не очень) инструментами из мира 1С: Allure, Vanessa Automation, Coverage41C и др.
Как я понимаю, они созданы в первую очередь для локального использования и для Gitlab, но кто нам запретит работать через GA, просто не с файлами репозитория, а с базой по http, правильно?
- Autumn workflows - набор основных must-have экшенов для разработки библиотек на OneScript
- setup-onescript - собственно, основной экшен для запуска вообще чего либо на OS под Github Actions. Устанавливает OneScript нужной версии без боли и заморочек
- precommit1c - известный инструмент для разборки/сборки внешних обработок и отчетов. Скажу честно - сам еще не пробовал применять его в GA, но звучит это все интересно
- osparser - парсер языка 1С. Очень гибкий инструмент с миллионом вариантов применения в своих скриптах по обработке исходников: хочешь делай каталоги методов в модулях, хочешь формируй автодокументацию на основе комментариев-описаний - как фантазия развернется.
Autumn workflows и Actions для 1С порекомендовали знающие люди из комментариев к первой статье по теме. Если вы знаете еще какие-нибудь интересные решения, созданные для работы с Actions в сфере 1С - напишите их в комментарии, я добавлю в список.
Ну а пока все
Спасибо за внимание!
Мой GitHub: https://gitub.com/Bayselonarrend Лицензия MIT: https://mit-license.org
Вступайте в нашу телеграмм-группу Инфостарт