
Планы обмена – это основной механизм регистрации изменений данных платформы 1С.
При интенсивных обменах данными возникают длительные ожидания на блокировках таблиц регистрации изменений, что порождает ряд проблем – тайм-ауты и прерывание обработки данных.
В 2017-м году я выступал на конференции Инфостарт с мастер-классом, где подробно разбирал, как работает механизм регистрации изменений планов обмена, почему возникают эти проблемы, а также предложил альтернативный способ решения.
По итогам мастер-класса была написана статья, которая актуальна до сих пор.
Коротко напомню, как возникают эти проблемы. У нас в 1С есть программное средство – менеджер планов обмена, который позволяет регистрировать изменения, удалять их и выбирать:
-
Для выбора изменений используется метод – ПланыОбмена.ВыбратьИзменения(…)
-
Для удаления зарегистрированных изменений – ПланыОбмена.УдалитьРегистрациюИзменений(…)
-
А для регистрации изменений – два метода: платформенный и произвольный:
-
Произвольный метод
ПланыОбмена.ЗарегистрироватьИзменения(…);
мы можем вызвать в любой точке кода. -
Платформенный метод срабатывает при записи объектов (при вызове Объект.Записать()). Он делает то же самое, что ПланыОбмена.ЗарегистрироватьИзменения(…), но работает фоном, в ядре платформы. При платформенном способе мы управляем регистрацией изменений при помощи коллекции Получатели из настроек обмена данными объекта: Объект.ОбменДанными.Получатели.Добавить(…);
-

При этом:
-
Платформенная регистрация изменений происходит после выполнения всех обработчиков транзакции, перед ее окончательной фиксацией – это самая короткая блокировка, которую мы можем себе позволить на таблицах регистрации изменений.
-
А в случае произвольной регистрации изменений – если мы вызываем ПланыОбмена.ЗарегистрироватьИзменения(…), например, где-нибудь в подписке на событие «Перед записью» – мы будем удерживать блокировку на таблице регистрации изменений все время до завершения транзакции.
Моделирование проблемы блокировок при регистрации изменений

Попробуем воспроизвести блокировку на таблице регистрации изменений и посмотреть на нее со стороны 1С. На слайде показан примерный типовой код, позволяющий это смоделировать:
-
мы получаем какой-то объект;
-
записываем его;
-
заполняем коллекцию получателей – я здесь использую платформенный метод регистрации;
-
и ставим точку останова на строке «ЗафиксироватьТранзакцию()» – таким образом мы искусственно продлеваем транзакцию, удерживая блокировку на таблице регистрации изменений. Блокировка создается по тому объекту, для которого выполняется регистрация изменений и по тем узлам, что мы для регистрации выбрали.
Запускаем сессию 1С, выполняем этот код, встаем на точке останова. И одновременно открываем вторую сессию – для создания конкурирующей транзакции, в которой мы пытаемся зарегистрировать изменения по тому же самому объекту, по тем же узлам.

Т.е. мы нажимаем кнопку «Зарегистрировать изменения» – получаем ошибку конфликта блокировок на таблице регистрации изменений.

«Удалить регистрацию изменений» – получаем ошибку.

«Выгрузить данные РИБ» – например, мы здесь вызвали «ВыбратьИзменения, тоже получили ошибку.
Во всех трех случаях мы видим ошибку СУБД.
Причем эта ошибка СУБД характерна как для Microsoft SQL Server, так и для PostgreSQL – там происходит ровно то же самое.

И если мы пытаемся этот объект записать, мы тоже получаем ошибку. Причем это уже не ошибка СУБД – это объектная, так называемая управляемая блокировка, которую накладывает сервер 1С.
На этой блокировке я хотел бы особенно остановиться. Это очень важная и нужная блокировка, которая не имеет ничего общего с блокировками на таблице регистрации изменений планов обмена. Эта блокировка про другое – она защищает целостность данных объекта, который мы записываем.
Схема решения проблемы блокировок таблицы регистрации изменений на уровне СУБД
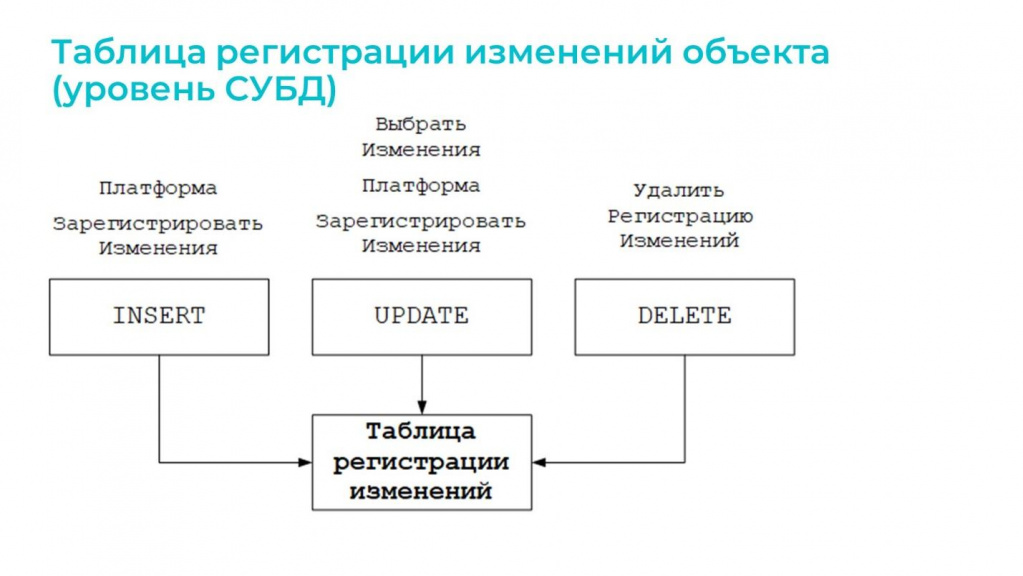
А теперь давайте спустимся на уровень СУБД – здесь я еще раз напомню о своей статье, где подробно расписано, как все это работает на уровне СУБД.
Платформа 1С по отношению к таблице регистрации изменений выполняет команды SQL: INSERT, UPDATE и DELETE.
Эти команды вызываются в следующих случаях:
-
INSERT может вызываться в результате:
-
платформенной регистрации – она здесь у меня помечена как «Платформа»
-
или при произвольной регистрации методом «Зарегистрировать изменения»
-
-
UPDATE вызывается в процессе выполнения метода «Выбрать изменения».
-
DELETE – вызывается при удалении регистрации.
При этом на уровне СУБД:
-
методы UPDATE и DELETE блокируют записи в таблице регистрации изменений, и из-за этого возникают ожидания на блокировках – мы ждем, пока они закончат свою работу;
-
а метод INSERT – это неблокирующая операция, она просто добавляет записи в таблицу и никого не ждет при этом.

Методика тюнинга планов обмена, про которую я буду говорить далее, решает только проблемы блокировок СУБД и именно на таблицах регистрации изменений.
Еще раз повторяю, что объектную блокировку, которая защищает целостность данных объекта, мы не трогаем. Мы не должны ее удалять или что-то с ней делать.
Чтобы бороться с объектными блокировками, существуют другие методики – в частности, этим занимаются 1С-эксперты: они пытаются как-то укоротить транзакцию, оптимизировать код в процедурах проведения и так далее. Тюнинг планов обмена на поведение платформы никак не влияет. И это правильно. Все остальные блокировки мы удаляем.

На этом слайде показана ключевая идея доклада.
Давайте попробуем поразмышлять, что нам надо сделать, чтобы не было блокировок на записях таблиц регистрации изменений. Очевидно, что нам надо каким-то образом сделать так, чтобы команды UPDATE и DELETE ничего не блокировали.
Для этого мы делаем таблицу регистрации изменений пустой – если блокировать нечего, то и эти команды работают вхолостую.
Возникает вопрос – а что делать с регистрациями? Регистрации мы перехватываем командой INSERT, которая содержит ключи изменяемых объектов. И записываем данные об этих регистрациях в регистр сведений «Таблица-очередь Регистрация изменений».
Я так понимаю, что эта методика в принципе не новая – когда мы пытаемся оптимизировать проблемы с планами обмена, мы так или иначе используем регистры сведений в качестве очереди.
Здесь то же самое. И возникает вопрос, как же у нас в этот регистр сведений, в эту очередь, будет что-то попадать, если платформа ничего вообще про тюнинг планов обмена не знает, потому что этот механизм для платформы абсолютно прозрачен.
Мы используем триггеры СУБД.
-
Для SQL Server это триггеры INSTEAD OF, которые формируют инструкцию типа: «Вместо команды INSERT положи в регистр сведений» – примерно так.
-
А для PostgreSQL это триггерные функции, которые потом «подвешиваются» к триггеру BEFORE – там аналогичная методика.
С помощью этих триггеров мы будем перенаправлять команды INSERT, которые шлет платформа для таблицы регистрации изменений, в регистр сведений «Таблица-очередь Регистрация изменений».
В чем плюсы этой методики ?
-
Во-первых, мы решаем все проблемы с блокировками на таблице регистрации изменений – все потенциально блокирующие команды работают вхолостую.
-
Во-вторых, огромным плюсом я считаю то, что мы в принципе не меняем код 1С вообще никак – для платформы все работает прозрачно!
Сохраняется работоспособность кода по регистрации изменений, который относится к типовым механизмам – например, к механизму регистрации изменений БСП, правилам регистрации объектов КД2. А также продолжит работать код по регистрации изменений, который мы сами написали, включая ручную регистрацию пула объектов, полученных запросом.
Единственный минус:
-
Методы ВыбратьИзменения и другие, завязанные на таблице регистрации изменений, ничего выгружать не будут. Потому что таблицы пустые – им выгружать нечего. Этот код мы не меняем, но он работает вхолостую. Поэтому нам код выгрузки надо каким-то образом адаптировать для получения данных о регистрации из этого регистра «Таблица-очередь Регистрация изменений». Это можно отнести к минусам. В любой технологии есть плюсы и минусы, здесь так.
Всё это до сих пор была теория – она содержит идею, как можно решить проблему. А теперь поговорим о том, реализуемо ли это вообще практически.
Платформа DaJet – приложение для тюнинга планов обмена
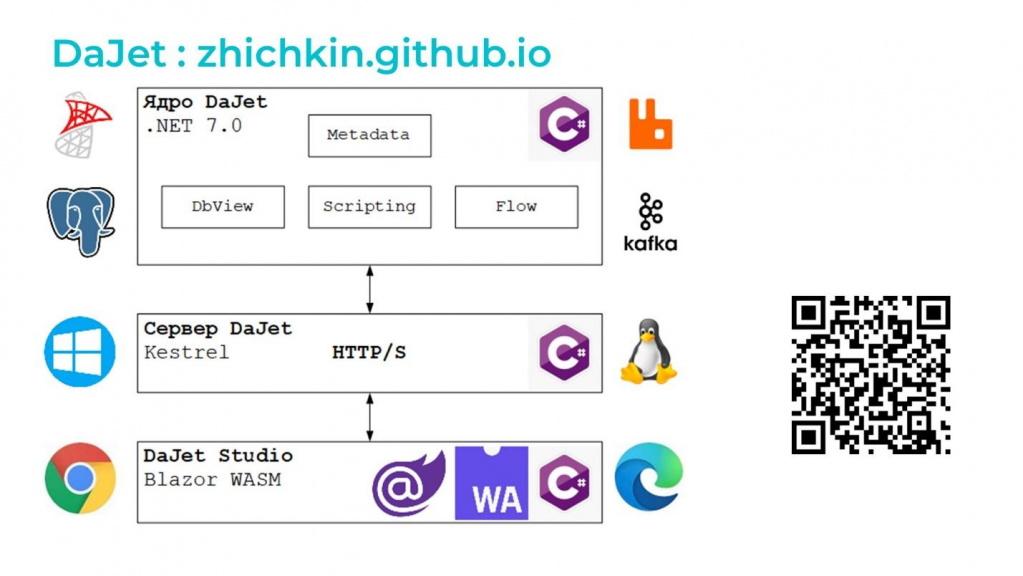
Чтобы реализовать прототипы и доказать состоятельность этой идеи, я разработал небольшое приложение на платформе DaJet, автором и единственным разработчиком которой на данный момент выступаю я.
Платформа DaJet состоит из следующих компонент:
-
В ядро DaJet входят:
-
Библиотека Metadata, которая позволяет читать метаданные 1С.
-
Компонент DbView, который позволяет создавать вьюхи, представления СУБД. Этот компонент очень активно используют, например, аналитики данных – он позволяет им в нормальных терминах работать с базами данных 1С.
-
Модуль Scripting, предоставляющий SQL-язык запросов в терминах 1С, но со своими дополнениями и расширениями.
-
И модуль Flow – это библиотека для создания и построения конвейеров потоковой обработки данных. По сути, это аналог Kafka Streams для C#.
-
Библиотеки ядра поддерживают работу с основными СУБД – MS SQL Server и PostgreSQL. И с наиболее популярными брокерами – RabbitMQ и Kafka.
-
-
У библиотек ядра нет интерфейса – с ними можно работать напрямую на C#, но не все знают C#. Поэтому для создания классической трехзвенной архитектуры разработан сервер DaJet. Он построен на базе веб-сервера Kestrel и в его задачи входит:
-
Во-первых, выполнение скриптов.
-
И он используется как хост для конвейеров обработки данных. Если говорить в терминах 1С, то сервер DaJet – это аналог 1С-вского rphost, а конвейеры – это фоновые задания.
-
Все компоненты платформы DaJet написаны на C#. И они кроссплатформенны – работают на Windows, на Linux и на macOS. Декларируется, что платформа .NET 8.0, которую я использовал, работает даже на ARM-процессорах, но я не проверял.
-
Для удобства работы с сервером DaJet у него есть свой веб API – можно выполнять команды через Postman или Curl, обращаться к этим библиотекам, выполнять какие-то задачи.
-
-
Также разработан клиент с веб-интерфейсом пользователя – DaJet Studio. Это приложение написано на технологии Blazor – это микрософтовский UI-фреймворк, основанный на WASM (WebAssembly). Клиент работает во всех современных браузерах, которые поддерживают технологию WASM – все последние версии браузеров эту технологию сейчас точно поддерживают.

Платформа расширяемая, и для нее можно писать приложения – на слайде показана главная страница приложения, которое я написал специально для тюнинга планов обмена.
Установка DaJet очень простая – скачал zip-архив, распаковал в папку, запустил http-сервер DaJet и просто зашел браузером по адресу http:/localhost:5000. Открылось приложение, и мы там можем что-то делать.
Чтобы это можно было самим потрогать и поэкспериментировать с новыми технологиями, я разработал специальную версию DaJet 2.3.3, которая содержит, в том числе, cf-ник для 1С и демо-базу.
На слайде – главное окно этого приложения.
-
Слева – панель, которая показывает зарегистрированные базы 1С.
-
Справа – рабочая панель.
Сделано это по аналогии с MS SQL Server Management Studio или pg-admin, если кто знает. Концепция примерно такая.
Слева – список баз. В каждой базе есть всякие разные сервисы. Например:
-
сервис api – это для скриптов;
-
сервис exchange – это для обменов;
-
сервис dbw – это сгенерированные вьюхи;
-
а «Расширения» и «Конфигурации» – это просто метаданные 1С.
Если мы кликнем на сервис exchange правой кнопкой мыши, у нас откроется контекстное меню с волшебной кнопкой, которая называется «Тюнинг планов обмена».
При вызове «Тюнинга планов обмена» в рабочей панели откроется форма с двумя кнопками – «Включить» и «Выключить». Т.е. вся реализация – это две кнопки.
Получается, что в клиенте DaJet у меня есть возможность для базы ms-exchange – очевидно, что эта база на MS SQL – включить тюнинг планов обмена или выключить.

При включении «Тюнинга планов обмена» выводится список всех объектов, которые входят в состав всех планов обмена – все, что в принципе можно оттюнить, где есть таблицы регистрации изменений. Сейчас это реализовано так, чтобы работать по всем планам обмена и по всем объектам – в конце концов, это прототип и НИОКР.
Что делает кнопка «включить»:
-
Первым делом она создает объект базы данных SEQUENCE – это генератор числовой последовательности на уровне ядра СУБД. Для чего он нужен, я чуть позже расскажу.
-
Потом начинается транзакция.
-
По очереди блокируется таблица регистрации изменений каждого объекта метаданных – проходит цикл по таблицам регистрации, каждая таблица обрабатывается в транзакции. Для MS SQL Server она накладывает на таблицу исключительную блокировку – TABLOCKX. А для PostgreSQL – EXCLUSIVE MODE, что то же самое.
-
Блокировка нужна для того, чтобы перенести все уже существующие регистрации в регистр сведений, чтобы нам там ничего не мешало. 100 тысяч записей из таблицы регистрации изменений переносятся в регистр сведений одной командой SQL – на это уходят считанные секунды.
-
На таблице регистрации изменений создается триггер, который будет перенаправлять все регистрации в регистр сведений.
-
Фиксируется транзакция, и все.
В принципе, это можно выполнять при работающей базе – будет короткая блокировка на перенос данных. Потом пользователи продолжат работать дальше, а регистрация уже будет идти не в таблицу регистрации изменений, а в регистр сведений – это все произойдет прямо у вас на глазах.

При выключении тюнинга плана обмена все триггеры сбрасываются, и система возвращается в обратное состояние.
При этом в 1С вообще ничего не надо делать, для нее это абсолютно прозрачно – просто удаляются триггеры, и дальше работает платформенная регистрация изменений.

Для регистра сведений, в который перенаправляются данные, я предлагаю некую типовую структуру.
-
Первое измерение – это «Вектор», число (19, 0). Здесь в пояснении написано, что это гарантированно уникальный последовательный ключ. Объект SEQUENCE, который создается на уровне ядра СУБД, триггером генерирует значение этого вектора. Название «Вектор» произошло от векторных часов. Если вы не знакомы с этим термином, в моей статье вы можете почитать, как и зачем использовать векторные часы для синхронизации в распределенных базах данных. По сути, вектор – это версия.
-
Далее у нас идет два измерения (или ресурса, что неважно) – это «Узел» и «Ссылка» для ссылочных типов данных – справочники, документы и прочее. Это те данные регистрации изменений, которые должны были попасть в таблицу регистрации изменений, но попали в регистр. Они попадают сюда.
-
«Данные» и «Транзакция» – это реквизиты регистра. Их заполнение необязательно, но с их помощью мы получаем дополнительные бонусы.
Преимущества такой структуры регистра сведений:
-
Во-первых, все регистрации становятся последовательными. Все зарегистрированные изменения идут в строгой последовательности согласно этому вектору.
Это то, чего у нас нет в планах обмена – там регистрация зависит от GUID, от внутреннего идентификатора объекта. В какой он там последовательности попадет в эту таблицу – вообще неизвестно. Здесь гарантируется некая последовательность. Это первый бонус. -
Второй бонус – мы можем получить идентификатор транзакции СУБД. Например, у нас пишутся движения документа в какие-нибудь регистры в одной транзакции. Мы здесь получим один какой-то идентификатор, который их всех объединяет. Если мы хотим обеспечивать целостность данных – т.е. нам нужен транзакционный обмен данными – мы можем объединить все эти объекты по этому идентификатору и пульнуть в одном сообщении, в одном пакете. Многим это очень нужно. Это тоже как бонус. При помощи «Тюнинга планов обмена» мы получаем это из коробки.
-
Ну а значение реквизита «Данные» – произвольное. Мы можем его использовать для служебных целей – написать там вообще что угодно. Например, мы можем его использовать при регистрации изменений для регистров сведений и вообще регистров. Вы знаете, что у них чаще всего составной ключ – это несколько полей. А здесь для ключа объекта у нас одно поле. Например, есть регистр сведений, у которого три измерения – как их запихать в одно? С этим пока есть техническая сложность, но я сейчас покажу, как ее в прототипе реализовал.
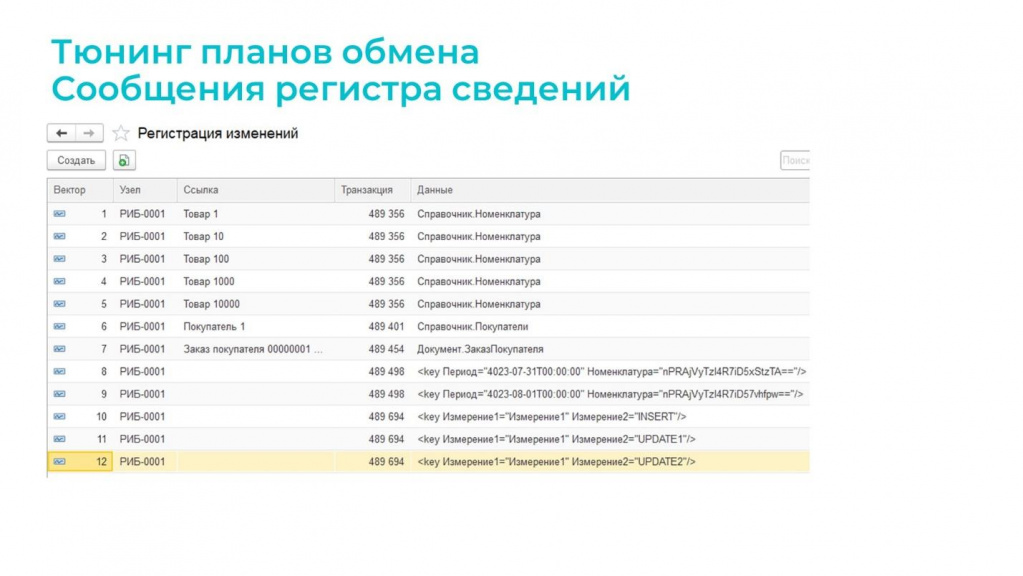
Ключ регистра сведений записи в прототипе помещается в поле «Данные». И если нам нужно каким-то образом сериализовать ключ записи регистра сведений в одно поле – эта проблема в принципе решаемая, поскольку у всех современных СУБД есть средства работы как с XML, так и с JSON. И даже можно в бинарном виде при желании все это сериализовать.
Я видел решение, когда вместо одного регистра делается свой на каждый регистр сведений. Чтобы ничего не сериализовать, не мучиться, он просто дублирует структуру измерений, туда забрасывает, и потом с этим работает. Нормально работает. В принципе, тоже вариант. Там неудобно то, что у вас вместо одного универсального регистра их становится больше.
Но в данном случае это работает так, как показано на слайде.
Например, здесь мы видим, что идентификатор транзакций для пяти объектов одинаковый – видимо, в транзакции регистрировали справочник «Номенклатура». Если нам это важно, мы можем эти записи по транзакции объединить.
Еще здесь решается проблема блокировок таблицы регистрации, характерная для планов обмена – она возникает из-за того, что в таблице регистрации изменений для одного ключа есть всегда только одна запись. Из-за этого и возникают блокировки, что они все время конкурируют за эту запись между собой.
А здесь, поскольку у нас все время идет добавление – может быть много объектов. Но есть «Ссылка» и есть ключ «Данные», по которым мы эти данные можем агрегировать. Об этом я скажу позже.

Здесь я привожу шаблон триггера для MS SQL Server с комментариями

И то же самое для PostgreSQL.
Такой триггер вешается на каждую таблицу регистрации изменений. А мы знаем, что она у нас одна для каждого объекта, независимо от того, во сколько планов обмена этот объект входит.
Таблица регистрации изменений у него одна, и триггер на эту таблицу тоже один.

Как работать с этим регистром сведений – с этой «Таблицей-очередью Регистрация изменений»?
Здесь показан типовой код, но он в зависимости от структуры регистра у всех может быть разный. В данном случае используется такой шаблон:
-
Выбираем первые 10000 записей (регистраций).
-
Упорядочиваем по возрастанию поля Вектор, потому что это очередь – когда мы работаем с очередью, мы с головы снимаем, а в хвост пишем.
-
Получаем поля «Вектор», «Узел» и «Ссылка». «Узел» и «Ссылка» – это данные регистрации, которые мы перехватили и перенаправили.
-
Если применить группировку по «Узлу» и «Ссылке», можно актуальную версию получить. Это как раз к вопросу о дедупликации данных. Мы с ней боремся вот таким образом – просто группируем по ключам и таким образом устраняем дубли. Я еще люблю это называть сжатием потока данных.
Поток данных сжали, получили то, что мы хотим обработать, упорядочили, если нам нужна последовательность. И дальше, как получить из «Ссылки» или из ключа «Данные» объекты – это мы все знаем, все умеем.
Администрирование триггеров

Часто возникает вопрос: «Что делать, если у нас реструктуризация? Куда денутся эти триггеры? Слетят, не слетят? И вообще, что с этим делать?»
По ссылочным объектам – сразу скажу, ничего не произойдет.
По регистрам при реструктуризации мы можем увидеть сообщение: «Регистрация изменена» – это означает, что произошла реструктуризация таблицы регистрации изменений. Это может произойти, например, когда изменился ключ записи регистра сведений – если мы добавили измерение или удалили, будет реструктуризация.
На слайде показано, что происходит в 1С при реструктуризации. Сначала создается новая таблица, в нее переносятся данные, потом старая таблица удаляется через DROP TABLE, а новая таблица с перенесенными данными переименовывается в старое название.
Поскольку DROP TABLE удаляет все триггеры, с этим нужно что-то делать. Но, если помните, там была кнопка «Включить тюнинг планов обмена» – ровно так же нажимаем кнопку, и все триггеры восстанавливаются.
Причем сзади к этим кнопкам прикручен веб-API, как мы помним. То есть в принципе можно кнопку не нажимать – можно дергать этот скрипт из Postman или CURL. Обновили базу данных, реструктуризация прошла, дернули скрипт по веб-API – у нас триггеры восстановились. Это тоже решаемая проблема.

Таким образом, тюнинг планов обмена позволяет решить проблему блокировок, но требуется адаптация кода выгрузки – это, наверное, самая большая проблема.
По ссылке вы можете скачать релиз платформы DaJet с демобазой 1С.
Платформа DaJet позволяет решать еще много других задач – смотрите обучающие видео, изучайте выложенные материалы и пользуйтесь.
Когда все совсем плохо с планами обмена – есть готовое решение. Можно взять и использовать. Это решение с открытым исходным кодом. Единственное ограничение – на его основе нельзя делать коммерческие продукты.
Вопросы
Получается, что платформа 1С регистрирует изменения в отдельных таблицах для каждого из метаданных – справочников, документов, регистров. А вы создаете один регистр сведений, который является сборным для всех справочников и документов. И чем их больше, тем у нас больше записей туда будет писаться. Что происходит при повторной перезаписи документа?
Будет еще одна запись в регистре сведений. Сколько регистраций летит в план обмена, столько же записей будет в регистре сведений.
Но в таблице регистрации у вас может быть одна запись по объекту, а в регистре сведений таких записей может быть много. Как с этим бороться, я уже сказал – при выборке мы можем сжать поток данных группировкой по Узлу и Ссылке.
Когда обмен успешно прошел, мы должны удалить записи регистрации. Чтобы их найти, у нас есть поле вектор. Выбираем первые 10000, и там не зря была актуальная версия, МАКСИМУМ(Вектор) – вы знаете, по какой вектор вы уже выбрали. Обработали, и все, что меньше этого вектора, просто удалили.
А как получить подтверждение с узла, что этот обмен успешен, что они приняли наш пакет данных?
Обычно из таких регистров сведений данные передаются, например, в брокер – в RabbiMQ или в Apache Kafka. Там применяется паттерн Transactional Outbox плюс Polling publisher. Рекомендую ознакомиться, почитать в Интернет, найти, что это такое.
Это работает следующим образом:
-
Открывается транзакция в СУБД.
-
Выбираются данные для обмена и запихиваются в брокера.
-
Если от брокера получается подтверждение, транзакция закрывается.
-
Если в этом процессе происходит ошибка, транзакция в СУБД откатывается, все записи возвращаются в очередь.
Этот паттерн называется Outbox.
Вы можете открыть транзакцию, чтобы это все куда-то отправить или записать. А после отправки удаляете записи и закрываете транзакцию. Чтобы не потерять данные и гарантировать доставку из этого регистра, вы в любом случае все время работаете в транзакции.
Но если мы откроем транзакцию, мы же тоже будем иметь блокировку для записи?
Если вы не будете параллельно обрабатывать одни и те же сообщения, ожиданий на блокировке не будет.
Понятное дело, что если вы открываете транзакцию, считываете записи, потом начинаете их удалять, вы накладываете блокировки, и параллельный поток будет вас ждать. Но есть много способов, как этого избежать и эти процессы распараллелить.
У нас вообще в один поток все выгружается – весь этот один регистр со всеми объектами в системе, которые там зарегистрировались, выгружается в один поток в Kafka или в RabbitMQ. И очень редко бывает, когда в этом регистре есть записи. DaJet умудряется в одном потоке успевать выгружать всё, что бы там на центральном сервере ни зарегистрировали.
Это получается асинхронная отправка?
Да, асинхронная. Правда, чтобы гарантировать последовательность, там есть нюансы работы с разными брокерами. Но в целом асинхронная.
И удаление записей из этого регистра у меня выполняет не 1С, а DaJet на уровне SQL.
Если вы думаете, что у нас система маленькая – нет, 100 миллионов записей в день вполне переваривает. Причем на выгрузку работает в один поток.
Как осуществляется изоляция вектора, что нет двух записей с одним и тем же вектором?
Это гарантирует ядро СУБД. SEQUENCE – это объект СУБД, который гарантированно при многопоточной конкурентной нагрузке всегда выдает один вектор, чтобы дублей не было. Именно поэтому этот объект и используется.
В свое время мы использовали UTC время, которое 1С генерирует с точностью до миллисекунды. Вот у нас были ситуации, когда в одну миллисекунду было 10 регистраций. SEQUENCE помогает с этим разобраться.
Решение DaJet уже где-то используется?
Сейчас это прототип, НИОКР. Я люблю заниматься исследованиями всевозможных проблем и решил поделиться с вами идеей. Я смотрю, что в сообществе планы обмена уже потихоньку «хоронят», но я считаю, что их еще рано закапывать. У многих ещё есть легаси-системы, которые достались в наследство. И когда уже построена целая цепочка обменов, от этого очень сложно уйти.
Я могу рассказать о нашей ситуации. У нас был РИБ на 50 узлов – и там обмены просто вставали, актуальность данных на узлах отставала от центральной базы от часа и выше. Для онлайн-торговли это абсолютно неприемлемо.
Сначала мы там реализовали другую методику – через регистр сведений и свои подписки на события, чтобы потом через RabbitMQ раскидать это все по нашей РИБ-овской сети.
Сейчас мы применили DaJet и это позволило масштабироваться с 50 до 300 узлов. При этом актуальность данных на узлах у нас сейчас меньше 10 секунд. Бывают всплески, когда 5000 сообщений в очереди – это уже аларм летит. В такие всплески у нас актуальность данных может быть на узлах до 5 минут. Но обычно там пусто – DaJet разгребает все эти очереди очень быстро.
Т.е. мы с РИБа собирались переходить, а я на досуге подумал: «А зачем с РИБа переходить? РИБ у всех есть. Нельзя ли как-то еще по-другому это сделать?» И придумал такой вариант – он тоже рабочий.
А CDC-механизм почему не попробовали? Там же почти онлайн получается?
На Инфостарте есть замечательная статья Юрия Пермитина по поводу CDC в 1С. Ознакомьтесь, я вам советую. Эта статья сейчас под авторством Инфостарта, т.к. Юра Пермитин, к сожалению, покинул наше сообщество и все свои статьи передал Инфостарт.
У него в статье очень подробно расписано, как можно применить CDC для 1С. Но там есть ряд минусов:
-
В случае реструктуризации и изменения структур данных CDC надо перенастраивать. Для этой цели у Юры сделана подсистема, которая автоматически это все делает прозрачно для 1С – вы можете реструктуризироваться, как хотите, а его подсистема это все поддерживает.
-
И CDC, опять же, регистрирует изменения в таблице SQL, где все поля называются так, как мы «любим»: Fld***, VT*** и т.д. Работать с этим неудобно.
Да, CDC – это хорошая вещь. У PostgreSQL это называется логическая репликация – тоже замечательная вещь. Для работы с ней есть Kafka Connect. Мы берем Kafka Connect и настраиваем его на СУБД. В PostgreSQL Kafka Connect работает как раз с логической репликацией. И она прекрасно вам будет это все в Kafka загонять.
Но, опять же, вопрос, а что делать с этими Fld*** и прочее? Проблема.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.

Вступайте в нашу телеграмм-группу Инфостарт