










Введение
При проектировании структуры регистров накопления важно учитывать их особенность работы, влияющие на производительность системы, в нагруженных системах это будет решающим фактором, по которому можно будет судить о жизнеспособности спроектированной подсистемы. Ключевым фактором к производительности конечно же являются индексы, которые будут задействованы при получении необходимых данных. На ИТС есть хорошее описание типичных причин неоптимальности запросов и особенности организации основного и дополнительного условия запросов. Но зачастую при проектировании системы в условиях неопределенности не всегда есть возможность точно оценить как эффективно организовать структуру метаданных.
Проблема
Рассмотрим, например, подсистему "Проведения акций", где у нас есть документ Проведения акции, в нем мы указываем, по какой номенклатуре, цене проводить акцию и какое количество товара выделяем под акцию. При этом мы хотим позднее проанализировать как удачно прошла та или иная акции. В данном случае мы можем выбрать оборотный регистр накопления, указав в ресурсах сколько мы выделяем товара для акции (План) и сколько пройдет по продажам (Факт). Пример описания в метаданных 1С:
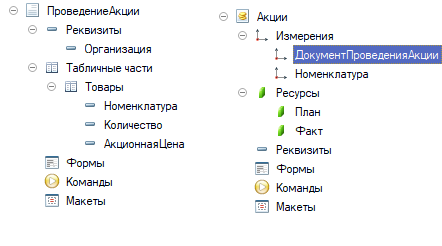
рис 1. Метаданные для тестирования
Почему именно такая последовательность в регистре Акции: ДокументПроведенияАкции, Номенклатура? Известно, что платформа создает кластерный индекс, включая туда измерения в той последовательности, в которой они указаны. Это означаем, что для ускорения доступа к нашим данным первыми лучше ставить измерения, которые отвечают нашим потребностям по запросам и являются наиболее селективными (реже встречаются в таблице). Из наших данных, документ конкретной акции будет самым редким, потому он идет первый.
Позже появляется требование, что нам не хотелось бы отдавать товара больше, чем мы планировали при проведении акции. Теперь нам понадобился контроль остатков, который хорошо бы организовать на регистре накопления с видом Остатки, но если нет такой возможности или она ограничена, получится ли на оборотном регистре эффективно получать остатки? Чтобы точно ответить на этот вопрос, нужно рассматривать каждый конкретный случай в отдельности, но мы посмотрим на тестовом примере, какие особенности возникают.
Тестирование
Проверка идет при следующих настройках:
1. Платформа 8.3.24.1368, PostgreSQL 14.10, Ubuntu 22.04.3;
2. Сгенерировано документов ПроведениеАкции (движение по ресурсу План) - 3 000;
3. Сгенерировано документов Продажа (движение по ресурсу Факт) - 60 000;
4. Записей в регистре Акции - 2 763 012 за период с 01.01.2020 - 31.12.2024;
5. Планы запросов собираются по технологическому журналу;
6. Скорость работы запросов в мс имеет в данном случае показательный характер не в абсолютных единицах, а друг относительно друга.
Начнем с оборота по всему периоду по ДокументуПроведенияАкции, Номенклатуре:
ВЫБРАТЬ
АкцииОбороты.ПланОборот - АкцииОбороты.ФактОборот КАК Остаток
ИЗ
РегистрНакопления.Акции.Обороты(
,
,
,
ДокументПроведенияАкции = &ДокументПроведенияАкции
И Номенклатура = &Номенклатура) КАК АкцииОбороты
Кажется, что все неплохо, мы соблюдаем требования из рекомендаций, указываем все отборы по измерениям, начиная с первого измерения. Если такую проверку делаем при проведении, то по мере роста базы в составе затрат времени на данный контроль остатков мы увидим рост времени выполнения этого запрос. В чем же тут проблема? Посмотрим на план запроса (более подробно про планы запросов можно посмотреть в это обучающем видео от 1С или от postgrespro):

рис 2. План запроса к таблице оборотов без указания периода, время работы 33 мс
проблема в том, что мы не попадаем в индекс, который создает платформа, на что в плане указывает оператор последовательного сканирования (Seq Scan), который в цикле обошел всю выборку и отбросил по условию 656230 записей, но предварительно пришлось это все считать в нашем случае из памяти (Buffers: shared hit), а мог и с диска, тогда было бы значительно медленней. На плане наши измерения - это fld302rref (ДокументПроведенияАкции), fld320rref (Номенклатура). Согласно публикации на ИТС, кластерный индекс, который создаем автоматически платформа, имеет вид:
[ОРРХ | ОРНР1 +] Период + Измерение1 + ... + ИзмерениеN + [DimHash] + [Splitter] (кластерный индекс)
Первым важным для нас полем идет Период (ОРРХ и ОРНР расставит платформа, нас это не касается), Период у нас не задан, в этом и дело, задав его мы точно попадем в индекс и проблема будет решена. Посмотрим пример, наша акция шла, например, полгода (с 01.09.2022 по 01.03.2023), добавим эти параметры в запрос, получим:
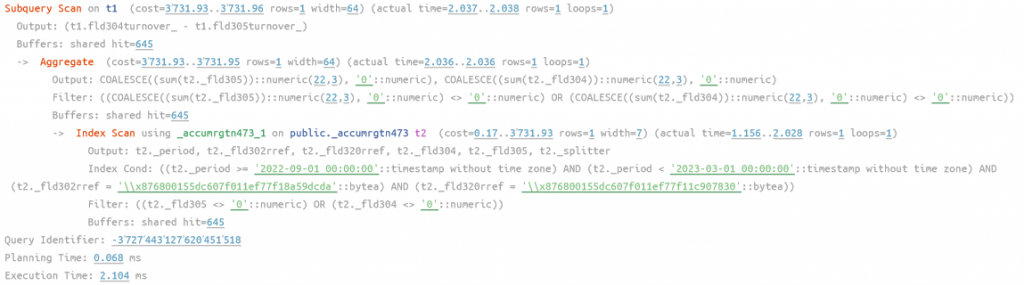
рис 3. План запрос с указание короткого периода, время работы 2 мс
Ускорение в 16 раз, видим операцию сканирования индекса (Index Scan), что говорит нам об использовании индекса, причем в индексе период и два наших измерения. Видим, что есть оператор Filter, но платформа сама выставлять эти условия, чтобы отбросить строки, где ресурсы нулевые, в нашем случае таких не оказалось. Но, что если период действия акции длительный, а документов с разными датами много? В таком случае селективность по периоду станет хуже и такой запрос будет работать медленно, подставим теперь период с 01.01.2020 по 31.12.2024 и убедимся в этом:
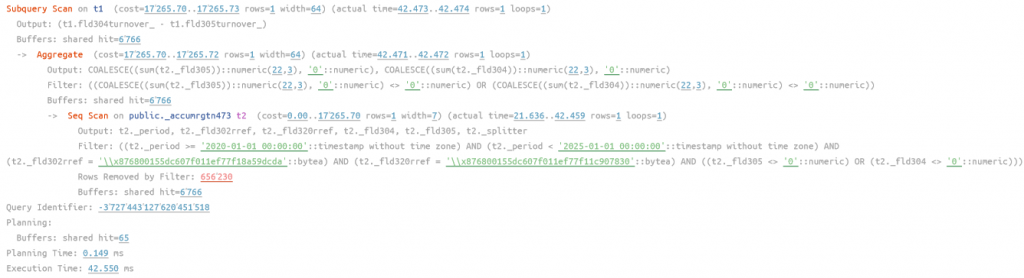
рис 4. План запрос с указание большого периода, время работы 42 мс
Хоть у нас и есть индекс, но из-за большого объема планировщик посчитал, что дешевле произвести последовательного сканирование всей таблицы сразу (Seq Scan).
Ранее был сказано о такой особенности учета: документ акции по сути одноразовый, как только акция заканчивает документ больше не используется, это значит, что он достаточно редко использует относительно всех данных и селективность должна быть наилучшей. Чтобы проверить это нужно по установить на поле ДокументПроведенияАкции признак Индексировать:
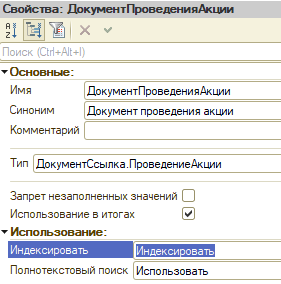
рис 5. Устанавливаем признак Индексировать.
После индексирования пробуем самый первый запрос (без указания периодов), в данном случае как мы видели, кластерный индекс не будет задействован, а вот индекс по документу должен начать работать. Получаем план:
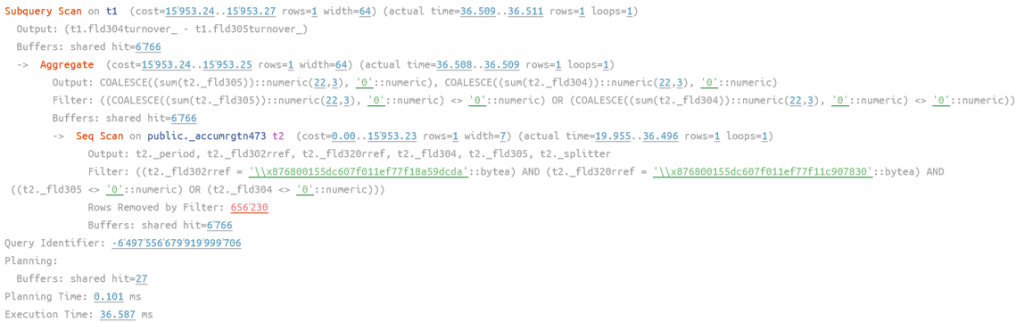
рис 6. План запрос с индексированием ДокументПроведенияАкции без заданных периодов, время работы 36 мс.
Вышло то же, что на рис 2. - индекс не сработал, а не сработал он, потому, что его на самом деле нет, если посмотреть в документацию по индексам, то увидим:
Таблица оборотов
[ОРРХ | ОРНР1 +] Измерение + Период (Измерению задано свойство Индексировать, начиная со второго измерения)
То есть первое измерение в оборотном регистре не индексируется платформой. При этом в основной таблице индекс будет создан:
Основная таблица
[ОРРХ | ОРНР1 +] Измерение + Период + Регистратор + НомерСтроки (Измерению задано свойство Индексировать)
Перепишем запрос на основную таблицу:
ВЫБРАТЬ
СУММА(Акции.План) - СУММА(Акции.Факт) КАК Остаток
ИЗ
РегистрНакопления.Акции КАК Акции
ГДЕ
Акции.ДокументПроведенияАкции = &ДокументПроведенияАкции
И Акции.Номенклатура = &Номенклатура
получим план:
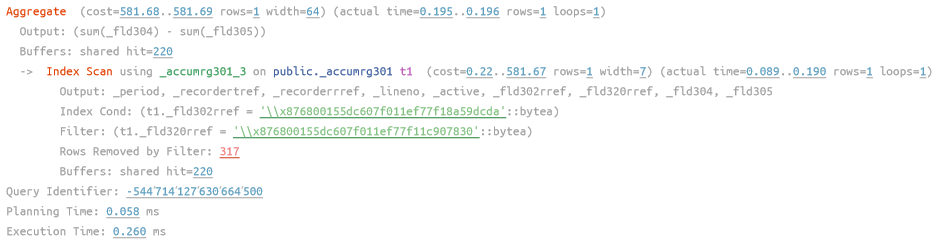
рис 7. План запроса к основной таблице без периодов с индексированным 1 измерением, время работы 0.26 мс
Индекс позволил отобрать данные эффективно и фильтром отбросить по Номенклатуре 317 записей.
А если добавим еще и отбор по периоду за полгода:
ВЫБРАТЬ
СУММА(Акции.План) - СУММА(Акции.Факт) КАК Остаток
ИЗ
РегистрНакопления.Акции КАК Акции
ГДЕ
Акции.ДокументПроведенияАкции = &ДокументПроведенияАкции
И Акции.Номенклатура = &Номенклатура
И Акции.Период >= &ДатаНачала
И Акции.Период < &ДатаОкончания
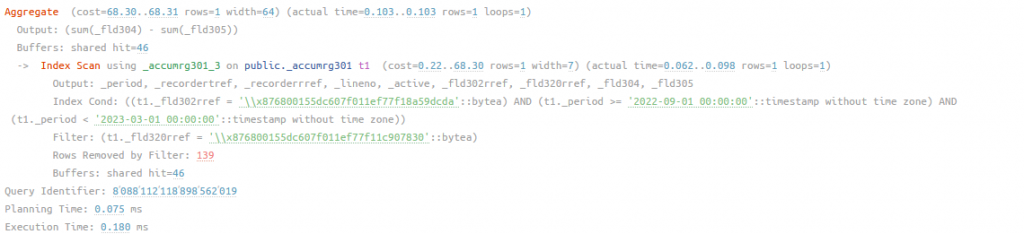
рис 6. План запроса к основной таблице регистра c установкой периодов и индексированным 1-ым измерением, время работы 0.180 мс
Индекс позволил отобрать данные еще эффективней и фильтровать еще меньший объем строк по Номенклатуре - 139 записей. Получили хорошие результат, но кажется, что на оборотном регистре можно выжать еще. Даже если мы отметим измерение первое как индексируемое, платформа все равно его не создаст, только со второго измерения. Чтобы бы нам задействовать индекс измерение ДокументПроведенияАкции должно стать минимум вторым. Поменяем местами ДокументПроведенияАкции с Номенклатурой:
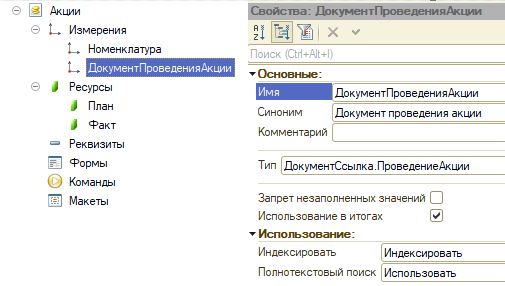
рис 8. Установка измерения ДокументПроведенияАкции вторым по порядку
используем запрос
ВЫБРАТЬ
АкцииОбороты.ПланОборот - АкцииОбороты.ФактОборот КАК Остаток
ИЗ
РегистрНакопления.Акции.Обороты(
,
,
,
ДокументПроведенияАкции = &ДокументПроведенияАкции
И Номенклатура = &Номенклатура) КАК АкцииОбороты
получаем такой план исполнения:
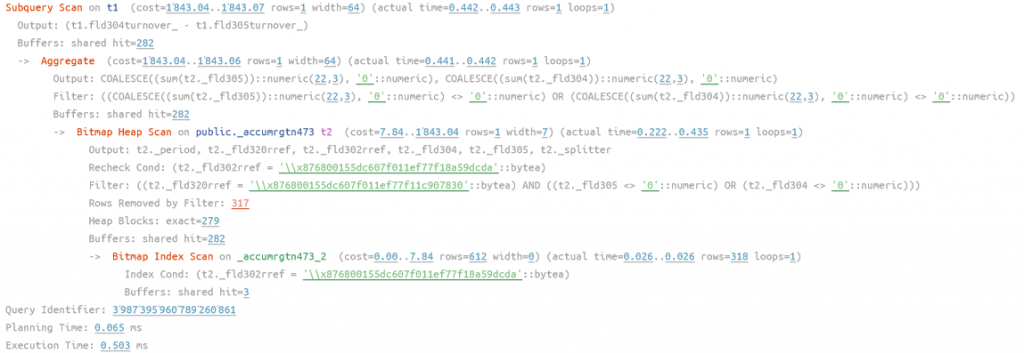
рис 9. План запроса к таблице оборотов без периодов с индексированным 2 измерением ДокументПроведенияАкции, время работы 0.503 мс
Видим, что теперь индекс задействован, но время выполнение больше чем к основной таблице, но сопоставимы. О том, что отработал не кластерный индекс нам говорит оператор сканирования по битовой маске (Bitmap scan), которому сначала нужно найти адреса строк, а потом по этим адресам считать сами строки, в кластерном же индексе данные берутся из самого индекса. Попробуем добавить период за полгода, это позволит задействовать весь составной индекс (Измерение+Период), используем запрос:
ВЫБРАТЬ
АкцииОбороты.ПланОборот - АкцииОбороты.ФактОборот КАК Остаток
ИЗ
РегистрНакопления.Акции.Обороты(
&ДатаНачала,
&ДатаОкончания,
,
ДокументПроведенияАкции = &ДокументПроведенияАкции
И Номенклатура = &Номенклатура) КАК АкцииОбороты
получаем:
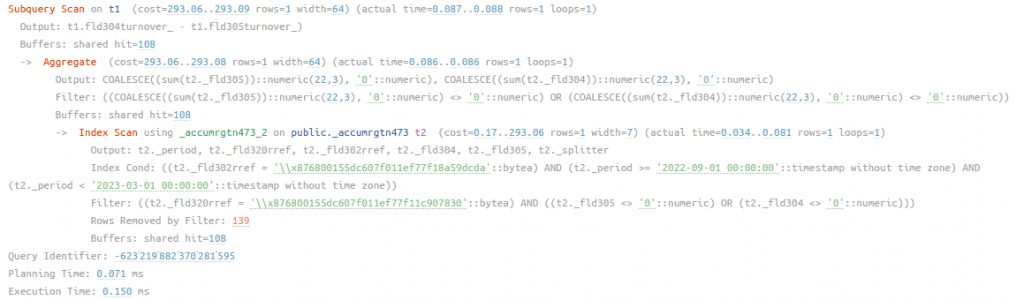
рис 10. План запроса к таблице оборотов с заданным периодом и индексированным 2 измерением ДокументПроведенияАкции, время работы 0.15 мс
Сработал составной индекс ДокументПроведенияАкции + Период, который выполнился быстрее остальных, это объясняется тем, что таблица оборотов компактней основной таблицы, так как данные хранятся в свернутом виде по месяцам и измерениям, на плане это также видно по количество отфильтрованных строк по номенклатуре - 139.
Сравнение с видом регистром накопления Остатки
Для полноты картины посмотрим как сработает запрос получения остатков без указания конкретной даты остатков, но только к таблице остатков, сконвертируем наш регистр в регистр накопления остатков. Порядок измерений вернем к исходному состоянию, без индексирования измерений, а именно: ДокументПроведенияАкции, Номенклатура, получаем:
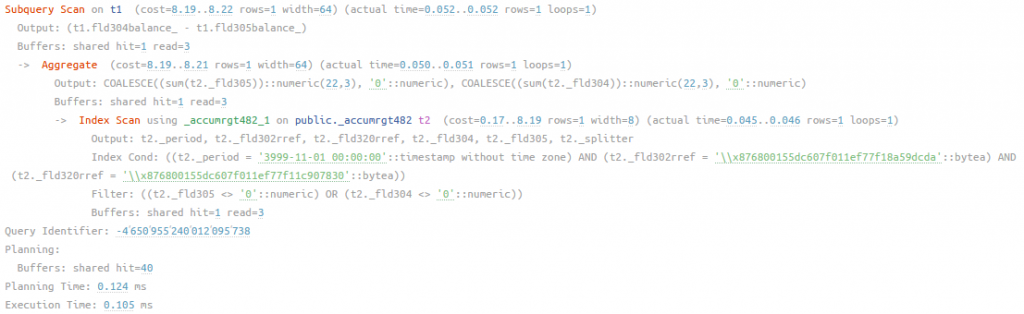
рис 11. План запроса к регистру остатков, порядок измерения ДокументПроведенияАкции, Номенклатура, дата остатков не указана, время работы 0.105 мс
Из плана видно, что задействован кластерный индекс (Период + Измерения), дату мы не указывали, но платформа выставляет по умолчанию в таком случае 3999-11-01. Даже с учетом того, что большая часть данных была считана с диска (buffers: hit1 read 3 - одна страница данных из буфера, а 3 с диска), время выполнение наилучшее. Таблица остатков по факту сама компактная: в ней только один период и свернутые данные по измерениям, при том еще имеется кластерный индекс, из которого все необходимые данные можно получить сразу.
Итоговые результаты
| Способ контроля остатков | Фактическое выполнение, мс |
|---|---|
| 1. Таблица остатков | 0.105 |
|
2. Таблица оборотов с указанием периода и смещением ключевого измерения ДокументПроведенияАкции на 2 позицию с указанием индексируемости поля |
0.150 |
| 3. Основная таблица с указанием периодов, ключевое измерение ДокументПроведенияАкции на 1 позиции с признаком индексировать | 0.180 |
| 4. Основная таблица без указания периода, ключевое измерение ДокументПроведенияАкции на 1 позиции с признаком индексировать | 0.260 |
| 5. Таблица оборотов без указания периода с индексированным измерением ДокументПроведенияАкции на 2 позиции | 0.503 |
| 6. Таблица оборотов с указанием периода, ключевое измерение ДокументПроведенияАкции на 1 позиции без признака индексировать | 2.104 |
| 7. Таблица оборотов без указания периода и без индексированных измерений | 33.607 |
| 8. Таблица оборотов без указания периода, ключевое измерение ДокументПроведенияАкции на 1 позиции с признаком индексировать | 36.587 |
- Как бы банально не звучало, если нужно контролировать остатки и это частое действие (нагруженный поток заказов клиента, реализаций), то нужно использовать регистр с видом Остатки.
- Таблицу оборотов возможно использовать для контроля остатков если есть селективное измерение, по которому будет отбор, оно должно идти со второй позиции с признаком Индексировать.
- Основную таблицу возможно использовать для контроля остатков если есть селективное измерение, по которому будет отбор, порядок не важен и есть признак Индексировать. На самом деле она тоже используется при формировании запросов к СУБД, когда в виртуальных таблицах задействованы периоды, которые в ней не хранятся (обороты, остатки). Поэтому при проектировании расстановки признака индексирования над селективными полями и порядком полей необходимо хорошенько подумать.
- Указание периода значительно улучшает эффективность запроса. Имеет смысл использовать любую доступную информацию, например, если мы не знаем, когда акция закончится, но совершенно понятно, что продаж не может быть раньше чем начало действия акции, значит мы точно можем указать начало периода, в таком случае уже подключиться индекс и выборка станет эффективней.
Вступайте в нашу телеграмм-группу Инфостарт