





Давно не публиковал статей, и на то были свои причины. Однако недавно я столкнулся с интересным случаем, который, как мне кажется, будет полезен коллегам. Решил поделиться своими наблюдениями.
Тема индексов в базах данных, особенно в контексте 1С, действительно интересная и одновременно сложная. Многие разработчики, включая даже опытных сеньоров, не всегда до конца понимают, как они работают и когда их стоит использовать. Документация 1С, к сожалению, часто обходит эту тему стороной, ограничиваясь общими фразами вроде «это зависит от ситуации и необходимости». Получается, что кто разобрался — тот молодец, а кто не разобрался — учится на своих ошибках, и не факт, что поймет, в чем была проблема.
Поиск проблемы
Сегодняшнюю ситуацию мы будем разбирать на примере нашей конфигурации «Мониторинг производительности». Дело было так. Поскольку мы работали с высоко нагруженной (highload) базой заказчика, объем накопленных данных для анализа оказался огромным — более двух десятков миллионов записей. В какой-то момент форма динамического списка событий замеров начала заметно подтормаживать, особенно при прокручивании списков.
Такое поведение стало мягко говоря не комфортным. Мы решили разобраться в причинах и исправить такую ситуацию.
В замерах длительных запросов мы обнаружили некоторые записи, которые выполняются подозрительно долго. Выбрав одну из строк мы решили посмотреть контекст и текст запроса.
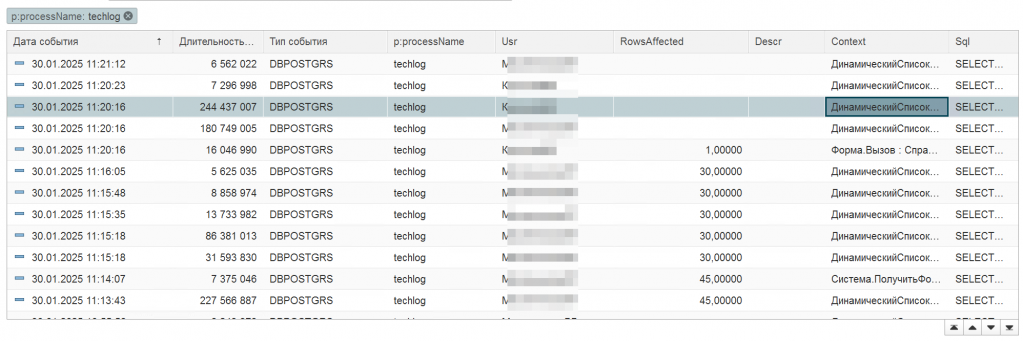
Рис. Таблица длительных запросов

Рис. Контекст длительного запроса
Ниже приведены два запроса. Один SQL запрос, а второй с подстановкой представлений полей и таблиц в термины 1С. Для преобразования мы воспользовались обработкой "Конвертер для преобразования текстов запросов и планов SQL в представления языка 1С"
ВЫБРАТЬ ПЕРВЫЕ 25
T1.Ссылка,
T1.ПометкаУдаления,
T1.Владелец,
T1.Наименование,
T1.ДатаСобытия,
T1.ДлительностьМкс,
T1.ТипСобытия,
T1.Файл,
ВЫБОР КОГДА T1.ИмяПредопределенныхДанных > '\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000'::bytea ТОГДА ИСТИНА ИНАЧЕ ЛОЖЬ КОНЕЦ,
T2.Значение,
T3.Значение,
T4.Значение,
T5.Значение,
T6.Значение,
T7.Значение,
T8.Значение
ИЗ Справочник.СобытияЗамера КАК T1
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.СобытияЗамера.ТабличнаяЧасть.КлючевыеСвойства КАК T2
ПО (T2.Ссылка = T1.Ссылка) И (T2.Свойство = '\\201\\031\\000PV\\234(A\\021\\350\\342\\310\\357\\214\\210\\011'::bytea)
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.СобытияЗамера.ТабличнаяЧасть.КлючевыеСвойства КАК T3
ПО (T3.Ссылка = T1.Ссылка) И (T3.Свойство = '\\201\\031\\000PV\\234(A\\021\\350\\342\\310\\357\\214\\210\\012'::bytea)
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.СобытияЗамера.ТабличнаяЧасть.КлючевыеСвойства КАК T4
ПО (T4.Ссылка = T1.Ссылка) И (T4.Свойство = '\\201\\031\\000PV\\234(A\\021\\350\\342\\310\\357\\214\\210\\023'::bytea)
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.СобытияЗамера.ТабличнаяЧасть.КлючевыеСвойства КАК T5
ПО (T5.Ссылка = T1.Ссылка) И (T5.Свойство = '\\201""\\000PV\\234(A\\021\\352\\302\\244\\232>\\220\\204'::bytea)
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.СобытияЗамера.ТабличнаяЧасть.КлючевыеСвойства КАК T6
ПО (T6.Ссылка = T1.Ссылка) И (T6.Свойство = '\\201\\031\\000PV\\234(A\\021\\350\\342\\310\\357\\214\\210\\014'::bytea)
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.СобытияЗамера.ТабличнаяЧасть.КлючевыеСвойства КАК T7
ПО (T7.Ссылка = T1.Ссылка) И (T7.Свойство = '\\201\\032\\000PV\\234(A\\021\\351x\\207\\020\\212:\\016'::bytea)
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.СобытияЗамера.ТабличнаяЧасть.КлючевыеСвойства КАК T8
ПО (T8.Ссылка = T1.Ссылка) И (T8.Свойство = '\\201\\034\\000PV\\234(A\\021\\351\\344=\\200\\233\\271M'::bytea)
ГДЕ ((T1.ДатаСобытия >= '2025-01-30 00:00:00'::timestamp) И (T1.Владелец = '\\201""\\000PV\\234(A\\021\\352\\277\\225\\315q\\234d'::bytea))
И T1.ДатаСобытия = '2025-01-30 09:37:55'::timestamp И T1.Ссылка < '\\226\\300\\000PV\\234\\320\\245\\021\\357\\336\\326\\035A\\265\\033'::bytea
СОРТИРОВАТЬ ПО (T1.ДатаСобытия) УБЫВ, (T1.Ссылка) УБЫВ
Анализ
Если мы посмотрим на SQL запрос выше, то мы там не увидим ничего криминального:
- Происходит выбор 25 первых из записей основной таблицы справочника "События замера".
- К основной таблице ней присоединяются левым соединением несколько табличных частей.
- Ограничений RLS нет.
- Есть ограничения в секции ГДЕ по полям "Владелец", "Дата События", "Ссылка". Для этих полей есть индексы.
- Есть сортировка по полям "Дата события" и "Ссылка". Мы упорядочивали только по полю "Дата события", что выглядит логично. Откуда появилась "Ссылка" написано ниже.
Замечание! Небольшое пояснение по используемой сортировке в запросе. Как вы видите в секции СОРТИРОВКА у нас присутствуют два поля "Дата события" и "Ссылка". Однако, в самом динамическом списке мы указываем сортировать только по полю "Дата события" (или любому другому). Это легко делается нажатием на соответствующую колонку. Поле "Ссылка" добавляет сама платформа - это позволяет сохранить повторяемость вывода данных при условии равенства некоторых записей по полю "Дата события".
Замечание! Рекомендуем упорядочивать только по проиндексированным полям. В этом случае с большой долей вероятности динамический список будет работать максимально быстро. Для других полей я советую запрещать возможность сортировки. Также не рекомендую ставить упорядочивания по множеству полей, в большинстве случаев достаточно одного поля. Ответ на вопрос "Почему такие советы?" - это отдельная тема для обсуждения. Если интересует, могу рассказать отдельно.
Учитывая, что видимых проблем нет, то давайте посмотрим план запроса. Возьмем SQL запрос и получим его план в pgAdmin. Либо можно сделать все тоже самое через консоль запросов с сайта ИТС (она умеет получать планы запросов) или поискать такую же консоль на текущем ресурсе.
https://explain.tensor.ru/archive/explain/76d083c28179eadc70140a90d233ae9c:0:2025-01-30#visio
Кратко проведем анализ этого простого плана запросов.
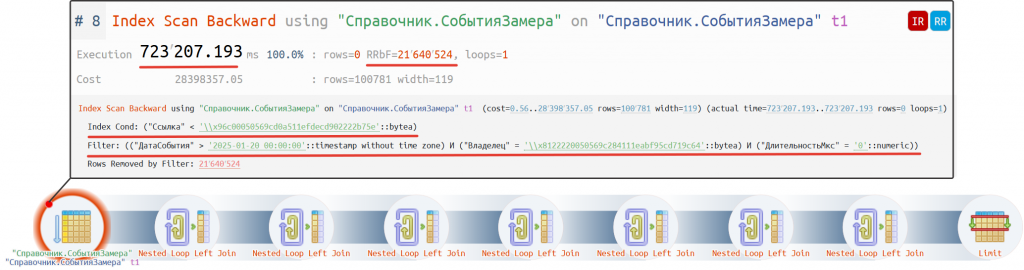
Рис. План запроса
Мы видим, что самый проблемный участок на плане запроса - это оператор получения данных #8. На него приходится 100% времени выполнения в более чем 700 с (около 12 мин). Этот оператор сканирует некоторую индексную таблицу. Это лучше чем выполнять последовательное сканирование всей таблицы, но почему же тратится столько ресурсов?
При детальном рассмотрении оператора получения данных по индексу мы видим следующую картинку:
- В индексном условии (index condition) указано условие «меньше ссылки». Не очень хорошее условие.
- Отбор (filter) у нас есть по владельцу, дате события и длительности. Ожидалось, что часть полей (владелец и дата события) будет верхнем условии.
- Отбрасывается (RRbF) более 21 млн строк. Очень много лишней работы.
Исходя из того что мы видим, планировщик запросов решил воспользоваться неподходящей индексной таблицей для справочника или сформировал плохой план, что привело к необходимости перебирать более двадцати миллионов записей для выполнения требуемого отбора. Это, мягко говоря, далеко от оптимального решения. Почему так происходит? В голову начали приходить неприятные мысли.
Первым делом мы решили проверить, всё ли в порядке с индексами. Неужели мы забыли создать индекс по полю «Дата события»? Ведь он должен был быть создан.
В действительности индекс для поля «Дата события» есть, но выглядит он немного странно.
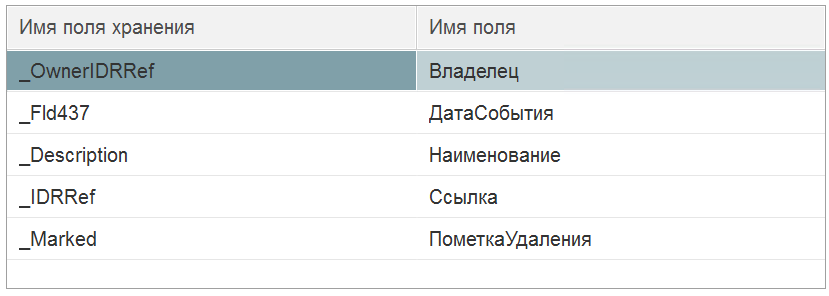
Рис. Структура индексной таблицы для поля "Дата События"
Мы видим, что между ссылкой и датой события находится поле «Наименование». Планировщик запросов соответственно не смог или не стал использовать этот индекс по дате события, а взял другой. Потому что поля "Владелец", "Дата События" прерываются полем "Наименования", которое стоит перед полем "Ссылка". А в исходном запросе у нас нет никакого поля "Наименование" в сортировке или условиях.
Но откуда взялось «Наименование»? Давайте разбираться. Если мы внимательно посмотрим в конфигураторе на свойства реквизита "Дата события" справочника "События замера", то обнаружим, что для него задано дополнительное упорядочивание в свойстве "Индексирование". Именно это условие повлияло на то, что так у нас выглядит эта индексная таблица.
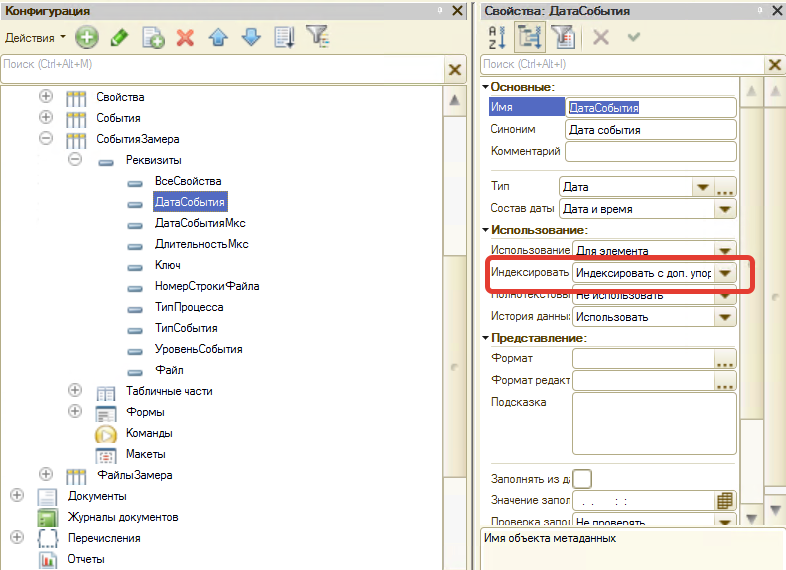
Рис. Настройки свойства "Индексировать" для поля "Дата события"
Если обратиться к документации (индексы таблиц базы данных), то мы увидим, что в случае, если поле имеет дополнительное упорядочивание, в индекс добавляется «Наименование». Однако в нашем случае это явно избыточно и даже плохо (разрыв в использовании порядка полей делает этот индекс не эффективным). У нас система сортирует и ограничивает данные по набору полей - дате события, владельцу и ссылке. Мы не используем поле «Наименование».
Кстати, в MS SQL планировщик запросов работал немного иначе. В отличие от текущей ситуации, он смог более эффективно использовать индекс по полю «Дата события», несмотря на наличие дополнительного упорядочивания по «Наименованию». Это связано с тем, что оптимизатор MS SQL по-другому оценивает стоимость выполнения запросов и выбирает наиболее подходящий индекс, учитывая статистику и распределение данных.
Такое поведение еще раз подчеркивает, что работа планировщика запросов может сильно зависеть от используемой СУБД и её внутренних механизмов оптимизации.
Решение
Таким образом, такая индексная таблица нам не нужна и мы можем смело от нее отказаться. Однако здесь есть важный нюанс: если вдруг мы решим добавить сортировку по «Наименованию» (крайне сомнительно), то возникнут проблемы с производительностью, так как подходящий индекс будет отсутствовать.
Мы изменяем свойство "Индексировать" со значения "Индексировать с дополнительным упорядочиванием" на "Индексировать".
После проведенной оптимизации — ура! — наши запросы стали выполняться практически мгновенно. Убрав избыточность в индексной таблице и пересмотрев логику использования, мы значительно улучшили производительность системы. Это лишний раз подтверждает, как важно внимательно анализировать планы запросов и понимать, какие индексы действительно нужны, а какие лишь создают дополнительную нагрузку.
Посмотрим на план запроса после оптимизации:
https://explain.tensor.ru/archive/explain/6f26cd305dd667b05451131445145b67:0:2025-01-30#explain
https://explain.tensor.ru/archive/explain/8d9dd242ba2207713fd734d3b5366c35:0:2025-01-30#visio
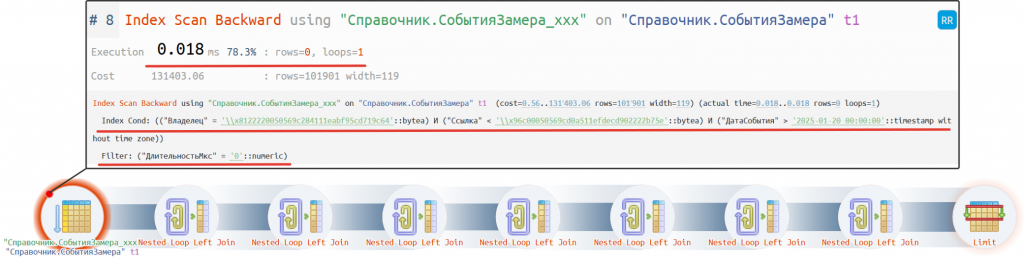
Рис. Оптимизированный план запроса
В результате у нас запрос стал работать так как ожидалось. Время его выполнения составило менее 1 мс, что более чем в 40 млн раз эффективнее.
При детальном рассмотрении мы видим что:
- Теперь используется индекс по полю "Дата события", мы в его наименование для наглядности специально добавили постфикс "xxx".
- Условие по индексу (index condition) у нас используется по всем ключевым полям - "Дата события", "Владелец", "Ссылка"
- В отборе (filter) осталось только поле "Длительность"
Резюме
Часто от коллег можно услышать, что дополнительное упорядочивание — это полезная функция, которая что-то улучшает. Однако, после того как вы прочитали эту статью, я задам вопрос: в каких случаях вы считаете использование дополнительного упорядочивания действительно необходимым?
На текущий момент (воспользуюсь техническим стилем вендора) я бы не рекомендовал использовать эту функцию без крайней и обоснованной необходимости. Дополнительное упорядочивание может быть полезно в некоторых других сценариях в отличии от справочников, например, при работе с документами, где часто требуется отбор и/или сортировка по дате документа вместе с произвольным индексируемым полем. Но даже в таких случаях стоит тщательно оценить необходимость его использования.
Постфактум
Кстати, 1С обещали реализовать возможность создания произвольных индексов (начиная с версии 8.3.26), что, возможно, сделает дополнительное упорядочивание менее актуальным. В будущем эту функцию, вероятно, можно будет отправить в утиль.
Еще пара советов:
- Всегда анализируйте планы запросов при работе с большими объемами данных.
- Не создавайте индексы "на всякий случай" — каждый индекс должен быть обоснован.
- Регулярно проводите ревизию индексов, особенно в highload-системах — отсутствующие индексы и неиспользуемые.
Думаю, Вам будет интересно ознакомиться с другими моими статьями по исправлению ошибок и повышению производительности - другие публикации.
P.S. В ближайшее время будет выпущен новый релиз конфигурации "Мониторинг производительности" с описанной оптимизацией и не только.
Вступайте в нашу телеграмм-группу Инфостарт