
{kind=link}
Идея довольно проста:
-
Загрузить изображение на Google Диск.
-
Сохранить его в формате документа Google Docs.
-
Извлечь текст из этого документа.
-
Удалить документ после завершения работы.
Для загрузки файла на Google Диск требуется аутентификация по протоколу OAuth 2.0. OAuth — это открытый протокол авторизации, который позволяет предоставить доступ к защищённым ресурсам (например, вашему Google Диску) без передачи логина и пароля. Вместо этого используется токен доступа, который выдаётся после подтверждения прав доступа. Это безопасно и удобно.
Подробнее о том, как работает аутентификация OAuth 2.0, можно узнать здесь.
Обращаю внимание, для того чтобы файл в формате pdf или jpeg можно было экспортировать в текстовый формат его необходимо сохранить в формате application/vnd.google-apps.document.
Процедура ВыполнитьРаспознаваниеНаСервере(ПутьККартинке)
//Порядок распознавания:
//- сохраняем картинку на гугл диск в формате гугл документа
//- экспортируем этот гугл документ в текст
//- удаляем гугл документ
Если Токен <> "" Тогда
ИдентификаторФайла = ЗагрузитьФайлНаGoogleDrive(ПутьККартинке, Токен);
Если ИдентификаторФайла <> Неопределено Тогда
Результат = РаспознатьТекстЧерезGoogleDrive(ИдентификаторФайла, Токен);
УдалитьФайлСGoogleDrive(ИдентификаторФайла, Токен);
Сообщить(Результат);
КонецЕсли;
КонецЕсли;
КонецПроцедуры
Функция ЗагрузитьФайлНаGoogleDrive(ПутьКФайлу, Токен, ТокенОбновлен = Ложь) Экспорт
Файл = Новый Файл(ПутьКФайлу);
boundary = СтрЗаменить(Строка(Новый УникальныйИдентификатор()), "-", "");
//Метаданные файла {{
//для того чтобы файл в формате pdf или jpeg можно было экспортировать в текстовый формат
//необходимо сохранить его в формате application/vnd.google-apps.document
mimeType = "application/vnd.google-apps.document";
Свойства = Новый Соответствие();
Свойства.Вставить("name", Файл.Имя);
Свойства.Вставить("mimeType", mimeType); // тип файла
СтрокаМетаданныеФайла = СформироватьТекстJSON(Свойства);
Поток = Новый ПотокВПамяти();
ЗаписьДанных = Новый ЗаписьДанных(Поток);
ЗаписьДанных.ЗаписатьСтроку("Content-Type: application/json; charset=UTF-8");
ЗаписьДанных.ЗаписатьСтроку("");
ЗаписьДанных.ЗаписатьСтроку(СтрокаМетаданныеФайла);
ЗаписьДанных.Закрыть();
ДвоичныеДанныеМетаданные = Поток.ЗакрытьИПолучитьДвоичныеДанные();
//Данные файла {{
ДвоичныеДанные = Новый ДвоичныеДанные(ПутьКФайлу); // двоичные данные файла
Поток = Новый ПотокВПамяти();
ЗаписьДанных = Новый ЗаписьДанных(Поток);
ЗаписьДанных.ЗаписатьСтроку("Content-Type: " + mimeType);
ЗаписьДанных.ЗаписатьСтроку("");
ЗаписьДанных.Записать(ДвоичныеДанные);
ЗаписьДанных.Закрыть();
ДвоичныеДанныеФайла = Поток.ЗакрытьИПолучитьДвоичныеДанные();
//Данные файла }}
//формирование тела запроса {{
ПотокТело = Новый ПотокВПамяти();
ЗаписьДанных = Новый ЗаписьДанных(ПотокТело);
ЗаписьДанных.ЗаписатьСтроку("--" + boundary);
ЗаписьДанных.Записать(ДвоичныеДанныеМетаданные);
ЗаписьДанных.ЗаписатьСтроку("--" + boundary);
ЗаписьДанных.Записать(ДвоичныеДанныеФайла);
ЗаписьДанных.ЗаписатьСтроку("--" + boundary + "--");
ЗаписьДанных.ЗаписатьСтроку("--" + boundary + "--");
ЗаписьДанных.Закрыть();
ДвоичныеДанныеТело = ПотокТело.ЗакрытьИПолучитьДвоичныеДанные();
//формирование тела запроса }}
Заголовки = Новый Соответствие;
Заголовки.Вставить("Authorization", "Bearer " + Токен);
Заголовки.Вставить("Content-Type", "Multipart/Related; boundary=" + boundary);
Заголовки.Вставить("Content-Length", Формат(ДвоичныеДанныеТело.Размер(), "ЧГ="));
HTTPЗапрос = Новый HTTPЗапрос("/upload/drive/v3/files?uploadType=multipart", Заголовки);
HTTPЗапрос.УстановитьТелоИзДвоичныхДанных(ДвоичныеДанныеТело);
SSL = Новый ЗащищенноеСоединениеOpenSSL(Неопределено, Неопределено);
Соединение = Новый HTTPСоединение("www.googleapis.com",,,,,,SSL);
Ответ = Соединение.ОтправитьДляОбработки(HTTPЗапрос);// post запрос
Если Ответ.КодСостояния = 401 Тогда
//Это значит токен устарел и его надо обновить
Если Не ТокенОбновлен Тогда
Токен = ПолучитьAccessToken();
Возврат ЗагрузитьФайлНаGoogleDrive(ПутьКФайлу, Токен, Истина);
КонецЕсли;
КонецЕсли;
Если Ответ.КодСостояния <> 200 И Ответ.КодСостояния <> 204 тогда
ВызватьИсключение "Ошибка загрузки файла: " + Ответ.КодСостояния + ". Тело ответа: " + Ответ.ПолучитьТелоКакСтроку();
Возврат Неопределено;
КонецЕсли;
ДанныеОтвета = Ответ.ПолучитьТелоКакСтроку();
ЧтениеJSON = Новый ЧтениеJSON;
ЧтениеJSON.УстановитьСтроку(ДанныеОтвета);
Попытка
РезультатЧитаемый = ПрочитатьJSON(ЧтениеJSON,Истина);
Исключение
Возврат Неопределено;
КонецПопытки;
ИдФайла = РезультатЧитаемый.Получить("id");
Возврат ИдФайла;
КонецФункции
Функция СформироватьТекстJSON(Данные)
ЗаписьJSON = Новый ЗаписьJSON;
ЗаписьJSON.УстановитьСтроку();
ЗаписатьJSON(ЗаписьJSON, Данные);
Результат = ЗаписьJSON.Закрыть();
Возврат Результат;
КонецФункции
После загрузки файла получаем id файла, который необходим для получения текстового представления и для дальнейшего удаления файла.
Подробнее о загрузке файла на Google диск можно ознакомиться здесь.
Функция РаспознатьТекстЧерезGoogleDrive(ИдентификаторФайла, Токен) Экспорт
// Создание HTTP-запроса
ЗапросHTTP = Новый HTTPЗапрос("drive/v3/files/" + ИдентификаторФайла + "/export?mimeType=text/plain");
ЗапросHTTP.Заголовки.Вставить("Authorization", "Bearer " + Токен);
ЗапросHTTP.Заголовки.Вставить("Content-Type", "application/json" );
ЗапросHTTP.Заголовки.Вставить("mimeType", "text/plain");
// Отправка запроса
SSL = Новый ЗащищенноеСоединениеOpenSSL(Неопределено, Неопределено);
HTTPСоединение = Новый HTTPСоединение("www.googleapis.com",,,,,, SSL);
ОтветHTTP = HTTPСоединение.Получить(ЗапросHTTP);
// Обработка ответа
Если ОтветHTTP.КодСостояния = 200 Тогда
//распознанный текст
Результат = ОтветHTTP.ПолучитьТелоКакСтроку();
Иначе
Результат = "Ошибка при распознавании текста: " + ОтветHTTP.КодСостояния + " " + ОтветHTTP.ПолучитьТелоКакСтроку();
КонецЕсли;
Возврат Результат;
КонецФункции
Процедура УдалитьФайлСGoogleDrive(ИдентификаторФайла, Токен) Экспорт
// Создание HTTP-запроса
ЗапросHTTP = Новый HTTPЗапрос("drive/v3/files/" + ИдентификаторФайла);
ЗапросHTTP.Заголовки.Вставить("Authorization", "Bearer " + Токен);
ЗапросHTTP.Заголовки.Вставить("Content-Type", "application/json" );
// Отправка запроса
SSL = Новый ЗащищенноеСоединениеOpenSSL(Неопределено, Неопределено);
HTTPСоединение = Новый HTTPСоединение("www.googleapis.com",,,,,, SSL);
HTTPСоединение.Удалить(ЗапросHTTP);
КонецПроцедуры
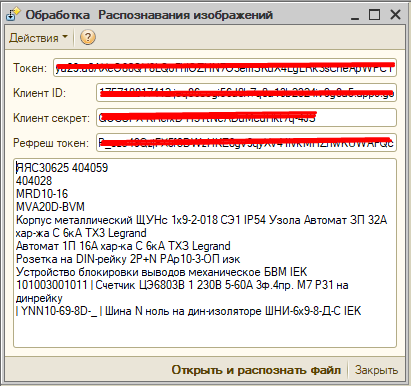
Обработка создана на обычных формах, тестировалась на версии платформы 8.3.21.1302.
Данная обработка создана исключительно для демонстрации возможности распознавания файлов, загруженных на Google Drive. Все необходимые процедуры и шаги подробно описаны в этой статье. Если вы хотите поблагодарить автора или протестировать функционал, вы можете скачать обработку.
Проверено на следующих конфигурациях и релизах:
- Управление торговлей, редакция 10.3, релизы 10.3.86.2
Вступайте в нашу телеграмм-группу Инфостарт