Хочу поговорить про код-ревью с помощью искусственного интеллекта.
Несмотря на то, что доклад называется «Текущие возможности и тренды», пока я к нему готовился, многое изменилось. Поэтому в основном речь пойдет о вчерашних возможностях. И вообще в этой сфере, как мне кажется, невозможно успеть за прогрессом. Технологии развиваются стремительно – то, что мы обсуждаем сегодня, уже завтра может измениться, и придется заново все изучать и подстраиваться.

Я считаю, что код-ревью – это один из самых важных этапов разработки, и он непосредственно влияет на уровень качества всего процесса.
Рассмотрим инструменты, которые используются в традиционном код-ревью – с помощью чего мы его проводим.

Первый инструмент, который мы используем чаще всего – это насмотренность. Опытный тимлид может бегло взглянуть на код и сразу найти в нем 5-10 ошибок. А если он внимательно посмотрит, то найдет еще больше ошибок. Соответственно, чем больше кода мы смотрим, тем лучше наши навыки насмотренности.

Второй инструмент, который помогает нам в код-ревью – это стандарты фирмы «1С», свод правил, позволяющий программисту избежать многих возможных ошибок. Если хотите, чтобы все работало качественно, быстро и хорошо, соблюдайте стандарты – их знание существенно повышает качество проведения код-ревью.

Еще один инструмент – «1С:Автоматизированная проверка конфигурации» (АПК).
Это довольно забавная штука. Обычно она находит 20 тысяч ошибок, чем повергает в шок и уныние, напрочь отбивая желание что-либо исправлять – хочется все закрыть, расплакаться и уйти. Кажется, что в этом коде вообще нет смысла – ошибок слишком много.

Поэтому на смену АПК или в дополнение к АПК часто используют SonarQube. Этот инструмент позволяет динамически отслеживать все изменения, исправлять только то, что появилось в новых версиях, не пытаясь разобраться с тем, что было раньше. Двигаться все время вперед и смотреть, чтобы в новом коде все было хорошо.
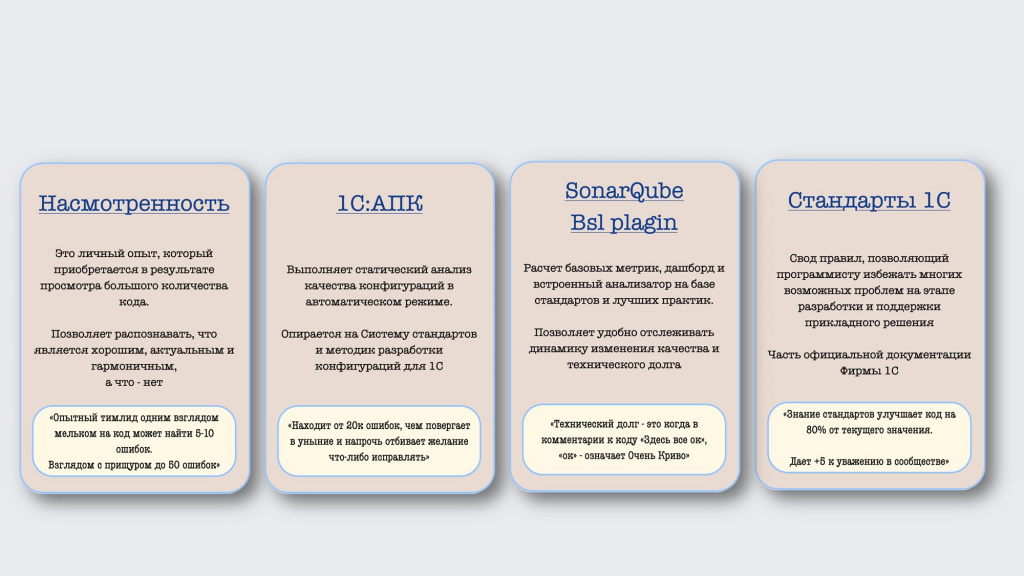
Вот такие четыре основных инструмента, которые используют практически все.
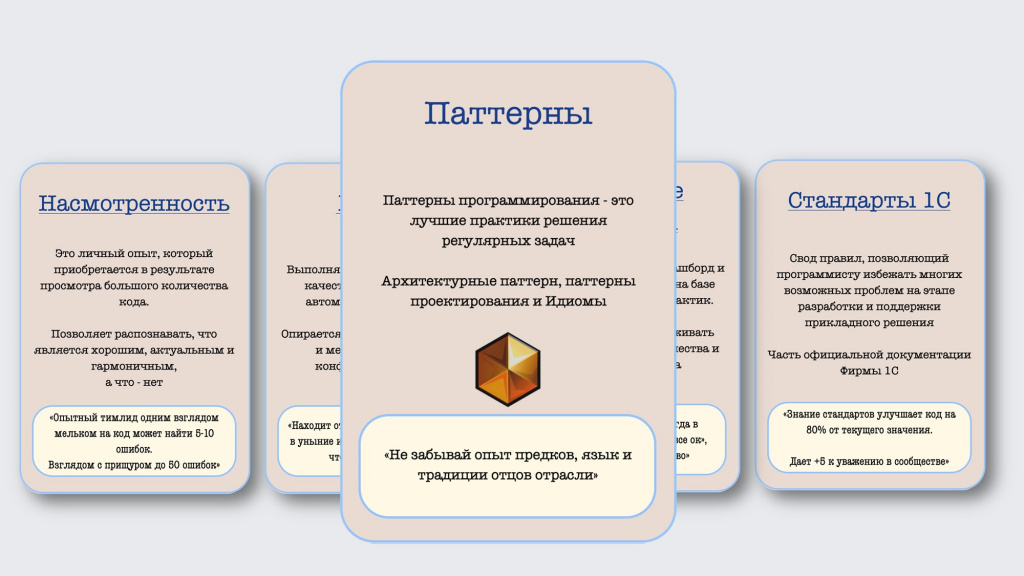
Но есть еще так называемые «легендарные карточки».
Первая карточка – это паттерны программирования. Если вы знаете и умеете применять паттерны программирования, ваш уровень код-ревью становится еще выше. Этот инструмент используется не у всех, но если он есть в вашем арсенале – это большое преимущество для Вас и для команды!
И вторая такая карточка – это соглашения о написании кода. Если вы с командой договорились, каким образом писать код, и документировали эти договоренности, это еще лучше. Считайте, что вы отменили стандарты – вы можете ссылаться на свои соглашения и проверять код уже с ними.

Если вам интересно узнать больше о практике проведения код-ревью, у меня об этом был доклад на DevCon. Я там рассказывал о том, как код-ревью проводится у нас при разработке 1С:Бухгалтерии – на что мы обращаем внимание, какие инструменты используем и так далее.
Проблемы
Теперь о том, какие у традиционного код-ревью есть проблемы, и почему он не всегда получается хорошо.

Первая проблема, которая бывает, наверное, у всех – это отсутствие контекста. Когда разработчик получает код на проверку, ему приходится тратить значительное время на разбор изменений: что именно было сделано, зачем это понадобилось, и как это влияет на всю систему.

Следующая проблема – это большой объем изменений. Наверняка, многие сталкивались с тем, что если разработчик смотрит на код из 10 строк, то пишет 10 замечаний, а когда смотрит на код из 1000 строк, говорит: «Ну, вроде норм».

Это даже подтверждено исследованиями: чем больше кода на ревью, тем меньше проверяющий дает замечаний, и тем хуже получается качество этого ревью. Поэтому ревьюшечки желательно делать поменьше. В 1С с этим могут быть сложности, но приходится как-то выкручиваться.

Следующая проблема – это человеческий фактор. Например, недостаточная квалификация может быть не только у того, кто передает код на ревью, но и у самого ревьюера.
Плюс бывает медленная реакция – ревью откладывается на конец спринта, что приводит к потере мотивации и контекста у разработчиков.

Еще одна проблема, которую тоже можно отнести к человеческому фактору – это конфликты и разногласия между автором и ревьюером кода.
Это проблема характерна не только в 1С-ном сообществе. Есть даже рекомендации от Google, как правильно делать ревью – например, что важно быть доброжелательным, объяснять свои замечания и обосновывать критику.
В противном случае такие конфликты приходится эскалировать наверх – до архитекторов и еще выше. Не доводите, пожалуйста, до такого.

И последняя проблема – это неправильная приоритизация. Часто проверяющие погружены в свои задачи и хотят их доделать как можно быстрее, а код-ревью взять попозже.
Но это не очень хорошо, потому что чем быстрее мы проведем код-ревью, тем быстрее разработчик все исправит – и такая приоритизация лучше.
Мы, например, используем у себя Kanban – у нас все работает по методу вытягивания. Поэтому освободившемуся разработчику важно взять задачу, которая ближе к концу процесса. В этом случае код-ревью в бОльшем приоритете, чем взятие в разработку новых задач. Это помогает нам делать такие ревью быстрее и ритмичнее.

Вот такие проблемы есть у код-ревью в целом.
В чем может помочь искусственный интеллект при код-ревью?

Мы сейчас рассмотрели стандартные инструменты код-ревью. Но я хочу, чтобы после этого доклада вы добавили в вашу колоду карт новый инструмент – AI-агенты для код-ревью.
AI-агенты – это сервисы на базе искусственного интеллекта, которые умеют анализировать код, выявлять ошибки и выдавать результат. Они специализируются на задачах код-ревью, поэтому нам не нужно заморачиваться с объяснениями в промпте – AI-агенты сразу понимают, что мы от них хотим, и лучше нам помогают.
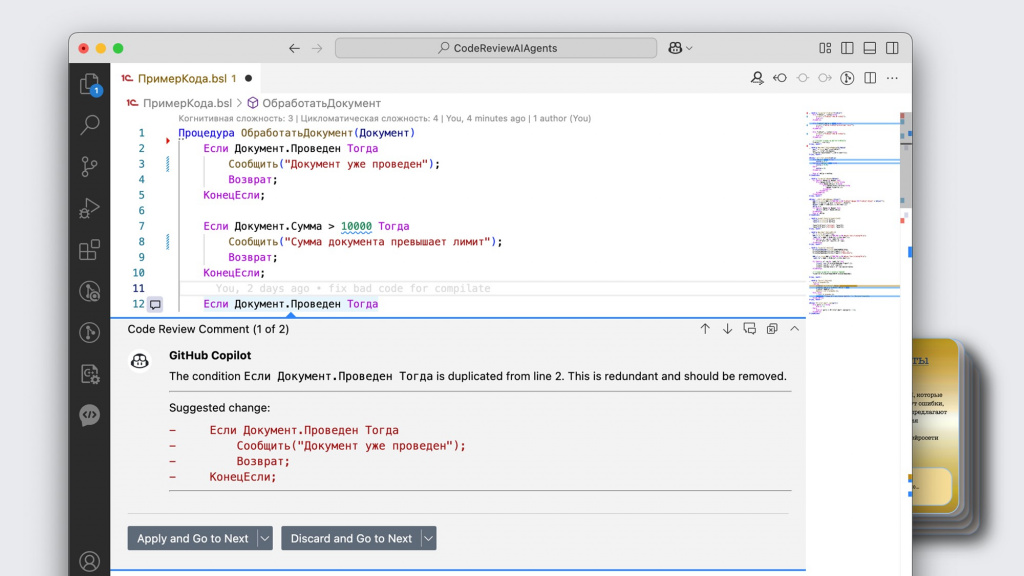
Возьмем самый простой код, натравим на него GitHub Copilot и посмотрим, на что он обратит внимание.
Он показывает, что здесь задублированы условия – первое и третье «если».
Но, например, магические цифры он здесь уже не заметил – для него это вроде как норм.
Все равно нам с ним будет чуть проще – не надо самим это вычитывать.
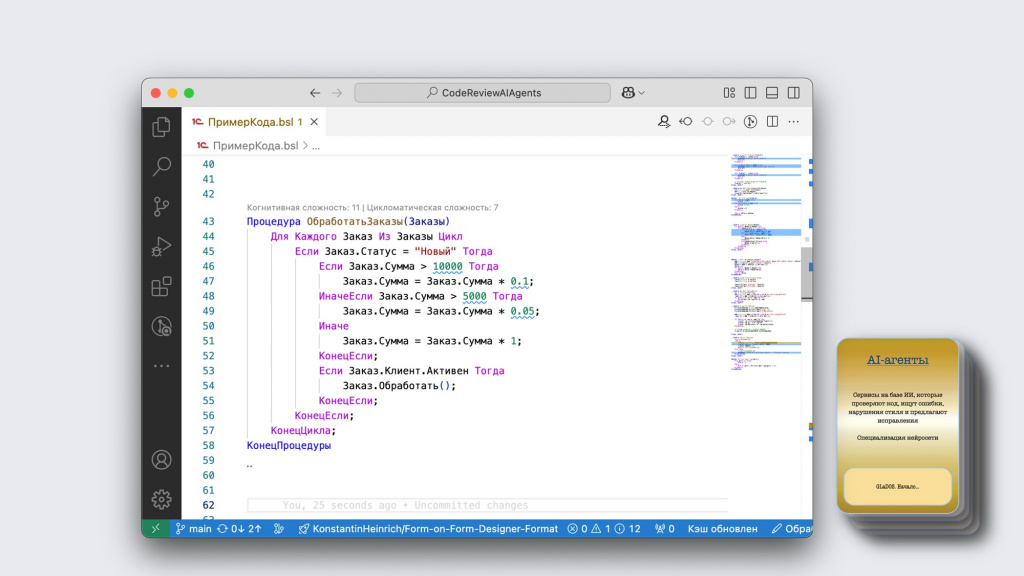
А теперь возьмем чуть более сложный код и попробуем его скормить уже другой нейросети – в данном случае, DeepSeek. Посмотрим, что она здесь найдет.
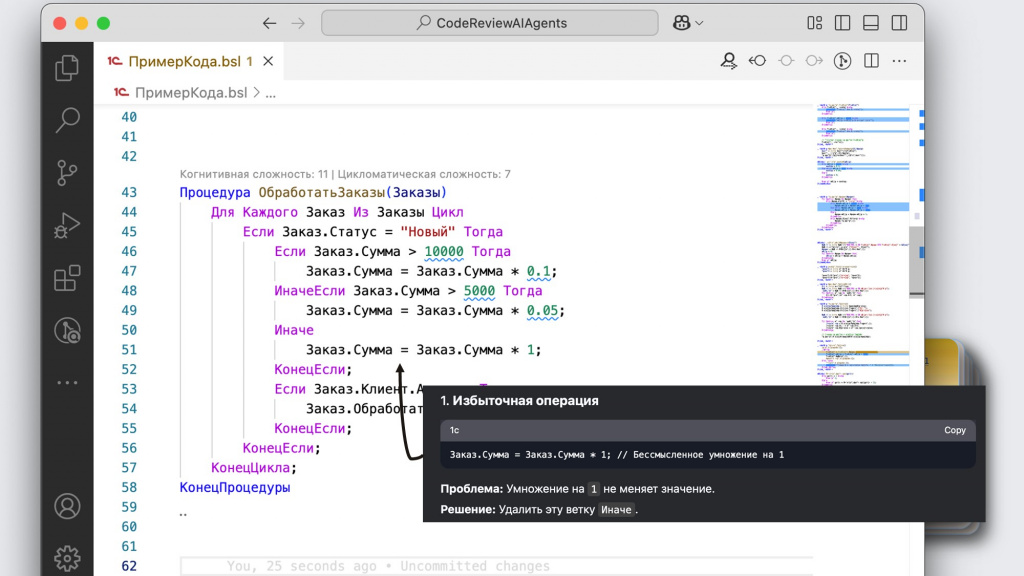
Первое замечание – это избыточная операция. Модель показывает, что умножение суммы на единицу не меняет значения, и эту ветку условия можно вообще удалить.
Понятно, что в этом случае мы можем словить замечание от SonarQube, который потребует дополнить условие веткой «Иначе». Но тут уже нужно выбирать, что для нас важнее.
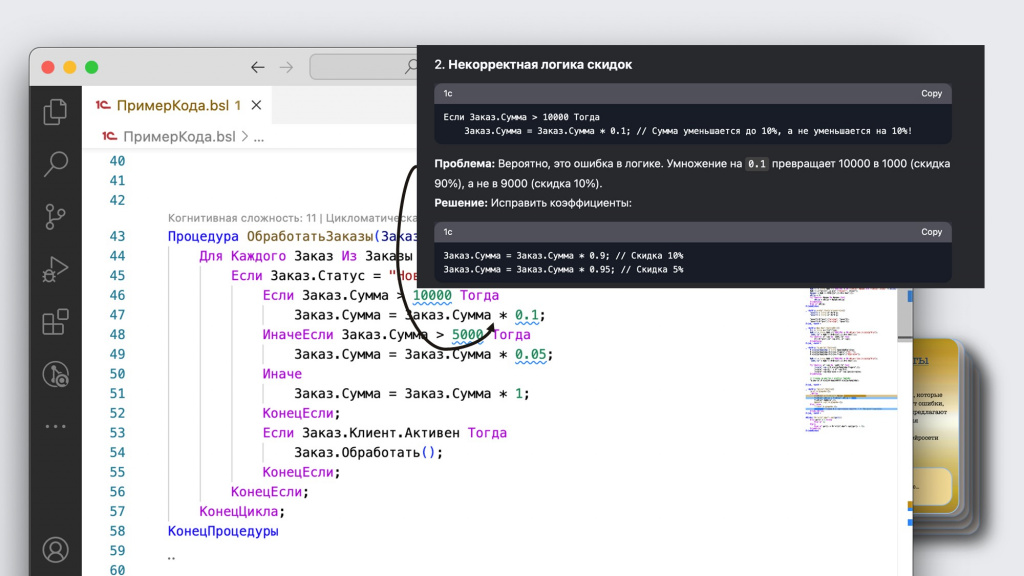
Второе замечание интереснее – DeepSeek уже пытается анализировать логику программы.
Если посмотреть внимательно, видно, что мы сумму умножаем на 0.1. Не вычитаем из суммы 10%, а в целом приводим ее к 10%.
Получается, что мы неправильно посчитали скидку – вместо того, чтобы уменьшить на 10%, мы уменьшили на 90%. DeepSeek это нашла и предложила обратить внимание.
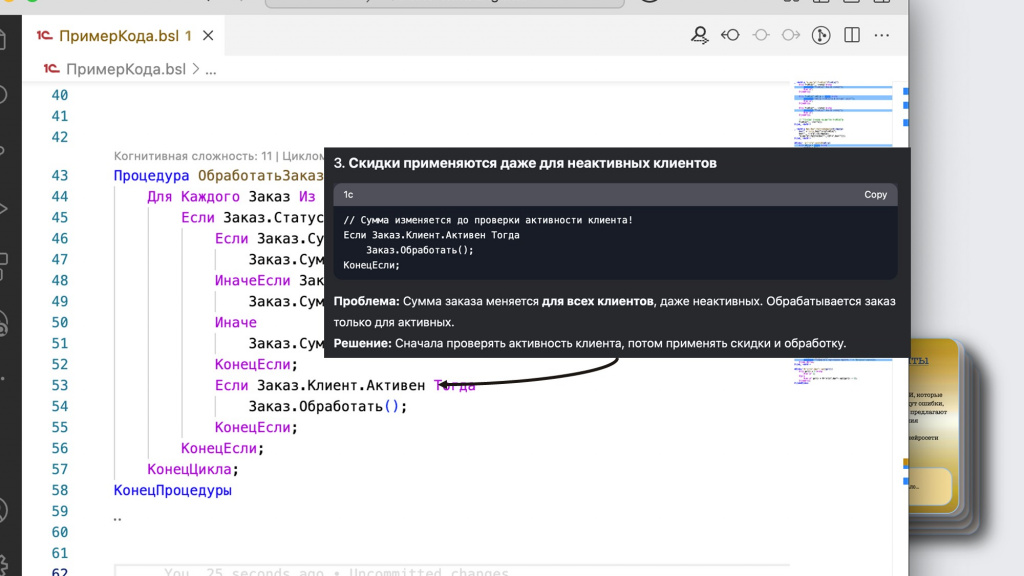
На этом она не останавливается и еще детальнее анализирует логику программы – говорит, что скидки у нас применяются даже для неактивных клиентов. Возможно, так и задумано, но логика по ее мнению странная, поэтому она об этом сообщает.
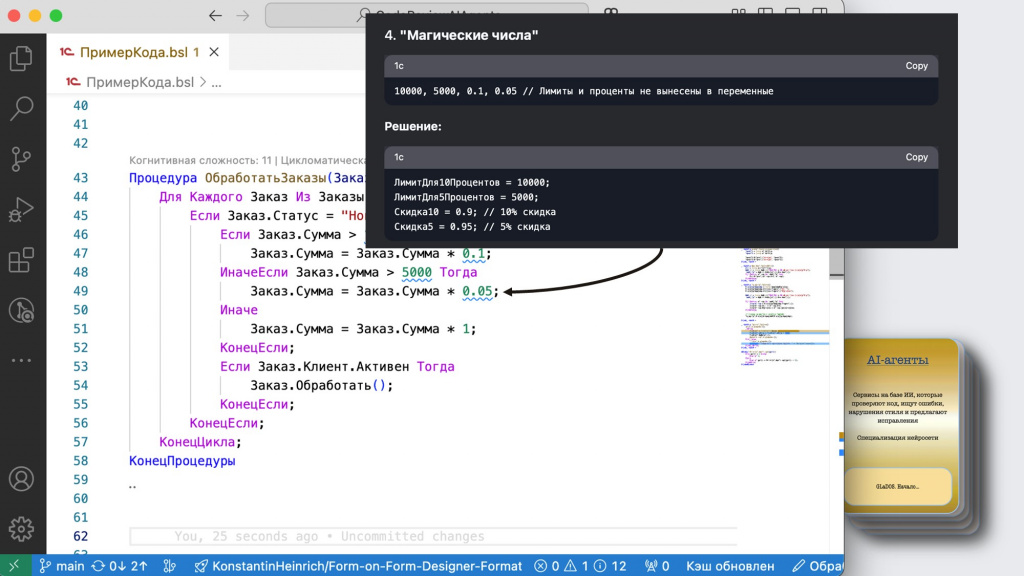
Следующий момент – она обращает внимание на магические числа, их лучше не указывать напрямую в коде, а выносить в отдельные переменные.
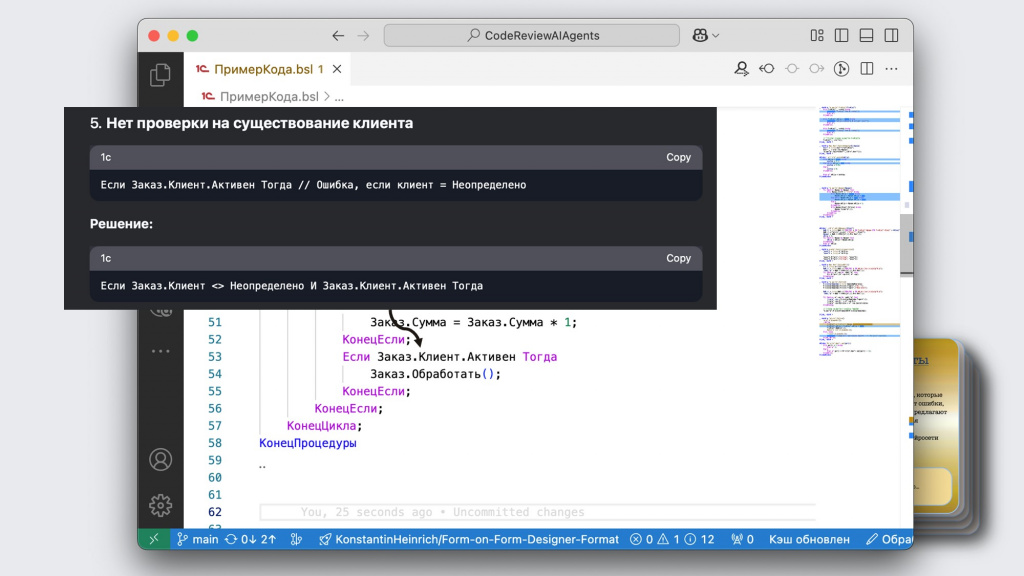
Дальше она показывает, что мы обращаемся к свойствам реквизитов документа через две точки, не проверяя при этом, что реквизит вообще заполнен. Это тоже следует исправить.
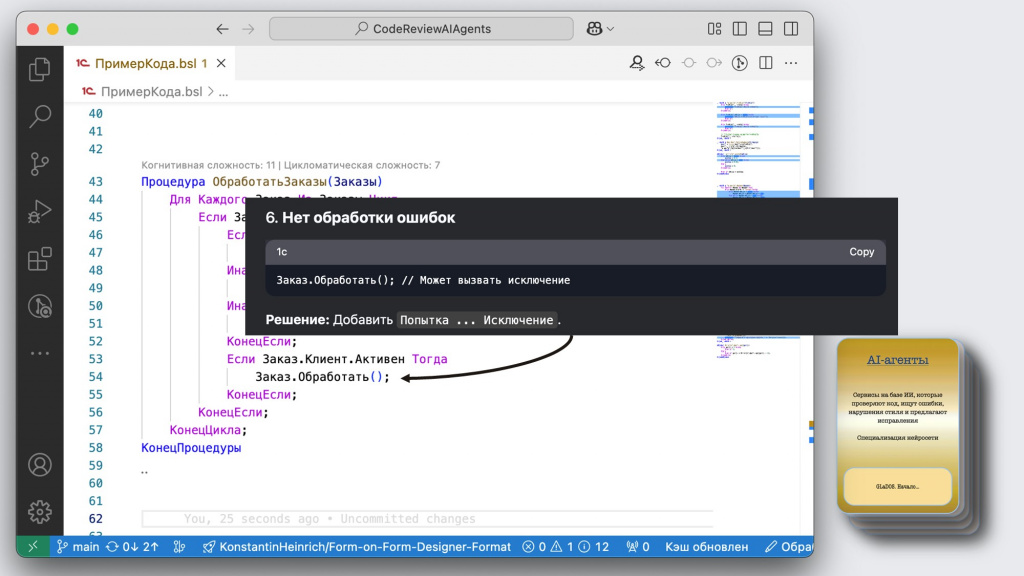
И в конце говорит, что хорошо бы еще обработать ошибки при выполнении операции через конструкцию «Попытка… Исключение». Но здесь уже каждый сам решает – нужно это или не нужно.
Вот на таком маленьком коде DeepSeek нашла столько замечаний.
Я бы здесь, наверное, добавил ранний выход из условия для заказов, у которых статус не «Новый», чтобы немного сократить когнитивную сложность. Но все равно работа уже проделана большая.
Рассмотрим еще один пример код-ревью – на этот раз с помощью ChatGPT. Возьмем этот кусок кода, и посмотрим, какие замечания по нему нам выдаст нейросеть.
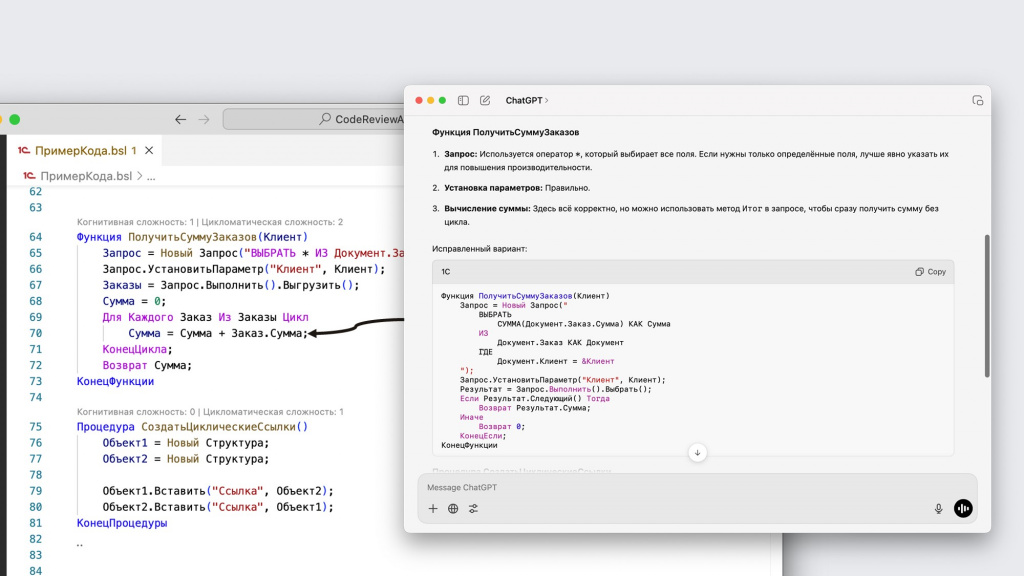
Первое, на что ChatGPT обращает наше внимание – это то, что в коде присутствует запрос для получения сумм заказов, и поэтому складывать эти суммы в цикле неправильно. Лучше прямо в запросе все сложить – будет и быстрее, и удобнее.
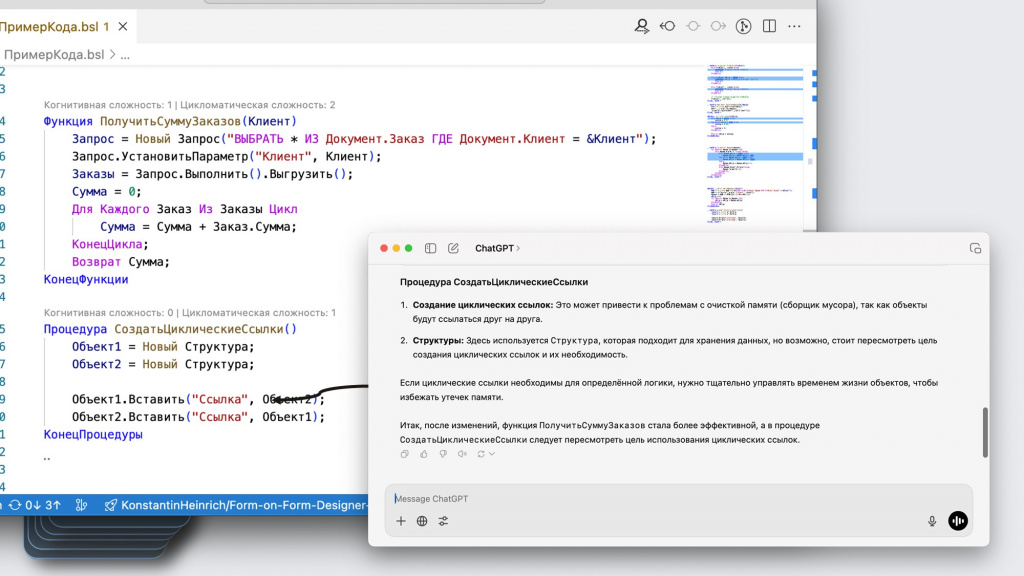
Кроме этого, ChatGPT анализирует, что здесь используются циклические ссылки – структура ссылается сама на себя. Вы можете об этом не знать, но если что, искусственный интеллект вам поможет избежать такие ошибки.
Преимущества ИИ при код-ревью
Если обобщить, чем может помочь искусственный интеллект при код-ревью, то я здесь выделил три ключевых преимущества.

Первое – это быстрый ответ. К ИИ можно обратиться за проверкой практически в любой момент, и получить ответ в течение минуты. Это быстрее, чем ждать, пока какой-то занятый разработчик освободится.
Таким образом мы исключаем две проблемы – с неправильным приоритетом код-ревью и с человеческим фактором.
-
Мы можем получить ревью от ИИ в любой момент.
-
Если что-то пошло не так, он, в отличие от тимлида, не будет сильно ругаться.

Второе преимущество ИИ – это улучшение качества кода и поддержка общего стиля.
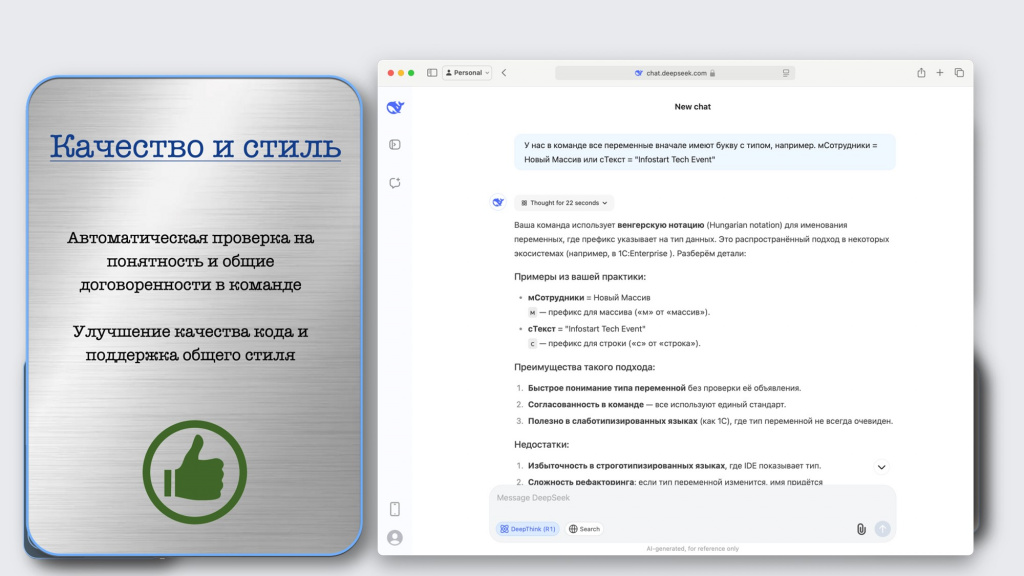
Если в вашей команде используется свой подход к написанию кода – например, венгерская нотация, где к каждой переменной нужно добавлять префикс согласно ее типу («мСотрудники = Новый Массив» и так далее) – достаточно обучить этому нейросеть, и она будет формировать все замечания с учетом этих требований.
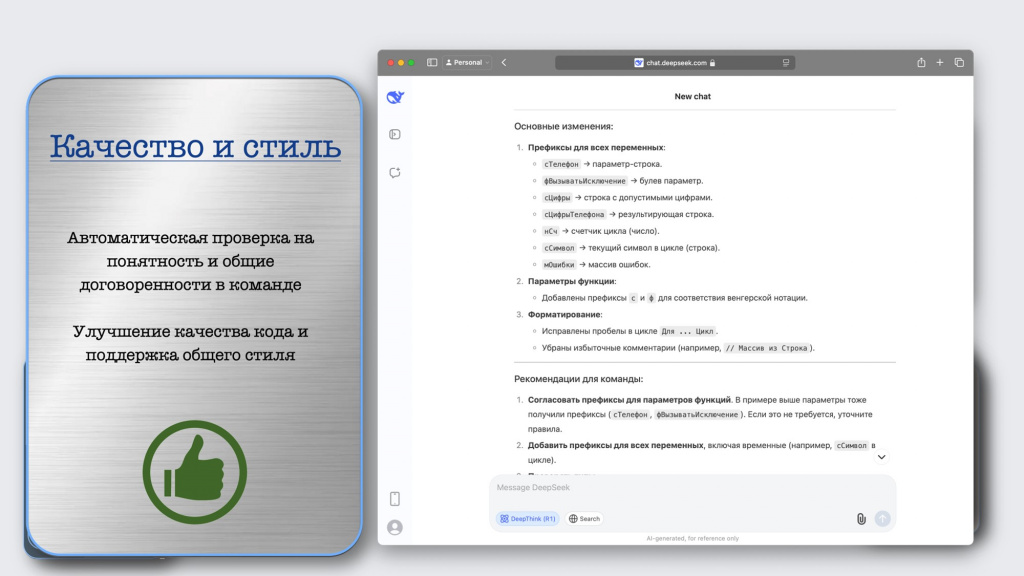
Например, при ревью она скажет, как должны выглядеть переменные.

И даже подготовит код, который бы соответствовал таким замечаниям – переименует переменные в «сЦифры», «сНомерТелефона» и так далее.

Таким образом ИИ поможет вам соблюдать соглашение о написании кода внутри команды, что позволит вам избежать конфликтов и разногласий.

И третье преимущество – это поиск скрытых ошибок. Нейросеть всегда выполняет полный анализ кода с учетом всего контекста, смотрит незамыленным взглядом и умеет находить в коде неправильную логику.

Это убирает две последние проблемы.
-
Переданный ранее контекст учитывается полностью – можно скормить код нейросети, и она найдет ошибки, которые человек может пропустить.
-
Анализ большого объема изменений становится проще – разработчику не нужно разбираться во всем самому.

Такие преимущества использования ИИ при код-ревью я увидел. Возможно, есть и другие.
ИИ-Инструменты для код-ревью

Теперь давайте рассмотрим инструменты для проведения код-ревью с помощью искусственного интеллекта. Я выделил основные три категории таких инструментов.
-
Отдельно стоящие инструменты, которые никуда не встраиваются – ни в IDE, ни в процесс.
-
Инструменты, которые встраивается непосредственно в среду разработки – в VS Code или EDT.
-
Инструменты, которые встраиваются в процесс – вне зависимости от используемой у вас среды разработки. Например, у вас настроен процесс CI/CD, который проверяет код в результате пулл-реквеста, туда встраивается искусственный интеллект и выполняет за вас какую-то работу.
Все эти подходы имеют свои преимущества и недостатки. Давайте посмотрим конкретные инструменты, которые относятся к каждой категории.

Первый инструмент из тех, которые стоят отдельно – это YandexGPT, отечественная нейросеть.
Сейчас многие с ней экспериментируют, рассказывают, что она становится все лучше и лучше. Даже на 1С у нее вроде получаются какие-то моменты. Работает бесплатно. Если интересно, можно пробовать.

Вторым идет ChatGPT – его название уже стало нарицательным, как ксерокс, памперс, скотч или термос. Любые решения, связанные с генеративным искусственным интеллектом, сейчас называют ChatGPT. Но в России он, к сожалению, недоступен.

Поэтому переходим к нашумевшему сервису DeepSeek. Очень коротко расскажу, что он умеет.
Ему можно дать ссылку на файл в GitHub и попросить провести его код-ревью.
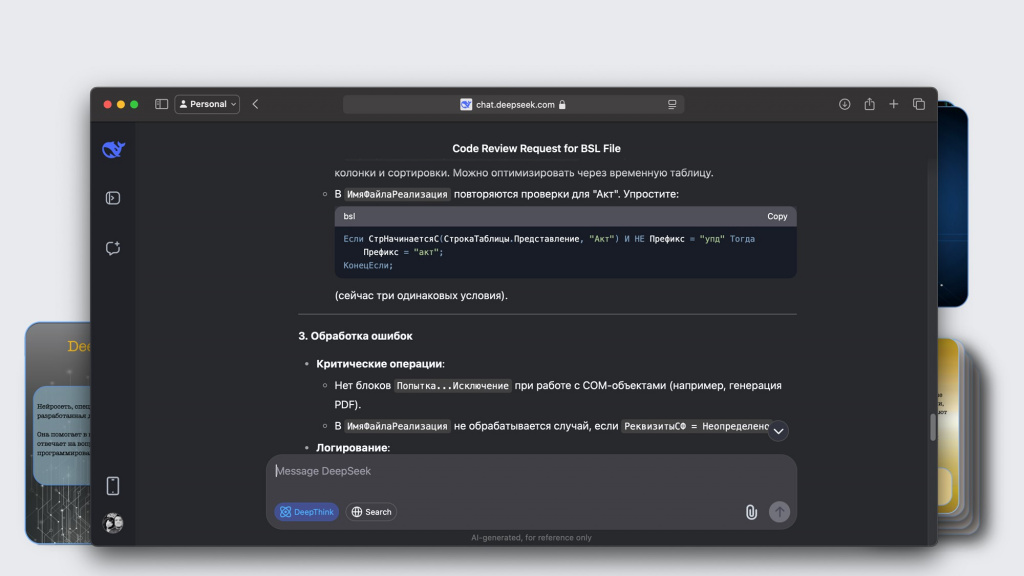
В результате он даст замечания к конкретным строчкам кода – на что нужно обратить внимание.
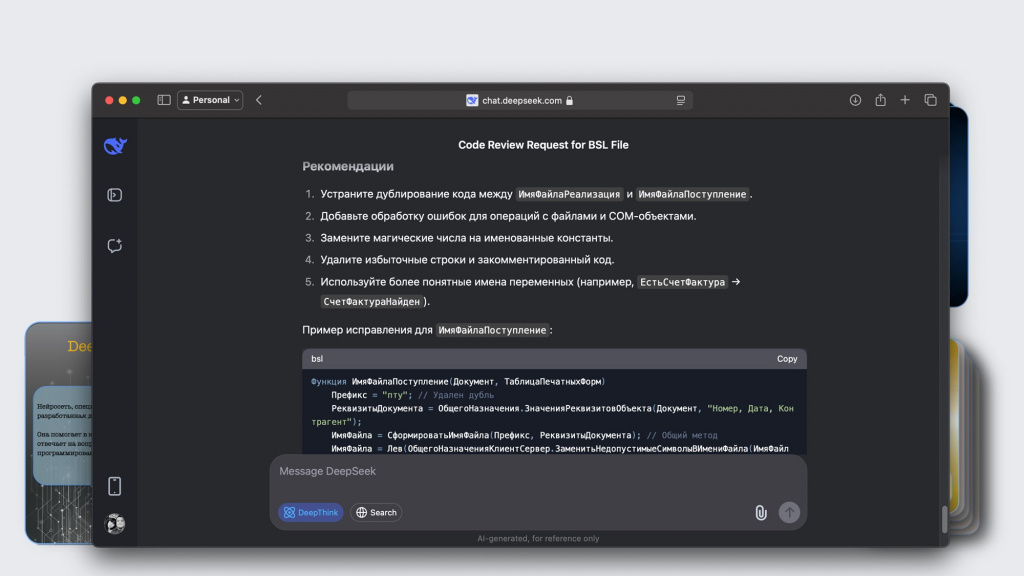
И в конце даст рекомендации в целом по файлу.
Но он, бывает, ленится – проверит только одну функцию, а про остальное скажет, что дальше по аналогии нужно сделать самому. Приходится напоминать, чтобы он проверил и остальное. Здесь нужно пробовать.

Следующая категория – инструменты, которые встраиваются непосредственно в IDE.
Здесь первое, что приходит на ум, и с чего все началось – это GitHub Copilot. Он встраивается в VS Code и может показывать замечания к коду прямо там.
Сейчас GitHub Copilot стал бесплатным, но в России, к сожалению, не работает.

Поэтому переходим к другому инструменту – Bito’s AI. Это специальный AI-агент, который встраивается в VS Code и позволяет проводить код-ревью в отдельном окне.
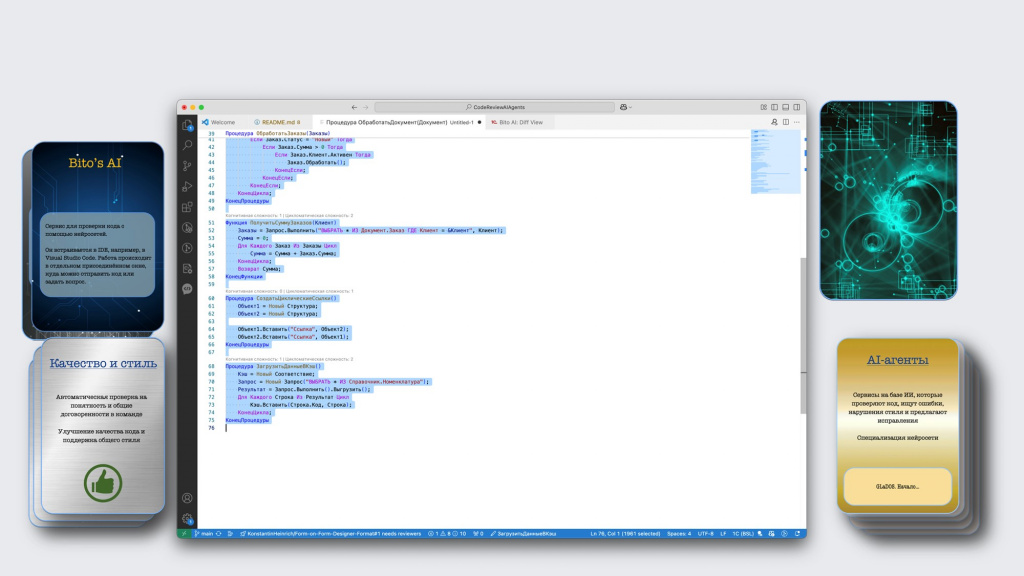
Допустим, у нас есть код в VS Code – выделяем нужный фрагмент кода, вызываем контекстное меню и выбираем проверку из подменю Bito AI.

Здесь есть три вида проверок:
-
проверки производительности – Performance Check;
-
проверки безопасности – Security Check;
-
стилистические проверки – Style Check.
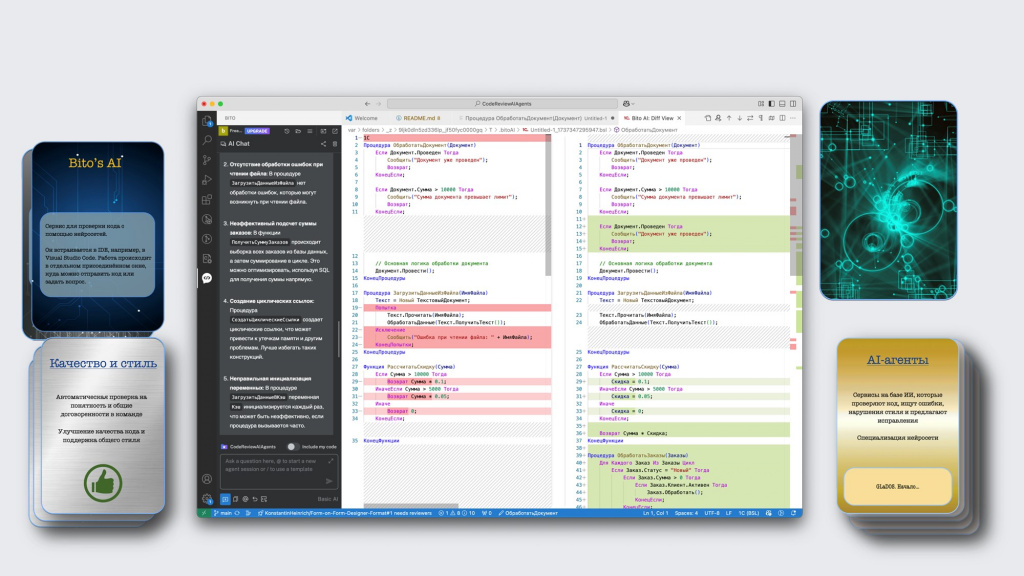
В результате сервис прямо в этом же окне дает вам обратную связь по коду:
-
слева показывает замечания, которые он нашел;
-
а справа – конкретные изменения, которые можно сразу внести в код.
Эти изменения даже не нужно отсюда отдельно копировать – нажимаем плюсик, и они сразу прилетают к нам в рабочую область. Очень удобно.
В ближайшее время фирма «1С» выпустит инструмент для проведения код-ревью, встраиваемый в EDT (обновление – вышел 1С:Напарник). Но для конфигуратора, к сожалению, ничего подобного вендор не обещает.

Следующая категория инструментов – это те, которые встраиваются в процесс. Если у вас выстроены процессы CI/CD – используется GitHub, GitLab, Bitbucket либо отечественный GitVerse – вы уже можете использовать эти инструменты.
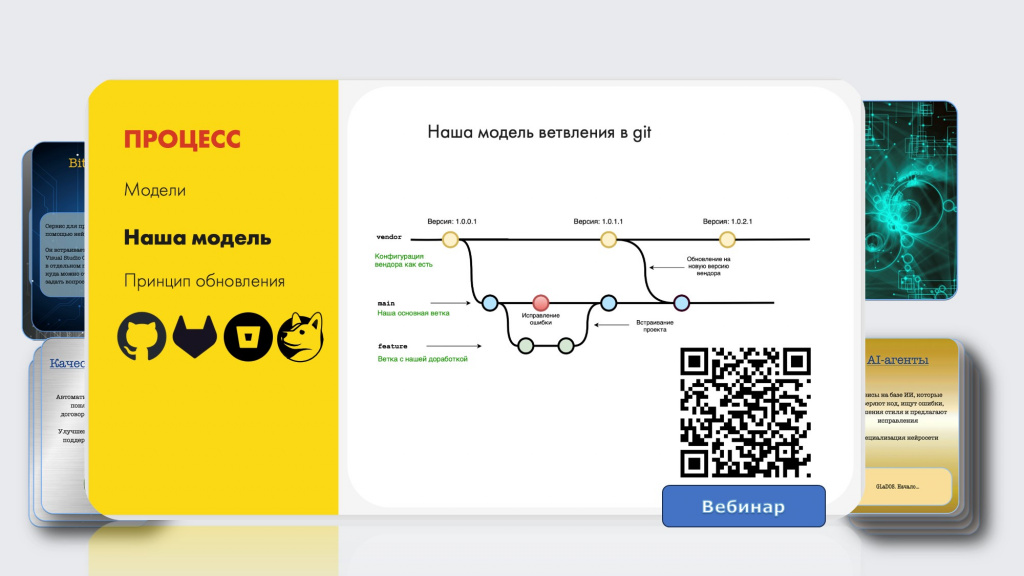
Если вы ничего такого не используете, то совсем недавно мы вместе с Матвеем Серегиным записали вебинар, где мы дорабатываем и обновляем конфигурацию, работая с Git.
Например, мы там рассказываем, как обновить типовую доработанную конфигурацию за 8 минут. Нам никто не верит, но это правда возможно. Посмотрите вебинар, там есть интересные моменты.

Вернемся к ИИ-инструментам, которые можно использовать, если у вас уже есть настроенный процесс CI/CD.
Первый инструмент – это Codacy, сервис для автоматического анализа и мониторинга качества кода, аналог SonarQube «на максималках», который отслеживает изменения в коде и анализирует их.
К сожалению, с 1С он пока не работает, зато работает с другими языками программирования. И я о нем говорю для общего понимания, что такие инструменты существуют, хотя и пока нам не подходят.

Второй инструмент – это CodeRabbit. Его уже довольно часто можно встретить в публичных репозиториях на GitHub – он позволяет встроиться непосредственно в процесс и выполнять код-ревью.
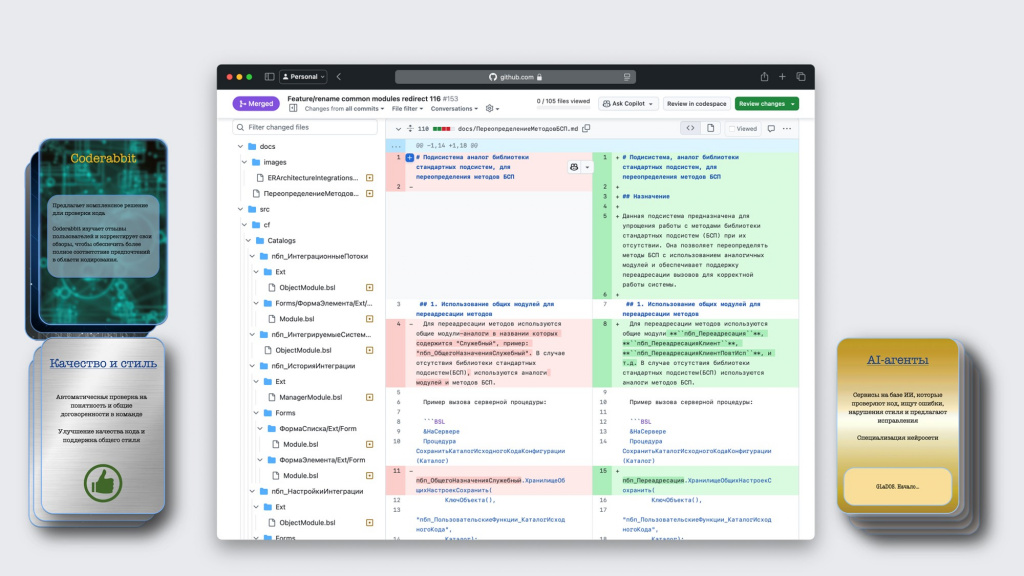
Это выглядит примерно так. Представьте, что у вас есть pull-реквест с изменениями на GitHub (или merge-реквест на GitLab).
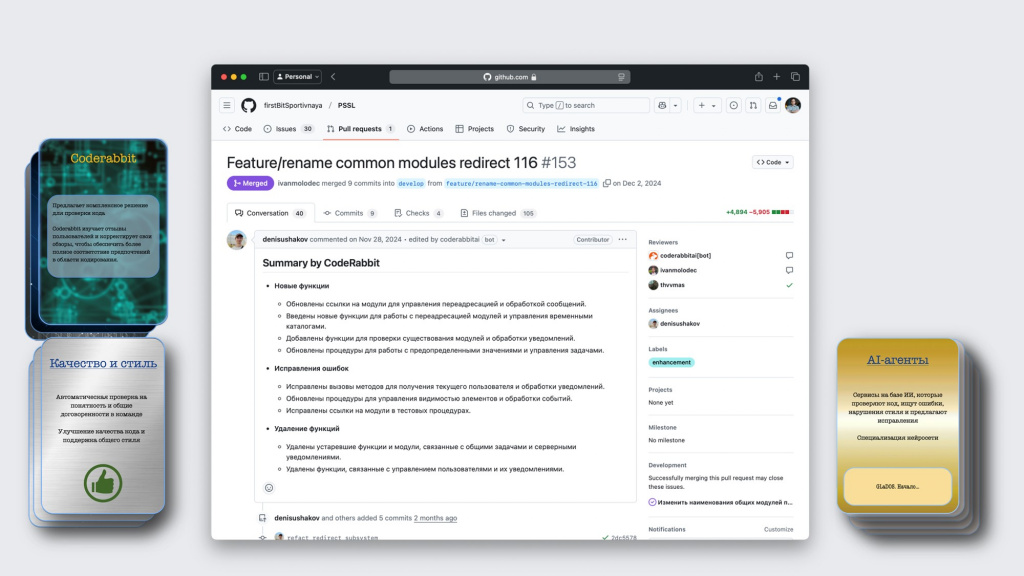
Первое, что делает CodeRabbit – это пишет сводку по всему пулл-реквесту: что было исправлено и каким образом. Это позволяет разработчику быстро погрузиться в контекст и разобраться в изменениях.
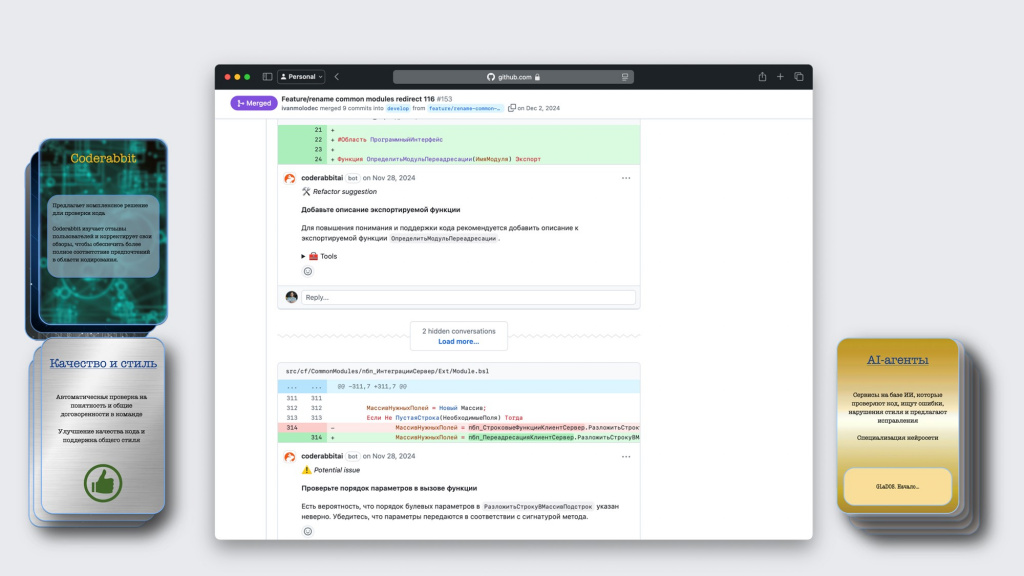
Кроме этого, CodeRabbit может оставлять замечания к конкретным строчкам кода.
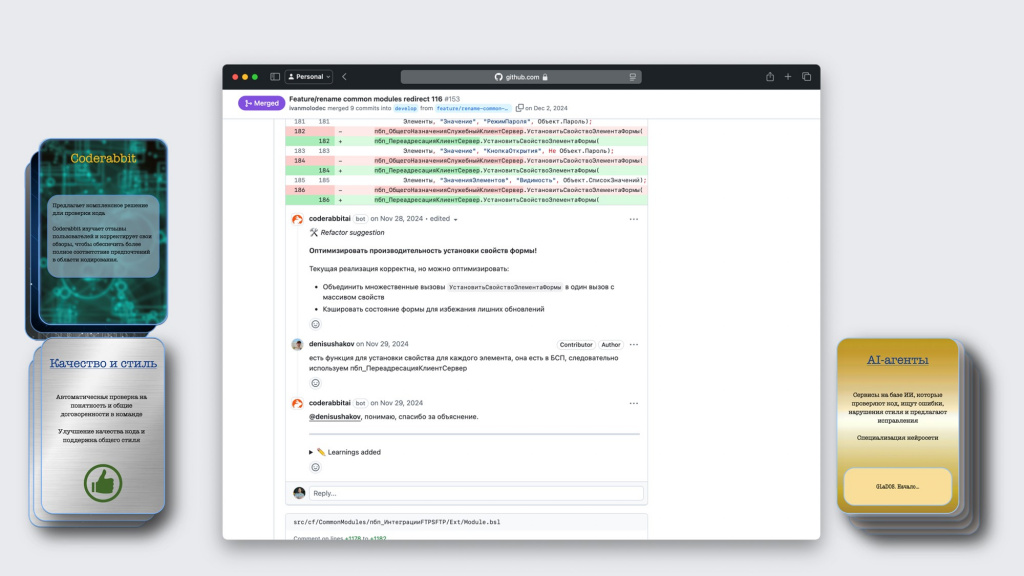
Потом в это обсуждение может подключиться обычный разработчик и обосновать свои решения – с некоторыми замечаниями не согласиться.
Если он не соглашается и говорит, что замечание неправильное, модель таким образом дообучается и в дальнейшем такие замечания выводить не должна.
Причем она обучается именно в рамках тех репозиториев вашей команды, к которым вы ее подключили – в этом ее преимущество.

Я рассказал о наиболее актуальных инструментах для проведения код-ревью с помощью ИИ есть в каждой области – Bito’s AI, CodeRabbit, DeepSeek.

Но это не все инструменты, которые существуют, их гораздо больше.
Пока я готовился к выступлению, появился DeepSeek, Qwen 2.5, Grok 3 от Илона Маска. Perplexity и так далее.
Новые интересные инструменты появляются каждый день.
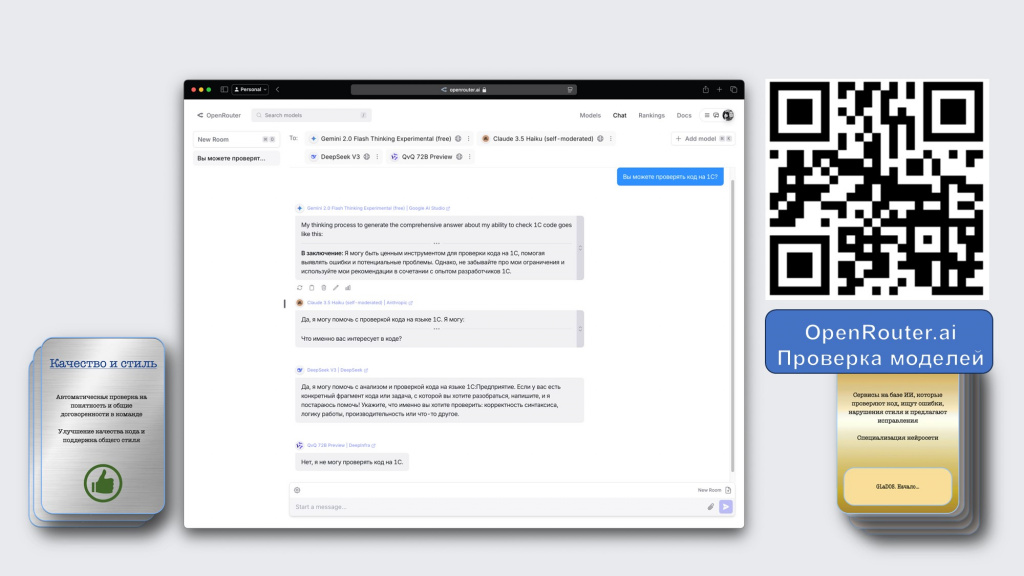
Следить, слава богу, за этим всем не нужно, потому что есть специальный сервис OpenRouter.ai, который собирает все эти платные и бесплатные инструменты, добавляя их себе.
Здесь можно выбрать несколько моделей и задать им всем одновременно какой-то вопрос – например, я здесь спросил: «Вы можете проверять код на 1С?»
А потом из этого можно выбрать.

В результате, для 1С сейчас наиболее актуальны два инструмента – DeepSeek сейчас самый нашумевший и CodeRabbit, если вы используете у себя CI/CD в репозитории GitLab, GitHub и т.д.
Основные минусы
Давайте чуть подробнее остановимся на том, какие вообще у использования нейросетей для код-ревью могут быть минусы.

Первое – это ограничение сложной логики. Хотя нейросеть и умеет находить логические и синтаксические ошибки, со сложной логикой она справляется не всегда. Поэтому как никогда становятся важны архитектурные навыки, глубокое понимание контекста, работа архитектора становится более важной и востребованной, поэтому развивайтесь в этом направлении. В этом случае вас точно не заменят нейросети.
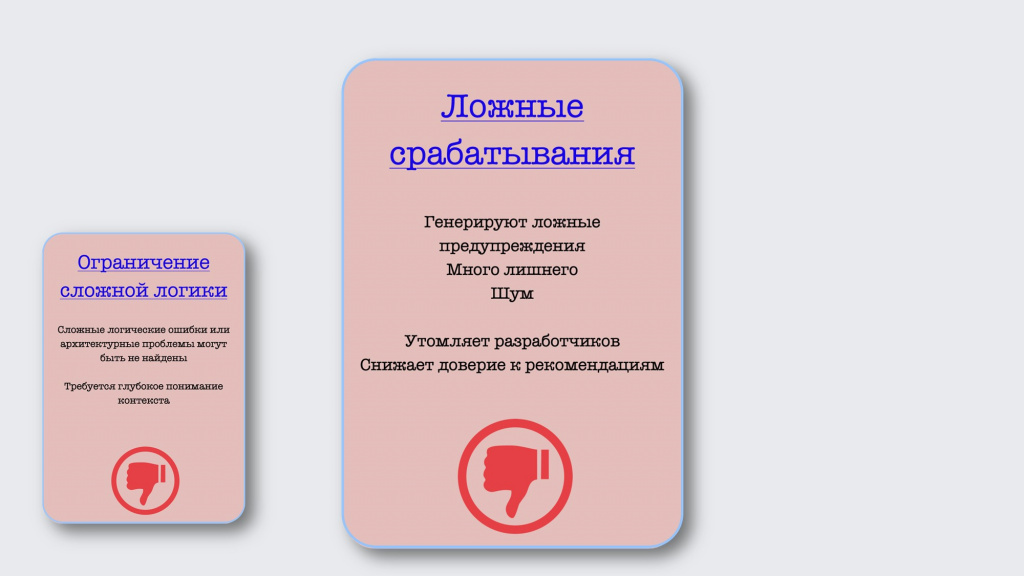
Еще один недостаток, с которым мы часто сталкиваемся и в других инструментах – это ложные срабатывания.
Бывает, что нейросеть нагенерирует настолько много замечаний, что их даже смотреть не хочется – неинтересно, много лишнего, воспринимается как шум. Это может утомлять и снижать мотивацию разработчиков.
Однако в отличие от других инструментов, у того же CodeRabbit здесь есть преимущество, потому что он потихоньку дообучается, и со временем количество нерелевантных замечаний будет уменьшаться.

Еще один минус – особенно актуальный для нашей отрасли – это то, что открытых данных на языке 1С для обучения нейросетей критически мало.

Если сравнить количество репозиториев на GitHub:
-
На языке 1С там 4000 репозиториев – это меньше 0,001% от всех.
-
А на Python и на Java – по 18 миллионов репозиториев.

Конечно, благодаря сообществу здесь есть подвижки.
Например, очень рекомендую агрегатор 1С-ных open-source проектов OpenYellow, где собраны все репозитории GitHub по 1С, у которых есть хотя бы одна звездочка.
Поэтому добавляйте свой 1С-ный код на GitHub. Это не только интересно, но и развивает сообщество – нам всем от этого будет лучше.
Типовых конфигураций для обучения, к сожалению, недостаточно – их уже проанализировали вдоль и поперек. Плюс там практически везде повторяется код из БСП, а нового кода появляется не так много.

Следующий минус – это безопасность. Когда мы отправляем данные на ревью, они уходят на внешние серверы. Куда и зачем – непонятно.
Можно встраивать модели нейросети у себя, но это тоже бывает дорого.
Поэтому ждем решение от вендора – возможно, это будет интереснее и лучше.

Отсюда же вытекает следующий минус – высокая стоимость.
Поэкспериментировать с ИИ-инструментами самому или для небольшой команды – не проблема, это хорошо и интересно. Но для больших команд это уже может быть сложнее, потому что там получаются совсем другие тарифы.
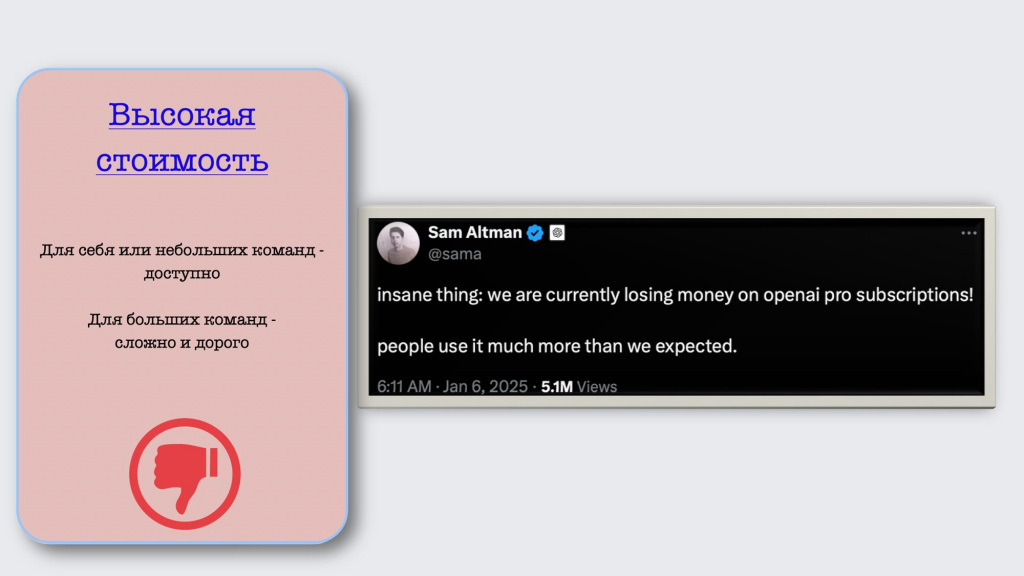
Кстати, в начале 2025 года Сэм Альтман, который отвечает за ChatGPT, заявил, что подписки OpenAI Pro не окупаются – пользователей так много, что нагрузка от них превышает доступные мощности.
Правда, вскоре после этого DeepSeek показал, что аналогичный результат можно получить и дешевле, поэтому надеюсь, что какие-то изменения будут и дальше.
Итого: для больших команд автоматизировать код-ревью с использованием нейросетей может быть сложно и дорого, но для себя можно попробовать вообще без проблем.

И еще один минус, довольно спорный – это возможное снижение компетенций.
Если полностью автоматизировать код-ревью и переложить этот процесс на искусственный интеллект, разработчики будут реже работать с кодом напрямую, сосредотачиваясь на более сложных задачах.
Со временем отсутствие глубокого и регулярного анализа может привести к тому, что качество собственного понимания кода у команды может снизиться, а навыки код-ревью – ослабнуть.

Вот такие минусы я для себя выделил, когда готовился. Возможно, у вас по этому поводу будут свои соображения – оставляйте их в комментариях.
Будущее ИИ в код-ревью
Какое же будущее у ИИ в код-ревью? Будущее постоянно меняется – мы ни за чем не успеваем.

Понятно, что нейросети будут развиваться.
Будут новые модели – точнее, эффективнее.
Будет меньше зависимости от промта. Я вообще изначально хотел добавить в доклад отдельный блок про то, как правильно составлять запросы для нейросети. Но сейчас нейросети сами пытаются анализировать, что вы хотели сказать – условно, первая нейросеть готовит расширенный промпт, обращается ко второй нейросети, и вторая уже выдает ответ.
Можно сказать, что нейросети породили профессию промпт-инженера, и сами же ее и убили – хотя и было много курсов, убеждающих, что нужно срочно получить эти знания, чтобы не отстать от жизни.
Следующий шаг в развитии – это интеграция с ИИ на каждом из этапов разработки.
AI-агенты будут использоваться не только для написания кода или код-ревью, но и для тестирования, для планирования, для выпуска релизов, измерений и так далее.
На каждом этапе будет свой инструмент – будет больше инструментов, и больше специализации.
И третий момент – это быстрая адаптация под код.
Уже сейчас появляются новые типы моделей с долгосрочной памятью. Например, недавно Google презентовали архитектуру нейросетей Titan, которая имеет долгосрочную память – может хранить у себя все оставленные ранее замечания и обращаться к ним.
Кроме этого, нейросеть будет больше персонализировать свои ответы под конкретных членов команды. Например, она запомнит, что Вася часто забывает проверки заполнения и будет обращать его внимание на это.
Или увидит, что Никита не учитывает в своих процессах проблемы с УСН и будет дополнительно это проверять в коде, постоянно дообучаясь на различных данных команды.
Технологии очень быстро меняются – пока я готовил презентацию, часть информации уже устарела. Завтра какие-то из упомянутых решений станут неактуальными, а вместо них появится что-то новое. Может быть по-разному.
Итоги

Надеюсь, теперь в вашу колоду карт с инструментами для код-ревью добавятся новые – вы познакомитесь с AI-агентами и начнете их применять.

Выберете для себя те плюсы, которые подходят именно вам – для кого-то это будет качество и стиль, для кого-то – быстрый ответ или еще что-то.

Но не забывайте и про минусы – учитывайте возможные риски и ограничения.
В любом случае, вы можете попробовать использовать эти инструменты для себя – это вас ни к чему не обязывает. В крупных компаниях с этим сложнее, но со временем, я думаю, мы к этому тоже придем.

Если хочется с чего-то начать, попробуйте DeepSeek – он сейчас самый продвинутый и доступный.
Причем, как правило, сами инструменты не так важны – гораздо важнее, как у вас выстроен процесс. А уже под него вы подберете нужные вам инструменты.

И не забывайте развиваться и духовно расти – иначе нам всем конец.
Software 3.0: будущее для процессов разработки
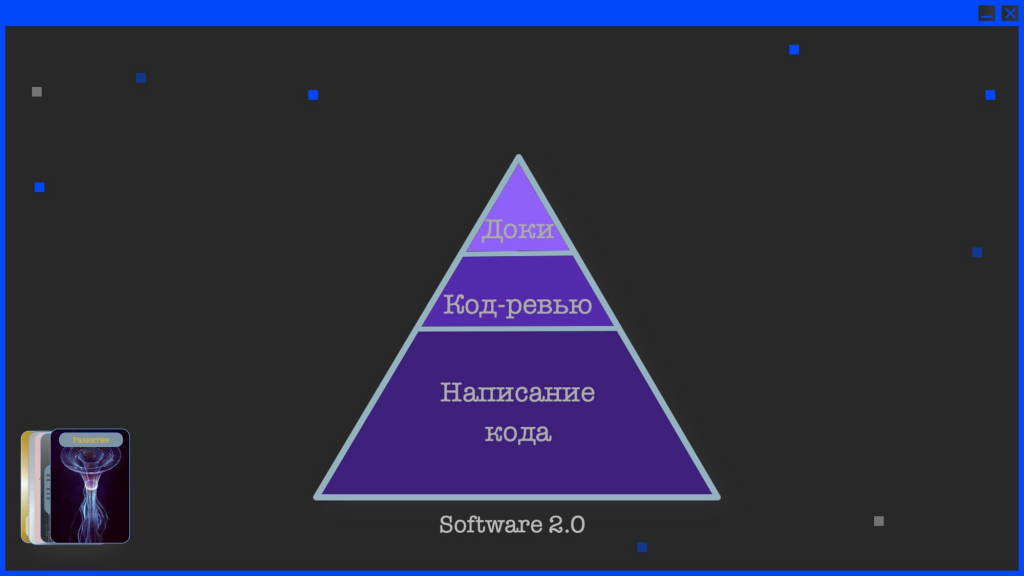
В завершение хочу упомянуть одно из последних исследований – там было показано, что процесс нашей разработки сейчас выглядит следующим образом:
-
мы пишем много кода;
-
потом чуть-чуть делаем код-ревью;
-
и очень мало пишем документации.
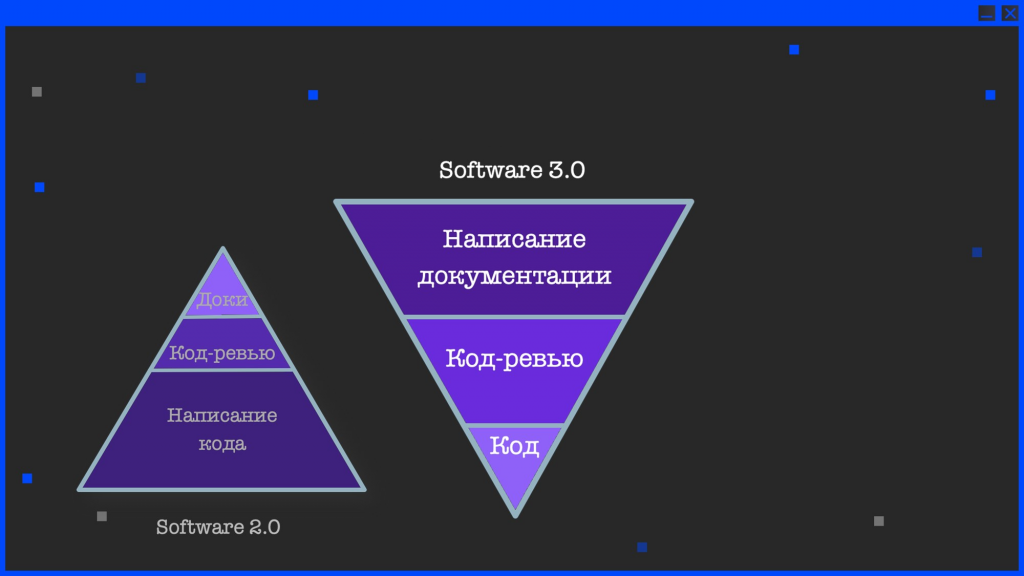
Однако уже в ближайшем будущем эта пирамида перевернется:
-
кода мы будем писать очень мало;
-
будем больше ревьюить код, который написала нейросеть;
-
а основное время в нашей отрасли будет занимать написание спецификаций – описания того, как программа должна работать, в какую сторону двигаться и так далее.
Вопросы и ответы
Какой размер контекстного окна у этих систем? Например, если у меня функция на 10 тысяч строк – как ее передать нейросети? Или когда решение само по себе большое, и нам нужно вызвать проверку актуальности заказа, которая находится в совсем другом месте через стек на 10 вызовов. Как это передать в контекст?
Все зависит от моделей. Текущие модели, не связанные с 1С, не знают, как у нас все устроено. Им с этим работать сложнее.
Но судя по тому, что обещает нам фирма «1С», возможно, часть из этих проблем будет решена. Понятно, что всю конфигурацию в памяти сохранить невозможно, код анализируется частично и на основании этого выдаются замечания.
Насколько большая величина этого окна, я, к сожалению, не знаю. У всех моделей по-разному. Нужно экспериментировать.
Код может быть написан красиво, читаемо. А как нейросеть понимает, насколько он производительный?
Я не знаю. Я сам, если посмотрю код, не уверен, что пойму, насколько он производительный. Возможно, в этом помогут какие-то другие инструменты – например, методики по производительности от фирмы «1С». Поэтому не знаю.
Но у текущих моделей нет настолько глубоких знаний по 1С, поэтому вряд ли они могут это понимать.
Я это к тому, что не будет ли нейросеть навязывать нам в исправлениях красивый код, который будет не очень производительным?
Возможно. Но в большинстве случае поддерживаемый и понятный код лучше, чем максимально производительный, написанный под конкретную задачу.
Конечно, в критичных случаях важнее высокая производительность, но если с кодом предстоит работать дальше, его читаемость и простота обычно в приоритете.
В любом случае ИИ – это всего лишь инструмент, а окончательное решение за разработчиками. Тимлид может посмотреть этот код и сказать, что нам здесь нужен более производительный, но менее красивый код. Решать все равно нам самим.
Код-ревью – это не только инструмент для проверки качества кода, но и важный инструмент для обмена знаниями в команде, выравнивания уровня и формирования хорошего стиля. Как не упустить этот аспект, переходя на использование ИИ?
Я вижу это так: мы можем использовать ИИ для первичного ревью своего кода. Мы прогоняем код через нейросеть и исправляем мелкие недочеты, чтобы коллега, проверяющий код, не тратил время на банальности вроде неправильно названных переменных или пропущенной точки с запятой. Но саму логику, архитектурные решения и общую согласованность кода все равно должен оценивать другой разработчик.
Любой код перед выпуском должен быть просмотрен кем-то еще – без этого никуда.
AI-агент, как и SonarQube, и другие статистические анализаторы кода, позволяет лишь упростить работу разработчика и автоматизировать рутинные проверки. Но ключевые аспекты, такие как чистота архитектуры, соответствие паттернам и общую логику все же стоит проверять отдельно.
Правильно ли я понимаю, что сейчас, пока фирма «1С» свое решение для EDT не представила, для 1С наиболее актуальны DeppSeek и CodeRabbit?
На текущий момент из того, что мне понравилось по личному опыту, для 1С наиболее актуальны DeepSeek и CodeRabbit.
-
CodeRabbit – потому что он легко встраивается в процесс и в принципе работает с 1С, с ним есть уже примеры интеграции на GitHub. Можно посмотреть, как это работает у коллег и хотя бы уже не в одиночку с этим разбираться.
-
А DeepSeek – потому что вроде он получше разбирается в коде. Говорят, что эта нейросеть придумана специально для разработчиков. Насколько это правда – не знаю.
Вопрос по CodeRabbit. Насколько я знаю, он работает не только в GitHub, но и в GitLab. Пробовали ли вы его в платной версии? У нас на GitLab бесплатная версия, но он там работает как-то грустно.
Не пробовал. Я попробовал по верхам все инструменты, в том числе, Amazon CodeGuru Reviewer и прочее.
Пример, который показывался в докладе – это репозиторий от «Первого Бита». Не знаю, что у них используется – платное оно или бесплатное.
Выглядело солидно, поэтому я его и вставил в презентацию. А сам глубже туда не лез пока что.
Я достаточно давно использую DeepSeek, но многие замечания, которые он выдает, слишком формальные. Есть ли у тебя промпт для настройки этих замечаний, а то я уже начал генерировать кучу страниц текста, чтобы сказать ему: «Здесь делай так, а здесь так и так»
У меня был опыт, что при анализе большого куска кода он начинал лениться и ничего практически не делал. Поэтому я разделял текст на небольшие кусочки, которые у меня, условно, вызывали подозрения, и скармливал их ему по-отдельности.
А что касается промпта, я обычно пишу: «Представь, что ты крутой тимлид. Сделай код-ревью этого кода, обрати внимание на это и на это». И каждый раз добавляю это в запрос. Но я все-таки рассчитываю, что в ближайшее время нужда в настройке промпта отпадет. А пока да, приходится тратить время, добавлять эти инструкции
Важно, что ты сам дообучаешь эту ветку, в которой ты ведешь с ним диалог.
И с большими текстами действительно есть проблема, потому что он ленится.
А большой объем текста – это сколько?
У каждой нейросети размер контекстного окна разный. Бывает, что если ему передать несколько функций на два экрана, он уже начинает тупить – какую-то одну проверит, а дальше не проверяет.
Лучше бить по экрану?
Лучше бить по функциям.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TEAMLEAD & CIO EVENT 2025.

Вступайте в нашу телеграмм-группу Инфостарт