




















- Проблема
- Эмуляция проблемы
- Разбор индексов и планов
- «Исправление» итогов
- Проблема решена?
- Заключение
В рамках данной статьи рассмотрим пример почему обновление итогов может занимать много времени, как на это могут влиять рассчитанные итоги и доработаем планировщик для улучшения производительности 1С. Уровень статьи экспертный, но, думаю, каждый найдет для себя здесь информацию, которая может пригодиться в работе. Начнем статью, как обычно, с описания проблемы.
Проблема
В техническую поддержку «Тантор Лабс» клиент обратился с проблемой: при миграции с MS SQL на СУБД Tantor Special Edition 1C (из семейства СУБД Tantor Postgres) закрытие месяца в 1C:ERP стало выполняться дольше. К заявке были прикреплены логи, в которых после анализа выделялся следующий запрос:
Query Text: UPDATE _AccumRgT68428 SET _Fld68403 = _AccumRgT68428._Fld68403 + T2._Fld68403, _Fld68404 = _AccumRgT68428._Fld68404 + T2._Fld68404, _Fld68405 = _AccumRgT68428._Fld68405 + T2._Fld68405, _Fld68406 = _AccumRgT68428._Fld68406 + T2._Fld68406, _Fld68407 = _AccumRgT68428._Fld68407 + T2._Fld68407, _Fld68408 = _AccumRgT68428._Fld68408 + T2._Fld68408, _Fld68409 = _AccumRgT68428._Fld68409 + T2._Fld68409, _Fld68410 = _AccumRgT68428._Fld68410 + T2._Fld68410, _Fld68411 = _AccumRgT68428._Fld68411 + T2._Fld68411, _Fld68412 = _AccumRgT68428._Fld68412 + T2._Fld68412, _Fld68413 = _AccumRgT68428._Fld68413 + T2._Fld68413, _Fld68414 = _AccumRgT68428._Fld68414 + T2._Fld68414, _Fld68415 = _AccumRgT68428._Fld68415 + T2._Fld68415, _Fld68416 = _AccumRgT68428._Fld68416 + T2._Fld68416, _Fld68417 = _AccumRgT68428._Fld68417 + T2._Fld68417
FROM pg_temp.tt120 T2
WHERE (T2._Period = _AccumRgT68428._Period AND T2._Fld68396RRef = _AccumRgT68428._Fld68396RRef AND T2._Fld68397RRef = _AccumRgT68428._Fld68397RRef AND T2._Fld68398RRef = _AccumRgT68428._Fld68398RRef AND T2._Fld68399_TYPE = _AccumRgT68428._Fld68399_TYPE AND T2._Fld68399_RTRef = _AccumRgT68428._Fld68399_RTRef AND T2._Fld68399_RRRef = _AccumRgT68428._Fld68399_RRRef AND T2._Fld68400_TYPE = _AccumRgT68428._Fld68400_TYPE AND T2._Fld68400_RTRef = _AccumRgT68428._Fld68400_RTRef AND T2._Fld68400_RRRef = _AccumRgT68428._Fld68400_RRRef AND T2._Fld68401_TYPE = _AccumRgT68428._Fld68401_TYPE AND T2._Fld68401_RTRef = _AccumRgT68428._Fld68401_RTRef AND T2._Fld68401_RRRef = _AccumRgT68428._Fld68401_RRRef AND T2._Fld68402RRef = _AccumRgT68428._Fld68402RRef AND T2._Fld2931 = _AccumRgT68428._Fld2931 AND T2._Fld2931 = _AccumRgT68428._Fld2931 AND _AccumRgT68428._Splitter = CAST(0 AS NUMERIC)) AND ((_AccumRgT68428._Fld2931 = CAST(0 AS NUMERIC)))
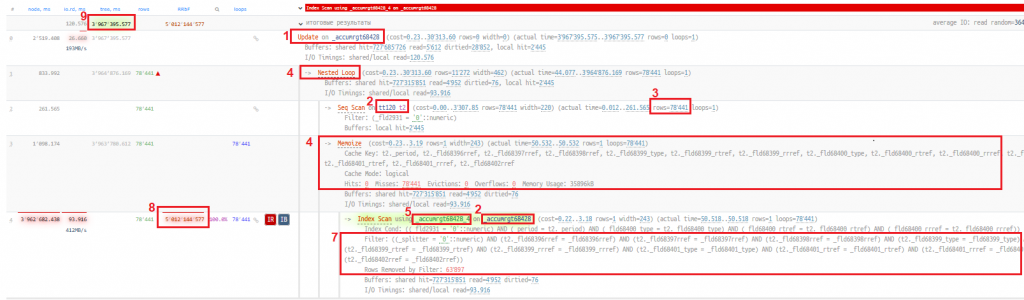
Со следующим планом запроса:
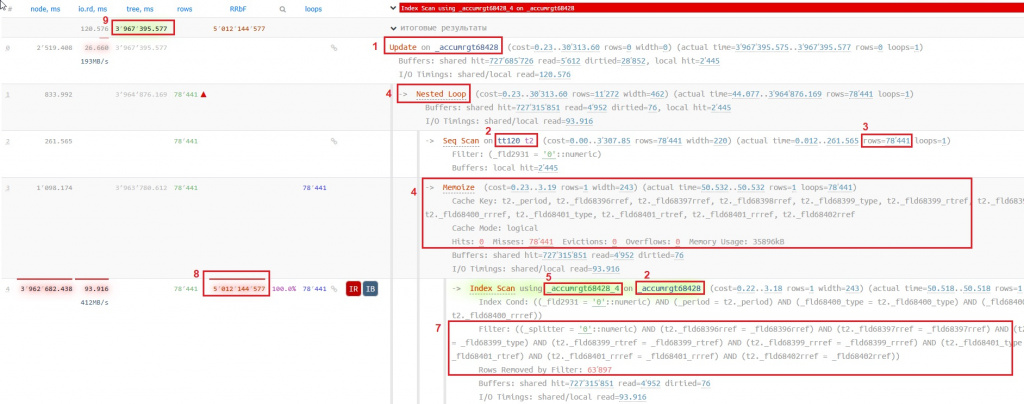
Что можно сказать об этом запросе и его плане:
- Идет запись в таблицу итогов регистра накопления.
- Идет соединение двух таблиц: временной таблицы
tt120и таблицы итогов_AccumRgT68428(в тексте запроса нет явной конструкцииJOIN, потому что так позволяет "писать соединение" синтаксис psql при операцииUPDATE). - Во временной таблице 78 441 запись.
- Планировщик выбирает вариант соединения
Nested loops, т.е. для временной таблицы поиск в таблице итогов будет выполнен 78441 раз. Почему выбираетNested loops, а неHash join? Поиск в таблице_AccumRgT68428идет через индекс, и планировщик кеширует результат каждого поиска в индексе через операторMemoize, ожидая, что это может быть эффективно, но, как видим по плану запроса, поиск в хеш-таблице был неэффективен (Hits: 0 Misses: 78441), т.е. по ключу поиска (полеCache Key) в хеш-таблице не было найдено ничего, т.к. все строки временной таблицыtt120были уникальными по полям из спискаCache Key. Также таблицы соединяются по 14 полям, что делает операциюHash joinболее дорогой в подготовке. - Для поиска в таблице итогов выбирается некластерный индекс
_AccumRgT68428_4, который не содержит всех полей, по которым идет соединение, и не является покрывающим для данного условия соединения. - Покрывающим индексом для данного запроса всегда будет только кластерный
индекс_AccumRgT68428_1, который содержит все поля, по которым идет соединение. - В результате выбора неоптимального индекса происходит фильтрация по полям соединения, которая в плане запроса выделена в условие Filter при скане индекса
_AccumRgT68428_4и в результате каждой итерации поиска по этому индексу фильтром отбрасывается 63897 строк. - 78 441 циклов поиска умножаем на 63 897 фильтруемых строк, получаем 5 012 144 577 строк, которые СУБД Tantor нужно отфильтровать при выполнении этого запроса.
- Вследствие большого количества фильтруемых строк в предыдущем пункте запрос выполняется 66 минут.
Но почему СУБД Tantor решает выбрать не кластерный индекс, а другой? Например, в MS SQL всегда выбирается кластерный, более селективный под такие условия. Там не приходилось даже задумываться о такой проблеме.
Первое, что я подумал: возможно, при создании базы создались не все индексы, но как такое может произойти? Я сталкивался с такой ситуацией при создании базы из дампа утилитой pg_restore. Создание базы состоит из 3х последовательных действий:
- Создается схема базы данных.
- Таблицы заполняются данными.
- После заполнения каждой таблицы по ней идет создание индексов.
При создании индексов важен параметр maintenance_work_mem, который по дефолту равен 64 Мб. Если памяти, установленной в параметре maintenance_work_mem, не хватает для создания индекса, то создаются временные файлы на диске. Логично, что самые большие индексы будут создаваться в конце операции pg_restore, поскольку самые большие таблицы дольше заполняются данными. Если создание индекса завершится ошибкой, то создаваемая база 1С все равно будет работоспособна, ведь отсутствие индекса не является каким-то блоком для ее работы. Создание индекса может завершиться ошибкой, если в какой-то момент, допустим, закончилось место на диске или кто-то рестартнул службу PostgreSQL. Тогда пользователь, зайдя в базу, увидит, что все данные загрузились, но некоторые индексы по факту могут и не создаться.
Последовательность действий при создании базы загрузкой из DT такая же.
Я попросил клиента выполнить запрос, чтобы проверить, существует ли кластерный индекс на таблице _AccumRgT68428. Оказалось, что он существует – значит, проблема в чем-то ином.
Чтобы разобраться в причинах, я попытался с эмулировать проблему на своем стенде.
Эмуляция проблемы

Воспроизвести проблему удалось довольно легко, и как станет ясно чуть позже, мне просто повезло. У меня есть база ERP для нагрузочного тестирования, я провел в ней случайный документ "Приобретение товаров и услуг", и в логе СУБД был запрос с такой же проблемой:
Query text: UPDATE _AccumRgT48209 SET _Fld48202 = _AccumRgT48209._Fld48202 + T2._Fld48202, _Fld48203 = _AccumRgT48209._Fld48203 + T2._Fld48203, _Fld104498 = _AccumRgT48209._Fld104498 + T2._Fld104498, _Fld104499 = _AccumRgT48209._Fld104499 + T2._Fld104499
FROM pg_temp.tt86 T2
WHERE (T2._Period = _AccumRgT48209._Period AND T2._Fld48197_TYPE = _AccumRgT48209._Fld48197_TYPE AND T2._Fld48197_RTRef = _AccumRgT48209._Fld48197_RTRef AND T2._Fld48197_RRRef = _AccumRgT48209._Fld48197_RRRef AND T2._Fld48198RRef = _AccumRgT48209._Fld48198RRef AND T2._Fld48199RRef = _AccumRgT48209._Fld48199RRef AND T2._Fld48200 = _AccumRgT48209._Fld48200 AND T2._Fld48201RRef = _AccumRgT48209._Fld48201RRef AND T2._Fld2488 = _AccumRgT48209._Fld2488 AND T2._Fld2488 = _AccumRgT48209._Fld2488) AND ((_AccumRgT48209._Fld2488 = CAST(0 AS NUMERIC)))
Его план:
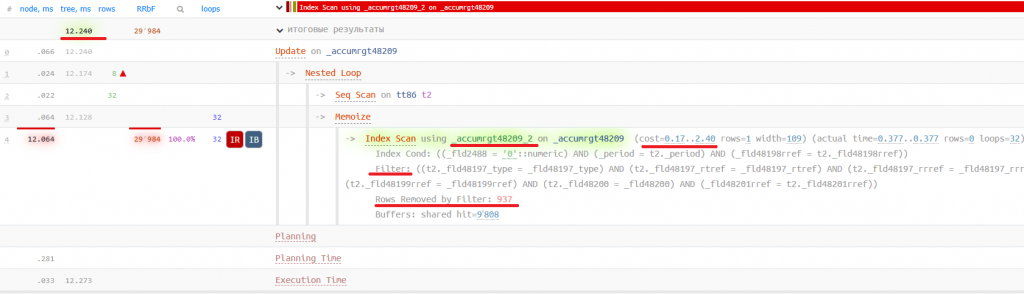
Запрос, конечно же, выполняется не 70 минут, а всего 12 мс, но главное, что он содержит ту же проблему: выбирает некластерный индекс _accumrgt48209_2.
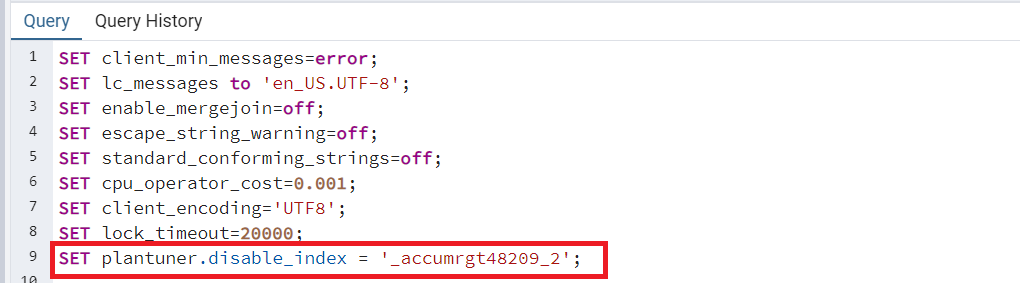
Чтобы разобраться, почему планировщик решает выбрать именно его, заставим СУБД выбрать нужный нам кластерный индекс. Для этого можно удалить индекс _accumrgt48209_2, чтобы планировщик не мог его использовать, или воспользоваться расширением plantuner. У него есть GUC "disable_index", позволяющий запретить планировщику использование определенных индексов (GUC'ом в мире Postgres называется любой параметр, который можно установить в файлах настроек postgresql.conf, postgresql.auto.conf).
Отключаем планировщику возможность использования индекса _accumrgt48209_2 – при выполнении через PgAdmin это будет выглядеть так:
Получаем план:
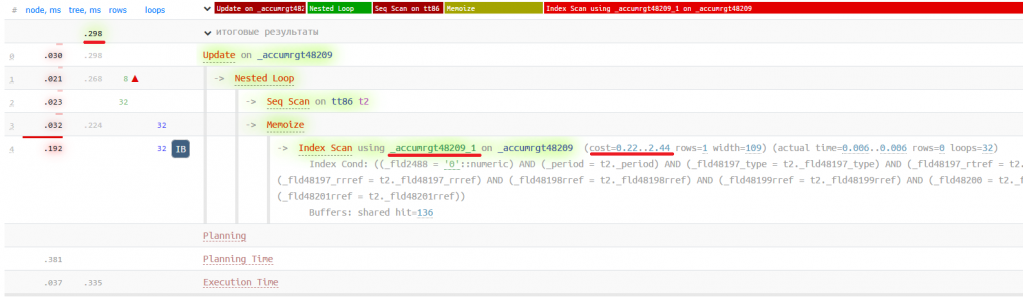
Теперь планировщик выбирает наиболее покрывающий под данный запрос индекс – accumrgt48209_1, и запрос выполняется быстрее в 40 раз! Казалось бы, 40 раз – это много, но по факту разница составляет всего 12 мс, и на большинстве продуктивных баз она не будет особо заметна для пользователя. Однако для высоконагруженных баз это может быть очень заметно. В статье «Как мы загружаем данные в "Центр управления кассами Магнита"» рассмотрен кейс высоконагруженной системы, в которой в среднем за час создавался 1 млн документов, которые делали движения в регистры накопления (и это было 4 года назад, сейчас уже значительно больше). Представим, что документы создаются в 20 потоков, и вычислим, сколько времени нужно на создание и проведение одного документа: 3 600 / (1 000 000 / 20) = 0, 072 с или 72 мс. Если к полученным 72 мс добавить еще 12 мс, то получится, что документ будет создаваться и проводиться на 15% дольше. Для высоконагруженных систем разница слишком велика!
Но вернемся к индексам.
Разбор индексов и планов

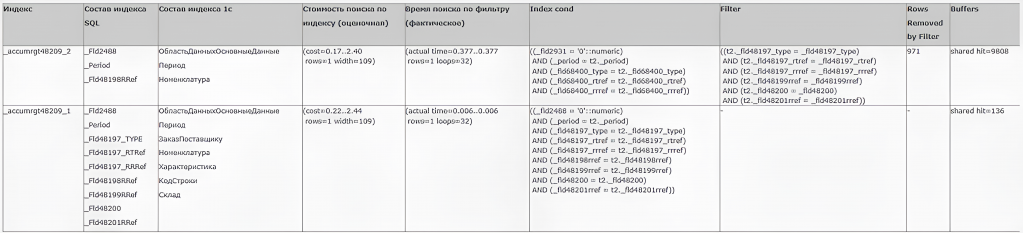
Чтобы понять, почему планировщик выбирает не тот индекс, давайте рассмотрим эти индексы и полученные планы запросов. Для начала имеем вот такую таблицу:
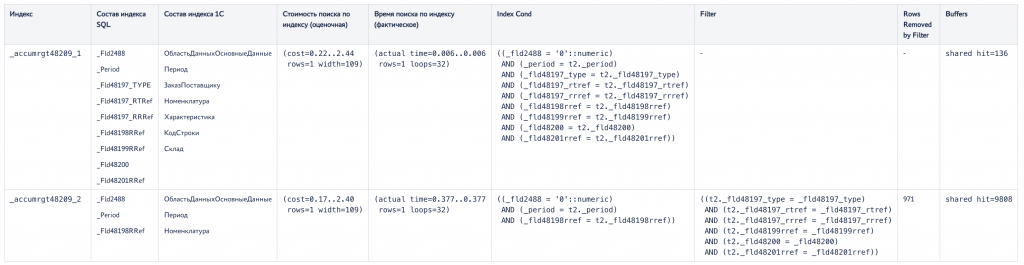
Эти индексы относятся к таблице РегистрНакопления.ЗаказыПоставщикам.Итоги.
При выборе индекса _accumrgt48209_2 фильтр накладывается по полям, которые не входят в индекс, следовательно, необходимо дополнительно читать записи таблицы и накладывать эти фильтры на них (количество строк, удаленных фильтром за один поиск по индексу – 971). Это и приводит к тому, что один такой поиск по индексу выполняется 0.377 мс против 0.006 мс по индексу _accumrgt48209_1. По значению в поле Buffers также видим, что при выборе индекса _accumrgt48209_2 приходится прочитать почти в 100 раз больше страниц. Очевидно, что выбирать индекс _accumrgt48209_2 невыгодно, но почему планировщик это делает?
Чтобы ответить на этот вопрос, давайте рассмотрим алгоритм выбора планировщиком лучшего индекса. Используемые термины:
Path— это путь выполнения запроса, который использует, например, индекс для получения данных. При выборе оптимального плана планировщик генерирует ряд возможных стратегий (путей) выполнения, включая последовательное сканирование (Sequential Scan Path), поиск по индексу (Index Scan Path) и другие методы доступа. Например, "Index Scan using _accumrgt48209_2 on _accumrgt48209" – это путь доступа к данным таблицы_accumrgt48209через поиск по индексу_accumrgt48209_2. Далее для обозначения этого термина мы в статье будем использовать понятие "путь индекса".Startup Cost– стоимость подготовки к выполнению узла плана запроса. Например, в "(cost=0.17..2.40 rows=1 width=109)" это 0.17;Total Cost– полная стоимость выполнения узла. Например, в "(cost=0.17..2.40 rows=1 width=109)" это 2.40.
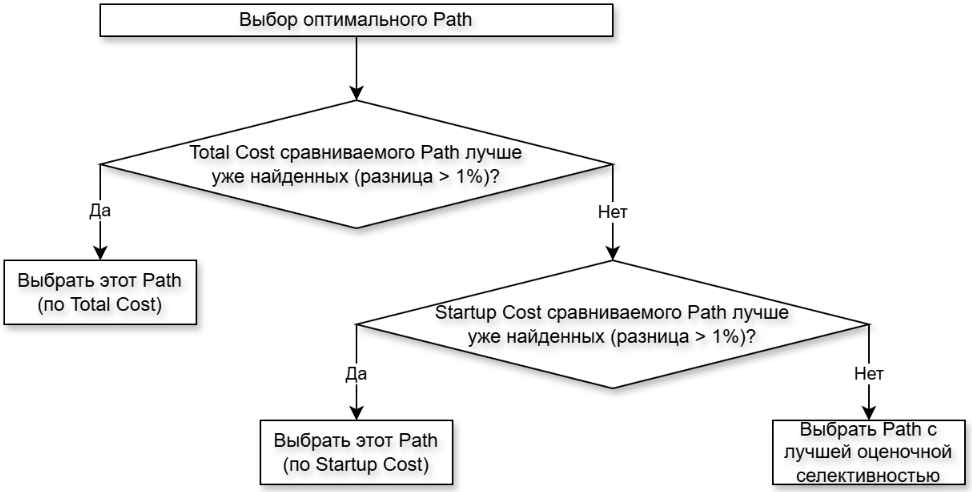
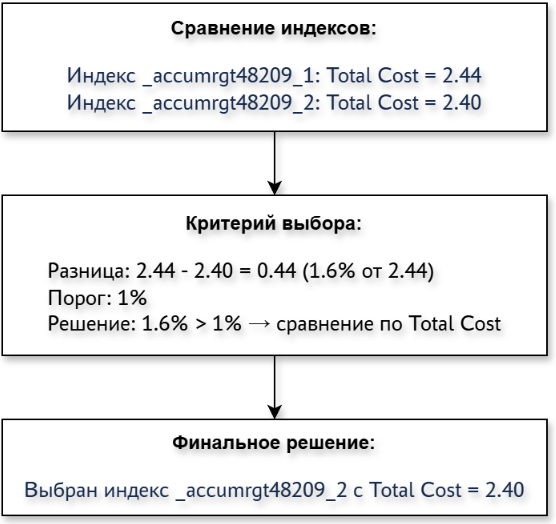
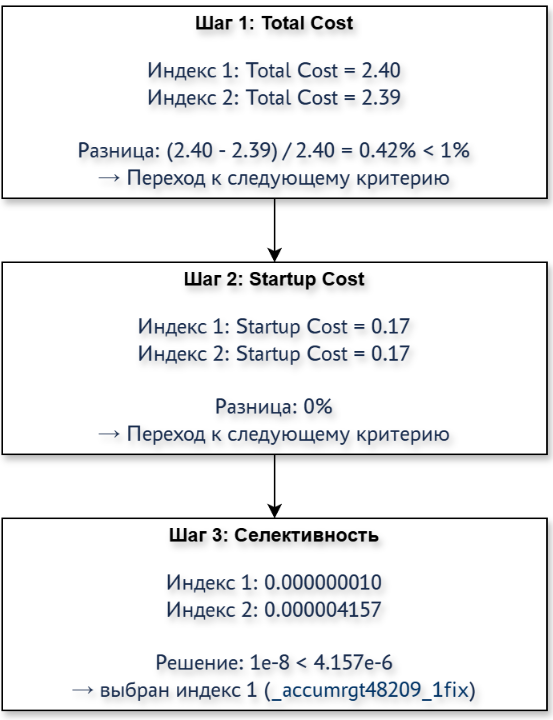
Чтобы определить лучший путь индекса, планировщик перебирает все возможные пути по следующей логике:
- Сравниваются
Total Costс учетом погрешности в 1%: если сравниваемый путь индекса поTotal Costлучше уже найденных, то выбирается он; - Если
Total Costсравниваемых путей индексов не отличается более чем на 1%, то сравниваютсяStartup Cost: если сравниваемый путь по Startup Cost лучше уже найденных, то выбирается этот путь; - Если
Startup Costсравниваемых путей индексов не отличается более чем на 1%, то сравнивается оценочная селективность: если сравниваемый путь по оценочной селективности лучше уже найденных, то выбирается этот путь.
Можно представить данную логику в виде несложной диаграммы:
В нашем случае планировщик выбирает индекс _accumrgt48209_2, потому что согласно п.1 описанной логики его Total Cost лучше, чем у индекса _accumrgt48209_1 с учетом порога в 1%:
Давайте разберемся, как Total Cost вычисляется планировщиком. Выяснить это через чтение плана запроса нельзя, поэтому обратимся к документации. Согласно ей, формула вычисления Total Cost выглядит так:
*indexTotalCost = seq_page_cost * numIndexPages + (cpu_index_tuple_cost + index_qual_cost.per_tuple) * numIndexTuples;
Давайте разберем переменные этой формулы:
seq_page_cost –стоимость последовательного чтения одной страницы с диска. Данный параметр задается на уровне всего инстанса, и его значение установлено в 1.cpu_index_tuple_cost–стоимость обработки одной записи индекса при сканировании индекса. Данный параметр также задается на уровне всего инстанса, и его значение установлено в 0.005.numIndexTuples –количество кортежей (строк таблицы), на которые ссылается индекс.numIndexPages –количество страниц, необходимых для хранения индекса.index_qual_cost.per_tuple–стоимость, связанная с обработкой условий квалификации для каждого кортежа в индексе. Это значение обычно зависит от конкретного запроса и структуры данных.
Первые три параметра не помогут выяснить, в чем причина: первые два являются константами, а третий параметр numIndexTuples также будет одинаков для обоих проверяемых путей индексов, поскольку b-tree индексы одной таблицы ссылаются на одинаковое количество записей. Остаются параметры numIndexPages и index_qual_cost.per_tuple. Вычислить параметр index_qual_cost.per_tuple для каждого рассматриваемого пути индекса можно только через отладчик исходного кода при исполнении запроса планировщиком. Сейчас мы делать этого не будем, но отметим, что с большой вероятностью для каждого рассматриваемого пути индекса он будет индивидуальным. В общем, пока этим параметром пренебрежем.
Остается параметр numIndexPages. Получается, что это он влияет на Total cost, т.к. все другие переменные формулы мы исключили. На данном этапе расследования можно сделать вывод, что планировщик выберет тот индекс, для которого нужно прочитать меньшее число индексных страниц, а поскольку у индекса _accumrgt48209_2 более "узкий ключ" (т.е. меньше полей в индексе), то на одну страницу помещается больше индексных строк, а значит, прочитать страниц нужно меньше. Отсюда получается довольно неприятный вывод, что планировщик не учитывает, сколько строк ему в результате чтения такого индекса придется откинуть через Filter, для него главное, что на этапе планирования он предполагает, что количество страниц индекса придется читать меньше!
Вычислить количество страниц каждого индекса можно следующим запросом:
erp_v=# SELECT relname, relpages, reltuples FROM pg_class where relname in ('_accumrgt48209_1', '_accumrgt48209_2');
relname | relpages | reltuples
------------------+----------+--------------
_accumrgt48209_1 | 17381 | 1.150079e+06
_accumrgt48209_2 | 8302 | 1.150079e+06
Мы получили цифры, но что с ними делать? Да, очевидно, что в кластерном индексе страниц будет больше, потому что там и полей больше. Можно попытаться оценить количество различных значений в каждом поле индекса, чтобы понять, какое из полей содержит больше всего различных значений, ведь чем больше различных значений в поле, тем больше места потребуется для их хранения. Для этого выберем количество различных значений (поле 'n_distinct') по каждому полю из статистики таблицы (таблица pg_stats):
erp_v=# SELECT attname, n_distinct
FROM pg_stats
WHERE schemaname = 'public' AND tablename = '_accumrgt48209';
attname | n_distinct
-----------------+------------
_period | 19112
_fld48197_type | 1
_fld48197_rtref | 2
_fld48197_rrref | 3930
_fld48198rref | 2731
_fld48199rref | 1
_fld48200 | 240
_fld48201rref | 15
_fld48202 | 737
_fld48203 | 630
_fld104498 | 1
_fld104499 | 1
_fld2488 | 1
Бросается в глаза 19 тысяч различных значений по полю "Период", ведь правда? Но количество различных значений в статистике может не совпадать с фактическим количеством различных значений в таблице, потому что при расчете статистики анализируется не вся таблица, а только ее часть (300 * default_statistics_target страниц).
Выберем фактическое количество различных значений поля "Период":
erp_v=# SELECT COUNT(DISTINCT _period) FROM _accumrgt48209;
count
-------
24028
Но это таблица итогов регистра накопления, и различных периодов в ней за год должно быть 12. За сколько же лет хранятся итоги? Делим 24028 на 12 и получаем 2002 года! Выглядит как некорректно введенные данные. Открываем 1С и видим: действительно, при вводе начальных остатков несколько документов были введены с ошибочными датами. С точки зрения пользователя все выглядело хорошо, потому что итоги получаются корректными, а то, что они считаются со времен императора Тиберия, пользователи могут и не знать:

Давайте удалим все периоды до 2020 года и посмотрим, как изменится план нашего запроса обновления итогов.
«Исправление» итогов

От теории к практике: создадим копию таблицы _accumrgt48209 путем копирования данных, но только данные перельем начиная с 2020 года. Сделать это проще всего через PgAdmin. Находим нашу таблицу в схеме public, нажимаем правую кнопку и вызываем команду скрипта создания таблицы. Таким образом мы получим готовый скрипт создания структуры нашей таблицы со всеми индексами:
Назовем создаваемую таблицу _accumrgt48209fix и наполним ее данными с помощью скрипта:
INSERT INTO public._accumrgt48209fix
(_period, _fld48197_type, _fld48197_rtref,_fld48197_rrref, _fld48198rref,_fld48199rref, _fld48200, _fld48201rref, _fld48202, _fld48203,_fld104498, _fld104499, _fld2488)
SELECT _period, _fld48197_type, _fld48197_rtref, _fld48197_rrref, _fld48198rref, _fld48199rref, _fld48200, _fld48201rref, _fld48202, _fld48203, _fld104498, _fld104499, _fld2488
FROM public._accumrgt48209 where _period > '2020-01-01 00:00:00';
Обновляем статистику по таблице:
analyze _accumrgt48209fix;
А вот как изменилось количество страниц индексов...
erp_v=# SELECT relname, relpages, reltuples FROM pg_class where relname in ('_accumrgt48209_1fix', '_accumrgt48209_2fix');
relname | relpages | reltuples
---------------------+----------+-----------
_accumrgt48209_1fix | 6509 | 329577
_accumrgt48209_2fix | 3133 | 329577
... и количество различных периодов:
erp_v=# SELECT COUNT(DISTINCT _period) FROM _accumrgt48209fix;
count
-------
51
Теперь вновь выполняем запрос обновления таблицы итогов и получаем план:
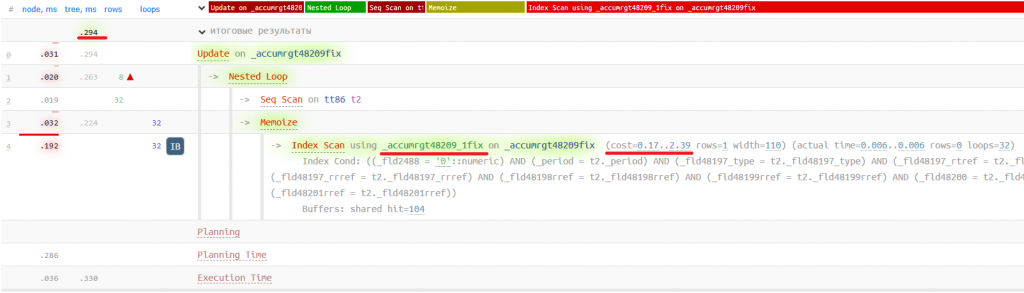
Видим, что теперь, как положено, выбирается правильный кластерный индекс, то есть, дело было в «кривых» данных (поэтому в самом начале статьи я написал, что сэмулировать проблему на своей базе мне повезло).
Запретим наш кластерный индекс _accumrgt48209_1fix с помощью plantuner.disable_index и посмотрим, какой индекс будет выбран:
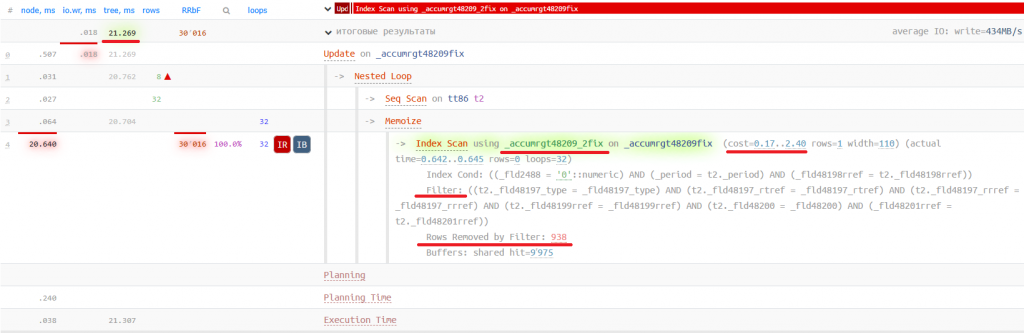
Startup cost обоих индексов одинакова: 0.17, а Total cost меньше у кластерного индекса: 2.39 против 2.40. Разница составляет менее процента, значит, индекс выбирается по упомянутой выше формуле за счет лучшей селективности.
Давайте посчитаем селективность каждого индекса. Формула расчета:

1. Для каждого поля индекса берем значение количества различных (поле n_distinct) из данных статистики (таблица pg_stats) и делим единицу на это значение, получая селективность каждого поля:
| Поле | n_distinct | Селективность |
| _Fld2488 | 1 | 1 |
| _Period | 51 | 0,0196 |
| _Fld48197_TYPE | 1 | 1 |
| _Fld48197_RTRef | 2 | 0,5 |
| _Fld48197_RRRef | 7704 | 1,298e-4 |
| _Fld48198RRef | 4713 | 2,121e-4 |
| _Fld48199RRef | 1 | 1 |
| _Fld48200 | 352 | 0,0028 |
| _Fld48201RRef | 17 | 0,0588 |
2. Чтобы вычислить селективность всех полей индекса, необходимо перемножить селективность каждого поля друг на друга. Для индекса _accumrgt48209_2fix перемножаем селективность его полей (_Fld2488, _Period, _Fld48198RRef) и получаем число 4,157e-6, а для индекса _accumrgt48209_1fix нужно перемножить все селективности из таблицы выше, но можно этого не делать, поскольку очевидно, что там выйдет число намного меньше чем 1e-8. Мы вычислили селективность каждого индекса.
3. Далее, чтобы понять сколько строк вернет использование каждого из индексов, нужно умножить полученные числа на количество строк в таблице:
_accumrgt48209_1fix = 329577 * 1e-8 = 0.003 = 1 (планировщик всегда округляет до ближайшего целого в большую сторону)
_accumrgt48209_2fix = 329577 * 4,157e-6 = 1.37 = 2
По индексу _accumrgt48209_1fix будет возвращено меньшее количество строк (1 против 2), т.е. селективность лучше, поэтому планировщик его и выбирает.
Можно сделать вывод, что некорректные данные в таблице итогов могут быть проблемой как для СУБД Tantor, так и для других форков PostgreSQL.
Напишем скрипт, который выведет все потенциально проблемные таблицы. Если количество различных периодов в таблице согласно статистики превышает 300 (25 лет), то считаем такую таблицу проблемной:
DO $$
DECLARE
rec RECORD;
period_values RECORD;
results RECORD;
BEGIN
CREATE TEMP TABLE temp_results (table_name TEXT, min_period TIMESTAMP, max_period TIMESTAMP);
FOR rec IN
SELECT tablename
FROM pg_stats
WHERE attname = '_period' AND tablename LIKE '_accumrgt%' AND n_distinct > 300
LOOP
EXECUTE format('
SELECT MIN(_period) AS min_period, MAX(_period) AS max_period
FROM %I
WHERE _period <> ''3999-11-01 00:00:00''', rec.tablename) INTO period_values;
INSERT INTO temp_results (table_name, min_period, max_period)
VALUES (rec.tablename, period_values.min_period, period_values.max_period);
END LOOP;
END $$;
SELECT * FROM temp_results;
Получаем следующий список проблемных таблиц:
table_name | min_period | max_period
-----------------+---------------------+---------------------
_accumrgt111724 | 0021-02-01 00:00:00 | 2024-03-01 00:00:00
_accumrgt48209 | 0022-01-01 00:00:00 | 2024-03-01 00:00:00
_accumrgt48318 | 0021-11-01 00:00:00 | 2024-03-01 00:00:00
_accumrgt50376 | 0001-02-01 00:00:00 | 2024-03-01 00:00:00
_accumrgt50412 | 0022-01-01 00:00:00 | 2024-03-01 00:00:00
_accumrgt50494 | 0001-02-01 00:00:00 | 2024-03-01 00:00:00
_accumrgt50514 | 0022-01-01 00:00:00 | 2024-03-01 00:00:00
_accumrgt50530 | 0022-01-01 00:00:00 | 2024-03-01 00:00:00
_accumrgt51066 | 0001-02-01 00:00:00 | 2024-03-01 00:00:00
Максимальный период выводим на случай, вдруг итоги рассчитаны далеко в будущее, что также является ошибкой. Таким образом, помимо того, что итоги всегда нужно держать в актуальном состоянии, необходимо следить за тем, чтобы «с обратной стороны» таблицы итогов все также было корректно и актуально!
Проблема решена?

Проблема была в итогах, и значит, у клиента скорее всего с ними тоже проблема? Я попросил клиента выполнить вышеприведенный скрипт, который выводит список проблемных таблиц — безрезультатно, то есть с итогами у клиента проблем не было! Тогда я вернулся к своей базе и исправил таблицу итогов РегистрНакопления.ЗаказыПоставщикам.Итоги, удаляя лишние периоды и массово проводя документы "Приобретение товаров и услуг", предварительно настроив сбор всех запросов обновления итогов по данной таблице с отбором по длительности более 1 мс с помощью расширения pg_trace:
postgres=# SELECT pg_trace_start(
plan := TRUE, duration := '1ms', query_like := 'UPDATE%_AccumRgT48209%'
);
В собранной трассировке снова вижу наш проблемный запрос, но уже с заметно более длительным временем выполнения, более секунды:
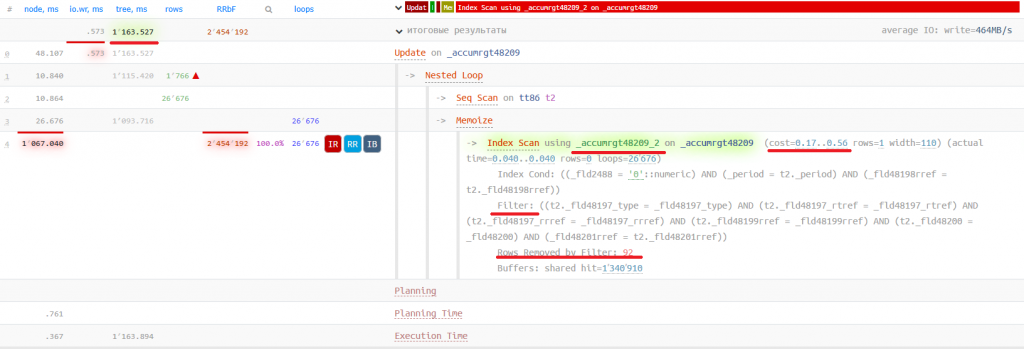
Отключаем индекс с помощью plantuner и получаем план:
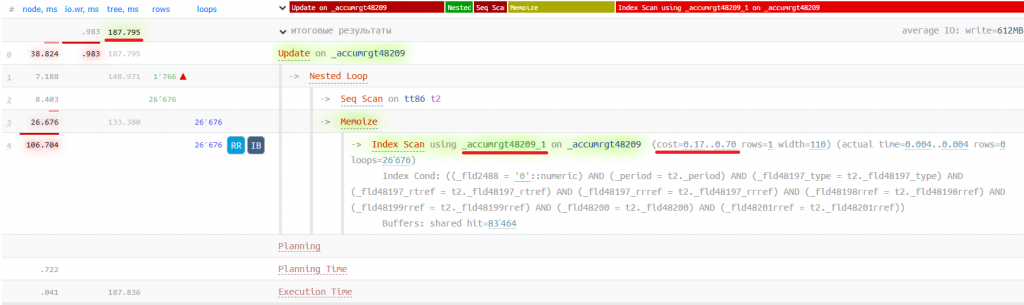
Здесь уже разница в производительности в 6 раз (и целую секунду!).
Несмотря на то, что мы уменьшили количество индексных страниц, Total Cost все равно влияет на выбор неоптимального индекса. Если выше мы смогли разобраться в причинах, обратившись к формуле вычисления *indexTotalCost, то здесь она нам не поможет, т.к. при выборе индекса _accumrgt48209_2 планировщик сильно ошибается в том, какое количество строк будет возвращено, и ему на каждом цикле поиска в индексе приходится отфильтровывать 92 неподходящие под условие строки (Rows Removed by Filter: 92). Это приводит к тому, что и страниц он читает намного больше, чем при использовании индекса _accumrgt48209_1 (1340910 против 83464). Эти ошибки приводят к тому, что на этапе планирования по индексу _accumrgt48209_2 сильно занижается Total cost, что способствует выбору именно этого индекса. Более подробно эта проблема рассматривалась (Rutube/YouTube) на конференции PG BootCamp Russia 2025 в Екатеринбурге разработчиком «Тантор Лабс» Максимом Старковым.
Мы пришли к выводу, что доработать логику планировщика СУБД Tantor стоит, поскольку текущая логика его работы не учитывает выявленные особенности, массово присутствующие в запросах 1С. При доработке логики планировщика мы проанализировали все случаи и добились, чтобы планировщик выбирал оптимальный индекс во всех случаях, однако мы не стали менять алгоритмы расчета Total cost, а сделали акцент на селективность. Доработка планировщика — дело непростое, по итогам нагрузочных тестов у нас было несколько вариантов реализации, и об этом можно написать отдельную статью. Я лишь укажу, какую логику в итоге мы реализовали.
Планировщик при выборе пути индекса корректирует выбор индекса с учетом лучшей селективности для перебираемых индексов, но только в случае, если:
- ключи индексов таких путей непрерывно и последовательно покрывают предикаты соединения и/или отбора, а все такие предикаты используют только оператор "=";
- индексы параметризованы одинаковым количеством соединяемых таблиц и их предикатов.
При таких условиях Total cost и Startup cost теперь не так важны, индексы будут сравниваться по их селективности. Индекс с лучшей селективностью будет иметь приоритет.
После реализации данной логики планировщик в подобных запросах всегда выбирает нужный индекс. Также есть альтернативный вариант реализации – его детально рассматривает Максим в докладе, который я упомянул выше. Мы отдали новую сборку клиенту и он подтвердил, что закрытие месяца существенно ускорилось, аналогично тому, как было на MS SQL!
Заключение
Мы начали статью с рассмотрения проблемного запроса у клиента, затем воспроизвели проблему у себя и обнаружили, что некорректные данные в таблице итогов могут быть проблемой. В статье приведён скрипт для проверки корректности таблиц итогов. Его можно выполнить на 1С:ERP, проверить, присутствует ли проблема, которая замедляет такие операции как закрытие месяца, проведение документов, и исправить её заранее.
Однако скрипт, к сожалению, не устраняет причину проблемы, которая может быть исправлена только внесением изменений в код планировщика СУБД. Исправления кода планировщика, которые позволяют выбирать покрывающие условия запросов индексы, включены в выпуск СУБД Tantor Special Edition 1C 16.6, который вышел в декабре 2024 г.
Александр Симонов, «Тантор Лабс»
Вступайте в нашу телеграмм-группу Инфостарт