В этой статье я расскажу про облака и инфраструктуру как код, а именно о том, как объединить эти два понятия, чтобы оптимизировать и значительно удешевить нагрузочное тестирование 1С.
Меня зовут Овчаренко Дмитрий, я технический архитектор. С 1С я работаю уже более 14 лет. Последние пять лет плотно занимаюсь вопросами DevOps и управлением качеством кода, разрабатываю собственные инструменты и контрибьючу популярные проекты. Например, вы могли видеть меня в списке контрибьюторов jenkins-lib, BSL Language Server, Vanessa Automation и так далее.
Я работаю в компании «Корус Консалтинг», у которой 15 различных направлений, и хотя мы работаем не только с 1С, именно эта практика самая большая по численности сотрудников. Наши проекты, как правило, очень крупные.

Вот список наших клиентов – уверен, большинство из них вам знакомы. Это крупные проекты, и они ставят перед командами нестандартные задачи, требующие креативного подхода.
Именно решение одной из таких задач и подтолкнуло меня к разработке фреймворка, о котором я расскажу.
Для тех, кто с нагрузочным тестированием не знаком, я коротко расскажу о его специфике и особенностях.
Специфика нагрузочного тестирования 1С
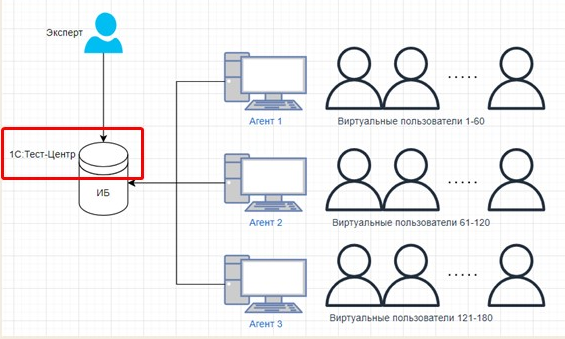
Тест проводится с помощью расширения 1С:Тест-центр – это стандартный подход. Оно встраивается в базу, в нем пишутся обработки, которые потом должны выполнять виртуальные пользователи.
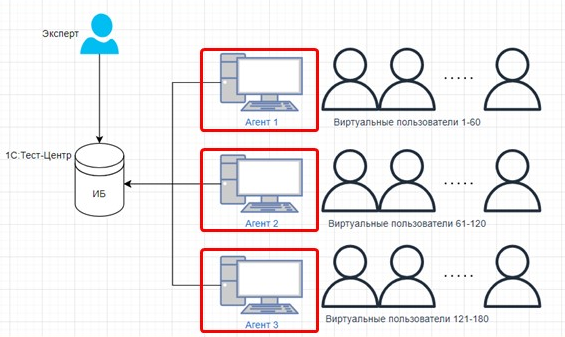
Виртуальные пользователи запускаются на множестве RDP-серверов, потому что на одном сервере нельзя запустить большое количество пользователей. Из-за специфики работы операционных систем и тонкого клиента это всегда должен быть целый набор серверов.
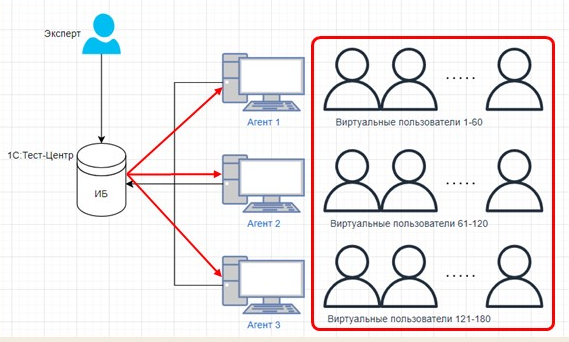
Поэтому эксперт, проводящий нагрузочный тест, должен выделить лицензии и запустить базу в режиме агента, чтобы она подключилась к 1С:Тест-центр, и чтобы 1С:Тест-центр мог запускать на ней виртуальных пользователей.
То есть требуется немалая инфраструктура: не только основные (сервер баз данных и сервер приложений), но и вспомогательные серверы.
Далее я сосредоточусь на инфраструктуре и проблемах, с которыми, уверен, многие сталкивались.
Проблемы с ресурсами
-
Когда мы проводим нагрузочный тест, очень сложно выделить достаточный объем ресурсов. Если это существующая система, нам нужно выделить контур, аналогичный продуктиву, а то и более мощный. Это первая проблема.
-
Даже если ресурсы есть, их нужно настроить: установить все ПО, настроить мониторинг. Когда мы делаем это для заказчиков, это трудоемко как для нас, так и для них, потому что нужно задействовать специалистов, согласовывать наряды со службами инфраструктуры и так далее. Это довольно сложно.
-
И третий пункт, о котором мало кто говорит, но который, по моему мнению, значительно снижает эффективность, – это простой стенда большую часть времени.
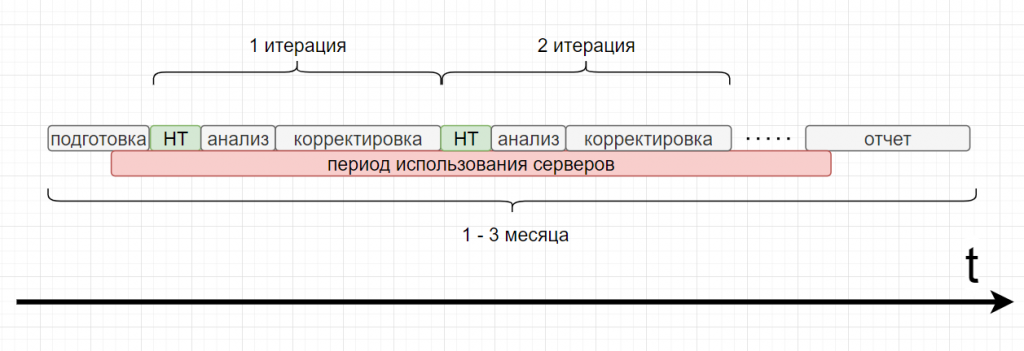
Проект по нагрузочному тестированию занимает от 1 до 3 месяцев. Он состоит из нескольких крупных фаз:
-
Когда мы готовим этот проект,
-
Когда мы проводим несколько итераций нагрузочного тестирования,
-
Когда мы пишем отчет.
Стенд нагрузочного тестирования мы создаем примерно в конце фазы подготовки. А когда все сервера уже развернуты, то они остаются развернутыми и занятыми на протяжении всего проекта. То есть мы не можем использовать их для других целей.
Самое обидное – непосредственно нагрузочный тест (работа виртуальных пользователей) длится всего от 2 до 12 часов. Но с первой итерации тест почти никогда не проходит: нужно проанализировать результаты, внести корректировки и перейти к следующей итерации, на которую снова уходит от 2 до 12 часов, а затем может уйти от одного дня до недели на анализ и исправления. Стенд все это время просто стоит, а ресурсы, между прочим, не бесконечны. На них можно было бы поднять, например, дополнительный сборщик или усилить продуктив, но этого не происходит.
Кейс заказчика и идея решения
Перейду к кейсу нашего заказчика: он довольно стандартный, и с подобным сталкивались многие.
Мы делаем для этого заказчика проект на базе УТ 11. Сейчас он работает в продуктиве на Windows, но бизнес расширяется, и через несколько месяцев в базе будет примерно в 5 раз больше пользователей. Поскольку заказчик планирует переезд на Linux, необходимо понять, как это все будет работать в Linux.
База сильно доработана: есть функционал управления товарными матрицами, очень большой ассортимент, сложная логика ценообразования – нагрузка высокая. Из тысячи пользователей 50 могут нагрузить базу так, что мало не покажется.
Для тестирования нужно не только создать аналог продуктивного стенда, но и 16 терминальных серверов.
Мы столкнулись с такой реальностью: у заказчика этих ресурсов просто нет, а согласовать их – процесс длительный, и успех не гарантирован. Мы собрались командой, посмотрели в нашем пуле – таких ресурсов тоже не нашли. Сначала возникла идея арендовать виртуальные машины. Но, все посчитав, мы поняли, что наш бюджет этого не выдержит.
Тогда появилась другая идея – поднимать стенд в облаке только на время выполнения тестов. То есть использовать ресурсы только на короткий период, чтобы они не простаивали, и мы за них не платили.
Идея хорошая, но, очевидно, довольно проблематична в реализации, потому что:
-
Разворачивать стенд с нуля на каждой итерации – очень трудоемко,
-
Повторяемость каждой итерации не гарантирована, ведь где-то что-то могли забыть доустановить или донастроить,
-
Поскольку после каждой итерации стенд предполагается удалять, это снижает надежность: если мы проведем длительную итерацию, а результаты не сохраним, мы потеряем время.
Рождение концепции
Соответственно, родилась концепция, которую я сейчас кратко опишу. Когда идея созрела, я понял, что нужно делать, мысленно попросил коллег «подержать мое пиво» и ушел разрабатывать репозиторий – описывать инфраструктуру нагрузочного теста в виде кода. По сути, наш стенд создается из этого репозитория и применяется в облаке.
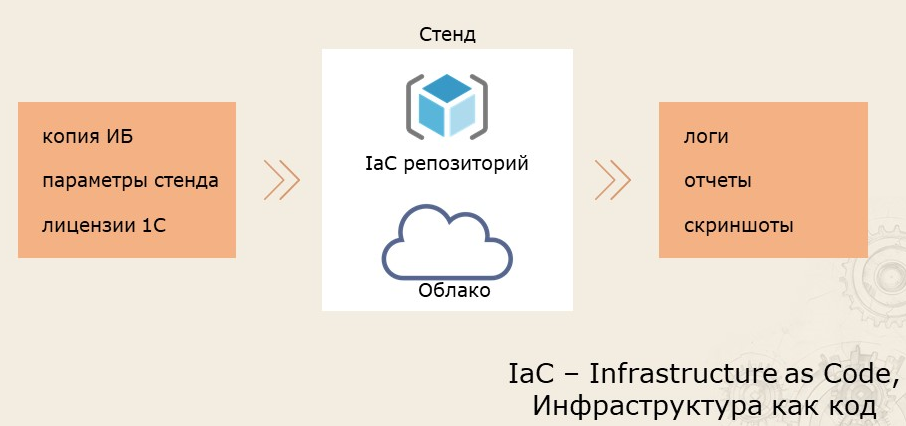
На входе мы имеем копию базы, в которой уже установлен 1С:Тест-центр, написаны все обработки и даже частично настроен сценарий. Мы знаем параметры нашего стенда. Также у нас есть отдельный сервер с лицензиями 1С.
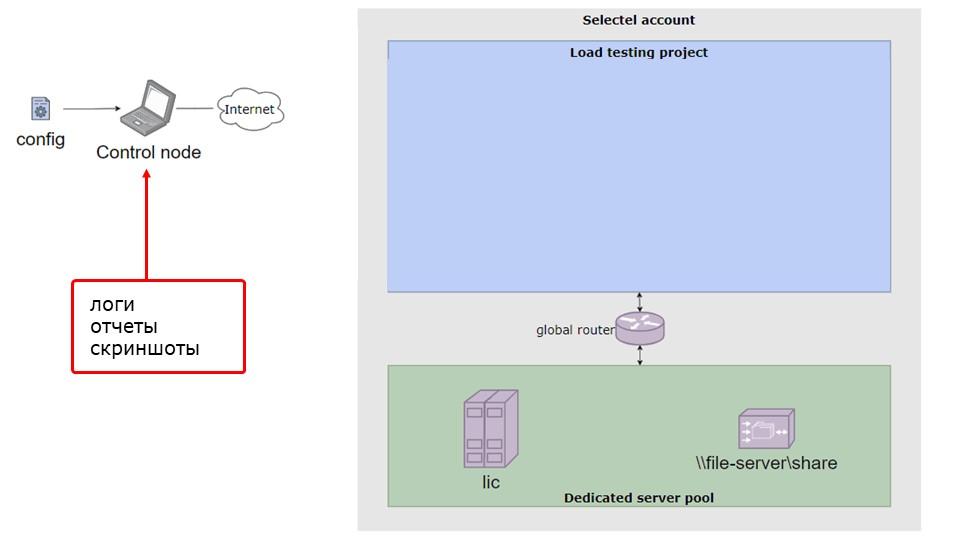
Мы применяем наш репозиторий, содержащий код инфраструктуры. Это и есть IaC – инфраструктура как код. Прогоняем нагрузочный тест. В конце получаем логи, отчеты и скриншоты для последующего анализа. А стенд удаляется – мы за него не платим. Попользовались, оплатили, удалили.
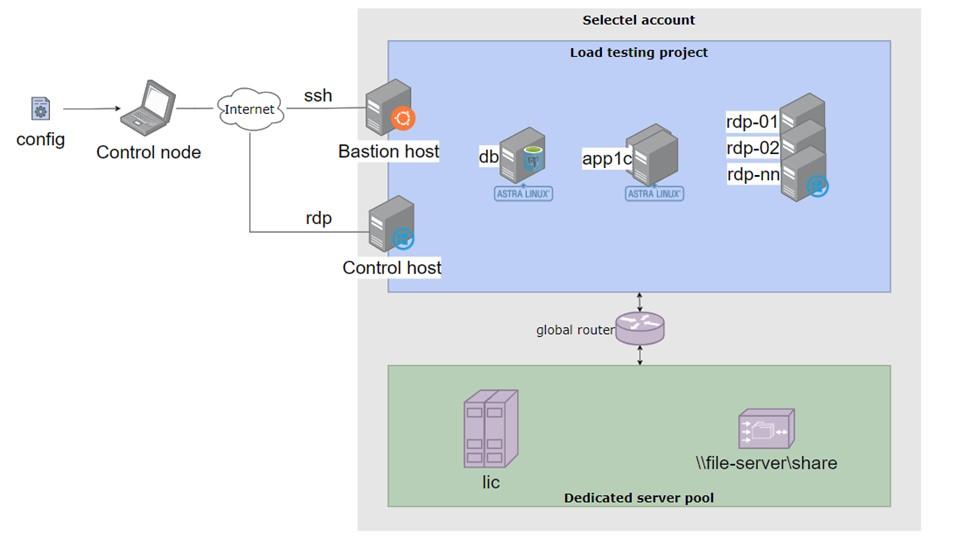
В развернутом виде это выглядит, как на схеме. Схема может показаться сложной, но сейчас я объясню, что к чему.
Архитектура облачного решения
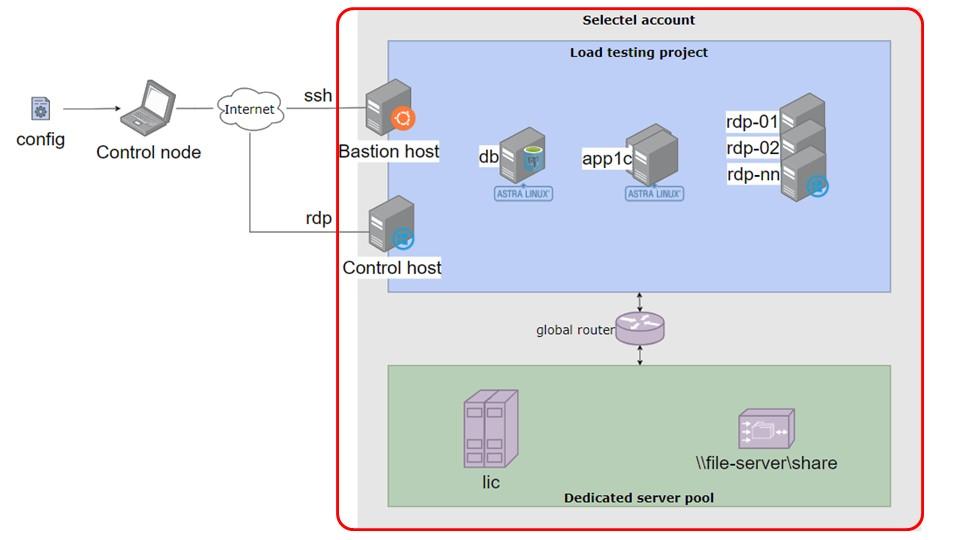
У нашего департамента есть аккаунт в облаке Selectel, на схеме он выделен красной рамкой.
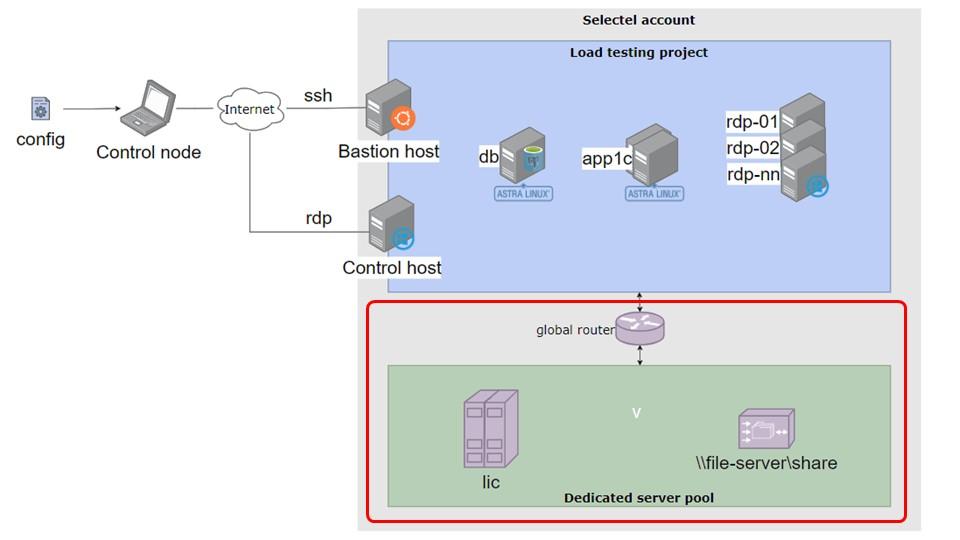
Зеленая область – это область, где мы держим выделенные серверы, такие как сервер лицензирования и файловый сервер.
На отдельном сервере лицензирования активируются все необходимые программные лицензии: серверные и клиентские. Мы используем этот набор лицензий для всех наших проектов разработки. Файловый сервер служит для хранения различных файлов: копий баз данных, DT-файлов и прочего.
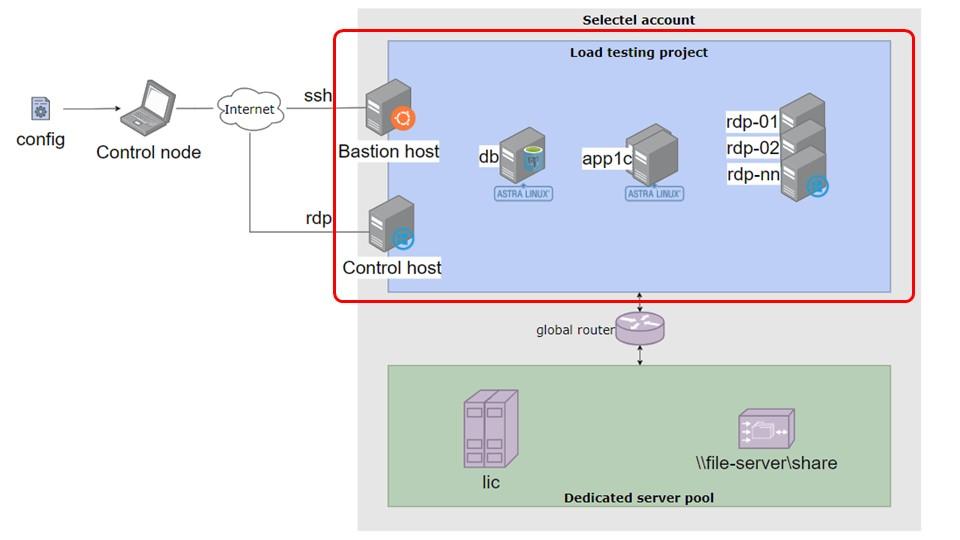
Для каждого проекта по нагрузочному тестированию в консоли Selectel создается отдельный облачный проект. Это способ логического разделения ресурсов. Все серверы, необходимые для конкретного тестирования, создаются внутри этого проекта.
Помимо очевидных серверов баз данных и серверов приложений (RDP), создаются еще два служебных хоста. Они имеют публичные («белые») IP-адреса, то есть доступны извне, и к ним можно подключиться. Один хост используется для размещения инструментов мониторинга, а второй – это Windows-хост, созданный исключительно для удобства: чтобы можно было на нем вручную открыть базу и проверить что-либо визуально.
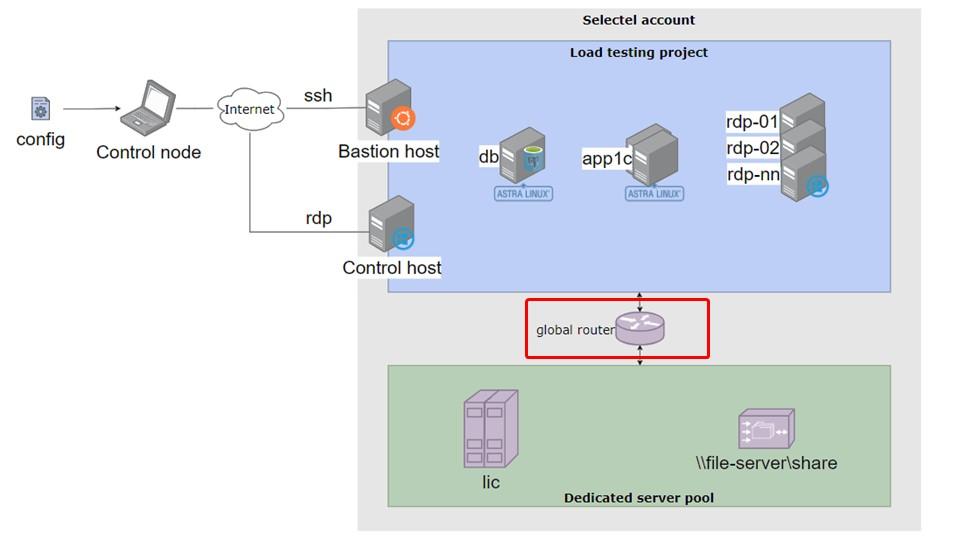
Соединения двух сегментов сети осуществляется с помощью так называемого глобального роутера. Есть выделенные серверы от Selectel, есть облачный сегмент, который, как я предполагаю, живет в совершенно другой инфраструктуре. Чтобы их соединить, используется такой функционал, который, я думаю, используется в любом облаке. По сути, это маршрутизатор.
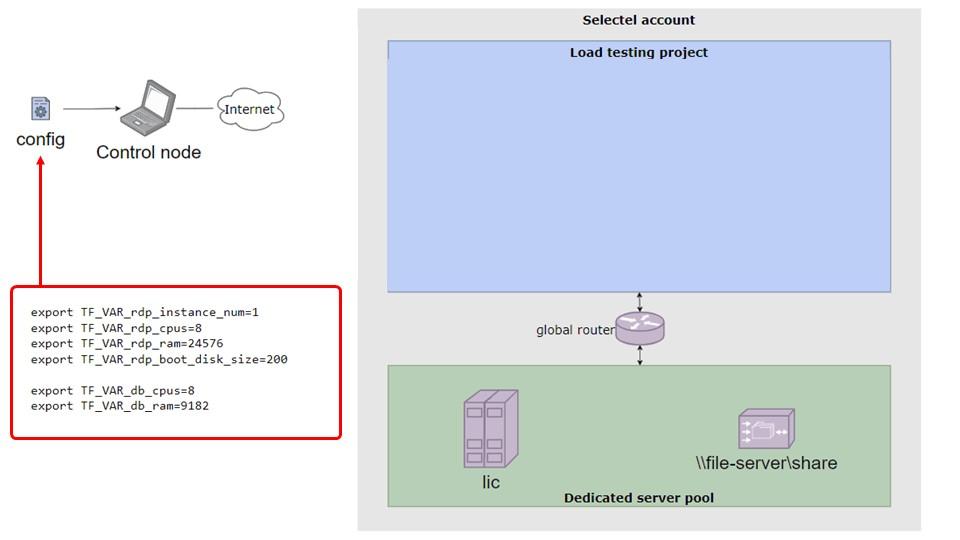
У нас заранее настроен облачный проект – мы создали его и настроили роутинг. Я клонирую репозиторий с кодом инфраструктуры себе на компьютер и открываю конфигурационный файл. Буду называть его «тем самым конфигурационным файлом», потому что в нем хранятся все параметры стенда: количество RDP-серверов, их CPU, объем оперативной памяти, диски и так далее. Файл довольно большой, параметров, может быть, около 50, и это еще не все – есть желание добавить больше.
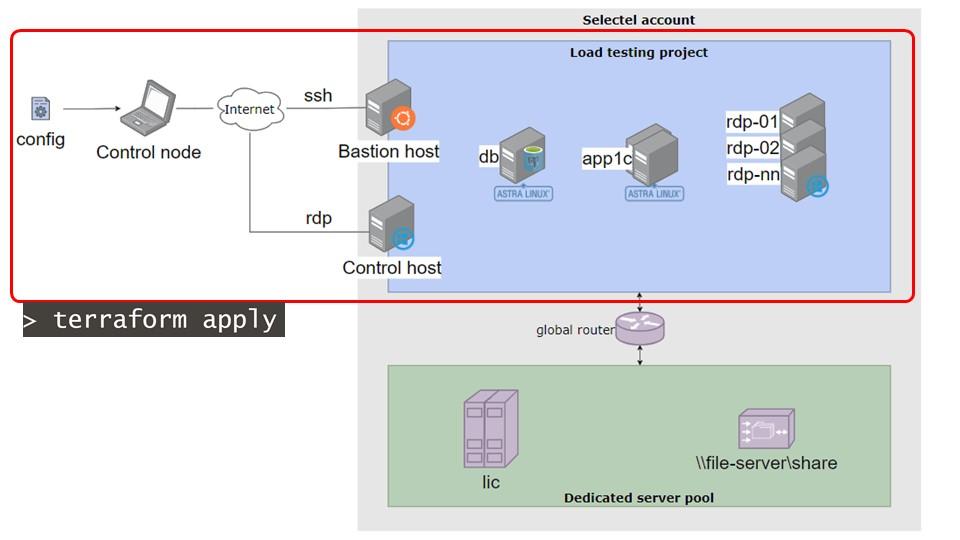
Далее, после редактирования параметров, я запускаю простую команду – terraform apply. Подробнее о terraform я расскажу дальше, но суть в том, что эта команда создает серверы в облачном проекте.
Можно представить, что terraform apply – это бригада строителей, которая возводит здания, подводит электричество и воду, но не делает внутреннюю отделку. Отделкой занимается ansible.
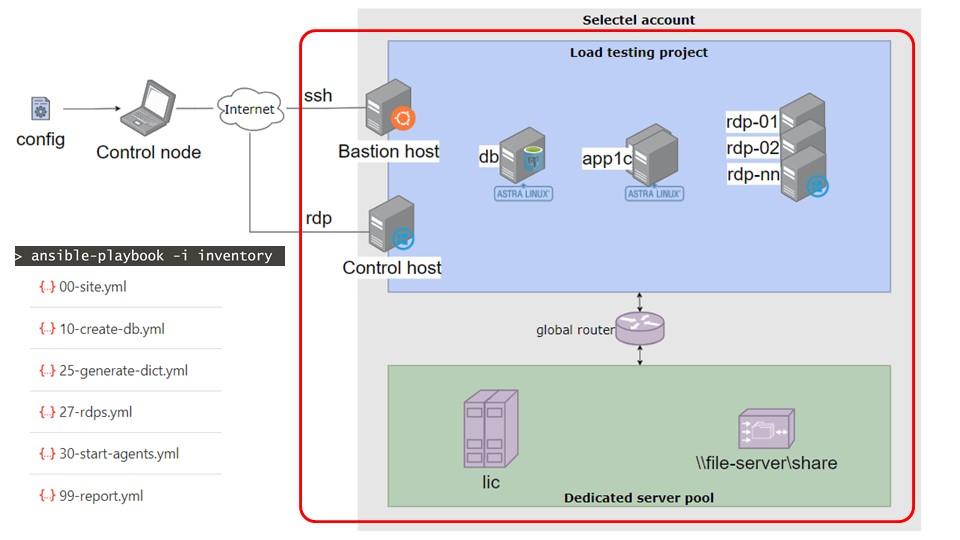
В данном контексте «отделка» – это установка программного обеспечения, настройка и размещение различных файлов и так далее.
В репозитории описаны несколько плейбуков, пронумерованных строго по порядку (например, 00, 10, 25). Пропуски в нумерации предусмотрены для добавления промежуточных этапов, если это понадобится. От человека, проводящего нагрузочный тест, требуется только запустить их последовательно. Параметры уже заданы в конфиге. Мы просто выполняем плейбуки по порядку. Сначала запускается плейбук 00-site.yml, который устанавливает инструменты мониторинга и другие служебные компоненты – всю эту основную, низкоуровневую часть. Далее идет создание базы и другие этапы, о которых я расскажу подробнее.
Когда, например, мы выполнили плейбук 30-start-agents.yml, это означает, что на всех RDP-серверах запущены агенты тест-центра.
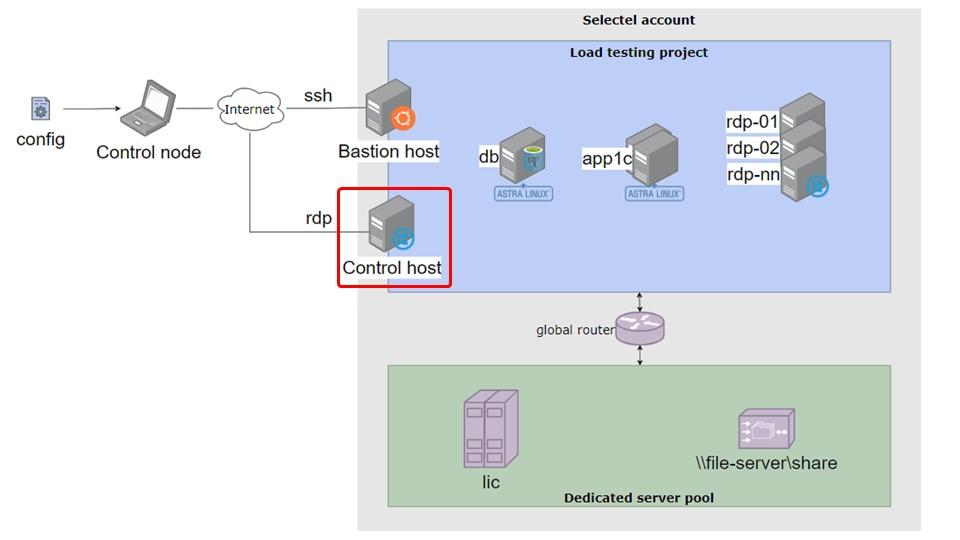
Теперь мы можем подключиться к Control host через RDP, открыть базу и, предварительно настроив тест, запустить нагрузочное тестирование.
После завершения теста запускается последний плейбук 99-report.yml, который обходит все узлы стенда, собирает всю информацию и сохраняет ее локально.
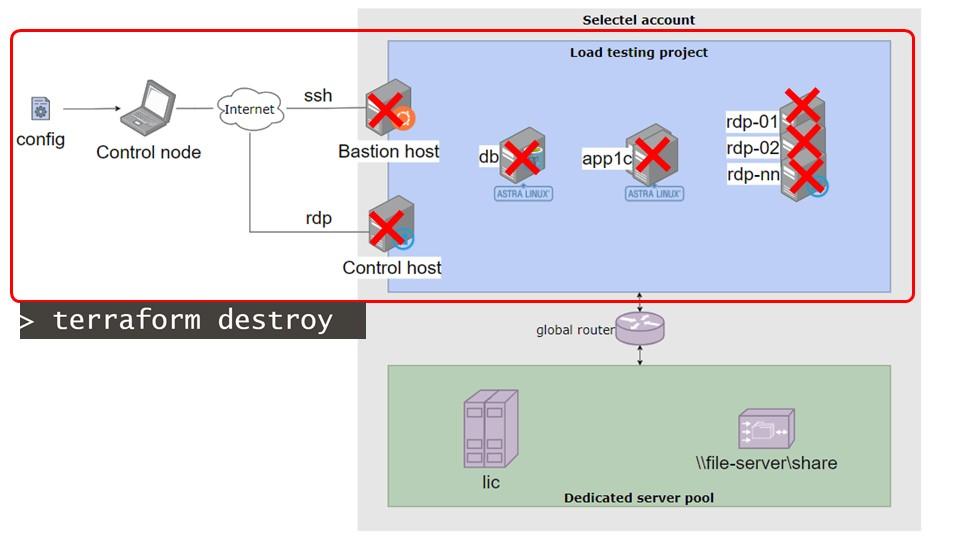
После этого мы можем смело выполнить команду terraform destroy – все облачные серверы будут уничтожены, мы перестаем за них платить, в облаке от них не остается никаких следов, и все довольны. А мы переходим к анализу полученных результатов. Как я уже упоминал, все результаты сохраняются локально.
Используемые инструменты: Terraform и Ansible
.

Terraform. Это стандарт де-факто в области облачной инфраструктуры – продукт, который позволяет развернуть серверы и многое другое, используя всего один файл конфигурации. Он параметризуется с помощью «того самого конфига»: все необходимые параметры прописываются в нем, и Terraform создает нужные серверы.
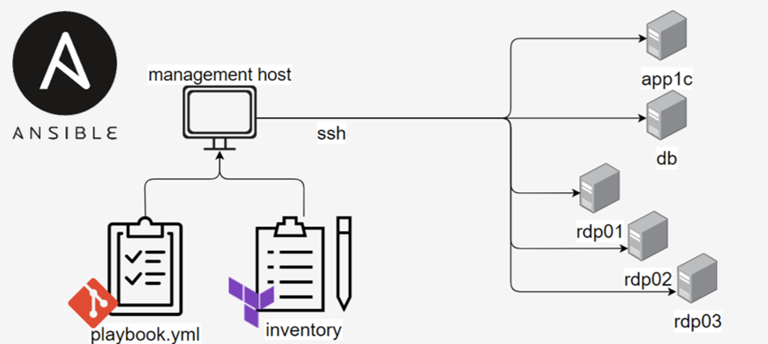
Ansible. В репозитории описаны плейбуки, содержащие множество ролей для различных ситуаций. Ansible должен знать, на каких конкретных машинах выполнять эти плейбуки.
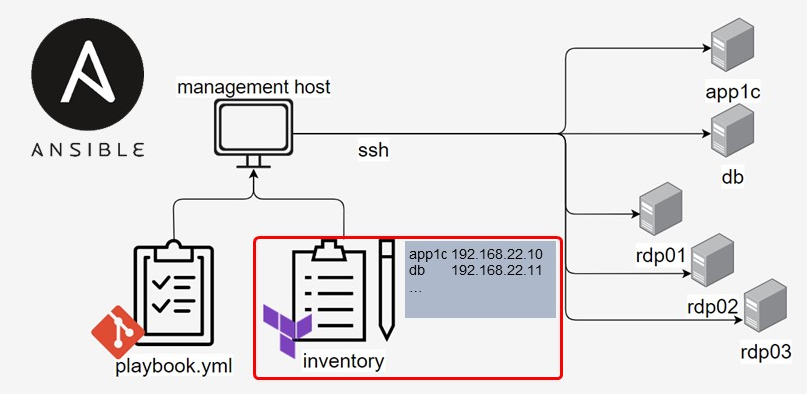
Эту задачу он решает с помощью файла Inventory. Это, грубо говоря, очень продвинутый аналог файла hosts. В нем можно группировать машины и указывать различные дополнительные параметры.
Поскольку наша облачная инфраструктура создается динамически, мы заранее не знаем, какие IP-адреса будут у конкретных серверов. Однако эту информацию знает Terraform. При выполнении он генерирует файл Inventory, используя специальный шаблон.
Детали настройки серверов и базы данных
СУБД
При развертывании кластера на уровне СУБД устанавливается версия Postgres Pro, указанная в конфигурационном файле. Можно выбрать версию 15, 16 или любую другую – она будет установлена автоматически.
Далее происходит настройка кластера: задаются основные, наиболее важные параметры. Не все параметры вынесены в конфиг – при необходимости их можно изменить непосредственно в ролях. Вынести параметры в конфиг – задача довольно простая, просто до некоторых параметров не дошли руки.
Затем загружается база данных. Мы берем файловый сервер, который уже примонтирован к служебному хосту СУБД. Мы знаем, откуда взять в нашем случае DT-файл. Загружаем с помощью ibcmd, выполняем VACUUM ANALYZE и активируем расширение pg_stat_statements на этой базе.
Кластер 1С
Далее собирается кластер 1С. На каждом сервере необходимо установить платформу 1С. Для этого реализовано автоматическое скачивание с releases или из локального каталога использования дистрибутива, который там лежит. Версия платформы, которую нужно установить, также указывается в конфигурационном файле. Если используется защищенная версия, ее нужно положить в локальный каталог, и система ее тоже корректно установит.
На каждом узле 1С мы собираем кластер – точнее, включаем серверы в кластер. Выполняются соответствующие скрипты. Если серверов в кластере больше одного, назначаются ТНФ для централизации журнала регистрации и полнотекстового поиска.
Добавляем внешний сервер лицензирования, чтобы наш кластер мог получать лицензии. Параметры сервера (его адрес, порты и т.д.) также задаются в конфигурационном файле, и для этого тоже назначаются ТНФ.
В проекте есть шаблон файла logcfg.xml. В нем задаются параметры, значения которых подставляются с помощью Ansible. Например, можно указать длительность запросов, которые нужно отбирать (в секундах). Ansible затем распределяет этот logcfg.xml по всем серверам приложений.
Далее добавляем базу в кластер – операция тривиальная.
Затем мы запускаем базу в специальном режиме со специальной обработкой, которая формирует JSON-файл с соответствием между именами таблиц БД и именами объектов 1С по каждой таблице.
RDP и тонкие клиенты
На RDP-серверах мы аналогичным образом загружаем и устанавливаем тонкие клиенты 1С. Причем, чтобы не качать их на каждый сервер отдельно (их может быть много), мы сначала скачиваем дистрибутив на один хост, а затем копируем и устанавливаем его на все RDP-серверы.
Также база добавляется в список баз – просто для удобства.
Регистрируем консоль кластера, чтобы не запускать соответствующий bat-файл вручную для подключения к кластеру.
И, как я показывал на одном из первых рисунков, запускаем базу в режиме агента тест-центра. Вместо того чтобы вручную заходить на каждый сервер и запускать базу, это делается автоматически. Более того, агенты можно перезапускать. Если что-то пошло не так, нет необходимости полностью гасить весь стенд – можно просто запустить соответствующий плейбук, который завершит нужные процессы и запустит их заново.
Организация мониторинга
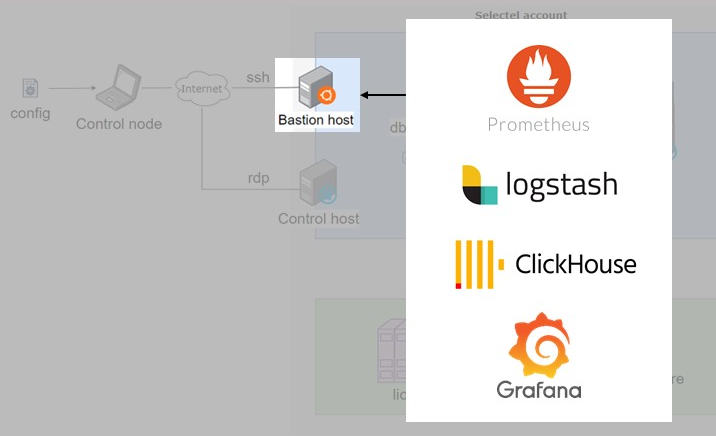
Чуть подробнее о том, как устроен мониторинг. На служебном хосте Bastion размещены центральные компоненты средств мониторинга: Prometheus, Logstash, ClickHouse и Grafana. Это довольно стандартный стек для мониторинга 1С.
Что касается экспортеров, то здесь тоже используется стандартный набор:
-
node_exporter для Linux-машин,
-
win_node_exporter для Windows-машин,
-
postgres_exporter для СУБД,
-
prometheus_1C_exporter для сбора метрик 1С через RAS.
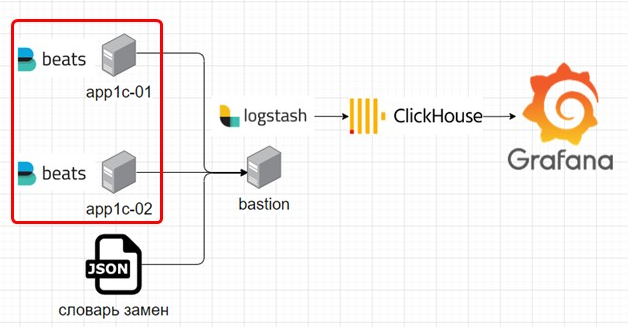
На каждом сервере 1С ведется технологический журнал, и для его обработки установлена программа Beats. Это компонент ELK-стека, который следит за изменениями в файлах техжурнала и отправляет каждую запись в Logstash. Перед отправкой она собирает многострочные записи техжурнала в одну строку.
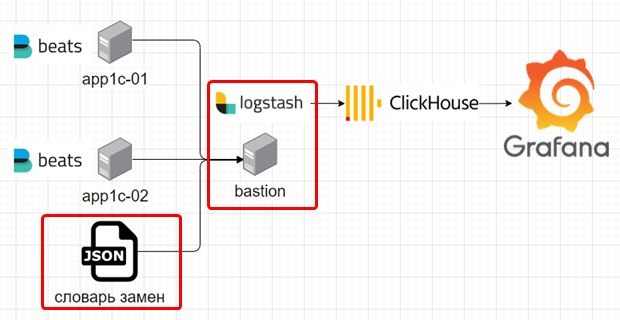
Logstash не просто принимает эти записи, но и использует словарь замен, который для некоторых полей техжурнала меняет имена таблиц на термины 1С. После обработки данные сохраняются в ClickHouse, который служит источником данных для Grafana, а в Grafana можно визуализировать практически любую информацию.
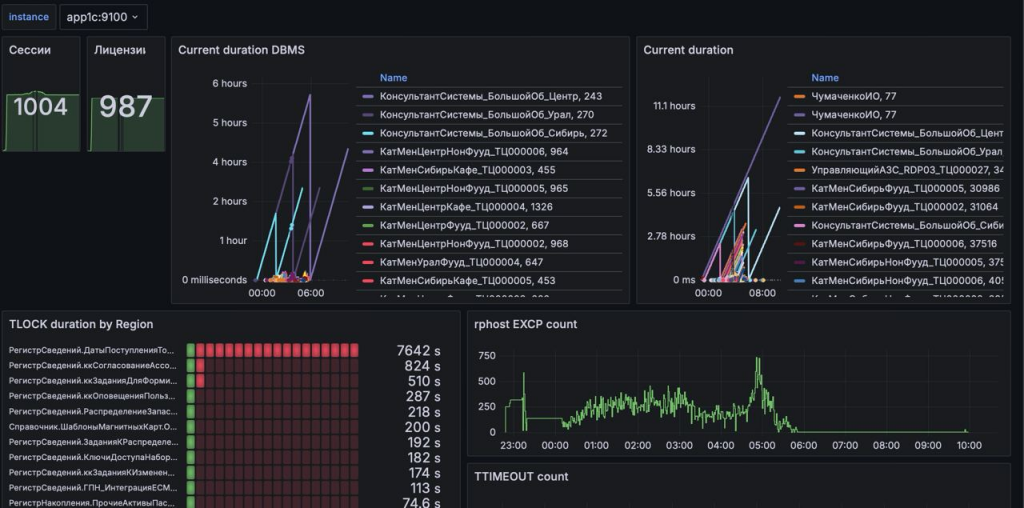
Вот как это выглядит на практике. Хочу подчеркнуть, что эта панель мониторинга становится доступна сразу после развертывания стенда и выполнения первого плейбука. Никакой дополнительной настройки не требуется – просто запустили плейбук, открыли браузер, и все работает.
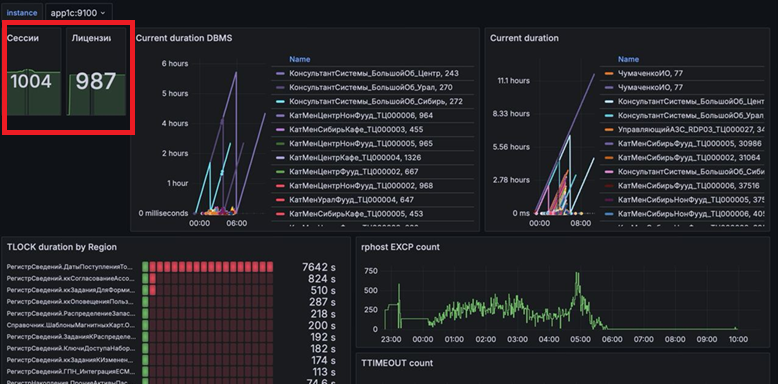
Здесь мы мониторим сессии и лицензии.
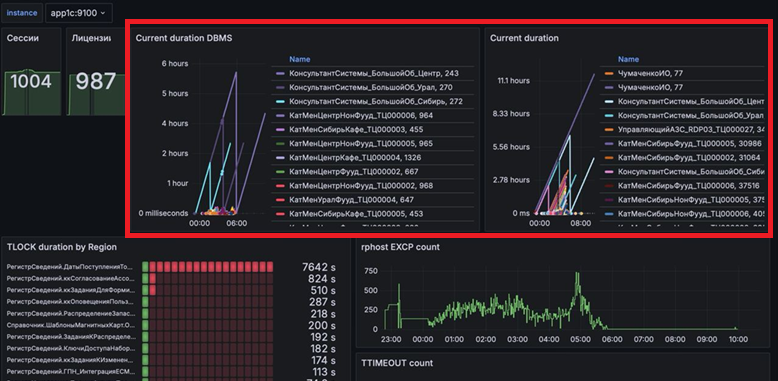
Длительность серверных вызовов и обращений к СУБД.
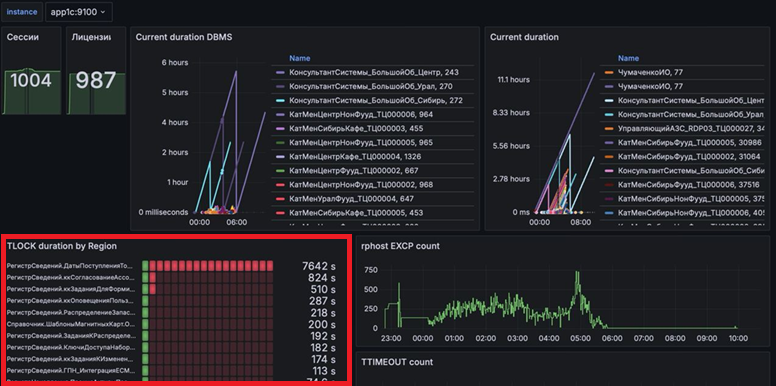
Здесь показана визуализация данных из ClickHouse – длительное суммарное ожидание на управляемых блокировках, сгруппированное по областям. Обратите внимание, области блокировок представлены в терминах 1С, прямо как в конфигураторе. Мне кажется, это очень удобно и круто.
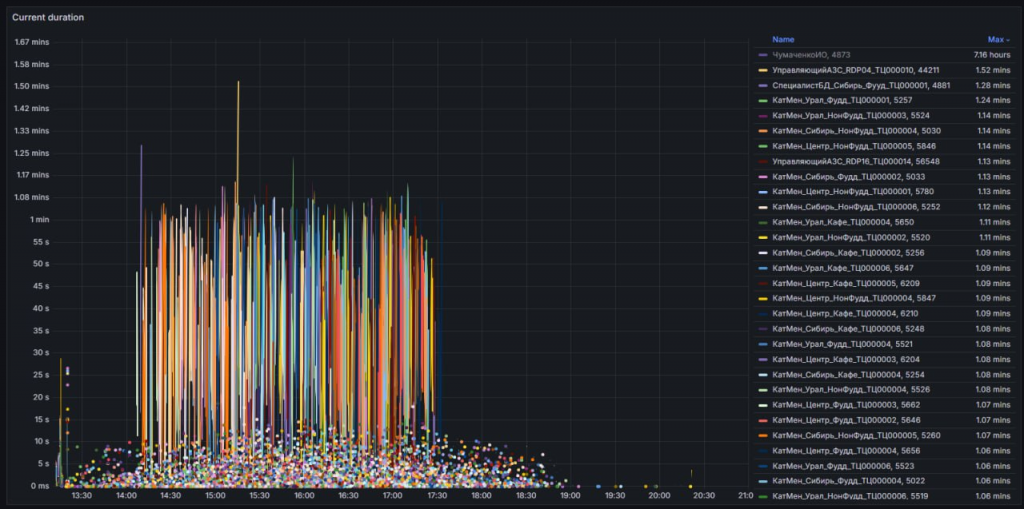
Длительность вызовов на примере реального проекта нагрузочного тестирования. Тут видны отдельные точки (короткие вызовы) и некий «забор» – это работа тех самых пользователей, которые умеют очень эффективно нагружать базу.
Сбор результатов тестирования
После проведения нагрузочного теста необходимо собрать все результаты. Это осуществляется с помощью специального плейбука, который обходит все серверы стенда и собирает всю необходимую информацию. Он сохраняет локально технический журнал и журнал регистрации.
Происходит выгрузка логов PostgreSQL.
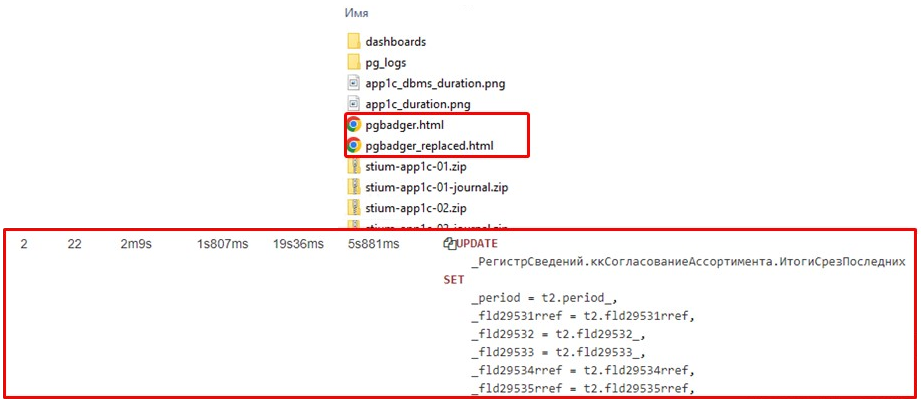
На основе этих логов формируется отчет pgbadger. И здесь еще одна киллер-фича: в pgbadger также реализована замена технических имен таблиц на термины 1С.
Далее используется утилита, которая проходит по дашбордам Grafana и делает скриншоты с каждой панели, сохраняя их в PDF-файл.
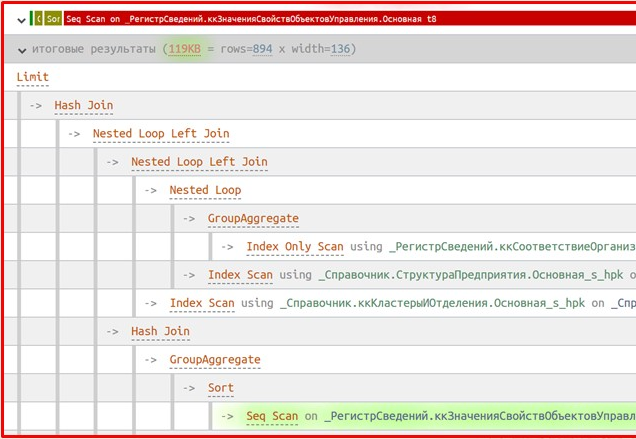
Отдельно из логов PostgreSQL с помощью специального Python-скрипта извлекаются планы запросов. И в этих планах тоже присутствует замена имен таблиц. Планы запросов сохраняются в отдельный каталог, причем файлы именуются так, что самый медленный запрос будет первым в списке. Вам остается только открыть нужный файл в текстовом редакторе и вставить его содержимое на сайт explain.tensor.ru – и вы сразу увидите план запроса, представленный в терминах 1С.
Проблемы и нюансы, возникшие при разработке
Сам по себе 1С:Тест-центр – очень классный инструмент, но не все операции в нем можно автоматизировать. Я стремлюсь к такому уровню автоматизации, чтобы нагрузочный тест выполнялся одной командой – это моя мечта. Пока что все же приходится заходить интерактивно, настраивать и запускать тест вручную. Думаю, что со временем эту проблему удастся решить.
Еще один нюанс тест-центра: мои коллеги проводили тест на 10 000 пользователей и столкнулись с тем, что 1С:Тест-центр очень медленно запускает виртуальных пользователей.
Также возникли вопросы с лицензированием. Когда я завершал свой проект, мои коллеги из другого проекта уже использовали мой фреймворк для тестирования на 10 000 пользователей. У нас было всего 10 000 лицензий, и если бы тесты запустились одновременно, обе итерации пришлось бы признать недействительными. Мы вовремя это заметили и перепланировали работы. Это важный момент – ресурсы используются совместно.
При именовании объектов в облаке мы столкнулись с тем, что в Selectel определенные виды объектов должны иметь глобально уникальное имя. Эта проблема проявилась снова при параллельном тестировании двух проектов, и для ее решения пришлось добавить в конфигурационный файл новый параметр – префикс. Теперь все объекты в облаке для каждого проекта имеют уникальный префикс.
Что касается облачного провайдера, то мы используем Selectel. Однако можно использовать практически любого провайдера, у которого есть Terraform-провайдер. Важно, на какой технологии он основан. Например, если бы нам нужно было переехать на VK Cloud, где также используется OpenStack, адаптация наших Terraform-файлов была бы минимальной. А вот для Яндекс.Облака, у которого свой Terraform-провайдер, потребовалась бы переработка кода. Но не думаю, что это заняло бы больше двух дней.
Также стоит учитывать дистрибутивы операционных систем. Мы тестировали на Linux, используя Astra Linux и Red OS в разных проектах. Если в будущем понадобится работа с какой-то экзотической сборкой, скрипты также придется адаптировать.
Результаты и выводы
Мы сократили расходы на вычислительные ресурсы в 7 раз. Представьте, если стоимость инфраструктуры на весь период вашего нагрузочного теста составляет 700 000, то с использованием нашего подхода вы заплатите всего 100 000. Это ощутимая экономия.
Что касается заказчика, мы выполнили задачу в срок. Но важно даже не это – важно, что мы полностью сняли с заказчика головную боль, связанную с разворачиванием стенда, согласованием ресурсов и прочими сопутствующими задачами. Единственное, что мы попросили у заказчика – это полные характеристики их продуктивной среды: выгрузку их pg_settings и аналогичную информацию.
Бонусом, о котором я упоминал вскользь, стала стандартизация. Теперь мы можем запускать другие проекты на этом же фреймворке, значительно упрощая себе работу. Как я уже говорил, мои коллеги успешно провели нагрузочный тест на 10 000 пользователей с помощью этого фреймворка.
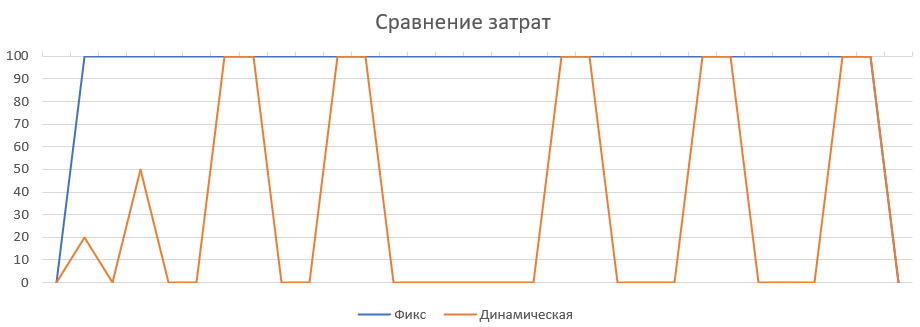
Визуально разницу в стоимости ресурсов можно представить так: в случае фиксированного подхода (синяя линия) мы создаем все ресурсы и платим за них до конца проекта. В случае динамического подхода мы платим только в момент использования.
Если вы не знаете, для какой задачи применить облако в вашей ситуации, вот вам подсказка: нагрузочное тестирование, CI/CD (агенты в облаке, поднимающиеся по требованию) и различные интеграции, включая микросервисные приложения – все это решаемые в облаке задачи.
Хочу выразить благодарность всем, кто участвовал в создании инструментов, которые я использовал. Эти люди, так или иначе, очень сильно помогли в создании этой публикации. Все, о чем я здесь рассказал, бесплатно – за исключением стоимости самих облачных ресурсов.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт