
Первые релизы Apache Kafka были выпущены в 2010 году, и по данным официального сайта ее сейчас используют около 80% компаний из рейтинга Fortune 100. И хотя российские компании в этом рейтинге сейчас не упоминаются, они тоже используют Apache Kafka.

Например, если обратиться к ресурсу TAdviser, то можно обнаружить, что среди компаний, которые на своих проектах так или иначе внедряли Kafka, достаточно много известных – на слайде я привел лишь некоторую часть их логотипов, все бы сюда не поместились.

Kafka фактически стала ядром для построения решений класса Event Stream и событийной интеграции. Вокруг нее сформировалась целая экосистема, в которую входят такие крупные инструменты как Kafka Connect и Kafka Streams. Также доступны реализации API для взаимодействия с Kafka на многих популярных языках программирования.

Возникает закономерный вопрос: как обстоят дела с нашей платформой 1С?
-
Встроенных решений для работы с Kafka в платформе 1С нет.
-
Есть возможность работать с Kafka через 1С:Шину, но на текущий момент (прим. ред. доклад от 11 октября 2023 года) ее нельзя назвать полноценным инструментом для такого взаимодействия.
-
Можно использовать коммерческий продукт – нативную внешнюю компоненту Yellow Kafka от команды Серебряная пуля.
-
Другой вариант – это использование платформы DaJet от Дмитрия Жичкина.
-
Можно построить взаимодействие через самописный микросервис, работающий на базе внешней компоненты для tcp/ip, или через компоненты, подгружающие код в .jar-файлах.
-
А я сейчас хочу рассказать еще об одном инструменте – полностью открытой нативной внешней компоненте Simple Kafka.
Казалось бы, название Simple Kafka звучит несерьезно, но этому есть объяснение. Изначально эта компонента была написана только под Windows и использовалась для небольших рабочих задач интеграции. Но потом мы стали ее использовать практически во всех серьезных проектах, где нужно связать 1С с другими системами. В результате мы разместили код данной компоненты в открытом репозитории на GitHub и продолжили ее развитие, исходя из реальных практических потребностей:
-
Реализовали версию компоненты под Linux по технологии Native API.
-
Добавили дополнительные функции, которые давно напрашивались.
В репозитории вы можете увидеть исходный код компоненты, а также ознакомиться с документацией и описанием кейсов использования. А в релизах – скачать готовый zip-архив, который достаточно загрузить в макет двоичных данных и быстро начать работать с компонентой на любой операционной системе (и на Windows, и на Linux).
Внутреннее устройство Simple Kafka

Немного о том, как устроена компонента Simple Kafka.
В ее основе – достаточно известная open-source библиотека Librdkafka, которая разрабатывается и поддерживается командой Confluent Inc.
Сама внешняя компонента реализована на основе кастомного шаблона, который оказался более понятным, прозрачным и простым, чем типовой шаблон нативной компоненты от вендора. Поэтому автору и контрибьюторам, которые указаны на слайде, большой респект за исходники этого шаблона.
Подключается компонента стандартно – примеры подключения можно посмотреть на сайте ИТС или в синтакс-помощнике. Но есть два важных нюанса, на которые я хотел бы обратить внимание:
-
Для работы компоненты версия платформы должна быть не ниже, чем 8.3.21.1302.
-
Второй нюанс – компонента должна быть подключена в изолированном режиме Да, ее можно подключать и неизолированно, но тогда в случае сбоя ее падение будет приводить к аварийному завершению всех использующих ее сеансов. Понятно, что бизнес нам за это спасибо не скажет.
Интерфейс Producer API – публикация сообщений
У компоненты Simple Kafka предусмотрено несколько API-интерфейсов. С их помощью можно:
-
отправлять сообщения из 1С;
-
получать сообщения в 1С;
-
вести логирование событий;
-
собирать статистику.
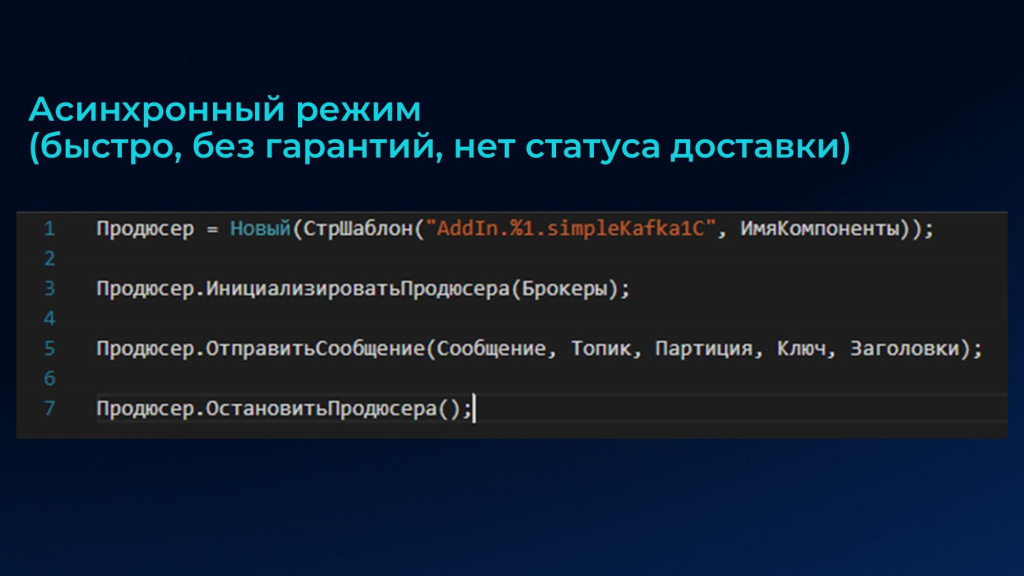
Однако прежде чем получать сообщения в 1С, нужно научиться их отправлять. Поэтому первый интерфейс, который мы рассмотрим – это Producer API, интерфейс отправителя.
Отправлять сообщения с помощью компоненты можно как асинхронно, так и синхронно. Самый быстрый способ отправить сообщение в нужный топик брокера Apache Kafka – это асинхронный метод «ОтправитьСообщение()».
В нем в качестве параметров указывается:
-
Сообщение – например, json строка или упакованные в base64 двоичные данные.
-
Топик – строка.
-
Партиция – число. По умолчанию запись производится в 0 раздел.
-
Ключ – произвольный ключ сообщения.
-
Заголовки – перечень так называемых хедеров сообщения в строковом формате: «ключ1,значение1;ключ2,значение2».
Асинхронный режим хорош тем, что он действительно быстрый, но у него есть особенность: проверить результат доставки можно только через механизм обратных вызовов, а это в платформе никак не реализовано.
Возникает справедливый вопрос – как убедиться, что сообщение доставлено? Для асинхронной отправки результаты можно получить с помощью следующих архитектурных подходов:
-
При создании экземпляра продюсера рядом создаем экземпляр консьюмера и подписываем его на тот же топик, куда производится отправка. А далее через сравнение хэша или ключа отправленного и полученного сообщений можем подтвердить успешную отправку.
-
Читаем логи. Про логи я расскажу подробнее чуть позже, сейчас лишь отмечу, что сами сообщения в логах не сохраняются, потому что сообщений может быть много, и они могут быть большие. Но в логах фиксируется сопроводительная метаинформация, которая позволяет судить о том, было доставлено сообщение в брокер или нет:
-
если при отправке был указан ключ сообщения, он фиксируется в логе.
-
если ключ отсутствует – в логе будет hash md5.
-
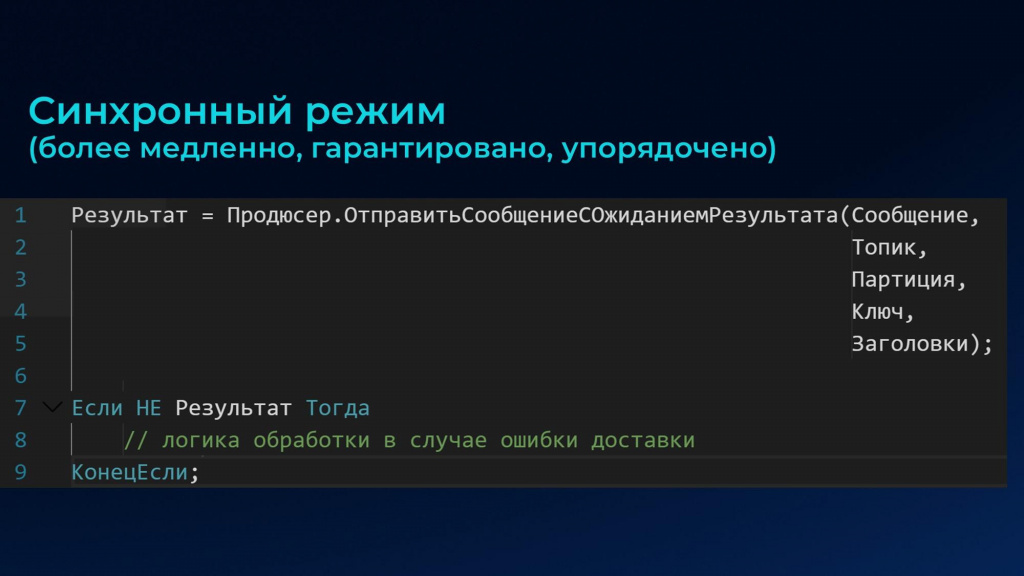
Синхронный режим, в отличие от асинхронного, в разы медленнее, зато он обладает двумя важными свойствами:
-
Упорядоченная гарантированная доставка.
-
Возможность получения статуса доставки – доставлено сообщение или нет.
Метод, обеспечивающий синхронную отправку – ОтправитьСообщениеСОжиданиемРезультата(). Его параметры полностью совпадают с асинхронным методом, но у него есть возможность вернуть результат – булево.

Как в синхронном, так и в асинхронном режиме есть несколько важных ключевых параметров, которые значительно влияют на производительность.
Здесь я сразу сделаю важную ремарку – все настройки, которые есть в библиотеке Librdkafka, поддерживаются во внешней компоненте. Т.е. через внешнюю компоненту можно устанавливать любые из более чем 200 настроек библиотеки.
Первые четыре параметра относятся к синхронному режиму. А последние три – к асинхронному:
-
acks – параметр, который отвечает за получение подтверждений от брокеров кластера. По умолчанию значение -1, а это значит, что мы ждем ответа от всех брокеров. Это немного замедляет работу, но дает значимую гарантию. Если значение 0 – значит, мы не ждем подтверждения вообще. А все, что больше нуля – это количество брокеров, от которых нужно получить ответ.
-
queue.buffering.max.ms – время накопления сообщений в буфере в миллисекундах. По умолчанию отправка в библиотеке Librdkafka производится в виде пакета – сообщения сначала накапливаются в некотором буфере до достижения определенного объема или истечения заданного времени. В синхронном режиме этот параметр можно выставить в самое маленькое значение 1 или 0, потому что мы отправляем каждое сообщение по отдельности и хотим удостовериться, что оно дошло – нам не нужно копить пакет.
-
message.timeout.ms – таймаут ожидания ответа от брокеров в миллисекундах. По умолчанию этот параметр равен 5 минутам, что для синхронного режима слишком долго. Правильнее подбирать этот параметр эмпирически – например, мы в компании ставим 5 секунд (5000 миллисекунд), и этого вполне достаточно.
-
enable.idempotence – включение идемпотентного производителя. Этот режим немного замедляет работу, но гарантирует упорядоченность доставки, исключая дублирование сообщений при сетевых сбоях или ошибках.
-
socket.nagle.disable – оптимизация работы с tcp/ip. Этот параметр зачастую помогает повысить пропускную способность – его можно оставить по умолчанию или включить, посмотреть, будет ли эффект по производительности или нет.
-
compression.codec – кодек компрессии, сжатия сообщения. Можно выбирать из четырех кодеков: «gzip», «zstd», lz4», «snappy». Причем применение этого параметра сильно влияет как на синхронный, так и на асинхронный режим, причем диаметрально по-разному. Именно это влияние я сейчас и хочу показать на замерах.
Замеры

Если обратиться к документации Librdkafka, там заявляется, что данная библиотека позволяет отправлять сотни тысяч сообщений в секунду. Я к этому отношусь скептически, потому что никто никогда не указывает в рекламных заявлениях параметры: какой размер сообщений учитывался, использовался ли кластер брокеров, применялось ли шифрование, в каких условиях работала сеть и т.д.
Для компоненты Simple Kafka я провел собственные замеры производительности на примере пакета сообщений, в котором каждое сообщение составляет 10 Кб, и отправка производится в кластер из трех брокеров.
Оказалось, что для асинхронного режима самый лучший результат получается, если мы используем сжатие пакета сообщений с применением кодека Zstd, отключаем логи и режим идемпотентного производителя. Если же мы не используем сжатие и включаем логи, мы можем потерять производительность в два раза.

А с синхронным режимом всё наоборот – там максимальная производительность достигается именно без применения сжатия.
Это логично, потому что когда мы отправляем каждое сообщение по отдельности и ждем подтверждения доставки, здесь нет никакого буфера, который можно сжимать и отправлять, тем самым экономя трафик.
Здесь показатели примерно в 8 раз ниже, но они тоже неплохие.
Особенности Producer API

Показанные ранее результаты замеров производительности – далеко не предел, потому что есть еще несколько способов ускорить отправку:
- Например, можно значительно повысить показатели за счет параллельности записи в разные партиции одного топика. За эту возможность как раз отвечает третий параметр – как в асинхронном ОтправитьСообщение(), так и в синхронном ОтправитьСообщениеСОжиданиемРезультата().
- Более того, у библиотеки Librdkafka существует более 30 показателей Producer API, за счет которых можно произвести тонкую настройку клиента. Но не стоит сразу же кидаться их менять. Можно попробовать поработать на дефолтных параметрах, посмотреть за статистикой, и уже потихоньку подкручивать параметры. Это как в спортзале – если в первый день наброситься одновременно и на кардио, и на штангу, и на бокс, последствия будут скорее вредными, чем полезными.
Теперь несколько практических нюансов, выявленных за время использования компоненты в крупных проектах:
-
Kafka по умолчанию ограничивает размер сообщений в 1Мб – это ограничение присутствует как в самой библиотеке, так и в топике брокера. А если используется XML-формат – например, при обмене по технологии КД 2.0 либо EnterpriseData – сообщения получаются значительного размера. Казалось бы – можно использовать сжатие и избавиться от этого ограничения, но нет. Размер в самой библиотеке проверяется до сжатия. А также проверяется размер сжатого сообщения в топике самим брокером. Поэтому здесь я рекомендую общий подход: в настройках топика эмпирически подобрать значения по максимальному размеру сообщения, а также можно через метод «Продюсер.УстановитьПараметр()» динамически выставлять значение параметра message.max.bytes – вычислить его, исходя из реального размера сообщения до сжатия.
-
При сжатии пакета сообщений есть важный нюанс – кодек, которым производится сжатие, можно выставить на стороне брокера через установку параметра compression.type в брокере, а можно во внешней компоненте через установку параметра compression.codec. По умолчанию берутся настройки из внешней компоненты. Но если значения кодека установлены на обеих сторонах и отличаются, брокер будет производить разархивацию, а потом сжатие кодеком. Это может значительно снизить производительность…
-
И третий нюанс – это отправка картинок, PDF и прочих двоичных данных. Мы для себя давно выработали правило – не засорять святые топики Kafka двоичными данными, которые могут спокойно храниться во внешних хранилищах – S3 или FTP. Мы применяем следующий подход: складываем файлы в S3-хранилище, а в сообщении просто указываем путь, где лежит файл.
Интерфейс Consumer API. Получение сообщений
Итак, с помощью интерфейса Producer API нашей компоненты мы уже можем отправлять сообщения из наших баз 1С в топики брокеров. Их уже могут считывать различные микросервисы, подписанные на эти топики. Но и базы 1С могут так же считывать сообщения из других систем. Для этого в компоненте предусмотрен интерфейс Consumer API.

Чтобы начать получать сообщения, достаточно установить консьюмеру параметр group.id:
УстановитьПараметр("group.id", ИмяВашейГруппы);
где ИмяВашейГруппы – строка.
Параметр group.id объединяет всех консьюмеров-подписчиков в одну группу, чтобы они могли получать сообщения из разных разделов топика. Благодаря этому параметру брокер может идентифицировать консьюмера и сохранять о нем метаинформацию во внутренних служебных топиках – например, фиксировать последнюю обработанную позицию в очереди сообщений.
Далее выполняется инициализация консьюмера с указанием брокеров через запятую. Если используется кластер, нет необходимости указывать список всех брокеров, достаточно указать одного основного, потому что брокер-лидер хранит в себе всю информацию о других брокерах кластера.
Топики при инициализации консьюмера также перечисляются через запятую. Причем если в более ранних версиях компоненты можно было подписаться в рамках одного консьюмера только на один топик, в последних релизах в рамках одного консьюмера появилась возможность чтения сообщений из нескольких топиков, что значительно экономит накладные расходы.
Процесс получения сообщений реализуется в виде бесконечного цикла Пока Истина Цикл, внутри которого консьюмер спрашивает у брокера, есть ли новые данные. Но поскольку такой цикла приводит к 100% загрузке ядра процессора, чтобы это нивелировать, в компоненте есть метод УстановитьТаймаутОжидания(Таймаут). На первый взгляд может показаться, что это некая пауза, но на самом деле это работает следующим образом:
-
Пока сообщений нет, мы проходим шаг итерации, спрашиваем, есть ли сообщения, ожидаем их в рамках установленного таймаута, и если сообщений не появляется, заходим на следующий шаг.
-
Как только сообщения начинают появляться, мы их сразу же без промедления начинаем получать методом Слушать().
Тем самым мы бережем ядро, не нагружаем его на 100%, а с другой стороны, почти мгновенно получаем сообщения, как только они начинают поступать в указанные нами топики.
При окончании работы консьюмера, когда чтение сообщений больше не требуется, необходимо использовать обязательный метод «ОстановитьКонсьюмера()», чтобы освобождалась память и консьюмер мог корректно завершить работу. Если этого не сделать – могут происходить утечки памяти.
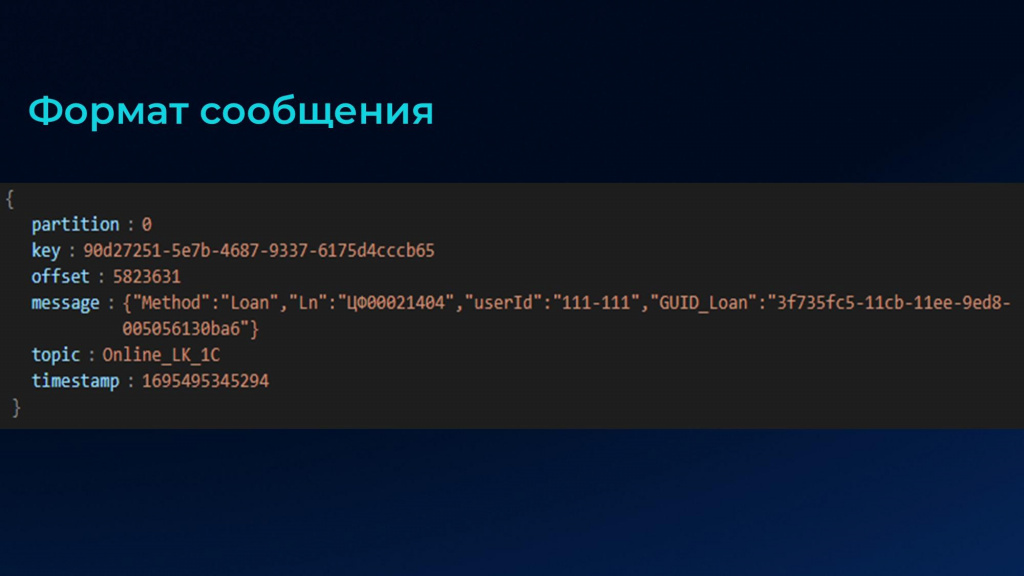
Вот так выглядят сами сообщения. Здесь помимо самого сообщения в значении ключа «message» есть еще дополнительная метаинформация, которая может пригодиться для дальнейших алгоритмов:
-
partition – номер партиции;
-
key – ключ сообщения;
-
offset – смещение;
-
topic – топик, откуда мы прочитали;
-
timestamp – временная метка/
И в последних версиях появились еще заголовки – headers.
Чтение с произвольной позиции и фиксация смещений

Когда мы из 1С впервые подключаем консьюмера к топику, он начинает читать сообщения с того момента, как подключился. За такое поведение отвечает параметр конфигурации топика auto.offset.reset, который по умолчанию = latest. Это поведение можно переопределить, задав этому параметру другие значения, например, earliest – чтение с самых ранних смещений.
Однако при дальнейшей работе – после переподключения 1С к топикам – сообщения всегда будут читаться с того места, на котором остановились в прошлый раз.
Но бывают ситуации, когда необходимо заново перечитать сообщения с определенной позиции. Для этого в компоненте реализован метод УстановитьПозициюЧтения().
Причем недавно данный метод пригодился в бою. У нас была ситуация, когда разработчик допустил ошибку в алгоритме «После загрузки данных» правил КД2, из-за чего мы на проде столкнулись с проблемами.
Вместо того чтобы писать обработки по корректировке данных, мы пошли другим путем – взяли бэкап базы до момента, когда ошибка была допущена, выявили ту позицию, начиная с которой возник сбой, вызвали указанный метод компоненты и просто перечитали сообщения с исправленным алгоритмом. Нам не пришлось писать никакие обработки по корректировке – проблема решилась за счет возможностей самой Kafka: хранения сообщений с определенными смещениями и возможность чтения с конкретной позиции.

После чтения сообщений в метаданных брокера происходит фиксация информации о прочитанном сообщении. Это делается автоматически в виде фиксации смещений.
Но это происходит не мгновенно – по умолчанию запись выполняется с задержкой в 5 секунд. И если в этот интервал консьюмер упадет или возникнут проблемы с сетью, информация о позиции может не сохраниться, и тогда при следующем подключении консьюмер начнет повторно читать уже обработанные ранее сообщения.
Есть два способа минимизировать такие ситуации:
-
Снизить интервал автофиксации – параметр auto.commit.interval.ms. По умолчанию он 5 секунд, можно поставить ниже, но это будет дополнительная нагрузка на брокер, потому что ему надо будет записывать информацию о позиции еще и в служебный топик, что повысит трафик.
-
Использовать ручную фиксацию. Иногда может возникнуть потребность не производить автоматическую фиксацию, например, в случае ошибки обработки сообщения все дальнейшие не имеют смысла. В этом случае необходимо отключить автоматическую фиксацию: enable.auto.commit = false и использовать метод ЗафиксироватьСмещение(). Здесь трафик тоже будет повыше, но мы этим уже управляем вручную – прочитали сообщение, зафиксировали его в какой-то буфер (регистр сведений или очередь) и в следующий раз считываем со следующей позиции.
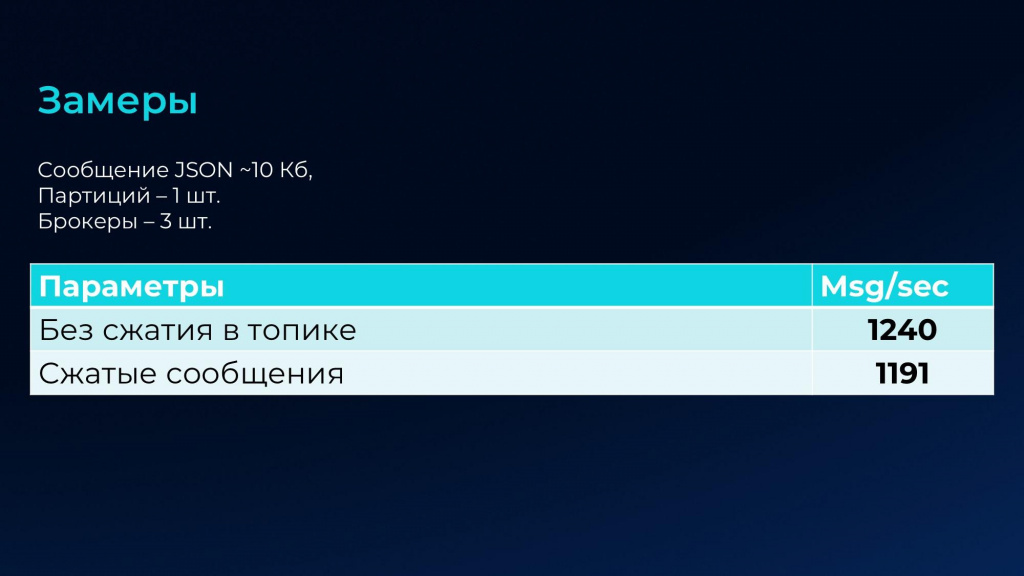
Немного цифр по замерам консьюмера, подписчика. Здесь опять же влияет сжатие, но уже незначительно: в отличие от отправки мы будем читать чуть медленнее, потому что сообщения сначала нужно разархивировать.

Особенности, в принципе, такие же как у Producer API:
-
Скорость чтения можно повысить, читая из разных разделов топика, а также за счет тонкого тюнинга через настройки библиотеки.
-
Есть нюанс – это расход оперативной памяти. Так как сообщения забираются библиотекой Librdkafka пакетами и всегда есть внутренний буфер в оперативной памяти – за памятью нужно смотреть и периодически перезапускать компоненту. У нас это делается каждые 4 часа. Переподключение в среднем происходит за 15 секунд, поэтому негативного эффекта мы не отмечали.
Интерфейс Logger API
После того как мы разобрались, как отправлять и читать сообщения, хочется рассказать о последнем интерфейсе по списку, но не последнем по значимости – это интерфейс логирования Logger API.
На первых этапах внедрения компоненты ведение логов очень желательно.
Логи можно ввести как для продюсера, так для консьюмера, а также собирать статистику работы брокера и отладочную информацию.
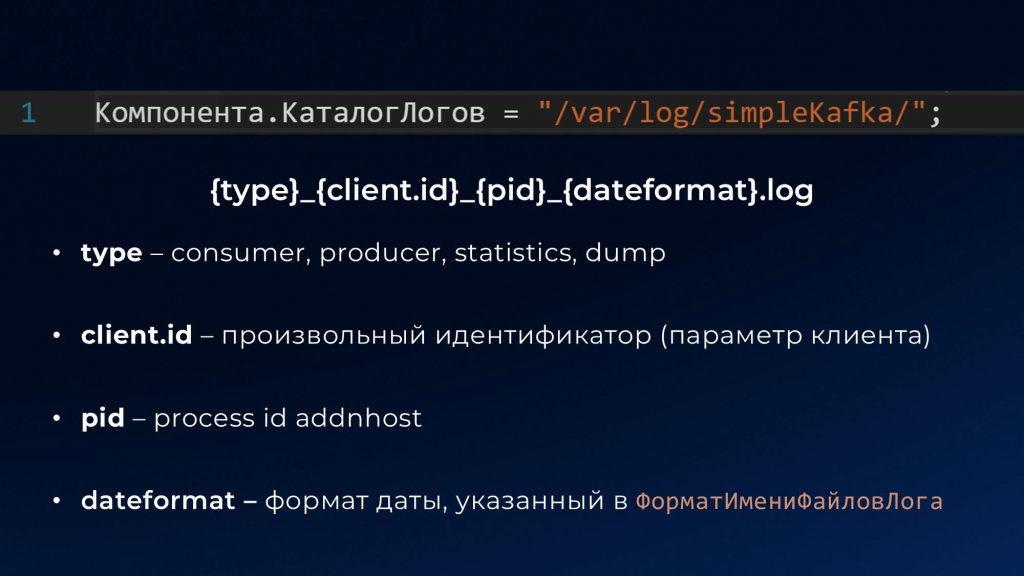
Чтобы включить логирование, достаточно указать каталог, куда будут писаться логи в компоненте:
Компонента.КаталогЛогов = "/var/log/simpleKafka/";
Логи начнут собираться автоматически.
Формат имени файла, в который будут записываться логи:
{type}_{client.id}_{pid}_{dateformat}.log
По умолчанию каждый новый файл будет создаваться раз в сутки, но это можно отрегулировать через свойство ФорматИмениФайловЛога:
Компонента.ФорматИмениФайловЛога = "%Y%m%d";
Можно сделать раз в час, раз в минуту, даже раз в секунду.

На слайде приведен пример лог-файла для Producer API.
-
Здесь первые две строчки – подтверждение о том, что мы успешно отправили сообщение с некой метаинформацией, статусом и смещением, зарегистрированными именно со стороны продюсера.
-
Третья, четвертая строчка – это ошибочная установка параметров, мы это в логах увидим.
-
И если нам брокер недоступен – это тоже отразится в логах.

Для Consumer API логи на каждое сообщение не пишутся, но в его лог-файле тоже может содержаться полезная информация.
Например, у нас был случай: при асинхронной отправке со сжатием zstd сообщения перестали корректно распаковываться. Оказалось, что проблема заключалась в баге библиотеки zlib, которая используется кодеком zstd. Мы узнали об этом только благодаря логам – сменили кодек и решили проблему.
Статистика

Иногда может быть полезно собирать статистику по работе брокеров и некоторую служебную информацию. Чтобы начать собирать это в отдельный файл, достаточно указать параметр statistics.interval.ms:
УстановитьПараметр("statistics.interval.ms", "15000");
Этот параметр не нужно ставить слишком маленьким, потому что каждая запись статистики содержит в себе порядка 200 параметров. Его значение надо подбирать эмпирически, исходя из ваших потребностей – если будете настраивать мониторинг, собирать это в ElasticSearch либо другие системы.
Также можно ввести логи самой библиотеки Librdkafka – для этого необходимо установить параметр debug и сказать события, по которым будет собираться отладочная информация (они указаны на слайде). Например, для сбора событий продюсера:
УстановитьПараметр("debug", "broker,topic,msg")
Для сбора событий консьюмера:
УстановитьПараметр("debug", "consumer,cgrp,topic,fetch")
Но учтите, что при сборке отладочной информации диск забьется очень быстро.
Заключение

Немного про условия использования компоненты.
-
Компонента полностью бесплатная.
-
Используйте как хотите – ограничений по количеству баз или пользователей нет
-
Единственный момент – на основе компоненты нельзя делать коммерческие версии продукта.

В репозитории Simple Kafka есть примеры кода 1С, с помощью которого можно достаточно быстро адаптировать 1С в мир событийной интеграции.
Интерфейс внешней компоненты предоставляет возможность обращаться ко всем параметрам, которые есть в библиотеке Librdkafka. Их порядка 200, а сейчас может даже больше. Сама библиотека постоянно обновляется, и я как автор внешней компоненты стараюсь пересобирать внешнюю компоненту, исходя из обновлений самой Librdkafka. Этих параметров во многом достаточно, чтобы делать нормальную событийную интеграцию.
Но если хочется погрузиться во внутренности Kafka, есть две интересные книги, изображенные на слайде. А также статьи:
-
Оптимизация производителей: https://strimzi.io/blog/2020/10/15/producer-tuning/
-
Оптимизация потребителей: https://strimzi.io/blog/2021/01/07/consumer-tuning/
Вопросы и ответы
Насколько стабильно компонента ведет себя на больших объемах информации?
Мы используем компоненту в проде на реальной нагрузке. Перед внедрением она обкатывается на тестовой площадке, потом мы ее портируем в прод. После выхода обновлений в самой библиотеке Librdkafka мы пересобираем компоненту, нам нужно убедиться, что она работает.
По поводу скоростей – я замеры указал.
-
При обмене с микросервисами у нас основная нагрузка – когда мы собираем клики в личном кабинете клиента. Там у нас используется асинхронный режим, потому что некоторая потеря сообщений допустима – нам не нужно собирать конкретно каждый клик.
-
А для обмена между базами 1С мы применяем синхронный режим – там будет работать медленнее в 8 раз, зато есть гарантия доставки, и мы всегда видим статус получения сообщений.
-
При массовой загрузке или повторном чтении сообщений с определенной позиции нагрузка также возрастает. Здесь время обработки зависит от того, как у вас реализована архитектура: сохраняются ли сообщения для последующей обработки или обрабатываются сразу. Допустимо и то, и другое, но в первом случае надо управлять смещениями и автофиксацией, а это сильно влияет на производительность.
А если говорить не про производительность, а именно про стабильность – на больших объемах компонента не падает, не зависает?
Компонента ведет себя достаточно надежно, но здесь могут быть проблемы в самой платформе 1С – с изолированным режимом подключения компонент. Он иногда работает не совсем корректно, из-за этого примерно раз в три дня компонента может упасть. Но у нас настроено регламентное задание, которое автоматически перезапускает процесс чтения с последней зафиксированной позиции, так что это не критично.
Причем мы нашли причину падения и зарегистрировали баг в платформе, спасибо команде Антона Дорошкевича. Там проблема была в том, что при использовании изолированного режима DLL, связанные с архивацией и чтением XLSX, начинали падать. И сама компонента тоже падала. Но с выходом новых версий стабильность постепенно улучшается, и есть надежда, что ошибка будет исправлена окончательно.
Почему вы не выбрали RabbitMQ?
RabbitMQ уже приелся, хотелось попробовать что-то новое. Kafka существует уже много лет, но в мире 1С она начала светиться только последние 7 лет.
Для каких сценариев вы используете Apache Kafka?
Для сбора метрик из личного кабинета, обмена между базами 1С, обмена между 1С и другими системами.
В open source лежит только библиотека или подсистема для 1С?
В репозитории лежит исходный код и сама собранная компонента, которую можно использовать и для Linux, и для Windows, а также есть документация и примеры 1С-ного кода.
Готовую подсистему в виде расширения или cf-файла мы не публиковали, но примеров достаточно, чтобы собрать рабочее решение.
Увидел, что храните компоненту в макете конфигурации. Почему не используете справочник «Внешние компоненты»?
Можно использовать справочник. Можно вообще разархивировать компоненту и подключать только один нужный для вашей ОС файлик. Просто нам так удобнее.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.
Также рекомендуем посмотреть мастер-класс об использовании внешней open source компоненты Simple Kafka.

Вступайте в нашу телеграмм-группу Инфостарт