Введение
С 26 версии платформы появились методы для массового изменения записей регистров сведений и накоплений, данные методы особенно востребованы в системах, где большие объемы данных, и их изменение может занимать длительное время. При использовании "старого функционала" замещения записей набора, где сначала данные удаляются, а затем записываются новые наборы по отбору измерений или регистратору, время массовой обработки данных достаточно велико, что очень негативно сказывает на общей производительности системы и увеличивает технологическое окно обслуживания. С появлением новых вариантов обработки большого объема наборов записей возможно значительно сократить время обработки. Далее рассматриваются особенности новых методов на платформе 8.3.27.1688 с использованием СУБД PostgreSQL 14.17 на тестовом примере. На ИТС описание работы новых методов здесь.
Рассмотрим пример, где у нас есть документ Расходная накладная и оборотный регистр накопления Продажи. При проведении документ делает движения в регистр Продажи, по которому менеджеры оценивают продажи.
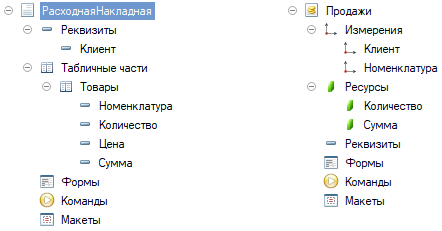
рис 1. Исходная структура метаданных
Продажи идут активно и за месяц внесено 100 000 документов. Бизнес развивается и теперь появилось новое требование, менеджерам необходимо анализировать не только стоимость продажи, но и сумму НДС, который включен в продажу. Задачу можно решать по-разному, один из вариантов состоит в том, чтобы добавить в регистр накопления Продажи новый ресурс Сумма НДС. Получим следующую структуру:
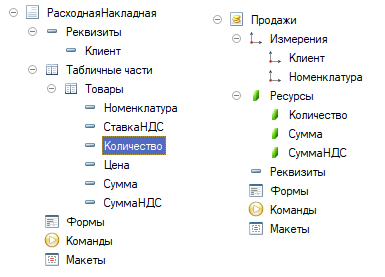
рис 2. Новая структура метаданных
Теперь необходимо обновить данные в информационной базе. С документами у нас только один способ: выбираем каждый документ, заполняем его новыми данными и записываем. В старом варианте работы мы можем только сформировать по регистратору набор с заполненными данными и вызвать запись набора в режиме замещения данных, причем только по одному регистратору. Так придется делать 100 000 раз, что очень не быстро, единственный вариант ускорения - это распараллеливания записи документов. Если предположить, что при первоначальном заполнении нам нужно ставку НДС брать из Номенклатуры, НДС всегда в цене (сложные условия расчета, ограничение выборки, распараллеливание опускаем для наглядности), то базовый код по заполнению данных может выглядеть так:
Код обработки в старом варианте
//Шаг 1 - читаем данные
Запрос = Новый Запрос;
Запрос.Текст = "ВЫБРАТЬ
| Продажи.Период КАК Период,
| Продажи.Клиент КАК Клиент,
| Продажи.Номенклатура КАК Номенклатура,
| Продажи.Количество КАК Количество,
| Продажи.Сумма КАК Сумма,
| Продажи.Сумма - ВЫБОР
| КОГДА Продажи.Номенклатура.СтавкаНДС = ЗНАЧЕНИЕ(Перечисление.СтавкиНДС.Ставка10)
| ТОГДА Продажи.Сумма / 1.1
| КОГДА Продажи.Номенклатура.СтавкаНДС = ЗНАЧЕНИЕ(Перечисление.СтавкиНДС.Ставка20)
| ТОГДА Продажи.Сумма / 1.2
| // ... Прочие ставки НДС
| ИНАЧЕ Продажи.Сумма
| КОНЕЦ КАК СуммаНДС
|ИЗ
| РегистрНакопления.Продажи КАК Продажи
|
|УПОРЯДОЧИТЬ ПО
| Продажи.Регистратор,
| Продажи.НомерСтроки
|ИТОГИ ПО
| Продажи.Регистратор";
ВыборкаРегистраторов = Запрос.Выполнить().Выбрать(ОбходРезультатаЗапроса.ПоГруппировкам);
//Шаг 2 - записываем данные
НачатьТранзакцию();
Попытка
// Этот цикл идет столько сколько документов = 100 000 раз
Пока ВыборкаРегистраторов.Следующий() Цикл
НовыйНабор = РегистрыНакопления.Продажи.СоздатьНаборЗаписей();
НовыйНабор.Отбор.Регистратор.Установить(Выборка.Ссылка);
ВыборкаЗаписей = ВыборкаРегистраторов.Выбрать();
Пока ВыборкаЗаписей.Следующий() Цикл
НоваяЗапись = НовыйНабор.Добавить();
ЗаполнитьЗначенияСвойств(НоваяЗапись, ВыборкаЗаписей);
КонецЦикла;
НовыйНабор.Записать();
КонецЦикла;
ЗафиксироватьТранзакцию();
Исключение
ОтменитьТранзакцию();
КонецПопытки;
В наилучшем варианте, когда сможем за одно чтение получить всю выборку и обновить данные у нас все равно образуется цикл, при котором вынужденны обращаться к СУБД столько раз, сколько документов надо обработать, при этом при каждой записи набора в оборотный регистр неявно происходит пересчет в таблице оборотов, что добавляет свои издержки. В худшем случае необходимо ограничивать выборку из таблицы неким объемом, при этом усложнить алгоритм так, чтобы в выборке были все записи по обрабатываемым документам. Таким образом, для казалось бы простой операции с позиции SQL массового обновления:
update НашаТаблица set СуммаНДС = ... where ....
приходится организовывать непростой алгоритм. Примером тому может служить архитектура расчета себестоимости в УТ/КА/ЕРП, где регламентной процедурой расчета себестоимости результат расчета дописывается к документам расхода (продажи) и возникает ровно такая же проблема - запись наборов регистра накопления в цикле. Новые операции как раз и призваны максимально уменьшить использование циклов при записи данных в СУБД. Далее рассмотри применимость трех новых вариантов замещения данных в наборах регистра.
Режим замещения Обновление
Для использования данного режима потребуется в наборе регистра включить расширенный режим замещения и сбросить отбор:
Набор = РегистрыНакопления.Продажи.СоздатьНаборЗаписей();
Набор.РасширенныеРежимыЗамещения = Истина;
Набор.Отбор.Сбросить(); // необходимо использовать так как у набора в структуре Отбор
//свойство Использовать отбора Регистратор по умолчанию включено
//...Заполнение набора
Набор.Записать(РежимЗамещения.Обновление);
Получившийся набор - это просто записи, которые будут обновлены в таблице по совпадающим ключам (для регистра накопления это Регистратор и НомерСтроки), ранее разработчики не управляли полем НомерСтроки, а теперь его необходимо заполнять, чтобы уникально определить строку, которую потребуется обновить. По сути, свойство РасширенныеРежимыЗамещения переключает поле НомерСтроки в режим редактирования. Так же необходимо, чтобы при обновлении присутствовали все поля, выборочно обновить только нужные поля нельзя, код получится таким:
//Шаг 1 - читаем данные
Запрос = Новый Запрос;
Запрос.Текст = "ВЫБРАТЬ
| Продажи.Регистратор КАК Регистратор,
| Продажи.НомерСтроки КАК НомерСтроки,
| Продажи.Клиент КАК Клиент,
| Продажи.Номенклатура КАК Номенклатура,
| Продажи.Количество КАК Количество,
| Продажи.Сумма КАК Сумма,
| Продажи.Сумма - ВЫБОР
| КОГДА Продажи.Номенклатура.СтавкаНДС = ЗНАЧЕНИЕ(Перечисление.СтавкиНДС.Ставка10)
| ТОГДА Продажи.Сумма / 1.1
| КОГДА Продажи.Номенклатура.СтавкаНДС = ЗНАЧЕНИЕ(Перечисление.СтавкиНДС.Ставка20)
| ТОГДА Продажи.Сумма / 1.2
| // ... Прочие ставки НДС
| ИНАЧЕ Продажи.Сумма
| КОНЕЦ КАК СуммаНДС
|ИЗ
| РегистрНакопления.Продажи КАК Продажи";
ВыборкаЗаписей = Запрос.Выполнить().Выбрать();
//Шаг 2 - записываем данные
НовыйНабор = РегистрыНакопления.Продажи.СоздатьНаборЗаписей();
НовыйНабор.РасширенныеРежимыЗамещения = Истина;
НовыйНабор.Отбор.Сбросить();
Пока ВыборкаЗаписей.Следующий() Цикл
НоваяЗапись = НовыйНабор.Добавить();
ЗаполнитьЗначенияСвойств(НоваяЗапись, ВыборкаЗаписей);
КонецЦикла;
НовыйНабор.Записать(РежимЗамещения.Обновление);
Код стал выглядеть проще и наглядней и теперь хочется увидеть, что он ровно делает то, что от него ожидается. По технологическому журналу соберем события работы с СУБД и с управляемыми блокировками, на небольшом объеме данных (2 документа по 6 номенклатур в каждом) увидим следующее:
Часть технологического журнала, показывающая обновление большого количества строк
AccumRg110 - основная таблица регистра накопления Продажи
Period - Период, Recorder - Регистратор, LineNo - Номер строки, Active - Активность, Fld111 - Клиент, Fld112 - Номенклатура, Fld113 - Количество , Fld114 - Сумма, Fld128 - СуммаНДС,
AccumRgTn115 - таблица оборотов регистра накопления Продажи
Period - Период, Fld111 - Клиент, Fld112 - Номенклатура, Fld113 - Количество, Fld114 - Сумма, Fld128 - СуммаНДС, Splitter - Спллитер
// Устанавливается эксклюзивная блокировка по регистраторам
07:40.550058-5,TLOCK,5,Regions=AccumRg110.RECORDER,
Locks='AccumRg110.RECORDER Exclusive Recorder=102:b4f92887bae1b3dd11f0ad1ff1223127,
AccumRg110.RECORDER Exclusive Recorder=102:b4f92887bae1b3dd11f0ad2077bfd9cd'
// Определяется максимальный номер строки по регистраторам, видимо, необходим для внутренней логики,
// в целом не очень ясно зачем для обновления получать максимальный номер строки по регистратору
07:40.550062-1,DBPOSTGRS,Sql='SELECT
T1._RecorderRRef,
MAX(T1._LineNo),
BOOL_OR(T1._Active)
FROM _AccumRg110 T1
WHERE (T1._RecorderRRef IN ('\\264\\371(\\207\\272\\341\\263\\335\\021\\360\\255\\037\\361""1'''::bytea, '\\264\\371(\\207\\272\\341\\263\\335\\021\\360\\255 w\\277\\331\\315'::bytea))
GROUP BY T1._RecorderRRef'
// Подготавливается временная таблица по нашем набору
07:40.550082-1,DBPOSTGRS,
Sql='drop table if exists pg_temp.tt2 cascade;create temporary table tt2 (_Period timestamp, _RecorderRRef bytea, _LineNo numeric(9, 0), _Active boolean, _Fld111RRef bytea, _Fld112RRef bytea, _Fld113 numeric(10, 2), _Fld114 numeric(10, 2), _Fld128 numeric(10, 2) ) without oids '
07:40.550091-1,DBPOSTGRS,Func=quickInsert,tableName=pg_temp.tt2,Sql=COPY pg_temp.tt2 FROM STDIN BINARY,RowsAffected=12
07:40.550093-1,DBPOSTGRS,Sql=ANALYZE pg_temp.tt2
// Запрос соединяет данные в регистре с нашим набором, это используется для проверки,
// чтобы те данные, что мы указали, присутствуют в исходной таблице
07:40.566000-15903,DBPOSTGRS, Sql='SELECT
T1._Period,
T1._RecorderRRef,
T1._LineNo,
T1._Active,
T1._Fld111RRef,
T1._Fld112RRef,
T1._Fld113,
T1._Fld114,
T1._Fld128
FROM _AccumRg110 T1
INNER JOIN pg_temp.tt2 T2
ON T1._RecorderRRef = T2._RecorderRRef AND T1._LineNo = T2._LineNo
ORDER BY T1._RecorderRRef, T1._LineNo'
// Эксклюзивная блокировка на пространство набора записей по измерениям
07:40.566017-5,TLOCK,Regions=AccumRg110.DIMS,Locks='AccumRg110.DIMS Exclusive
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad1fa3cfe76c Fld112=47:b4f92887bae1b3dd11f0ad1fb820a723 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad1fa3cfe76c Fld112=47:b4f92887bae1b3dd11f0ad1fc28dd677 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad1fa3cfe76c Fld112=47:b4f92887bae1b3dd11f0ad1fc91d4358 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad1fa3cfe76c Fld112=47:b4f92887bae1b3dd11f0ad1fd364daaa Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad1fa3cfe76c Fld112=47:b4f92887bae1b3dd11f0ad1fb820a722 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad1fa3cfe76c Fld112=47:b4f92887bae1b3dd11f0ad1fb05f9a47 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad206d4d23fe Fld112=47:b4f92887bae1b3dd11f0ad1fb820a723 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad206d4d23fe Fld112=47:b4f92887bae1b3dd11f0ad1fc28dd677 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad206d4d23fe Fld112=47:b4f92887bae1b3dd11f0ad1fc91d4358 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad206d4d23fe Fld112=47:b4f92887bae1b3dd11f0ad1fd364daaa Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad206d4d23fe Fld112=47:b4f92887bae1b3dd11f0ad1fb820a722 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad206d4d23fe Fld112=47:b4f92887bae1b3dd11f0ad1fb05f9a47 Period=T"20251001000000"'
// Зачем-то второй раз тоже самое
07:40.566025-5,TLOCK,5,Regions=AccumRg110.DIMS,Locks='AccumRg110.DIMS Exclusive
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad1fa3cfe76c Fld112=47:b4f92887bae1b3dd11f0ad1fb820a723 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad1fa3cfe76c Fld112=47:b4f92887bae1b3dd11f0ad1fc28dd677 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad1fa3cfe76c Fld112=47:b4f92887bae1b3dd11f0ad1fc91d4358 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad1fa3cfe76c Fld112=47:b4f92887bae1b3dd11f0ad1fd364daaa Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad1fa3cfe76c Fld112=47:b4f92887bae1b3dd11f0ad1fb820a722 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad1fa3cfe76c Fld112=47:b4f92887bae1b3dd11f0ad1fb05f9a47 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad206d4d23fe Fld112=47:b4f92887bae1b3dd11f0ad1fb820a723 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad206d4d23fe Fld112=47:b4f92887bae1b3dd11f0ad1fc28dd677 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad206d4d23fe Fld112=47:b4f92887bae1b3dd11f0ad1fc91d4358 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad206d4d23fe Fld112=47:b4f92887bae1b3dd11f0ad1fd364daaa Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad206d4d23fe Fld112=47:b4f92887bae1b3dd11f0ad1fb820a722 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad206d4d23fe Fld112=47:b4f92887bae1b3dd11f0ad1fb05f9a47 Period=T"20251001000000"'
// Всегда обновляются все поля по ключу (Регистратор + НомерСтроки)
07:40.566029-1,DBPOSTGRS, Sql='UPDATE _AccumRg110 SET
_Period = T2._Period, _Active = T2._Active, _Fld111RRef = T2._Fld111RRef, _Fld112RRef = T2._Fld112RRef, _Fld113 = T2._Fld113, _Fld114 = T2._Fld114, _Fld128 = T2._Fld128
FROM pg_temp.tt2 T2
WHERE _AccumRg110._RecorderRRef = T2._RecorderRRef AND _AccumRg110._LineNo = T2._LineNo'
// Подготовка временных таблиц для обновления таблицы оборотов
07:40.566034-1,DBPOSTGRS,Sql='drop table if exists pg_temp.tt3 cascade;create temporary table tt3 (_Period timestamp, _Fld111RRef bytea, _Fld112RRef bytea, _Fld113 numeric(16, 2), _Fld114 numeric(16, 2), _Fld128 numeric(16, 2) ) without oids
07:40.566043-1,DBPOSTGRS, Func=quickInsert,tableName=pg_temp.tt3,Sql=COPY pg_temp.tt3 FROM STDIN BINARY
07:40.566052-1,DBPOSTGRS, Sql='drop table if exists pg_temp.tt4 cascade;create temporary table tt4 (_Period timestamp, _Fld111RRef bytea, _Fld112RRef bytea, _Fld113 numeric(22, 2), _Fld114 numeric(22, 2), _Fld128 numeric(22, 2) ) without oids
07:40.566056-1,DBPOSTGRS,Sql='INSERT INTO pg_temp.tt4 (_Period, _Fld111RRef, _Fld112RRef, _Fld113, _Fld114, _Fld128) SELECT
date_trunc('month',T1._Period),
T1._Fld111RRef,
T1._Fld112RRef,
SUM(T1._Fld113),
SUM(T1._Fld114),
SUM(T1._Fld128)
FROM pg_temp.tt3 T1
GROUP BY date_trunc('month',T1._Period),
T1._Fld111RRef,
T1._Fld112RRef'
// Обновление таблицы оборотов
07:40.566064-1,DBPOSTGRS, Sql='UPDATE _AccumRgTn115 SET _Fld113 = _AccumRgTn115._Fld113 + T2._Fld113, _Fld114 = _AccumRgTn115._Fld114 + T2._Fld114, _Fld128 = _AccumRgTn115._Fld128 + T2._Fld128
FROM pg_temp.tt4 T2
WHERE T2._Period = _AccumRgTn115._Period AND T2._Fld111RRef = _AccumRgTn115._Fld111RRef AND T2._Fld112RRef = _AccumRgTn115._Fld112RRef AND _AccumRgTn115._Splitter = CAST(0 AS NUMERIC)'
Из запросов видно, что все достаточно компактно: 1С сама наложит эксклюзивные управляемые блокировки на нужные пространства, сформирует из наших записей временную таблицу и в один запрос запустить обновление таблицы, при этом обновление итогов (таблица оборотов) также будет выполнено в один запрос.
Теперь попробуем сделать тоже самое с замером времени, сгенерируем 100 000 документов, в каждом также по 6 товаров. Итого в регистре накопления Продажи будет 600 000. Запустим обновление и получим такие характеристики:
Количество записей к обновлению: 600 000.
Время выполнения транзакции: 42 сек.
Количество обращений к СУБД: 424, время работы запросов составило 23 сек.
Остается 19 сек, на некие события, да и количество запросов интуитивно много, посмотрим, что в технологическом журнале.
AccumRg110 - основная таблица регистра накопления Продажи
Period - Период
Recorder - Регистратор
LineNo - Номер строки
Active - Активность
Fld111 - Клиент
Fld112 - Номенклатура
Fld113 - Количество
Fld114 - Сумма
Fld128 - СуммаНДС
// Устанавливается блокировкп по всем регистраторам
24:25.976003-313003,TLOCK,Regions=AccumRg110.RECORDER,Locks='
AccumRg110.RECORDER Exclusive Recorder=102:b4f92887bae1b3dd11f0ad1ff1223127,
AccumRg110.RECORDER Exclusive Recorder=102:b4f92887bae1b3dd11f0ad2077bfd9cd
...
// Срабатывает эскалация и блокируется весь регистр
24:25.991005-5,TLOCK, Regions=AccumRg110.RECORDER,Locks=AccumRg110.RECORDER Exclusive,escalating=true
// Непонятный запрос, но не все регистраторы, а сгруппировано по 256 штук
24:26.070000-46999,DBPOSTGRS, Sql="SELECT
T1._RecorderRRef,
MAX(T1._LineNo),
BOOL_OR(T1._Active)
FROM _AccumRg110 T1
WHERE (T1._RecorderRRef IN ('\\264\\371(\\207\\272\\341\\263\\335\\021\\360\\255\\037\\361""1'''::bytea, ...
...'\\264\\372(\\207\\272\\341\\263\\335\\021\\360\\255\\361%By\\256'::bytea))
GROUP BY T1._RecorderRRef",RowsAffected=256
// RowsAffected=256 - обработано 256 строк
// Таких запросов 391 шт, последний
24:45.366000-45996,DBPOSTGRS,
T1._RecorderRRef,
MAX(T1._LineNo),
BOOL_OR(T1._Active)
FROM _AccumRg110 T1
WHERE (T1._RecorderRRef IN ( ...
GROUP BY T1._RecorderRRef"
// Таким образом, 24:45-24:26 = 19 сек ушло на некий внутрений алгоритм, который обрабатывает по 256 регистраторов
// Запрос соединяет данные в регистре с нашим набором, это используется для проверки,
// чтобы те данные, что мы указали, присутствуют в исходной таблице
24:51.429000-1046989,DBPOSTGRS, Sql='SELECT
T1._Period,
T1._RecorderRRef,
T1._LineNo,
T1._Active,
T1._Fld111RRef,
T1._Fld112RRef,
T1._Fld113,
T1._Fld114,
T1._Fld128
FROM _AccumRg110 T1
INNER JOIN pg_temp.tt2 T2
ON T1._RecorderRRef = T2._RecorderRRef AND T1._LineNo = T2._LineNo
ORDER BY T1._RecorderRRef, T1._LineNo'
// Эксклюзивная блокировка на пространство набора записей всего регистра, сработала эскалация. Снова наложилась два раза
24:53.507020-5,TLOCK, Regions=AccumRg110.DIMS,Locks=AccumRg110.DIMS Exclusive
24:53.507024-1,TLOCK, Regions=AccumRg110.DIMS,Locks=AccumRg110.DIMS Exclusive,alreadyLocked=true
// Само обновление записей
24:57.445000-3937969,DBPOSTGRS,Sql='UPDATE _AccumRg110 SET _Period = T2._Period, _Active = T2._Active, _Fld111RRef = T2._Fld111RRef, _Fld112RRef = T2._Fld112RRef, _Fld113 = T2._Fld113, _Fld114 = T2._Fld114, _Fld128 = T2._Fld128
FROM pg_temp.tt2 T2
WHERE _AccumRg110._RecorderRRef = T2._RecorderRRef AND _AccumRg110._LineNo = T2._LineNo'
// Дальше подготовка обновление таблицы итогов и само обновление, так же как и в предыдущем варианте
Внутри платформа так же использует порционную обработку данных, но при это ключевое обновление данных реализовано в 1 запрос, на мой взгляд объем возвращаемых данных по 256 строк достаточно мал и это число явно можно увеличить, иначе получаются те же запросы в цикле, но уже самой платформой, хоть и в 256 раз меньше. В нашем случае получилось, что циклический перебор пачек по 256 регистраторов занял половину времени всей процедуры, что не может не вызывать грусть.
Режим замещения Удаление
Для режима замещения Удаление так же потребуется установка свойства набора РасширенныеРежимыЗамещения в Истину и сбросить отбор, а далее необходимо заполнить набор строками-ключами для удаления. После удаления может нарушиться нумерация строк в наборе, но платформа берет на себя этот момент и выровняет номера по порядку, поэтому в документации делается аккуратное замечание, что не стоит строить логику на номерах строк набора записей подчиненного регистратору. Чтобы протестировать данный функционал и посмотреть, что происходить на уровне СУБД, реализуем следующий код: предположим, что при формировании допустили ошибку и каждая строка в табличной части была задублирована по порядку при записи в регистр, тогда получается, что в наборе каждая четная строка ошибочная, которую нужно удалить. Новый подход к работе с наборами позволяет избежать множественных перезаписей набора, код для удаления будет выглядеть так:
//Шаг 1 - читаем данные
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| Продажи.Регистратор КАК Регистратор,
| Продажи.НомерСтроки КАК НомерСтроки
|ИЗ
| РегистрНакопления.Продажи КАК Продажи
|ГДЕ
| Продажи.НомерСтроки / 2 = ЦЕЛ(Продажи.НомерСтроки / 2)";
РезультатЗапроса = Запрос.Выполнить().Выбрать();
//Шаг 2 - формируем набор к удалению и удаляем данные
Набор = РегистрыНакопления.Продажи.СоздатьНаборЗаписей();
Набор.РасширенныеРежимыЗамещения = Истина;
Набор.Отбор.Сбросить();
Пока РезультатЗапроса.Следующий() Цикл
НоваяЗапись = Набор.Добавить();
ЗаполнитьЗначенияСвойств(НоваяЗапись, РезультатЗапроса);
КонецЦикла;
Набор.Записать(РежимЗамещения.Удаление);
Результат работы по технологическому журналу:
Часть технологического журнала, показывающая SQL запросы по удалению строк
AccumRg110 - основная таблица регистра накопления Продажи
Period - Период, Recorder - Регистратор, LineNo - Номер строки, Active - Активность, Fld111 - Клиент, Fld112 - Номенклатура, Fld113 - Количество , Fld114 - Сумма, Fld128 - СуммаНДС,
AccumRgTn115 - таблица оборотов регистра накопления Продажи
Period - Период, Fld111 - Клиент, Fld112 - Номенклатура, Fld113 - Количество, Fld114 - Сумма, Fld128 - СуммаНДС, Splitter - Спллитер
// Установка управляемой блокировки на основную таблицу регистра Продажи по пространству набора записей
13:13.962056-5,TLOCK, Regions=AccumRg110.RECORDER,Locks='
AccumRg110.RECORDER Exclusive Recorder=102:b4f92887bae1b3dd11f0ad1ff1223127,
AccumRg110.RECORDER Exclusive Recorder=102:b4f92887bae1b3dd11f0ad2077bfd9cd'
// Подготовка временной таблицы по нашему набору записей
13:13.978014-1,DBPOSTGRS,Sql='drop table if exists pg_temp.tt2 cascade;create temporary table
tt2 (_Period timestamp, _RecorderRRef bytea, _LineNo numeric(9, 0), _Active boolean, _Fld111RRef bytea, _Fld112RRef bytea, _Fld113 numeric(10, 2), _Fld114 numeric(10, 2),
_Fld128 numeric(10, 2) ) without oids'
// Часть для внутренного алгоритма - определяется количество записей, минимальный период по регистратору и номеру строки
// по основной таблице Продаж в разрезе признака активности/не активности записей
13:13.978030-1,DBPOSTGRS,Sql='SELECT
T1._Active,
COUNT(*),
MIN(T1._Period)
FROM _AccumRg110 T1
INNER JOIN pg_temp.tt2 T2
ON T1._RecorderRRef = T2._RecorderRRef AND T1._LineNo = T2._LineNo
GROUP BY T1._Active'
// Формируется временная таблица по нашему набору и соединяется с основной таблицей, при этом значение ресурс
// инвертируется по знаку для обновления таблицы оборотов
13:13.978039-1,DBPOSTGRS, Sql='INSERT INTO pg_temp.tt3 (_Period, _RecorderRRef, _LineNo, _Active, _Fld111RRef, _Fld112RRef, _Fld113, _Fld114, _Fld128) SELECT
T1._Period,
T1._RecorderRRef,
T1._LineNo,
T1._Active,
T1._Fld111RRef,
T1._Fld112RRef,
-T1._Fld113,
-T1._Fld114,
-T1._Fld128
FROM _AccumRg110 T1
INNER JOIN pg_temp.tt2 T2
ON T1._RecorderRRef = T2._RecorderRRef AND T1._LineNo = T2._LineNo
WHERE T1._Active = TRUE'
// Устанавливается эксклюзивная блокировка по измерениям регистра Продажи
13:13.978069-5,TLOCK, Regions=AccumRg110.DIMS,Locks='AccumRg110.DIMS Exclusive
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad1fa3cfe76c Fld112=47:b4f92887bae1b3dd11f0ad1fc28dd677 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad1fa3cfe76c Fld112=47:b4f92887bae1b3dd11f0ad1fd364daaa Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad1fa3cfe76c Fld112=47:b4f92887bae1b3dd11f0ad1fb05f9a47 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad206d4d23fe Fld112=47:b4f92887bae1b3dd11f0ad1fc28dd677 Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad206d4d23fe Fld112=47:b4f92887bae1b3dd11f0ad1fd364daaa Period=T"20251001000000",
Splitter=0 Fld111=61:b4f92887bae1b3dd11f0ad206d4d23fe Fld112=47:b4f92887bae1b3dd11f0ad1fb05f9a47 Period=T"20251001000000"'
// Далее подгтовливаются данные для обновления таблицы оборотов регистра Продажи
13:13.993004-1,DBPOSTGRS, Sql='INSERT INTO pg_temp.tt4 (_Period, _Fld111RRef, _Fld112RRef, _Fld113, _Fld114, _Fld128) SELECT
date_trunc('month',T1._Period),
T1._Fld111RRef,
T1._Fld112RRef,
SUM(T1._Fld113),
SUM(T1._Fld114),
SUM(T1._Fld128)
FROM pg_temp.tt3 T1
GROUP BY date_trunc('month',T1._Period),
T1._Fld111RRef,
T1._Fld112RRef'
// Обновление итогов в таблице оборотов
13:13.993012-1,DBPOSTGRS, Sql='UPDATE _AccumRgTn115 SET _Fld113 = _AccumRgTn115._Fld113 + T2._Fld113, _Fld114 = _AccumRgTn115._Fld114 + T2._Fld114, _Fld128 = _AccumRgTn115._Fld128 + T2._Fld128
FROM pg_temp.tt4 T2
WHERE T2._Period = _AccumRgTn115._Period AND T2._Fld111RRef = _AccumRgTn115._Fld111RRef AND T2._Fld112RRef = _AccumRgTn115._Fld112RRef AND _AccumRgTn115._Splitter = CAST(0 AS NUMERIC)'
// Удаление строк из основной таблицы
13:13.993029-1,DBPOSTGRS, Sql='DELETE FROM _AccumRg110 T1
WHERE EXISTS(SELECT 1
FROM pg_temp.tt2 T2
WHERE (T1._RecorderRRef = T2._RecorderRRef) AND (T1._LineNo = T2._LineNo))'
// Обновление номеров строк
13:13.993050-1,DBPOSTGRS, Sql='UPDATE _AccumRg110 SET _LineNo = _AccumRg110._LineNo - T2._Shift
FROM pg_temp.tt5 T2
WHERE _AccumRg110._RecorderRRef = T2._RecorderRRef AND _AccumRg110._LineNo >= T2._LowerLineNo AND _AccumRg110._LineNo <= T2._UpperLineNo'
По запросам видно, что проверки существования ключей перед удалением не происходит, в отличие от режима Обновление. Так же виден один запрос, по обновлению нумерации строк. Временная таблица, по которой определяется на сколько (Shift) надо уменьшить номер строки, чтобы вернуться к порядку, рассчитывается на стороне платформы.
Проверим то же самое на 600 000 записях, будем также удалять четные позиции, получаем:
Количество записей к удалению: 300 000.
Время выполнения транзакции: 7.9 сек., время работы запросов: 7.1 сек.
Часть технологического журнала при удалении большого количества строк
AccumRg110 - основная таблица регистра накопления Продажи
Period - Период, Recorder - Регистратор, LineNo - Номер строки, Active - Активность, Fld111 - Клиент, Fld112 - Номенклатура, Fld113 - Количество , Fld114 - Сумма, Fld128 - СуммаНДС,
AccumRgTn115 - таблица оборотов регистра накопления Продажи
Period - Период, Fld111 - Клиент, Fld112 - Номенклатура, Fld113 - Количество, Fld114 - Сумма, Fld128 - СуммаНДС, Splitter - Спллитер
// Установка блокировки по регистраторам
47:13.531003-297003,TLOCK,Regions=AccumRg110.RECORDER,Locks='
AccumRg110.RECORDER Exclusive Recorder=102:b4f92887bae1b3dd11f0ad1ff1223127,
AccumRg110.RECORDER Exclusive Recorder=102:b4f92887bae1b3dd11f0ad2077bfd9cd,
...'
// Сработала эскалация и заблокирован весь регистр по пространству регистратора
47:13.546005-5,TLOCK, Regions=AccumRg110.RECORDER,Locks=AccumRg110.RECORDER Exclusive,escalating=true
// Подготовка обновления таблицы итогов
47:16.203000-265994,DBPOSTGRS,Sql='SELECT
T1._Active,
COUNT(*),
MIN(T1._Period)
FROM _AccumRg110 T1
INNER JOIN pg_temp.tt2 T2
ON T1._RecorderRRef = T2._RecorderRRef AND T1._LineNo = T2._LineNo
GROUP BY T1._Active
// Обновление таблицы итогов
47:16.828005-1,DBPOSTGRS,Sql='UPDATE _AccumRgTn115 SET _Fld113 = _AccumRgTn115._Fld113 + T2._Fld113, _Fld114 = _AccumRgTn115._Fld114 + T2._Fld114, _Fld128 = _AccumRgTn115._Fld128 + T2._Fld128
FROM pg_temp.tt4 T2
WHERE T2._Period = _AccumRgTn115._Period AND T2._Fld111RRef = _AccumRgTn115._Fld111RRef AND T2._Fld112RRef = _AccumRgTn115._Fld112RRef AND _AccumRgTn115._Splitter = CAST(0 AS NUMERIC)'
// Удаление строк в основной таблице
47:17.640000-811979,DBPOSTGRS,Sql='DELETE FROM _AccumRg110 T1
WHERE EXISTS(SELECT
1
FROM pg_temp.tt2 T2
WHERE (T1._RecorderRRef = T2._RecorderRRef) AND (T1._LineNo = T2._LineNo))'
// Обновление номеров строк после удаления строк
47:21.390000-2655994,DBPOSTGRS, Sql='UPDATE _AccumRg110 SET _LineNo = _AccumRg110._LineNo - T2._Shift
FROM pg_temp.tt5 T2
WHERE _AccumRg110._RecorderRRef = T2._RecorderRRef AND _AccumRg110._LineNo >= T2._LowerLineNo AND _AccumRg110._LineNo <= T2._UpperLineNo'
Удаление большого объема без вложенных циклов, практически все потраченное время - это исполнение запросов, что и ожидается.
Режим замещения Слияние
В результате слияния будет выполнено две операции: обновлены строки, совпадающие по ключам, и добавлены записи, которые не были найдены по ключам. Не работает для регистров, подчиненных регистратору, поэтому на нашем примере с регистром накопления не проверить. Сделаем регистр сведений, который будет хранить оперативный остаток по номенклатуре в разрезе складов и каждый раз, когда будет делать некий документ делать движения по складу мы будет производить расчет текущий остатков и записывать в данных регистр сведений. Такая таблица позволит эффективно строить рабочие места с динамическими списками, где нужно отражать текущий остаток по складу. Данная таблица по сути аналогична регистру сведений РаспределениеЗапасов из ЕРП/КА/УТ систем, который показывает текущий срез по запасам (резерв, остаток, доступность и т.д.). Режим замещения Слияние позволит избавиться от множества наборов, которые надо записать, обновляя и дополняя остатки по списку номенклатуры.
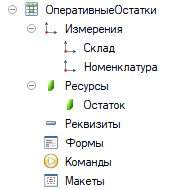
рис 3. Структура регистра оперативных остатков
Проверку организуем следующим образом, предварительно заполним регистр ОперативныеОстатки частью данных, чтобы были совпадающие ключ для обновления, а затем в режиме замещения Слияние добавим записи по всем номенклатурам. Псевдокод использования режима замещения Слияние:
Набор = РегистрыСведений.ОперативныеОстатки.СоздатьНаборЗаписей();
//РасширенныеРежимыЗамещения - указывать не нужно
//Отбор по умолчанию пустой
//... Заполняем набор данными
//Записываем набор
Набор.Записать(РежимЗамещения.Слияние);
Результат работы по технологическому журналу:
Часть технологического журнала, показывающая SQL запросы по слиянию записей в регистре
InfoRg131 - Регистр сведений Оперативные остатки
Fld132 - Склад, Fld133 - Номенклатура, Fld134 - Остаток
// Установка эксклюзивной управляемой блокировки по комбинации измерений из нашего набора
14:22.166013-9,TLOCK, Regions=InfoRg131.DIMS,Locks='
InfoRg131.DIMS Exclusive Fld132=130:b4fa2887bae1b3dd11f0ade88df8f239 Fld133=47:b4f92887bae1b3dd11f0ad1fc91d4358,
Fld132=130:b4fa2887bae1b3dd11f0ade88df8f239 Fld133=47:b4f92887bae1b3dd11f0ad1fb820a722,
Fld132=130:b4fa2887bae1b3dd11f0ade88df8f239 Fld133=47:b4f92887bae1b3dd11f0ad1fd364daaa,
// Подготовка временной таблицы по нашему набору
14:22.166029-1,DBPOSTGRS, Func=quickInsert,tableName=pg_temp.tt4,Sql=COPY pg_temp.tt4 FROM STDIN BINARY
// Обновление записей в регистре сведений, обновляются только ресурсы и реквизиты
14:22.166036-1,DBPOSTGRS,Sql='UPDATE _InfoRg131 SET _Fld134 = T2._Fld134
FROM pg_temp.tt4 T2
WHERE T2._Fld132RRef = _InfoRg131._Fld132RRef AND T2._Fld133RRef = _InfoRg131._Fld133RRef'
// Вставка новых значений, которых не существует в таблице
14:22.166041-1,DBPOSTGRS, Sql='INSERT INTO _InfoRg131 (_Fld132RRef, _Fld133RRef, _Fld134) SELECT
T1._Fld132RRef,
T1._Fld133RRef,
T1._Fld134
FROM pg_temp.tt4 T1
WHERE NOT (EXISTS(SELECT
CAST(1 AS NUMERIC)
FROM _InfoRg131 T2
WHERE T1._Fld132RRef = T2._Fld132RRef AND T1._Fld133RRef = T2._Fld133RRef))'
Код работы платформы по слиянию набора и регистра сведений в запросах выглядит интуитивно понятно из-за того, что не содержит таблиц итогов (не надо обрабатывать связанные данные) и нет подчинения к регистратору (не надо следить за номерами строк). В целом, такая комбинация запросов должна исполняться максимально эффективно в рамках архитектуры платформы.
Теперь попробуем произвести слияние остатков по всем уникальным номенклатурам, количество таких 28 434, количество записей в регистре до слияния 10 004. Таким образом, 10 004 должны быть обновление и 18 430 будут добавлены.
Результат работы по технологическому журналу:
Часть технологического журнала, слияние большого объема данных
InfoRg131 - Регистр сведений Оперативные остатки
Fld132 - Склад, Fld133 - Номенклатура, Fld134 - Остаток
// Установка эксклюзивной управляемой блокировки по комбинации измерений из нашего набора
25:27.949004-125004,TLOCK,Regions=InfoRg131.DIMS,Locks='InfoRg131.DIMS Exclusive
Fld132=130:b4fa2887bae1b3dd11f0ade88df8f239 Fld133=47:b50104421a2b171f11f0b29daff7feba,
Fld132=130:b4fa2887bae1b3dd11f0ade88df8f239 Fld133=47:b50104421a2b171f11f0b29d5c653e0a,
Fld132=130:b4fa2887bae1b3dd11f0ade88df8f239 Fld133=47:b50104421a2b171f11f0b29dcdd1752e,
....
// Подготовка временной таблицы по нашему набору
25:28.042000-61996,DBPOSTGRS,Func=quickInsert,tableName=pg_temp.tt2,
Sql=COPY pg_temp.tt2 FROM STDIN BINARY
// Обновление 10004 записей
25:28.105000-30999,DBPOSTGRS,Sql='UPDATE _InfoRg131 SET _Fld134 = T2._Fld134
FROM pg_temp.tt2 T2
WHERE T2._Fld132RRef = _InfoRg131._Fld132RRef AND T2._Fld133RRef = _InfoRg131._Fld133RRef'
// Добавление новых 18430 записей
25:28.152000-46996,DBPOSTGRS,Sql='INSERT INTO _InfoRg131 (_Fld132RRef, _Fld133RRef, _Fld134) SELECT
T1._Fld132RRef,
T1._Fld133RRef,
T1._Fld134
FROM pg_temp.tt2 T1
WHERE NOT (EXISTS(SELECT
CAST(1 AS NUMERIC)
FROM _InfoRg131 T2
WHERE T1._Fld132RRef = T2._Fld132RRef AND T1._Fld133RRef = T2._Fld133RRef))'
Время выполнения транзакции: 1.75 сек., время работы запросов составило 0.16 сек.
В данном случае, слияние записей отрабатывает заметно быстро. При этом самая длительная операция чуть более 1 сек - это наложение управляемой блокировки на 28 434 строк по комбинациям измерений склада и номенклатуры.
Итого
- Для регистра сведений, не подчиненному регистратору, доступны все три новых режима замещения: Обновление, Удаление, Слияние. Для подчиненных регистров в расширенном режиме замещения только два: Обновление, Удаление.
- Чем проще структура регистра, тем эффективнее будет массовая обработка за счет уменьшения накладных расходов на поддержании нумерации строк в подчиненном регистре и уменьшении запросов для поддержания консистенции в таблицах итогов.
- В новых трех режимах поле свойство набора Отбор теряет смысл.
- Режим замещение Обновление самый медленный вариант работы из-за внутреннего алгоритма, который разбивает регистраторы на блоки по 256 штук и циклично выполняем по ним запросы к СУБД. Остальные режимы выполняют запросы по сути в одном запросе и в целом по результатам тестов достаточно эффективны.
- Стоит контролировать объем изменяемых данных и не забывать про эскалацию на управляемых блокировках, что может привести к блокировке всей таблицы и заблокировать работу пользователей. Так же стоит большие объемы данных дробить так, чтобы время транзакции не было большим, иначе это уже может сказываться на работу всей системы, особенно на PostgreSQL, где длинная транзакция может блокировать работу autovacuum, что приведет к деградации работы всего кластера.
- При использовании режимов замещения платформа сама позаботиться о выполнении действий в транзакции и расставит необходимые управляемые блокировки.
- Выявлено два недочета в режиме замещения Обновление, снижающие производительность: работа алгоритма блоками по 256 регистраторов, установка лишней управляемой блокировки.
- Стоит ожидать в типовых конфигурация ускорения расчета себестоимости на этапе записи расчета, а так же ускорение работы подсистем взаиморасчеты онлайн, распределение запасов и всех динамических списков, которые являются отражением сложного представления данных, использующие отложенное отражение данных, например, регистр Реестр документов в УТ/КА/ЕРП, используемый для отображения документов продажи и закупок.