Цель этой статьи – поделиться опытом не только эффективного, но и безопасного использования искусственного интеллекта в своей работе. Именно безопасность – один из самых важных моментов.
В статье будет два смысловых блока:
-
Мой смысловой блок – это опыт использования LLM-моделей непосредственно в коммерческой службе и те подводные камни (а они, конечно, есть в любом деле), с которыми я столкнулся лично.
-
Мой соавтор Денис Беляев расскажет об использовании этих моделей в автоматизации бизнес-процессов и покажет интересные примеры.
Что такое LLM
LLM – это аббревиатура. В переводе с английского она означает «большая лингвистическая модель». Примером такой модели является ChatGPT, про который знают все. Школьники с его помощью пишут сочинения, студенты защищают дипломы, причем достаточно успешно.
Это одно из определений LLM (их достаточно много): LLM модель (Large Language Model, большая языковая модель) – нейронная лингвистическая сеть, обученная на огромных корпусах данных.
Кроме упомянутого мной ChatGPT, существуют такие разработки, как Gemini от Google, YandexGPT, GigaChat от Сбера. После информационной утечки стало известно о модели Llama, разработанной компанией Meta – о ней я тоже немного расскажу. И это далеко не полный список.
Уникальная возможность для сообщества 1С
Перед нами сейчас фактически пустой рынок по автоматизации бизнес-процессов с помощью искусственного интеллекта. Мы с вами понимаем, что природа не терпит пустоты, и этот рынок в ближайшее время будет занят. И у сообщества 1С сейчас есть уникальная возможность занять этот рынок. Я даже написал небольшой вызов для нашего сообщества: Сообщество 1С имеет реальную перспективу мирового лидерства за счет опережающего применения LLM технологий в автоматизации бизнес-процессов.
Предвижу вопрос: «А зачем мне, условному программисту из Курска или из Воронежа, какое-то международное лидерство и так далее?» Дам пояснение.
У сообщества 1С в целом есть одна уникальная особенность и уникальная компетенция. С одной стороны, мы прекрасно разбираемся в автоматизации бизнес-процессов, а с другой – постоянно погружены в бизнес-процессы и текущую ситуацию: либо у заказчиков, либо in-house. Мы чувствуем пульс компании. Если к этой компетенции добавить еще и быструю трансформацию с помощью LLM-технологий, то я считаю, что нас ждет прекрасное будущее. Этот тренд, в том числе выход на международный рынок, отразится и на доходах, и на интересных проектах у всех участников сообщества: программистов, аналитиков и так далее.
На разработку и обучение модели Llama компанией Meta было потрачено порядка трех миллионов часов. Одна из ее версий весит всего 7,4 гигабайта. Эту версию можно поставить на компьютер, запустить и сразу начать использовать в своих бизнес-процессах. Не нужно никакого дополнительного обучения.
Это пример того, как просто начать использовать нейросети в автоматизации бизнес-процессов – именно в коммерческих целях.
Опыт применения ИИ в компании: выбор направления
Расскажу про опыт применения нейросетей в нашей компании. Перед нами стояло четыре глобальных вопроса, но я расскажу только про фокусировку. Вопрос фокусировки достаточно важный: можно потерять много времени и денег, просто неправильно выбрав направление применения.
По фокусировке у нас было два варианта:
-
Использовать ИИ в нашей традиционной работе: для математической аналитики, прогнозирования и так далее.
-
Использовать ИИ в работе по разгрузке наших специалистов: например, для контроля звонков.
Мы решили выбрать первое направление, а именно:
-
Расчеты плановых показателей,
-
Математические модели по управлению рисками предприятия,
-
Определение рентабельности инвестиций в наши ПО,
-
Расчеты ставки эффективности сотрудников, занятых в проектах, на основании круговых диаграмм Эйлера – Венна.
Начали работать в этом направлении, и нам повезло. Повезло в том, что мы не успели потратить много времени и денег, чтобы понять достаточно простые вещи.
LLM-модели соображают лучше, чем любой математик. Но они уступают там, где в процессах автоматизации применяются программные решения. Потому что есть один очень важный момент – галлюцинации нейросетей. Об этом мы поговорим чуть позже, но сейчас хочу дать совет: не стоит использовать нейросети там, где вопросы можно решить с помощью простого алгоритмического программирования. Пока нейросети не достигли таких высот, чтобы заменять программы.
Рекомендации по применению ИИ: фокус на человеческие процессы
Мы решили перейти на гуманитарные рельсы. Вот перечень тех направлений, по которым мы сейчас применяем нейросети:
-
Поиск аномалий в финансовых показателях и отчетных данных (угроза наступления риска или признаки мошенничества),
-
Анализ ВНД (внутренней нормативной документации) – инструкций, регламентов, чек листов и т.д.,
-
Консультации по вопросам, связанным с принятием решений в различных ситуациях и проработка различных вариантов (аналог генерации гипотез с помощью «мозгового штурма»),
-
Распознавание документов и отражение их в информационной системе,
-
И очень, очень, очень много чего еще!
Хочу показать рисунок который в дальнейшем сэкономит вам много времени и денег.

Здесь нарисованы человек и робот. Самый главный посыл, который нужно понять, чтобы не потратить время и деньги, заключается в следующем: постарайтесь не автоматизировать с помощью искусственного интеллекта те направления, которые уже решаются программными средствами. Обратите внимание на те направления, которые выполняют люди. Да, есть галлюцинации нейросетей, но нейросети ошибаются не чаще, чем обычный человек. Плюс в любых процессах, где так или иначе задействованы люди, существуют так называемые циклы проверки, контроля и так далее. Для быстрого и эффективного внедрения нейросетей в автоматизацию бизнес-процессов я рекомендую обратить внимание именно на процессы, в которых задействованы живые люди.
Сколько бы мы не встречались с коллегами в профессиональном сообществе и сколько бы не обсуждали нейросети, все сводилось к идее: «Давайте автоматизировать именно человека, а не машину». Так что этот рисунок – это реально «серебряная пуля».
Практические примеры автоматизации с LLM
Представьте себе, что мы берем входящие документы в компанию и автоматически загружаем их в Документооборот. Это реальная обработка – скажу вам заранее. Она уже существует и не требует никакой настройки, несмотря на то, что в Документообороте разные поля, разные виды документов и так далее.
Мне часто говорят: «Но договора-то должны быть шаблонные!». Нет, больше не должны. Нам не нужны шаблонные договоры в LLM. Она сама определяет любой договор, каким бы он ни был, и извлекает из него нужные данные.
Кто-то скажет: «А как же информационная безопасность?» Модель Llama 2, которая весит 7,4 гигабайта, очень хорошо справляется с этой задачей. Для ее работы подойдет видеокарта 3060 или 3080; мы ее запускали даже на 3050. Ведь документы не нужно обрабатывать в реальном времени – не надо сидеть и смотреть на экран, обработка происходит фоном.
Это то, что у нас уже есть. И таких задач просто огромное количество. Примеров, как можно применить данную технологию – тысячи. Через два года мы с вами не узнаем ни одну нашу информационную систему. В этом я на 100% уверен.
Вы можете использовать ChatGPT, Qwen, DeepSeek – что хотите. У нас ИИ встроен в 1С. Чтобы протестировать гипотезу, можно ли автоматизировать задачу с помощью LLM или нет, вы вводите запрос и в конце указываете: «Выдай мне результат в формате JSON с такими-то полями». Почему JSON? Потому что его потом можно автоматизировать. Программист может сделать запрос и получить ответ алгоритмически – не в виде чатика, как мы обычно делаем, а так, чтобы это было зашито в обработку. Представьте, что у вас есть список заказов, который нужно заполнить, и система чем-то его заполняет, чтобы в итоге это работало в автоматическом режиме.
Подход, когда мы просим выдать результат в формате JSON, решает, наверное, 90%, если не почти 100% подобных задач.
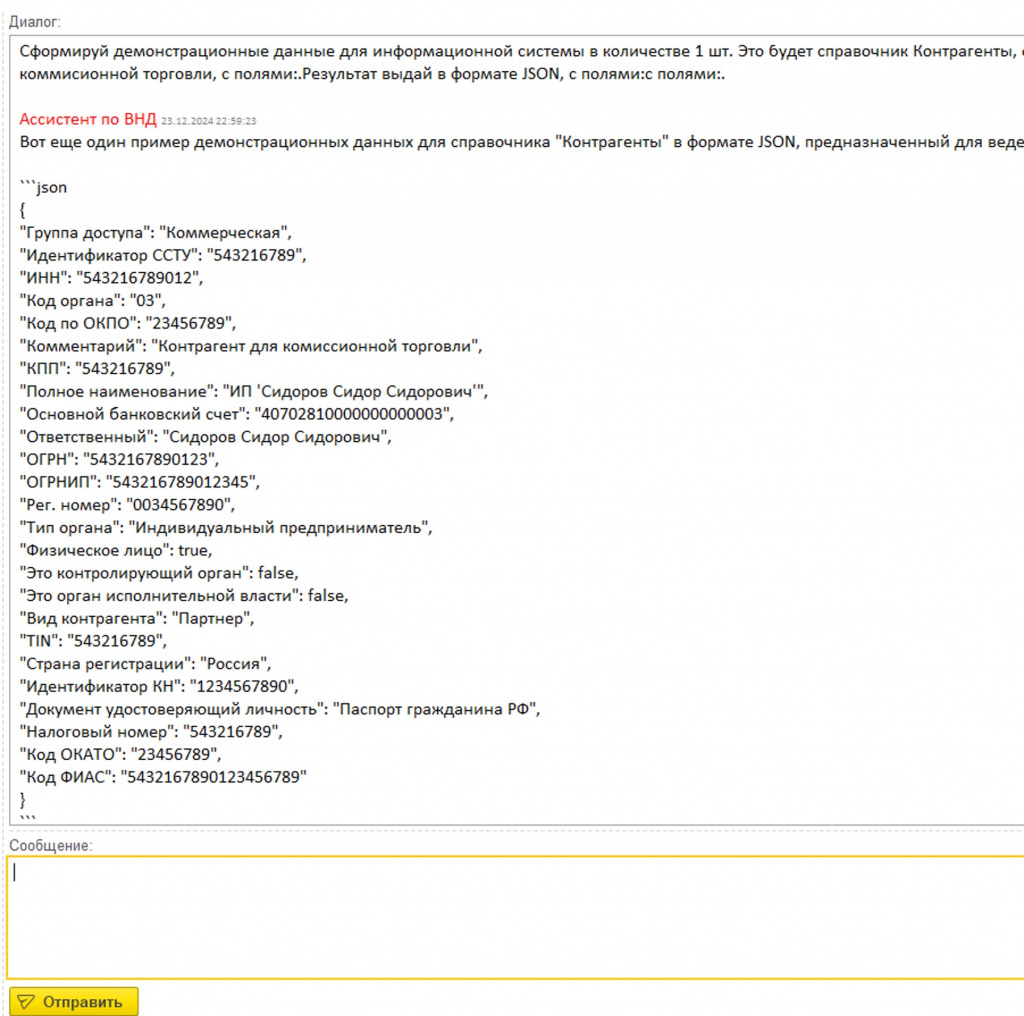
Вот результат: ИИ выдал демо-данные в формате JSON, которые можно загрузить.
Дополнительные инструменты и кейсы
Мы сделали обработку по созданию любых демо-данных в любой конфигурации 1С. То есть вы что-то запрограммировали, и обработка сама накидывает демо-данные, причем качественнее, чем это делают тестировщики.
Это реальные результаты с проектов, где мы уже провели пилоты и внедрили решения.
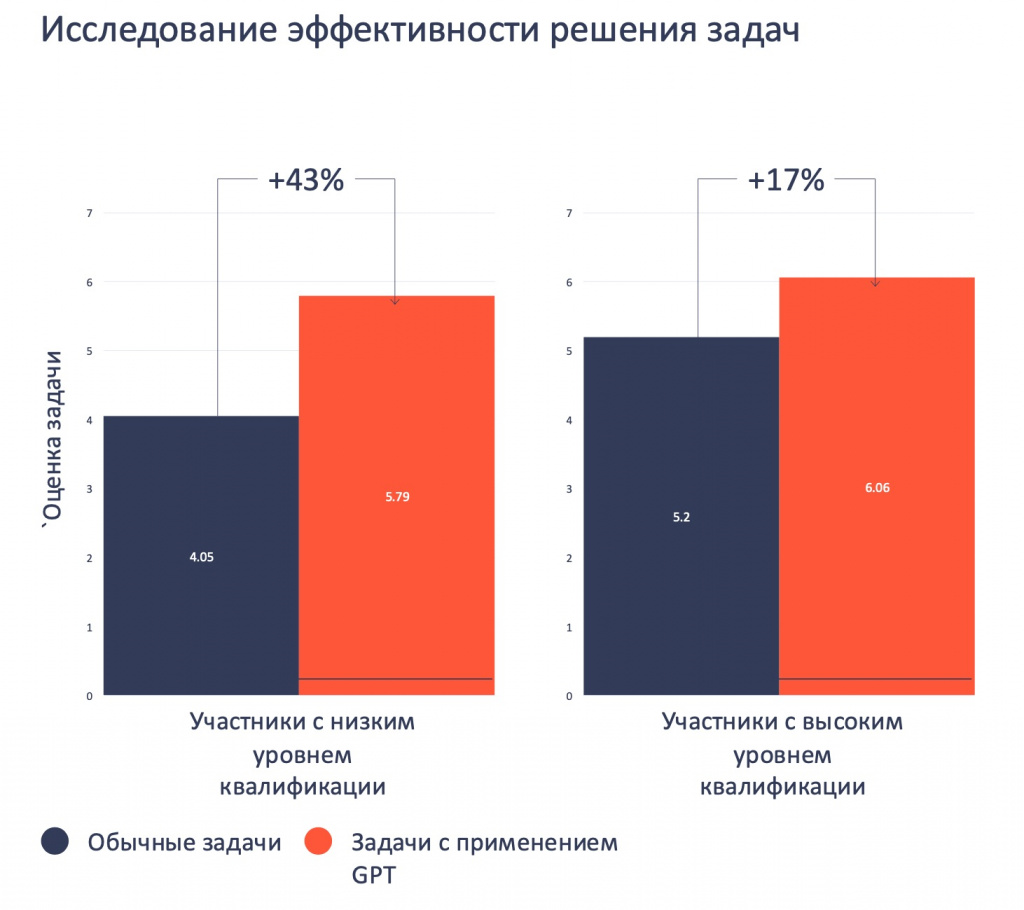
Так как мы занимаемся рисками, одно из наших решений – идентификация рисков проекта. Мы автоматизируем систему риск-менеджмента, работу службы риск-менеджмента. Загружается описание проекта, в данном случае это было строительство, и мы говорим: «Модифицируй риски этого строительного проекта». И система выдает, что может случиться, где могут произойти сбои, потери. Работает, по оценке нашего клиента, очень хорошо, хотя и не идеально.
План аудита – это то, что мы делали в рамках службы внутреннего аудита.
Консультации по метрикам: руководитель может сказать:«Составь мне метрики для такого-то сотрудника», и система их дает, причем дает хорошо.
И еще одна килл-фича – консультации по внутренним нормативным актам. В большой компании регламентов много, и часто непонятно, как нужно поступать в том или ином случае. Система очень хорошо консультирует по ВНД (внутренним нормативным документам): загружены различные приказы, регламенты, множество инструкций.
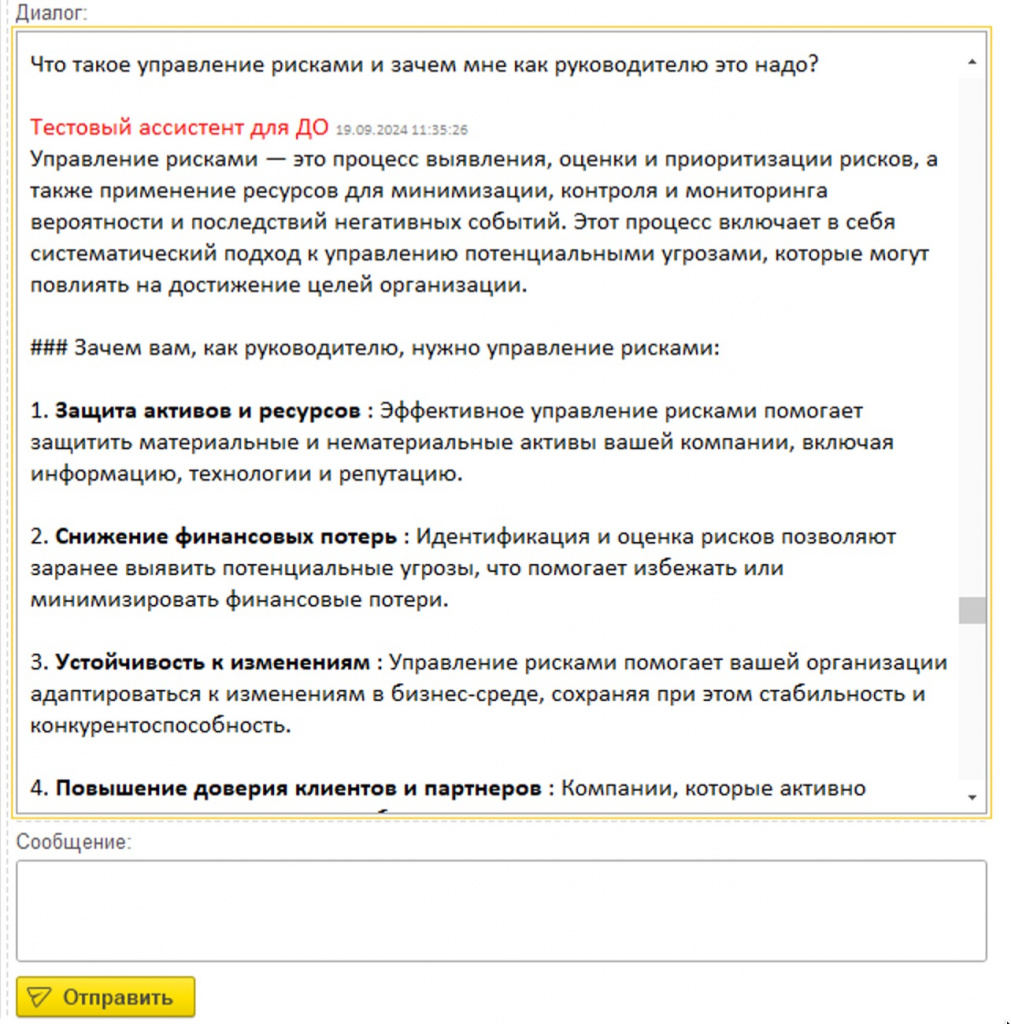
У нас эта штука встроена в Документооборот, где есть все документы. Вводишь в чат: «Как мне оформить заявление на отпуск?» – и он сразу дает ответ. Или то, с чем множество проблем в крупных компаниях: «Как мне ввести информационную систему в эксплуатацию?» И система рассказывает: к кому бежать, с кем согласовывать, какие документы по каким формам нужно взять и так далее.

Еще один пример: выявление инцидентов промышленной безопасности по видеопотоку. Мы пытаемся завернуть это в коробку, но сейчас это реализовано как пилот.
Идут фотографии – или видеопоток мы нарезаем на фотографии – и говорим: «Где нарушение на нем?» Система указывает, какие нормы акта нарушены, какие ГОСТы, какие внутренние документы.
Ключевое здесь – она не требует настройки. Раньше нам нужно было делать машинное обучение: разметку, 60 тысяч касок отметить, потом 60 тысяч арматурин, потом 60 тысяч еще чего-то – это работа на годы. А эта штука работает прямо сейчас – вообще без какой-либо настройки. Чем бы вы ни занимались, например, вагонами, строительством или транспортом – вообще все равно. Это работает сразу.
Эта гипотеза тестируется в компании за 1–3 месяца. Вопрос лишь в том, где вы можете это применить, и какой можно получить эффект.
Мы добавили образ сотрудника с привычками. Допустим, один человек постоянно все нарушает. Мы его и обучали, и штрафовали, и депремировали – а он все равно нарушает. Система формирует этот образ сотрудника и говорит нам, что с ним надо сделать.
И последнее – оценка влияния этих нарушений на бизнес: бизнес остановился или не остановился из-за этого нарушения.
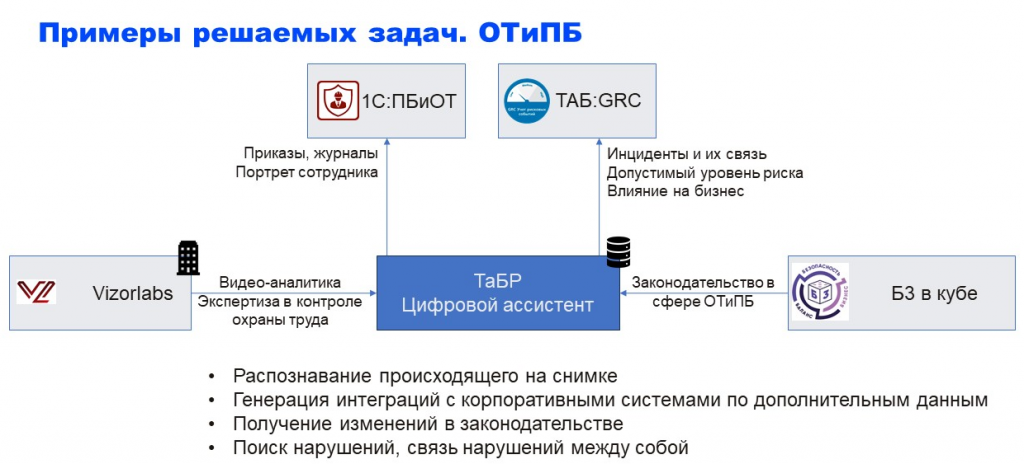
Вот так работает эта конструкция. Мы здесь интегрировались с камерами, потом все, что связано с обучением, журналами обучения и привычками, скинули в 1С:ПБиОТ. В TAБ:GRC у нас инциденты и их связь с бизнесом. И еще отдельный подрядчик, который дает нам нормативные акты внешних регуляторов: он их сохраняет, отбирает и загружает.
Сейчас мы стараемся систематизировать это решение для более быстрых внедрений – чтобы поставил как коробку, и оно сразу заработало с кучей подрядчиков.

Сервис для распознавания первичных документов существует давно. Этот инструмент стоит очень дешево – около 600 или 1000 рублей. Он распознает все входящие первички и создает акты, накладные. Сервис построен тоже на LLM, крутится на серверах 1С.
Еще есть ассистент. Он работает в виде чата. Была практика его внедрения в юридическом департаменте. Это конкретные кейсы, с которыми работают юристы, реально применяемые, отобранные на практике:
-
Найди ответ. Подготовь ответ на вопрос с ссылками на ВНД.
-
Проверь договор. Проверь по чек-листу на соответствие стандартам компании и выбери маршрут согласования.
-
Сделай документ. Создай договор, доп. соглашение, акт, протокол, НПА, ЛНА, инструкцию и другие документы.
-
Извлеки данные. Проанализируй документ и извлеки важные данные.
-
Резюмируй. Проанализируй документ и подготовь его краткое содержание.
-
Ответь на письмо. Подготовь ответ на письмо, претензию или сообщение.
-
Улучшай текст. Проверь и улучшай мой текст.
-
Переведи. Переведи на другой язык или сделай двуязычный документ.
-
Протокол разногласий. Сравни две версии договора и подготовь протокол.
-
Сделай справку. Проанализируй документы и подготовь справку или юридическое заключение.
Например, юристы формируют чек-лист и спрашивают: «Есть ли в договоре форс-мажор? Есть ли ответственность сторон? Есть ли штрафы за нарушение сроков?» Сделан универсальный чек-лист: загружаешь в него любые договоры – и он говорит, есть или нет этих блоков. Работает достаточно надежно.
Замена человека, а не машины
У LLM-моделей бывают галлюцинации, но, если мы поручим эти задачи человеку, а не искусственному интеллекту, он совершит не меньше ошибок. Главное, чтобы вы понимали – ИИ это замена человека, а не машины.
Даже дома я пользуюсь такими инструментами. Жена попросила помочь составить претензию в управляющую компанию, а я ответил: «Зачем мне это делать? Напиши вон туда – он все подготовит, не мучайся». Можно использовать ChatGPT или Qwen.
Сообщество экспертов и пользователей 1С имеет колоссальное преимущество. Мы знаем бизнес-процессы и то, как они работают! Разработчики LLM этого не знают!
Эту мысль я хотел бы еще раз подчеркнуть. Мы сами пришли к ней не сразу. Я смотрю на проекты разработчиков LLM – транскрибации, сервисы-помощники по аренде отелей. Это, конечно, хорошо и удобно. Но мы-то с вами занимаемся автоматизацией бизнес-процессов! И я вижу огромный потенциал для применения LLM-моделей в разных сферах. Начинаешь обсуждать это с ребятами, которые делают «линки», – а они вообще не понимают, что эту технологию можно использовать гораздо эффективнее.
Приведу пример с обработкой загрузки любых документов в систему. Было предприятие на 300 сотрудников – небольшое, но с огромным объемом документооборота, так как у них это контрольная функция. Мы посчитали, что благодаря внедрению обработки для загрузки документов в 1С:Документооборот, экономия составила 8 миллионов рублей в месяц. Представьте: восемь миллионов в компании всего из 300 человек! Для них это колоссальная сумма.
И таких примеров очень много. Внедрение занимает примерно месяц, а эффективность подтверждается уже в первую неделю.
У нас есть огромное преимущество – мы знаем бизнес-процессы. Достаточно немного подучить LLM, попробовать на практике – и задачи начинают решаться буквально за считанные минуты. За пределами нашего сообщества многие до сих пор не осознают этого потенциала.
Информационная безопасность и локальное развертывание

Один из краеугольных камней всей этой истории в том, что нельзя поставить ChatGPT во внутреннюю инфраструктуру. Инфобез сопротивляется.
Но есть Llama, DeepSeek, Qwen – бесплатные модели, которые можно скачать и использовать локально, развернув у себя в инфраструктуре. У нас уже была такая практика. На рынке есть отечественные решения с сертификатами ФСТЭК, на них можно ориентироваться. Оборудование для них требуется не очень мощное и не слишком дорогое.
В своей практике мы защищали подобные проекты перед безопасниками и строили следующую конструкцию.
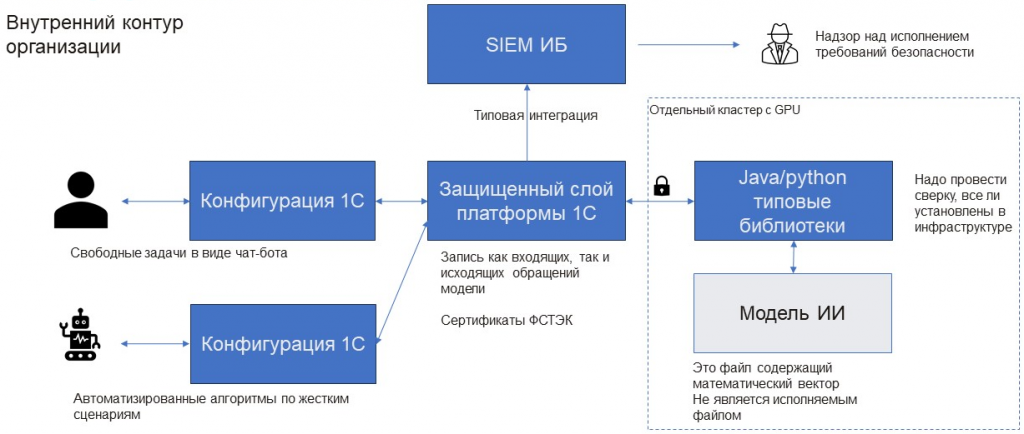
Мы используем 1С как источник инфобеза – берем платформу 8.3z. У нее есть сертификаты ФСТЭК, и в 8.3z уже встроена интеграция со слоями информационной безопасности компании. То есть службе ИБ ничего дополнительно настраивать не нужно: интеграция и мониторинг уже есть. Наша задача – только пропустить API через 1С. Запросы идут через 1С, в которой строятся ключи (закрытый и открытый) для серверов с Python и Java. При этом Python и Java работают на стандартных библиотеках, почти все они есть в публичных репозиториях.
За счет этого проект легко согласуется: там нет ничего уникального, нет нужды в постоянных обновлениях. Поставили библиотеку math на Python – она работает и дальше.
Сервер можно масштабировать горизонтально, поставить второй, третий, четвертый, пятый сервер в зависимости от задач. Но все должно идти через защищенный слой 1С, иначе безопасники не пропустят. Для того, чтобы использовать это не в 1С, просто делаете API в 1С. В этом случае 1С работает как proxy-сервер: все запросы проходят через нее, а журналы логируются средствами ИБ. Это и реально, и формально соответствует требованиям безопасности – сертификаты ФСТЭК по АУ-4, и все требования по этому классу выполняются. Таким образом, решение формально допускается в инфраструктуру.
Если сильно сопротивляются и говорят: «А вдруг можно ввести какие-то некорректные вопросы в чат?» – чат можно вообще исключить. Вы можете протестировать все в чате, а в рабочий контур внедрять уже в автоматизированном режиме, где нельзя задать свободный промпт – он заранее зашит в конфигурацию. Тогда с LLM работают только автоматизированные обработчики, без свободного ввода. Это тоже вариант, если сопротивление слишком сильное.
Мы даже составили карту рисков для инфобеза:
-
Утечка данных через обучающие или предобученные модели. Предобученные модели могут сохранять следы данных, использованных при их обучении. Если файл вектора утечет, это будет практически равно утечке внутренних нормативных актов компании.
-
Ошибки конфигурации и уязвимости в защите. Неправильная конфигурация окружения или недостаточная защита модели может привести к несанкционированному доступу даже внутри организации.
-
Качество и некорректность ответов. LLM-модели склонны к «галлюцинациям» – генерации неправдивых или неполных данных. Это может ввести сотрудников в заблуждение и привести к принятию неверных решений.
-
Зависимость от модели. Возникает риск «технологического лока» – высокая зависимость сотрудников и бизнес-процессов от LLM, что снижает гибкость в случае сбоев или необходимости замены модели. Риск аналогичен любому процессу автоматизации.
-
Сложности контроля и интерпретации вывода модели. Модель является «черным ящиком», и сложно точно контролировать ее выводы, что создает риск некорректного использования информации.
-
Отсутствие аудита и прозрачности. Внутренняя LLM-инфраструктура может затруднить проведение аудита данных и контроля за действиями сотрудников при использовании модели.
-
Социальные риски. Внутреннее использование моделей может привести к ошибочному восприятию их «непогрешимости», что снижает уровень критического мышления сотрудников.
-
Эскалация ошибок. Ошибочные ответы или выводы модели могут быстро распространяться в организации и масштабировать неправильные решения.
С ней мы ходили к службе ИБ и показывали: да, вот риски, вот меры по каждому пункту. Карта может быть неполной, но пока мы не выявили рисков, которых там нет. И когда нам говорят: «Слишком много рисков», мы отвечаем: «Какие именно? Вот список, все расписано. Если у вас есть что-то еще – давайте рассмотрим». Это переводит разговор в объективную плоскость.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TEAMLEAD&CIO EVENT.

Вступайте в нашу телеграмм-группу Инфостарт