Я хочу поделиться опытом компании Magnit Tech, как мы применяем искусственный интеллект для проведения код-ревью. В статье расскажу, почему мы решили использовать ИИ именно для код-ревью, как организовали процесс и что получилось в результате, когда начали применять решение на практике.
Цели внедрения ИИ в процесс код-ревью
Многие уже устали от того, что ИИ внедряют повсюду – где нужно и где не нужно, с разным результатом. Мы определили конкретные цели, которые, по нашему мнению, ИИ способен решить. А получилось у нас это или нет – расскажу в конце статьи.
Первое, для чего мы хотели использовать искусственный интеллект – это быстрая проверка кода. Многие знают, что код-ревью – узкое горлышко разработки. На практике это выглядит так: вы быстро написали задачу, код готов, можно отдавать на тестирование, но нужно провести код-ревью. Просите коллегу проверить – он отвечает, что занят и посмотрит завтра. Завтра растягивается до второй половины дня, он возвращает комментарии, вы их исправляете, снова ждете проверки. В итоге к разработке добавляются два дня.
Это неприятно, но понятно, почему так происходит. Писать свой код куда приятнее, чем разбираться в чужом. Поэтому идея переложить рутинную проверку на искусственный интеллект выглядит очень заманчиво.
Также мы хотели, чтобы искусственный интеллект помог улучшить качество кода и поддерживать общий стиль написания, когда в компании работают десятки программистов 1С выдерживать общий стиль становиться сложнее. Конечно, у нас существуют стандарты, как нужно писать код и приводить его к единому виду, но у каждого свой взгляд, и каждый вносит свое понимание того, каким должен быть код. Мы рассчитывали, что искусственный интеллект станет универсальным инструментом и будет проверять код по одному шаблону.
Еще одна важная цель – уменьшение количества ошибок. Часто бывает так: эксперт присылает свой код на проверку, и его авторитет влияет на восприятие. Думаешь: он уже десять раз присылал безупречный код, и в одиннадцатый наверняка все в порядке. Просматриваешь бегло, утверждаешь – а ошибка оказывается именно там.
Искусственный интеллект лишен предвзятости. На эти цели мы и делали ставку, когда начали использовать ИИ.
Выбор модели ИИ и техническая реализация
Теперь перейдем к самому интересному – как мы это реализовали. Первая и самая большая проблема – выбор искусственного интеллекта. На рынке их сейчас много: платные, бесплатные, их десятки, а то и сотни. Есть универсальные модели, есть специализированные, ориентированные только на программный код – для 1С и не для 1С.
В статье моего коллеги Александра Леонова https://habr.com/ru/companies/magnit/articles/819583/ подробно описан анализ различных моделей искусственного интеллекта, который мы проводили для языков 1С в прошлом году. На тот момент мы еще не знали об «1С-Напарнике», поэтому подходящих моделей не нашли. Эффективность решений была неоднозначной, качество тестирования у большинства плагинов – низкое. Были и хорошие варианты, но они оказались платными, что делало их использование менее привлекательным.
В итоге, когда мы решили внедрять искусственный интеллект для код-ревью, нам пришлось выбирать лучший вариант из худших. Им стал DeepSeek. Когда мы определились с выбором, столкнулись с классической проблемой всех коммерческих организаций: программный код, который разрабатывают сотрудники, является интеллектуальной собственностью компании. Просто так отправить его в онлайн-сервис DeepSeek мы не можем – это разглашение коммерческой тайны, за которое последует реакция службы информационной безопасности. Поэтому мы решили поднять собственный сервер, на котором развернули искусственный интеллект.
Оказалось, что у DeepSeek есть языковая модель, способная справиться с нашими задачами, которой достаточно 32 ГБ оперативной памяти. Мы взяли тестовый сервер с нужными параметрами и успешно все запустили.
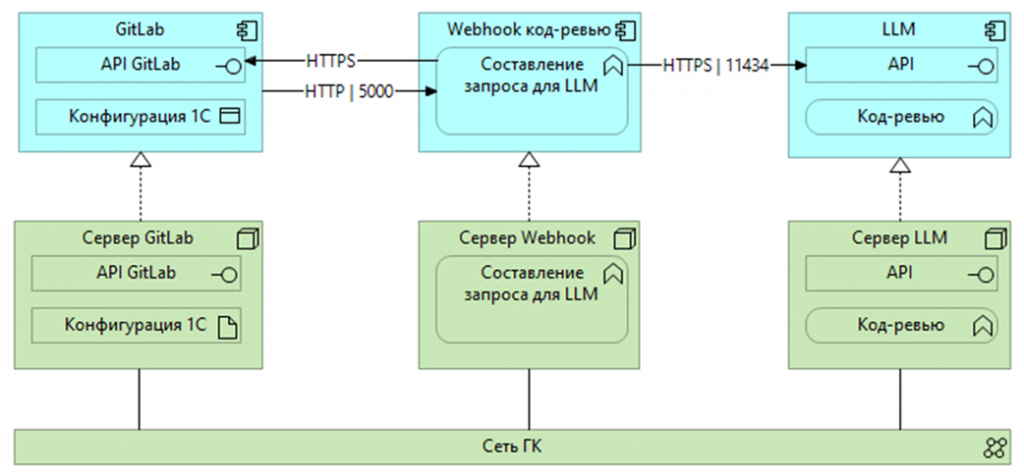
В результате появилась следующая схема. Все конфигурации компании переведены на EDT. Репозитории и GitLab находятся внутри корпоративного контура, с полным доступом и безопасным хранением данных. Когда создается merge request, он размещается в GitLab, и это удобно интегрируется с системой взаимодействия.
Мы подняли контейнер в Docker, разместили в нем webhook и написали на Python код, который опрашивает порт GitLab (в нашем случае порт 5000), получает merge request и контекст – фактически конфигурацию, добавляет к ней промпт и передает все это в API нашей LLM, то есть искусственного интеллекта. API обрабатывает данные и возвращает результат код-ревью.
Среднее время обработки составляло 1–2 минуты, но при больших изменениях нагрузка возрастала, и обработка контекста могла занимать до 30 минут. Мы поняли, что при масштабировании возможны проблемы с производительностью: об этом речь пойдет ниже.
В целом модель показала себя хорошо. После обработки результат код-ревью размещался в виде комментария к merge request. Так как в GitLab много проектов, чтобы синхронизировать их между собой, мы изначально присвоили каждому проекту уникальный токен. Этот токен вместе с запросом передавался в ИИ. Обратно передавался уже результат.
Практические команды и настройка окружения
# Запуск Ollama в Docker, будем хранить все данные Ollama в отдельном каталоге (например, /var/1C/ollama)
docker run -d -v /var/1C/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
# Проверка, что API Ollama работает
curl http://localhost:11434
# Копирование модели в Ollama
docker cp DeepSeek-R1-Distill-Qwen-32B-Q5_K_M.gguf ollama:/root/.ollama/models/
Здесь несколько команд, которые вам помогут, если вы решите пойти нашим путем. Первая – запуск Ollama в Docker. Ollama используется для работы с различными языковыми моделями. Сначала мы запускаем Ollama в Docker, затем проверяем, что API работает корректно. После этого копируем нашу языковую модель в Ollama.
Так как доступ к внешним ресурсам запрещен, напрямую скачать модель из интернета нельзя. Команды для этого есть, но служба информационной безопасности не разрешила их использовать. Поэтому мы сначала копировали модель во внутренний контур, проводили проверки и только после этого запускали ее в Ollama с локального сервера.
# Создать Modelfile для сборки модели
nano Modelfile
# В Modelfile добавитьстроку
FROM /root/.ollama/models/DeepSeek-R1-Distill-Qwen-32B-Q5_K_M.gguf
# Перенести Modelfile вконтейнер ollama
docker cp Modelfile ollama:/root/.ollama/models/
# Создатьмодель
docker exec -it ollama ollama create deepseek-r1:32b -f /root/.ollama/models/Modelfile
Далее создавали Modelfile для сборки моделей, перемещали их в контейнеры Ollama, и модель успешно разворачивалась. По сути, еще четыре команды – и искусственный интеллект на сервере начинает работать.
Плюсом еще три полезные команды:
-
dockerexec-it ollama ollama run deepseek-r1:32b – проверить, что модель запустилась и функционирует с установленной языковой моделью.
-
dockerexec-it ollama ollamaps – узнать, есть ли активный запрос к модели. Когда процесс зависал на 30 минут, мы использовали эту команду, чтобы понять, что происходит.
-
dockerexec-it ollama ollama list – вывести список установленных моделей. Полезно, если вы пробовали разные варианты и хотите посмотреть, какие именно модели сейчас установлены.
Промпт и пример работы в GitLab
# Промт
Ты программист 1С. Ответ должен быть максимально коротким и содержать только рекомендации по исправлению ошибок в коде 1С. Все выходные данные должны быть только на русском языке. Не пиши код.
# Запрос
Выведи на русском языке список кратких рекомендаций без пояснений и без примеров для исправления методов {methods_list} из приведенного кода 1С: {module}’
Это промпт, который мы используем в нашем коде на Python, по которому он донасыщается, и по нему языковая модель понимает, что надо делать с тем кодом, который в него прилетел.
Следующий пример – как это выглядит на практике в GitLab. Здесь пример синтетический: мы специально создали функцию с ошибками и сказали: «Посмотри, что у нас там за ошибки, проведи нам код-ревью». В итоге получился такой результат.
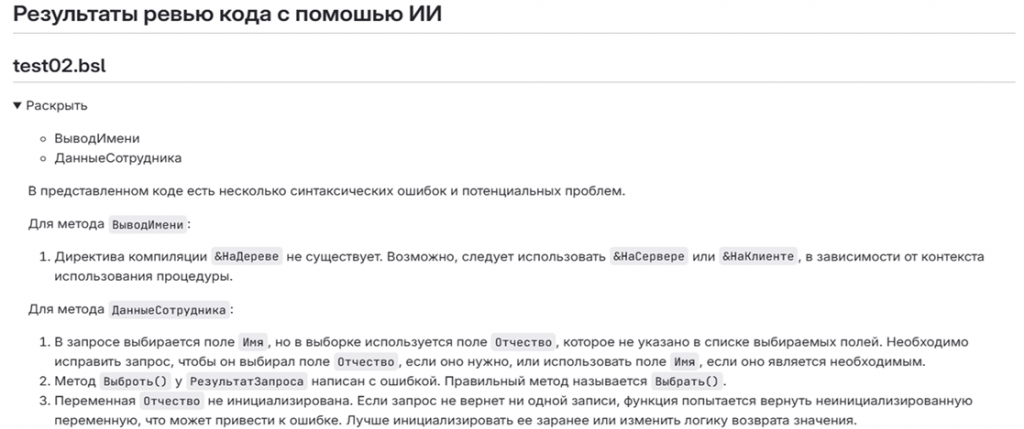
«Для метода ВыводИмени директива компиляции &НаДереве не существует. Возможно, следует использовать &НаСервере или &НаКлиенте, в зависимости от контекста использования процедуры».
Описание развернутое. Если начинающий программист допустит явные ошибки, система понятно объяснит, что нужно поменять.
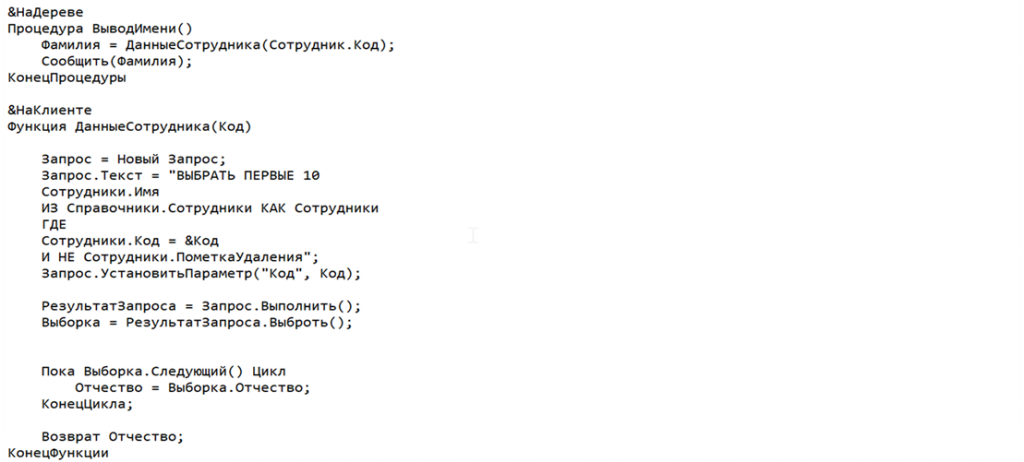
А это то, что мы скармливали нашему ИИ для проверки. Можете сравнить, какой вариант у нас был на входе и что получилось.
Проблемы и пути их решения
Классическая проблема всех искусственных интеллектов – галлюцинирование. В нашем случае, когда мы запустили код-ревью, возникло ощущение, что в искусственный интеллект вселился Лев Толстой. Комментарии занимали несколько страниц и превращались в философские рассуждения о сути кода. Это выглядело странно и читать такое не хотелось – открываешь, смотришь и сразу закрываешь.
Оказалось, что при работе с языковыми моделями есть параметры, регулирующие баланс между вариативностью текста и степенью отклонения от истины. Эти параметры позволяют сделать текст разнообразным и осмысленным, но при этом удерживать модель от излишнего фантазирования. Настроить этот баланс можно вручную.
Кратко о параметрах, чтобы вы могли их подкорректировать, если решите использовать модель:
-
Температура (Temperature). Влияет на правдоподобие и креативность. Высокая температура (ближе к 1) делает результат более креативным, но высок риск малого правдоподобия, а низка (ближе к 0) – более детерминированным и сосредоточенным на самых вероятных словах. Пример; Запрос «Небо…» при низкой температуре даст «голубое», а при высокой – «усыпано алмазными звездами».
-
Параметры сэмплинга – Top-p и Top-k. Они определяют вариативность токенов: какое количество токенов и насколько вероятна популярность этих токенов будет отобрано. Данный параметр позволяет предотвращать выбор странных маловероятных слов. Пример: при top-p = 9 модель будет выбирать из короткого списка лучших вариантов, игнорируя совсем уже странные.
-
Штраф за частоту (Frequencypenalty) – снижает вероятность слов, которые уже часто использовались. Это помогает избежать повторений и делает текст более разнообразным. Пример: Если модель уже несколько раз использовала слово «прекрасны», этот штраф заставит ее подобрать синоним, например, «замечательный».
-
Штраф за присутствие (Presencepenalty) –уменьшает вероятность слов, которые уже есть в вашем промпте или в сгенерированном тексте, независимо от того, как часто они встречались. Это помогает избежать зацикливания.
Когда мы решали проблему галлюцинирования, для нас оптимальным оказалось изменение параметра температуры. По умолчанию Ollama устанавливает температуру 0,8 – это высокий показатель: все, что выше 0,5, уже повышает риск галлюцинаций. Мы снизили температуру до 0,1, и количество галлюцинаций резко сократилось.
В тестировании нашего код-ревью для ИИ участвовало 10 разработчиков. Первую версию они оценили как некачественную, но через пару недель после изменения параметров вернулись с обратной связью – работать стало гораздо приятнее.
Отмечу, что есть соблазн поставить температуру равной нулю, но тогда результат будет шаблонным и одинаковым. В этом случае теряется смысл использования искусственного интеллекта.
Результаты внедрения и обратная связь
Все участники тестирования, все 10 разработчиков, подключенных к код-ревью с искусственным интеллектом, отметили, что работать стало удобнее. Код-ревью стало осмысленным. После снижения процента галлюцинаций разработчики сказали, что инструмент можно использовать и передавать программистам, особенно начинающим, которые недавно в компании и еще плохо ориентируются. Для них это отличная помощь.
Более опытные программисты отметили, что для них ИИ служит вспомогательным триггером: открываешь, смотришь, на что обратить внимание, где возможны ошибки. Работать с подсказками проще, чем разбираться с кодом с нуля.
Из минусов:
-
Полностью избавиться от галлюцинаций не удалось, они остались, но стали встречаться реже.
-
На больших конфигурациях мы не рискнули запускать систему. В компании есть небольшие конфигурации и есть ERP или схожие по масштабу, в том числе самописные. Мы понимаем, что обработка таких проектов может занять несколько часов, поэтому пока в эту сторону не пошли.
Планы на будущее
-
У нас есть планы по масштабированию. Попробовать запустить систему на более мощном сервере с увеличенными параметрами и протестировать ее на больших конфигурациях.
-
Мы участвовали в тестировании «1С-Напарника» в этом году и получили хорошие результаты. Один из вариантов развития – использовать «1С-Напарник» как инструмент, направленный на работу с кодом 1С и проверку наших решений.
-
У нас в компании разработан собственный искусственный интеллект Magnit GPT. Он работает внутри корпоративного контура и обучен на нашей коммерческой информации, что позволяет учитывать особенности внутренних систем. Поэтому вариантов развития дальше достаточно много.

*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт