


{kind=link}
Во встроенном языке платформы 1С:Предприятие, как и во многих других языках программирования, присутствует возможность сложения строк. Это легко:
Переменная="Мама"+"мыла"+"Раму";
Когда же нужно из некоторой коллекции строк получить одну единую, то можно сделать в цикле:
Строка = Строка + ЭлементКоллекции;
Все это хорошо работает когда у нас немного данных. Но все кардинально меняется, когда счет строк идет на тысячи (обычное дело при работе с клиент-банками, веб-сервисами, КПК и в прочих ситуациях). Попробуйте и сами увидите как на глазах падает производительность. О резкой деградацию производительности при множественных конкатенациях уже писали. Даже на Инфостарте. Не говоря уже про обсуждения на партнерском форуме.
Но водь нас больше всего интересуют практические решения. Варианты с внешними компонентами я даже не стал рассматривать. Нужно ведь писать код сразу так, что бы он работал кросплатформенно! Так же были проигнорированы варианты с записью в файл - нам лишние задержки от дисковой подсистемы совсем не нужны.
Некоторые предлагают очевидное в таком случае решение - использование текстового документа. С практической стороны необходимо отметить, что все составные строки в этом объекте идут отдельными строками. Т.е. воспользовавшись методом ПолучитьТекст() необходимо еще сделать замену переносов строк на пустую строку. В случае использования вами символа переноса строки в подстроках, необходимо предварительно сделать замену его на некоторую уникальную последовательность символов, а после получения результата произвести обратное преобразование.
Я же для себя изобрел собственный велосипед, который по скорости превзошел использование текстового документа. Все подстроки заносятся в массив, который перегоняется в текстовое представление с помощью ЗначениеВСтрокуВнутр(), а далее вычищается от "лишнего". Работает стабильно и довольно быстро. Подробности реализации можете посмотреть в прикрепленной обработке.
UPD 1. Из комментария узнал про новый способ конкатенирования - использование объекта ЗаписьXML. У него есть интересный метод ЗаписатьБезОбработки() для помещения уже готового документа в том виде, какой подается на вход, т.е. без лишних тегов.
Для того, что бы определить какой метод лучше (и стоило ли вообще заморачиваться) была написана маленькая обработка. Условия для всех равны - замер происходит в милисекундах от вызова серверной функции с реализацией соответствующего алгоритма до получения отклика. Что бы нивелировать случайные факторы, я проводил по четыре замера и выводил в таблицу среднее значение.
В результате я получил следующую таблицу:
| Попыток | Обычная конкатенация | Текстовым документом | Масивом подстрок |
| 1000 |
63 |
97 | 57 |
| 5000 |
327 |
353 | 185 |
| 10000 |
847 |
642 | 330 |
| 15000 |
4100 |
958 | 462 |
| 20000 |
8672 |
1299 | 656 |
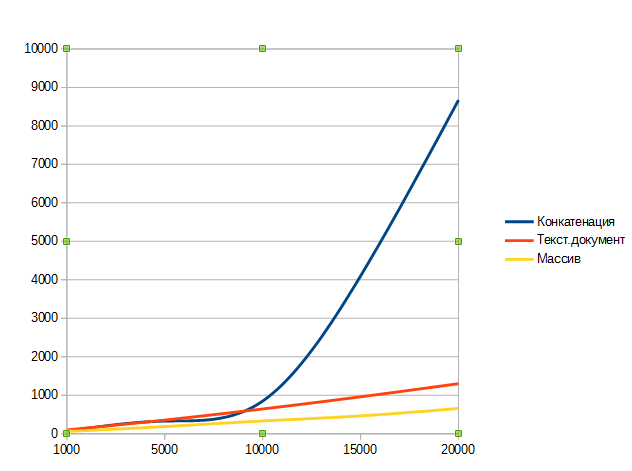
В результате мы еще раз убедились в непрактичности использования обычной конкатенации на больших объемах строк. Как видно из получившегося графика зависимость скорости выполнения от количества элементов имеет экспоненциальный характер. В то время, как оба метода "обхода" стабильно показывают прямолинейную зависимость. Что позволяет нам прогнозировать общее время выполнения обработок связанных с обработкой текста. И мой метод превосходит по быстродействию использование текстового документа в 2 раза! 
UPD 2. К сожалению не нашел в инфостартовском редакторе инструмента для редактирования количества столбцов таблицы и не увидел переключения в режим HTML-документа для правки руками. По результатам тестирования метода с ЗаписьXML получились результаты идентичные методу массивом как на малых, так и на больших наборах подстрок. Поэтому я отдаю этому методы лавры победителя - при прочих равных он легко запоминается и не содержит подводных камней.
Вступайте в нашу телеграмм-группу Инфостарт