О чем пойдет речь в статье?
- Я хочу очень вкратце рассказать про то, как вообще растут проекты: в чем заключается этот рост с точки зрения тестирования.
- После этого расскажу о различных решениях, которые мне кажутся неправильными, но их очень многие используют.
- Затем мы немного поговорим про решения, которые мне кажутся правильными.
- И в конце я поделюсь с вами несколькими «читерскими» приемчиками, которые иногда позволяют, не тратя никаких дополнительных ресурсов, где-то очень сильно выигрывать.
Я быстро «пробегусь» по всему, покажу вам возможные подходы, расскажу, как можно поступать в тех или иных ситуациях.
Обо мне
Немного обо мне:
- Я занимаюсь тестированием уже больше 10 лет.
- Работала в различных компаниях: Acronis, Kaspersky, 1С и некоторыхдругих.
- С 2009 года я руковожу компанией «Лаборатория качества». Мы занимаемся аутсорсингом, оказываем консалтинг в сфере тестирования, помогаем реализовывать различные проекты (крупные и не очень).
На кого рассчитан этот материал?
Здесь в основном присутствуют специалисты, отвечающие за разработку различных решений. Но даже если вы не являетесь тестировщиками, у вас, в любом случае, наверняка есть обязанности по тестированию, прописанные в регламентах, или, возможно, просто какие-то внутренние стремления повлиять на качество. Для того чтобы иметь возможность реализовать такие стремления, вам необязательно быть специалистом по качеству: вы можете это сделать, просто предлагая какие-то решения по улучшению конечного продукта.
Как растут проекты


Давайте для начала посмотрим, как вообще измеряются проекты.
Если говорить про совсем маленькие проекты, то я думаю, что в рамках 1С-деятельности вы с такими, скорее всего, не работаете.
Это когда приходит какой-нибудь один конкретный заказчик и говорит: «я хочу кнопочку, которая будет решать вот эту мою конкретную проблему». Фактически, получается, что у нас есть один источник требований, который точно знает, что хочет, и после того, как мы для него что-то сделали, у него все это замечательно работает.


После этого мы решаем, что имеет смысл вывести эту функциональность на рынок. Но когда мы предлагаем ее другим заказчикам, они нам говорят: «нет, это кнопочка должна работать по-другому». Мы удивляемся: ведь первый заказчик хотел совсем не так, что же теперь делать? И решаем добавить настроечку – одну, вторую, пятую, десятую – под каждого пользователя. При этом уже приходится учитывать разное окружение, разные платформы, выполнение одних и тех же действий, но в разных последовательностях и на разных данных.
В результате наш проект растет.
А когда мы уже начинаем интегрироваться с какими-то внешними сторонними решениями, мы уже становимся совсем большими. И, как в случае с тем же 1С, наш продукт вырастает в целую «платформу разработки».


В чем выражается такое повышение сложности?
- Во-первых, в количестве строк кода. Я работала на одном проекте, где было 2 миллиона строк кода – задача протестировать их все была физически невыполнима.
- Во-вторых,в количестве заказчиков (источников требований)
- И в-третьих, в количестве тех окружений, где все это должно работать.
Тут еще важно понимать, что на конкретных данных что-то может работать по-разному. Например, у меня есть три заказчика, которые используют одну и ту же «фичу» на пяти разных окружениях и в пяти разных последовательностях. Соответственно, конкретных комбинаций использования у меня получается 5*5*3=75 (потому что заказчиков три, а платформ пять и сценариев пять). Немало.
Получается, что весь наш рост идет по экспоненте. Сложность повышается и непрерывно растет все дальше и дальше.
Как это обычно происходит?
Какой-нибудь менеджер по продажам где-то на конференции или в личном общении обещает клиенту, что, несмотря на то, что пока что наше приложение работает только на IE, мы, если нужно, его доработаем, и на следующей неделе оно будет поддерживать еще пять браузеров.
И вот этот менеджер приходит к разработчику и говорит: «нужно поддерживать». И разработчик отвечает: «да без проблем, будет работать, никуда не денется!»
И на этом работа и менеджера по продажам, и разработчика завершена – все счастливы. А тестировщик сидит и думает: «ребята, мне же на то, чтобы это проверить на одной платформе, два дня надо было, а теперь еще и на пяти платформах проверять, что ли?
Если он проверяет на пяти платформах и там все работает, то получается, что он был вообще единственный, кому пришлось «попахать». А если там выявляются проблемы, то уже понятно, что они потом вернутся к разработчику – и на исправление, и на переисправление. И дальше уже циклы будут более длительными.
В любом случае, рост сложности проекта всегда по умолчанию затрагивает тестирование.
Зачем вообще нужны тестировщики? Казалось бы, разработчики – такие умные ребята! Взяли, написали и все сразу хорошо работает! Но так не получается. Необходима некоторая эмпирическая проверка, чтобы подтвердить, что все хорошо, либо убедиться в том, что существует ошибка. Иначе, основываясь на каких-то логических предпосылках, которые были у нас в голове при разработке, мы всегда можем столкнуться с какими-то сложностями. И, когда нам кажется, что все должно работать, оно может не работать, поэтому проверять все равно приходится.
Неправильные решения по организации тестирования
Так вот, представьте, что наш проект растет: у него появляются различные интеграции, связи, и соответственно, хочется все это как-то лучше тестировать. Какие решения по тестированию могут оказаться неправильными?


Первое понятное решение, которое многим приходит в голову, это: «давайте наймем еще тестировщиков. Вот у нас был один браузер, а теперь пять, так давайте в пять раз больше тестировщиков наймем».
Но, как правило, процесс тестирования так не масштабируется, потому что при увеличении штата возникает потребность всовсем другом управлении, подразумевающем некую централизацию и структуризацию. В любом случае ничего хорошего из этого не выйдет. И бюджеты у нас тоже не бывают настолько «резиновыми».


Следующее решение – не самое правильное, но на него от отчаянья соглашаются очень многие: «давайте пользователю отдадим, и там посмотрим, что получится».
Чаще всего, это не очень хорошо заканчивается, поэтому имеет смысл так не делать.


Еще есть решение, которое обычно предлагают разработчики – «автоматизаторы до мозга костей». Они говорят: «давайте, если тестировать, то автоматизированно».
А что происходит, когда мы автоматизируем хаос? Получается автоматизированный хаос. Понятное дело, что автоматизация бывает очень полезной, выгодной и оправданной, но сам по себе этот наш «бардак» она не решит. К тому же, если и внедрять автоматизированное тестирование, то для этого нужны какие-то грамотные продуманные тестовые подходы.


Ну и четвертое решение, к которому очень часто приходят крупные компании, это замедлять тестовые циклы, делать релизы все дольше и дольше, выделять на тестирование несколько недель. В результате можно очень долго ждать, пока отдел тестирования все протестирует, проверит, очень поздно сообщит какие-то ошибки, а после того, как мы их исправим, они еще несколько недель будут все перепроверять.
Я знаю одну очень крупную в России компанию, у них еще поезда ходят. Так вот, они свой сайт в летний период не обновляют вообще, потому что летом билетов через сайт покупается много, нагрузка на движок большая, и им страшно. Поэтому у них все релизы начинаются с октября. А с мая по октябрь релизов нет вообще. Компания большая, они выросли, и им страшно – я их в принципе понимаю.
Правильные решения по организации тестирования
А теперь давайте посмотрим, какие же все-таки решения, как мне кажется, могут быть более-менее правильными.

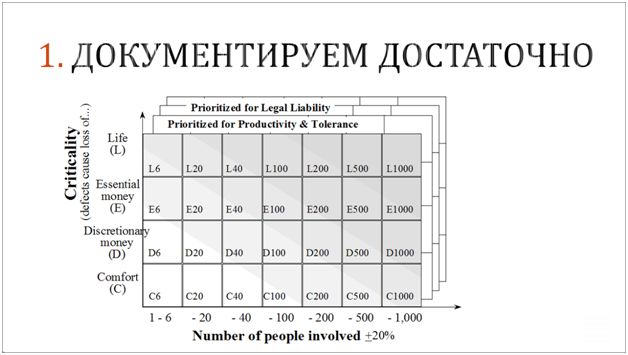
Во-первых, есть такая модель, которую предложил Алистер Коберн, автор таких методологий разработки, как crystal и crystallight.
В этой модели отражена взаимосвязь между критичностью проекта, количеством его участников и требованиями к документированию. Под критичностью подразумевается риск ошибки при реализации, когда он может быть связан с жизнью людей (как, например, в каком-то военном ПО и в авиапромышленности), или с «большими деньгами», как у крупных банков. А если вы разрабатываете какую-нибудь браузерную игрушку, то критичности нет, потому что риски маленькие.
Так вот, Алистер Коберн сказал следующее: «чем выше риски и чем больше людей на проекте, тем больше для него требуется документации». Потому что когда количество людей на проекте растет, передавать им информацию устно становится уже недопустимо, поскольку при этом теряется возможность непрерывно контролировать все эти процессы. Ответственность повышается: людей больше, вовлеченных задач больше, интеграции больше, тестовых данных больше – всего больше.


В качестве документации нам, конечно, нужны и какие-то тесты, чтобы были прозрачны статусы их прохождения, и мы видели, что именно было проверено.
Причем, если говорить о необходимом объеме покрытия тестами, то, например, когда мы выписали, сколько нужно тестов, чтобы проверить обычное создание платежного поручения в одном типовом решении (не скажу, в каком), то оказалось, что нужно чуть больше 800 тестов. И это – просто такая физическая потребность с точки зрения основных комбинаций входных данных, которые там возможны: например, мы можем ввести туда очень большие или очень маленькие значения, выбрать их из справочника или откуда-то еще.
Что нам дает эта задокументированная информация? Благодаря ей мы можем управлять рисками и своевременно сказать: «ребята, вот это мы проверили, а это мы не проверили».

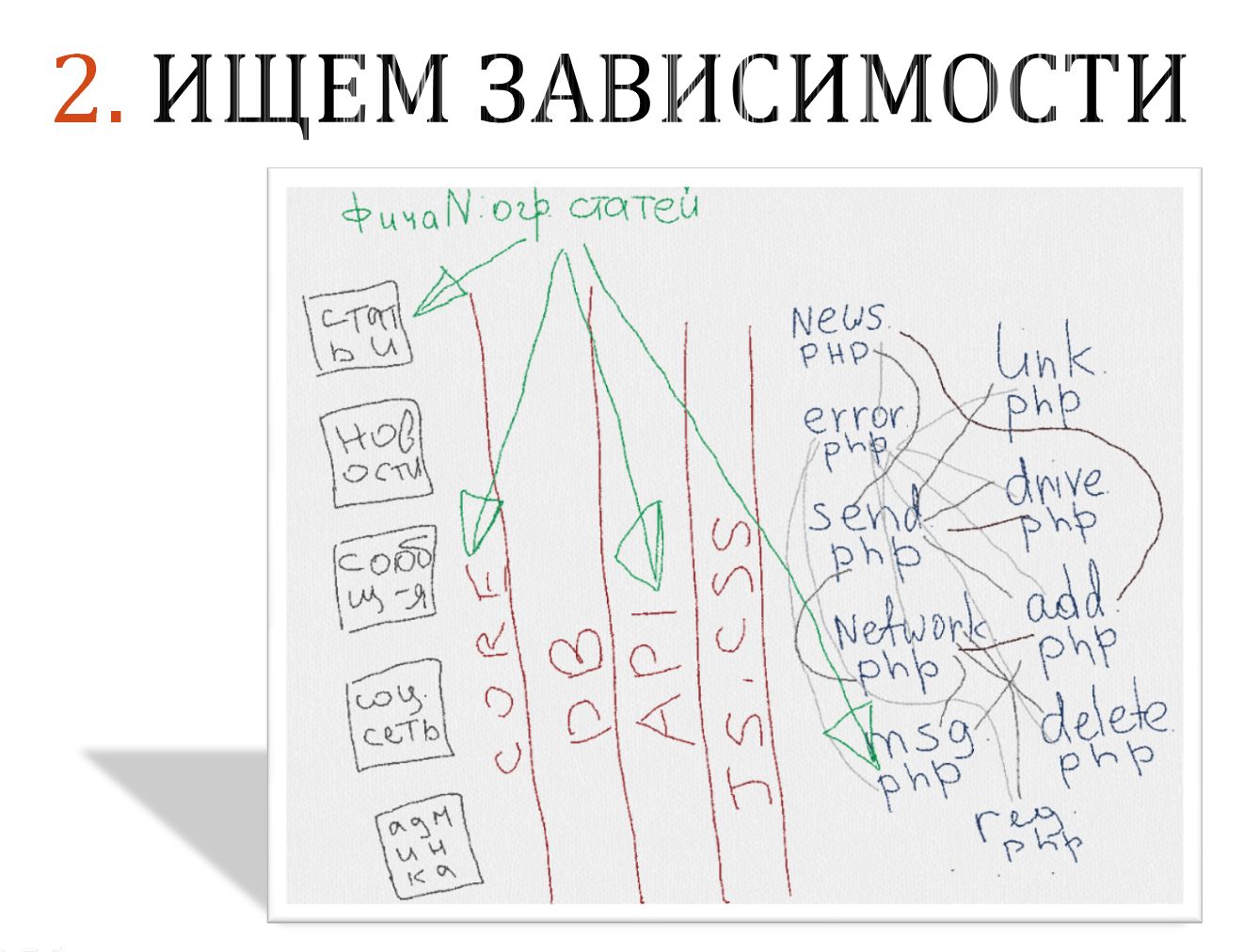
Естественно, в больших проектах мы понимаем, что все проверить мы не сможем. Поэтому нам очень важно выяснить, какие объекты связаны между собой и имеют какие-то пересечения, а где таких пересечений быть не может. Тут мы зачастую просто садимся с разработчиками, с архитекторами и начинаем выяснять, как все устроено, где при выполнении той или иной операции в нашем программном продукте могут затрагиваться рискованные зоны, в которых происходят такие пересечения, и соответственно помечаем их, как зависимые друг от друга.
Обычно мы, как тестировщики, приходим ради этого в отдел разработки, но иногда и сами разработчики первые идут к нам с желанием поделиться этими сокровенными знаниями.
В любом случае, получая эту информацию, мы узнаем, где вообще находятся эти риски, эти слабые зоны.

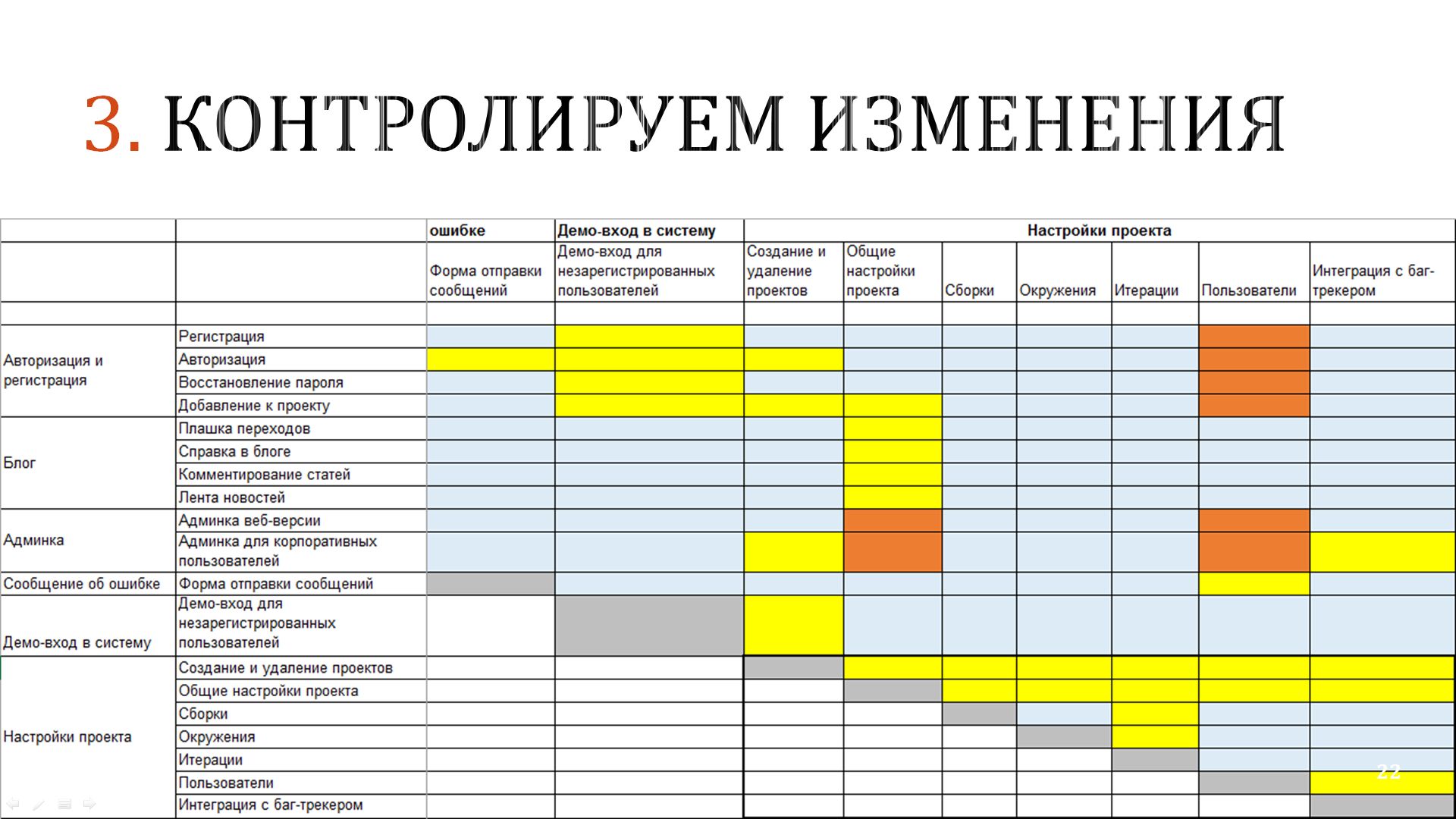
Проводится тестирование, которое называется «регрессионным» – это когда разработчики что-то поменяли или «впилили» новое, и нужно проверить, работает старое или нет, есть там какой-то регресс (провал) или все в порядке. Однако, когда продукт большой, объем такого «регрессионного тестирования» может вырасти как снежный ком, и проверить весь функционал целиком становится уже невозможно, но если мы не станем этого делать, риски возрастут.
Поэтому что мы делаем? На слайде вы видите скриншот одной таблички (одной маленькой части этой таблички). В ее столбцах и строках перечислены одни и те же фичи программного продукта. И на их пересечении мы совместно с командой разработки помечаем, какие фичи могут влиять друг на друга, а какие нет. Где-то разработчики говорят: «вот здесь эти фичи очень тесно между собой связаны, и при затрагивании одной из них могут возникнуть проблемы в другой». А где-то мы, исходя из своего опыта тестирования, говорим: «вот здесь эти связи бывают очень часто».
Что мы делаем с этой табличкой дальше?
Выпускается какая-то новая версия продукта. Мы знаем, что в ней затронуты 3 фичи: из строки 22, 35 и 47.И я сразу же вижу, с какими столбцами они связаны немного (эти ячейки помечены желтым цветом) или сильно (оранжевым). Мы начинаем с оранжевого и переходим к желтому. Все остальное, что вроде бы как не связано, мы уже не смотрим.
Естественно, там тоже могут быть ошибки. Как я уже говорила, пока эмпирическим путем все не проверим, ни в чем не убедимся. Но здесь мы сразу идем по приоритетам, и можем отследить те изменения, которые были затронуты с большей вероятностью. В результате растет скорость предоставления обратной связи, которая важна для успешной разработки.

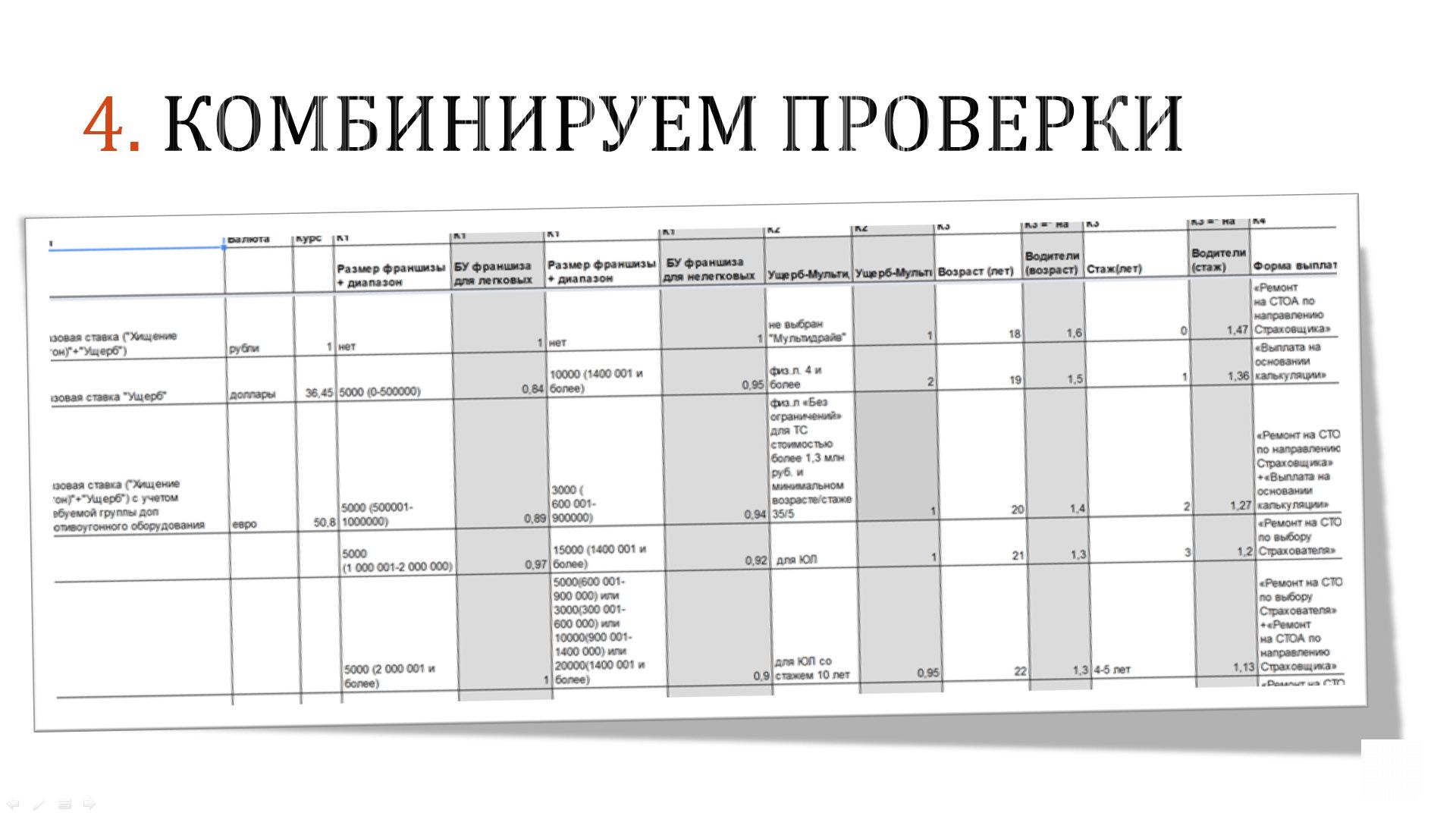
Следующее решение – это некоторая комбинация проверок. Здесь в качестве примера можно привести то же самое платежное поручение, у которого есть огромное количество полей, принимающих те или иные значения. Допустим, мы хотим проверять, как поведет себя система при установке туда различных величин: больших, маленьких, стандартных, нестандартных, хороших, недопустимых и т.д., которые мы можем комбинировать в рамках одной проверки.
Кроме этого, мы можем провести так называемые «негативные проверки», когда в систему вводится что-то недопустимое. Но их мы не должны комбинировать, они всегда должны проверяться по отдельности, потому что если все корректно упадет с ошибкой из-за одной негативной проверки, то это не значит, что другая негативная проверка пройдет так же успешно.
Но любые позитивные проверки мы можем объединять вместе, и в одном тесте сразу проверять огромное количество данных.


Особенно здорово, когда данные для тестирования мы можем подготовить заранее: это могут быть медиа-файлы, библиотеки, базы данных – все, что угодно. Единожды подготовленное мы можем переиспользовать и в последующем тестировании. Например, у нас очень много тестов связано с правами доступа (что этот пользователь имеет доступ туда, а этот – сюда, и у него эти файлы должны отображаться так, а эти отчеты читаться вот так). И чтобы это проверить, мы заранее готовим базы с нужными данными, чтобы сразу по ним видеть, для каких прав в каком отчете какие значения отображаются. Естественно, уже на основе этого мы можем сделать значительно более быструю какую-то эффективную и показательную для нас самих автоматизацию.Но здесь очень важно то, что мы не заводим каждый раз в справочники одни и те же данные, а используем информацию, которую единожды заготовили заранее.
«Читерские» способы увеличения качества тестирования


Кроме уже упомянутых решений, есть еще несколько «читерских» методов, которые нам обычно помогают.
В чем заключается это «читерство»? Тестирование – это очень зависимая область, в которой нагрузка получается очень неравномерной:
- Сегодня мы сидим, и нам делать нечего: у нас нет сборки и непонятно, когда она будет. Мы, конечно, можем что-нибудь поавтоматизировать «на будущее» или научиться чему-то умному, но какой-то конкретной срочной работы у нас нет.
- А послезавтра выходит сборка, которую нужно отдавать заказчику через два дня, потому что вышел новый формат отчета, и они ждать не могут. И за эти два дня нам нужно проверить целый мир, целый космос – конечно, мы не успеваем.
Получается очень большая нелинейность нагрузки, зависящая от того, когда и что готово. И вот эту нелинейность мы с вами можем немного компенсировать.
Наверняка вы слышали про то, что у нас есть проектный треугольник: сроки, бюджет и качество. И считается, что невозможно повысить качество, не расширив бюджет или сроки. Но это, конечно, не совсем правда.


Во-первых, есть интересный опыт – привлекать для проверки программных продуктов различных внешних бета-тестировщиков. Правда, это не работает на достаточно глубоких сценариях, где требуется очень квалифицированная проверка, но на стандартных сценариях (на проверке трех миллионов окружений) мы получаем вполне детальную расширенную обратную связь от наших пользователей.
Недавно мы делали такой проект для одной очень известной многопользовательской системы, которую все знают. У них в компании было пять тестировщиков, которые всей командой за месяц находили в системе, допустим, 200 каких-то ошибок. И мы решили устроить бета-компанию, привлечь к тестированию этой системы участников на портале тестировщиков software-testing.ru. И тому, кто заведет наибольшее количество полезных ошибок, пообещали в рамках этой бета-компании приз – iPhone. Ошибки начали сыпаться: и сыпались, и сыпались. Вся команда сидела, их обрабатывала и заводила в багтрекер. За время этой компании (две недели) было заведено, допустим, 250 ошибок – имеются в виду только те ошибки, которые были приняты командой на исправление. Но если поделить стоимость iPhone на 250 и если поделить зарплату 5 тестировщиков в месяц, сидящих в офисе, на 100 (количество ошибок, заводимое штатными тестировщиками за две недели), то получается, что стоимость одной ошибки из этой бета-компании нам обошлась в 10 раз дешевле. И мы так удивились, что за маленькую детальку iPhone получили столько полезного фидбека.
Помимо портала software-testing.ru есть и другие специальные площадки – fixber.ru, utest.com, freelansim.ru – их достаточно много. На них мы можем привлекать людей за вознаграждение, чтобы они поделились с нами информацией о конкретных найденных ошибках. Это очень помогает наращиванию покрытия наших платформ.


Следующее «читерство» – это, конечно, аутсорс.
Многие воспринимают аутсорс как некоторый способ нарастить отдел, правда, не в самом офисе, а где-то со стороны (то, что мы уже рассматривали в неправильных решениях). При этом вроде как ничего не меняется – мы опять же раздуваем бюджет, у нас опять же растет количество людей.
Но когда же все-таки выгодно использовать аутсорс?
- Либо мы говорим про вот эти пики, предрелизные моменты, когда люди привлекаются для содействия в тестировании незадолго до релиза (только на это некоторое количество дней).
- Либо у нас происходит такая ситуация, когда нам нужно в короткие сроки «объять необъятное». Вот вроде бы был у нас еще вчера маленький проект – какая-то крохотулька, а сегодня мы уже видим, что кодовая база огромная, а тестового покрытия для нее до сих пор нет (мы где-то чуть-чуть «лопухнули» и пропустили этот момент). Здесь тоже можно привлекать аутсорс для того, чтобы как-то наработать ручных или автоматизированных тестов, и догнать разработку. Это позволит нам нашей достаточно компактной управляемой командой справляться и дальше.


Ну и третий момент – это, конечно же, некоторые «ролевые игры» в команде.
Что я имею в виду под ролевыми играми?
Перед релизом очень часто другие участники проекта, такие как системные администраторы, помощники бухгалтеров и еще кто-то скучают и хотят нам помочь: видят, что мы так стараемся с релизом, а там еще поле работы непаханое. Поэтому мы очень часто привлекаем к тестированию и других участников. Конечно, чтобы их привлечь, необходима соответствующая подготовка, поэтому мы дополнительно снабжаем их инструментарием. В частности, предоставляем им:
- какой-то список того, что необходимо проверять.
- какие-то критерии проверки,
- а также те самые готовые тестовые базы, на которых есть смысл это тестировать.
Подключаем к процессу тестирования весь офис, всех, кого только можно, и получаем абсолютно разный фидбек, который позволяет нам увидеть ситуацию с разных сторон.Особенно ценно, если эти люди квалификационно по ментальным моделям схожи с нашей целевой аудиторией. Они замечают то, что мы, как тестировщики, не замечали: у нас там свои профдеформации, и мы все видим сломанным. А они нам очень часто показывают, что использовали бы это вообще по-другому.
Поэтому опять же, в моменты «пиков» мы подключаем людей на тестирование, чтобы как-то это скомпенсировать.
****************
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2015 CONNECTION 15-17 октября 2015 года.
Приглашаем вас на новую конференцию INFOSTART EVENT 2019 INCEPTION.
Вступайте в нашу телеграмм-группу Инфостарт