






{kind=link}
ВНИМАНИЕ! Есть новая статья как сделать такую задачу на Яндекс Облаке.
Распознавание текста из изображений и PDF с помощью нейросетей Yandex Vision и 1С
Здравствуйте!
В этой статье я рассмотрю возможности распознавания текста (OCR) на чистом 1С с помощью нейросетей сервиса Google Cloud Vision.
Всё началось с того, что мне попалась на глаза статья на хабре о том, что можно очень легко использовать нейросети как сервис. Не нужно писать свою сеть и обучать ее, можно воспользоваться уже готовыми API. Принцип работы очень простой: нужно сделать POST запрос с картинкой, закодированной в base64, и получить json-ответ. И, разобрав его, программа может понять что изображено на картинке (Label detection) или же получить распознанный текст (OCR). Детальное описание возможностей Cloud Vision API можно посмотреть по ссылке. Работу с этим сервисом можно легко реализовать на чистом 1С, что я и сделал.
Регистрация в консоли разработчика и получение ключа.
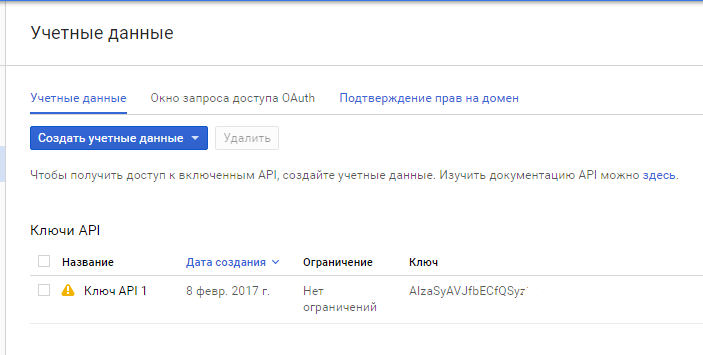
Для начала нужно зарегистрироваться в консоли разработчика по ссылке console.cloud.google.com. Нужно создать проект, включить для него Google Cloud Vision API. Далее в меню консоли необходимо перейти в Диспетчер API-учетные данные и создать ключ API, который будет использоваться для тестирования. В документации есть хорошая инструкция на английском. Если все было сделано верно, то ваша консоль должна выглядеть как на картинке ниже:

Формат json-запроса
Согласно инструкции сервису нужно прислать json с полями requests (массив) image (объект с полем content где содержится base64-закодированное изображение) и features (массив с указанием нужного типа распознавания type, в данном случае TEXT_DETECTION). Код, который это делает, можно посмотреть в приложенной внешней обработке. В итоге получается вот такой файл JSON:
{
"requests": [
{
"image": {
"content": "base64 image content"
},
"features": [
{
"type": "TEXT_DETECTION"
}
]
}
]
}
Получение ответа Google
Отправка данных осуществляется с помощью объекта HTTPСоединение по протоколу HTTPS (с установкой ЗащищенноеСоединениеOpenSSL) и метода ОтправитьДляОбработки. В него передается HTTPЗапрос с сформриованным json файлом для отправки, заданным через метод УстановитьТелоИзДвоичныхДанных. В json-ответе Google нас интересует первый элемент с именем свойства description и его значение, в котором будет содержаться распознанный текст.
Попробуем отправить на распознавание картинку с английским текстом:

И вот что приходит в ответ, приведу фрагмент текста:
CEN Perform a wireless installation (wireless models only)
Before starting the installation, verify that the wireless access
point is working correctly, the computer is connected to the
network, and the product is turned on.
product, go
If there is not a solid blue light on the top of the to process A.
to
If there is a solid blue light on the top of the product, go process B.
1. Connect the USB cable between the computer and
the product. The HP Smart Install program (see picture
Как видно, получается очень хорошее качество распознавания.
А теперь попробуем русский текст:

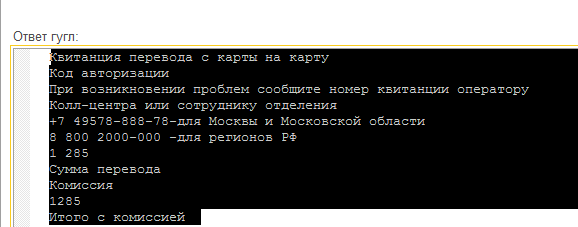
И вот что получается в ответе от Google:
A
KBMTaHUIA nepeBopa C KapTbl Ha KapTy
KOA aBTOpH3aUnn
npH BO3HMKHOBeHun np06neM, cooounTe HOMep KBHTaHurn onepaTopy
Konn-ueHTpa unu coTpYAHMKV OTAeneHMA
+7 495 78-888-78-ANA MOCKBbIM MOC KOBCKoi o6naCTIA
8 800 2000-000 -Ana pernOHOB P]4;
CyMMa nepeBoga:
1 285P
Да, печальный итог. Но, как подсказали в комментариях, оказывается нужно в запросе у свойства imageContext поставить languageHints в ru.
Работа с русским языком
Как мне верно подсказали в комментариях, есть возможность указать язык для распознавания. Получается вот такой json-запрос:
{
"requests":
[
{
"image": {
"content": "base 64 image content"
},
"features": [
{
"type": "TEXT_DETECTION"
}
],
"imageContext": {
"languageHints": "ru"
}
}
]
}
Отправим для распознавания ту же самую квитанцию и получается очень хороший результат:

Выводы
Сама по себе возможность использовать мощнейшие нейросети Google с помощью несложных запросов впечатляет.
Распознавание русского языка тоже работает весьма хорошо, таким образом может вполне составить конкуренцию ABBYY. И цены на распознавание у Google Cloud гораздо более низкие.
В приложенной к статье внешней обработке можно посмотреть код конструирования JSON запроса, отправки его через HTTPСоединение и получения ответа.
PS Во вложении я добавил и новую версию обработки, которая формирует json запрос для распознавания русского языка.
Вступайте в нашу телеграмм-группу Инфостарт