Сейчас, действительно, настал момент, когда надо задуматься о переходе на PostgreSQL. Компания «Инфософт», как интегратор, давно интересуется этой темой, причем, следит за связкой PostgreSQL именно с 1С.
Все давно слышат, что системе 20 лет, она удачно работает как на маленьких инсталляциях, так и на огромных базах данных. Но как она работает совместно с 1С – большой вопрос. До сих пор есть опасения, что система долго и сложно настраивается.
Все эти сложности из-за информационного вакуума. Знающих людей достаточно мало, даже в рамках страны, и тем более, в рамках партнерского сообщества 1С. Людей, которые конкретно могут подсказать настройки, – единицы.
Наша компания накопила определенный практический опыт по переходу на PostgreSQL. Мы работали и на небольших инсталляциях, и на крупных – оперирующих терабайтами данных и обслуживающих сотни пользователей одновременно. Поэтому уверены, что наши подсказки понадобятся многим.
Подготовка к переходу и первый опыт
Непосредственно перед переходом придется решить один вопрос: на какой операционной системе это делать. Большинство переходов, осуществленных компанией «Инфософт», было совершено на ОС Windows. И вот почему.
Несмотря на то, что PostgreSQL разрабатывался под Linux-системы переход сам по себе с наиболее популярной системы в 1С на MS SQL на PostgreSQL – это риск. Риск, связанный с тем, что база данных работает совсем по-другому, и в большинстве случаев ее особенности малоизвестны. Поэтому если одновременно поменять операционную систему и перейти на Linux, то риск увеличивается в степень. Придется обучить администраторов с нуля, сломать все их стереотипы. Они всю жизнь работали на Windows. Более того, мир 1С – это 99% Windows. Конечно, есть энтузиасты, и их достаточно много, которые удачно ставят систему на Linux, но если что-то менять, то лучше постепенно.
Поэтому пока компания «Инфософт» проводит инсталляции на Windows. И тесты производительности 1С не выявляют особых кардинальных отличий на одной и той же скорости и конфигурации. Разница в реальных, не синтетических, нагрузках составляет 1-2% и не является критичной.

Первый опыт «Инфософта» – перевод базы данных Microsoft на PostgreSQL в самой компании. Что это за базы данных? Это полностью переписанные ПП1.3 (? Время: 3.56) на неуправляемых формах с интегрированной телефонией, рабочим кол-центром и т.д. до типовой бухгалтерии 3.0 уже на управляемых формах. Нагрузка составляет примерно 150 пользователей в пике.
Главным результатом перехода на PostgreSQL стало то, что пользователи ничего не заметили. Это один из самых положительных результатов, которые можно достичь при переходе. Какие-то процедуры стали немного быстрее, но в основном все работает точно так же. PostgreSQL позволяет спокойно спать администраторам ночью, и при этом не имеет никаких дополнительных расходов на покупку программного обеспечения, как сегодня MS SQL.
Поэкспериментировав на локальных серверах, мы перевели наш облачный сервис на PostgreSQL. Раньше он также работал на MS SQL.

1С Fresh в фирме 1С тоже частично работает на PostgreSQL. Мы полностью перевели наш сервис. Тут нагрузки серьезнее – 200 с лишним баз данных. Согласитесь, большая разница: администрирование 1 базы данных на 1,5 терабайта и 200 баз на 1,5 терабайта. Отличаются требования к отказу устойчивости сервиса, к работе на 24/7/366 (? Время: 5:20). Кроме того, клиенты находятся по России, технологических окон практически нет, так что требования очень жесткие.
Что тут нас ждало? Очень приятный сюрприз: типовые конфигурации 1С хорошо справляются со своими действиями после перехода. Никаких значительных переписок кода нет.
Ничего не надо делать с массовыми типовыми конфигурациями, если они выпущены после 2015-го года. Фирма 1С сделала большие шаги с точки зрения платформы и с точки зрения переписывания кода в типовых конфигурациях, поэтому от очень тонких моментов мы были избавлены.
Выход на рынок
После того, как все свои системы компания «Инфософт» перевела, было решено выйти на широкий рынок. Самым большим проектом по переводу с MS SQL на PostgreSQL был проект с крупным федеральным обувным ритейлером, который хотел перевести на систему PostgreSQL базы розницы.
Сложность перехода в данном случае заключалась в том, что необходимо брать в расчет сразу несколько сотен точек по всей стране, и все это должно реплицироваться. Это 40 баз общим объемом 6 терабайт. Это тысяча пользователей в онлайне. Очень жесткие требования к отказу устойчивости на уровне транзакций, при этом требования ужесточаются еще и тем, что никакого общего хранилища данных быть не должно. Все должно быть максимально независимо.
Тут очень сильно порадовала репликация PostgreSQL, работающая из коробки, плюс каскадная репликация, просто супер вещь, которая решает очень много задач. Фактически это полный аналог Microsoft, только полностью бесплатный.

Еще одним интересным проектом был перевод базы бухгалтерского учета федерального оператора экспресс доставки на PostgreSQL. Этот проект запомнился тем, что клиента перевели на новую систему за одну ночь. Представьте, 150 бухгалтеров ушли вечером, закрыв 1С в MS SQL, а утром пришли и открыли его в PostgreSQL. Ничего не поменялось в худшую сторону, некоторые операции стали работать лучше, некоторые продолжили работать точно так же. Клиент был настолько доволен результатом, что принял решение перевести все свои базы 1С, как существующие, так и проектируемые, на PostgreSQL. Он даже он готов рискнуть перейти на Linux в 2017 году.
Технические стороны перехода
Какие особенности нужно учитывать, чтобы угодить клиенту при переходе на PostgreSQL? В принципе имеется 3 этапа. На первом надо настроить код 1С, на втором – подкорректировать настройки самого PostgreSQL, а на последнем – заняться подбором железа. Рассмотрим подробно каждый из них.
Код 1С. На этом этапе больше всего проблем, но когда они решаются, получаем огромный эффект. Конкретный пример: возьмем номенклатуру 300 тысяч позиций и попытаемся сформировать ценники и этикетки на все позиции. У конкретного заказчика MS SQL справлялся с этой задачей за 15 минут. Полностью настроенный PostgreSQL на Windows на том же железе, к сожалению, пришлось ждать 6,5 часов. Он справился, но с большой задержкой. Еще один пример: номенклатура 10 тысяч характеристик. Открывая позицию номенклатуры, заказчик хочет видеть не только 10 тысяч характеристик, но еще и остатки по каждой характеристике, да еще и в разрезе складов. Опять же MS SQL справлялся за 30 минут, а PostgreSQL пришлось ждать 12 часов. Но все гениальное – просто. Более того, написано на ИТС фирмы 1С. Основной причиной такого поведения было левое соединение с виртуальной таблицей последних средств. Здесь главная рекомендация – выносите срез последних виртуальных таблиц в отдельную временную таблицу и затем уже делайте соединение, как требует бизнес-логика клиента. После этих изменений в коде (дольше их было искать, чем менять), скорости стали следующими: вместо 6,5 часов печать ценников производится за 13 секунд, вместо 12 часов открытие номенклатуры стало занимать 10 минут. Это совершенно приемлемые условия.
Еще одна рекомендация, правда, ее сложнее выполнить. Попробуйте избавиться от полного соединения. Тут уж если бизнес-логика позволит.
Никаких других рекомендаций нет.
Еще раз подчеркну, что все массовые конфигурации 1С прекрасно показывают себя на PostgreSQL. Не бойтесь переводить типовые инсталляции на PostgreSQL. Все отлично. Никаких задержек даже у такой тяжелой конфигурации как Комплексная 2.0 (там только запуск первого соединения к базе занимает около 1,5-2 минуты и минус 2 гигабайта на сервере 1С оперативки).
Перейдем ко второму этапу – настройки самого PostgreSQL. Как наточить нашу систему в связке с 1С?
Для 1С используются (? Время: 12:00). Одним из главных патчей, которые влияют именно на быстродействие, является online_analyze. Обратите внимание: на сайте 1С последняя релизная версия PostgreSQL вышла 1,5 года назад, новее нет. Она содержит критичную ошибку в конфигурации PostgreSQL. Этот патч (online_analyze) отключен. То есть мало того, что 1С и так любит временные таблицы, а PostgreSQL их недолюбливает, в конфигурации еще и патч отключен. Конкретно эта ошибка заставила нашу компанию отказаться от использования PostgreSQL на полгода. Мы поставили, попробовали, ужаснулись, но времени разбираться не было. А когда еще раз все перечитали, поменяли off на on, все поехало. Дальше остаются тонкости.

Еще несколько важных настроек.
1. Не отключайте autovacuum. Единственный оправданный случай, когда можно отключить «автовакуумное» время, - это загрузка DT (? Время:13:40) в базу. Тогда, действительно, он будет создавать лишние блокировки. Загрузка – монопольная операция, в базу больше никто не заходит. Вы отключаете autovacuum, все спокойно создается, а затем включаете обратно. Но чтобы autovacuum еще и плодотворно трудился и не сильно нагружал систему, количество worker-ов должно быть как минимум 4, а в идеале – 25% всех ядер, которые выделены серверу базы данных для работы с PostgreSQL.
2. Оnline_analyze.enaible обязательно on. Кто пробовал, и не устроило быстродействие, пересмотрите настройки в PostgreSQL. В самом конце, в самом неприметном месте, может быть такое «чудо».
3. synchronous_commit = off. Эту настройку могу порекомендовать, только если fsync включен. Тогда мы экономим время записи транзакции. Она записывает только валы, и дальше идем, не ждем записи базы.

4. В PostgreSQL имеется еще одно ограничение: здесь нет инструмента, похожего на профайлер. И чтобы собирать статистику, помимо технологического журнала 1С, рекомендую включать статистику logging_collector (оn).
5. Следующий параметр позволит ограничить запросы 10 секундами. Все, что быстрее 10 секунд, не надо собирать, иначе соберёте гигабайт, а все что выше – собирать. Параметр log_min_duration_statement варьируете, как хотите, собираете сначала пики, когда десятисекундные пики срезали, собираете трехсекундные и так далее.
6. Еще один параметр – update_process_title. Недавно появилась статья о результатах синтетического теста именно на Windows. Отключая параметр «обновление ID процесса», люди получили производительность в 2 раза выше. Но это только на очень серьезных нагрузках. В эксперименте тест начинал оправдывать себя только после 2 тысяч одновременных соединений. При этом на маленьких нагрузках это тоже не приводит ни к чему плохому. Все работало как раньше. Но на всякий случай включите, вдруг к вам зайдут 2 тысячи человек, а у вас система не выдержит.
Переходим к последнему этапу – подбор железа. Тут есть пара особенностей.
Во-первых, PostgreSQL не умеет работать многопоточно на много запросов. Один запрос – одно ядро. Поэтому количество ядер является достаточно критичным параметром при подборе железа сервера. Заставить PostgreSQL работать по-другому в нашей компании пока не знают как.
Второе ограничение. Мы живем в эпоху твердотельных накопителей. Нам повезло, они стали доступны и в то же время настолько надежны, что их можно использовать для баз данных. Единственное отличие: PostgreSQL в отличие от MS SQL всегда-всегда пишет в новое место, всегда создает рядом файл, неважно обновление это или нет. MS SQL создает файлик mdf, когда он пометил строчку на удаление, он пишет туда же. Это с одной стороны влияет на скорость, с другой – очень быстро наступит деградация ssd, если ваша операционная система и raid контроллеры не поддерживают команду TRIM. Иначе ssd (даже терабайтные) серверной версии «умрут» очень быстро, даже на 20 гигабайтной базе. На это обратите особое внимание. TRIM надо поддерживать. Обязательно.
Чтобы уменьшить требования к дисковой системе оборудования, можно воспользоваться несколькими трюками. Первый – директорию статистики перенести в диск оперативной памяти. Чем это хорошо? Это никогда не занимает много места – 256 мегабайт выделили, создали диск, перенесли. Даже если неожиданно каталог исчезнет, PostgreSQL не остановится. Просто будет появляться ошибка, что некуда записывать статистику. Тогда достаточно создать каталог заново, и статистика продолжит собираться. Несмотря на то, что директория не занимает много места, туда каждый процесс пишет очень много потоков, сильно нагружает диски. Очень рекомендую перенести директорию.

Первый трюк – это, можно сказать, must have. А второй – требует внимательности и аккуратности. Речь идет о переносе каталога журнала транзакций в оперативную память. В нашей компании это есть. Но я вам рекомендую это делать только в том случае, если у вас есть постоянный автоматический мониторинг репликаций, лучше еще и репликация каскадная. Если вдруг что-то пойдет не так, база встанет. Обратите внимание, если рискнете, нужно протестировать пиковые нагрузки на свои системы, чтобы понять, какой объем вала будет занят в оперативной памяти, чтобы выделить место заранее с запасом. Иначе, неожиданно сервер может остановиться.
Разработчики PostgreSQL, наверное, будут против такого решения, но оно очень помогает снизить нагрузку на дисковую подсистему. И в принципе где-то имеет право на жизнь. Наша компания пользуется таким решением год, и пока все хорошо.
Фичи
У PostgreSQL есть несколько неприятных особенностей, некоторые из них можно «пережить», другие – достаточно сложно.
Первая: PostgreSQL не умеет делать дифференциальное резервное копирование. Только полный backup. Казалось бы, ну и что? А то, что теперь место на резервном сервере, если вы хотите хранить информацию месяц (стандартный режим хранения), должно быть почти в 20 раз больше чем при использовании MS SQL.
Вторая: технологическое окно каждый день должно быть достаточно большим, чтобы спокойно сливать резервные копии. Как это обойти? Опять же с помощью репликаций. Настраиваете реплику, сливаете копии с серверов реплик и все прекрасно. Production CD работает, сервер реплики может иметь на борту любое сетевое хранилище данных, а там сливаете и сливаете.
Еще один момент – гораздо более серьезный: PostgreSQL не имеет средств валидации файлов backup. Совсем. Вы сняли backup и никогда не узнаете, можно ли из него восстановиться. Казалось бы, ладно, восстанавливайся, проверяй, что база целая. Отлично. А если база в 15 терабайт и восстанавливается 3 дня? Я трое суток не буду знать, у меня на тот день база живая или нет? Здесь разработчики нам обещают, что в версии 9.6 либо 9.7 появится средство валидации, а также дифференциальные backup. Но пока их нет. На это надо обратить внимание. Резервная копия – спокойный сон для админов. Такого тут нет.
В связи со всеми описанными моментами мониторинг системы на PostgreSQL особенно важен. Потому что нет профайлера, нет валидации backup, нет еще пары фишек, которые MS SQL имеет.
Поэтому рекомендуем настраивать средства мониторинга. Можно писать свои, использовать известные, например, Zaibix. Надо мониторить параметры железа, параметры баз данных, дополнительно мониторить еще лог, и вытаскивать из него ошибки...
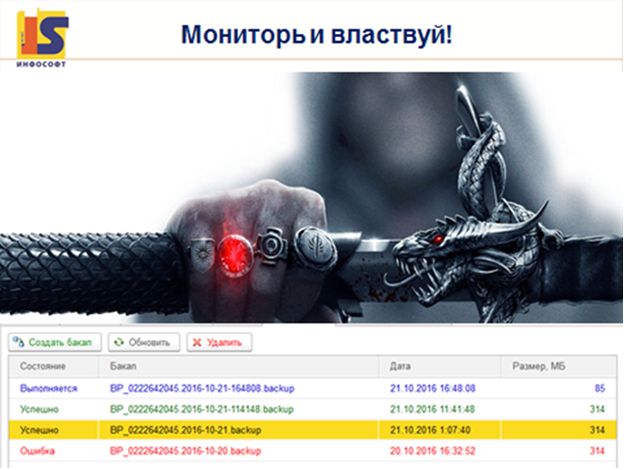
В компании «Инфософт» решили проблему валидации backup-ов следующим образом: на 1С мы написали специальный веб-сервис (его можно увидеть на картинке). Что он делает? Посмертно проверить файл backup невозможно, но в процессе создания backup утилита (? Время 22:38) пишет лог ошибок. Мы анализируем во время создания backup лог, выводим в отдельный файл лог ошибок, и если файл пустой, значит, backup создался удачно. Если хотя бы что-то помешало это сделать, файл будет содержать текст ошибки. Далее достаточно администраторам выдать само сообщение, что какой-то backup ошибочный. Они уже разберутся, проверят все логи и остальное.
В завершении хочется подчеркнуть, что PostgreSQL позволяет не только жить в парадигме «денег нет, но вы там держитесь», но еще и жить комфортно и безопасно. А все ограничения, которые есть, в принципе удачно решаются.
Отдельное спасибо команде Postgres Pro за то, что они очень быстро делают сборки для 1С. Фактически спустя месяц после появления релиза PostgreSQL на сайте уже есть сборка для Linux и Windows. Пожалуйста, тестируйте. Причем, сборка для Windows крайне удачна, setup делает за вас 90% настроек, остается буквально чуть-чуть «подшаманить» и все.
Пробуйте, дерзайте, у вас точно получится. У нас же получилось!
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2016 DEVELOPER.

Вступайте в нашу телеграмм-группу Инфостарт