Рассматриваемая ситуация


Подробнее о ситуации:
- Заказчик занимается микрофинансовой деятельностью – у них большая сеть.
- Очень много пользователей, работающих в online (в пике доходит до 1000 человек). Нагрузка на базу достаточно серьезная.
- По факту база должна работать стабильно практически 24/7. Регламентное время есть (не 24 часа полной работы базы), но оно очень маленькое, в пределах 4 часов, и желательно не каждый день. За это время нужно успеть произвести с базой все регламентные операции.
- Но, по сути, у заказчика все успешно работало.


И к нам они обратились в таком формате: «У нас все было отлично, но вдруг начали возникать проблемы, причем значительные».


Начали разбираться. С чем столкнулись?
- В их оперативной базе использовался регистр накопления, где было более миллиарда записей – это был такой «собирательный образ», с которым работало очень много пользователей. Возвращаясь к докладу Андрея Бурмистрова, хочу сказать, что в этом регистре было включено разделение итогов, и когда мы в нем измеряли количество записей итогов, их было 1.2 миллиарда. Это вообще «жесть». Но проблема была скорее не в количестве записей этого регистра, сколько в том, что большая часть запросов выполнялась именно к нему.
- Работали с этим регистром, по факту, три группы пользователей:
- Первая группа пользователей – это, так скажем, группа пострадавших, их работа заключалась в заведении договоров на эти микрофинансовые займы. Сами они создавали минимальную нагрузку на систему, но когда из базы формировались какие-то сложные выгрузки, они ничего не могли делать, у них работа просто вставала.
- Вторая группа пользователей – это аналитики, основные зачинщики проблем. Они создавали на базу достаточно большую нагрузку, потому что делали оперативные отчеты, которые формировались по 3-5 минут. В течение этого времени с базой вообще никто не мог работать, а аналитикам эти отчеты были нужны достаточно часто.
- Третья группа пользователей – это группа коллекторов. Они делали еще более дикие выборки, общее время формирования которых доходило до получаса. Но им оперативные данные были не нужны, и в этом была принципиальная разница между второй и третьей группой, поэтому мы с ними работали очень по-разному.
- И тут начинается интересное. Дело в том, что в этом регистре очень много записей (по факту, примерно 40%) находилось в будущем. Помните слова Андрея, который говорил о том, что какие-то случайные записи «из будущего» могут сломать работу системы? У нас в будущем была просто тонна записей, и это не было случайностью, это было, по факту, осознанным самостоятельным решением заказчика. Они, таким образом, решали вполне конкретную проблему. Дело в том, что ранее для сведения взаиморасчетов они ежемесячно делали один регламент, в рамках которого рассчитывали все взаиморасчеты по всем имеющимся договорам. Поначалу все было хорошо, но с определенного момента они увидели, что не укладываются в регламентное время, и решили сделать по-другому – не тратить операционное время на заведение регламента, а заблаговременно рассчитывать весь график платежей, чтобы понимать на будущее вперед, какие суммы задолженности возникнут к определенному моменту. Поначалу с этим тоже все было хорошо, пока они не рассчитали все договора, которые были заведены когда-то в прошлом, после чего у них в базе сформировался такой объем записей, что все начало «ложиться» и начались серьезнейшие проблемы.
- Тут еще важно отметить и тот факт, что итоги были включены, но не рассчитаны.
- И регламенты по обновлению статистики MS SQL тоже были настроены, но за ночь они выполниться не успевали.


Как поступает сервер 1С в случае, когда регламент MS SQL не успевает сделаться в нужное время? Как вообще работает сервер, когда у вас столько записей в будущем? Например, если вы захотите взять данные на сегодня (сегодня у нас 26 октября), а у вас последние ежемесячные итоги рассчитаны на конец сентября, тогда сервер будет всегда пытаться брать текущие итоги. Но если в обычной деятельности текущие итоги – это конец октября (что-то близкое к текущей дате), то в их случае это было сильно далеко впереди. К тому же текущие итоги, по сути, всегда берутся на конец эпохи, на 3099 год. И в данном случае, если бы даже у нас ежемесячные итоги бы рассчитаны на конец сентября, сервер все равно бы лез максимально вперед в будущее, где находятся самые последние записи. И потом такой вот лавиной цунами выкручивал бы оттуда дикие обороты полностью всего до текущей даты. Это собственно и происходило. Но даже если бы у них не было записей в будущем, то из-за того, что ежемесячные итоги у них были два с половиной года назад, а работали они чаще всего с текущими датами, они бы все равно никакого профита не получили – не смогли бы просто. А тут еще и такая ситуация наложилась.
Принятые решения по оптимизации


Конечно, ситуация печальная, но что с ней делать-то?
Закономерным решением было:
- Рассчитать ежемесячные итоги. Конечно, их нужно рассчитать не все сразу, а последовательно, потому что этот процесс занимает много времени, а регламентное окно узкое.
- И, конечно же, надо было полностью снести текущие итоги – прямо снести и отключить. Почему? Причины две. Помимо того, что они там создают паразитическую нагрузку, они же еще и постоянно плодятся – пока они включены на регистре, эти паразитические записи будут постоянно появляться. А если еще и сервер 1С будет брать всегда именно их, то от них очевидно, надо избавляться.
- Ну и все-таки надо обновить статистику.


Но все это не просто. Я бы даже сказал, что это очень непросто, потому что если использовать стандартный подход, который исповедует 1С, то у нас бы все это заняло около 13 часов. Что бы при этом происходило?
- При стандартном отключении текущих итогов на регистре из него последовательно начали бы удаляться записи. Построчно. А вы представляете, сколько там записей – там 1.2 миллиарда. Даже на мегамощностях заказчика на это ушло бы 13 часов. Мы предложили заказчику: «давайте отключим это по всем канонам 1С». Они говорят: «нет, нам такой вариант не подходит, давайте что-то думать дальше».
- И кстати, про интерфейсные настройки MS SQL – в сервере MS SQL нет никакой такой интерфейсной настройки, которая бы позволяла обновлять какие-то таблицы выборочно. А полное обновление статистики происходит целиком по всему и занимает достаточно большое время. Соответственно, просто запуск регламента еще не означает, что он будет успевать проходить.


В результате, мы приняли решение просто снести таблицу итогов и напрямую сделали truncate table из MS SQL. Сразу оговорюсь, что трюк был выполнен профессиональными каскадерами, в домашних условиях не повторять. Тем более что 1С не просто так запрещает прямые запросы к базам данных. Почему? Потому что текущие итоги и обычные ежемесячные итоги – это одна и та же таблица. И когда мы ее снесли, снеслись также и ежемесячные итоги. А 1С помнит, что там были итоги, рассчитанные два с половиной года назад. И она пытается к ним обратиться, а база ей отвечает: «какие итоги? тут ничего нет». И все, коллапс. Такие случаи надо предусматривать.
Естественно, я не рекомендую прямые запросы к базе, но у нас была вынужденная ситуация. Наверное, к этой возможности можно иногда прибегать, если продумать все возможные последствия. Потому что в таких ситуациях целостность данных оказывается под очень большим вопросом.


И следующим шагом мы обновили статистику. Для этого мы использовали скрипт, текст которого приведен на слайде. Конечно, это не наше открытие, в интернете есть различные варианты этой настройки. Мы, по сути, просто взяли в основу то, что нашли, и доработали под свои нужды, чтобы обновлять статистику только по тем объектам, которые были изменены. В результате регламент стал проходить достаточно быстро – за считанные минуты. Кому надо – пользуйтесь. В интернете есть разного рода альтернативы.
После этого нагрузка на базу в целом резко уменьшилась, и если изначально запросы выполнялись по 3.5-5 минут, они стали отрабатывать гораздо быстрее, чаще всего секунд за 15.
«Подводные камни»


Но все равно остались и аномальные случаи, когда база на небольших запросах «подвисала» очень долго.
Начали разбираться, и выяснилось, что нагрузка увеличивалась за счет того, что в системе неконтролируемо использовались внешние обработки и отчеты, у которых были разные версии, потому что заказчик их постоянно допиливал, менял. А когда у тебя онлайн в базе работает почти тысяча пользователей, контролировать запуск различных версий внешних обработок очень сложно. И если этот вопрос не решить сразу жестко, будут продолжать использовать «кто в лес, кто по дрова». В результате мы решили использовать те же самые отчеты и обработки, но прикрепленные к системе. И если они дорабатываются, то просто выпускается новая версия и сразу прикрепляется. Потому что использовать внешние обработки, свободно распространяемые по почте или как-то еще – это плохой вариант, он может приводить к большим печалям на больших нагрузках.


Казалось бы, наконец, все заработало: запросы начали выполняться быстро, оперативная работа пошла, и заказчик вздохнул с облегчением.


Но не тут-то было. Приходит начало месяца и у заказчика опять все «ложится». Там была печаль печальная.


Обычно при обращении к оперативным объектам в базе – открываешь, одна секунда, и ты уже все получил. А тут они начали открываться по 16, по 25, а некоторые еще и больше секунд. Откуда такая аномалия – непонятно. Заказчик говорит: «Вы нам сказали рассчитывать итоги и обновлять статистику – мы все делаем. Вот вам план запроса, только решите проблему, потому что у нас начался сезон, и мы однозначно не можем тратить на это время. У вас есть полчаса, час, давайте, что-то решайте».
Мы посмотрели план запроса – он вообще какой-то дикий, аномалия налицо. Вроде бы и статистика обновлена по регламенту, и итоги рассчитаны – все должно быть нормально. В результате обсуждения решили посмотреть, когда, в каком часу была обновлена статистика – и увидели, что она была обновлена ночью, а итоги рассчитаны уже утром, что и порождало такую аномалию. После этого мы уже известным вам скриптом вновь обновили статистику, и все начало «летать».
Но возник закономерный и интересный вопрос – а как так получилось? Откуда в базу закралась такая барабашка? Почему так себя ведет планировщик? Что такое вообще обновление статистики для планировщика?


Вообще планировщик – это конечно огромный черный ящик и сервер 1С с ним никак не взаимодействует. Планировщику вообще не интересно все внешнее воздействие – его не волнует, как вы написали запрос или какие вы отборы там поставили. На то, как он формирует план запроса, вы вообще никак повлиять не сможете. По факту, обновление статистики и создание индексов на таблицах – это единственное, или почти единственное, что может повлиять на поведение планировщика.
Как планировщик работает?
- Пока вы статистику не обновили, он видит, что есть итоги на конец сентября, и у него указано, какой там индекс, он знает, что раз таблица огромная, искать надо в индексе. Он находит какую-то запись, выбирает из нее все связанные подзапросы, получает данные, и никаких проблем нет.
- А тут происходит расчет итогов, который добавляет в таблицу сколько-то записей, о которых планировщик и понятия не имеет. И он начинает просто как слепой шариться по этой таблице, и искать, а где там нужные ему записи?
- А когда ты статистику обновляешь, планировщик прозрел, увидел, что все понятно, вот он, индекс, можно делать поиск по индексу и сканировать всю таблицу ему уже не надо. Он нашел нужную запись и ее отдал.
Когда таблица 10 тысяч записей – это может быть не критично. А когда в таблице сотни миллионов записей и итогов за один месяц там очень много, тогда это становится колоссально критично. Поэтому очень важно понять эту логику, как планировщик все это подтягивает. Ну и собственно, сервер 1С так же работает, потому что он тоже не особо напрягается, думая, как MS SQL сервер будет формировать эти выборки.
Инструменты для изучения проблем производительности

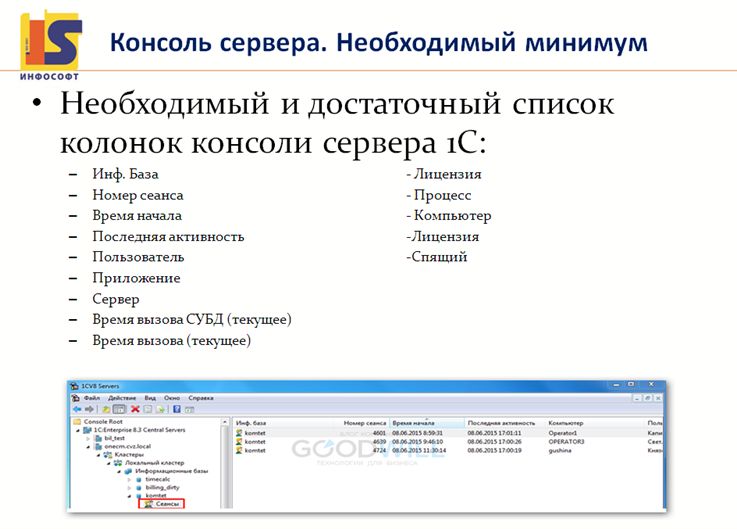
Теперь важно обратиться к тем инструментам, которыми мы пользовались для этого случая, и вообще для всех случаев пользуемся.
Вроде все знают, что существует корпоративный инструментальный пакет, но в реальной жизни, чтобы ты пришел к заказчику и сказал – вот он, КИТ, все настроено, все классно, открывай, анализируй, все тебе дано – так в реальности не бывает вообще. И даже настроенный профайлер – это уже чудо. Поэтому анализ начинается, конечно же, совсем по-другому.
Например, консоль сервера. Этим инструментом очень часто пренебрегают, а ведь по факту он дает ответ на многие вопросы. В нем можно посмотреть какой сеанс, какую нагрузку создает, где какие аномалии. Где у тебя длительный запрос к базе данных, а где у тебя уже длительный ответ от сервера 1С, где математика, а где диски – и дальше уже в эту сторону анализировать. Более того, в консоли сервера можно «отрубить» сеанс, который создает аномальную нагрузку, сохранив тем самым работоспособность базы. Убили сеанс, сохранили работоспособность, а потом занимаемся анализом, потому что бывает, что базу нельзя просто так рестартовать.
И здесь важно еще вот о чем сказать. Убивать сеансы – это замечательная возможность, но если вы этим сеансом проводили какой-то длительный регламент типа расчета себестоимости выпуска, восстановления последовательности партионного учета или что-то еще в этом духе, то вам придется все начинать заново, потому что никакой результат не сохранится – это очень важно иметь в виду. Потому что вся операция расчета себестоимости может длиться 8.5 часов, а если она длилась 8 ч, и вы решили ее прервать, чтобы дать работать пользователям, то вам придется все начинать заново. А надо было всего-то подождать полчаса и все.


Следующий очень важный инструмент – технологический журнал 1С. Он вроде бы тривиальный, но, тем не менее, помогает решать огромное количество вопросов. Здесь на экране показана настройка – тут максимум 15 строчек кода. С помощью этой настройки вы можете вывести все события выполнения запроса, которые длились более 10 секунд, тем самым, сразу отсечь все то, что неинтересно, и проанализировать только длительные запросы. И дальше уже, если будет нужно, погрузиться в их какой-то более детальный анализ.
И еще один инструмент – это SQL Management Studio, тоже очень интересная вещь, особенно в контрасте того, что профайлер MS SQL надо настраивать, на это требуется время, а его иногда нет. А Management Studio – это достаточно простой инструмент, и более того, он включен в любую версию MS SQL (и в SQL Express в том числе – он там в комплекте не идет, но его можно установить, лицензия это позволяет делать). Пользоваться им достаточно удобно и легко.
Ну и конечно, если время позволяет, настраиваем профайлер MS SQL, чтобы он нам выдавал то, что мы хотим видеть, потому что многие ответы находятся только там. Тем более что в отличие от технологического журнала 1С, он позволяет увидеть все запросы – это, наверное, чуть ли не главное преимущество MS SQL. У технологического журнала 1С есть ограничение, что он позволяет увидеть только те запросы, которые были успешно выполнены – это одно из серьезных ограничений при анализе подобных аномалий для СУБД PostgreSQL. А профайлер MS SQL позволяет увидеть все запросы. Можно запустить запрос, тут же его отключить, получить полный план запроса и анализировать его дальше, что там вообще происходит. Это очень большое преимущество и важно правильно этим пользоваться.
Заключение
Весь наш опыт подсказывает, что все гениальное – просто, и что чудеса очень часто решаются достаточно простыми и тривиальными способами.
Еще раз подытожим наши выводы
- Важно то, что не все итоги одинаково полезны. В данном случае, очевидно, что текущие итоги – это явный паразит в базе, с которым жить и мириться никак нельзя, его надо беспощадно сносить, отключать и т.д.
- А ежемесячные итоги как раз наоборот – крайне полезная вещь, без которой жить бывает очень сложно. Если у вас в регистрах накопления очень много записей без итогов – это печаль и боль.
- Что еще очень важно – это последовательность расчета итогов и обновления статистики. Потому что у заказчика даже мысли не промелькнуло по поводу того, что в последовательности его действий что-то может быть не так. Потому что, казалось бы – база в 2 терабайта, ну записали мы итогов на месяц, ну и что, почему это так должно сказаться на производительности? А вот может так сказываться. Последовательность действий здесь имеет крайне большое значение. И если вы используете какое-то решение «из коробки», где все по порядку настроено, то все будет работать хорошо. А если вы просто будете кусочно использовать разного рода инструменты в хаотичном порядке, то можете не достигнуть позитивного эффекта.
Лично от себя хочу добавить, что, несмотря на то, что мы достаточно давно уже занимаемся оптимизацией (в сумме, наверное, больше двух лет), меня искренне удивляет тот факт, что при решении большинства проблем помогает просто расчет итогов и обновление статистики. Прямо серьезно. Мало кто этим озадачивается – либо просто забывают, либо что-то еще. Поэтому не забывайте, обращайте внимание, это крайне важно.
Пользуйтесь инструментами, будьте молодцами!
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2016 DEVELOPER.

Вступайте в нашу телеграмм-группу Инфостарт