






{kind=link}
Пример 1: Консолидация данных из разных источников и веб-отчеты
Пример 2: Статистические функции языка R и HTML-виджеты
Области применения программы DataReducer:
Консолидация данных |
Публикация отчетов в веб |
|
| DataReducer позволяет объединять данные из разных источников: информационные базы 1С, таблицы Excel, базы данных SQL, XML-документы, файлы множества других форматов. | DataReducer включает веб-приложение, предназначенное для передачи аналитической информации другим пользователям по сети. Данные 1С могут быть быстро опубликованы в виде веб-отчета. | |
Визуализация данных |
Интеграция 1С с другими системами |
|
| R обладает мощными графическими возможностями. Вы можете создавать интерактивные диаграммы на основе данных из 1С и автоматически встраивать их в страницы сайта или корпоративного портала. | Веб-приложение DataReducer автоматически конвертирует данные в форматы XML и JSON и предоставляет к ним доступ по HTTP. DataReducer можно использовать как сервис интеграции с 1С. | |
Статистический анализ |
Предварительная обработка данных |
|
| Ко множеству сфер применения R относятся статистика, эконометрика, финансовые исследования, машинное обучение. Если перед вами стоит задача статистического анализа данных 1C, то лучшего инструмента чем R не найти. | DataReducer можно использовать для извлечения и обработки данных перед их передачей в 1С. Возможности R по работе с различными API и форматами данных превосходят аналогичные возможности платформы 1С. |
Системные требования
- Операционная система: Windows 10 x64 / DEB-based Linux x64
- 1C:Предприятие 8 - Версия 8.3.9 или старше
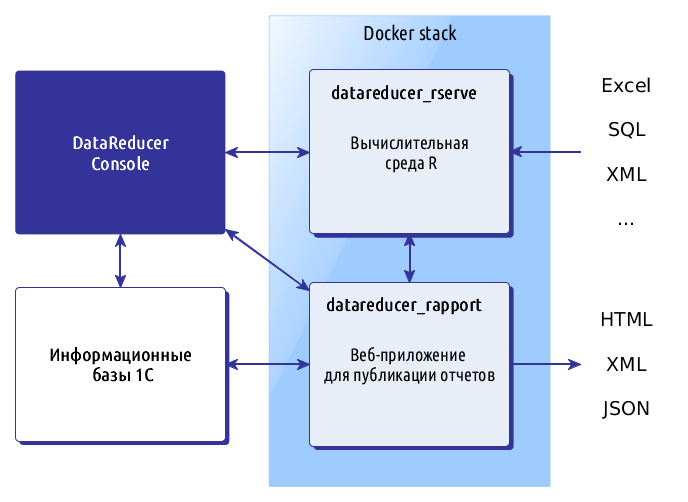
Схема развертывания
Процесс развертывания DataReducer состоит из следующих этапов:
- Публикация интерфейса OData информационных баз 1С на веб-сервере.
- Запуск сервисов rserve и rapport в Docker-контейнерах.
- Установка и настройка приложения DataReducer Console.
Эти этапы подробно описаны в Руководстве пользователя.
Интерфейс главного окна программы
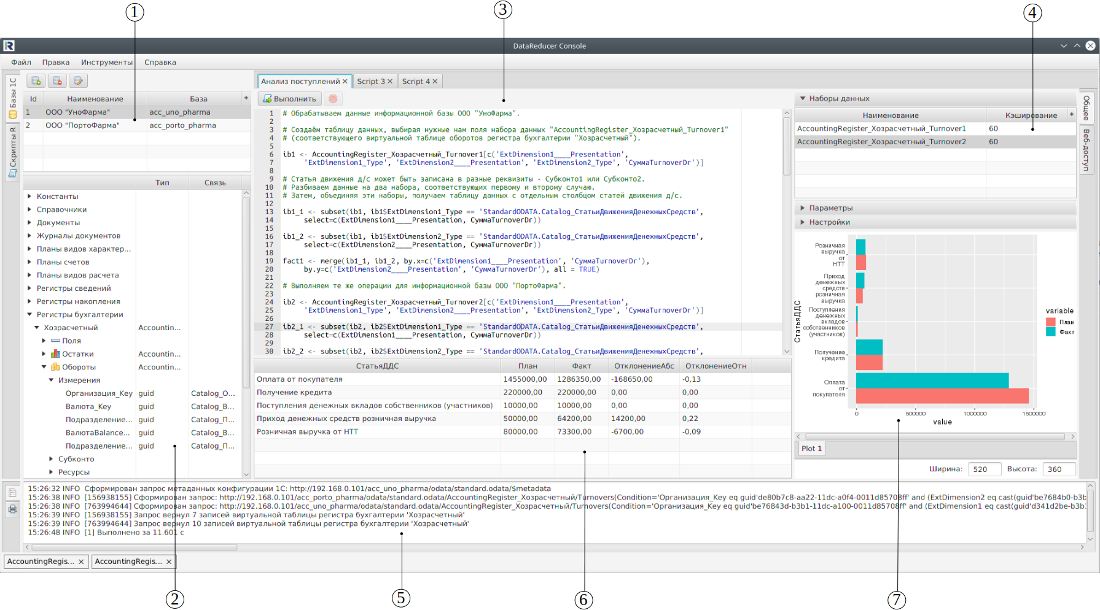
| 1. Список информационных баз | 4. Наборы данных скрипта R | 7. Область вывода графики |
| 2. Дерево метаданных | 5. Область вывода сообщений | |
| 3. Вкладка скрипта R | 6. Таблица данных |
Пример 1: Консолидация данных из разных источников и веб-отчеты
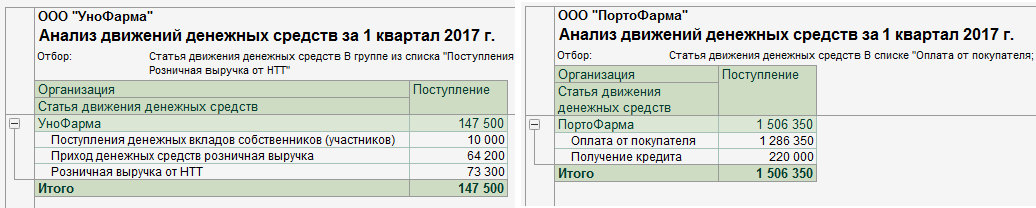
Требуется выполнить план-фактный анализ поступлений денежных средств компании за квартал. Компания состоит из двух юридических лиц — организаций «УноФарма» и «ПортоФарма». Бухгалтерский учёт организаций ведётся в двух разных информационных базах «1С:Бухгалтерия предприятия 3.0»:
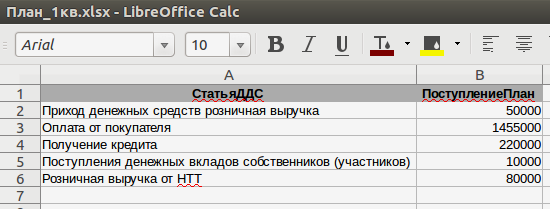
Запланированные значения поступлений необходимо получить из таблицы Excel, в которой отражены суммарные данные по всем организациям:
Шаги решения поставленной задачи в программе «DataReducer Console»
- Добавляем настройки подключения к информационным базам «УноФарма» и «ПортоФарма». Интерфейс OData этих баз предварительно должен быть опубликован на веб-сервере и настроен в соответствии с документацией платформы «1С:Предприятие». В DataReducer можно одновременно работать с данными любого количества информационных баз. Список подключенных баз отображается в главном окне программы.
- После подключения информационной базы, DataReducer Console выводит дерево её метаданных. Дерево метаданных включает все сущности, доступные через интерфейс OData (справочники, регистры, виртуальные таблицы и пр.). Для свойств сущностей выводится их тип. Для свойств с ссылочным типом выводится связанная сущность.
- Создаём новый скрипт R и открываем его. Каждый скрипт открывается в отдельной вкладке.
- Находим в дереве метаданных информационной базы «УноФарма» виртуальную таблицу оборотов регистра бухгалтерии «Хозрасчётный» и через контекстное меню добавляем её в наборы данных скрипта R. Повторяем для информационной базы «ПортоФарма». Любой набор данных можно открыть в отдельном окне и загрузить данные для просмотра.
- Поочерёдно открываем окна созданных наборов данных и вводим настройки запросов. Перечень доступных настроек зависит от типа объекта, которому соответствует набор данных. Начало и конец периода получения оборотов регистра бухгалтерии «Хозрасчетный» задаём в виде параметров ${periodBegin} и ${periodEnd}. Значения этих параметров будут общими для всех наборов данных скрипта R.
- Пишем код на языке R (см. листинг). Обращение к наборам данных осуществляется по их именам.
- Выполняем скрипт. На экран выводятся сообщения о ходе выполнения, в том числе сформированные запросы REST-сервису «1С:Предприятия». В области вывода графики выводится построенная диаграмма. Результаты выполнения скрипта (таблицу данных и диаграмму) можно сохранить в файлы, используя методы языка R.
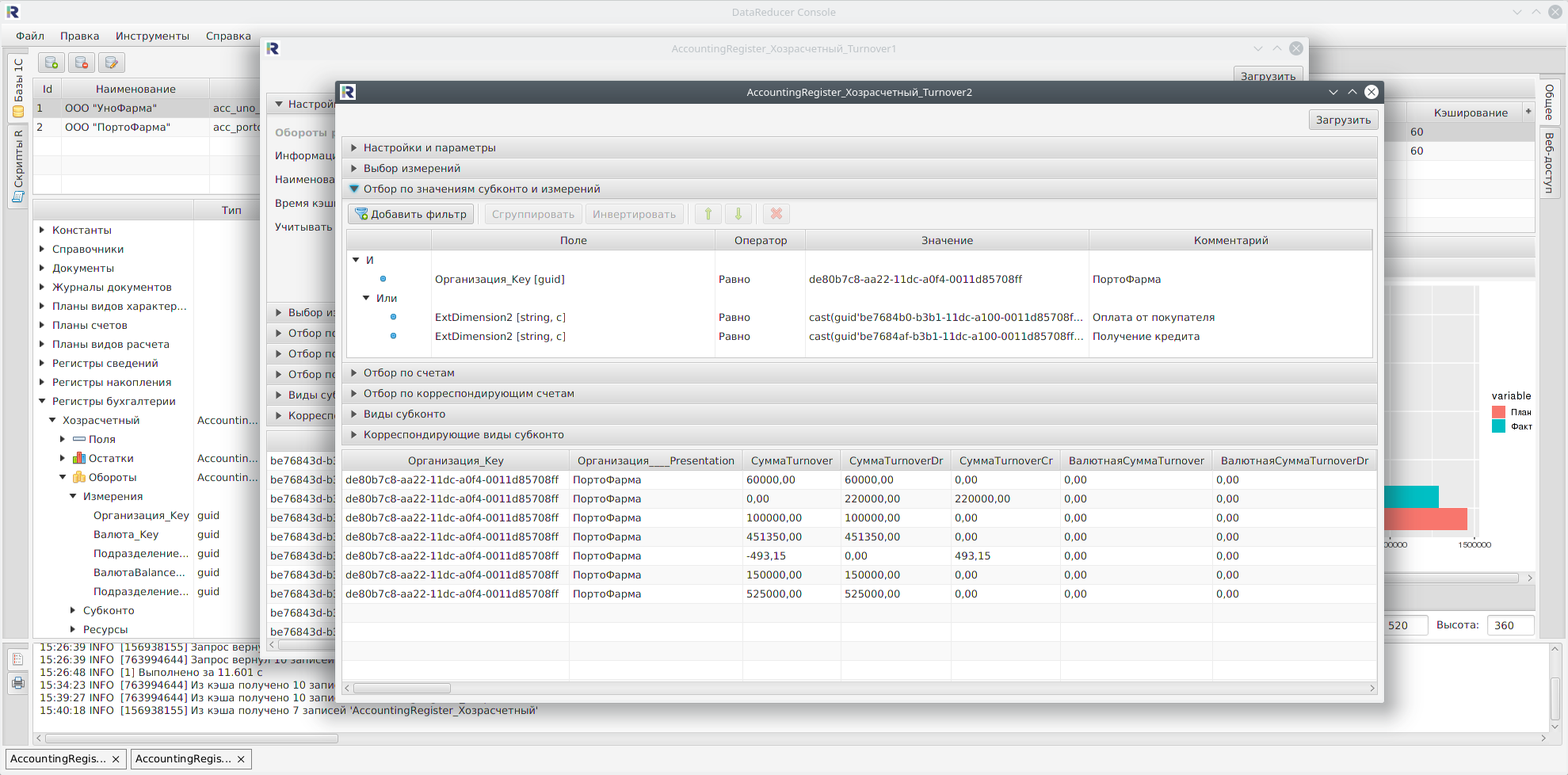
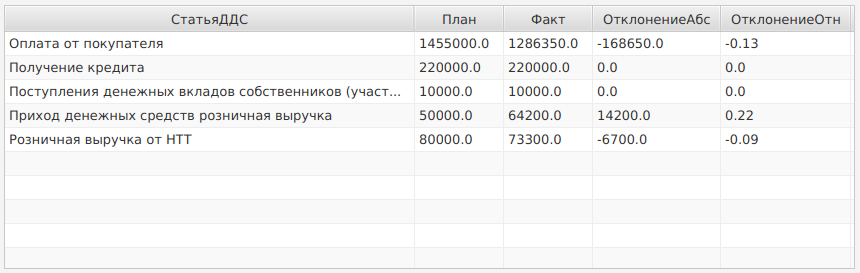
На данном примере были продемонстрированы основные инструменты программы «DataReducer Console» для импорта данных информационных баз «1С:Предприятия» и некоторые методы языка R для обработки этих данных. Были консолидированы данные из трёх разных источников: двух информационных баз «1С: Бухгалтерия предприятия 3.0» и файла Excel. С помощью пакета ggplot2 была построена столбчатая диаграмма, отображающая отклонения фактических значений показателей от плановых.
Теперь опубликуем веб-отчет, содержащий результаты анализа.
В строке №96 листинга скрипта изменяем каталог сохранения файлов на /mnt/webapp-files , соответствующий каталогу файлов веб-приложения.
На вкладке «Веб-доступ» скрипта ставим галочку «Веб-доступ». При необходимости на этой вкладке можно изменить имя веб-ресурса и определить роли доступа.
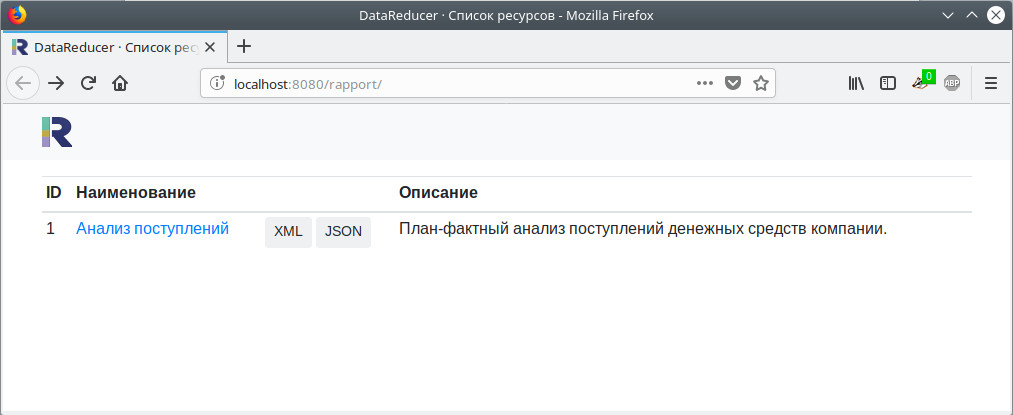
В главном меню программы выбираем «Файл → Загрузить модель на сервер». Список ресурсов модели, к которым открыт веб-доступ, появится на главной странице веб-приложения:
Страница отчета с шаблоном по умолчанию:
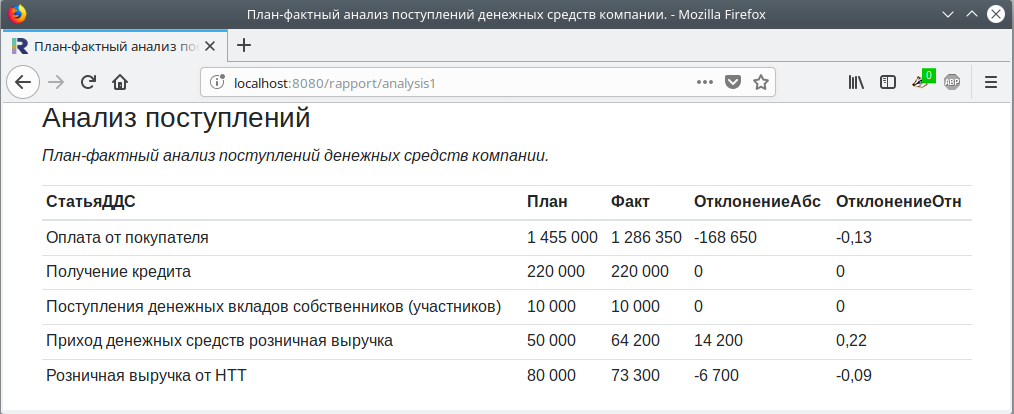
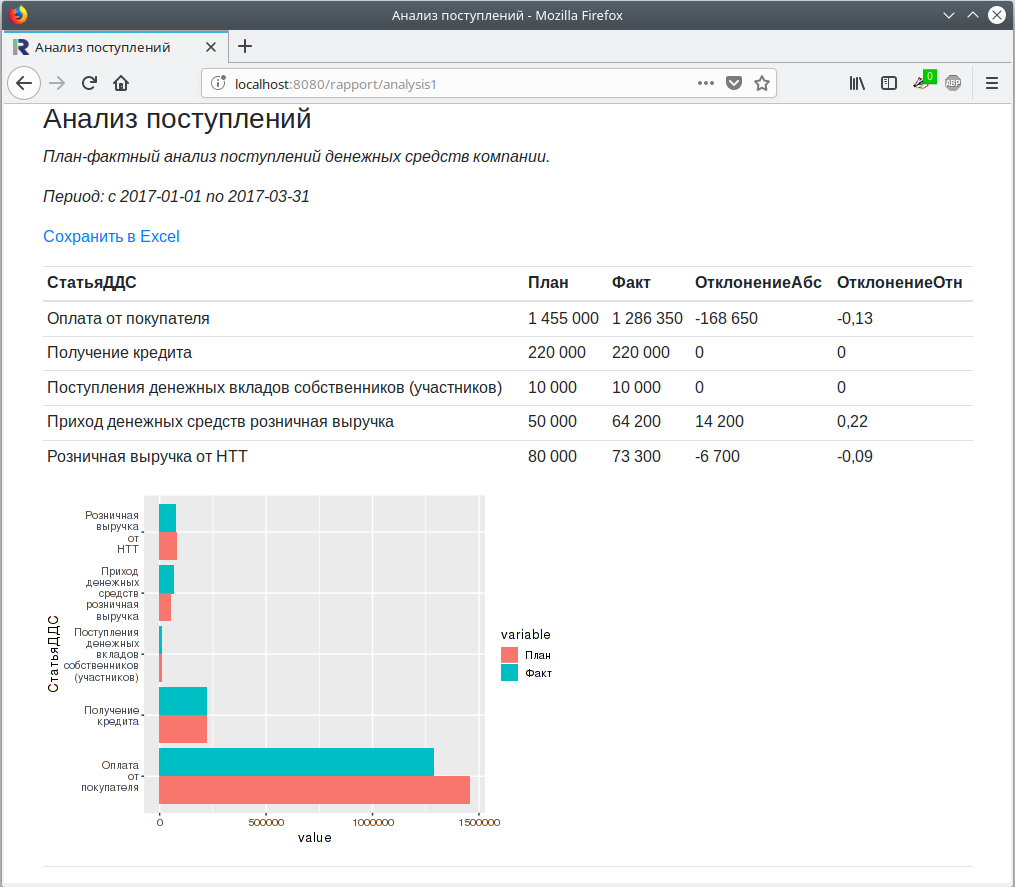
Добавим на страницу ресурса период отчета, ссылку на скачивание данных в формате Excel и сгенерированную в R диаграмму. Для этого внесём изменения в шаблон страницы ресурса.
На вкладке «Веб-доступ» скрипта снимаем галочку «Шаблон по умолчанию». После этого шаблон страницы можно редактировать:
Добавляем в контейнер <body> следующие элементы:
<p><i>Период: с ${periodBegin?keep_before('T')} по ${periodEnd?keep_before('T')}</i></p>
<p><a href="/rapport/files/${resourceName}/${requestId}/ПланФакт.xlsx">Сохранить в Excel</a></p>
<p><img src="/rapport/files/${resourceName}/${requestId}/chart.png" class="img-responsive"></p>
После повторной загрузки модели на сервер мы увидим новую страницу ресурса:
Пример 2: Статистические функции языка R и HTML-виджеты
Основное назначение языка R – статистические вычисления. Если перед вами стоит задача статистического анализа данных «1С:Предприятия», то лучшего инструмента, чем R не найти.
В данном примере мы попробуем предсказать значение показателя прибыли от продаж по значениям показателей дебиторской и кредиторской задолженностей при помощи линейной регрессии.
Также мы построим интерактивный график, на который выведем как известные, так и прогнозные значения показателей. График будет иметь формат HTML и может быть опубликован в веб-отчете DataReducer.
Для построения регрессионной модели воспользуемся данными учета компании за 16 предыдущих кварталов. Эти данные мы получим из информационной базы «1С:ERP Управление предприятием 2».
Введём обозначения переменных и определим источники данных.
prib — Прибыль от продаж (зависимая переменная)
Прибыль от продаж = Выручка от продаж - Себестоимость продаж - Коммерческие и управленческие расходы
Источники данных: обороты регистров накопления «Выручка и себестоимость продаж» и «Прочие расходы».
deb — Дебиторская задолженность (независимая переменная)
Источники данных: остатки регистра накопления «Расчеты с клиентами по документам».
kred — Кредиторская задолженность (независимая переменная)
Источники данных: остатки регистра накопления «Расчеты с поставщиками по документам».
Таким образом, каждому кварталу будет соответствовать четыре набора данных по числу запросов к регистрам информационной базы. Необходимо получить данные по 16-ти периодам, значит, всего будет выполнено 64 запроса.
Формируем наборы данных, используя дерево метаданных информационной базы и конструкторы запросов.
Наблюдение по каждому кварталу и итоговую таблицу данных для анализа создаём следующим образом:
001 # Получаем значения показателей для каждого квартала 002 Q1_2014 <- data.frame( 003 period = "${Q1_2014_end}", 004 prib = Q1_2014_ВыручкаИСебестоимость[1, c("СуммаВыручкиTurnover")] - 005 Q1_2014_ВыручкаИСебестоимость[1, c("СтоимостьTurnover")] - 006 Q1_2014_ПрочиеРасходы[1, c("СуммаTurnover")], 007 deb = Q1_2014_РасчетыСКлиентами[1, c("ДолгBalance")], 008 kred = abs(Q1_2014_РасчетыСПоставщиками[1, c("ДолгBalance")]) 009 ) 010 Q2_2014 <- data.frame( 011 period = "${Q2_2014_end}", 012 prib = Q2_2014_ВыручкаИСебестоимость[1, c("СуммаВыручкиTurnover")] - 013 Q2_2014_ВыручкаИСебестоимость[1, c("СтоимостьTurnover")] - 014 Q2_2014_ПрочиеРасходы[1, c("СуммаTurnover")], 015 deb = Q2_2014_РасчетыСКлиентами[1, c("ДолгBalance")], 016 kred = abs(Q2_2014_РасчетыСПоставщиками[1, c("ДолгBalance")]) 017 ) (...) 131 # Объединяем все наблюдения в одну таблицу 132 df <- rbind(Q1_2014, Q2_2014, Q3_2014, Q4_2014, Q1_2015, Q2_2015, Q3_2015, Q4_2015, 133 Q1_2016, Q2_2016, Q3_2016, Q4_2016, Q1_2017, Q2_2017, Q3_2017, Q4_2017)
«Q1_2014_ВыручкаИСебестоимость», «Q1_2014_ПрочиеРасходы» и пр. - это имена, которые мы дали наборам данных, соответствующим виртуальным таблицам регистров накопления. «СуммаВыручкиTurnover», «СтоимостьTurnover» и пр. - имена полей этих таблиц, формируемые платформой 1С. Периоды задаем в виде параметров.
Смотрим полученную таблицу данных:
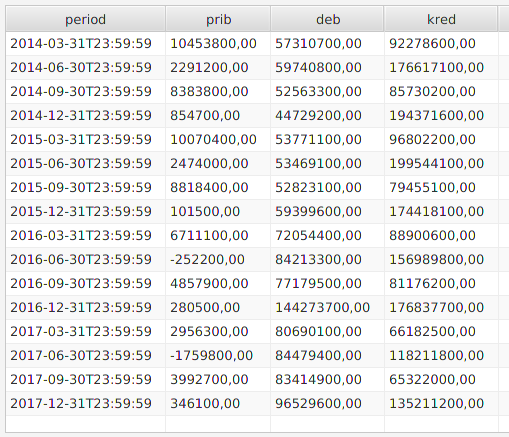
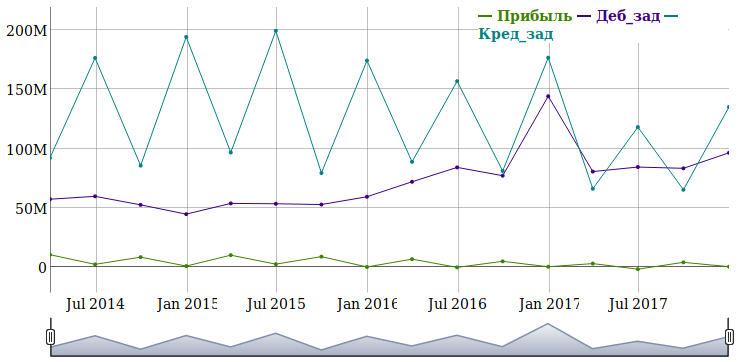
Создадим интерактивный график изменения показателей по кварталам. Для этого воспользуемся пакетом «dygraphs», предоставляющем R-программисту возможности одноименной JavaScript-библиотеки:
135 # Приводим данные к формату xts 136 library(xts) 137 data_xts <- xts(df[,-1], order.by=as.POSIXct(df[,1])) 138 139 # Строим график 140 library(dygraphs) 141 graph <- dygraph(data_xts, width=750, height=350) %>% 142 dySeries("prib", label = "Прибыль") %>% 143 dySeries("deb", label = "Деб_зад") %>% 144 dySeries("kred", label = "Кред_зад") %>% 145 dyOptions(drawPoints=TRUE, pointSize=2, drawAxesAtZero=TRUE, labelsKMB=TRUE) %>% 146 dyRangeSelector() 147 148 # Сохраняем виджет с графиком 149 library(htmlwidgets) 150 saveWidget(graph, file="/mnt/host/prib.html", selfcontained = TRUE)
Создаём линейную модель и предварительно оцениваем её:
155 model <- lm(data=df, prib~deb+kred) 156 paste(capture.output(print(summary(model))), collapse='\n')
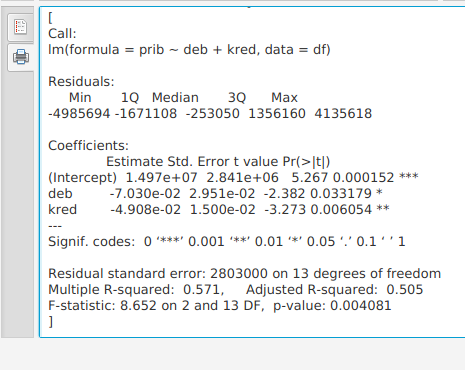
Как видно из последнего столбца таблицы, коэффициенты при переменных deb и kred статистически значимо отличаются от нуля при p < 0.01 и p < 0.001, соответственно. Это указывает на то, что и дебиторская и кредиторская задолженности влияют на показатель прибыли от продаж. Взятые вместе, они на 57% описывают изменения показателя (Multiple R-squared: 0.571).
Теперь проверим данные и посмотрим, можем ли мы нашу модель улучшить.
Для этого воспользуемся методами, реализованными в пакете car (пакет уже установлен в Docker-контейнере rserve).
Проверим, что ошибки регрессии нормально распределены (одна из предпосылок линейной регрессии, которые должны выполняться, чтобы мы могли считать модель адекватной). Выполним это графически, построив Q-Q график, или график Квантиль-Квантиль:
160 library(car) 161 qq <- qqPlot(model, labels = row.names(df), simulate = TRUE, main = "Q-Q plot") 162 print(qq) 163 dev.off()
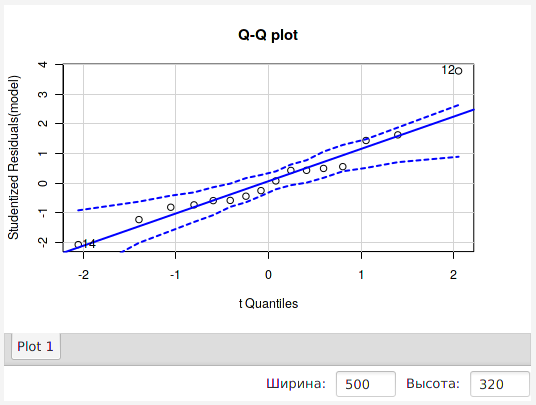
На графике хорошо видно, что одно из наблюдений выпадает из доверительных границ (изображенных пунктирными линиями) — это т. н. «выброс», т. е. наблюдение, которое плохо предсказывается моделью.
Удаляем «выброс» и снова оцениваем модель:
165 # Удаляем "выброс" 166 df1 <- df[-c(12),] 167 168 # Снова оцениваем модель 169 model1 <- lm(data=df1, prib~deb+kred) 170 paste(capture.output(print(summary(model1))), collapse='\n')
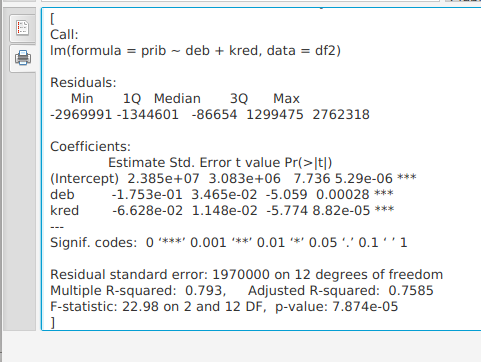
Как мы видим, после удаления «выброса» значимость коэффициентов при независимых переменных увеличилась и модель в целом стала лучше соответствовать данным (Multiple R-squared: 0.793).
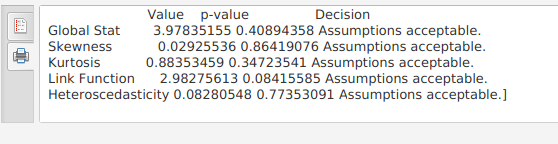
Проверим выполнение всех остальных предпосылок линейной регрессии при помощи функции gvlma() из пакета gvlma.
173 library(gvlma) 174 gvmodel <- gvlma(model1) 175 paste(capture.output(print(summary(gvmodel))), collapse='\n')
Воспользуемся моделью для предсказания прибыли от продаж за три последующих квартала:
177 # Создаем таблицу с плановыми данными дебиторской и кредиторской задолженностей 178 # и приводим её к формату xts 179 q1_2018_plan <- data.frame(period="2018-03-31T23:59:59", deb=${deb_plan1}, kred=${kred_plan1}) 180 q2_2018_plan <- data.frame(period="2018-06-30T23:59:59", deb=${deb_plan2}, kred=${kred_plan2}) 181 q3_2018_plan <- data.frame(period="2018-09-30T23:59:59", deb=${deb_plan3}, kred=${kred_plan3}) 182 plan_df <- rbind(q1_2018_plan, q2_2018_plan, q3_2018_plan) 183 plan_xts <- xts(plan_df[,-1], order.by=as.POSIXct(plan_df[,1])) 184 185 # Предсказываем прибыль от продаж 186 predicted <- predict(model1, newdata=plan_xts, interval="prediction")
Предсказанные значения показателя, а также доверительные интервалы, выводим на интерактивный график:
191 # Объединяем все наборы данных 192 combined <- cbind(data_xts, plan_xts, predicted) 193 194 # Строим новый график 195 graph1 <- dygraph(combined, width=750, height=350) %>% 196 dySeries("prib", label = "Прибыль", color="red") %>% 197 dySeries("deb", label = "Деб_зад", color = "blue") %>% 198 dySeries("kred", label = "Кред_зад", color = "green") %>% 199 dySeries("deb.1", label = "Деб_зад_план", color = "blue", strokePattern="dashed") %>% 200 dySeries("kred.1", label = "Кред_зад_план", color = "green", strokePattern="dashed") %>% 201 dySeries(c("lwr", "fit", "upr"), label = "Прибыль_прогноз", color = "red", strokePattern="dashed") %>% 202 dyEvent("2018-03-31", "Прогноз", labelLoc = "bottom", color="red", strokePattern="dotted") %>% 203 dyLegend(width = 300) %>% 204 dyOptions(drawPoints=TRUE, pointSize=2, drawAxesAtZero=TRUE, labelsKMB=TRUE) %>% 205 dyRangeSelector() 206 207 # Создаем каталог для хранения файлов в точке монтирования /mnt/webapp-files, 208 # соответствующей каталогу файлов веб-приложения. 209 requestDir <- '/mnt/webapp-files/${resourceName}/${requestId} 210 dir.create(requestDir, recursive=TRUE) 211 212 # Сохраняем виджет с новым графиком в каталоге для публикации 213 graphPath <- paste(requestDir, 'prib_predicted.html', sep='/') 214 saveWidget(graph1, file=graphPath, selfcontained = TRUE)
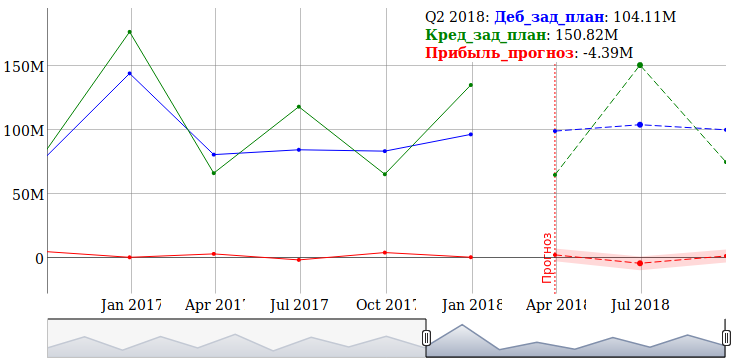
Подробнее о методах, используемых в данном примере:
- Лысенко М.В., Лысенко Ю.В., Якушев А.А., Согрина Н.С. «Cтатистический анализ дебиторской и кредиторской задолженности при оперативном прогнозировании прибыли от продаж» // Фундаментальные исследования. – 2016. – № 12-4. – С. 884-890
- Цикл видео-лекций Демешева Б.Б. по курсу Эконометрики
- Кабаков Р.И. «R в действии. Анализ и визуализация данных в программе R» / пер. с англ. Полины А. Волковой. – М.: ДМК Пресс, 2014. – 588 с.: ил.