Определения NoSQL и CRDT
Если дать расшифровку определениям, которые используются в заголовке, то:
- аббревиатуру NoSQL обычно переводят как «не только SQL», хотя есть сторонники прямого перевода, в котором, по сути, технология NoSQL противопоставляется классическим базам данных SQL
- А CRDT (Conflict-free Replicated Data Types) – это типы данных для бесконфликтной репликации. По сути, требования к объектам обмена для минимизации проблем
О чем будет статья?
- Мы поговорим про обмен данными, который традиционно предполагает наличие двух и более распределенных систем, которые, в идеале, друг про друга почти ничего не знают, но умеют между собой взаимодействовать
- Сразу оговорюсь, что к распределенным системам я отношу, в том числе, мобильные и веб-приложения, которые я рассматриваю не только как интерфейс пользователя, но и как полноценный инструмент для хранения и обработки данных
- Рассмотрим, что предлагают базы NoSQL в части хранения и репликации, какие там есть встроенные механизмы для построения распределенных систем
- А также у нас будет четыре наглядных примера, которые проиллюстрируют работу взаимодействия между базой NoSQL и 1С
Почему именно NoSQL?
Список преимуществ, которые дает использование NoSQL, упорядочить трудно – для меня все перечисленные здесь пункты важны:
- Это, конечно, высокая скорость работы приложений под большой нагрузкой
- Это – экстремальная надежность, практически неубиваемость данных
- Наличие встроенных на уровне ядра инструментов для построения распределенных систем
- В NoSQL есть интересный механизм – map-reduce индексы. В некоторых случаях использование этих индексов оказывается существенно эффективнее, чем традиционные SQL-запросы
- Ну и, наконец, открытый исходный код. Когда мы строим серьезную систему, хочется, чтобы платформа, на которой мы ее строим, нам сюрпризов не преподносила
Вокруг много технологий, и непонятно, на изучение какой стоит потратить время. Я расскажу о некоторых возможностях CouchDB и надеюсь, что эта математика вас заинтересует, и вы захотите потратить на нее еще немного времени.
Теорема CAP
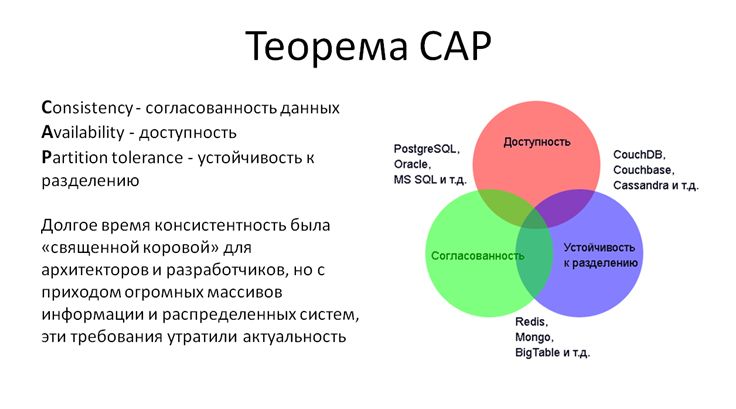
У теоремы CAP нет строгого доказательства, но она получила широкое признание среди специалистов по распределенным вычислениям. Суть теоремы сводится к тому, что обеспечить одновременно целостность данных, их высокую доступность и способность к разделению очень трудно. Каким-то одним из этих показателей приходится жертвовать. Проблема не новая, и в нашем распоряжении достаточно инструментов, которые отдают приоритет той или иной паре показателей:
- В традиционных SQL-базах все хорошо с доступностью и с согласованностью данных, но есть проблемы с разделением данных
- Есть базы, где во главу угла поставлена консистентность и устойчивость к разделению, но могут возникать проблемы с доступностью
- А CouchDB сосредоточена на высокой доступности и разделяемости данных, но не гарантирует их транзакционной целостности
В реляционных базах данных (таких, как PostgreSQL, Oracle и MS SQL) определенный уровень изоляции обеспечивается за счет блокировок или undo-логов. Но с приходом огромных массивов информации и распределенных систем стало ясно, что обеспечить для них транзакционность набора операций с одной стороны и получить высокую доступность и быстрое время отклика с другой — невозможно, соответственно требования к транзакционной целостности стали уже неактуальны. Известно мнение разработчиков всемирной сети банкоматов – процитирую: «если бы мы на самом деле дожидались окончания каждой транзакции, это занимало бы столько времени, что клиенты убегали бы прочь в ярости». Например, если вы и ваш партнер одновременно в двух банкоматах снимаете деньги с одного банковского счета и превышаете лимит – что происходит? Несмотря на это, вы оба получите деньги, а банк решит эту проблему позднее – будет сформирован технический овердрафт и в худшем случае, даже если деньги не удастся вернуть, это будет все равно в 10 раз дешевле, чем попытки обеспечить синхронную работу большой системы.
Что такое NoSQL?
- В SQL мы сначала раскладываем наш объект по прямоугольным табличкам, а потом мучаемся с блокировками, чтобы обеспечить целостность при записи, и строим многоэтажные join-ы при чтении данных
- А в NoSQL вместо термина «запись» или «строка» используют понятие «документ»
- Структура этого документа, за исключением служебных полей, не регламентирована – можно добавлять новые реквизиты без предварительного декларативного описания
- Сами реквизиты NoSQL-документов могут быть как примитивных, так и сложных типов – это могут быть массивы и объекты, также содержащие свои вложенные реквизиты, массивы и объекты
Основные отличия традиционных баз SQL и базы NoSQL
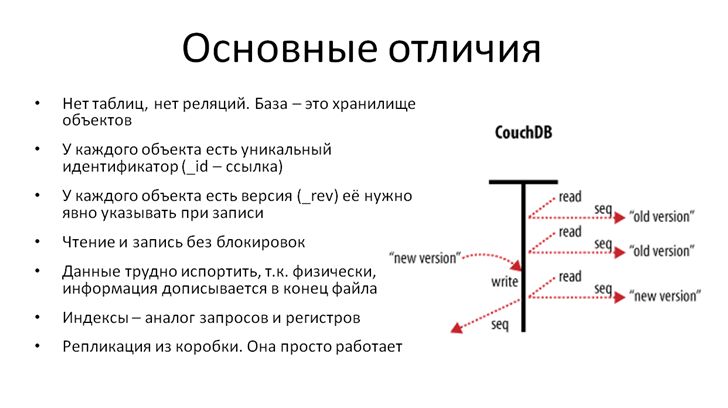
- В NoSQL нет таблиц и, соответственно, нет реляций между этими таблицами. Базу данных можно рассматривать просто как «свалку» объектов
- У каждого объекта есть уникальный идентификатор-ссылка. Это нам близко – в 1С у документов и справочников тоже есть ссылки
- Существенное отличие – это поле версии. Оно в NoSQL неотъемлемое, и это – не какой-то инструмент, спрятанный вовнутрь ядра. Это – реквизит, с которым мы явно работаем, когда хотим записать изменения. Версия в NoSQL – это важно
- Чтение и запись происходят без блокировок. Картинка справа это иллюстрирует. Понятно, что и для чтения, и для записи нужно время, но первым двум читателям отдается предыдущая версия объекта. А когда транзакция записи завершилась, очередной читатель получит уже свежие данные
- Данные в NoSQL трудно испортить, так как физически они просто дописываются в конец файла. За все системы NoSQL не скажу, но в CouchDB именно такая организация B-дерева. Поэтому при аварийном отключении питания, обрыве сетевых проводов последнюю транзакцию мы можем потерять, но все остальное хранится в том самом виде, в котором записалось
- Индексы кроме прямой функции указателя на запись в NoSQL еще могут содержать итоги. И в этом смысле они больше похожи на наши регистры накопления
- Ну и наконец, репликация из коробки. В CouchDB она просто работает
Демо-приложение № 1 «Миллион записей».

Я подготовил для доклада несколько живых примеров. Это – не навороченные приложения, а компактные обработки в один экран для демонстрации короткого списка возможностей.
Данный пример иллюстрирует работу со списком номенклатуры длиной в миллион записей. Перейдя по QR-коду, приведенному на слайде, можно самому протестировать работу этого приложения.
- Здесь задействован элемент управления «Динамический список» с бесконечной полосой прокрутки – Infinite Loader
- Использована фильтрация данных с помощью индексов NoSQL
- На серверной стороне использовано довольно скромное оборудование, например, для той виртуальной машины, на которой крутится CouchDB, сейчас отдано только два физических ядра и 8Gb ram, но она спокойно может обслуживать сотни параллельных запросов клиентов, что соответствует тысячам одновременных клиентов. Все это хорошо масштабируется – достигаются высокопроизводительные результаты
- В таблице честный миллион записей – код примера опубликован в github – желающие могут повторить и сделать замеры производительности на своих компьютерах
- Те записи, которые выводятся в список – это, физически, не какие-то сырые данные, а элементы справочника «Номенклатура». В качестве наименования использованы случайные слова русского и английского языков, длина наименования варьируется от одного до трех слов
- Поисковый индекс устроен таким образом, что мы ищем по первым символам любого из слов наименования. В этом индексе примерно 2 миллиона записей (так как наименование у нас в среднем состоит из двух слов, а записей – миллион)
- Кроме этого, работает поиск по коду, например, можно сразу перейти к самой последней записи в этом списке
Списки короче 10 тысяч записей я рекомендую загружать в ОЗУ при старте приложения. Это убивает сразу двух зайцев. Во-первых, отзывчивость интерфейса – мы эти данные можем быстро показать человеку, а во-вторых, мы по пустякам не беспокоим сервер, разгружаем его. По длинным спискам тут нужно принимать творческие решения – иногда их бывает дешевле и проще прочитать прямо с сервера. Но если списки не такие длинные, удобнее держать их на клиенте, особенно если эти данные нужны для автономного режима работы.
Индексы в NoSQL

Мы привыкли, что индексы – это просто перечисление полей в инструкции ALTER TABLE или галочка «Индексировать» в конфигураторе 1С. И еще привыкли, что индексы магически ускоряют выполнение запросов. Но мало кто задумывается о физическом устройстве индексов и о накладных расходах на создание индексов при записи основных объектов.
- Индексы, которые создаются автоматически, в CouchDB тоже есть – это поисковые индексы (появились в CouchDB2.0)
- Но основные индексы map/reduce – это код JavaScript. И этот код похож на то, что мы пишем в процедуре проведения документов
- При запросах к данным NoSQL мы явно указываем индекс, из которого хотим прочитать данные, и явно указываем диапазон ключа, по которому эти данные должны быть ограничены
- Таким образом, мы используем те подходы, которые были популярны у программистов 40 лет назад (в до-SQL-ную эпоху). Оказывается, что когда данных становится очень много, эти подходы не так уж и плохи
Запас масштабируемости
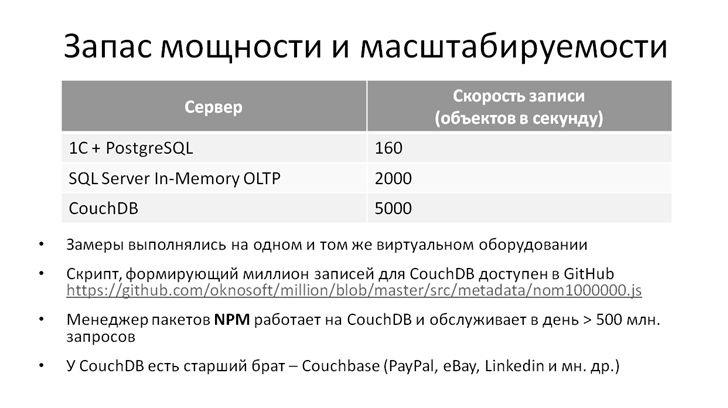
В прошлом году на конференции Инфостарт Денис Кирьяк рассказывал про свои эксперименты с Microsoft SQL Server In-Memory OLTP. В его докладе возможность записать 2000 объектов в секунду выдавалась как большое достижение. Чтобы добиться таких результатов, Денису пришлось создать хитрую виртуальную среду и написать скрипт, имитирующий высокую нагрузку на MS SQL. А в случае с CouchDB я на бытовом компьютере (а точнее, на виртуальной машине внутри бытового компьютера) не напрягаясь, получил скорость записи 5 тысяч объектов в секунду. Причем сделал это не на стерильном скрипте, а на реальной задаче при подготовке данных для предыдущего примера про миллион записей. Обратите внимание, что там используется не просто запись, а еще и заполнение реквизитов случайными значениями. Код на github доступен, можете открыть, посмотреть, как это сделано – прорешать, провести измерения на своем оборудовании.
Еще про масштабируемость:
- Согласно общеизвестной статистике пакетный менеджер npm от nodejs обрабатывает в день полмиллиарда запросов. Причем делает это уже много лет, и ни одного сбоя еще не зарегистрировано
- Такие известные сервисы, как PayPal, eBay и Linkedin используют базу Couchbase. У истоков баз Couchbase и CouchDB стоит один и тот же человек. Это разные базы, но протокол репликации у них поддержан одинаковый, и при необходимости они могут работать в тандеме
Поэтому когда мы примеряем, сгодится ли для нашей задачи с двумя сотнями пользователей CouchDB в качестве движка – скорее всего, сгодится
Распределенная система взаимодействующих баз CouchDB и 1С
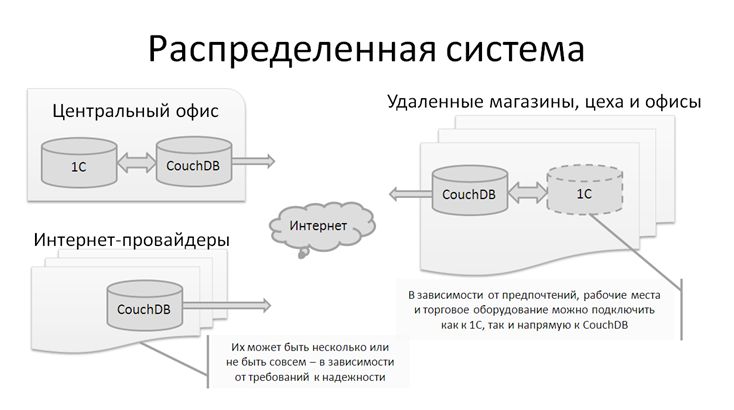
Данный слайд отвечает на вопрос «а причем здесь 1С»? Дело в том, что есть библиотека интеграции Metadata.js, которая делает подключение CouchDB к 1С таким же простым, как включение утюга в розетку
Использование совокупности этих методик позволяет нам строить распределенные системы, автономные рабочие места почти без кодирования. Трудности с репликацией объектов при взаимодействии по плохим каналам связи возьмет на себя математика CouchDB. В результате наша система получится:
- Очень надежная – любую часть можно в любой момент выключить
- Очень быстрая – попутно будет реализовано сжатие данных с минимизацией трафика. Таким образом, ограничение будет зависеть только от пропускной способности сети.
- А главное, что немаловажно, система получится очень простая – внешне интерфейсы, с которыми предстоит иметь дело программисту 1С, очень просты, с ними любой желающий разберется.
Демо-приложение № 2 «Безбумажка»

Следующие два примера иллюстрируют работу распределенных систем. Приложение «Безбумажка» и «Регистратор штрихкодов» умеют работать при отсутствии связи с сервером. Сначала приложение «Безбумажка». На первый взгляд, ничего особенного. Сканируем штрихкод, получаем соответствующее ему задание на производство, регистрируем факт готовности. Особенности есть:
- Про автономный режим я уже сказал. Если взорвать сервер при помощи динамита, у нас конвейер в цеху не остановится. Вся необходимая информация для сегодняшнего суточного задания в мобильном клиенте у нас есть – мы продолжим отдавать команды конвейеру, и он будет выпускать изделия.
- В штатном режиме, когда сеть исправна и сервер доступен, информация по событиям диспетчеризации будет поступать в 1С в реальном времени.
- Это приложение работает, в том числе, на бытовых телевизорах – мои клиенты любят в цеху вывешивать такие большие экраны. И компьютер рядом ставить не нужно. Достаточно браузера, встроенного в современный телевизор.
- Можно реализовать сложные алгоритмы регистрации и сложные рабочие места. Эскиз, который мы здесь наблюдаем, это не простой вид-массив – каждый элемент понимает, какой кусок спецификации под ним лежит, и, соответственно, на основании этих данных мы можем сформировать рекламацию или корректировочное задание на производство.
- Кроме сканера, к веб-странице подключен станок по отрубанию фурнитуры. Когда человек кликает по ссылке, веб-приложение отправляет в станок команду, упор отъезжает на нужный размер и отрубает лишний кусок металла.
Демо-приложение № 3 «Регистратор штрихкодов»

Еще одно приложение – «Регистратор штрихкодов». Позволяет регистрировать штрихкоды в привязке к исполнителю и этапу производства. Главная задача этого слайда – продемонстрировать оффлайн режим с последующей синхронизацией.
Это приложение можно рассматривать как терминал сбора данных: когда связь отсутствует, мы можем автономно регистрировать события – например, те, которые поступают со сканера. А при возобновлении связи эти события отправляются в 1С.
Важно: здесь мы обмениваемся не какими-то сырыми данными, а передаем на сторону 1С полноценный документ «События планирования». У него есть табличная часть «Исполнители», которая заполняется в зависимости от настроек текущего пользователя. У него кроме обычных реквизитов есть дополнительные реквизиты и сведения, внесенные в 1С из соответствующей подсистемы БСП (мы в metadata.js также поддерживаем дополнительные реквизиты и сведения). В данном случае, в эти дополнительные реквизиты попадет информация по этапу производства (также из настроек пользователя).
Репликация в CouchDB

CouchDB изначально создавалась для работы в распределенных системах и умеет отвечать на вопрос: «Что изменилось в нашей базе данных, начиная с момента времени X». Для того, чтобы сформулировать ответ на этот вопрос, данные организованы определенным образом.
- Во-первых, это – версии объектов
- Во-вторых, это – уникальные метки для каждого события записи, поскольку все эти события у нас упорядочены во времени
- Ну и для того, чтобы обеспечить монотонность состояний, пришлось отказаться от операции удаления и изменения объекта
- Если нам нужно удалить объект, мы записываем новую версию, в которой взведена пометка на удаление
- Если нам нужно изменить объект, мы записываем новую версию с новыми значениями полей
- Список изменений можно отфильтровать на стороне сервера для задач частичной репликации. Данные можно передавать с фильтром по контрагенту, по подразделению и т.д. – любые алгоритмы, любые фильтры поддерживаются
- Есть излучатель событий. Клиенты, подключенные к обмену, получают от сервера сообщения о том, что некие объекты изменились, их данные нужно перечитать и на своей клиентской стороне как-то обработать
Разрешение конфликтов версий. CRDT (Conflict-free Replicated Data Types)

- Бесконфликтность репликации правильнее всего обеспечивать методологически – с помощью однонаправленного потока данных.
- Но в том случае, если разрулить проблему на уровне бизнес-процессов не получается и конфликты неизбежны, CouchDB помогает разрешать эти конфликты достаточно изящным способом, обеспечивая монотонность состояния.
- По умолчанию, при разрешении конфликтов просто выигрывает та версия, изменения в которую вносились позже.
- При этом прикладной программист в Conflict Resolver-е может реализовать любые алгоритмы, сказать, что победил первый, второй, третий и последний, или синтезировать свой собственный объект на основании прибежавших из разных мест данных. Например, для записи можно склеить строки табличных частей из разных версий. Однако при написании Conflict Resolver-ов следует придерживаться правил строгой событийной целостности (они здесь на слайде перечислены). Иначе можно сделать такой Conflict Resolver, который всегда будет создавать новые версии, и система будет генерировать незатухающие колебания.
Преимущество NoSQL – агрегаты по датам и строкам

В начале статьи я обещал привести пример, когда индексы NoSQL оказываются интереснее привычных запросов. Таким примером являются задачи диспетчеризации. Для их решения нужны итоги по датам. Обычно для получения итогов по состояниям изделий и датам событий используют объединения (в некоторых случаях для этого могут сгодиться агрегатные функции min-max). Но что тут важно понимать? Событий диспетчеризации, как правило, на один-два порядка больше, чем других хозяйственных операций. И если мы считаем оправданным использование регистров накопления для расчета остатков товаров на складах и остатков во взаиморасчетах, использование аналогичной математики тем более оправданно для решения задач диспетчеризации.
А используя индексы NoSQL, мы можем рассчитать статусы, рассчитать итоговые даты, сложить это все в значение индекса, а при построении отчетов просто показать пользователям готовые данные.
Демо-приложение №4. Отчеты для анонимных клиентов

Примером такого отчета, содержащего итоговые данные по диспетчеризации, является отчет для анонимного клиента. Казалось бы, это обычный бланк заказа, на котором нанесен QR-код. Однако, сфотографировав этот QR-код и перейдя по ссылке, можно увидеть актуальную информацию по событиям оплаты, отгрузки и изготовлению изделия этого заказа – все живые данные о диспетчеризации здесь присутствуют. Причем, эти данные не вычисляются кодом при построении отчета, а извлекаются из индекса map/reduce. При этом регистрация на сайте и специальный личный кабинет не требуются, достаточно только бланка с QR-кодом, который можно сфотографировать и перейти по ссылке. Конечно, найдутся маркетологи, которые скажут, что человеку не нужно давать простого способа увидеть интересующие его данные, что людей на сайте надо удерживать и показывать им разные рекламные пошлости, но я своим клиентам информацию предоставляю наиболее простым и быстрым способом.
Заключение

Итак, для построения распределенных систем с большой нагрузкой, если требуется экстремальная надежность и быстродействие на ограниченном железе, рекомендую использовать наш тандем и зарабатывать на внедрениях.
Конечно, любую задачу можно решить почти любыми инструментами. Можно написать редактор видеоклипов на 1С или написать складскую систему, например, на Autocad. Но я хочу напомнить про подход unix way, рекомендующий строить сложные системы из простых блоков, которые сосредоточены на решении конкретных задач и решают эти задачи самым оптимальным способом.
Задачи транспорта и репликации данных, база CouchDB решает очень эффективно, а библиотека metadata.js делает подключение CouchDB к 1С максимально простым.
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2016 DEVELOPER.
Вступайте в нашу телеграмм-группу Инфостарт