
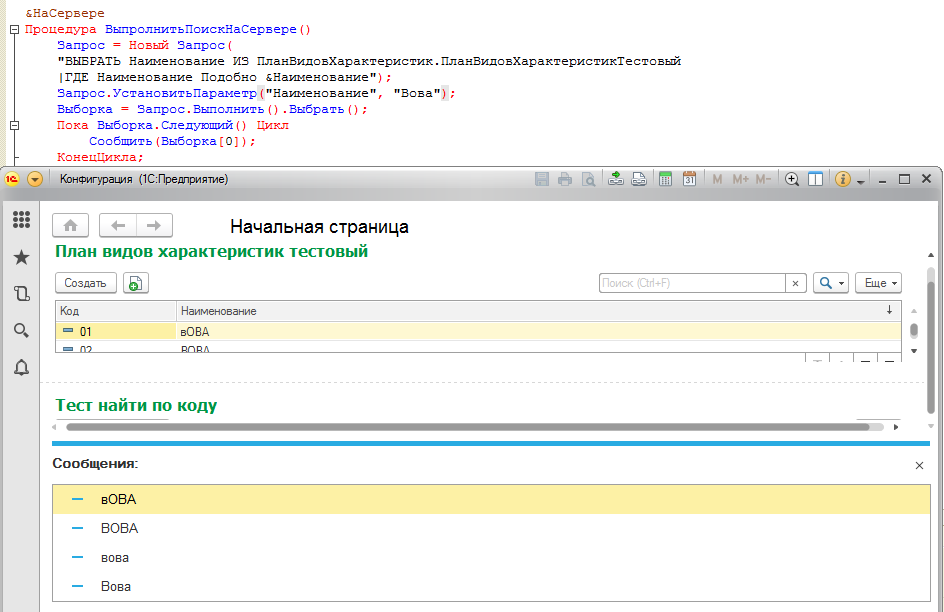
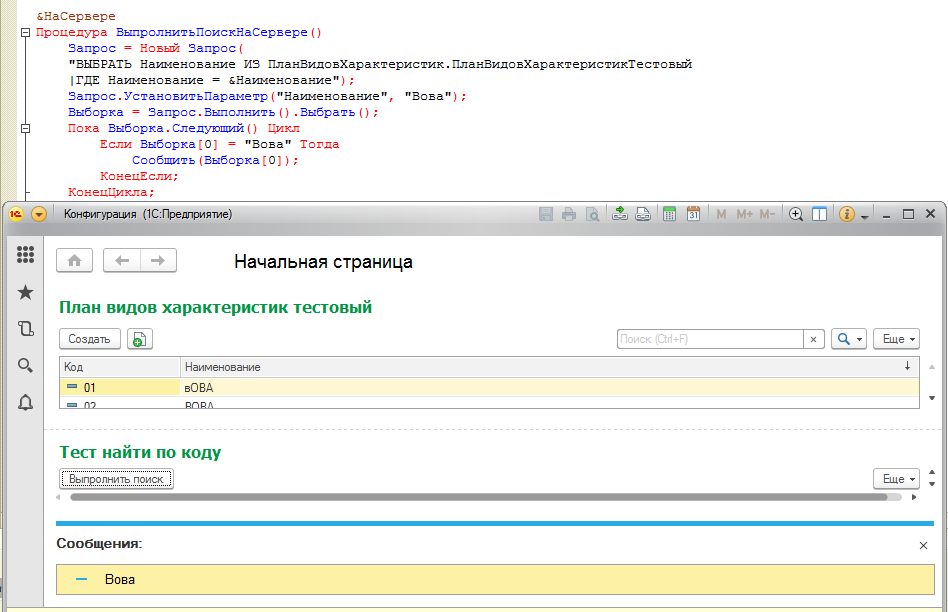








Предыстория
Как-то при переносе данных в одну животноводческую базу, я столкнулся со странным поведением выполнения довольно простого кода. У меня было множество животных с уникальными шифрами, описывающими их породу. Те, кто помнят школьные уроки по генетики, знают, что доминантные гены принято изображать большими буквами, а рецессивные - маленькими. Для остальных небольшая иллюстрация для понимания:
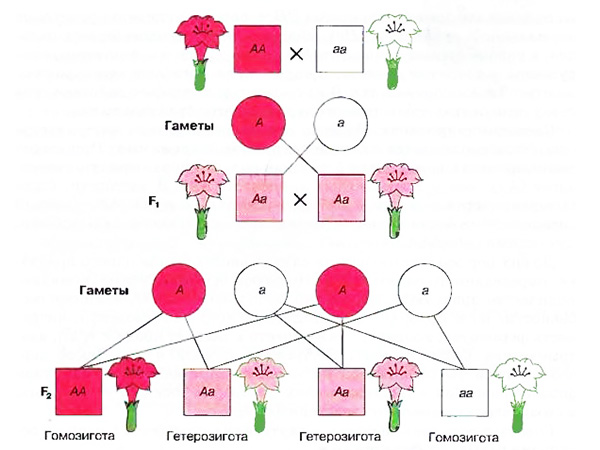
Казалось бы, что загрузку написал правильно, но результат в базе не соответствовал данным источника - данные по некоторым животным были перепутаны, а по части вообще ничего не загрузилось. Пристальное изучение несоответствий показало, что путаница наблюдались в тех случаях, когда шифры животных различались не составом, а только регистром.
Поиск по данным в базе
Давайте попробуем воссоздать пример с картинки выше и создадим справочник "Виды цветов" с тремя элементами: АА -> красный, Аа -> розовый и аа -> белый. Проблему можно увидеть сразу, если попытаться наш код внести в стандартное поле "Код":
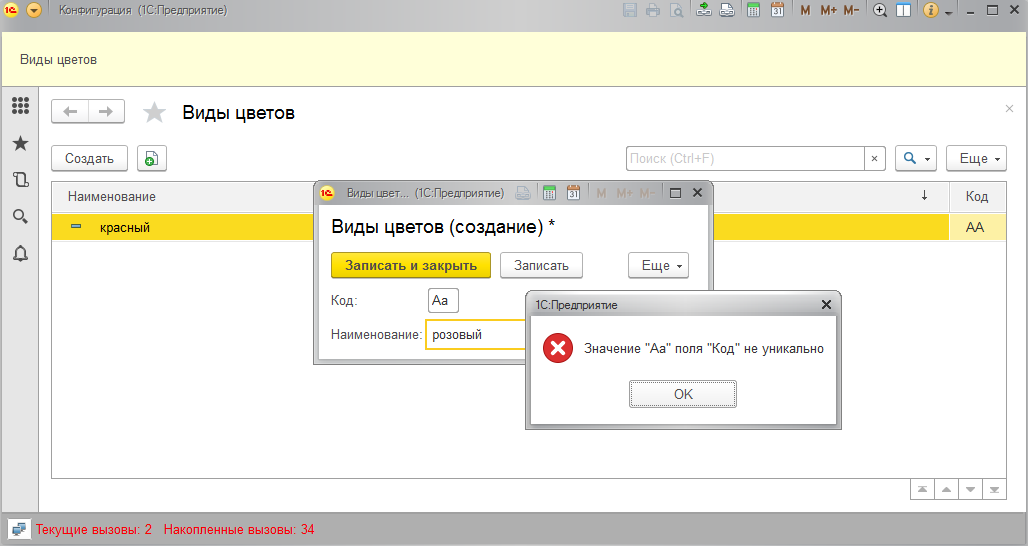
Заметим, что таким образом мы можем задать элементу справочника код А00001 и при автонумерации получим А00002, А00003 и так далее. Так же мы можем задать код а00001 и получить а00002, а00003... Но если мы при наличии А00001 по какой-то причине захотим установить номер а00001, то получить "облом".
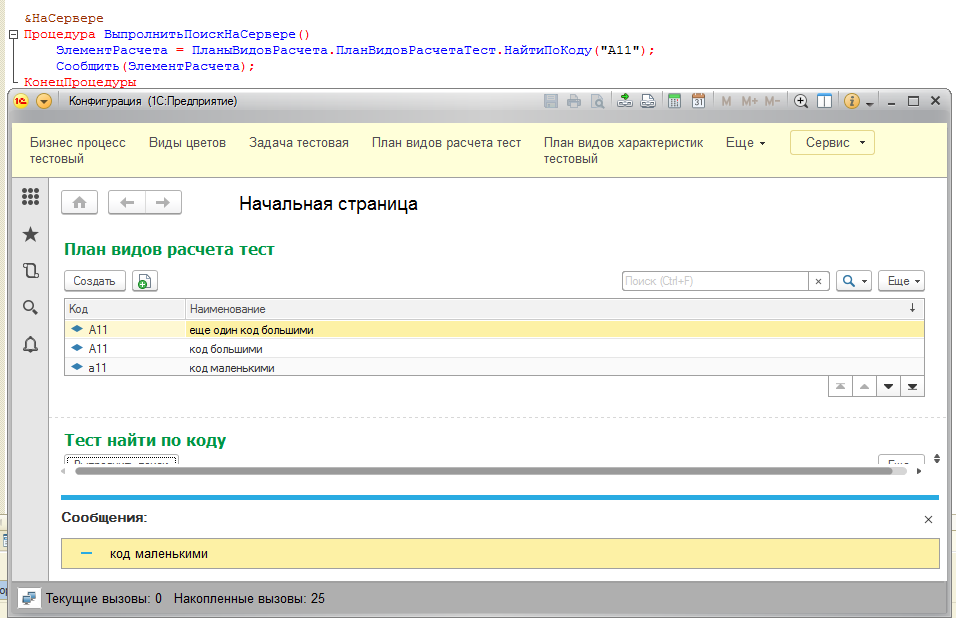
Аналогичное поведение при тестировании кодов/номеров я обнаружел у документов, задач, бизнес-процессов, планов видов характеристик, планов счетов и планов обмена. Но у планов видов расчетов, однако, разрешается создать одновременно элементы с номерами "А00001" и "а00001", что очень странно - тут можно было бы сослаться на то, что у плана видов расчетов в настройках отсутствует свойство включения/отключения контроля уникальности номера, но этого свойства так же нет и у плана обменов. В документации о такой выборочно действующей особенности поведения ничего не написано. Если я просто не увидел, то напишите в комментариях.
Кстати, поскольку удалось создать несколько видов расчета с идентичными кодами, то это прекрасный повод проверить результат функции НайтиПоКоду(). Только предварительно я воспользуюсь отсутствием у плана видов расчетов контроля уникальности номеров и добавлю еще один элемент с большой "А" - интересно какой из этих двух элементов будет выбран:
Да, уж. Согласитесь, результат оказался неожиданным и он подтверждает ранее замеченное наблюдение, что для платформы 1С регистр символов как минимум в кодах/номерах значения не умеет. Выходит, создавая код на нашей платформе, программист получает по факту выполнения: 1040 = КодСимвола("А") = КодСимвола("а") = 1072 , и лишь конечный пользователь системы видит на экране реальные символы.
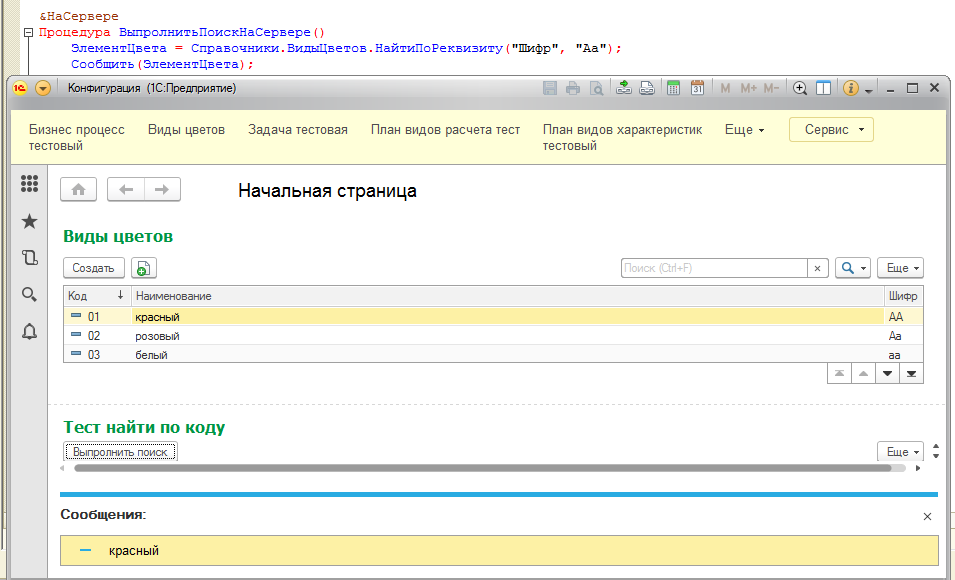
Но продолжим нашу проверку. Обычно на практике для всяких внешних кодов используют реквизиты - в моем случае было так же. Создадим такой для справочника "Виды цветов" и попробуем воспользоваться другим стандартным поисковым методом - НайтиПоРеквизиту():
Как раз с этим я и столкнулся при переносе - в поиске по реквизиту регистр символов игнорируется.
Хотя, как оказывается, не обязательно быть программистом, что бы испытать дискомфорт при точном поиске - аналогичное поведение наблюдается и при использовании отборов СКД в динамическом списке (видимо одна и та же поисковая функция из внутренней библиотеки):
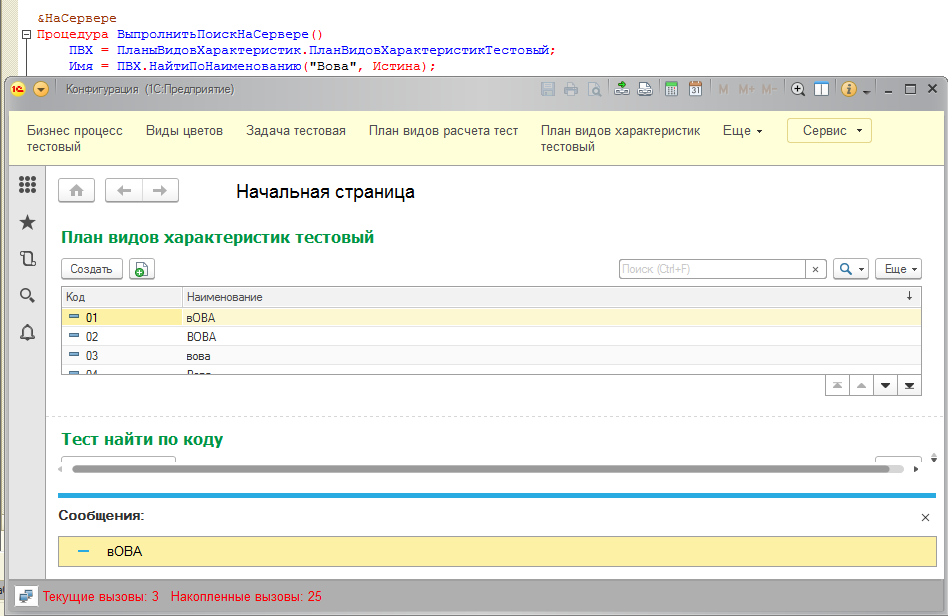
Для полноты картины, давайте протестируем последний оставшийся метод - ПоискПоНаименованию() и получим тот же результат (даже требование "точного соответствия" не помогло):
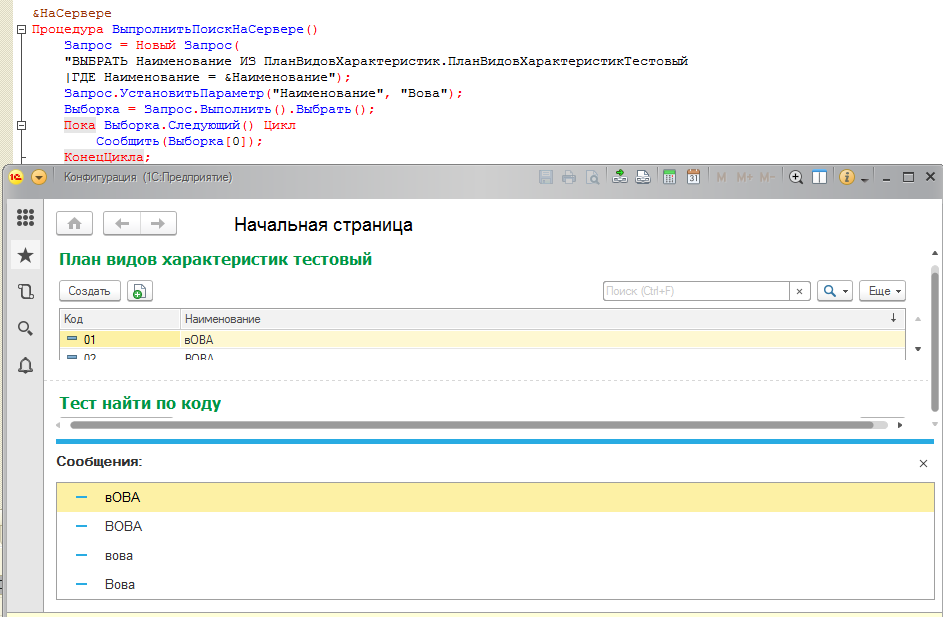
Итак, поисковые методы менеджеров объектов отказываются правильно искать чувствительные к регистру символов данные. А можно ли самостоятельно создать подобные методы с помощью механизма запросов? Давайте попробуем:
Как видите, ни использования оператора "=" в тексте запроса, ни оператор "Подобно" не помогли - каждый раз выбираются все похожие элементы, игнорируя регистры символов.
Т.е. для текста запроса, который транслируется в SQL и выполняется во внешних СУБД, снова верно выражение: 1040 = КодСимвола("А") = КодСимвола("а") = 1072. Я уже приготовился, что все во что я верил ложно и в мире 1С будет справделиво ("А" = "а") = Истина, но к счастью хотя бы примитивное сравнение строк работает и нужную нам функцию все же можно создать:
Поиск по коллекциям
С данными базы как мы уже убедились - грустно. А как дело обстоит с коллекциями?
Массив - обнаружена чувствительность к регистру символов в обычном и фиксированном вариантах для метода Найти().
Таблица значений - методы Найти() и НайтиСтроки() чувствительны к регистру.
Список значений - метод НайтиПоЗначению() чувствителен к регистру символов.
Структура - поисковые методы отсутствуют, а ключи регистр игнорируют.
Соответствие - поисковые методы отсутствуют, но зато поддерживаются ключи в разных регистрах.
Заключение
Я понимаю, что разработчики платформы хотели упростить работу бабушек из бухгалтерии, что бы те не тянулись к Shift (или даже CapsLock) и при наборе "вова" в поле ввода у них сразу выбрался "Вова". Только я отказываюсь понимать - почему из-за этого "облегчения труда" должны страдать разработчики конфигураций. Зачем и нам навязали отсутствие у строк регистра? Ведь именно нам-то как раз "вова" и "Вова" различать нужно (или пути в линуксах, или буквы "м" и "М" в форматных строках, или...). Да и самим пользователям иногда в списке нужно найти единственного человека с фамилией "Кар", а не увидеть сотню макарычей.
Выход, как мы видим, существует. Тут можно написать поисковую функцию с перепроверкой результата. Еще можно вместо поиска перед основным алгоритмом создать соответствие, где по строковым ключам загнать значение соответствующих ссылок. Но хотелось бы применять подобные костыли реже.
P.S. Если кто-нибудь до сих пор этого не знал, то открою тайну - пароль на вход в 1С тоже нечувствителен к регистру! ;)
Вступайте в нашу телеграмм-группу Инфостарт
