
{kind=link}
Те версии программ взаимодействия "клиент-банк", которые работают с текстовыми файлами, при больших объёмах думают долго, последовательно обходя файл построчным чтением текста. Что можно сделать:
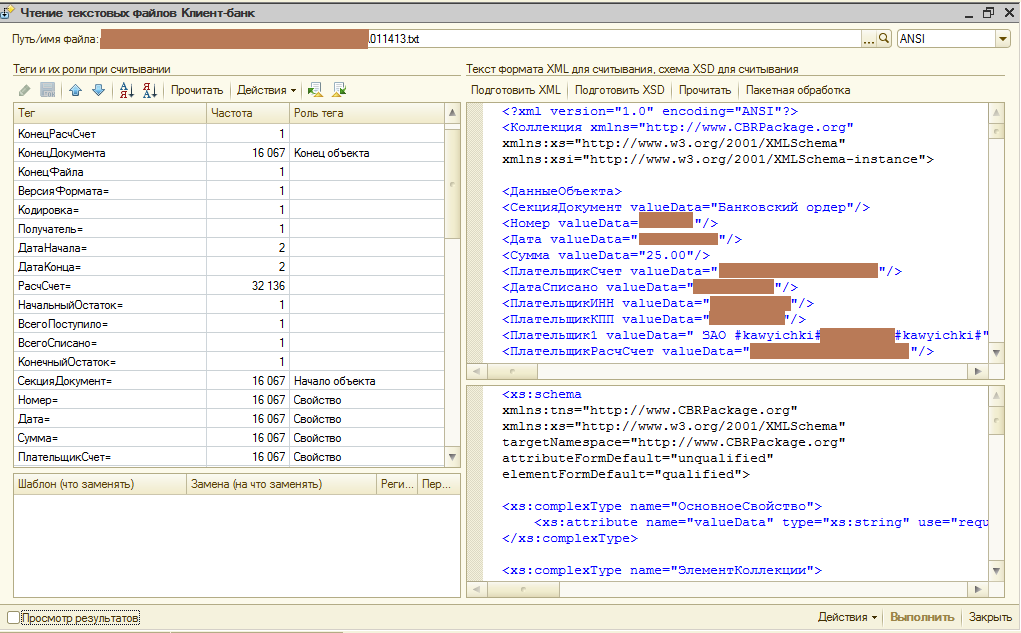
1. Проанализировать наполнение текстового файла, стабильность разметки, разнообразие специфических символов (особенно в назначениях платежей).
2. С помощью регулярных выражений или простым СтрЗаменить привести текст к виду xml.
3. Исходя из разметки (т.е. тегов), используемых в ваших файлах, сделать xdto-объекты ровно той структуры, которая отвечает разметке. Правильно объявляем типы свойств. Динамически создаём и подгоняем xsd под файл xml.
4. Использовать сериализатор для быстрого чтения и получаем, например, СписокXDTO, каждый объект которого есть платёжная транзакция со своими xdto-свойствами.
5. Выполнить чтение из полученных объектов. От цикла всё равно не уйти, но это в разы быстрее благодаря сериализации п.4
UPD: Выкладываю обработку, иллюстрирующую эту технологию. Рассчитана на интерфейсно-пользовательско-клиентское и на серверное применение. Не является законченным решением, т.к. вся работа доходит до чтения объекта "СписокXDTO" и заполнения таблицы значений - поэтому, коллеги, вы можете сделать собственные обход и обработку результатов чтения.
Ахтунг! Недостаток способа в том, что он чувствителен к наполнению и структуре файла, поэтому при битых, экзотических или изменившихся текстовых входных данных xml-вариант просто не прочитается, и эту уязвимость придётся "лечить" каждый раз очень внимательно. В предлагаемую обработку встроена возможность делать свои замены с помощью регулярных выражений, и эти замены могут сохраняться в настройках чтения.
На моих данных, типовой "Клиент-банк" сперва думал около часа, тогда как мой вариант работал 5-7 минут; а потом и вовсе пришлось заменить, т.к. типовая обработка стала вылетать и виснуть. Надеюсь, вам удастся ускорить работу примерно так же. В принципе, обратная выгрузка может быть сделана аналогично - запись в xml средствами xdto и обратная конвертация в текст с заменой на общепринятую разметку.
Также обработка может пригодиться как пример работы с динамическими xsd.
Вступайте в нашу телеграмм-группу Инфостарт