Резервное копирование 1С средствами MS SQL
Администраторы БД делятся на тех, кто делает бэкапы, и тех, кто будет делать бэкапы.
Введение
В этой статье описано самое обычное резервное копирование ИБ 1С при помощи инструментов MS SQL Server 2008 R2, объяснено почему следует делать именно так, а не иначе, и развеяно несколько мифов. В статье достаточно много ссылок на документацию MS SQL, эта статья скорее обзор механизмов резервного копирования, чем всеобъемлющее руководство. Но для тех, кто сталкивается с этой задачей впервые, даны простые и пошаговые инструкции, которые применимы к простым ситуациям. Статья предназначена не для гуру администрирования, гуру и так всё это знают, но предполагается, что читатель способен сам установить MS SQL Server и заставить это чудо враждебной техники создать в своих недрах базу данных, которую в свою очередь он же способен заставить хранить данные 1С.
Я считаю команду TSQL BACKUP DATABASE (и её брата BACKUP LOG) по сути единственным средством резервного копирования баз 1С, использующих MS SQL Server в качестве СУБД. Почему? Давайте рассмотрим, какие у нас способы вообще есть:
| Как | Хорошо | Плохо | Итого |
| Выгрузка в dt | Очень компактный формат. | Долго формируется, требует монопольного доступа, не сохраняет часть малозначительных данных (таких как настройки пользователей в ранних версиях), долго разворачивается. | Это не столько способ резервного копирования, сколько способ переноса данных из одной среды в другую. Идеален для узких каналов. |
| Копирование файлов mdf и ldf | Очень понятный способ для начинающих админов. | Требует освобождения файлов базы данных от блокировки, а это возможно, если база отключена (команда take offline контекстного меню), отсоединена (detach) или просто остановлен сервер. Очевидно, что пользователи в это время работать не смогут. | Этот способ имеет смысл применять тогда и только тогда, когда уже произошла авария, чтобы при попытках восстановления хотя бы иметь возможность вернуться к тому варианту, с которого началось восстановление. |
| Резервное копирование средствами ОС или гипервизора | Удобный способ для сред разработки и тестирования. | Не всегда дружит с целостностью данных. Ресурсоёмкий способ. | Может ограниченно применяться для разработки. В продуктовой среде практического смысла не имеет. |
| Резервное копироавние средствами MS SQL | Не требует простоев. Позволяет восстановить целостное состояние на произвольный момент, если заранее об этом побеспокоиться. Отлично автоматизируется. Экономный по времени и другим ресурсам. | Не очень компактный формат. Не все умеют пользоваться этим способом в необходимой мере. | Для продуктовых сред — основной инструмент. |
Основные сложности при использовании резервного копирования встроенными средствами MS SQL возникают из-за элементарного непонимания принципов работы. Это объясняется отчасти великой ленью, отчасти отсутствием простого и понятного разъяснения на уровне "готовых рецептов" (хм, скажем так, мне не встречалось), да еще и усугубляется ситуация мифосоветами "недогуру" на форумах. Что делать с ленью я не знаю, а вот объяснить основы резервного копирования попробую.
Что и зачем сохраняем?
Давным-давно в далёкой галактике существовал такой продукт инженерно-бухгалтерской мысли, как 1С:Предприятие 7.7. Видимо из-за того, что первые версии 1С:Предприятия разрабатывались для использования популярного формата файлов dbf, его SQL-версия не хранила в базе данных достаточно информации для того, чтобы считать резервное копирование MS SQL полноценным, да еще и при каждом изменении структуры нарушались условия работы полной модели восстановления, поэтому приходилось идти на разные ухищрения, чтобы заставить систему резервного копирования исполнять свою основную функцию. Но, с тех пор, как появилась версия 8 администраторы баз данных наконец-то смогли расслабиться. Штатные средства резервного копирования позволяют создать полную и целостную систему резервных копий. Не входит в резервное копирование только журнал регистрации и некоторые мелочи типа настроек положения форм (в старых версиях), но это потеря этих данных на функциональности системы в не сказывается, хотя безусловно резервные копии журнала регистрации делать правильно и полезно.
А зачем вообще нам нужно резервное копирование? Хм. На первый взгляд странный вопрос. Ну, наверное, во-первых, чтобы иметь возможность развернуть копию системы и во-вторых восстановить систему при сбое? На счет первого я согласен, а вот второе назначение — первый миф резервного копирования.
Резервное копирование — это последний рубеж обеспечения сохранности системы. Если администратору базы данных приходится восстанавливать продуктовую систему из резервных копий, значит, с большой вероятностью было допущено множество грубых ошибок в организации работ. Нельзя относиться к резервному копированию, как к основному способу обеспечения целостности данных, нет, это скорее ближе к системе пожаротушения. Система пожаротушения необходима. Она должна быть настроена, проверена и работоспособна. Но если она сработала, то это само по себе является серьёзным ЧП с массой негативных последствий.
Для того, чтобы резервное копирование применялось только "в мирных" целях, используйте для обеспечения работоспособности и другие средства:
- Обеспечьте физическую безопасность серверов: пожары, затопления, плохое электропитание, уборщицы, строители, метеориты и дикие животные — все они только и ждут за углом, чтобы уничтожить вашу серверную.
- Ответственно относитесь к угрозам информационной безопасности.
- Квалифицированно вносите изменения в систему и заранее максимально убедитесь, что эти изменения не приведут к ухудшениям. Кроме плана внесения изменений желательно иметь и план "что делать, если всё пойдёт не так".
- Активно используйте технологии повышения доступности и надёжности системы вместо того, чтобы потом разгребать последствия аварий. Для MS SQL следует обратить на следующие возможности:
- Использование кластеров MS SQL (хотя, если честно, я считаю, это одним из наиболее дорогих и бесполезных способов занять администратора БД для систем не требующих 24х7)
- Зеркалирование базы данных (в синхронном и асинхронном режиме в зависимости от требований доступности, производительности и стоимости)
- Доставка журналов транзакций
- Репликация средствами 1С (распределённые базы данных)
В зависимости от требований доступности системы и от бюджета, выделенного на эти цели, вполне можно выбрать решения, которые позволят на 1-2 порядка сократить время простоя и восстановления при сбоях. Не нужно бояться технологий повышения доступности: они достаточно просты для того, чтобы их изучить за несколько дней при базовых знаниях MS SQL.
Но, несмотря ни на что, резервное копирование всё ж таки необходимо. Это тот самый запасной парашют, который вы сможете использовать, когда все остальные средства спасения откажут. Но, как и настоящий запасной парашют, для этого:
- эта система должна быть заранее правильно и квалифицированно настроена,
- специалист пользующийся системой должен иметь теоретические и практические навыки её применения (регулярно подкрепляемые),
- система должна состоять из максимально надёжных и простых компонент (это же наша последняя надежда).
Базовая информация о хранении и обработке данных MS SQL
Данные в MS SQL обычно хранятся в файлах данных (далее ФД — сокращение не общеупотребимое, в данной статье будет еще несколько не очень распространённых сокращений) с расширениями mdf или ndf. Кроме этих файлов есть еще журналы транзакций (ЖТ), которые хранятся в файлах с расширением ldf. Нередко начинающие администраторы безответственно и легкомысленно относятся к ЖТ, как в отношении производительности, так и в отношении надёжности хранения. Это очень грубая ошибка. На самом деле, скорее наоборот, если есть надёжно функционирующая система резервного копирования и на восстановление системы можно выделить много времени, то можно хранить данные на быстром, но крайне ненадёжном RAID-0, но тогда ЖТ должны храниться на отдельном надёжном и производительном ресурсе (хотя бы на RAID-1). Почему так? Давайте рассмотрим подробнее. Сразу оговорюсь, что изложение несколько упрощено, но достаточно для начального понимания.
В ФД хранятся данные страницами по 8 килобайт (которые объединены в экстенты по 64 килобайт, но это не существенно). MS SQL не гарантирует, что сразу после выполнения команды изменения данных, эти изменения попадут в ФД. Нет, просто страница в памяти помечается как "требующая сохранения". Если у сервера достаточно ресурсов, то вскоре эти данные окажутся на диске. Причем, сервер работает "оптимистично" и если эти изменения происходят в транзакции, то они вполне могут попадать на диск до фиксации транзакции. То есть в общем случае, при активной работе ФД содержит разрозненные куски недописанных данных и незавершённых транзакций, для которых неизвестно, будут ли они отменены или зафиксированы. Есть специальная команда "CHECKPOINT", которая указывает серверу, что нужно "прямо сейчас" сбросить все несохранённые данные на диск, но область применения этой команды достаточно специфична. Достаточно сказать, что 1С её не использует (я не сталкивался) и понимать, что во время работы обычно ФД не находится в целостном состоянии.
Чтобы справиться с этим хаосом нам как раз и нужен ЖТ. В него пишутся следующие события:
- Информация о старте транзакции и её идентификатор.
- Информация о факте фиксации или отмене транзакции.
- Информация обо всех изменениях данных в ФД (грубо говоря, что было и что стало).
- Информация об изменении самого ФД или структуры базы данных (увеличение файлов, уменьшение файлов, выделение и освобождение страниц, создание и удаление таблиц и индексов)
Вся эта информация пишется с указанием идентификатора транзакции в которой она произошла и в достаточном объёме чтобы понять как из состояния до этой операции перейти к состоянию после этой операции и наоборот (исключение — модель восстановления с неполным протоколированием).
Важно, что эта информация пишется на диск сразу. Пока информация не записана в ЖТ, команда не считается исполненной. В нормальной ситуации, когда размер ЖТ достаточного объёма и когда он не сильно фрагментирован, записи в него пишутся последовательно небольшими записями (не обязательно кратные 8 кб). В журнал транзакций попадают данные только действительно необходимые для восстановления. В частности не попадает информация о том, какой текст запроса привел к модификациям, какой план выполнения был у этого запроса, какой пользователь его запустил и прочая ненужная для восстановления информация. Некоторое представление о структуре данных журнала транзакций может дать запрос
select * from ::fn_dblog(null,null)
Из-за того, что жёсткие диски значительно эффективнее работают с последовательной записью, чем с хаотичным потоком команд на чтение и запись и из-за того, что команды SQL будут ждать момента окончания записи в ЖТ, возникает следующая рекомендация:
Если есть хоть малейшая возможность, то в продуктовой среде ЖТ должны располагаться на отдельных (от всего остального) физических носителях, желательно с минимальным временем доступа для последовательной записи и с максимальной надёжностью. Для простых систем вполне подойдёт RAID-1.
Если транзакция отменяется, то все уже внесённые изменения сервер вернёт в предыдущее состояние. Именно поэтому
Отмена транзакции в MS SQL Server обычно длится сопоставимо с суммарной длительностью операций изменения данных самой транзакции. Старайтесь не отменять транзакции или принимать решение об отмене как можно раньше.
Если сервер по каким-то причинам неожиданно прекратит работу, то при повторном запуске будет проанализировано, какие данные в ФД не соответствуют целостному состоянию (незаписанные, но зафиксированные транзакции и записанные, но отмененные транзакции) и эти данные будут откорректированы. Поэтому если вы, например запустили перестроение индексов большой таблицы и перезапустили сервер, то при повторном запуске уйдёт значительное время на откат этой транзакции, причем прервать этот процесс возможности нет.
Что происходит когда ЖТ дошёл до конца файла? Всё просто — если есть освобождённое место в начале, то он начнёт писать в свободное место в начале файла до занятого места. Как закольцованная магнитная лента. Если места в начале нет, то сервер обычно попытается расширить файл журнала транзакций, при этом для сервера выделенный новый кусок является новым виртуальным файлом журнала транзакций, которых в физическом файле транзакций может быть много, но это уже к резервному копированию относится мало. Если у сервера не получится расширить файл (закончилось место на диске или запрещено настройками расширять ЖТ), то текущая транзакция отменится с ошибкой 9002.
Упс. А что же надо сделать чтобы место в ЖТ всегда было? Вот тут мы подошли к системе резервного копирования и к моделям восстановления. Для отмены транзакций и для восстановления корректного состояния сервера в случае внезапного выключения необходимо хранить в ЖТ записи, начиная с момента старта самой ранней из открытых транзакций. Этот минимум пишется и хранится в ЖТ обязательно. Вне зависимости от погоды, настроек сервера и желания админа. Сервер не может допустить, чтобы этой информации не было. Поэтому, если открыть в одном сеансе транзакцию, а в других выполнять разные действия, то журнал транзакций может неожиданно закончиться. Самую раннюю транзакцию можно выявить командой DBCC OPENTRAN. Но это только необходимый минимум информации. Дальнейшее зависит от модели восстановления. В SQL Server их три:
- Simple (Простая) — хранится только необходимый для жизни остаток ЖТ.
- Full (Полная) — хранится весь ЖТ с момента последнего резервного копирования журнала транзакций. Обратите внимание, не с момента полного бэкапа!
- Bulk logged (С неполным протоколированием) — часть (очень небольшая обычно часть) операций записываются в очень компактном формате (по сути только запись, что изменена такая-то страница файла данных). В остальном идентична Full.
С моделями восстановления связано несколько мифов.
- Simple позволяет снизить нагрузку на дисковую подсистему. Это не так. пишется ровно столько же, сколько при Bulk logged, только считается свободным гораздо раньше.
- Bulk logged позволяет снизить нагрузку на дисковую подсистему. Для 1С это почти не так. По сути одна из немногих операций, которая может без дополнительных плясок с бубном подпадать под минимальное протоколирование — загрузка данных из выгрузки в формате dt и реструктуризация таблиц.
- При использовании модели Bulk logged какие-то операции не попадают в резервную копию журнала транзакций и она не позволяет восстановить состояние на момент этой резервной копии. Это не совсем так. Если операция относится к минимально протоколируемым, то в резервную копию попадут текущие страницы с данными и будет возможность "проиграть" журнал транзакций до конца (хотя и нельзя на произвольный момент времени, если есть минимально протоколируемые операции).
Модель Bulk logged для баз 1С использовать почти бессмысленно, поэтому дальше мы её не рассматриваем. А вот выбор между Full и Simple расмотрим подробнее в следующей части.
Для любознательных — ссылки на русскоязычную документацию, которая более полно описывает работу журнала транзакций:
- Структура журнала транзакций
- Управление журналом транзакций
- Использование резервных копий журналов транзакций
Принцип действия резервного копирования в моделях восстановления Simple и Full
По типу формирования резервные копии бывают трёх видов:
- Full (Полная)
- Differential (Дифференциальная, разностная)
- Log (Резервная копия журналов транзакций, учитывая, то, насколько часто этот термин используется, будем сокращать до РКЖТ)
Здесь надо не запутаться: полная модель восстановления и полная резервная копия — существенно разные вещи. Для того чтобы их не спутать, ниже я буду использовать английские термины для модели восстановления и русскоязычные для видов резервных копий.
Полная и дифференциальная копия работают одинаково для Simple и Full. Резервная копия журналов транзакций полностью отсутствует в Simple.
Полная резервная копия
Позволяет восстановить состояние базы данных на некоторый момент времени (на тот в который начато формирование резервной копии). Состоит из постраничной копии используемой части файлов данных и активного куска журнала транзакций за то время пока формировалась резервная копия.
Разностная резервная копия
Хранит страницы данных, изменившиеся с момента последней полной резервной копии. При восстановлении нужно сначала восстановить полную резервную копию (в режиме NORECOVERY, примеры будут приведены ниже), потом можно к получившейся "заготовке" применить любую из последующих разностных копий, но, конечно только из тех, которые сделаны до следующей полной резервной копии. За счет этого можно значительно снизить объём дискового пространства для хранения резервной копии.
Важные моменты:
- Без предыдущей полной резервной копии разностная копия бесполезна. Поэтому желательно хранить их где-то рядом друг с другом.
- Каждая последующая разностная копия будет хранить все страницы, входящие в предыдущую разностную резервную копию, сделанную после предыдущей полной (хотя, возможно, уже с другим содержимым). Поэтому каждая следующая разностная копия больше предыдущих, пока снова не сделать полную копию (если это и нарушается, то только из-за алгоритмов сжатия)
- Для восстановления на какой-то момент достаточно последней полной резервной копии на этот момент и последней разностной копии на этот момент. Промежуточные копии для восстановления не нужны (хотя они могут быть нужны для выбора момента восстановления)
РКЖТ
Содержит копию ЖТ за некоторый период. Обычно с момента прошлой РКЖТ до момента формирования текущей РКЖТ. РКЖТ позволяет из восстановленной в режиме NORECOVERY копии на любой момент времени, входящий в период восстанавливаемой копии ЖТ, восстановить состояние на любой последующий момент времени, входящий в интервал восстанавливаемой резервной копии. При формировании резервной копии со стандартными параметрами, место в файле журнала транзакций высвобождается (до момента последней открытой транзакции).
Очевидно, что РКЖТ не имеет смысла в модели Simple (тогда ЖТ содержит лишь информацию с момента последней незакрытой транзакции).
При использовании РКЖТ возникает важное понятие — непрерывная цепочка РКЖТ. Эту цепочку может прервать либо потеря некоторых резервных копий этой цепочки, либо перевод базы данных в Simple и обратно.
Внимание: набор РКЖТ по сути бесполезен, если он не является непрерывной цепочкой, причем момент начала последнего успешного полного или разностного резервного копирования должен быть внутри периода этой цепочки.
Частые заблуждения и мифы:
- "РКЖТ содержит данные журнала транзакций от момента предыдущего полного или разностного бэкапа". Нет, это не так. РКЖТ содержит и на первый взгляд бесполезные данные между предыдущей РКЖТ и последующим полным бэкапом.
- "Полный или разностный бэкап должны приводить к освобождению места внутри журнала транзакций". Нет, это не так. Полный и разностный бэкап не трогают цепочку РКЖТ.
- ЖТ нужно перидически чистить вручную, уменьшать, шринкать. Нет, не надо и даже наоборот — нежелательно. Если освобождать ЖТ между РКЖТ, то будет нарушена цепочка РКЖТ, нужная для восстановления. А постоянные уменьшения/расширения файла приведут к его физической и логической фрагментации.
Как это работает в simple
Пусть есть база данных в 1000 ГБ. Каждый день база прирастает на 2 ГБ, при этом меняется 10 ГБ старых данных. Сделаны следующие резервные копии
- Полная копия F1 от 0:00 1 февраля (объём 1000 ГБ, сжатие для простоты картины не учитываем)
- Разностная копия D1.1 от 0:00 2 февраля (объём 12 ГБ)
- Разностная копия D1.2 от 0:00 3 февраля (объём 19 ГБ)
- Разностная копия D1.3 от 0:00 4 февраля (объём 25 ГБ)
- Разностная копия D1.4 от 0:00 5 февраля(объём 31 ГБ)
- Разностная копия D1.5 от 0:00 6 февраля (объём 36 ГБ)
- Разностная копия D1.6 от 0:00 7 февраля (объём 40 ГБ)
- Полная копия F2 от 0:00 8 февраля (объём 1014 ГБ)
- Разностная копия D2.1 от 0:00 9 февраля (объём 12 ГБ)
- Разностная копия D2.2 от 0:00 10 февраля (объём 19 ГБ)
- Разностная копия D2.3 от 0:00 11 февраля (объём 25 ГБ)
- Разностная копия D2.4 от 0:00 12 февраля(объём 31 ГБ)
- Разностная копия D2.5 от 0:00 13 февраля (объём 36 ГБ)
- Разностная копия D2.6 от 0:00 14 февраля (объём 40 ГБ)
При помощи этого набора мы можем восстановить данные на момент 0:00 любого из дней с 1 по 14 февраля. Для этого нам нужно взять полную копию F1 для недели 1-7 февраля или полную копию F2 для 8-14 февраля, восстановить её в режиме NORECOVERY и потом применить разностную копию нужного дня.
Как это работает в full
Пусть у нас есть такой же набор резервных полных и разностных резервных копий, как в предыдущем примере. В дополнение к этому есть следующие РКЖТ:
- РКЖТ 1 за период с 12:00 31 января по 12:00 2 февраля (около 30 ГБ)
- РКЖТ 2 за период с 12:00 2 февраля по 12:00 4 февраля (около 30 ГБ)
- РКЖТ 3 за период с 12:00 4 февраля по 12:00 6 февраля (около 30 ГБ)
- РКЖТ 4 за период с 12:00 6 февраля по 12:00 7 февраля (около 30 ГБ)
- РКЖТ 5 за период с 12:00 8 февраля по 12:00 10 февраля (около 30 ГБ)
- РКЖТ 6 за период с 12:00 10 февраля по 12:00 12 февраля (около 30 ГБ)
- РКЖТ 7 за период с 12:00 12 февраля по 12:00 14 февраля (около 30 ГБ)
- РКЖТ 8 за период с 12:00 14 февраля по 12:00 16 февраля (около 30 ГБ)
Обратите внимание:
- Размер РКЖТ будет примерно постоянным.
- Резервные копии мы можем делать реже, чем разностные или полные, а можем и чаще, тогда они будут меньше по размеру.
- Теперь мы можем восстановить состояние системы на любой момент с 0:00 1 февраля, когда у нас есть самая ранняя полная копия по 12:00 16 февраля.
В самом простом случае нам для восстановления понадобятся:
- Последняя полная копия до момента восстановления
- Последняя разностная копия до момента восстановления
- Все РКЖТ, от момена последней разностной копии до момента восстановления
Пример. Для восстановления на 13:13:13 10 февраля нам понадобятся:
- Полная копия F2 от 0:00 8 февраля
- Разностная копия D2.2 от 0:00 10 февраля
- РКЖТ 6 за период с 12:00 10 января по 12:00 12 февраля
Сначала будет восстановлена F2, потом D2.2, потом РКЖТ 6 до момента 13:13:13 10 февраля. Но существенное преимущество Full модели в том, что у нас появляется выбор — использовать последнюю полную или разностную копию или НЕ последнюю. Например, если бы обнаружилось, что копия D2.2 была испорчена, а нам надо восстановить на момент до 13:13:13 10 февраля, то для модели Simple это бы значило, что мы можем восстановить данные только на момент D2.1. При Full — "DON'T PANIC", у нас есть следующие возможности:
- Восстановить F2, потом потом D2.1, потом РКЖТ 5, потом потом РКЖТ 6 до момента 13:13:13 10 февраля.
- Восстановить F2, потом РКЖТ 4, потом РКЖТ 5, потом потом РКЖТ 6 до момента 13:13:13 10 февраля.
- Или вообще восстановить F1 и прогнать все РКЖТ до РКЖТ 6 до момента 13:13:13 10 февраля.
Как видно, полная модель предоставляет нам больший выбор.
А теперь представим, что мы очень хитрые. И за пару дней до сбоя (13:13:13 10 февраля.) знаем, что сбой будет. Мы восстанавливаем на соседнем сервере базу данных из полной резервной копии, оставляя возможность донакатывать последующие состояния разностными копиями или РКЖТ, т. е. оставили в режиме NORECOVERY. И каждый раз сразу после формирования РКЖТ применяем её к этой резервной базе, оставляя в режиме NORECOVERY. Ого! Да ведь на восстановление базы данных у нас теперь уйдёт всего 10-15 минут, вместо того, чтобы восстанавливать огромную базу! Поздравляю, мы заново изобрели механизм доставки журналов, один из способов снижения времени простоев. Если так передавать данные не раз в период, а постоянно, то получится уже зеркалирование, причем если база-источник ждёт пока база-зеркало обновится, то это синхронное зеркалирование, если не ждёт, то асинхронное.
Подробнее о средствах высокой доступности можно прочтитать в справке:
Прочие аспекты резервного копирования
Этот раздел можно смело пропустить, если вам наскучила теория и руки чешутся опробовать настройки резервного копирования.
Файловые группы
1С:Предприятие по сути не умеет работать с файловыми группами. Есть единственная файловая группа и всё. На самом деле программист или администратор базы данных MS SQL способен некоторые таблицы, индексы или даже куски таблиц и индексов положить в отдельные файловые группы (в простейшем варианте — в отдельные файлы). Это нужно либо для того, чтобы ускорить доступ к каким-то данным (положив на очень быстрые носители), либо наоборот, пожертвовав скоростью поместить на более дешёвые носители (например, малоиспользуемые но объёмные данные). При работе с файловыми группами есть возможность делать их резервные копии отдельно, также отдельно можно и восстанавливать, но нужно учесть, что все файловые группы придётся "догнать" до одного момента накатыванием РКЖТ.
Файлы данных
Если помещением данных в разные файловые группы управляет человек, то когда внутри файловой группы есть несколько файлов, то данные по ним распихивает MS SQL Server самостоятельно (при равном объёме файлов — постарается равномерно). С прикладной точки зрения это используется для распараллеливания операций ввода-вывода. А с точки зрения резервных копий есть другой момент. Для очень больших баз данных в эпоху "до SQL 2008" была типичной проблема выделить непрерывное окно для полной резервной копии, да и диск-приемник для этой резервной копии мог просто её не вместить. Самым простым способом в этом случае было делать резервную копию каждого файла (или файловой группы) в своё окно. Сейчас, с активным распространением сжатия резервных копий эта проблема стала меньше, но всё же этот прием можно иметь в виду.
Сжатие резервных копий
В MS SQL Server 2008 появилась супер-мега-ультра возможность. Отныне и навсегда резервные копии могут быть компрессированными при формировании на лету. Это уменьшает размер резервной копии БД 1С в 5-10 раз. А учитывая, что обычно производительность дисковой подсистемы является узким местом СУБД, то это даёт не только снижение стоимости хранения, но и еще мощное ускорение резервного копирования (хотя и повышается нагрузка на процессоры, но обычно процессорные мощности вполне достаточны на сервере СУБД).
Если в версии 2008 эта возможность была только для Enterprise редакции (которая стоит очень дорого), то в 2008 R2 эта возможность отдана в версию Standard, что сильно радует.
Ниже при разборе примеров настройки сжатия не рассматриваются, но я настоятельно рекомендую использовать сжатие резервных копий, если нет особых причин его отключить.
Один файл бэкапа — много внутренностей
На самом деле резервная копия это не просто файл, это достаточно сложный контейнер, в котором может храниться много резервных копий. У этого подхода очень древняя история (я лично её наблюдаю с версии 6.5), но на текущий момент для администраторов "обычных" баз данных, особенно баз данных 1С, нет каких-либо серьёзных причин не использовать подход "одна резервная копия — один файл". Для общего развития полезно изучить возможность складывать в один файл несколько резервных копий, но использовать её скорее всего не придётся (или если и придётся, то разбирая завалы горе-администратора, который эту возможность неквалифицированно использовал).
Несколько зеркальных копий
В SQL Server есть еще одна замечательная возможность. Можно резервную копию формировать параллельно в несколько приемников. Как простейший пример, можно сваливать одну копию на локальный диск и одновременно складывать на сетевой ресурс. Локальная копия удобна, так как восстановление из неё существенно быстрее, удалённая копия зато гораздо лучше перенесёт физическое уничтожение основного сервера базы данных.
Примеры систем резервного копирования
Довольно теории. Пора практикой доказать, что вся эта кухня работает.
Настройка типичного резервирования сервера через Планы обслуживания (MaintenancePlan)
Этот раздел построен в виде готовых рецептов с пояснениями. Этот раздел очень скучный и длинный за счет картинок, поэтому его можно пропустить.
Пользуемся мастером создания плана обслуживания
- Запускаем SSMS, подключаемся к нужному серверу.
- Запускаем мастер:
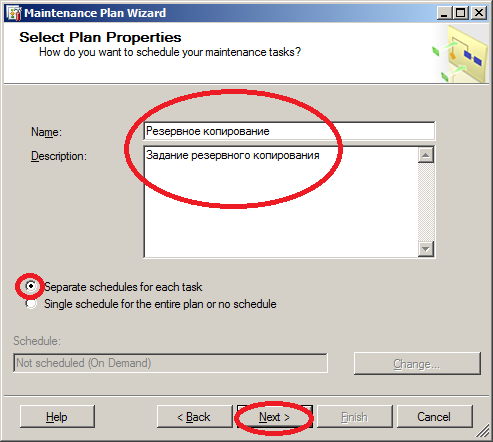
- Задаём имя плана "Резервное копирование" и описание, указываем галочку "Separate schedules for each task", переходим дальше
- Устанавливаем режимы работы (другие галочки лучше оставить отдельным планам обслуживания), переходим дальше
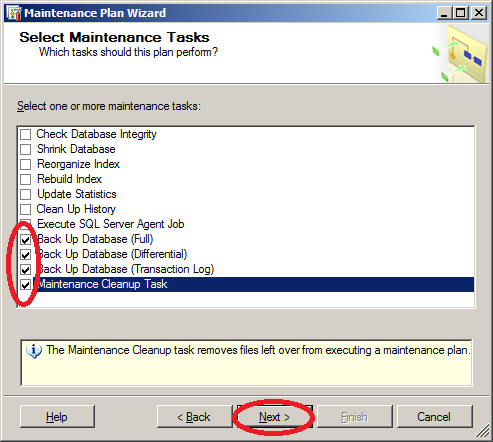
- Начинаем настраивать полное резервное копирование:
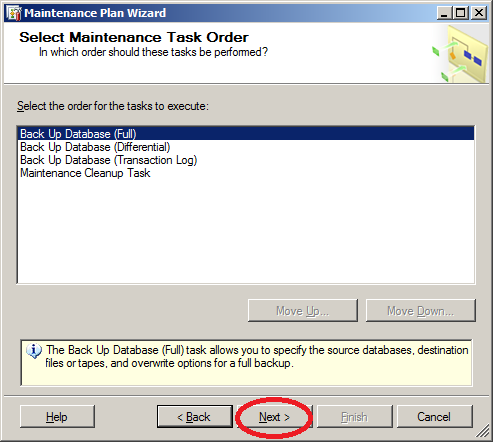
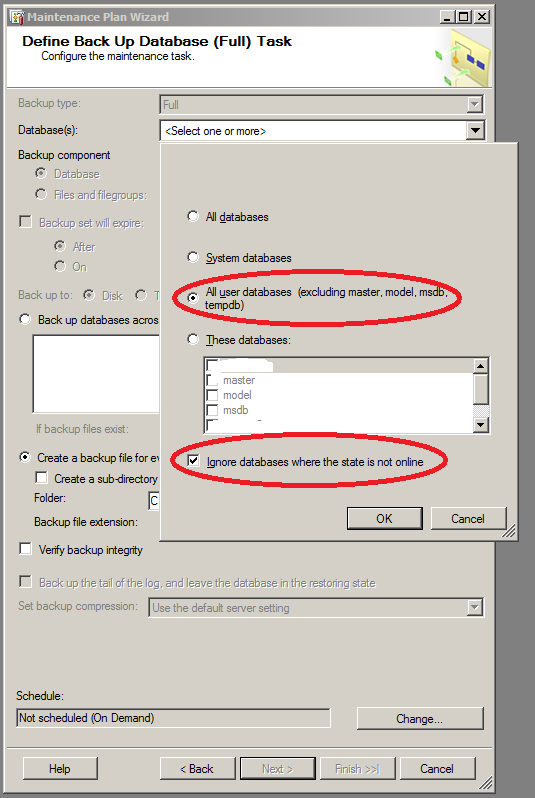
- Настраиваем полное копирование всех пользовательских баз данных. Системные базы данных тоже желательно сохранять, но во-первых не все (имеет смысл только master и msdb, если вы специально не изменяете model), во-вторых, возможно, с другой периодичностью, в-третьих для master не нужно сохранять РКЖТ.
- Настраиваем детали копирования. Обратите внимание на следующие моменты:
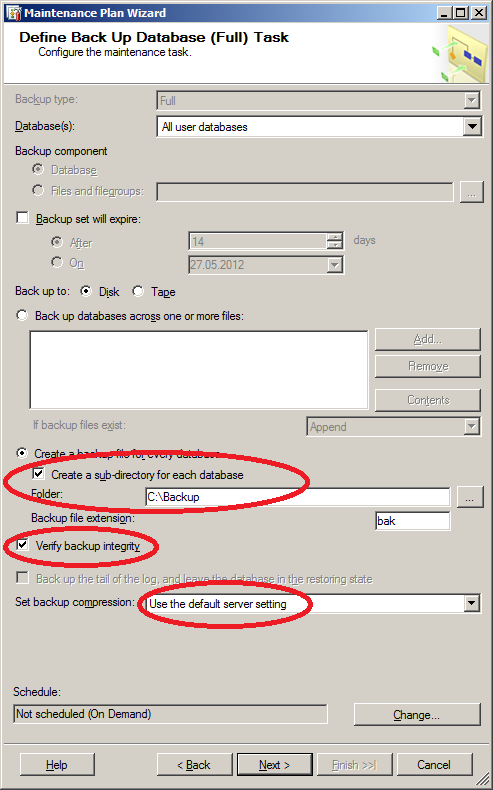
- удобнее для каждой БД делать отдельный подкаталог, если этих БД больше 2-3 на сервере;
- если нет дополнительных средств проверки, то крайне желательно выставить галочку "Verify backup integrity". Хотя возможна ситуация, когда даже проверенная таким образом копия не восстановится, но такая проверка лучше, чем никакая;
- вариант сжатия установлен "по настройкам сервера", очень желательно включить эту возможность на уровне сервера;
- папку "C:\Backup" я использую только для примера.
- Настраиваем расписание (например, раз в неделю по воскресеньям в полночь, примерно как в рассмотренном ранее примере):
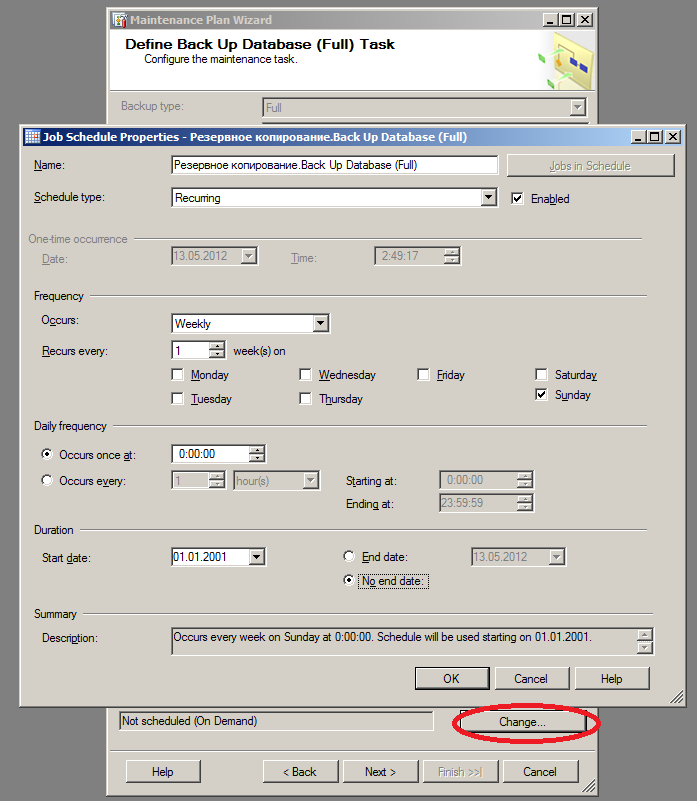
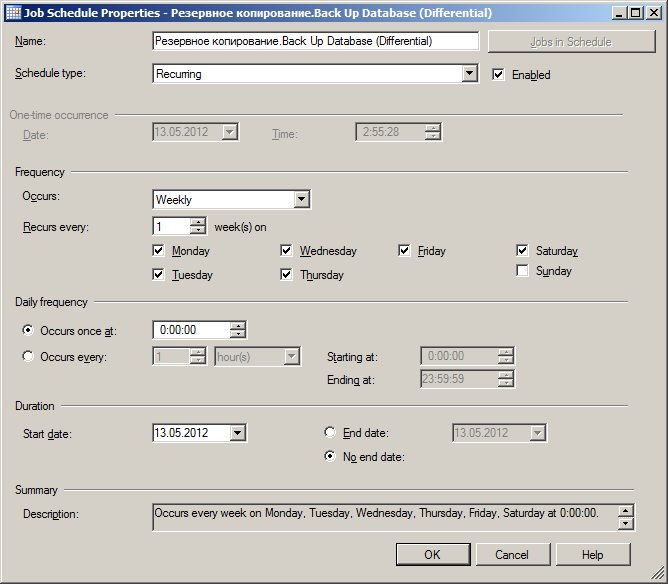
- Аналогично настраиваем разностные резервные копии, но раз в день, кроме воскресенья. Тоже в полночь.
- РКЖТ. Ежедневно в 12:00 (остальное аналогично предыдущим).
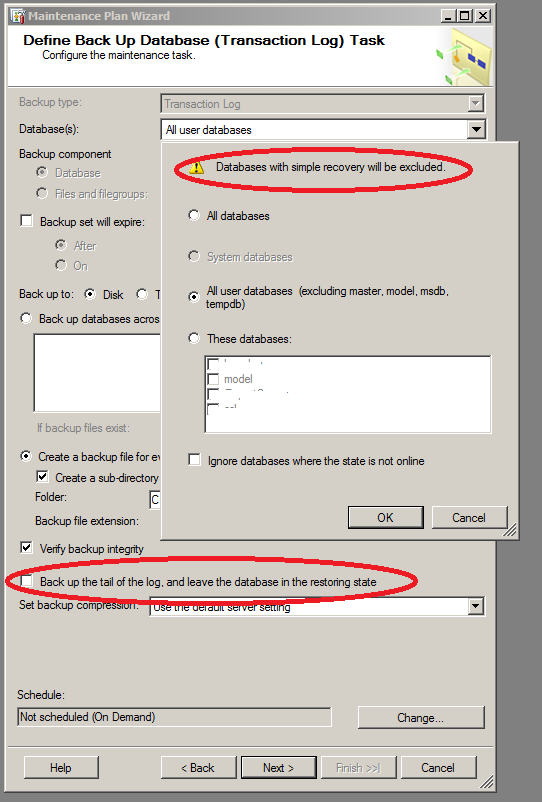
- Обратите внимание, что базы данных с моделью восстановления simple будут игнорироваться.
- Обратите внимание, что галочку "Back up the tail..." ставить не следует. Она не предназначена для обычного резервного копирования журналов транзакций.
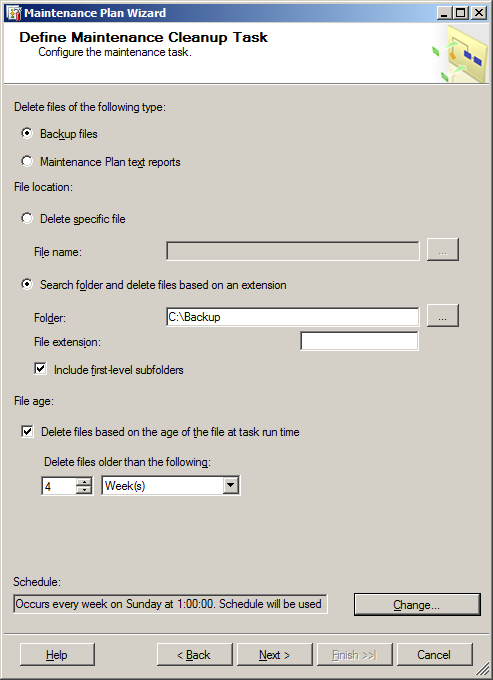
- Настроим разумный горизонт хранения резервных копий в этой папке (например, 4 недели, предполагается, что резервные копии из этой папки копируются еще куда-то и хранятся существенно дольше):
- Протоколы сохраняем в папку по умолчанию. Их вообще-то тоже желательно подчищать, но это можно делать и вручную раз в 3-4 года.
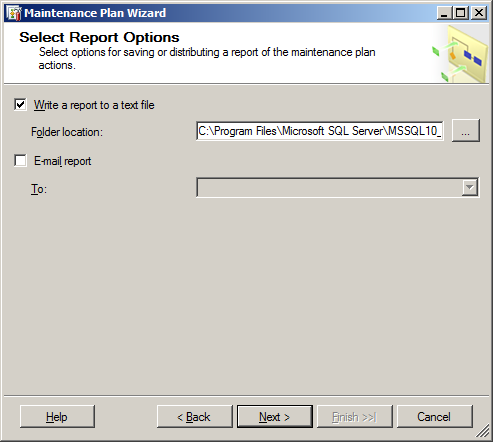
- Проверяем, убеждаемся, что всё правильно ...
- Вот в общем-то и всё. Резервное копирование, подходящее для большинства баз данных размером от 1-2 ГБ до 200-300 ГБ готово.
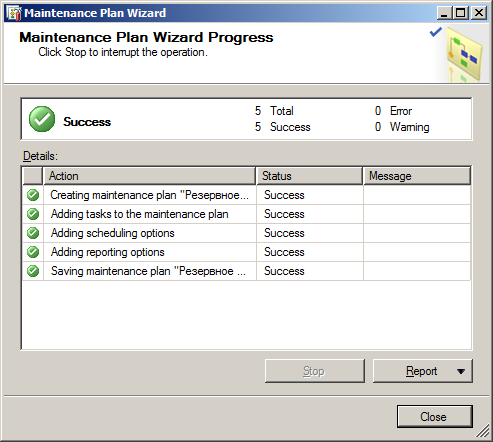
- Как проверить, что система работает?
- Проверяем, что нужные объекты созданы:
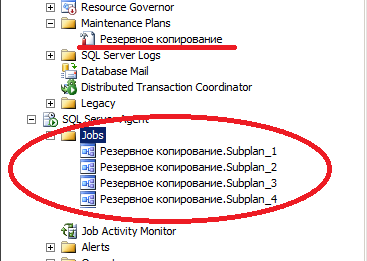
- Для каждого из заданий (Резервное копирование.Subplan_1, Резервное копирование.Subplan_2, Резервное копирование.Subplan_3, Резервное копирование.Subplan_4) проверяем, что они запускаются:
Проверять лучше последовательно: запустить, дождаться завершения, закрыть уведомление, перейти к следующему. - Проверяем, что в целевой папке появились резервные копии.
- Проверяем, что разностная копия существенно меньше полной.
- Снова запускаем задание Резервное копирование.Subplan_3 (это РКЖТ) и проверяем, что второй сгенерированный файл РКЖТ в каждой базе имеет небольшой размер относительно первого (В MS SQL Server 2005 стоит перед повторным выполнением нужно подождать пару минут.)
- Проверяем папку протоколов и читаем (у меня это папка C:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\Log — та, которая была настроена на шаге 12). Читаем протоколы, убеждаемся, что ошибок нет.
- Проверяем, что нужные объекты созданы:
- ...????
- PROFIT!!!
















Настройка резервирования сервера скриптами TSQL, примеры некоторых возможностей
Сразу возникает вопрос, а чего еще надо? Вроде ж только что всё настроили и всё работает как часы? Зачем маяться со всякими скриптами? Планы обслуживания не позволяют:
- Использовать зеркальное резервирование
- Использовать настройки сжатия отличные от настроек сервера
- Не позволяет гибко реагировать на возникающие ситуации (никаких возможностей по обработке ошибок)
- Не позволяет гибко использовать настройки безопасности
- Планы обслуживания очень неудобно развёртывать (и поддерживать одинаковыми) на большом количестве серверов (даже, пожалуй, уже на 3-4)
Ниже приведены типичные команды резервного копирования
Полная резервная копия
Полная резервная копия с затиранием существующего файла (если есть) и проверкой контрольных сумм страниц перед записью. При формировании резервной копии отсчтитывается каждый процент прогресса выполнения
BACKUP DATABASE [mydb] TO DISK = N'C:\Backup\mydb.bak'
WITH INIT, FORMAT, STATS = 1, CHECKSUM
Разностная резервная копия
Аналогично — разностная копия
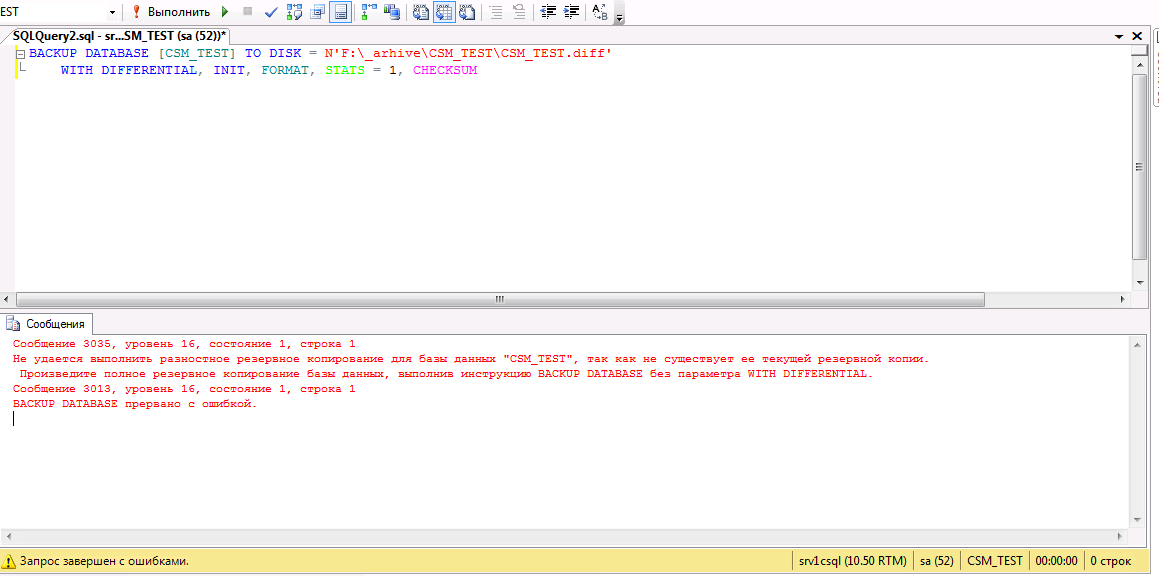
BACKUP DATABASE [mydb] TO DISK = N'C:\Backup\mydb.diff'
WITH DIFFERENTIAL, INIT, FORMAT, STATS = 1, CHECKSUM
РКЖТ
Резервная копия журнала транзакций
BACKUP LOG [mydb] TO DISK = N'C:\Backup\mydb.trn' WITH INIT, FORMAT
Зеркальное резервирование
Часто удобно делать сразу не одну резервную копию, а две. Например, одна может лежать локально на сервере (чтобы была под рукой), а вторая сразу формируется в физически удалённое и защищённое от неблагоприятных воздействий хранилище:
BACKUP DATABASE [mydb] TO
DISK = N'C:\Backup\mydb.bak',
MIRROR TO DISK = N'\\safe-server\backup\mydb.bak'
WITH INIT, FORMAT
Важный момент, который часто упускается: у пользователя, от имени которого запускается процесс MSSQL Server должен быть доступ к ресурсу "\\safe-server\backup\", иначе копирование завершится с ошибкой. Если MSSQL Server запущен от имени системы, то доступ нужно давать пользователю домена "имя_сервера$", но лучше всё-таки корректно настроить запуск MS SQL от имени специально созданного пользователя.
Если не указать MIRROR TO, то это будет не 2 зеркальных копии, а одна копия, разбитая на 2 файла, по принципу чередования. И каждая из них в отдельности будет бесполезна.
Ссылки
Полезнее всего для понимания работы резервного копирования ознакомиться со следующими статьями:
- BACKUP (Transact-SQL)- для подробного ознакомления с синтаксисом команды RESTORE
- Инструкции RESTORE для восстановления из копии, восстановления по журналу и управления резервными копиями (Transact-SQL) - страниц со статьями по вариантам RESTORE
- Форматирование носителей резервных копийразъяснение опций "FORMAT/NOFORMAT"
- Работа с устройствами резервного копирования и наборами носителей
- Восстановление резервных копий SQL Server
- Резервное копирование и восстановление баз данных SQL Server
- Модели восстановления (SQL Server)
- Общие сведения о резервном копировании (SQL Server)
- Обзор процессов восстановления (SQL Server)
- Сжатие резервных копий (SQL Server)
- Полные резервные копии баз данных (SQL Server)
- Частичные резервные копии (SQL Server)
- полные резервные копии файлов (SQL Server)
- Разностные резервные копии (SQL Server)
- Резервные копии только для копирования (SQL Server)
- Резервные копии журналов транзакций (SQL Server)
- Резервные копии заключительного фрагмента журнала (SQL Server)
- Устройства резервного копирования (SQL Server)
- Наборы носителей, семейства носителей и резервные наборы данных (SQL Server)
- Зеркальные наборы носителей резервных копий (SQL Server)
- Журнал и сведения о заголовке резервной копии (SQL Server)
- Возможные ошибки носителей во время резервного копирования и восстановления (SQL Server)
- Выполнение полного восстановления базы данных (Простая модель восстановления)
- Выполнение полного восстановления базы данных (модель полного восстановления)
- Восстановления файлов (простая модель восстановления)
- Файлы из резервных копий (модель полного восстановления)
- Применение резервных копий журналов транзакций (SQL Server)
- Восстановление в сети (SQL Server)
- Восстановление страниц (SQL Server)
- Поэтапное восстановление (SQL Server)
- Восстановление базы данных без восстановления данных (Transact-SQL)
- Резервное копирование и восстановление системных баз данных (SQL Server)
- Резервное копирование и восстановление: взаимодействие и совместимость (SQL Server)
Примеры использования систем резервного копирования
Так, так, так. Вы думаете что резервное копирование работает? А вы уверены? А вы уверены, что то, что формируется резервным копированием при аварии можно будет использовать для восстановления? Давайте проверим, а заодно научимся восстанавливать данные. Проверка возможностей восстановления — это обязательный этап настройки резервного копирования.
Проверяем резервную копию без восстановления
Файл лежит на диске. Но может быть это вовсе и не резервная копия? Как проверить:
RESTORE VERIFYONLY FROM DISK = N'C:\Backup\mydb.bak'
Здесь, правда, как с анализами в больнице: если результат анализа положительный, то болезнь есть, если отрицательный, то это еще не гарантирует, что болезни нет. Вот и тут также: если RESTORE VERIFYONLY ругается на ваш файл, то он некорректный. Но если не ругается, то это еще не окончательная гарантия, что он восстановится. Особенно это актуально для предыдущих версий MS SQL Server.
Восстановление полной копии в новую базу данных
Это, пожалуй, самая частая операция с файлами резервных копий. Делать её можно как скриптом, так и интерактивно. Давайте сначала интерактивно:
- Выбираем Restore Database из контекстного меню:
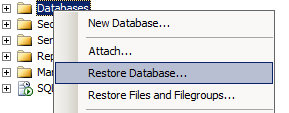
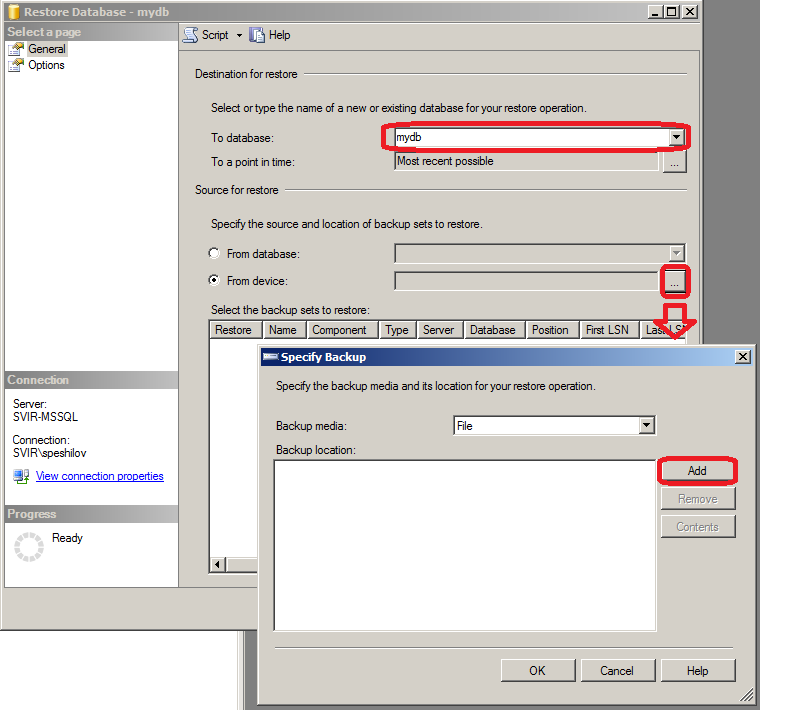
- Выбираем базу данных, в которую надо восстановить файл, и сам файл
- На закладке Options настраиваем, где будут лежать файлы восстановленной базы данных. Если базу данных восстанавливаем поверх существующей, то нужно установить флажок
WITH REPLACE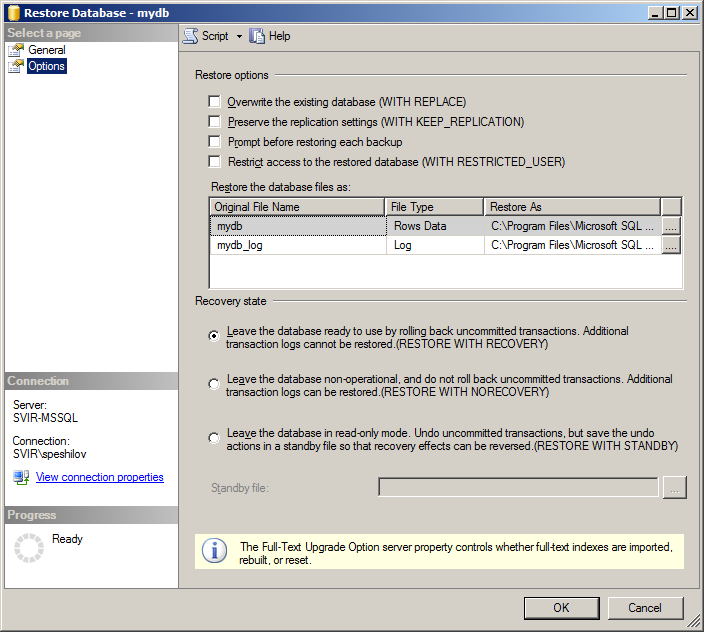
- Жмем OK



А вот вариант TSQL:
RESTORE DATABASE mydb FROM DISK = N'C:\Backup\mydb.bak'
Для самых хитрых и ленивых есть очень полезная возможность создать вариант TSQL из настроенного окна восстановления: 
Восстановление полной копии и разностной
RESTORE DATABASE mydb
FROM DISK = N'C:\Backup\mydb.bak'
WITH NORECOVERY;
RESTORE DATABASE mydb
FROM DISK = N'C:\Backup\mydb.diff'
WITH RECOVERY;
Восстановление полной копии, разностной и нескольких журналов транзакций
RESTORE DATABASE mydb
FROM DISK = N'C:\Backup\mydb.bak'
WITH NORECOVERY;
RESTORE DATABASE mydb
FROM DISK = N'C:\Backup\mydb.diff'
WITH NORECOVERY;
RESTORE DATABASE mydb
FROM DISK = N'C:\Backup\log1.trn'
WITH NORECOVERY;
RESTORE DATABASE mydb
FROM DISK = N'C:\Backup\log2.trn'
WITH RECOVERY;
Восстановление до определённой точки
RESTORE DATABASE mydb
FROM DISK = N'C:\Backup\mydb.bak'
WITH NORECOVERY;
RESTORE DATABASE mydb
FROM DISK = N'C:\Backup\mydb.diff'
WITH NORECOVERY;
RESTORE DATABASE mydb
FROM DISK = N'C:\Backup\log1.trn'
WITH STOPAT = '2013-02-12 21:45:00';
RESTORE DATABASE mydb
FROM DISK = N'C:\Backup\log2.trn'
WITH STOPAT = '2013-02-12 21:45:00';
Обратите внимание, если указанное время STOPAT назначено после создания последней резервной копии журналов, база данных остается в невосстановленном состоянии, как если бы инструкция RESTORE LOG работала с параметром NORECOVERY.
Факультативно рекомендую посмотреть самостоятельно
- Восстановление с использованием "хвоста" журнала транзакций (
WITH TAIL) - Восстановление в состояние standby (но важно понимать, что обычно 1С не сможет работать с БД, доступной только для чтения)
- Восстановление сбойных страниц, восстановление файлов (факультатив)
Все эти возможности можно посмотреть в MSDN:
- Инструкции RESTORE для восстановления из копии, восстановления по журналу и управления резервными копиями (Transact-SQL) - страниц со статьями по вариантам RESTORE
Заключение
Приведённой информации достаточно для ликбеза по резервным копиям, но недостаточно для практических навыков. Читайте, изучайте, тренируйтесь (в "песочнице", естественно). Всё вышеперечисленное применимо далеко не только к 1С:Предприятияю.
Напоследок ссылочка по теме: Пошаговая инструкция восстановления повреждённой БД (доля шутки)

DatabaseCompressionTool — сжатие и свертка любой базы 1С
Инструмент DatabaseCompressionTool (DCT) позволяет безопасно сжать и свернуть любую базу 1С, освободив сотни гигабайт и увеличив производительность системы. Доступна демо-версия для оценки эффективности.
Вступайте в нашу телеграмм-группу Инфостарт