

{kind=link}
Задача: научиться парсить сайт на конкретном примере
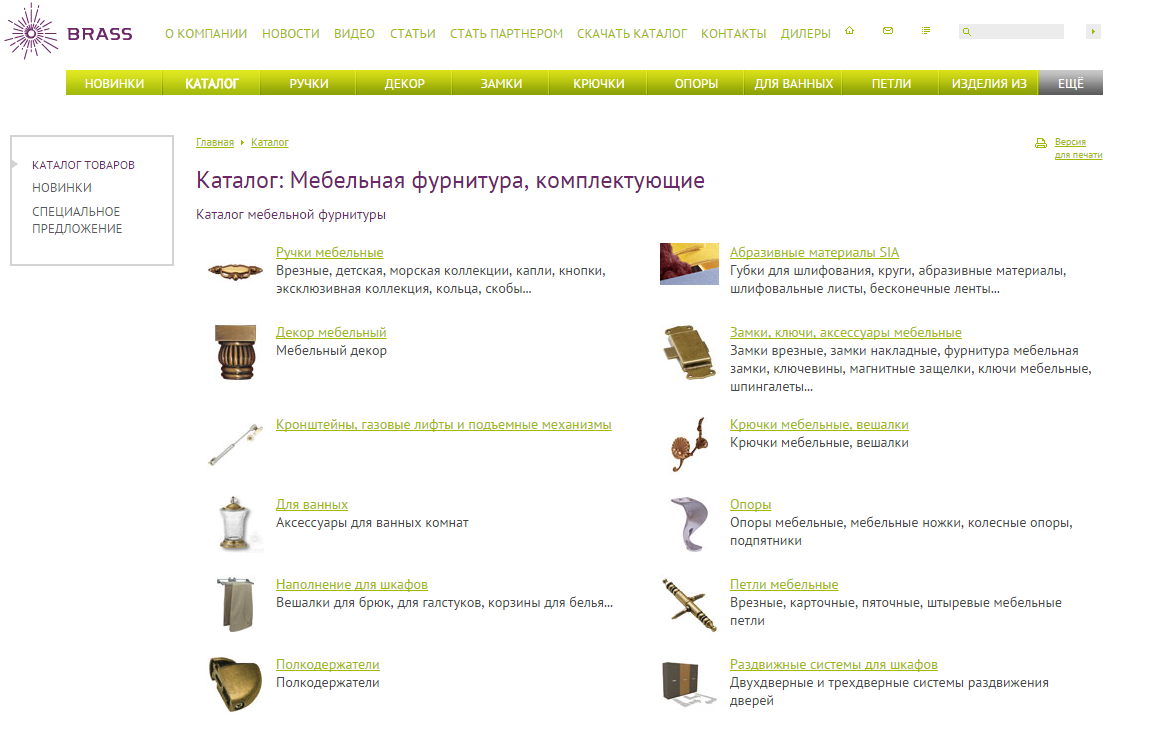
Будем парсить сайт brass.ru - крупного поставщика фурнитуры
Способ парсинга аналогичен тому, что указан в публикации //infostart.ru/public/88106/ , но имеет другой подход.
Далее следует большое полотно текста вперемешку с кодом, если нет желания читать – внизу можно скачать обработку и сразу разбираться в коде – он прокомментирован.
Следует сразу понять, что не существует универсальных парсеров сайтов, подходящих для всех. Большинство сайтов различаются своей структурой, поэтому для каждого из них существует свой алгоритм вытаскивания информации.
Поехали!
Парсить будем не с помощью элемента ДокументHTML на форме, а с помощью ЧтениеHTML (класс для загрузки html-документа) и ПостроительDOM (класс, загружающий в себя всю структуру и информацию документа). Суть этого метода заключается в том, что нам нужно подключиться к серверу, получить необходимую нам html-страницу (только html-код) и разобрать ее, а не загружать всё содержимое страницы на форму и потом рендерить его.
Практический любой сайт строится таким образом, что он состоит из блоков, которые содержат другие блоки, которые содержат другие блоки и так может повторяться огромное количество раз. Поэтому нам придется заранее узнать имена элементов, которые содержат необходимые нам данные.
Я использовал для этого Google Chrome.
Теоритическая часть
1. Парсим каталоги
Начнем собирать данные. Заходим в каталог товаров, клацаем правой клавишей на список товаров -> Показать код элемента. Видим, что список подкаталогов содержится в элементе TABLE с классом navCatalog, глядим на ссылки на подкаталоги – они представляют из себя элементы A. Это значит, что нам нужно найти элемент TABLE с классом navCatalog и получить из него все элементы A. Если мы перейдем в первый каталог, то увидим, что там есть еще каталоги – это не проблема, ведь эта страница подчиняется все тем же правилам, а наша процедура парсинга каталогов будет рекурсивна.
2. Парсим список товаров
Переходим в следующий подкаталог и, наконец, видим наши товары. Они, конечно, распределены по страницам, но, добавив в ссылку «?SHOWALL_1=1», мы сможем посмотреть весь список товаров из этого каталога. Смотрим код элемента, и видим, что все товары так же заключены в элементе TABLE, но уже с классом catalog. Этот элемент содержит в себе блоки TD с классом item – это и есть блоки с нашими товарами. В каждом из них содержится по два блока DIV с именами img и name – они содержат изображение и имя (ссылку на товар), соответственно. Все, с этой страницы мы вытянули все, что нам было нужно.
3. Парсим страницу товара
Все, что нам осталось найти – ссылка на картинку большого разрешения и описание товара. Переходим на страницу товара, все тем же способом видим, в каком блоке находится картинка (блок DIV класса big) и описание (блок DIV класса text). Все, осталась только техническая часть.
Техническая часть
Данный сайт устроен таким образом, что все товары распределены по каталогам и основная информация с картинками располагается только на страничке товара. Структура похожа на сайт связного (возможно, они на одной платформе). В таком случае, последовательность наших действий:
- Парсим страничку каталога верхнего уровня и получаем список остальных каталогов;
- Рекурсивно парсим страницы каталогов на подкаталоги;
- Парсим подкаталоги нижнего уровня на список товаров;
- Парсим страницу каждого товара для получения информации о нем.
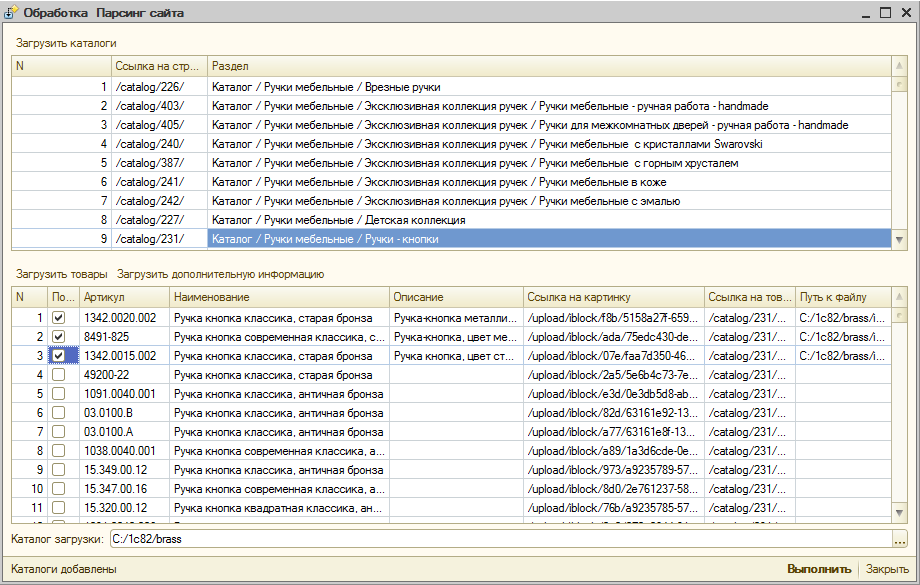
На каждом шаге нам нужно будет запоминать информацию с предыдущего, поэтому мы создадим две табличные части – одну для запоминания всех каталогов, содержащих товары, вторую – для запоминания товаров.
Создадим обработку. Добавим реквизиты:
- Сервер (будем хранить адрес нашего сайта);
- КаталогЗагрузки (путь к папке на диске, в которую будут загружаться временные файлы).
Добавим на форму табличную часть «СписокКаталогов» с реквизитами
- Раздел (для хранения имени каталога);
- СсылкаНаСтраницу (для хранения ссылки на каталог).
Будем грузить артикул, наименование, описание и большую картинку.
Добавим на форму табличную часть «Товары» с реквизитами:
- Артикул;
- Наименование;
- Описание;
- СсылкаНаКартинку (будем хранить ссылку на маленькую картинку);
- СсылкаНаТовар (будем хранить ссылку на страницу товара);
- ПутьКФайлу (будем хранить путь к картинке, которую загрузили на диск).
Все реквизиты должны быть типа строка неограниченной длины. Можно добавить реквизит-пометку для обозначения тех строк, которые нам нужно будет загрузить.
Собственно, реквизитов нам больше не нужно, приступим к написанию кода.
Первым делом грузим и парсим страницу основного каталога – brass.ru/catalog/.
При открытии формы нам следует запомнить сервер, с которого будем загружать страницы – www.brass.ru (адрес должен выглядеть именно так), каталог на диске. Так же откроем соединение с сервером.
Перем Соединение;
Процедура ПередОткрытием(Отказ, СтандартнаяОбработка)
Сервер = "www.brass.ru";
КаталогЗагрузки = "C:/1c82/brass";
Соединение = Новый HTTPСоединение(Сервер);
КонецПроцедуры
Так же нам обязательно нужно создать в этом каталоге еще три других, в них будут загружаться временные файлы:
- "/catalog/"
- "/temp/"
- "/img/"
Что бы понять, что будет происходить далее, нужно обязательно при запуске кода смотреть, что из себя прадставляют полученные нами структуры (табличцы значений) ДокументХТМЛ, ЭлементыTABLE, ЭлементыTD и прочие подобные - сразу все встанет на свои места.
Обозначим процедуру (сразу с параметрами, т.к. она будет рекурсивно парсить все каталоги).
Процедура ПропарситьКаталог(Каталог = "", Раздел = "")
ЧтениеХТМЛ = Новый ЧтениеHTML;
ПостроительДОМ = Новый ПостроительDOM;
//Генерируем имя файла на диске, в который запишется страница сайта
ИмяФайла = КаталогЗагрузки + "/catalog/" + СтрЗаменить(Каталог, "/", "_") + ".html";
//Загружаем нужную нам страницу в каталог
Соединение.Получить(Каталог, ИмяФайла);
//Начинаем чтение нашего файла
ЧтениеХТМЛ.ОткрытьФайл(ИмяФайла, "UTF-8");
//Загружаем всю структуру документа в DOM
ДокументХТМЛ = ПостроительДОМ.Прочитать(ЧтениеХТМЛ);
//Получаем все элементы TABLE
ЭлементыTABLE = ДокументХТМЛ.ПолучитьЭлементыПоИмени("TABLE");
//Находим в них нужный нам блок, содержащий ссылки на подкаталоги
Для Каждого ЭлементTABLE из ЭлементыTABLE Цикл
ОбработкаПрерыванияПользователя();
Если ЭлементTABLE.ИмяКласса = "navCatalog" Тогда
//Нашли, собираем из него все ссылки (элементы А)
ЭлементыA = ЭлементTABLE.ПолучитьЭлементыПоИмени("A");
Если ЭлементыA.Количество() > 0 Тогда
//Начинаем парсить каждую найденную ссылку как каталог этой же процедурой рекурсивно
Для Каждого ЭлементA из ЭлементыA Цикл
ПропарситьКаталог(ЭлементA.Гиперссылка, Раздел + " / " + ЭлементA.ТекстовоеСодержимое);
КонецЦикла;
Иначе
//Если ссылок не найдено, значит подкаталогов нет и это конечный подкаталог
//Добавляем его в нашу табличную часть
НоваяСтрока = СписокКаталогов.Добавить();
НоваяСтрока.Раздел = Раздел;
НоваяСтрока.СсылкаНаСтраницу = Каталог;
КонецЕсли;
КонецЕсли;
КонецЦикла;
КонецПроцедуры
Лепим на форму кнопку - при ее нажатии у нас загрузятся все каталоги и заполнится табличная часть каталогов, в событие при нажатии вставляем следующее:
ПропарситьКаталог("/catalog/", "Каталог");
Поздарвляю, теперь наша обработка может распарсить все каталоги сайта и загрузить их в табличную часть. Нужно нам это для того, что бы при выборе каждого каталога мы могли бы загрузить его содержимое.
Далее создадим кнопку для загрузки товаров в соответствующую табличную часть и пропишем ей следующий код:
Товары.Очистить();
ЧтениеХТМЛ = Новый ЧтениеHTML();
ПостроительДОМ = Новый ПостроительDOM;
//Добавляем к адресу ссылки обозначение, которое позволит нам получить полный список товаров выбранного каталога, а не постранично
АдресСайта = ЭлементыФормы.СписокКаталогов.ТекущиеДанные.СсылкаНаСтраницу + "?SHOWALL_1=1";
//Загружаем страницу с товарами
Соединение.Получить(АдресСайта, КаталогЗагрузки + "/site.html");
//Начинаем чтение нашего файла
ЧтениеХТМЛ.ОткрытьФайл(КаталогЗагрузки + "/site.html", "UTF-8");
//Загружаем всю структуру документа в DOM
ДокументХТМЛ = ПостроительДОМ.Прочитать(ЧтениеХТМЛ);
//Получаем все элементы TABLE
ЭлементыTABLE = ДокументХТМЛ.ПолучитьЭлементыПоИмени("TABLE");
Для Каждого ЭлементTABLE из ЭлементыTABLE Цикл
//Находим блок, содержащий все товары
Если ЭлементTABLE.ИмяКласса = "catalog" Тогда
//Теперь получаем все блоки TD, входящие в блок TABLE класса catalog
ЭлементыTD = ЭлементTABLE.ПолучитьЭлементыПоИмени("TD");
Для Каждого ЭлементTD из ЭлементыTD Цикл
//Находим блок каждого товара
Если ЭлементTD.ИмяКласса = "item" Тогда
//Теперь получаем все блоки DIV, входящие в блок TD класса item
ЭлементыDIV = ЭлементTD.ПолучитьЭлементыПоИмени("DIV");
//Мы знаем, что в каждом таком блоке лежат еще два блока с картинкой и ссылкой на страницу товара
Если ЭлементыDIV.Количество() = 2 тогда
НоваяСтрока = Товары.Добавить();
//Добавили новую строку в табличную часть товары, переходим к её заполнению
Для Каждого ЭлементDIV из ЭлементыDIV Цикл
//Нашли блок с картинкой маленького разрешения
Если ЭлементDIV.ИмяКласса = "img" Тогда
//Т.к. в этом блоке есть еще один блок, а в нем еще один, то мы можем спокойно обращаться к ним через ПервыйДочерний
//Таким образом мы спускаемся вниз по дереву структуры до нужных нам данных
НоваяСтрока.СсылкаНаТовар = ЭлементDIV.ПервыйДочерний.Гиперссылка;
Если НЕ ЭлементDIV.ПервыйДочерний.ПервыйДочерний = Неопределено Тогда
НоваяСтрока.СсылкаНаКартинку = ЭлементDIV.ПервыйДочерний.ПервыйДочерний.Источник;
КонецЕсли;
КонецЕсли;
//Нашли блок с именем товара
Если ЭлементDIV.ИмяКласса = "name" Тогда
//Получаем текстовое содержимое - артикул и наименование в одной строке! Не беда.
ПолученнаяСтрока = ЭлементDIV.ТекстовоеСодержимое;
//Артикул состоит из цифр и латинских символов, разберем строку по этому принципу
Н = 1;
Пока Н 1000 Тогда
Прервать;
КонецЕсли;
Н = Н + 1;
КонецЦикла;
Артикул = Лев(ПолученнаяСтрока, Н - 1);
Если СтрДлина(Артикул) > 0 Тогда
Наименование = Прав(ПолученнаяСтрока, СтрДлина(ПолученнаяСтрока) - Н);
Иначе
Наименование = Прав(ПолученнаяСтрока, СтрДлина(ПолученнаяСтрока) - Н + 1);
КонецЕсли;
НоваяСтрока.Артикул = Артикул;
НоваяСтрока.Наименование = Наименование;
КонецЕсли;
КонецЦикла;
КонецЕсли;
КонецЕсли;
КонецЦикла;
КонецЕсли;
КонецЦикла;
Поздравляю, теперь наша обработка может загрузить все товары из выбранного в первой табличной части каталога!
Следующим шагом создаем кнопку для загрузки дополнительной информации (картинки большого разрешения и описания) путем парсинга страницы товара:
ЧтениеХТМЛ = Новый ЧтениеHTML();
ПостроительДОМ = Новый ПостроительDOM;
//Т.к. ссылки на страницы с товарами у нас уже есть в табличной части, то мы просто загружаем и парсим их страницы
Для Каждого Строка из Товары Цикл
Если Строка.Пометка Тогда
//Код аналогичен предыдущим этапам, поэтому комментарии излишни
ИмяФайла = КаталогЗагрузки + "/temp/site_" + Строка.НомерСтроки +".html";
Соединение.Получить(Строка.СсылкаНаТовар, ИмяФайла);
ЧтениеХТМЛ.ОткрытьФайл(ИмяФайла, "UTF-8");
ДокументХТМЛ = ПостроительДОМ.Прочитать(ЧтениеХТМЛ);
//Получаем все блоки DIV
ЭлементыDIV = ДокументХТМЛ.ПолучитьЭлементыПоИмени("DIV");
Для Каждого ЭлементDIV из ЭлементыDIV Цикл
//Находим интересующий нас блок с картинкой большого разрешения
Если ЭлементDIV.ИмяКласса = "big" Тогда
Если НЕ ЭлементDIV.ПервыйДочерний = Неопределено Тогда
Строка.СсылкаНаКартинку = ЭлементDIV.ПервыйДочерний.Источник;
КонецЕсли;
КонецЕсли;
//Находим интересующий нас блок с описанием товара
Если ЭлементDIV.ИмяКласса = "text" Тогда
//В строке содержатся лишние символы, поэтому просто обрежем их
ПолученнаяСтрока = ЭлементDIV.ТекстовоеСодержимое;
Н = 1;
Пока Н 1000 Тогда
Прервать;
КонецЕсли;
Н = Н + 1;
КонецЦикла;
Строка.Описание = Прав(ПолученнаяСтрока, СтрДлина(ПолученнаяСтрока) - Н + 1);
КонецЕсли;
КонецЦикла;
КонецЕсли;
КонецЦикла;
Отмечаем галочками несколько товаров, жмем кнопку и видим, как загружается описание и ссылка на картинку заменяется новой.
По сути, текстовые данные мы получили, задача выполнена, но осталось еще загрузка картинок - это будет бонусом и без комментариев кода. Или другой, более эффективный способ сохранения картинки от Поручика
Для этого создадим функцию для загрузки картинки, которая вернет нам путь к ней:
Функция ЗагрузитьКартинку(КаталогСохранения, СсылкаНаКартинку, ИмяКартинки)
ИмяФайлаКартинки = "";
Попытка
ИмяФайлаКартинки = КаталогСохранения + ИмяКартинки;
Request = Новый COMОбъект("WinHttp.WinHttpRequest.5.1");
Request.SetTimeouts(10000, 10000, 10000, 10000);
Header1 = "Content-Type";
Header2 = "image/jpg";
Request.Open("GET", "http://" + СсылкаНаКартинку, False);
Request.setRequestHeader(Header1, Header1);
Request.Send();
СтатусОтправки = Request.status;
Если СтатусОтправки <> 200 Тогда
Сообщить("Ошибка отправки запроса на: " + СсылкаНаКартинку);
Возврат "";
КонецЕсли;
Stream = Новый COMОбъект("ADODB.Stream");
Stream.Mode = 3;
Stream.Type = 1;
Stream.Open();
Stream.Write(Request.responseBody);
Stream.SaveToFile(ИмяФайлаКартинки, 2);
Stream.Close();
Исключение
КонецПопытки;
Возврат ИмяФайлаКартинки;
КонецФункции
+ нам нужно для всех помеченных строк записать путь к файлу в соответствующее поле. Для это можем в процедуру загрузки дополнительной информации (предыдущая) в обходе строк табличной части добавить следующую строку:
Строка.ПутьКФайлу = ЗагрузитьКартинку(КаталогЗагрузки + "/img/", Сервер + Строка.СсылкаНаКартинку, ЗаменитьСимволы(Строка.Артикул) + ".jpg");
Имена картинок формируются из артикулов, а артикулы могут содержать неприемлимые знаки, избавимся от них функцией ЗаменитьСимволы, которая у нас использована в предыдущем отрывке кода:
Функция ЗаменитьСимволы(мСтрока)
Строка = СтрЗаменить(мСтрока, "", "");
Н = 1;
ДС = СтрДлина(Строка) - 1;
Пока Н 90) И (КодСимвола(Строка, Н) < 48 ИЛИ КодСимвола(Строка, Н) > 57) И (КодСимвола(Строка, Н) < 97 ИЛИ КодСимвола(Строка, Н) > 122) Тогда
Строка = СтрЗаменить(Строка, Сред(Строка, Н, 1), "-");
КонецЕсли;
Н = Н + 1;
КонецЦикла;
Возврат Строка;
КонецФункции
Алилуя! У нас есть артикул, наименование, описание и картинка в большом разрешении! Осталось только перенести эти данные в номенклатуру, но если вы дошли до этого момента, то, надеюсь, вы это сможете сделать сами.
В заключение лишь скажу, что есть и другие способы парсинга сайта, но этот для меня показался простейшим и эффективным. Здесь достаточно знать структуру сайта и менять лишь алгоритм перебора данных ПостроителяDOM.
Спасибо за внимание!
Вступайте в нашу телеграмм-группу Инфостарт