Функция ХэшБыстрый2(СтрокаХэш, Знач Основание = 31, Знач TABLE_SIZE = 18446744073709551616) Экспорт
Хэш = 0;ДлинаСтроки=СтрДлина(СтрокаХэш);
КоличествоПовторенийВРазвёртке = 60;Основание2=Основание*Основание;Основание3=Основание2*Основание;Основание4=Основание3*Основание;
Для Сч = 0 по Цел(ДлинаСтроки/КоличествоПовторенийВРазвёртке)-1 Цикл
//1С неэффективно работает с длинными строками, поэтому сначала откусываем кусочек
//складывать начинаем с меньших чисел, т.к. арифметика больших затратнее
ТекСтрока = Сред(СтрокаХэш, Сч*КоличествоПовторенийВРазвёртке+1, КоличествоПовторенийВРазвёртке);
Хэш = КодСимвола(ТекСтрока, 4) + Основание * КодСимвола(ТекСтрока, 3) + Основание2 * КодСимвола(ТекСтрока, 2) + Основание3 * КодСимвола(ТекСтрока) + Основание4 * Хэш;
Хэш = КодСимвола(ТекСтрока, 8) + Основание * КодСимвола(ТекСтрока, 7) + Основание2 * КодСимвола(ТекСтрока, 6) + Основание3 * КодСимвола(ТекСтрока, 5) + Основание4 * Хэш;
Хэш = КодСимвола(ТекСтрока, 12) + Основание * КодСимвола(ТекСтрока, 11) + Основание2 * КодСимвола(ТекСтрока, 10) + Основание3 * КодСимвола(ТекСтрока, 9) + Основание4 * Хэш;
Хэш = КодСимвола(ТекСтрока, 16) + Основание * КодСимвола(ТекСтрока, 15) + Основание2 * КодСимвола(ТекСтрока, 14) + Основание3 * КодСимвола(ТекСтрока, 13) + Основание4 * Хэш;
Хэш = КодСимвола(ТекСтрока, 20) + Основание * КодСимвола(ТекСтрока, 19) + Основание2 * КодСимвола(ТекСтрока, 18) + Основание3 * КодСимвола(ТекСтрока, 17) + Основание4 * (Хэш % TABLE_SIZE);
Хэш = КодСимвола(ТекСтрока, 24) + Основание * КодСимвола(ТекСтрока, 23) + Основание2 * КодСимвола(ТекСтрока, 22) + Основание3 * КодСимвола(ТекСтрока, 21) + Основание4 * Хэш;
Хэш = КодСимвола(ТекСтрока, 28) + Основание * КодСимвола(ТекСтрока, 27) + Основание2 * КодСимвола(ТекСтрока, 26) + Основание3 * КодСимвола(ТекСтрока, 25) + Основание4 * Хэш;
Хэш = КодСимвола(ТекСтрока, 32) + Основание * КодСимвола(ТекСтрока, 31) + Основание2 * КодСимвола(ТекСтрока, 30) + Основание3 * КодСимвола(ТекСтрока, 29) + Основание4 * Хэш;
Хэш = КодСимвола(ТекСтрока, 36) + Основание * КодСимвола(ТекСтрока, 35) + Основание2 * КодСимвола(ТекСтрока, 34) + Основание3 * КодСимвола(ТекСтрока, 33) + Основание4 * Хэш;
Хэш = КодСимвола(ТекСтрока, 40) + Основание * КодСимвола(ТекСтрока, 39) + Основание2 * КодСимвола(ТекСтрока, 38) + Основание3 * КодСимвола(ТекСтрока, 37) + Основание4 * (Хэш % TABLE_SIZE);
Хэш = КодСимвола(ТекСтрока, 44) + Основание * КодСимвола(ТекСтрока, 43) + Основание2 * КодСимвола(ТекСтрока, 42) + Основание3 * КодСимвола(ТекСтрока, 41) + Основание4 * Хэш;
Хэш = КодСимвола(ТекСтрока, 48) + Основание * КодСимвола(ТекСтрока, 47) + Основание2 * КодСимвола(ТекСтрока, 46) + Основание3 * КодСимвола(ТекСтрока, 45) + Основание4 * Хэш;
Хэш = КодСимвола(ТекСтрока, 52) + Основание * КодСимвола(ТекСтрока, 51) + Основание2 * КодСимвола(ТекСтрока, 50) + Основание3 * КодСимвола(ТекСтрока, 49) + Основание4 * Хэш;
Хэш = КодСимвола(ТекСтрока, 56) + Основание * КодСимвола(ТекСтрока, 55) + Основание2 * КодСимвола(ТекСтрока, 54) + Основание3 * КодСимвола(ТекСтрока, 53) + Основание4 * Хэш;
Хэш = КодСимвола(ТекСтрока, 60) + Основание * КодСимвола(ТекСтрока, 59) + Основание2 * КодСимвола(ТекСтрока, 58) + Основание3 * КодСимвола(ТекСтрока, 57) + Основание4 * (Хэш % TABLE_SIZE);
КонецЦикла;
Для Сч = ДлинаСтроки - ДлинаСтроки%КоличествоПовторенийВРазвёртке + 1 По ДлинаСтроки Цикл
Хэш = Основание * Хэш + КодСимвола(СтрокаХэш, Сч);
КонецЦикла;
Возврат Хэш%TABLE_SIZE;
КонецФункции
Показать

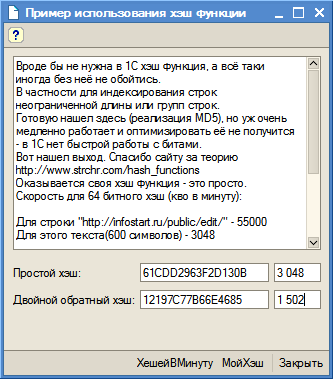{kind=link}