Почему Power BI?
В январе, когда наша компания терпела финансовые трудности, нам нужно было что-то менять. И мы решили попробовать что-то новое, чего никогда не пробовали, но про что все говорят.
Мы провели исследование, какой продукт бизнес-анализа сейчас в тренде. Оказалось, что первое место занимает Microsoft Power BI.
Когда мы его попробовали, оказалось, что работать с ним действительно комфортно, и первое время мы даже думали, что Power BI – это какой-то плагин к Excel с графиками и возможностями для анализа.
Следующим критерием выбора для нас стало то, с какими источниками данных он умеет работать.

Оказалось, что у Microsoft Power BI есть готовые коннекторы к различным форматам файлов – Excel, CSV, JSON, XML и т.д. Например, если в компании используются Excel-таблицы, то можно набросать какой-то план на следующий квартал, на следующее полугодие и т.д., и использовать эти планы в качестве источника данных.

Можно совмещать несколько различных источников. Например, мы у себя используем 5 различных баз данных от различных поставщиков, которые интегрируются между собой с помощью Power BI, чтобы находить какие-то закономерности и использовать их в целях бизнеса.

Кроме того, поскольку мы являемся партнерами Microsoft, для нас были очень важны коннекторы к облаку Azure, так как мы используем технологии этого облака, и это для нас было очень важно.

Также есть очень много других коннекторов. Например, наши маркетологи были очень нам благодарны за коннектор к Google Analytics. Представляете, мы просто взяли и построили воронку продаж напрямую с нашего сайта – это было действительно замечательно.
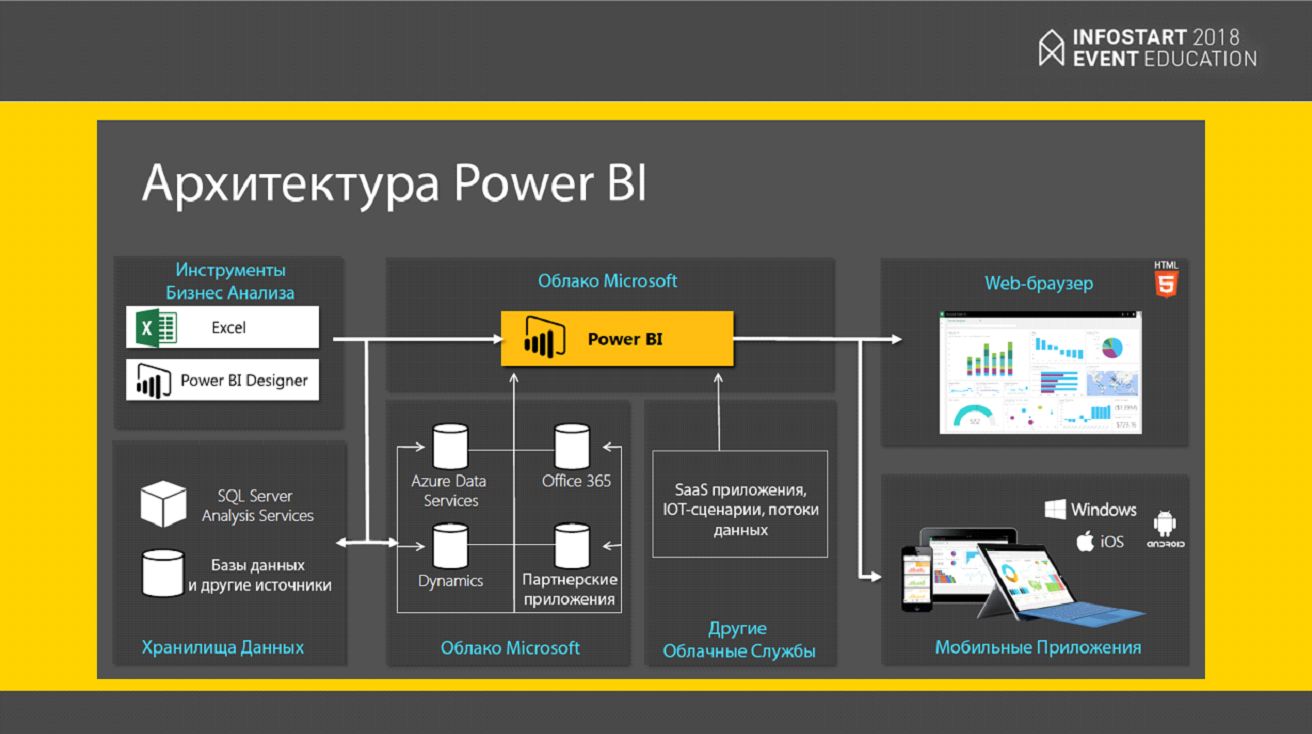
Что еще нам понравилось в Power BI – это то, что логика работы с ним похожа на логику разработки в 1С.
- У нас есть Power BI Designer – это то же самое, что конфигуратор в 1С. В нем мы набрасываем структуру данных и определяем, как будут строиться графики;
- Дальше мы запускаем на Production – все это выгружается в облако Microsoft;
- И облако Microsoft позволяет выводить эти графики на мобильных устройствах, в веб-приложениях, встраивать в ваши приложения и использовать везде, где это угодно и уместно.

Также нам очень понравилось, что есть:
- API для интеграции;
- И настройка прав доступа на уровне записей. Например, менеджер магазина может смотреть только те данные, которые ему доступны, а руководителю отдела назначаются более расширенные права. Это дает гарантию, что данные пребывают в безопасности.
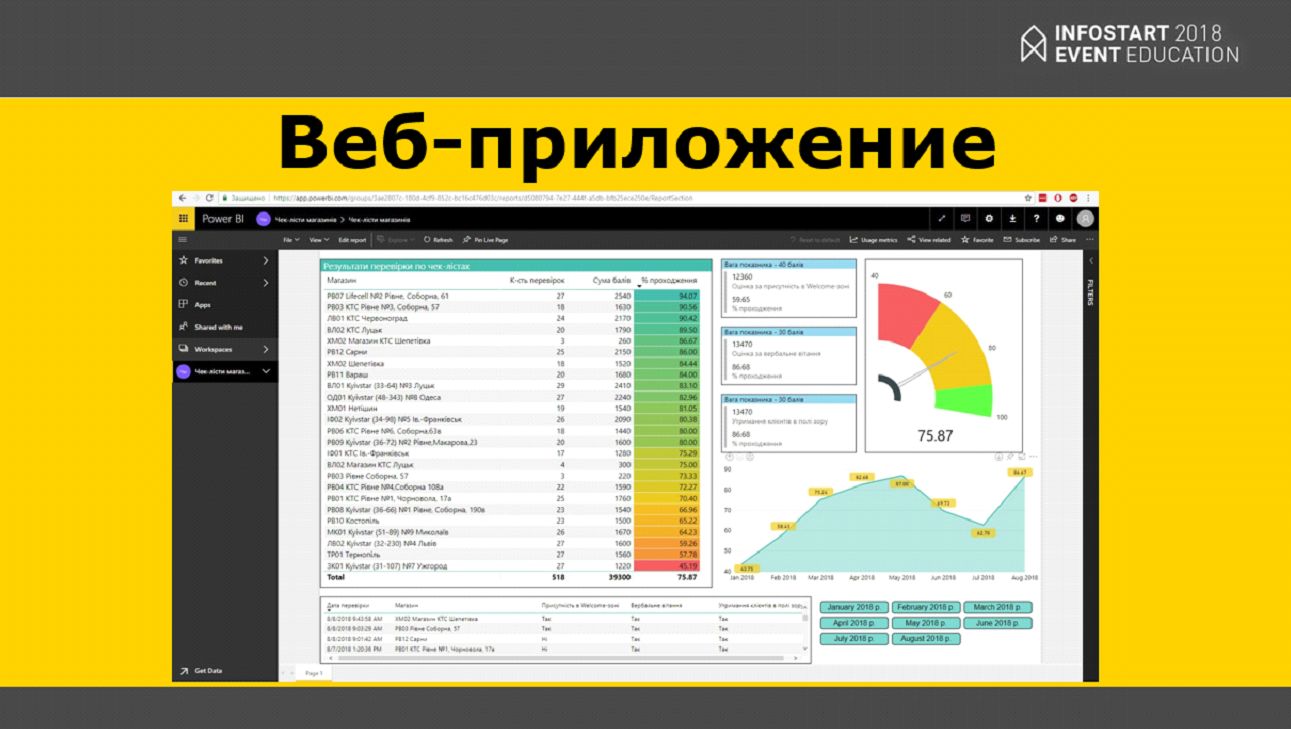
Вот так выглядит веб-приложение. Это наш отчет по качеству обслуживания в магазинах – то, над чем мы работаем.

А это – наше мобильное приложение, в таком виде мы отдаем отчеты вендорам.

А вот так выглядит отчет на носимых устройствах – наши руководители его очень любят. Если что-то пошло не так, они оперативно получают оповещения, и когда у них появляется время, могут сразу заняться проблемой.

Но Power BI, как и любая система бизнес-аналитики, без данных не стоит ничего. Эти данные нужно откуда-то брать, а так база данных 1С – это «сердце» нашей компании, то 90% данных мы берем из 1С:Предприятие.
Все знают способы получения данных из 1С – это:
- Различные выгрузки;
- REST\SOAP-сервисы;
- OData интерфейс;
- Или чтение напрямую из СУБД (чтение напрямую нарушает лицензионное соглашение)
Выгрузка из 1С:Предприятия – это плохо? События – наше все.
Однако оказалось, что стандартные способы интеграции с Power BI не всегда удобно использовать. Дело в том, что в нашей компании данных было действительно много – наша основная база данных размером чуть более 1 терабайта.
- Когда мы пытались использовать OData, у нас не получилось выгрузить данные из 1С.
- Мы пробовали различные выгрузки в файлы – данные выгружаются, но они очень быстро устаревают и становятся неактуальными, запаздывают. А данные нужны для принятия качественных решений.
В результате мы посмотрели на свой предыдущий опыт использования различных шин данных – а мы используем RabbitMQ, Elastic и прочие вещи, которые упрощают жизнь разработчиков – и подумали, почему бы в 1С не попробовать что-то похожее? И в результате мы сделали такую небольшую декомпозицию.

Что в 1С, по сути, есть событие?
- Это – создание (например, создание какого-то документа или создание записи в регистр сведений);
- Обновление данных
- И удаление данных.
Почему бы не подписаться на эти события, зарегистрировать их, а потом куда-то отправить.
Для того, чтобы это заработало, мы создали специальную базу MS SQL, назвали ее «Первоначальный образ». Выгрузили в нее данные, склеили их, и дальше, если где-то происходят изменения (например, совершилась продажа в магазине), мы фиксируем это событие и, соответственно, обновляем данные связанные с событием в «Первоначальном образе», там, где они пересекаются.

У меня есть небольшая памятка для всех начинающих разработчиков – пока транзакция не завершилась, никого оповещать нельзя.
Что имеется в виду? Если на кассе ваш клиент рассчитывается, и пропало соединение или не хватает остатка, то во время этой транзакции мы не должны никого оповещать, потому что, если мы оповестим, и транзакция откатится, в другой системе будет ошибка.
Что мы сделали? Мы фиксируем, что было какое-то событие, записываем его в справочник, и дальше, когда транзакция завершилась, это событие становится доступно для фонового потока, который подбирает его и обновляет этим событием наш «Первоначальный образ».
Что оказалось интересного? Когда мы сделали первую систему бизнес-аналитики – там было 5 дашбордов. Бизнесу это понравилось, они попросили еще 20. Но, поскольку с каждым новым дашбордом показатели производительности системы существенно снижались, мы решили не создавать сами события в подписке, а просто фиксировать какой-то минимальный набор данных, необходимый для восстановления данных целого события с помощью фонового задания.

Идею мы подхватили из 1С. Те, кто работал с внешними источниками данных и подключал какую-нибудь СУБД к конфигурации 1С, знают, что 1С разбивает каждую таблицу этой СУБД на два типа источников событий – на ссылочные и объектные. В контексте понятий конфигурации 1С:
- Ссылочные типы – это справочники, документы, планы видов характеристик;
- А объектные – это регистры сведений, регистры накопления и пр.
Мы для себя увидели, что для ссылочных типов нам, чтобы понять, что с каким-то объектом произошло какое-то событие, достаточно зафиксировать тип метаданного и его уникальную ссылку – например, справочник Номенклатура и GUID элемента этого справочника. Мы знаем, что с этим объектом что-то произошло, и это нужно как-то обработать.
А для объектных типов мы начали фиксировать фильтры, которые накладываются при записи объекта. Этого оказалось достаточно, чтобы сформировать какой-то набор данных для обновления нашего «Первоначального образа».

Дальше мы немного оптимизировали нашу систему – она работала не так быстро, как мы хотели.
Мы выяснили, что достаточно сериализовать только саму ссылку, а не весь объект в целом. И мы записывали только сериализованные данные, то есть, Справочник.Номенклатура.Ссылка, а остальное (СправочникОбъект, например) выбрасывали.
То же самое – для объектных типов. Мы сериализовали только измерения, по которым проходит запись, значение параметра замещения и тип метаданного, который изменяется (например, что это – регистр сведений «Курсы валют»).
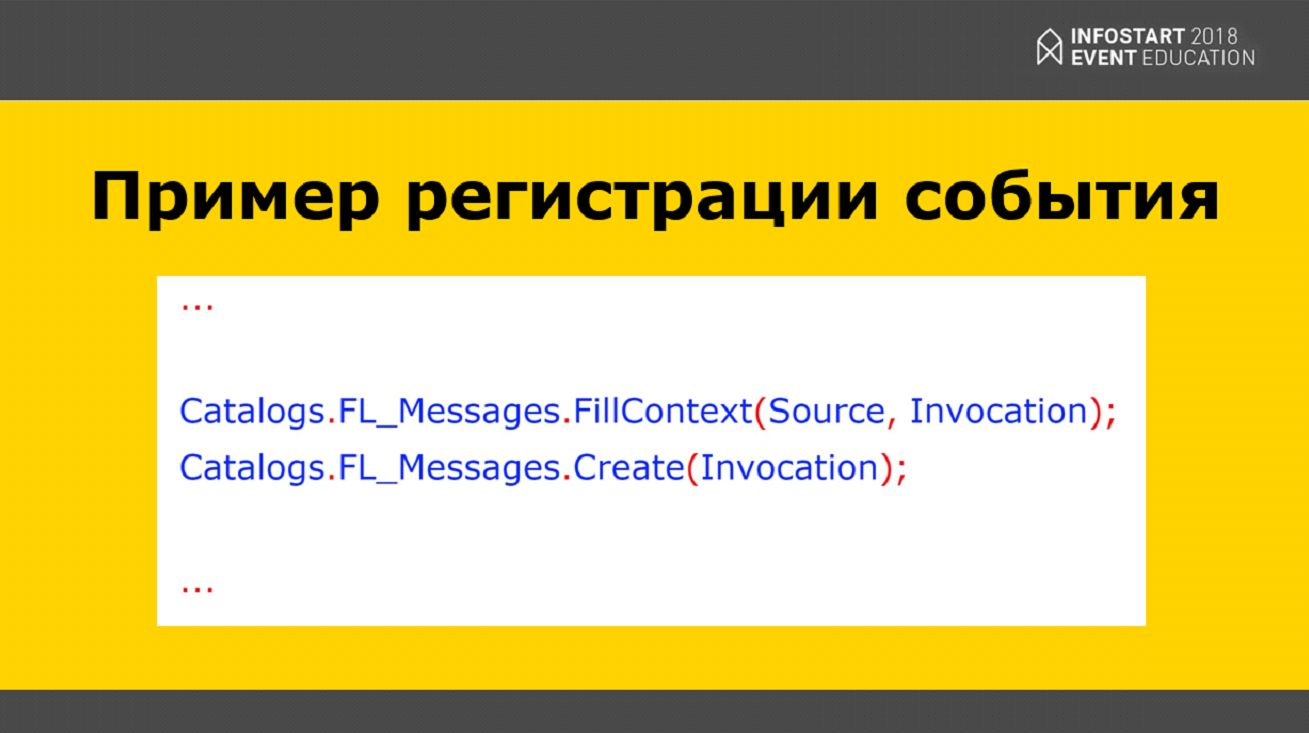
На слайде показан тривиальный пример регистрации события – это код подписки события, которая подписана на справочник. Мы передаем туда источник, из источника заполняется параметр Invocation, и дальше создается это событие. Если транзакция закончилась успешно, это событие появилось и стало доступно для обработки.
Почему на английском? Мы побоялись тестировать на боевой базе и «прогнали» это на наших клиентах в Канаде. У них это заработало, и мы уже не решились переписывать.

Данные вызова (Invocation) – это, по сути, структура, которая имеет два, даже три главных поля.
- Первое – это EventSource – строка источника, которая обозначает то, что это было (например, справочник или регистр сведений).
- Source – это ссылка или InvocationContext – таблица значений с фильтрами, которые накладываются на набор при записи в регистр сведений, регистр накопления и пр.
- И последнее поле, Routed – означает, было маршрутизировано это событие или еще нет.

Так как мы начали фиксировать только маленький кусочек необходимых данных, то поняли, что это позволяет нам решать ошибки связи.
- Например, вы наверняка сталкивались с тем, что в некоторых конфигурациях есть нетривиальные связи – допустим, документ реализации ссылается на документ возврата этого товара, а документ возврата ссылается на документ реализации. И, по сути, получается циклическая ссылка. Но мы во время обработки события можем восстановить для системы бизнес-анализа только те данные, которые считаем нужными.
- Или мы можем обогатить некоторые данные дополнительной информацией. Например, мы что-то поменяли в номенклатуре и хотим добавить к этому еще данные дополнительных сведений БСП, относящихся к этой номенклатуре. Соответственно, мы добавляем в наш «Первоначальный образ» обновление еще и этих трех таблиц.
- Более того, мы можем создавать в «Первоначальном образе» таблицы, которых в 1С вообще нет, но они помогают нам разобрать проблемы, которые накопились в самой базе данных 1С. То есть, вместо двух таблиц для документов реализации и возврата мы сделали три таблицы – «Реализация», «Возврат» и третья таблица, которая содержит между ними связь. Для систем бизнес-аналитики, таких, как MS Power BI, построить такой график или отчет очень просто – вы «в два клика», с помощью Drag&Drop переносите какую-то визуализацию, и она у вас сразу работает. Даже если вы перевыбираете какое-то значение, оно все моментально перестраивается, все адекватно показывает без какого-либо программирования.
Архитектура хранилища данных

В нашем случае мы в качестве «Первоначального образа» использовали такое понятие, как хранилище данных.
- Наш выбор пал на MS SQL;
- Потому что у нас были специалисты по MS SQL, и было понимание, как с работать с этой СУБД;
- И кроме этого, мы еще наняли специалиста по Power BI, который занимается финализацией тех данных, что появляются у нас в хранилище данных и показывает их в удобном виде.
Оказалась интересная вещь – так как у нас есть задачи разного плана, и некоторые из них в контексте 1С вообще решить нельзя, то специалист 1С приходит к специалисту MS SQL сервера и говорит: «У меня проблема, я могу тебе только так выразить», а специалист MS SQL говорит: «Без проблем, я напишу вьюшку, добавлю индексы, и все будет работать». Соответственно, сложность для специалиста 1С уменьшилась, а для специалиста MS SQL-сервера никак не изменилась, потому что он это делать умеет и только этим и занимается.
То же самое, специалист Power BI может перетянуть некоторые моменты на свою сторону и сделать то же самое для специалиста MS SQL-сервера и для специалиста 1С.
Эти три человека могут решить проблему сообща и без ругани – вот такая у нас получилась кроссфункциональная команда.
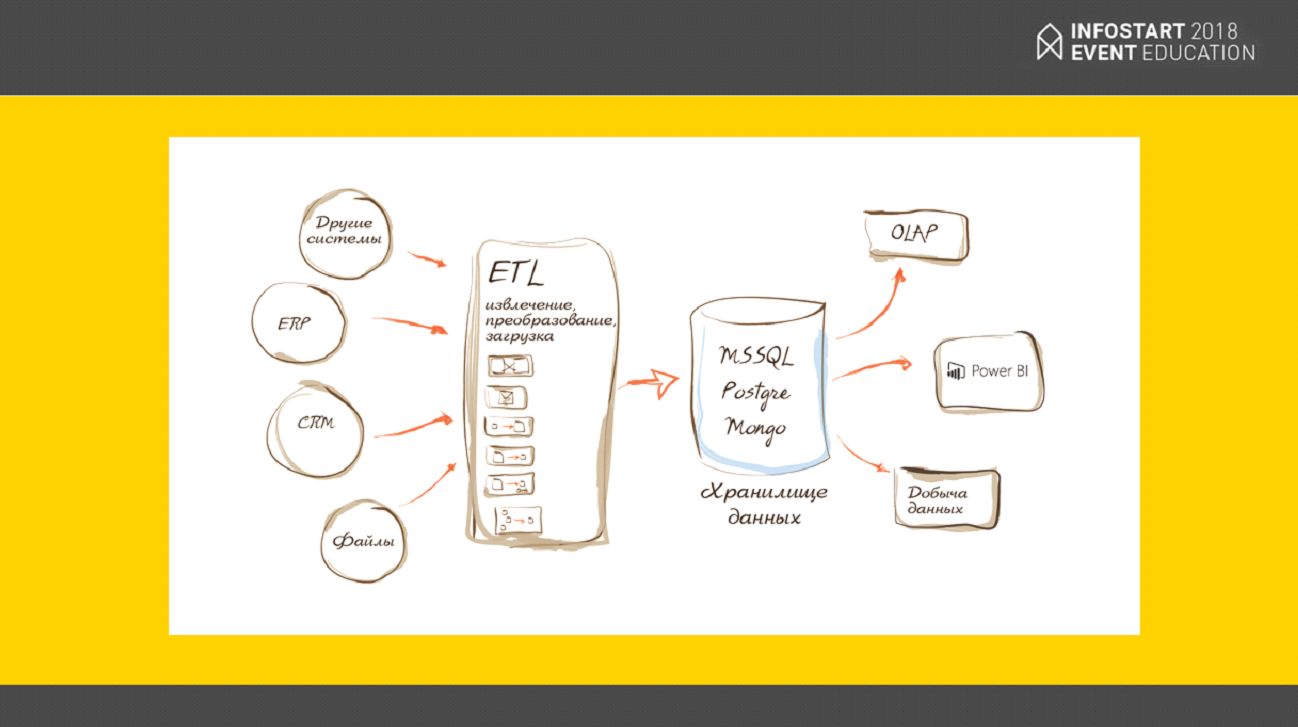
Здесь показана примерная архитектура того, как работает хранилище данных.
- Происходят какие-то события;
- Когда они зафиксируются, происходит трансформация этих событий уже в конечные данные;
- Эти конечные данные заливаются в нашем случае в MS SQL сервер;
- И к этому источнику данных подключается уже Power BI или другие системы обработки данных.
Возникает вопрос – как гарантировать целостность хранилища данных, что там все правильно? Не проверять же постоянно – выполнять какие-то запросы и смотреть, все ли мы туда выгрузили или нет, совпадает ли результат запроса с ожиданиями?
Первичные и внешние ключи. Связываем одну таблицу хранилища данных со множеством объектов конфигурации 1С

Мы начали использовать в хранилище данных первичные и внешние ключи – для каждой таблицы выбирали первичный ключ.
- Например, для ссылочных типов первичным ключом будет поле «Ссылка»;
- Для объектных типов – комбинированный ключ, причем, это не обязательно должно быть измерение.
Мы полностью изменяли таблицы в хранилище данных и делали их супер-удобными для аналитики. Это позволило нам четко понимать, что все данные у нас в хранилище данных валидные, ничего нигде не потерялось, нет битых ссылок и т.д.
В процессе внедрения мы осознали, что очень много лет в 1С что-то делали не так и начали очень серьезно над этим работать – подтянули качество кода, качество бизнес-процессов и т.д.
Реализация агрегатных типов
В 1С есть такая вещь, как составные типы. А в MS SQL Server изначально нет поддержки составных типов. Можно было пойти по пути 1С, как они реализовали составные типы. Но мы посчитали, что в контексте хранилища данных это неправильно, и нужно воспользоваться какими-то другими существующими практиками. Я вам их сейчас продемонстрирую.

Мы создали специальную таблицу, где выразили все ссылочные типы, которые у нас есть (такие, как Справочник.Номенклатура, Документ.РеализацияТоваровУслуг и т.д.).
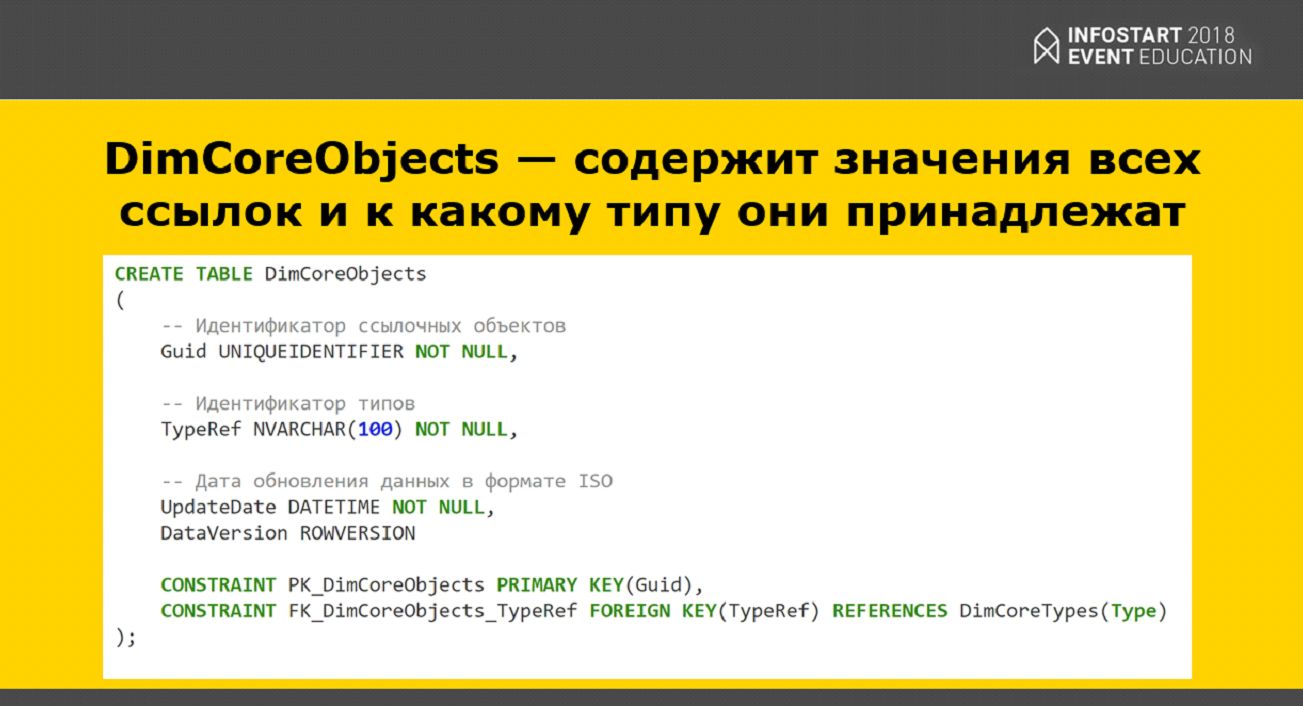
Также мы создали отдельную таблицу, куда добавили все ссылки, которые есть в конфигурации, с пометкой типа – все элементы всех справочников, ПВХ, планов счетов.
И, соответственно, когда мы в какой-нибудь таблице ссылались на составной тип, мы просто подставляли туда ссылку из этой отдельной таблицы. Это очень хорошее решение для Power BI, потому что Power BI использует СУБД VerticaDB. Она очень любит гигантские таблицы с небольшим количеством колонок. Про это нужно помнить.
Как максимально точно обновлять данные в хранилище – учимся делать MERGE

Соответственно, с хранилищем данных у нас те же самые операции, что и в 1С:
- Вставка;
- Обновление;
- Удаление.
Но мы подумали – так как мы восстанавливаем событие, и нам на этом этапе не важно, что это было – удаление, создание или обновление данных, мы просто всегда фиксируем, что с этой ссылкой что-то произошло. Соответственно, нам нужно просто выполнить какую-то схему запроса и отправить эту ссылку плюс результат выполнения схемы запроса в хранилище данных, чтобы они там как-то обработалось.
Если бы мы использовали вставку, обновление, удаление – система была бы очень сложной, и уследить за порядком выполнения команд было бы очень дорого (восстановление последовательности сообщений).

Но в MS SQL Server есть операция MERGE – слияние.
Основная задача – это взять две таблицы и синхронизировать их, чтобы их содержимое стало одинаковым.

Как работает Merge? Например, есть таблица АктивыПассивы. У нее есть первичный ключ (Primary Key), состоящий из полей:
- ObjectRef – это регистратор;
- И LineNum – номер строки этого регистратора.

Чтобы заработал Merge, нужны две таблицы.
Соответственно, те данные, которые приходят в 1С, мы сначала должны куда-то поместить, поэтому мы создаем в tempdb временную таблицу, вставляем туда эти данные и дальше с помощью операции Merge эти данные сливаем.

Сама операция слияния делится на такие блоки:
- Сначала мы пишем Merge для таблицы, куда мы хотим поместить эти данные;
- Указываем таблицу-источник;
- Указываем правила сравнения;
- И дальше, в зависимости от выполнения условий слияния что-то делаем:
- Когда строки совпадают, мы обновляем эти записи;
- Когда условия не совпадают (во временной таблице есть какие-то новые записи) они просто добавляются;
- Все, что не совпало – мы удаляем.

Соответственно, есть нюансы – если у нас в первоначальном образе было 100 миллионов записей, то после слияния с таблицей, указанной на слайде, у нас их станет всего четыре.
От автора: операция MERGE выглядит как будто она позаботится о параллелизме для вас, это кажется одним атомарным утверждением. Однако под прикрытием MS SQL Server действительно выполняет различные операции независимо. Это означает, что вы можете столкнуться с состояниями состязания или конфликтами первичных ключей, когда несколько потоков пытаются запустить один и тот же оператор MERGE одновременно. Несколько лет назад Dan Guzman подробно рассказал об этом в своем блоге, но в основном это означает, что, если вы не используете HOLDLOCK для операции MERGE, ваше запрос уязвим для условий гонки. Шаблон должен быть такого вида:
MERGE [FactOtherActivesPassives] WITH (HOLDLOCK) AS [TARGET]
Оптимизация MERGE с помощью Common Table Expression (CTE)

Чтобы обойти этот нюанс, есть такая вещь, которая называется Common Table Expression (общее табличное выражение). Оно позволяет отметить только те ссылки, которые действительно необходимо обновить в хранилище данных. И, соответственно, операция Merge будет работать уже только с этими ссылками, и мы обновим только те данные, которые нам нужны.
Но здесь тоже есть небольшой нюанс.
Там, где у нас есть SELECT T2.* FROM <временная таблица>, есть две строчки сравнения. Мы пришли к пониманию того, что в каждой таблице всегда есть какой-то мастер-ключ. То есть, если у вас в таблице Primary key состоит из двух колонок, то все равно одна колонка всегда будет главной. Это, например, если Primary key – это регистратор и номер строки, то главная колонка – это регистратор.

Что мы здесь решаем? Если у нас возникает необходимость обновить некоторые данные, и в первоначальном образе есть строки с большим номером, чем во временной таблице, то у нас останутся фантомные строки, которых, по сути, не должно быть. Поэтому мы выбираем все строки по какому-то мастер-ключу (без LineNum), и дальше уже отрабатывает операция Merge и удаляет все лишнее.
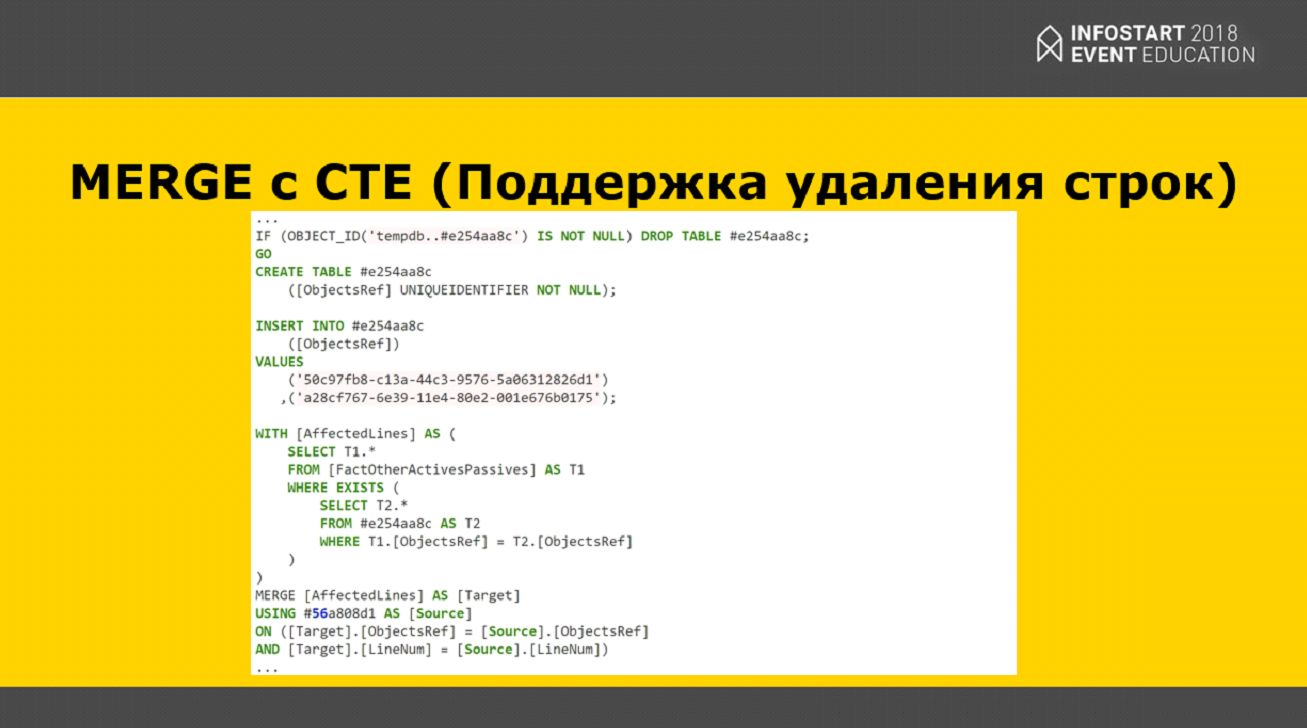
Есть еще поддержка удаления строк – это когда, например, мы в 1С что-то удалили, то при выполнении этого CTE-запроса он ничего не возвращает, и у нас остаются фантомные строки.
В этом случае мы решили поступать следующим образом – так как при записи события в 1С мы эти данные сериализуем, то создается еще одна небольшая табличка с мастер-ключами, подтягивающая все записи из основной таблицы, чтобы все эти записи точно были обновлены, и все у нас действительно стало хорошо.

По сути, полная реализация Merge – это:
- Создание временной таблицы приемника («Таблица1»);
- Вставка записи в «Таблицу1»;
- Создание временной таблицы «Таблица2» с первичными ключами (мастер-ключами);
- Вставка значений первичных ключей в «Таблицу2»;
- Common Table Expression для «Таблицы2»;
- Описание операции MERGE;
- И удаление временных таблиц.
Все-таки, полный онлайн возможен?
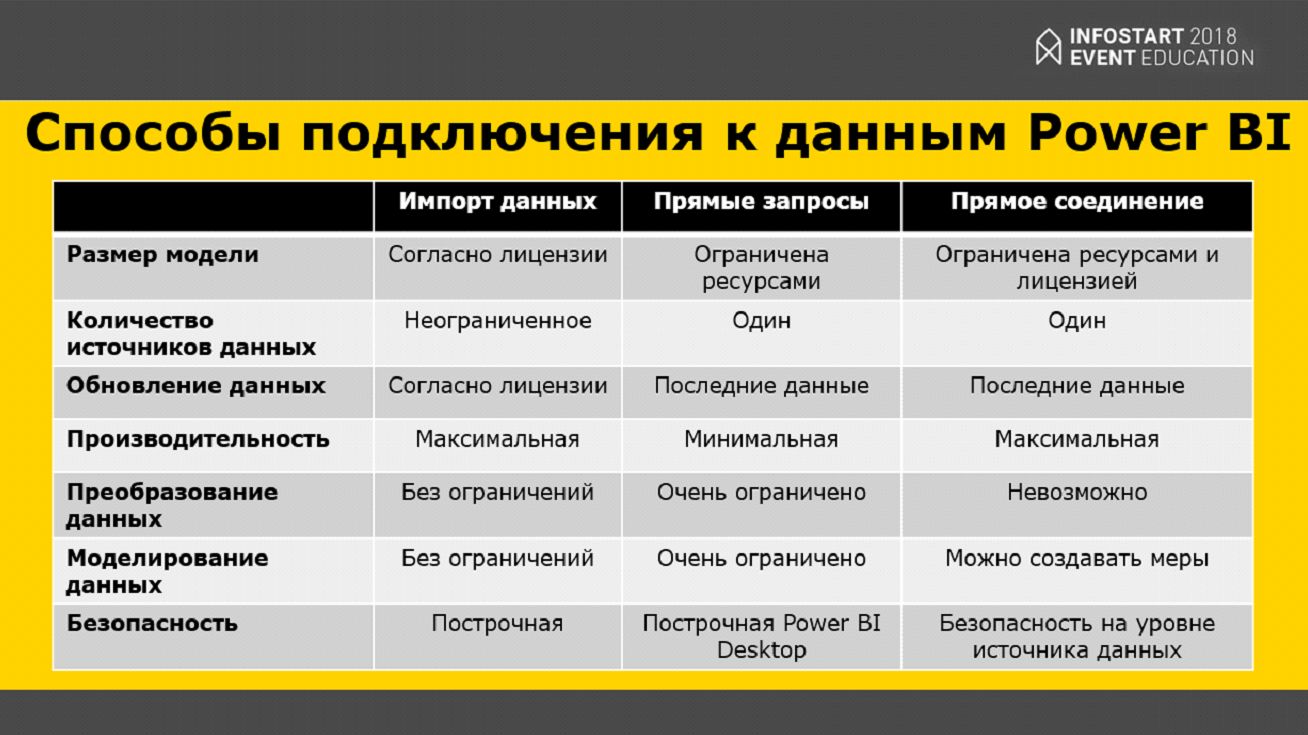
Когда я первый раз рассказывал про нашу систему бизнес-анализа, у меня спросили – возможен ли полный онлайн (если в базе 1С что-то произошло, чтобы это сразу отображалось где-то в мобильном приложении и т.д.). Power BI предоставляет следующие способы подключения к данным:
- Самый простой способ подключения к данным – это импорт данных. Вы указываете ваше хранилище данных, загружаете все данные и с ними работаете. Если работать на базовой лицензии, это можно делать 8 раз в день.
- Есть такая вещь, как прямые запросы. Что это такое? Вы заходите в какое-то мобильное приложение, нажимаете «Обновить», и облако Microsoft подключается к Power BI Gateway где-то в вашей сети. Power BI GateWay подключается к базе данных, выполняет этот запрос и возвращает уже результат на ваше мобильное приложение.
- И есть еще прямое соединение – когда что-то произошло в базе данных, оно сразу летит в облако Microsoft. Получается, по сути, в вашем хранилище сидит какой-то «демон» и, когда что-то происходит, передает данные в ваше облако, чтобы вы могли все это оперативно проконтролировать.
Результаты внедрения
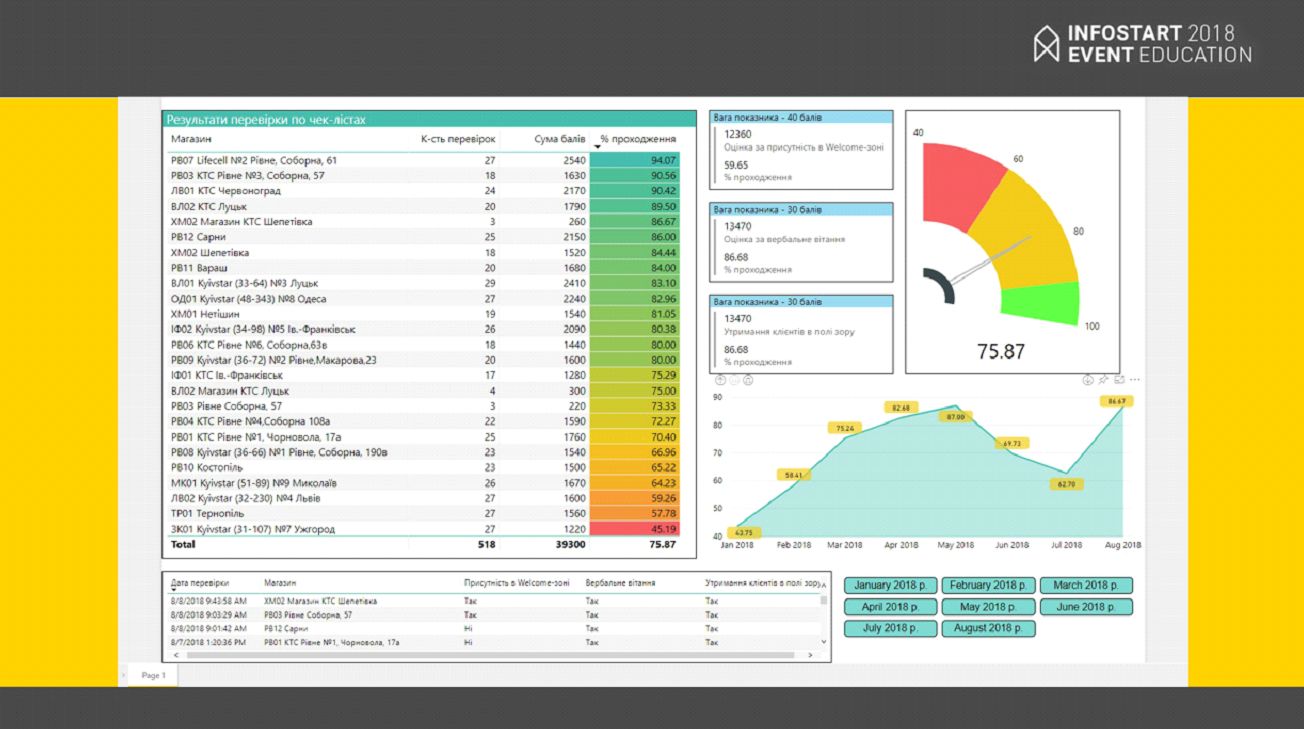
Мы внедрили контроль нашей розницы и измерение эффективности поведения наших продавцов. Результаты показали, что все у нас плохо. Мы начали меняться, вводить контроли, измерение температуры, установку датчиков, контроль разговоров, запись и анализ разговоров по телефону. Это все в автоматическом режиме начали собирать в Power BI, и это дало несравнимый эффект.

В результате, после 7 месяцев мы увеличили чистую прибыль с 0.4 % с оборота до 3 % с оборота. Закрыли 2 самых больших, самых крутых магазина, на которые тратились колоссальные деньги. Персонал за 7 месяцев у нас сменился на 55% – уволили 500 человек.
Я уже говорил, что система бизнес-аналитики – вещь опасная, поэтому, если руководители готовы, они должны понимать, что такое может быть.
Заключение
Изначально аналитику данных мы пытались запустить еще в 2015 году. Тогда это выглядело так –наш владелец бизнеса посетил гигантскую корпорацию, где работает 80 тысяч человек, и после возвращения сказал, что нам везде нужны телевизоры, чтобы показывать на них результаты работы компании за период. Мы повесили ему телевизор, вывели на него три небольших отчета, но никакой маркетинговой составляющей при этом тогда еще не анализировали. И, хотя владелец был доволен, никакого результата это не дало.
А в 2018 году мы подошли более комплексно – пообщались с математиками, взяли в команду человека, который занимается статистикой и понимает в математике на уровне доцента, и поняли, что просто вывести в отчет какую-то информацию недостаточно, это вообще никак не поможет. Мы начали комбинировать данные, ставить планы, искать закономерности, прогнозировать наши результаты, накладывать по нашим сегментам продаж мировую, внутриукраинскую динамику и т.д. Мы начали четко понимать, что этот закупщик недорабатывает, а этот, наоборот, намного поднял нам продажи. Мы поменяли систему мотивации, хотя людям, которые привыкли 5 лет ничего не делать, было очень сложно понять, что от них хотят. Зато стало очень четко понятно, что нужно бизнесу, чтобы получить результат.
Мой совет тем, кто собирается внедрять Power BI – это не такой проект, который можно запустить за месяц. В среднем, это – проект на год, комплексная задача, которая связана не только с 1С: это работа с Google-аналитикой, с планами, с датчиками, со сбором информации, с анализом телефонных разговоров, работа с телефонией. Это очень тяжело, и тот, кто думает, что можно взять одного человека, чтобы разобраться – так не получится. У нас, когда мы начинали, в проекте было занято 10 человек. Сейчас мы уже доделываем финансовый блок, и на поддержке у нас осталось 2 человека – руководитель и аналитик. А к Новому году мы планируем закончить этот проект.
От автора: фиксация событий выполняется с помощью подсистемы FoxyLink, с которой можно ознакомиться на github и по моим видео в YouTube.
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2018 EDUCATION.