.gif")
.gif")







Зачем мы здесь
Процессорные ресурсы и то, как работает с ними операционная система - тема на самом деле не простая. Бывают тривиальные ситуации, когда можно явно установить причины высокой нагрузки на CPU и их быстро исправить. С другой стороны, бывают и сложные случаи. Особенно, если в дело вмешивается виртуализация, проблемы оборудования или драйверов, ошибки в программном коде приложений или даже ядре системы.
Нет, мы не будем рассматривать все возможные проблемы и способы их диагностики в одной публикации. Вместо этого мы начнем с простейшей истории проблем производительности с мощностями CPU. Заодно пройдем по всем доступным счетчикам производительности Windows, которые позволяют  диагностировать работу процессорной подсистемы. Большая часть рассмотренных ниже показателей производительности актуальны и для *.nix-систем.
диагностировать работу процессорной подсистемы. Большая часть рассмотренных ниже показателей производительности актуальны и для *.nix-систем.
И так, начнем с минимального объема теории.
Не хочу читать
А читать придется, но не много. Рассмотрим основные показатели производительности, которые можно использовать для диагностики работы в части ЦП. Их не много, чуть больше десяти.
Это не полный список, но в большинстве случаев достаточно и этого набора показателей. На постоянной основе есть смысл собирать:
- % загруженности процессора
- % работы в пользовательском режиме
- % работы в привилегированном режиме
- Процент времени бездействия
- % времени прерываний
- Длина очереди процессора
- Контекстных переключений/с
Все остальные - по ситуации.
Теперь можно посмотреть на практике как эти показатели себя ведут в тех или иных ситуациях.
Исходная задача
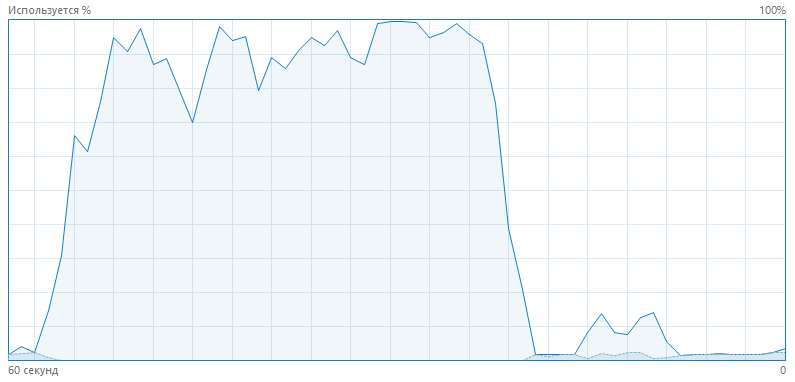
Поставим простую задачу, чтобы было интересней разбираться с перечисленными показателями. Нужно разобраться почему тормозит некоторый сервер, на котором установлен сервер 1С и периодически возникают пиковые нагрузки CPU до 100%. Из основных характеристик сервера - 8 ядер, частота 3.6 GHz, 16 ГБ RAM. Ничего сверхъестественного. Вот так эта нагрузка выглядит в диспетчере задач.
 На самом деле найти причину достаточно просто, но мы пойдем сложным путем, пройдя через все счетчики производительности. И так, поехали!
На самом деле найти причину достаточно просто, но мы пойдем сложным путем, пройдя через все счетчики производительности. И так, поехали!
Базовые показатели
В первую очередь посмотрим на три базовых показатели нагрузки на CPU:
- % загруженности процессора
- % работы в пользовательском режиме
- % работы в привилегированном режиме
Вот так появление этой нагрузки выглядит в системном мониторе (он же perfmon).
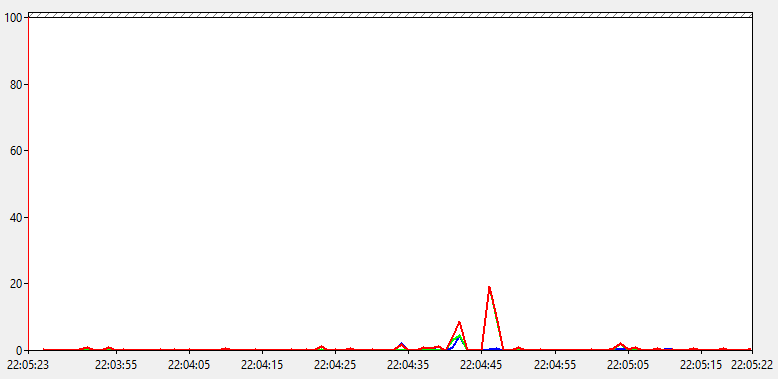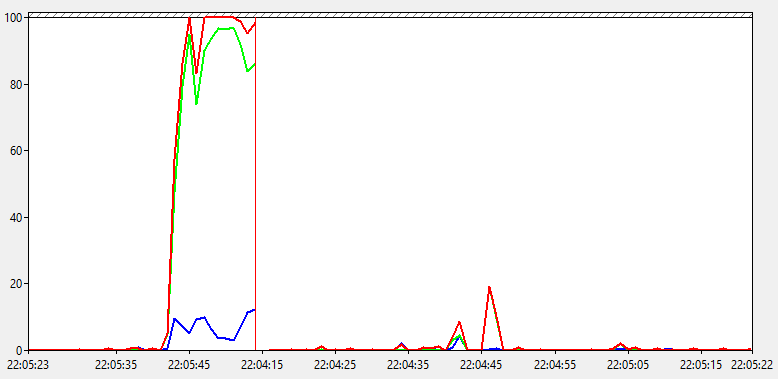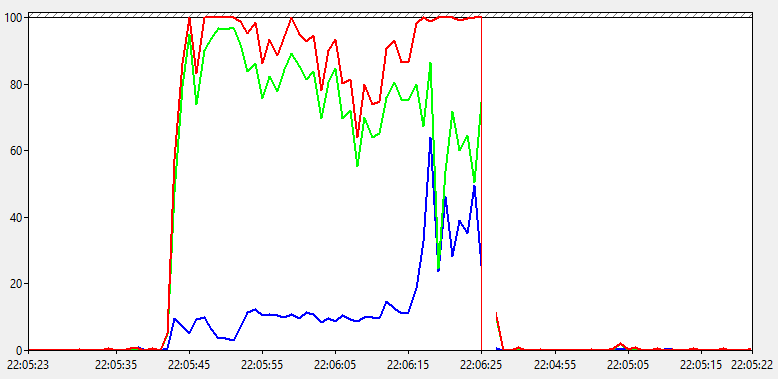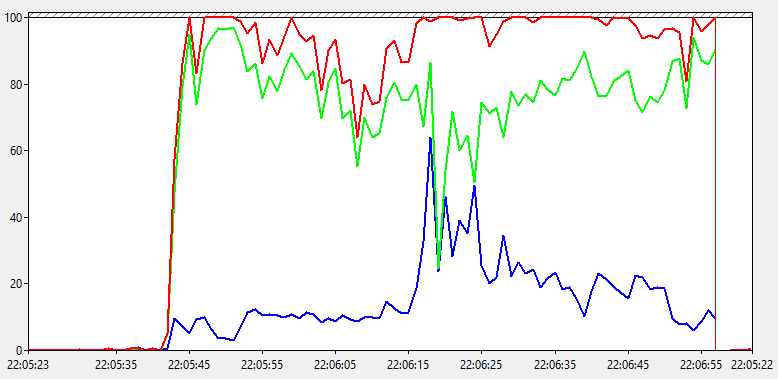 Как мы видим, общий % загруженности процессора доходит до 100 на продолжительное время. При этом % работы в привилегированном режиме держится выше 10%, а иногда доходит и до 60%! Явно что-то не так, но что?
Как мы видим, общий % загруженности процессора доходит до 100 на продолжительное время. При этом % работы в привилегированном режиме держится выше 10%, а иногда доходит и до 60%! Явно что-то не так, но что?
Копнем глубже
Дополнительно посмотрим на другие показатели:
- % времени прерываний
- % времени DPC
- Процент времени бездействия
На графике это будет выглядеть так.
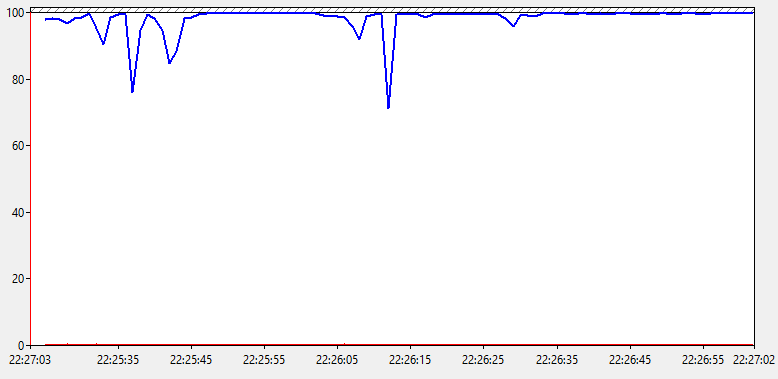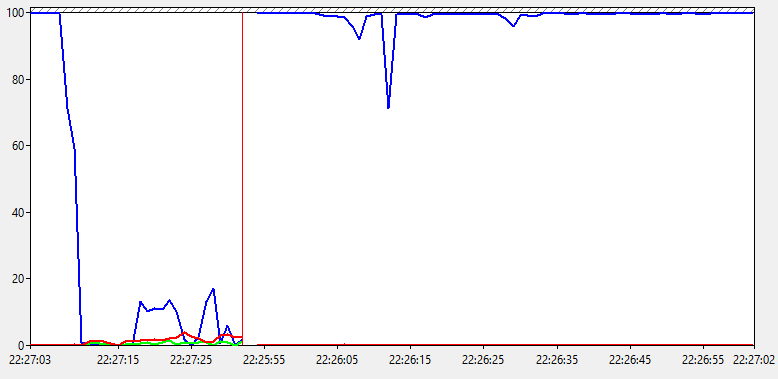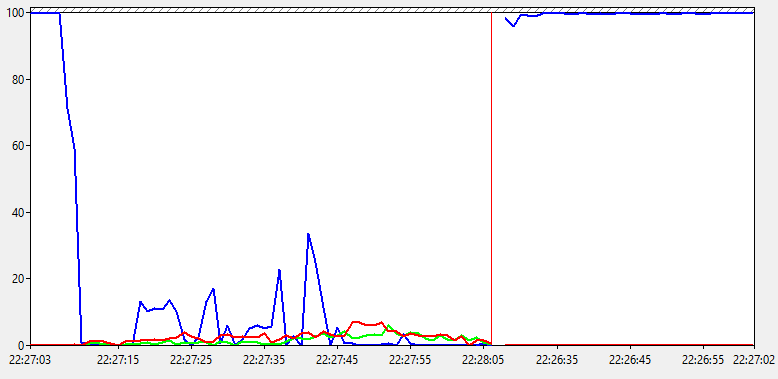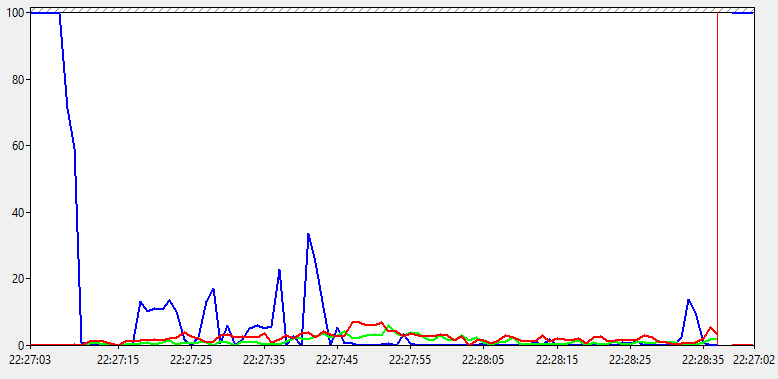 Ничего особенного здесь не видим. Процент времени бездействия упал до 0, что соответствует общей нагрузке под 100%, которую мы видели на предыдущем графике. Показатели % времени DPC и % времени прерываний находятся на минимальном уровне. Значит явных проблем с драйверами, железом или ПО нету. И мы все еще ничего не узнали, пойдем дальше.
Ничего особенного здесь не видим. Процент времени бездействия упал до 0, что соответствует общей нагрузке под 100%, которую мы видели на предыдущем графике. Показатели % времени DPC и % времени прерываний находятся на минимальном уровне. Значит явных проблем с драйверами, железом или ПО нету. И мы все еще ничего не узнали, пойдем дальше.
Какое состояние
Проверим состояния процессора в части энергосбережения. Может быть дело в этом? (что вряд ли, но взглянем для интереса):
- % времени C1, % времени C2, % времени C3
- C1-переходов/сек, C2-переходов/сек, C3-переходов/сек
Количество переключений в секунду отображены пунктиром, а проценты сплошной линией. Вот такой получился график.
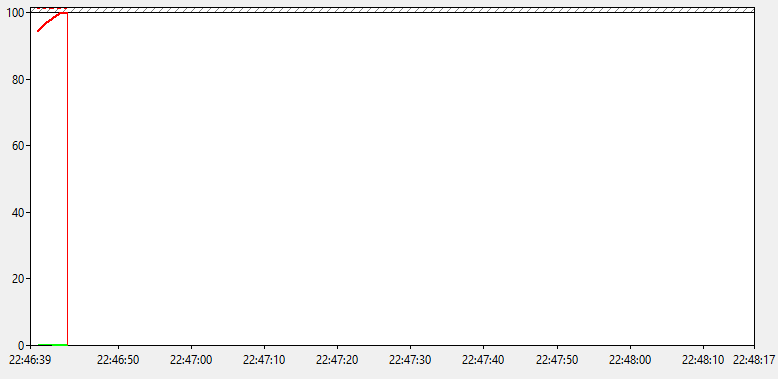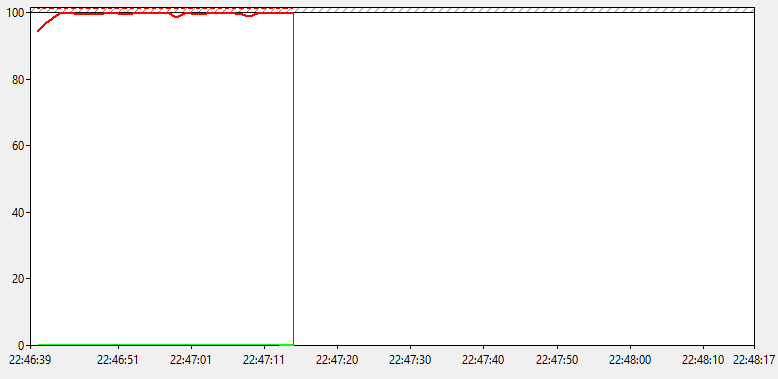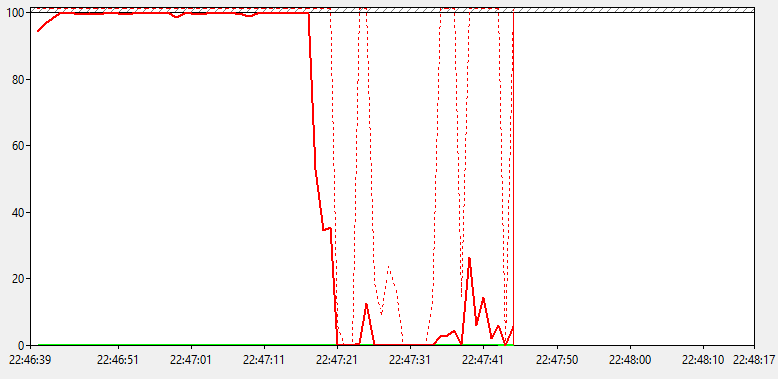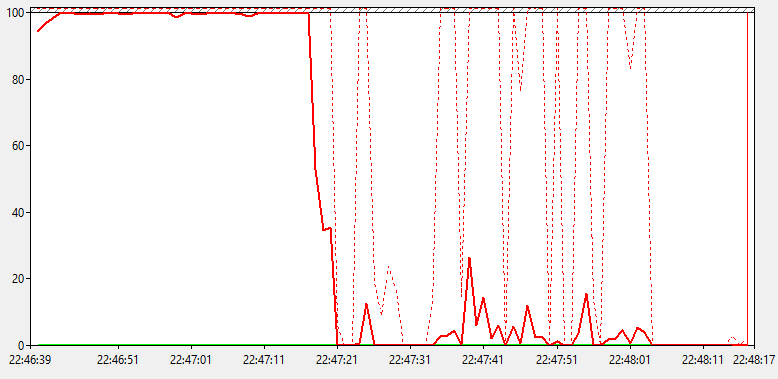 Переходов в состояние ниже C1 нет, а они бы были самыми дорогими. Если состояние С1 в рабочим режим переходит за ~10 нс, то C2 уже необходимо 100 нс, а для C3 - 50 мкс. В общем, дело точно не в энергосбережении, и это хорошо! Пойдемте дальше.
Переходов в состояние ниже C1 нет, а они бы были самыми дорогими. Если состояние С1 в рабочим режим переходит за ~10 нс, то C2 уже необходимо 100 нс, а для C3 - 50 мкс. В общем, дело точно не в энергосбережении, и это хорошо! Пойдемте дальше.
Все в очередь
Посмотрим как ведет себя показатель длины очереди к процессору. Вот что мы увидим.
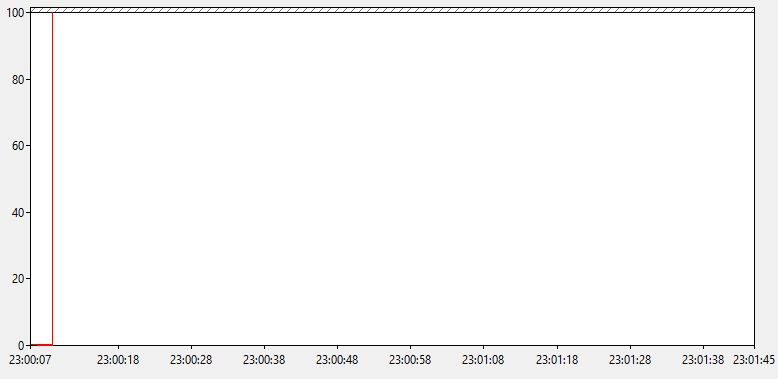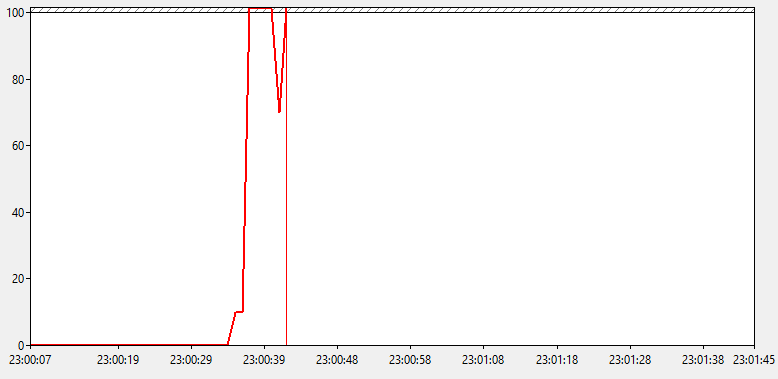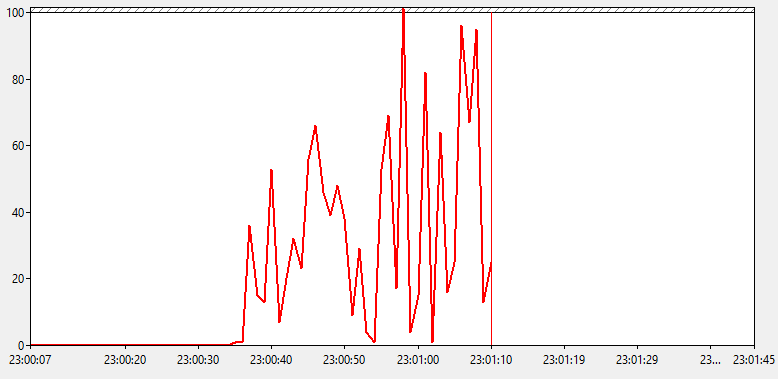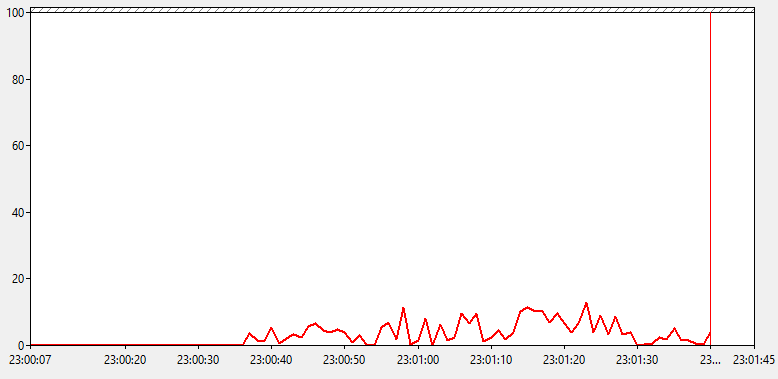 Видимо большую очередь к ЦП, при этом держится она длительное время, хоть значения очереди и изменяются иногда до 0. Получается, что у нашего сервера просто не хватает мощи переваривать взваливаемую на него нагрузку. Но прежде чем пойти посмотреть какие именно процессы виновны в происходящем, посмотрим что там с переключениями контекста.
Видимо большую очередь к ЦП, при этом держится она длительное время, хоть значения очереди и изменяются иногда до 0. Получается, что у нашего сервера просто не хватает мощи переваривать взваливаемую на него нагрузку. Но прежде чем пойти посмотреть какие именно процессы виновны в происходящем, посмотрим что там с переключениями контекста.
 На графике масштаб изначально 0.001, то есть в спокойном состоянии было около 8 тысяч переключений контекста. Затем мы видим резкий всплеск в момент возросшей нагрузки на ЦП, после чего показатель к предыдущим значениям практически не возвращался. То есть явно возросло количество активных потоков, которые требуют процессорных мощностей. Именно поэтому нужно анализировать этот показатель в динамике, чтобы было с чем сравнивать.
На графике масштаб изначально 0.001, то есть в спокойном состоянии было около 8 тысяч переключений контекста. Затем мы видим резкий всплеск в момент возросшей нагрузки на ЦП, после чего показатель к предыдущим значениям практически не возвращался. То есть явно возросло количество активных потоков, которые требуют процессорных мощностей. Именно поэтому нужно анализировать этот показатель в динамике, чтобы было с чем сравнивать.
Настал момент посмотреть что за процессы все это вытворяют.
Узнаем правду
Перейдем в старый и добрый диспетчер задач и посмотрим какие процессы в ТОП'е. И о чудо!
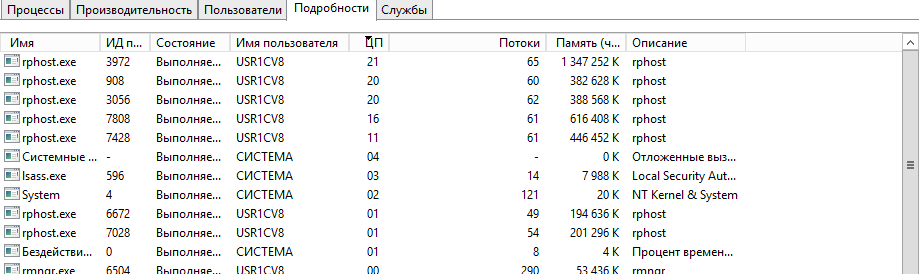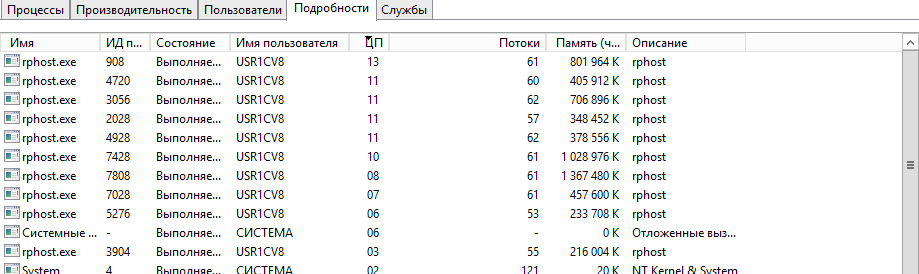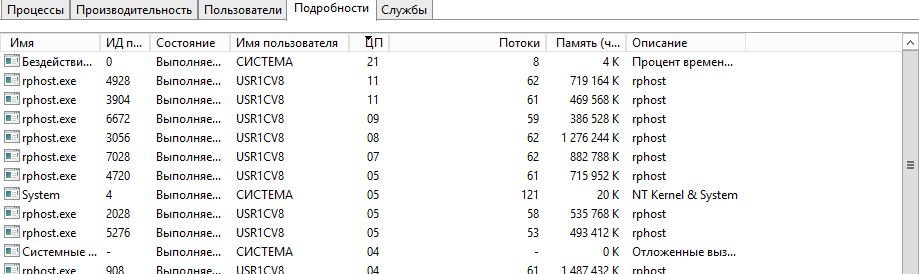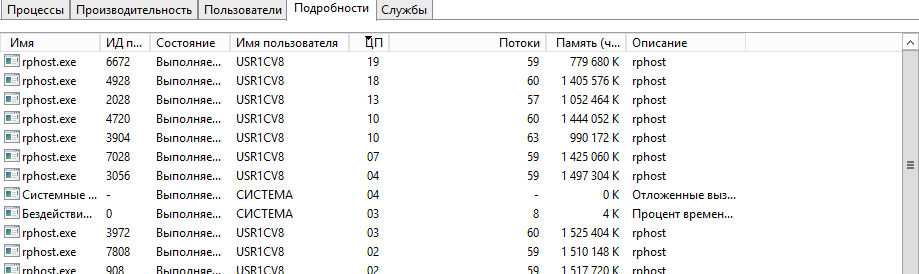 Это рабочие процессы сервера 1С! Вот это поворот! Идем в консоль кластера, чтобы понять кто и что делает на сервере.
Это рабочие процессы сервера 1С! Вот это поворот! Идем в консоль кластера, чтобы понять кто и что делает на сервере.
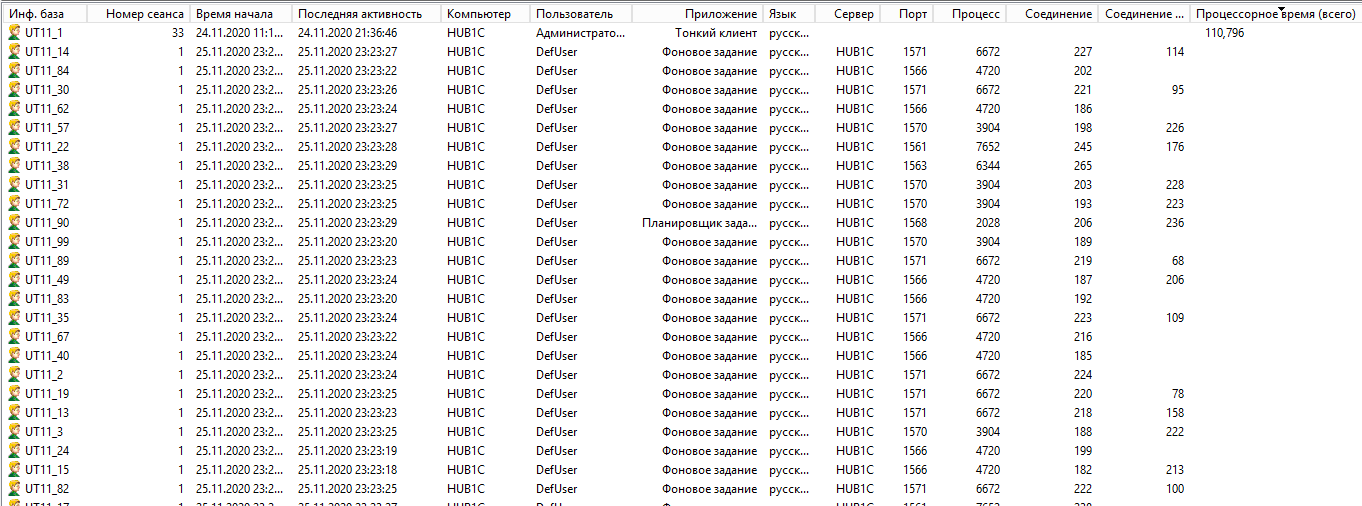
Большое количество фоновых задания. В колонке "Процессорное время" теперь можно отследить кто съедает процессорные ресурсы, но не в нашем случае. И обратите внимание на названия информационных баз в первой колонке. Видите странность? (нет, я не про имена). Да, баз достаточно много, причем фоновое задание запускается каждое в отдельной информационной базе. Но что это за задания?
Идем в журнал регистрации и видим там это.
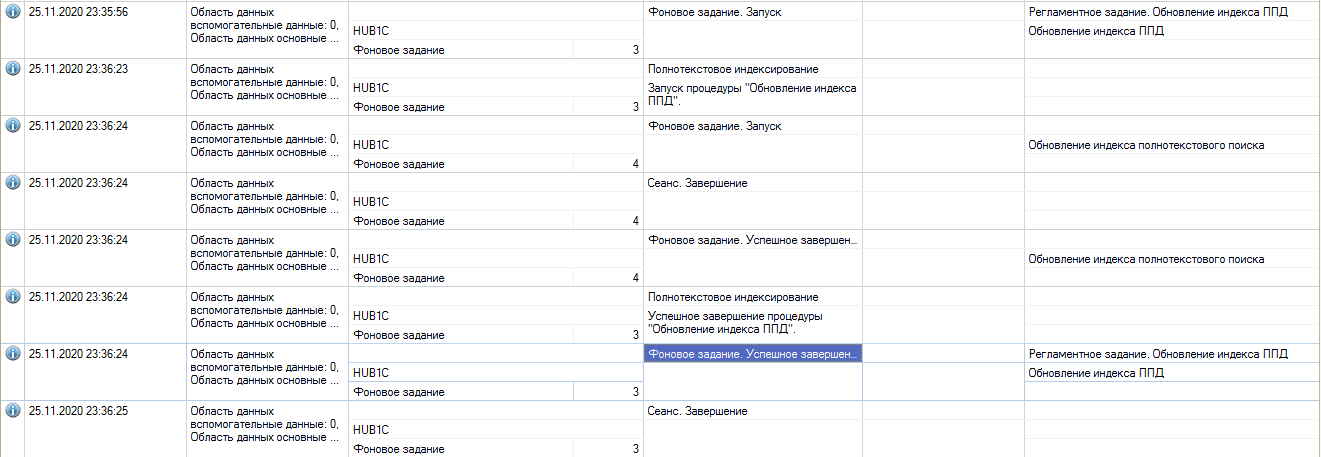
Да, в каждой информационной базе аналогичная картина - каждую минуту запускается фоновое задание обновления полнотекстового индекса. Но неужели это задание так может нагружать сервер? 
В нормальных ситуациях - нет. Но если на сервере столько баз...
В общем, в чем проблема понятна. 100 баз на одном сервере с 8 ядрами. А ведь нагрузку могут создавать не только фоновые задания обновления индекса ППД, но и остальное (отчеты, проведение документов и многое, многое другое). Можно услышать оправдание такой настройки - но базы то не большие и в каждой работает по 1 пользователю. Как мы видим, это далеко не аргумент в создании такой конфигурации.
Какое тут решение? Думаю, Вы и сами догадываетесь о возможных решениях. Можете написать в комментариях, если есть что сказать. Но если Ваш ответ - нужно отключать полнотекстовый поиск, потому что он тормозит, то Вы не правы. Все служит своим целям, поэтому лучше сначала разобраться с настоящими причинами проблем.
Мониторинг и сбор информации
Мы рассмотрели основные показатели CPU и их краткое описание. На небольшом и простом примере вживую увидели как эти показатели меняются. Но заходить на сервер каждый раз и проверять счетчики работы ЦП - дело не благодарное, ведь никогда точно не знаешь в какой момент проблема появится.
Очевидно, что нужен мониторинг на постоянно основе. Решений для этого достаточно много, но самым распространенным остается использование Zabbix. На Инфостарт не одна статья написана по этой теме. Ссылки на них добавил в конце публикации, а также вот еще некоторый материал, который может пригодиться:
Внедрение, развертывание и настройкам мониторинга - отдельная обширная тема. Но, по крайней мере, теперь Вы знаете с чего начать.
История не из мира Highload
Это была простая история с предсказуемой концовкой. Даже можно сказать - очень упрощенная история. Цель была очень проста - показать какие показатели диагностики ЦП имеются в наличии у каждого под рукой и дать им краткое описание. Как бонус, на графиках мы посмотрели их изменение при возникновении пиковых нагрузок и докопались до истины.
В будущем рассмотрим более сложные примеры связанные с виртуализацией, облаками и прочими ужасами современного мира ИТ. А пока что все.
Всего хорошего и производительного!
Для Вас интересны темы по разработке на платформе 1С и связанные темы по разработке, администрированию? Присоединяйтесь в Telegram-канал, где будет появляться информация о моих новых статьях и разработках на Инфостарт, выходу обновлений, а также некоторые материалы по не1Сной тематике (СУБД, мониторинг, C# и кое-что другое).
Часть материалов, не подходящих сюда по темам, будут выходить на сайте. Там же можно ознакомиться с полным списком разработок для 1С. Думаю, что будет интересно.
Другие ссылки
Авторские разработки (все разработки на одной странице)
-
Транслятор запросов 1С в SQL - инструмент для трансляции запросов платформы 1С в SQL, а также их диагностики.
-
Мастер создания копии информационной базы для отчетности - прототип инструмента для подготовки реплики в режиме только для чтения к использованию. Позволяет использовать "read-only" реплики как обычные информационные базы 1С.
-
Просмотр и анализ структуры базы данных (отчет на СКД) - отчет для просмотра и анализа структуры базы данных с поддержкой файловых баз (ограниченный режим), а также баз на SQL Server и PostgreSQL.
-
Просмотр и анализ журнала регистрации (отчет на СКД) - отчет на базе системы компоновки данных (СКД) для просмотра записей журнала регистрации.
-
История работы пользователей (отчет на СКД) - отчет для просмотра истории работы пользователей (СКД, просмотр для любого пользователя).
-
Экспорт журнала регистрации. Набор инструментов (приложения + исходный код) - набор инструментов для экспорта данных журнала регистрации во внешние хранилища для Windows и Linux. Готовые приложения и исходный код.
-
Технические проверки данных регистров бухгалтерии (отчет на СКД) - отчет для технических проверок данных бухгалтерских регистров.
-
Путеводитель по истории релизов - отчет по истории выпуска релизов продуктов фирмы "1С" и анализа информации по обновлениям.
Вступайте в нашу телеграмм-группу Инфостарт