Что и для чего мы будем делать?
Эта статья открывает цикл публикаций, в котором будет подробно рассмотрено построение среды для непрерывной интеграции (Continuous Integration или CI). Как и в случае предыдущего цикла, посвященного написанию сценарных тестов, целью данных публикаций будет не только описать основные идеи или похвастаться скриншотами, но и дать инструкции, описать архитектуру системы и показать приемы для её воспроизведения. Результатом будет работающий код и руководство по его использованию.
Мы будем стремится достичь максимальной автоматизации и получить систему, рабочие узлы которой можно развернуть и запустить с минимальным количеством ручных действий. Наш CI-контур должен удовлетворять не только критерию "непрерывная сборка и тестирование" для систем на 1С, но и "инфраструктура как код", позволяя воспроизводить себя на разных хостах и относительно быстро заменять компоненты системы.
Это согласуется с технической составляющей DevOps-подхода, важными частями которого являются CI и концепция "инфраструктура как код". Идея заключается в следующем. Всё, что требует сочетания таких качеств как скорость, повторяемость, надежность, не может и не должно выполняться как ручное рутинное действие, даже если вопрос касается самого процесса разработки и проверки его результатов. Ручные рутинные действия несут слишком большие риски человеческого фактора - забывчивость, случайность, халатность. Если что-то делается часто и при этом делается одинаково, то это можно (с технической точки зрения) и нужно (с экономической точки зрения) автоматизировать.
Как правило автоматизируется развертывание стандартизированной инфраструктуры и регулярная проверка стабильности и надежности того, что было сделано раньше - регрессионное тестирование. Сделать это можно за счет выражения инфраструктуры и регрессионных тестов в виде исполняемых сценариев, скриптов и конфигурационных файлов. То есть в виде кода.
Такой подход сильно отличается от традиционного, при котором сценарии развёртывания хранятся вместе с данными в закрытых базах за семью замками или в головах отдельных людей. И позволяет "убить двух зайцев сразу" - не только добиться стандартизации, но и сохранить при этом гибкость и возможность внесения изменений в созданные механизмы:
- Легко хранить историю всех изменений. И если правильность сделанных изменений будет подтверждена автоматическими или ручными проверками, то появится новая версия системы. А если нет - всегда есть возможность вернуться к любой из предыдущих версий.
- То, что описано кодом проще передать от одного специалиста к другому. Знания перестают быть сакральными и к развитию системы можно привлекать новых людей.
Фактически это распространение практик, применяемых для разработки программных продуктов, на инструментарий и окружение самих разработчиков и специалистов по сопровождению. И хотя сейчас DevOps-ом часто называется любое продвинутое системное администрирование (администраторы пишут, что делают это не по злому умыслу, а в борьбе за справедливость ;) ), продвинутым его обычно делает именно распространение практик разработчиков ПО на область администрирования и построения инфраструктуры.
Всё это может показаться просто вводными словами, но для применения того, что будет описано далее, действительно важно понимать и разделять такой подход. В ином случае все рассматриваемые задачи покажется проще решить одноразовой ручной настройкой и забыть об этом…. до первого сбоя или необходимости внести изменения в компоненты хрупкой системы.
Если мне не нужен CI, будет ли здесь что-то полезное?
Как можно понять из заголовка, механизмы будут во многом основаны на автоматической настройке и развертывании виртуальных машин в гипервизоре второго типа. Те же самые приемы можно применять не только для CI и не только для 1С, но также для развертывания различных сред для разработки. Например для автоматизации настройки одинакового окружения на рабочей и домашней машине или рабочих машинах в разных офисах, без ущерба для основной (хостовой) операционной системы и её настроек. Частично эти же подходы можно применить для нагрузочного тестирования, в случае если необходимо сэмулировать изолированные друг от друга клиентские машины, сделать это быстро и обеспечить на них одинаковое окружение.
Возможно и более простое применение рассматриваемой информации. В частности будут разобраны способы:
- автоматической установки различных версий сервера и клиента 1С на Linux (а впоследствии и на Windows)
- установки и простейшего конфигурирования Apache для 1С в автоматическом режиме.
- установка PostgreSQL 10 и 11 для 1С, а впоследствии и MS SQL.
- развертывания последних версий Ubuntu Server в виртуальных машинах.
- способы программной работы и работы из консоли с RAS и RAC, которые не доставляют больших неудобств.
- и ряд других подобных тем.
Каждый из рассматриваемых приемов можно применять в отдельности, безотносительно CI.
Исходные коды
Код, который мы будем использовать в ходе разработки нашего CI будет публиковаться в открытых репозиториях на gitlab.com и github.com (просто для возможности выбора). Результатом рассмотрения каждой темы будет являться отдельный коммит.
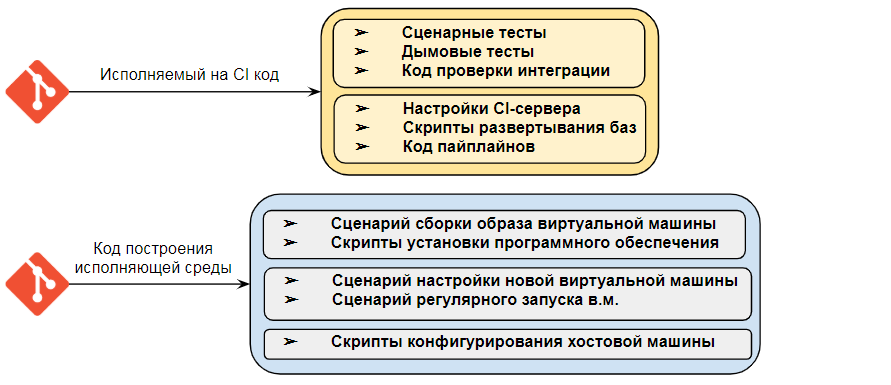
При этом всю нашу систему можно будет разделить на две независимых блока :
1) Развертывание тестовых сред и узлов для CI-контура : автоматическую настройку хоста и виртуальных машин.
2) Наполнение CI : сценарные тесты, пайплайны Jenkins, настройки веб-сервисов и т.д.
Первый блок не зависит от того, что именно мы будем запускать на CI. Здесь мы только обеспечиваем инфраструктуру - операционную систему, настройки сети и ресурсов машины, серверное программное обеспечение (1С , сервер SQL, Apache) и т.д. Именно эту часть можно использовать не только для CI, но и для других целей. Разработку, замену или обновление компонент этой системы можно выполнять независимо от того, какие именно задачи на ней исполняются, подобно тому, как вы можете обновить операционную систему на своем компьютере и заново установить то же программное обеспечение, что и раньше.
Второй блок - это регулярно исполняемые сценарии. Здесь мы описываем пайплайны CI-сервера, механизмы развертывания тестовых баз, их инициализацию. Эта же часть системы будет содержать и сценарные тесты для 1С. В более сложном варианте тесты также можно было бы выделить в независимую часть системы. Но сейчас, во избежание усложнения, мы этого делать не будем.
Зависимость этого второго блока от инфраструктуры и того, как инфраструктура разворачивается, тоже должна быть минимальной. Мы можем развернуть и настроить узлы для нашего CI хоть в полностью ручном режиме. Можно сделать это на разных физических серверах, если позволяют ресурсы компании. Если необходимые компоненты будут настроены корректно, то CI будет работать.
Таким образом выделяется две независимые друг от друга части системы, которые можно использовать по отдельности и которые некорректно смешивать в одном репозитории. Поэтому впоследствии у нас появится еще один репозиторий - непосредственно для наполнения CI-контура.
Технические требования
Для разработки, отладки и тем более развертывания потребуются аппаратные программные ресурсы. Ниже указаны требования для разработки и отладки CI-контура. Для полноценного использования может потребоваться значительно больше ресурсов.
Характеристики хостовой машины
Необходимо около 90 ГБ свободного места на диске. Желательно иметь от 24 ГБ оперативной памяти и SSD для комфортного использования. Хотя если виртуальные машины разнести по разным HDD, то это тоже хороший вариант. Минимум 4 ядра процессора, и при таком их количестве по частоте лучше ориентироваться на 2,8 ГГц и выше (уровень около Ryzen 5 или Intel Core i5 подойдёт). Это минимальная конфигурация, на которой мне удавалось вести разработку относительно комфортно. Хостовой ОС у нас будет Windows, но при необходимости ее будет легко заменить на Linux, так как на хостовой машине будет исполняться очень мало специфичного для нее кода - всего несколько скриптов, которые на bash выглядели бы даже лаконичнее.
Для реализации "многопоточного" CI в минимальном варианте потребуется развернуть по крайней мере три виртуальные машины, которые будут выступать в качестве сборочных узлов Jenkins. Обоснование такого количества приводится далее - при детальном рассмотрении структуры CI. С теми настройками узлов, которые будут использоваться в приводимых примерах, при развертывании большой конфигурации, вроде "Комплексной автоматизации" или "ERP", запуск хотя бы трех сборочных узлов будет съедать 100% ОЗУ и процессора на машине, обладающей описанными выше ресурсами. Но все же система будет работоспособна. При меньшем количестве ресурсов вероятно потребуется отказаться от выполнения процессов в несколько потоков и выполнять их только на одном из узлов.
Хранилище конфигураций
Часть механизмов будет рассчитана на то, что разработка на платформе 1С ведется с применением хранилища конфигураций. Это наиболее частый сценарий, при котором на сегодняшний день требуется CI для 1С. В случае работы напрямую через git описанные подходы также могут быть применимы, причем их можно сделать даже намного проще. Но всё же для воспроизведения всех примеров понадобится создать сервер хранилища конфигураций и развернуть на нем хранилище для базы на основе БСП. Доступ к нему будет производиться по протоколу tcp или http.
Физический сервер или вложенная виртуализация
На хостовой машине должна быть доступна виртуализация. Если вы уже работаете в виртуальной машине, то для нее должна быть включена вложенная виртуализация. Иначе программные гипервизоры (VMWare, VirtualBox) не смогут запускать виртуальные машины. Если разработку вы будете вести на физической машине, то проблемы возникнуть не должно.
Наличие ряда UNIX/POSIX-инструментов на хостовой машине
Это не вполне техническое требование, но здесь упоминается чтобы не возвращаться к этому вопросу в дальнейшем.
Нам потребуются такие утилиты как tee, grep, tr, sed, rm и путь к ним должен быть прописан в переменной окружения PATH.
Эти утилиты, кстати, в последнее время очень часто упоминают в контексте анализа логов платформы 1С и СУБД при анализе производительности и параллельности работы, так что можно считать, что это стильно и модно )) Сейчас же они будут нужны нам в ином контексте - для автоматического конфигурирования систем через bash- и bat- скрипты.
Если в качестве хостовой машины выступает Windows, то для того чтобы их получить достаточно установить сборку git для Windows и во время установки не снимать флаг указания путей к UNIX-инструментам в переменной PATH. Есть и другие способы, но git в любом случае необходим на всех машинах, с которыми мы будем работать. Поэтому установки его пакета будет достаточно.
Что нужно от читателя?
Заглядывать в документацию
Несмотря на желание изложить информацию максимально подробно, часто это будет физически невозможно или равносильно дословному перепечатыванию документации. Поэтому встретив незнакомый параметр команды sed , grep, git стоит обратиться за пояснением ко встроенной справке. Ознакомьтесь при необходимости с описанием Packer, Vagrant и Jenkins на сайтах разработчиков этих инструментов. Обязательно постараюсь приводить ссылки на основные источники информации. Но если Вы еще не "съели собаку" на рассматриваемых темах, то заглядывать в документацию и поисковики придется часто.
Знакомство с фреймворком для функционального тестирования
Применение фреймворков для тестирования является главной целью построения нашей системы CI. Поэтому желательно быть знакомым с Vanessa-Automation или Vanessa-ADD как минимум на уровне достаточном, чтобы не остановиться на вопросах "как выполнить сценарии из каталога с фичами". В качестве альтернативы можно применить любой другой инструмент для запуска тестов. Но думаю, что если у Вас есть альтернатива, то Вы уже сами знаете, что нужно делать и скорее всего даже CI у вас уже есть ))
Материалов на эту сейчас очень много и на Ютубе и на Инфостарте, достаточно вбить в строку поиска ключевые слова. Если Вы только начинаете изучать эту тему, то рекомендую ознакомиться с каналом, содержащим информацию о новинках VA и видео-документацию: https://www.youtube.com/channel/UC114RqHhG__1gET8pzs3AHA/playlists
Linux, командная строка и доработка скриптов
Потребуются минимальные значения Linux или готовность их получить в процессе. В основных частях публикации узлы будут собираться на Linux. Рассмотрение WIndows также в планах, но только в качестве дополнения к основной информации. Конфигурирование осуществляется в основном командными файлами (bat и bash). Это не универсальные приложения, которые полностью проанализируют Вашу систему, установятся куда нужно и будут работать на любом компьютере. Сейчас они работают на тех машинах которые доступны мне. Но Вам потребуется изменить часть параметров выполнения и это не должно становиться препятствием.
Другие языки разработки
Язык платформы 1С почти не будет применяться. При этом кода будет много. А значит этот код будет на других языках )) Надо быть готовым к минимальному знакомству ними - Groovy, Ruby, bash, синтаксис конфигурационных файлов, регулярные выражения и т.д. Поверьте, я тоже в них далеко не гуру, но рука набивается быстро, если изучить хотя бы основы и поупражняться. В общем здесь еще более актуальна заметка про чтение документации.
Самое главное
Внедрение и даже разработка учетных систем - это область, в которой техническое качество часто не является ощутимым конкурентным преимуществом. На рынке, ориентированном на быстрые дешевые внедрения, решение проблемы некачественной разработки редко видится в повышении инженерной культуры. Вместо этого выбор делается в пользу более бытовых и понятных заказчикам мер. В общем, внешнего стимула у Вас может и не быть.
Поэтому самое главное условие - это наличие Вашего личного интереса как технического специалиста к рассматриваемой теме и мотивации к её освоению. Без него сами собой будут находиться аргументы почему это сложно и не для "бизнес-программистов", и почему больше пользы можно принести сделав ещё один отчет по проводкам в УПП или загрузку из Excel ;))
Двигаясь дальше, будем считать, что личный интерес и мотивация у нас в наличии, и поэтому попыток упростить описание механизмов или уговорить Вас их попробовать не будет. Скорее даже наоборот ;)
Архитектура систем крупным планом
Системы, которые мы будем рассматривать, не могут жить сами по себе. Они являются частью процесса разработки. Поэтому, прежде чем переходить к рассмотрению основной темы, давайте посмотрим на следующую схему и определим место и роль CI-контура в ней:
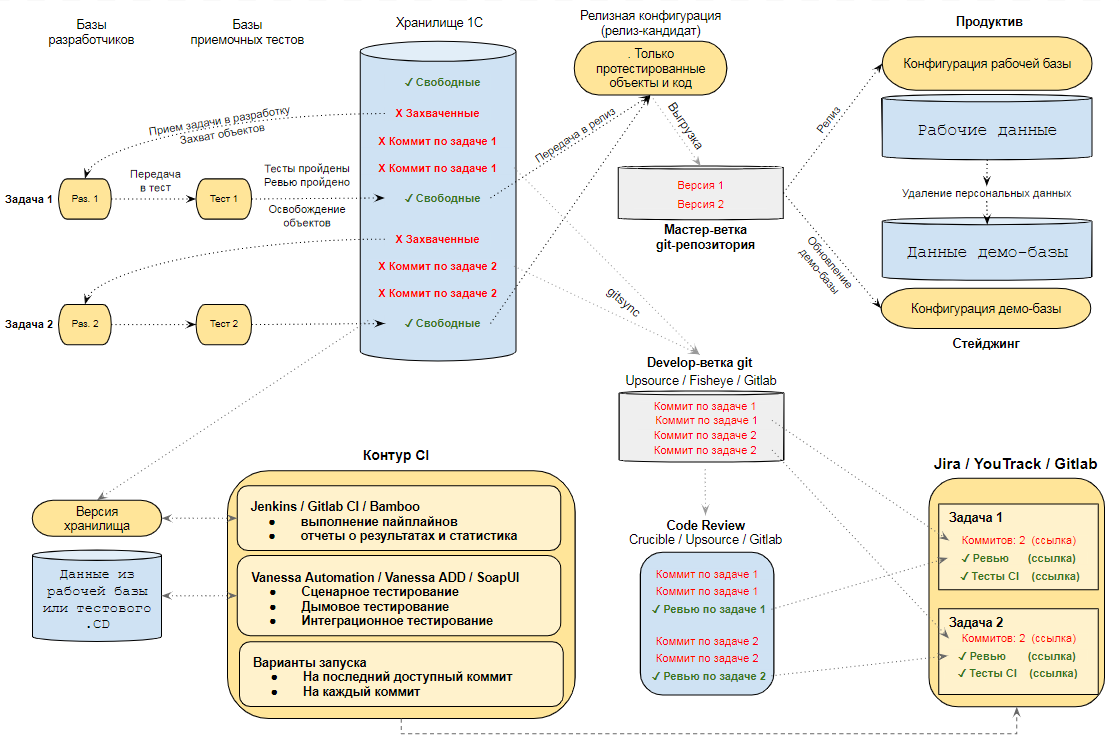
Здесь показан один из возможных подходов к организации процесса разработки с применением хранилища конфигураций 1С
Эта куча стрелочек требует пояснения. Если мы откроем методическое пособие по эксплуатации информационных систем от 1С , то сможем найти описание отдельных контуров (зон) необходимых для полноценной эксплуатации крупной системы: отдельные среды для разработки, тестирования, демо (стейджинга), рабочей среды и тд. Аналогичные описания можно найти и для систем отличных от 1С. Но помимо этой "статичной картинки" есть еще сам процесс разработки и построить его можно по разному.
Если у нас есть небольшая команда разработки, занимающаяся одним проектом то процесс можно построить следующим образом.
Информационные базы :
1) Базы разработки, где кодом (конфигурацией) и данными целиком владеет разработчик . Данные обновляются по запросу из рабочей или демо-базы.
2) Базы QA, куда код приходит от разработчика, но данными целиком владеет инженер QA. Код обновляется при передаче задачи в тестирование, а данные по запросу инженера QA из рабочей или демо-базы.
Под владением данными здесь понимается право и возможность их обновления в нужный момент времени и нужным содержимым по требованию владельца базы. Бывают случаи когда обновление данных в базах QA происходит по расписанию. Бывают случаи когда это происходит через бюрократическую цепочку заявок. Это плохие решения. У разработчика и QA-инженера должна быть возможность автоматически обновить и при необходимости переподключить к хранилищу свою базу парой кликов мыши. Это не так сложно, как может показаться.
3) Релизная конфигурация или информационная база. Содержит подготовленный к релизу слепок конфигурации. Может быть подключена к хранилищу разработки или к отдельному хранилищу. Главное требование - она должна содержать только тот код который:
- Прошел тестирование.
- Прошел код-ревью.
- Не привел к ошибкам на CI.
Если релизная база подключена не к отдельному хранилищу, а к хранилищу разработки , то лучше настроить регулярную выгрузку ее рабочей конфигурации в git. Это позволит не только получить аналог мастер-ветки, но и быстро видеть отличия от develo-ветки, которой является выгрузка в git хранилища разработки. А также позволит при необходимости быстро откатиться на предыдущую версию работоспособной релизной конфигурации.
4) Демо база. Регулярно обновляется данными из рабочей базы. При необходимости данные могут быть очищены от персональной информации, очищены от версий объектов, прикрепленных файлов и т.д. Код демо-базы регулярно обновляется из релизной конфигурации. Наличие этой базы может быть полезно при проведении спринт-ревью или окончательного интеграционного тестирования.
5) Рабочая база. Данными владеют пользователи. Код обновляется из релизной конфигурации или из соответствующей ей ветки git-репозитория.
Хранилище конфигурации
Отраженный на схеме процесс немного отличается от общепринятого:
1) Объекты захватываются при взятии задачи в разработку.
2) При передаче измененных объектов в тестирование захват объектов не снимается, а лишь переносится из базы работки в базу тестирования. Это позволяет разработчику в своей базе ( Dev-базе ) взять в работу новую задачу, требующую захвата уже других объектов. Но не отпускать объекты, по которым фактически не закончен процесс разработки. При этом можно исправлять ошибки, найденные QA-инженером, прямо в базе с тестовыми данными, на которых она воспроизводится. Это повышает оперативность исправлений.
Такой подход - это некая попытка сэмулировать форки в git не применяя при этом тяжёлую технологию разветвленной разработки.
3) Отмена захвата выполняется только тогда, когда процесс разработки полностью завершен. Если при этом коммиты по задаче прошли CI, то изменения можно смело переносить в релизную конфигурацию.
4) Требуются особые правила работы с корнем конфигурации для ускорения операций с ним. Необходимы методы-заглушки для подписок и регламентных заданий в общих модулях, которые никогда не захватываются. Помещение в хранилище объектов-пустышек, чтобы быстрее освободить корень при добавлении новых объектов. Это более-менее общепринятая практика и думаю большинству хорошо знакома.
5) Так как захват объектов одним и тем же разработчиком осуществляется в двух базах то:
- Требуется по два пользователя хранилища на каждого разработчика, например ivanov_dev , ivanov_test.
- Требуется их маппигн на одного и того же пользователя git-репозитория. Такой маппинг позволяет сделать как Gitsync, так и Гит-Конвертер.
Таск-трекер и его связи
Сложно представить качественный процесс разработки без удобной системы управления задачами.
Есть системы, ориентированные больше на формализацию отношений с заказчиком, далёким от IT. Они позволяют прямо из своих формочек обмениваться документами MS Word по электронной почте между заказчиком и проджект-менеджерами. Рисовать диаграммы ганта и описывать, как красиво закончится проект. Есть системы, ориентированные больше на IT отделы, осуществляющие поддержку пользователей. В них куча функционала для учета парка ПК, инвентаризаций, календарь профилактического осмотра компьютеров. Некоторые проджект-менеджеры и ИТ-директора пытаются всё это дело прикрутить к процессу разработки. Не переучиваться же, в самом деле ))
Но к подходящим под наши цели системам можно отнести такие как YouTrack, Jira, Gitlab, TFS. Главное отличие таких систем - возможность интеграции с системой версионирования кода, системой код-ревью, билд-серверами и системой документирования, которая также поддерживает версионирование.
Например меня в своё время поразила связка Crucible + Fisheye + Jira + Confluence и до сих пор я не встречал более удобного сочетания. Crucible позволяет прямо из Jira выполнять ревью одновременно на все коммиты по задаче ( не делать кучу разных ревью на отдельные закладки в хранилище 1С ), Fisheye - увидеть все изменения по задаче пользуясь удобной ссылкой из Jira . К этому можно добавить связку с документацией, для которой просто отследить историю изменений и сделать экспорт в различные форматы. Аналогичных возможностей позволяют добиться и другие названные системы.
Разумеется наличие YouTrack или Jira еще ничего не гарантирует. Они на практике могут использоваться, и часто используются, так же "в лоб" как какой-нибудь список задач в Excel или Гугл-документ. В этом случае можно заменить эту систему на Excel или 1С:Документооборот - и абсолютно ничего не изменится.
Для того чтобы получить от них эффект необходима их интеграция с другими инструментами разработки и использование возможностей этих инструментов из таск-трекера. В случае с 1С нужно еще обеспечить оперативную выгрузку хранилища конфигураций в git и соблюдать определенные правила при помещении объектов в хранилище конфигурации.
Контур CI
А вот и он, представляющий только небольшую часть на общей схеме. Здесь мы выполняем большинство проверок ранее реализованного функционала на предмет поломок. То есть то, что потребовалось бы делать QA-инженеру или тестировщику вручную при отсутствии этих механизмов.
Обрабатывать здесь мы можем каждый коммит, если позволяют ресурсы. В этом случае будет достоверно известно, какое именно изменение привело к ошибкам. Если же время за время тестирования в хранилище может быть сделано множество закладок и CI-контур оказывается перегружен, то можно рассмотреть иной вариант. Брать последний доступный на момент запуска коммит из хранилища, обрабатывать его, затем переходить к следующему последнему доступному коммиту. Таким образом мы будем пропускать некоторые коммиты и не сможем точно сказать, какой из них поломал сборку. Но сам факт поломки от внимания не уйдет и в этом случае.
Разве это оптимально?
Хотелось бы сразу согласиться со справедливыми замечаниями, что определенных ситуациях такая архитектура будет неоптимальной. Например удержание объектов хранилища захваченными до окончания тестирования может оказаться своего рода избыточной блокировкой. Описанный выше подход сработает в небольшой команде при выполнении таких условий, как:
- Подходящая декомпозиция задач на разработку и соответствующая декомпозиция модулей конфигурации по принципу "единой ответственности". Тогда при захвате объектов одними разработчиком он будет доставлять минимум неудобств другим разработчикам.
- Быстрое тестирование. Для этого нужны инструменты для автоматизации обновления данных в базах QA-инженеров и разработчиков по требованию владельцев этих баз , автоматизации последующего подключения к хранилищу и загрузки нужной версии хранилища.
- Быстрое исправление ошибок. Для этого можно исключить возврат работы над задачей в базу разработчика при ее обнаружении, как это описано выше. Единственная сложность скорее "психологического" характера - это то, что для каждого разработчика в хранилище надо завести двух пользователей и сопоставить их с одним пользователем git-репозитория (если у Вас есть выгрузка в git).
При отсутствии таких условий можно применить иной подход. Складывать в хранилище всё что угодно. Затем просто следить, какой коммит прошел ручное тестирование, код-ревью и не уронил CI. Последний из таких коммитов целиком брать для последующего релиза. Это подход, похожий на trunk-based. Но при таком подходе наличие CI является уже критически необходимым. В случае его отсутствия мы никогда не будем знать, какая из версий хранилища безопасна для рабочей базы. И давайте честно, в этом случае тестировщики ( если они вообще есть при такой организации труда ) берут для проверки только последний из них, проводят обычно только приемочные тесты, без какого-либо регрессионного тестирования, и затем все изменения отправляются в рабочую базу. Каждый хотя бы раз в жизни работал по такому хаос-процессу ;)
Целью демонстрации и описания приведенной выше схемы является не показать "классный процесс по которому нужно работать", и не убедить в его оптимальности, а показать место CI в общем процессе. CI - это далеко не всё, что необходимо для построения качественного процесса разработки и без комплексного подхода он может просто не оправдать вложений. Но комплексный подход требует усилий, и обычно усилий далеко не одного человека. Поэтому очень важным является следующий вопрос.
Вопрос применимости
В полном объеме реализация описанного выше или аналогичного ему процесса разработки будет излишней или невозможной в большинстве случаев.
Можно заметить, что применимость к разработке на 1С таких практик как как код-ревью, рефакторинг, паттерны проектирования, непрерывная интеграция и т.д. очень часто ставится под сомнение самими программистами 1С. При этом с довольно жизненными и понятными аргументами:
- отчетность надо обновлять и месяц закрывать - нет времени на другое,
- через два года всё равно перевнедрение делать и весь этот ваш рефакторинг на свалку,
- мы на проекте временно - нет никакого смысла в код-ревью, пускай потом другие разгребают,
- в новом релизе типовой конфигурации всё перепишут и все тесты упадут, время потратим зря,
- заказчики не знают и знать не хотят, что такое тестирование, и за тесты не заплатят,
- скриптовые языки без типизации вообще не предназначены для создания надёжных систем, не нужно и стараться.
С этим всем сложно спорить. Всё-таки за пределами небольшого числа компаний к нашим системам чаще применимы термины "обслуживание" и "внедрение", нежели "разработка". Чаще всего процессы сопровождения простые, разработчиков мало, тестировщиков нет и рассмотренные подходы перегрузят команду 1С-ников. Их просто некому будет поддерживать, а попытки усложнить процессы будут вредны.
В других компаниях системы уже давно выросли, но закостенели, и даже катастрофически нуждаясь практиках, направленных на повышение качества разработки, не смогут их принять. Для этого требуются изменения, которые "пока не горят", хотя на деле постоянно возникающие пожары без каких-либо качественных изменений тушатся увеличением затрат на железо и увеличением штата. Нужно ли говорить, что такая невыгодная для компании ситуация может быть выгодной для ряда сотрудников?
Почему важно это понимать? Чтобы трезво оценивать достаточность ресурсов и вероятность успешного применения этих практик в Вашей компании. И правильно выбирать направление приложения усилий: на всю компанию или отдельную команду, на отдельный проект или только на отдельные задачи в его рамках.
Посмотрим, например, на CI, являющийся темой этой публикации. Техническая составляющая здесь - только малая часть. Уже на уровне отдельной команды его эффективное применение нуждается особом подходе к постановке задач:
- Продуманных сценариев приемки отдельных задач, которые затем превращающиеся в тест-кейсы. Тест кейсы обязательны для появления качественной автоматизации тестирования на более-менее большой конфигурации.
- При изменении требований необходим анализ и адаптация существующих тест-кейсов.
- При постановке задач нужно сразу хорошо продумывать интерфейс. Сценарные тесты привязаны к нему, и бесконечные правки интерфейса приведут к бесконечным затратам на изменение сценариев.
- И всё это не работает само по себе - нужны специалисты, которые этим занимаются. Особенно для создания и адаптации сценарных тестов. Это очень рутинная операция, занимающая до 20%-30% времени от всей разработки.
В то же время важно соблюдать баланс:
- Слишком большое количество тестов может привести к проблемам. Их адаптация к изменениям в системе требует времени. Особенно если речь идет об обновляемой типовой конфигурации. Лучше создать минимум сценариев, покрывающих важные бизнес-процессы и всегда поддерживать их в актуальном состоянии, чем написать много пересекающихся сценариев и потом забросить их из-за нехватки времени на адаптацию.
- Излишняя детализация сценариев на этапе постановки, как и слишком детальное техзадание, может привести к превращению разработчика в "печатную машинку" и отказу от этих практик.
- Интерфейс нужно продумывать. Но в то же время важно соблюдать баланс с возможностью вносить правки в интерфейс в ходе реализации.
Общую схему можно обрисовать так:
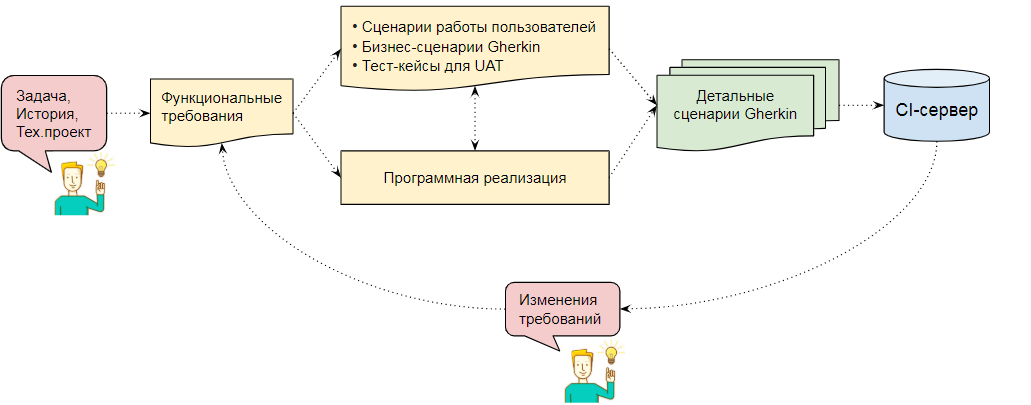
Без подобного подхода к постановке задач любой объем тестов на CI рано или поздно начнет выполнять функцию простейшего дымового тестирования - минимальных проверок, которые говорят о том, что 1С в принципе запускается и формочки в ней открываются. А сам CI превратиться в элемент очередного карго-культа или развлечение для айтишников. Пользы от этого будет мало.
Кроме постановки задач также требуется и правильный подход к их реализации. Система должна быть физически и организационно готова к автоматическому тестированию:
- Не перегружена расширениями, которые обычно даже не подключены к хранилищам конфигураций. Желательно иметь один репозиторий для кода, чтобы не превратить систему CI в неповоротливого монстра.
- Код не должен быть завязан на псевдо-предопределенные данные, которые ищутся по GUID или наименованию.
- Изменения не должны проходить мимо разработчиков тест-кейсов и разработчика автотестов.
- При этом нужно понимать и принимать тот факт, что при нехватке рабочих рук ощущение замедления разработки действительно будет. Ведь изменения в ранее реализованном функционале потянут за собой изменения в существующих сценариях и тест-кейсах.
Далеко не всегда текущее состояние информационных систем, заинтересованность руководства или квалификация сотрудников могут позволить поменять подход к разработке, чтобы система в принципе стала пригодна к автоматическим проверкам её работоспособности. В этом случае галочка "у нас есть тестирование" скорее всего будет поставлена за счет введения в процесс нерегулярных ручных проверок или простейших "дымовых" проверок.
Выше мы договорились, что у нас есть личная заинтересованность как технических специалистов в этих вещах. И если Вы уверены, что часть этих практик безопасна для проекта, то всегда сможете их применить, выбрав правильную точку приложения усилий. При этом важно, чтобы выбранный участок был независим от тех, где разработка построена по другим принципам, иначе реализованные механизмы будут очень хрупкими. Простейший пример - разработчик из соседней команды сломал половину покрытых тестами механизмов, но задачу он получал от начальника начальника начальника и поэтому чинить не собирается ;)) Или хранилище откатили без предупреждения на пару версий назад и поломалась его выгрузка в git. Вы будете готовы нянчиться с этим?
Что же, если подумав над этими вопросами Вы по прежнему готовы взяться за дело, то я рад! )) Перейдем наконец ближе к основной теме публикации.
Что будем понимать под "многопоточностью" и зачем она нужна?
Посмотрим на часть приведенной выше схемы, относящуюся к CI-контуру. Пока что мы рассматривали его как один "черный ящик": туда попадает версия хранилища, затем что-то происходит и информация об этом улетает в систему учета задач. Теперь нам нужно рассмотреть и понять устройство этого блока:
Начнем с определения термина "многопоточность" в применении к нашему CI-контуру. Под многопоточностью будем понимать систему с несколькими узлами ( в нашем случае - виртуальными машинами ) способными одновременно выполнять одинаковые задачи сборки и тестирования ( пайплайны ) для нескольких разных версий системы. Пайплайн для каждой версии в нашем случае будет запускаться только на одном узле CI-сервера, а параллельность будет достигаться за счет увеличения количества сборочных узлов.
Это в общем-то довольно простой и наиболее доступный подход. Распараллеливание по разным узлам процесса выполнения самого пайплайна - это более сложная задача, хотя и решаемая аналогичными способами. Если приводить аналогию с механизмами, знакомыми каждому специалисту по 1С , то разница примерно такая же как между обеспечением возможности запустить несколько клиентских сеансов 1С и провести в них параллельно несколько документов и задачей распараллеливания по нескольким фоновым заданиям процесса перепроведения этих документов с последующей синхронизацией результатов. Это задачи разного класса сложности.
Смысл слов "версия системы" при этом может быть разным. В простейшем случае это разные версии хранилища конфигурации. Но ей может быть например и набор согласованных версий из разных хранилищ. Или отдельный коммит в git-репозиторий, куда выгружается как код конфигурации, так и дополнительные файлы.
Целевой картиной в простейшем случае является следующая: две и более версии хранилища параллельно обрабатываются на разных узлах с возможностью видеть и контролировать ход процесса из одного места и получать финальную отчетность на одной странице браузера:
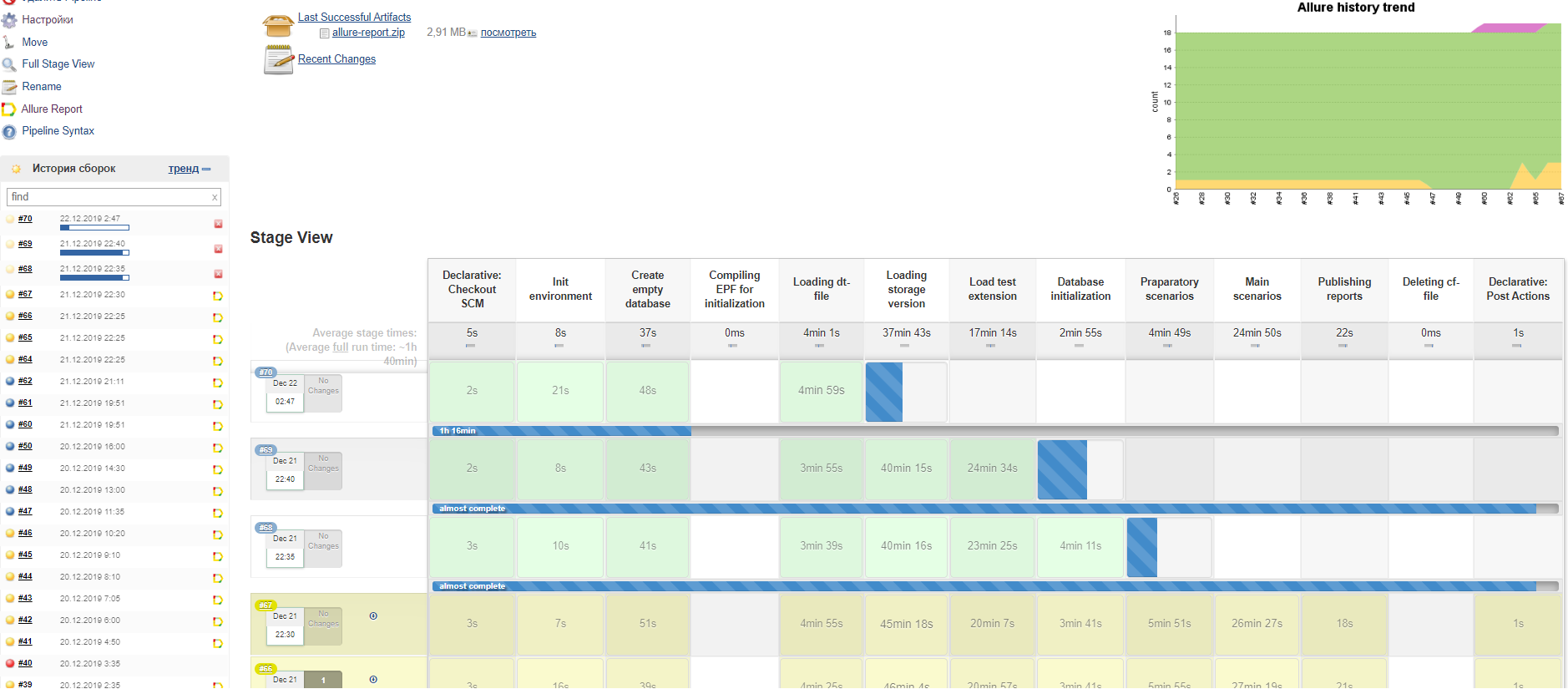
При этом исполнение распределено по изолированным друг от друга виртуальным машинам, которые не могут друг другу сильно помешать, хотя и могут бороться за ограниченные ресурсы основного хостового сервера:
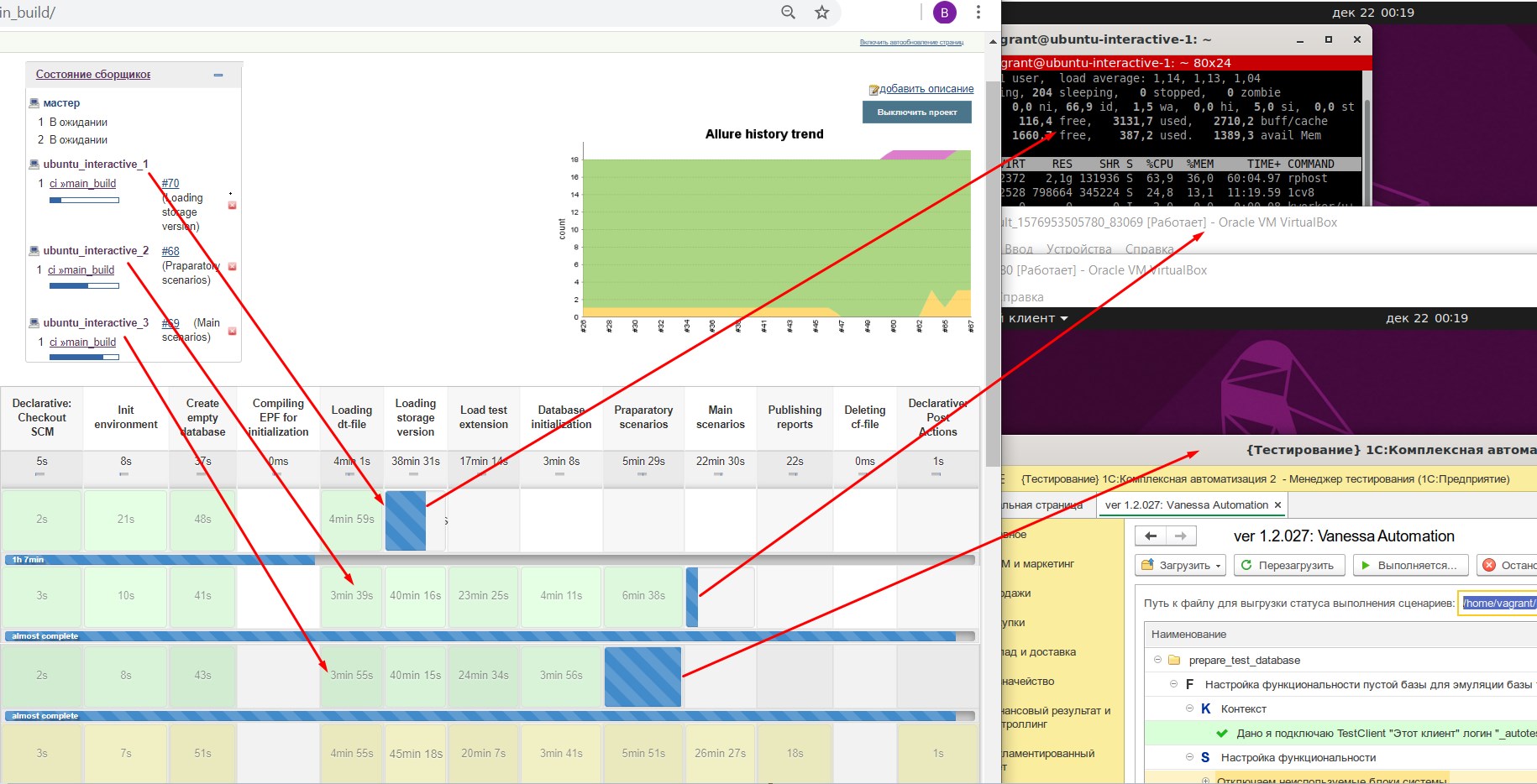
Обработка каждого коммита
Подобная "многопоточность" нужна для одной главной цели - добиться предсказуемого и примерно одинакового времени обработки каждого коммита, даже если несколько коммитов помещено в репозиторий ( хранилище 1С ) за короткий промежуток времени.
Это свойство CI очень важно, если разработка ведется на крупной конфигурации, например 1C:ERP или на "Комплексной автоматизации".
При работе с такими конфигурациями только развертывание и подготовка базы на CI может занимать более часа, и последовательная обработка коммитов может приводить к тому, что этот процесс будет сильно отставать от изменений в хранилище. При этом число разработчиков, работающих над конфигурацией, не обязательно должно быть большим. Бывают случаи когда несколько мелких задач решаются за короткий срок и по каждой из них в хранилище вносятся изменения. Это может привести к отказу от непрерывной интеграции. Придется пропускать часть изменений или даже переключиться на редкие "ночные" проверки.
Проблема здесь не только в том, что становится сложнее понять какая версия хранилища дала сбой или чья задача прошла мимо QA-инженера. Также затягивается процесс адаптации тестов к новому функционалу из-за несвоевременного выявления потребности в этом. Уходит "в прошлое" проблема, а вместе с ней и ответственность за изменения, прошедшие мимо этапа адаптации автотестов. Возникает скорее не техническая проблема, а организационная, связанная со взаимодействием разработчиков и инженеров QA. И мотивацией делать правильно.
Наличие нескольких узлов, дружно выполняющих обработку разных версий системы, поможет решить эту проблему. Если у нас есть 5 рабочих узлов и для них хватает серверных ресурсов, то мы можем сказать что как один отдельный коммит, так и 5 коммитов будут обработаны за примерно одинаковое время. Согласитесь, предсказуемое время - это уже хороший результат.
Разные комбинации серверного ПО
Тестирование в несколько потоков может позволить решить еще одну более "продвинутую" задачу - проверку работоспособности на разных комбинациях серверного и программного обеспечения .
Например наша CI система (точнее система её сборки с помощью Packer и Vagrant) позволит быстро комбинировать различные версии платформы 1С, версии PostgreSQL. С чуть большими усилиями заменять версию ОС. Благодаря этому можно поднять несколько узлов-сборщиков с разными комбинациями ПО. Аналогично можно включить в эту схему и узлы на Windows c MS SQL, если у Вас хватает на это технических ресурсов.
Таким образом выполняя часть операций на одних узлах, а часть на других, в целом мы сможем охватить различные комбинации серверного ПО.
А зачем разные машины? Почему бы не разместить все узлы на одном сервере?
Если вы уже знакомы с Jenkins, о котором пойдет речь, но еще не знакомы со сценарным тестированием в 1С, том может возникнуть такой закономерный вопрос.
Дело в том, что узлы Jenkins - это просто процессы Java, которым выделены отдельные рабочие каталоги в файловой системе. Эти узлы общаются с управляющим мастер-узлом (тоже Java-процессом ) либо через стандартные потоки stdin/stdout , либо через ssh, либо через tcp. Технически нет никаких препятствий для того, чтобы разместить большое число узлов на одной и той же машине, в одной и той же операционной системе, запущенных под одним и тем же пользователем.
Более того, у каждого узла может быть несколько сборщиков. Каждый сборщик - это отдельный поток в рамках одного процесса Java. Для решения многих задач не нужно даже создавать отдельные узлы, а достаточно просто увеличить количество потоков-сборщиков. Мы даже применим такой подход для решения отдельных задач подготовки баз. Но применить такой подход для всего контура не получится из-за специфики сценарного тестирования.
Сценарное тестирование осуществляется через запуск как минимум двух сеансов 1С - тест-менеджера и тест-клиента. Их запуск приводит к появлению на экране клиентских окон 1С. Тест-менеджер делает так, что в тест-клиенте эмулируются интерактивные действия пользователя. При этом если запустить несколько процессов тестирования то
1) Они будут друг другу мешать - стабильность связи между каждой парой тест-менеджера и тест-клиента сильно снижается. Решение возможно, и хорошо описано здесь //infostart.ru/public/1182048. Но все же требуются дополнительные действия по "внешнему управлению" процессом выполнения тестов.
2) Если запустить несколько процессов в одном сеансе, то нельзя будет автоматически сделать правильный скриншот при возникновении ошибки. Будет невозможно разобрать к какому из процессов он относится - разные окна от разных сеансов 1С будут постоянно перекрывать друг друга.
Это особенность не только сценарного тестирования в 1С, но и любых механизмов, эмулирующих действия пользователя в графической среде.
Почему тогда нельзя запускать несколько разных сеансов на одном сервере? Задействовать RDP или VNC?
На самом деле можно ;)) Такой подход не только возможен, но и будет более эффективным с точки зрения скорости работы. Но есть несколько веских причин для того, чтобы выбрать для разделения сеансов 1С разные виртуальные машины, а не разные клиентские сеансы операционной системы.
1) Возможность быстро менять состав и настройки программного обеспечения, а затем быстро откатывать изменения, если они оказались неудачными. Подход с использованием разных клиентских сеансов в одной операционной системе не позволит этого делать. Альтернативным решением в этом случае может быть выделение еще одного "эксперементального" сервера. И если у Вас есть для этого ресурсы, то это тоже хороший вариант.
2) Простота разработки, отладки и воспроизведения CI на другом сервере. Иными словами - переносимость и масштабируемость механизмов как в большую так и в меньшую сторону. Систему, которую мы построим на виртуальных машинах, в минимальном варианте легко воспроизвести на машине любого разработчика или даже на домашнем компьютере. Это позволяет относительно просто отлаживать нужные механизмы и только после этого отправлять их в "боевой" CI-контур.
Для меня, как разработчика, это наиболее важная причина. И именно благодаря этому свойству я могу поделиться кодом, который может работать не только на специальной серверной машине, но и на Вашем компьютере.
3) Также мы получаем меньшую зависимость процессов разработки от внешних по отношению к команде разработки факторов. Например от штатных администраторов компании ;)) Далеко не всегда системные администраторы и их руководство заинтересованы в процессах разработки 1С. Необходимость бегать по кабинетам, делать заявки в Сервис-Деск и описывать почему вам нужно "нарезать" еще одну виртуалку на общем хостовом сервере компании, затем описывать какие права и кому на ней выделить, затем ждать пару дней, недель, месяцев….. Это конечно закаляет физически и морально. Но всё же хочется этого избежать. Однажды выделенный под цели CI сервер достаточной мощности позволит системным администраторам надолго про вас забыть ))
4) При работе на одной машине налагается гораздо больше ограничений на автора сценарных тестов. Это связано с отсутствием изолированности параллельных процессов тестирования друг от друга. Файловая система и СУБД будут общими и уже нельзя будет использовать один предопределенный каталог для работы с файлами. Нужно будет обеспечивать уникальность имён файлов, каталогов, имен баз данных на сервере СУБД и уникальность прочих ресурсов в общей среде.
5) И последний по порядку, но не по важности фактор - легкость очистки ресурсов. Организовать-что то вроде блока finally на узлах CI очень сложно. Ведь на них мы ловим ошибки, а одной из ошибок может быть зависание процесса. Да и сам узел вполне может "отвалиться" в середине исполнения пайплайна. Потребуется регулярно чистить общую СУБД от неудаленных из-за зависания процессов баз. Решать вопрос переполнения диска на общем сервере. Чистить кэши…... Всё это - сомнительное удовольствие.
При применении виртуальных машин разрубить этот гордиев узел можно всего одним кликом мыши - запустив процесс пересоздания узла. И через 5 минут у нас будет чистый узел CI-сервера.
Но ведь виртуальные машины на программных гипервизорах тормозят!
Да, очень сильно. Замедление интерфейсных механизмов платформы 1С может быть существенным, а сценарное тестирование - это в первую очередь интерфейсные механизмы. В данном случае эта проблема может быть решена добавлением новых узлов в CI-контур, что позволит получить хоть и меньшую, но всегда прогнозируемую скорость и время обработки каждой закладки в хранилище или коммита в git-репозиторий.
Если приведенные выше аргументы про переносимость и независимость механизмов CI не покажутся Вам достаточными, чтобы предпочесть "виртуалки", и при этом у вас есть ресурсы на построение аналогичной системы на базе физических машин или Вы можете организовать систему на основе подключений RDP или VNC к одному серверу, то конечно используйте эту возможность.
В этом случае приведенная далее информация может быть взята как основа для построения собственных механизмов или, если они у Вас уже реализованы, для внесения в них каких-то полезных изменений.
Структура CI в деталях
Схема, которую я предлагаю Вам рассмотреть, отличается от того, что можно найти в других источниках и сначала может показаться излишне усложненной. Всё дело в том, что в большинстве случаев описываются подходы, с которых вы можете начать думать над CI или эксперементировать с небольшими конфигурациями. Есть даже вполне здравый совет не начинать разработку с многопоточности и сложных схем: //infostart.ru/public/1198146, и вообще, начинать с дымовых тестов.
Если Вы новичок и проходите весь путь самостоятельно, то это оправданный совет. Но ведь цель этих публикаций - сделать так чтобы Вы не проходили этот путь в одиночку и не собирали все "грабли", которые лучше обойти )) Кроме того, предполагается возможность применения CI для больших конфигураций вроде КА 2 и ERP 2 в условиях ограниченных серверных ресурсов.
Также, я бы не рекомендовал при наличии качественной информации на тему сценарного тестирования начинать с дымовых тестов. Видел уже две компании, где на этом путь в CI и был закончен, с постановкой той самой булшит-галочки "автотестирование у нас уже есть", хотя на самом деле его не было и в помине. Сделайте то, что действительно проверяет работу пользователя, а дым как раз лучше оставить на потом. Хотя это конечно мой личный опыт, и если Вы считаете, что нет риска остановиться на полпути, то этот совет можно пропустить.
Давайте посмотрим на предлагаемую схему, попробуем понять почему она такая и в каких случаях её можно упростить. Заодно рассмотрим несколько тонкостей и рецептов построения отдельных блоков.
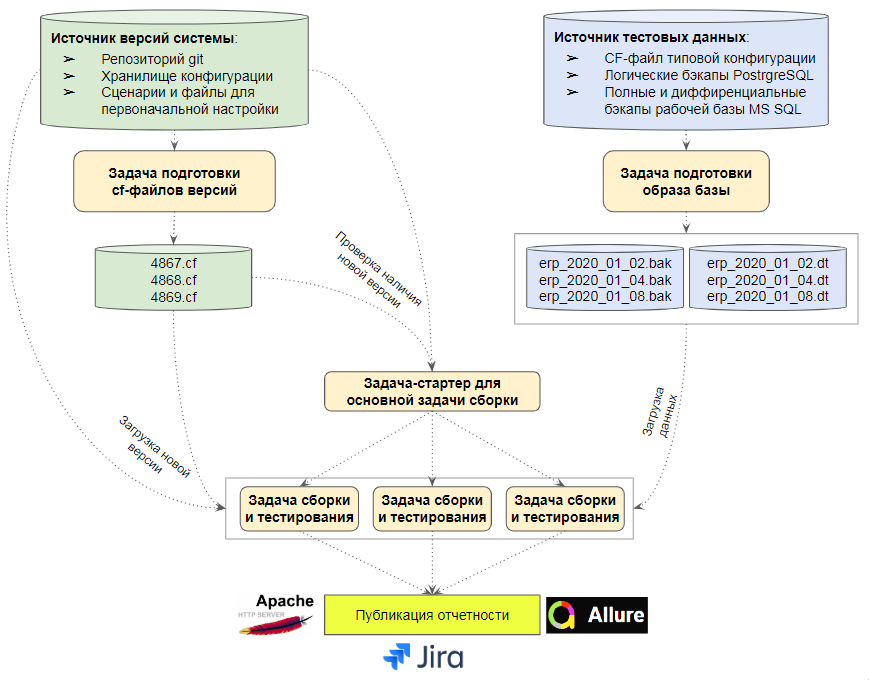
Задача подготовки образа тестовой базы
Справа на схеме обозначена задача, которая готовит образ базы для тестирования. В зависимости от того, на основе каких данных мы хотим выполнять процессы, входными данным для нее могут быть:
- Бэкап рабочей или демо-базы MS SQL.
- Логический бэкап рабочей или демо-базы PostgreSQL
- CF-файл типовой конфигурации
- Демо-база типовой конфигурации.
- Другие варианты исходных данных.
Результатом ее работы может быть
- bak-файл с архивом базы MS SQL
- или например DT-файл выгрузки базы,
- или логический бэкап PostgreSQL.
Цель существования этой задачи - максимально ускорить развертывание тестовой базы при начале выполнения основного пайплайна на CI. Главное требование - полученный архив базы можно достаточно быстро развернуть и подготовить к выполнению сценариев. Дело в том, что развертывание копии рабочей базы или подготовка базы из CF-файла может занять огромное количество времени.
Например, при использовании для тестирования бэкапов рабочих баз главная проблема может быть в занимаемом базой месте на дисках. Поэтому потребуется:
- В случае с MS SQL переключить модель восстановления на простую (SIMPLE), сделать шринк логов транзакций.
- В случае PostgreSQL сделать таблицы нежурналируемыми (UNLOGGED). На CI для 1С база не обязательно должна переживать аварийное падение сервера - она просто создаётся заново при каждой сборке. При необходимости обеспечить сохранность таблиц даже при перезагрузках можно просто корректно завершая работу сервера и операционной системы.
- Очистить базу от версий объектов и прикрепленных файлов.
- Удалить нулевые записи в таблице итогов.
- Сжать базу данных, причем не выполняя последующую операцию перестроения индексов.
- Заменить в базе данных пароли пользователей, создать администраторов информационной базы.
При подготовке базы из CF-файла необходимо
- Дождаться первоначального заполнения данных. На конфигурациях размера 1С:ERP этот процесс может выполняться до получаса.
- Выставить необходимые функциональные опции во всех подсистемах, заполнить календарные графики и графики работы, создать валюты и загрузить их курсы, выполнить прочие действия по наполнению базы минимальными данными.
- Создать администраторов базы данных.
- Меры по уменьшению вероятности разрастания базы, перечисленные для копий рабочих баз, могут иметь смысл и в этом случае. Но на небольших базах, созданных из CF-файлов, стоит соизмерять длительность таких "сервисных" операций с получаемым от них ускорением.
Все эти действия необходимо выполнить заранее. Затем результат обработки выгрузить в формат, пригодный для последующей быстрой загрузки. Загрузка будет выполняться в начале каждого запуска основной задачи (задачи, непосредственно выполняющей тестирование).
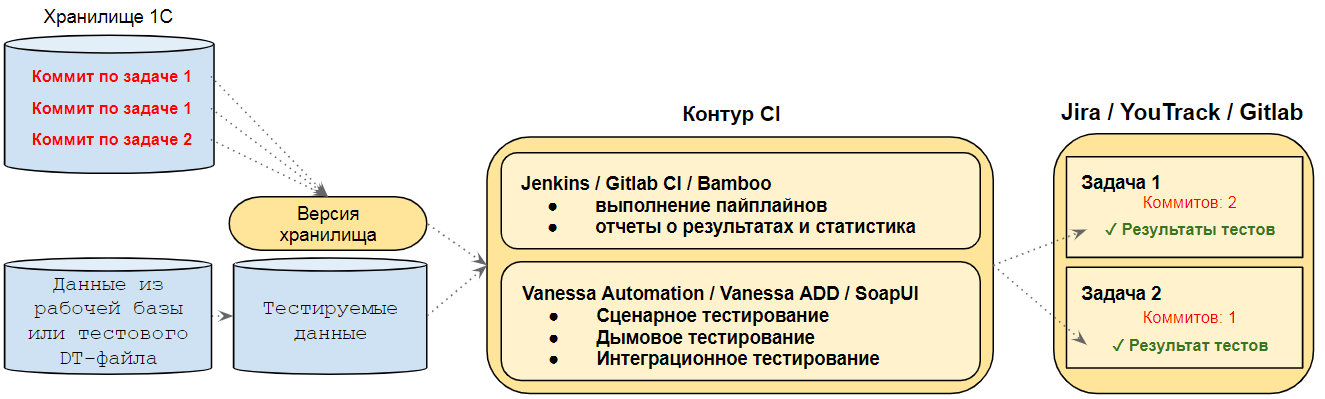
Задача выгрузки версий хранилища и задача определения необходимости запуска процесса тестирования
Эти две задачи обозначены на схеме слева и в центре. Для того, чтобы понять их назначение, рассмотрим варианты загрузки версии хранилища в тестовую базу.
1) Напрямую из хранилища
Развернув тестовую базу из заранее подготовленного образа мы загружаем в нее конфигурацию обращаясь напрямую к серверу хранилища конфигураций. В этом случае загрузка происходит там же где выполняются остальные процессы сборки. Задача-стартер периодически проверяет появление новой версии в хранилище и когда обнаруживает новую версию - запускает основную задачу сборки.
Это самый быстрый с точки зрения получения версии хранилища вариант. Но он имеет серьезный недостаток - для загрузки необходимо открывать базу в конфигураторе той же версией платформы, на основе которой работает сервер хранилища. Попытка открыть хранилище в другой версии приведет к сообщению о том, что версия клиента отличается от версии сервера. Таким образом мы лишаемся возможности выполнять тестирование на другой версии платформы.
В Windows это можно решить установив несколько версий платформы 1С. Но если база клиент-серверная, то придется еще и держать сервер другой версии на других портах. Прописать в нем ту же самую базу и фактически запускать одну и ту же базу, подключаясь к ней из разных кластеров 1С. Это резко снижает удобство от наличия нескольких версий платформы 1С в одной операционной системе. Усложняет пайплайны. Да и несет дополнительные риски для стабильности всей системы.
В Linux также есть возможность воспользоваться иной версией платформы. Например поместить ее в докер-контейнер или отдельную виртуальную машину, но это потребует решения отдельного круга задач. Подобных сложностей лучше избегать, они могут привести к нестабильности системы и запутанности алгоритмов.
В общем этот, вариант подходит в одном случае - если проверки системы выполняются на той же версии платформы 1С на которой работает хранилище, и вам никогда не понадобится постепенный переход на новую версию платформы.
2) Загружать из гит-репозитория исходников , куда хранилище предварительно выгружается через Gitsync или Гит-Конвертер
Это наиболее красивое решение. Оно позволило бы избавиться от задачи-стартера и задачи выгрузки хранилища. Хранилище просто выгружается в git-репозиторий. Тот же, который используется для загрузки данных в Fisheye, Upsource, Gitlab, код ревью и отображения изменений по задачам в таск-трекере.
Однако такое решение обладает другим серьезным недостатком. Платформа 1С всё-таки ориентирована на работу с бинарными форматами, в которых хранятся исходные коды конфигурации. Наиболее серьезно это сказывается на скорости загрузки. Время загрузки из CF-файла может отличаться от времени загрузки из XML-файлов десятикратно. Если загрузка из cf-файла может занять 2 минуты , то полная загрузка той же конфигурации из xml может занять 20 минут. На небольших конфигурациях вроде "Управления торговлей" это не критично. Но если речь идет об "ERP" то подобное замедление оказывается неприемлемым для тестирования каждого коммита.
Выходом из ситуации могла бы быть инкрементальная загрузка, но она не работает при добавлении новых объектов конфигурации, удалении объектов, значений перечислений и ряде других случаев. В итоге почти при каждом серьезном изменении конфигурации начинается ее полная выгрузка и загрузка. А вместе с ней и конфигурации поставщика. На больших конфигурациях очень хорошо чувствуется, что платформа пока не готова к быстрой работе с git.
3) Предварительно готовить cf-файлы, выгружая в них каждую версию хранилища
Вместо выгрузки версий хранилища в git мы выгружаем их в отдельный каталог в cf-файлы с отдельного узла с нужной версией платформы 1С. В начале процесса тестирования выполняется их загрузка в тестовую базу, а при завершении - удаление или перемещение (публикация) на сетевой диск. Удаление необходимо чтобы не занять всё свободное место на дисках этими выгрузками.
При таком подходе выгрузка хранилища должна производиться под той же версией платформы на которой работает сервер хранилища конфигураций. Но в этом случае мы обеспечиваем полную независимость узлов друг от друга. Выгрузку будем выполнять с одного узла, сборку и тестирование - на другом узле. Единственное что должно быть общего у этих узлов - это доступный им сетевой каталог, через который они будут обмениваться CF-файлами.
Задача выгрузки в нашем случае будет "однопоточной" - в настройках CI мы явным образом запретим выполнять более одной такой задачи одновременно. Это нужно чтобы упростить вычисление следующей версии, подлежащей выгрузке, и обеспечить последовательную обработку версий хранилища.
Как выбрать из трех вариантов?
В зависимости от целей развертывания CI-контура можно выбрать тот или иной подход.
- Вам важна возможность тестировать механизм на любой версии платформы, независимо от того, на какой платформе работает хранилище конфигурации? Сохранение приемлемой "средней" скорости загрузки-выгрузки? Тогда следует выбрать вариант с предварительной выгрузкой версий из хранилища.
- Вам важна максимизация скорости загрузки версии хранилища в развертываемую базу? Тода следует выбрать вариант прямой загрузки из хранилища. Понимая при этом, что на другой версии платформы просто так тест не запустить.
- Нужна максимальная универсальность с технологической точки зрения и максимальная простота CI-контура? Возможность запускать сборку по триггеру через гит-хуки или через регулярный опрос репозитория на предмет изменений? Общие механизмы с CI для других платформ, отличных от 1С? В этом случае ваш выбор - работа через git и предварительную выгрузку хранилища в xml.
- А можно сделать систему, позволяющую переключаться между этими вариантами ;))
Наш CI ориентирован на ускорение обработки хранилища при работе с большими конфигурациями. Поэтому мы не будем работать с выгрузкой хранилища в git. Но выбор между двумя другими вариантами будет. В зависимости от его настроек будет использоваться либо прямая загрузка из хранилища, либо загрузка из предварительно подготовленных CF-файлов.
У нас будет отдельная задача, выгружающая заданное в настройках максимальное количество версий хранилища в CF-файлы. Файлы будут удаляться по завершению их обработки задачей тестирования. После этого задача выгрузки приступит к выгрузке очередных версий хранилища. В зависимости от тех же настроек, задача запускающая процесс основной сборки будет проверять наличие следующей доступной версии либо среди выгруженных файлов, либо непосредственно в хранилище. Если согласно настройкам версия должна загружаться непосредственно из хранилища, то в задаче выгрузки нет смысла и ее можно просто выключить в настройках CI-сервера.
Если же Вы работаете с git, то я уверен, что при желании Вы сможете доработать этот механизм и сделать настройку, при которой вместо CF-файла будет использоваться git-репозиторий. Но и последствия этого при работе с большими конфигурациями надо понимать.
Основная задача сборки и тестирования
Итак, у нас есть каталог со "слепками" баз, для тестирования в виде DT- или bak- или sql-файлов. Есть также каталог с выгруженными в него версиями хранилища. Есть задача-стартер, определяющая факт появления нового объекта для тестирования - следующей доступной для обработки версии хранилища. Остается только выполнить основной процесс.
Для этого предназначена основная задача. Ее входными параметрами является
- версия, подлежащая тестированию,
- и информация о том, откуда ее брать - загружать непосредственно из хранилища или из CF-файла.
Делает она следующее:
- Находит последний доступный образ базы (по дате изменения или по имени файла) ,
- Разворачивает базу
- Загружает в нее версию хранилища.
- Выполняет завершающие действия по настройке базы, которые невозможно было сделать на этапе подготовки образа:
- создает пользователей со специфичными ролями, которых нет в типовой конфигурации, но есть в доработанной
- запускает генерацию основных тестовых данных, используемых в основных сценариях.
- Затем выполняет основные действия, связанные с тестированием.
- Публикует результаты в виде отчетности, по которой легко найти причину ошибки и понять общее состояние системы.
Распределение задач по узлам
Задачу подготовки образов тестовых баз лучше запускать на узлах, где установлена та же версия платформы 1С, на которой будет выполняться основная задача сборки и тестирования. Обеим этим задачам требуется запускать тест-клиент и тест-менеджер, выполнять команды открытия внешних обработок и прочие подобные действия. При этом для получения эффекта "многопоточности" в том виде, который описан выше, нам потребуется как минимум два таких узла.
Задачу "стартер" и задачу выгрузки версий хранилища можно расположить на одном отдельном узле. Эти две задачи связывает то, что они обязаны корректно читать данные из хранилища конфигураций и при этом не запускают клиентов 1С для эмуляции интерактивных действий (с появлением окошек).
Итого мы получаем минимум три узла для которых потребуются виртуальные машины. Увеличивать их количество можно по потребности и исходя из возможностей хостовой машины.
Вероятно начиная с какого-то их количества придется поработать над распараллеливанием задачи выгрузки из хранилища и возможно даже распределением его по разным физическим машинам. Так как если узлов, выполняющих основную задачу сборки и тестирования будет много, но хостовый сервер будет справляться с нагрузкой и успевать быстро выполнять задачи сборки, то процесс выгрузки из хранилища начнет отставать от процесса тестирования.
Инструменты
Зоопарк! Это первая мысль которая может возникнуть у специалистов 1С, начинающих изучение этой темы. И это вполне понятная мысль, учитывая что за годы работы мы привыкаем к "железному занавесу", который сами себе устраиваем. И распространенному подходу "всё что написано для 1С должно быть написано на 1С", который защищает нас от веяний моды в других областях IT.
В то же время я буду далеко не первым, кто призывает имея в руках только молоток всё таки не забивать им шурупы, а лучше обзавестись ящиком с набором более подходящих инструментов и научиться ими пользоваться. Ну в самом деле, это же не ракеты в космос запускать! ;))
При этом мы не будем пытаться закрутить шуруп одновременно двумя отвертками. Когда задачу можно удобно решить применяя только один инструмент и этот инструмент уже предназначен для решения задач такого класса , то использовать второй такой же нет смысла. Если задачу обработки текста и файлов можно решить только специально предназначенными для этого POSIX-инструментами, присутствующими в любой Linux-системе, то напишем решение исключительно с помощью них. Если мы уже используем код на Groovy чтобы вызвать команды bash и обращаться к CLI конфигуратора, то мы не будем прикручивать к этому дополнительные скриптовые движки и инструменты.
Это позволит сократить количество применяемых инструментов, оставив среди них только самые распространенные и богатые документацией системы.

Пожалуй самым спорным моментом в нашем наборе инструментов будет наличие в нем Linux, как основы для узлов CI-сервера. В большинстве случаев пользователи 1С работают на Windows и поэтому тестирование было бы более релевантным при его выполнении в Windows. Так зачем нам Linux?
Первое что приходит в голову - его бесплатность. Но, бесплатность ОС здесь ни причем. Посмотрите этот доклад:

Краткая суть в следующем. Правила лицензирования Windows, и в частности Windows Server, позволяют полноценно использовать их на CI, при применении Packer и Vagrant. Windows в этом случае будет полноценно функционировать на протяжении всего триального периода. А затем будет как птица-феникс, уничтожаться и появляться снова с теми же настройками. Добавьте к этому наличие полнофункционального MS SQL Server Developer Edition, который может без ограничений использоваться в средах разработки и тестирования, и получим нужный нам фундамент для CI совершенно бесплатно.
И после этого добавьте тот факт, что клиентская часть 1С оптимизирована под Windows. Взаимодействие тест-клиента и тест-менеджера также быстрее происходит в Windows. Тему производительности мы ещё затронем в будущем, но вот например замеры времени выполнения двух одинаковых сценарных тестов на стороне тест-менеджера в Windows и Linux. Обратите внимание на последнюю колонку. В Windows самые ресурсоемкие методы выполняются быстрее на 30%, при том , что в данном случае у виртуальной машины с Windows было даже чуть меньше свободных ресурсов. Такие результаты у меня воспроизводятся стабильно, независимо от состава ПО, хостовой машины или графического окружения на Linux:
Windows 10 :

Linux Ubuntu 19 :
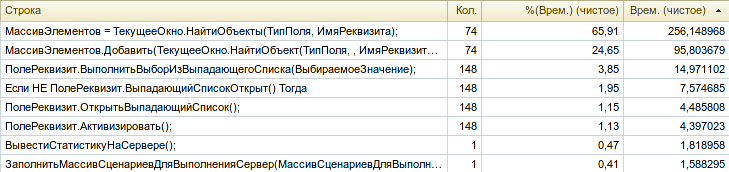
Здесь важно понимать, что не только выполнение сценарных тестов вносит существенный вклад в общую продолжительность процессов, выполняемых на CI-контуре. Поэтому разница в скорости выполнения тестов сглаживается примерно одинаковым временем работы серверной части 1С при выполнении тяжелых операций вроде выгрузки-загрузки базы.
Что же, назвав причины, по которым Linux не стоит выбирать, стоит назвать и причины по которым мы его всё таки выбираем )) Они следующие:
- Исходный размер узла CI (виртуальной машины) с Linux и PostgreSQL более чем в 4 раза меньше, чем с Windows и MS SQL И также машине с Linux нужно меньше оперативной памяти. Это очень важно при размещении всех узлов на одной хостовой машине.
И еще более важно в процессе его разработки, который вы будете вести скорее всего на более слабой машине. Мало создать CI, в него ведь нужно ещё вносить изменения, а их перед этим нужно где-то отладить. Не на боевых же серверах это делать. И если Вы можете вести разработку на обычном рабочем или домашнем компьютере, который совсем не тянет на звание "сервера", то это большое удобство.
Переносимость CI-контура между различными хостовыми машинами, в том числе с невысокими системными характеристиками - это главная причина выбора Linux.
- Несмотря на то, что узлы с Windows можно легко пересобирать, в случае с Linux в этом вообще нет необходимости. Это скорее фактор комфорта - не нужно вообще думать о пересборке по расписанию, а выполнять её только при необходимости изменить состав программного обеспечения.
- Только что развернутая виртуальная машина с Windows больше озабочена своим обновлением, чем выполнением задач сборки и тестирования 1С. Попробуйте развернуть её и посмотреть в мониторе ресурсов, чем она занимается )) То есть время от развертывания узла CI-контура с нуля до его полной готовности у Windows хоть немного, но больше.
- Гибкость инструментов командной строки Linux. Аналогичная PowerShell, но без PowerShell ;)) Даже работа с RAS и RAC становится удобной без привлечения каких-либо сторонних инструментов. Удалить заданную базу в кластере? Создать новую базу? Для этого достаточно однажды сохранить в переменные идентификаторы кластера и базы, после чего выполнить всего пару команд RAC:
CLUSTER_ID=$(rac addr cluster list | grep -B1 ' addr ' | head -1 | tr -d ' ' | cut -d ':' -f 2)
DB_ID=$(rac addr infobase --cluster $CLUSTER_ID summary list | grep -B1 ' dbname' | head -1 | tr -d ' ' | cut -d ':' -f 2)
Теперь удаляем базу, создаем новую, выполняем любые другие команды, связанные с нашей базой или кластером:
rac addr infobase --cluster $CLUSTER_ID drop --infobase=$ DB_ID
rac addr infobase --cluster $CLUSTER_ID create --create-database --name=dbname --dbms=PostgreSQL --db-server=addr --db-name=dbname --locale=ru --db-user=user --db-pwd=passwd
- Наличие практики работы с Linux позволит затем двинуться дальше и делать ещё более легковесные механизмы на Docker. Можно конечно упомянуть про наличие Docker на Windows, но меня пугают эти гигабайтные контейнеры )) В то же время Linux-контейнеры на Windows требуют всё тех же знаний, что и сама операционная система.
- Подавляющее большинство пользователей и серверов 1С работают на Windows. В то же время если вы разрабатываете тиражное решение или просто не хотите вендор-лока в своей компании, а разработка сейчас также ведется под Windows + MS SQL, то какую среду лучше выбрать для тестирования, чтобы не потерять универсальности?
- Есть еще один момент. Я ни в коем случае не призываю вас так делать и, конечно, сам не делаю. Но клиент-серверный вариант платформы 1С для Linux технически позволяет запускать до 12 клиентских сеансов без серверной лицензии, что очень удобно для CI. Клиентские лицензии конечно нужны. Но для нужд функционального тестирования фактически хватает от 2-ух до 4-ех клиентских подключений на одном узле CI-контура. Не делайте так )
В качестве дистрибутивов выберем последние релизы Ubuntu Server, хотя для 1С сейчас заявлена поддержка только Ubuntu 16.04. Почему последние? Ну хотя бы потому что это работает )) Также это позволит посмотреть с какими особенностями можно столкнуться при установке 1С и PostgreSQL с патчами для 1С на последних релизах операционных систем. Мы строим CI, а одним из его назначений может быть обкатка новых версий серверного программного обеспечения.
Образы виртуальных машин будем строить на основе 19.04 Disco Dingo и 19.10 Eoan Ermine.
Сверху на Ubuntu Server будем ставить графическое окружение Gnome. Для целей CI самым подходящим является окружение LXDE, которое очень быстро устанавливается и потребляет несравненно меньше ресурсов чем Gnome. Однако Gnome будет проще для начала работы с Ubuntu и по нему как правило быстрее найти информацию в случае затруднений в работе, поэтому будем использовать его.

MS SQL уже давно работает на Linux, но версия сервера 1С под Linux на момент этой публикации физически не умеет работать с MS SQL. Выбирать DB2 или Oracle было бы странно. В то же время PostgreSQL хорошо себя зарекомендовала в мире 1С и популярность её постоянно растет.
Также Постгрес больше соответствует остальному ПО, из которых состоит наша система - имеет открытый код, для 1С есть бесплатная сборка, документации много (особенно рекомендую по-настоящему замечательные обучающие материалы с сайта компании Postgres Pro). Поэтому для клиент-серверного варианта в Linux мы выберем именно эту СУБД.
Пожалуй, основной вопрос в этом случае - почему бы просто не выбрать файловую базу? Причин сразу несколько:
- Это менее релевантно условиям работы рабочих баз. Некоторые ошибки на CI можно пропустить, если работать файловой базой. Особенно если они связаны с работой с файлами, внешними ресурсами или регламентными заданиями.
- Возможно это не является общей проблемой, но на моих инсталляциях файловые базы на Linux продержавшись несколько дней в рабочем состоянии затем постоянно падают по тем или иным причинам. На CI потребности в долгоживущих базах вообще-то нет. Но всё же не хотелось бы получать лишние оповещения об ошибках от него, связанные с падением файловых баз.
- CLI конфигуратора для работы серверными базами не на много сложнее, чем для файловых баз. При этом появляется возможность управлять базами через RAS/RAC и утилиту psql.
- Что если вы решите переключиться на тестирование на копиях рабочих баз? Если CI настроен на использование файловых баз, то адаптация под такое требование займет больше времени. Если код вашей системы 1С частично задаётся в пользовательском режиме, или настройки в рабочей базе постоянно меняются или применяются ещё какие-то характерные для 1С антипаттерны, то у Вас скорее всего не будет иного выхода, чем работать на копиях рабочих баз. Хорошо, когда у нас есть система, которая может выжить и в таких условиях ))

Здесь я не могу объективно обосновать свой выбор, которого в общем то и не было. Сейчас я знаком только с этим CI-сервером. Могу только сказать, что он действительно хорошо решает свою задачу и позволяет обеспечить описанную выше структуру CI-контура.
Jenkins обладает всё теми же важными свойствами - открытость, гибкость, бесплатность, много информации в сети. Имеет открытый баг-трекер, в котором иногда можно узнать что какая-то проблема решается уже годами, плюнуть на поиск её решения и вызывать команды bash, выполняющие нужные действия ;))


Конечно нам потребуется платформа 1С. И типовая конфигурация на БСП. Подойдет любая конфигурация на БСП, но меньше всего отличий от приводимых примеров будет, если вы сделаете выбор в пользу КА 2 / ERP 2 / УТ 11.
Почему мы берем конфигурацию на базе БСП? Потому что рассматривать примеры на пустой конфигурации просто некорректно.
Подавляющее большинство систем основано на типовых конфигурациях, которые в свою очередь имеют в составе БСП. Тестирование и подготовка баз, основанных на БСП имеет много особенностей и отличий от тех же действий на пустых или самописных базах. Поэтому ни о каких "самописках" с двумя документами и одним справочником не может быть и речи, даже для целей демонстрации.
Конечно примеры, основанные на типовых конфигурациях, устаревают быстрее, чем основанные на пустых самописках. Но если честно, всё устаревает, и уже через два года многое придется делать по другому ;))
В качестве платформы будут использоваться 8.3.15 и 8.3.16.

Apache на хостовой машине будет применяться для публикации отчетности о результатах выполнения тестов (в дополнение к тому, что мы можем увидеть в интерфейсе Jenkins).
Apache внутри CI-контура будет применяться для публикации SOAP и HTTP-сервисов 1С. Мы рассмотрим как автоматически опубликовать веб- и http-сервисы входящие в состав конфигурации 1С. Выполним простейший тест http-сервиса. Думаю это будет полезный пример.


Packer и Vagrant - это фактически Docker в мире виртуальных машин. Они разработаны компанией HashiCorp и имеют японское происхождение, впрочем как и Jenkins, основным разработчиком которого является компания CloudBees.
Применение Packer позволяет собирать образы виртуальных машин:
- Взять за основу iso-дистрибутив операционной системы.
- Развернуть из него операционную систему и настроить её.
- Выполнить установку основного программного обеспечения, которое должно быть общим для всех виртуальных машин.
- Упаковать полученный результат в образ, пригодный к быстрому развертыванию в гипервизорах.
В свою очередь Vagrant - это инструмент, позволяющий
- Взять такой образ с локального диска или из облака.
- Поднять на его основе любое количество виртуальных машин-клонов.
- Выделить под них ресурсы хостовой машины: процессор, ОЗУ, настроить сеть, настроить общие каталоги.
- Выполнить окончательную настройку машин, установить специфичное для конкретной машины программное обеспечение.
Создание образов, их последующее развертывание и настройка представлены в виде конфигурационных файлов. Таким образом Packer и Vagrant позволяют автоматизировать создание одинакового окружения, независимо от сервера, на котором Вы это делаете. И на рабочем CI-сервере и на домашнем компьютере можно в течение часа подготовить необходимые образы машин. И затем в течение 5-10 минут с помощью Vagrant одновременно запускать и включать их.
При этом можно регулировать выделение виртуальным машинам ресурсов хостовой машины непосредственно в момент их запуска через Vagrant. На мощном сервере выделять больше ресурсов, на слабом железе - меньше ресурсов. Это незаменимая возможность в процессе разработки самих механизмов CI, когда нельзя ломать экспериментами уже работающий CI-контур, но хотелось бы развернуть его клон на другом сервере и проверить все гипотезы на нем.
Оба эти инструмента являются своего рода "оберткой" над инструментами командной строки, предоставляемыми гипервизорами. То есть в большинстве случаев они позволяют сделать ровно то же, что и CLI предоставляемый нам самим VirtualBox, VMWare или Hyper-V. Но при этом во первых делают это относительно универсально. Замена одного гипервизора на другой не приведет к необходимости переписать все сценарии развертывания. Потребуется лишь небольшая адаптация. Во вторых упрощают и автоматизируют выполнение тех операций, самостоятельное выполнение которых потребовало бы очень много кода и знания множества деталей работы с конкретным гипервизором.
Если сравнивать с более популярным сейчас Докером, то Packer - это то, что реализует функционал похожий на docker build. Его файл настроек в формате JSON - это аналог Dockerfile. В свою очередь Vagrant - это что-то похожее на docker-compose и его Vagrantfile на языке Ruby - это что то похожее на yml-файл с настройками для docker-compose.
Vagrant - это более распространенный инструмент, чем Packer. Причина в том, что в облаке HashiCorp уже есть множество готовых образов, которые достаточно скачать и "поднять" вместе со всем входящим в них программным обеспечением. Во многих случаях конечным пользователям этого достаточно и в сборке своего образа у них нет необходимости. Но это не наш случай.
Даже если бы был образ с 1С и PostgreSQL он бы нам не подошел. Нам нужна возможность устанавливать различные версии платформы 1С и PostgreSQL, заменять версию ОС, устанавливать Apache или OneScript при необходимости. Для этого лучше не использовать готовые образы и не выполнять их настройку в момент запуска через Vagrant ( ведь это тот момент, когда результат нужен быстро, а не через час ), а собрать свой собственный образ через Packer.

При выборе гипервизора главный критерий - это бесплатность применения совместно со связкой Packer + Vagrant и меньшая зависимость от хостовой ОС. Под первый критерий подходят только VirtualBox и Hyper-V. Под оба - только VirtualBox. Про поддержку Вагрантом других систем можно прочитать здесь https://www.vagrantup.com/docs/providers
В плюсы VirtualBox можно также записать простоту использования, наличие опыта работы с ним у большинства ИТ-специалистов и большое число примеров использования VirtualBox для сборки образов через Packer.
Для стабильной работы с Ubuntu 19.10 нам потребуется версия VirtualBox не ниже чем 6.0.14. Более ранние версии отлично работают с Ubuntu 19.04, но при запуске тяжелых операций с 1С на Ubuntu 19.10 могут возникать зависания.
Конфигурирование хостовой машины
Чтобы в этот раз не останавливаться исключительно на теоретической части, выполним начальное конфигурирование хостовой машины, которой у нас будет являться Windows. Если Вы используете в качестве хостовой машины Linux, то команды надо будет адаптировать.
Итак, нам нужно установить на хостовой машине Git, Packer, Vagrant, VirtualBox, Jenkins, Apache, и Visual Studio Code, как основную среду разработки. Ссылки ведут на страницы, где эти инструменты можно скачать вручную. Но давайте оставим ручную установку тем, кто не занимается CI и не не смотрит в сторону автоматизации своей работы. Далее будет приведен способ их установки с помощью менеджера пакетов для Windows Chocolatey, что позволит избежать ручных действий и быстрее выполнять обновление программ в дальнейшем.
Важно! Убедитесь, что выполняемые команды безопасны для текущей конфигурации вашей машины. Например если у Вас уже установлен Apache, то команду его установки можно просто закомментировать. Для остального ПО применима та же рекомендация.
Команды мы будет писать для bat-файла. Думаю это сделает скрипт более доступным для большего числа специалистов. Но для установки самого менеджера пакетов потребуется запуск PowerShell-скрипта, расположенного на сайте chocolatey.org. Поэтому нужно будет запустить PowerShell через bat-команду с соответствующими параметрами.
Установочный скрипт сам изменит в настройках ОС значение переменной PATH, прописав в ней путь к бинарникам Chocolatey. Однако значение этой переменной не будет действовать для эмулятора терминала до его перезапуска. Чтобы избежать такого перезапуска , сразу после установки добавим в "локальную" переменную PATH эмулятора терминала путь к бинарным файлам Chocolatey:
@"%SystemRoot%\System32\WindowsPowerShell\v1.0\powershell.exe" -NoProfile -InputFormat None -ExecutionPolicy Bypass -Command "[Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::Tls12; iex ((New-Object System.Net.WebClient).DownloadString('https://chocolatey.org/install.ps1'))" && SET "PATH=%PATH%;%ALLUSERSPROFILE%\chocolatey\bin"
Теперь мы можем выполнять установку остального ПО вызывая короткую команду choco имя_пакета.
В репозитории Chocolatey для каждого пакета есть отдельная страница, где приводится пример команды, необходимой для его установки. И что не менее важно - параметров этой команды, позволяющей сконфигурировать приложение.
В качестве примера рассмотрим установку пакета Git и Apache, а для остальных программ будем действовать по аналогии. Вот адрес страницы с git: https://chocolatey.org/packages/git
На ней указаны нужные нам параметры:
- /GitAndUnixToolsOnPath - инструкция прописать в переменной среды PATH пути к инструментам командной строки Unix. Этот параметр необходим, чтобы потом использовать git , set, tee, tail и т.д. без указания полного пути к ним. Его указывать обязательно.
- /NoAutoCrlf - я обычно устанавливаю этот параметр в системе глобально, чтобы не было "самодеятельности" со стороны git, связанной с перекодировкой файлов, с которыми ведется работа одновременно и на Windows и Linux. В сети можно встретить противоположную рекомендацию - наоборот устанавливать настройку autocrlf глобально, а при необходимости отключать ее для отдельных репозиториев. В общем при выборе этой настройки на уровне всей системы всё сводится к личным вкусам )) Для нашего репозитория эта настройка должна быть обязательно установлена. Поэтому либо укажите этот ключ при установке git , либо внутри репозитория выполните git config --local core. autocrlf false.
Также при установке пакетов через choco есть два важных аргумента:
- -y - автоматически отвечать да на вопросы в ходе установки. Если не указать этот ключ, то вычислив необходимые ресурсы для установки менеджер пакетов будет задавать вопрос " Вы действительно точно на самом деле хотите установить этот пакет ?" ;)) В общем этот ключ необходимо указывать, если мы хотим выполнять установку без взаимодействия с менеджером пакетов.
- --force - ключ, который принуждает менеджер Chocolatey переустановить пакет в том случае, если он уже установлен. Его мы также будем использовать, так как при переустановке на выделенной под цели CI машине не должно быть проблем, а если вы ведете разработку на своем компьютере, то лучше просто закомментировать лишние команды.
Таким образом команда установки git выглядит так:
choco install git --params "/GitAndUnixToolsOnPath /NoAutoCrlf" -y --force
После выполнения подобных команд менеджер пакетов кэширует скрипты установки и пакеты частично во временных файлах, частично в каталоге C:\ProgramData\chocolatey\lib, это необходимо для дальнейшего управления пакетами, их удаления или обновления . В то же самое время сама установка выполняется по "обычному" для приложений пути, если в параметрах установки не указано иного:
Для ряда пакетов можно указывать их версии и я буду это делать для некоторых из них, так как стабилизировав механизм на какой-то версии имеет смысл устанавливать именно её, а эксперименты с новыми версиями выполнять отдельно. В то же время для ряда пакетов это не имеет смысла. Они достаточно стабильны и крайне маловероятно, что их обновление может привести к сбою. Чтобы упростить указание версий будем сохранять их в переменные окружения и затем подставлять в команды. Например:
SET APACHE_VERSION=2.4.41
Настройка Apache на хостовой машине вовсе не обязательна. Мы будем использовать его для вывода отчетов о результатах проверки системы на 1С в "публичный доступ", но есть и более простые способы добиться той же цели через публикацию непосредственно из интерфейса Jenkins. Тем не менее предлагаю рассмотреть установку Apache, так как это хороший пример использования менеджера пакетов Chocolatey.
Для Apache есть важный параметр - каталог установки: /installLocation: каталог_установки
В указанном каталоге будет создан подкаталог Apache24 и в нем уже размещен пакет Apache. То есть если мы хотим, чтобы Apache разместился в каталоге C:/Apache24 , то в параметре installLocation нужно указать C:/
Также нужно учесть, что конфигуратор 1С при публикации конфигурации на веб-серверах ищет их по имени службы. Поэтому если мы не хотим потерять возможность выполнять публикацию конфигураций на веб-сервере Apache через конфигуратор 1С, то нужно задать подходящее для этого имя службы. Сделать это можно передав параметр установки /serviceName:Apache2.4
Таким образом команда установки Apache будет выглядеть следующим образом
SET APACHE_PARENT_DIR=C:/
SET APACHE_PORT=80
SET APACHE_VERSION=2.4.41
choco install apache-httpd --version=%APACHE_VERSION% --params '"/serviceName:Apache2.4 /installLocation:%APACHE_PARENT_DIR% /port:%APACHE_PORT%"' -y --force
Остановимся теперь на Jenkins. Установить этот CI-сервер мы можем простой командой:
choco install jenkins -y --force
Более подробно конфигурирование Jenkins мы разберем в отдельных публикациях, но один из его параметров лучше изменить непосредственно в момент установки. Параметр, о котором идёт речь - это командная строка запуска Jenkins. С помощью нее нам нужно включить работу с кодировкой UTF-8 и разрешить выполнение "небезопасного" с точки зрения Jenkins кода.
Исполнение небезопасного кода понадобится для задания максимального времени выполнения (таймаутов) отдельных операций в пайплайнах Jenkins и корректной обработки этих таймаутов.
Использование кодировки UTF-8 нужно как минимум по двум причинам:
- Для того, чтобы работать с файлами логов платформы 1С. Для этого и мастер-узел Jenkins на хостовой машине, и подчиненные узлы на виртуальных машинах должны работать с кодировкой UTF-8. Запускать с этой кодировкой только подчиненные узлы, непосредственно взаимодействующие с платформой 1С будет недостаточно, так как многие данные на CI-сервере проходят через управляющий мастер-узел.
- Если мы хотим задавать имена этапов сборки на русском языке, то необходимо чтобы мастер-узел на нашей хостовой машине работал с кодировкой UTF-8.
Если эти слова пока Вам мало о чем говорят, то не волнуйтесь, эти вопросы еще будут подробно разобраны далее. Сейчас лучше поближе познакомиться с утилитой sed, с помощью которой мы не раз будем редактировать конфигурационные файлы.
Утилита sed входит в пакет git и установилась на наш компьютер вместе с ним благодаря опции /GitAndUnixToolsOnPath. После того как мы закроем консоль и откроем ее заново команду sed можно будет вызывать без указания к ней полного пути. Но сейчас придется либо снова установить переменную PATH вручную, либо указать полный путь к утилите sed. Выберем второй вариант.
Сразу после установки нам становятся доступны конфигурационные файлы Jenkins и управление его службой. Нам нужно отредактировать конфигурационный файл, отвечающий за запуск Java-процесса, который представляет из себя мастер-узел. Сама служба Jenkins на Windows представлена exe-файлом. Но он при запуске читает файл C:\Program Files (x86)\Jenkins\jenkins.xml. В нём она находит в нем тег arguments и запускает Java-процесс с указанными в нем параметрами. Нам нужно чтобы одним из этих параметров была строка -Dfile.encoding=UTF-8. Ещё одним параметром нужно включить плагин Jenkins, делающий настройки безопасности более мягкими: -Dpermissive-script-security.enabled=true :
Если не добавить строку -Dfile.encoding=UTF-8, то даже несмотря на запуск агентов Jenkins с кодировкой UTF-8 в логах на стороне мастера мы будем видеть некрасивый вывод:

Изменить эти параметры запуска Java-процесса можно выполнив нехитрую команду sed с ключем -i (заменить исходный файл) и указанием того, какую строку на какую нужно заменить. Мы заменяем строку <arguments>- на строку
<arguments>-Dfile.encoding=UTF-8 -Dpermissive-script-security.enabled=true -
После чего перезапускаем службу Jenkins:
SET JENKINS_INSTALL_PATH=C:\Program Files (x86)\Jenkins
"C:\Program Files\Git\usr\bin\sed.exe" -i "s/<arguments>-/<arguments>-Dfile.encoding=UTF-8 -Dpermissive-script-security.enabled=true -/" "%JENKINS_INSTALL_PATH%/jenkins.xml"
"%JENKINS_INSTALL_PATH%/jenkins.xml"
net stop Jenkins
net start Jenkins
Что же, думаю этих примеров достаточно, чтобы можно было разобраться с остальной частью установочного скрипта. Поэтому привожу его полностью:
chcp 65001
SET JENKINS_INSTALL_PATH=C:\Program Files (x86)\Jenkins
SET APACHE_PARENT_DIR=C:/
SET APACHE_PORT=80
SET APACHE_VERSION=2.4.41
SET VIRTUAL_BOX_VERSION=6.0.14
@"%SystemRoot%\System32\WindowsPowerShell\v1.0\powershell.exe" -NoProfile -InputFormat None -ExecutionPolicy Bypass -Command "[Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::Tls12; iex ((New-Object System.Net.WebClient).DownloadString('https://chocolatey.org/install.ps1'))" && SET "PATH=%PATH%;%ALLUSERSPROFILE%\chocolatey\bin"
choco install vscode -y --force
choco install virtualbox --params "/NoDesktopShortcut" --version=%VIRTUAL_BOX_VERSION% -y --force
choco install packer -y --force
choco install vagrant -y --force
REM По умолчанию через choco инструменты HashiCorp ставятся в каталог C:\HashiCorp, создадим подкаталог для боксов прямо в нем
mkdir C:\HashiCorp\vagrant_home
choco install git --params "/GitAndUnixToolsOnPath /NoAutoCrlf" -y --force
choco install apache-httpd --version=%APACHE_VERSION% --params '"/serviceName:Apache2.4 /installLocation:%APACHE_PARENT_DIR% /port:%APACHE_PORT%"' -y --force
choco install jenkins -y --force
"C:\Program Files\Git\usr\bin\sed.exe" -i "s/<arguments>-/<arguments>-Dfile.encoding=UTF-8 -Dpermissive-script-security.enabled=true -/" "%JENKINS_INSTALL_PATH%/jenkins.xml"
net stop Jenkins
net start Jenkins
На этом сделаем первые коммиты в репозиторий на Гитлаб, его копию на Гитхаб, и перейдём к следующей части - детальному рассмотрению Packer и созданию образов виртуальных машин.
Вступайте в нашу телеграмм-группу Инфостарт