Добрый день! Меня зовут Владимир Бондаревский, я работаю в Яндекс.Маркете, занимаюсь разработкой рекомендательных систем.
О себе и Яндекс.Маркете

Пару слов о себе. Достаточно длительное время проработал в фирме «1С», успел сделать много интересных полезных штук.
С 2017 года работаю в Яндекс.Маркете, занимаюсь разработкой рекомендательных систем.

Думаю, не нужно рассказывать, что такое Яндекс.Маркет. Это, наверное, все знают.
Немного цифр:
- это сотни миллионов предложений от магазинов;
- более 2 миллионов пользователей в день;
- 30 миллионов уникальных наименований товаров.
В таком объеме информации очень трудно найти что-то нужное для пользователя. Единственная надежда – на поиск и на рекомендации.
Рекомендации в Яндекс.Маркете
Так как я занимаюсь рекомендациями, расскажу пару слов об этом.
Даже самые простые рекомендации увеличивают продажи.
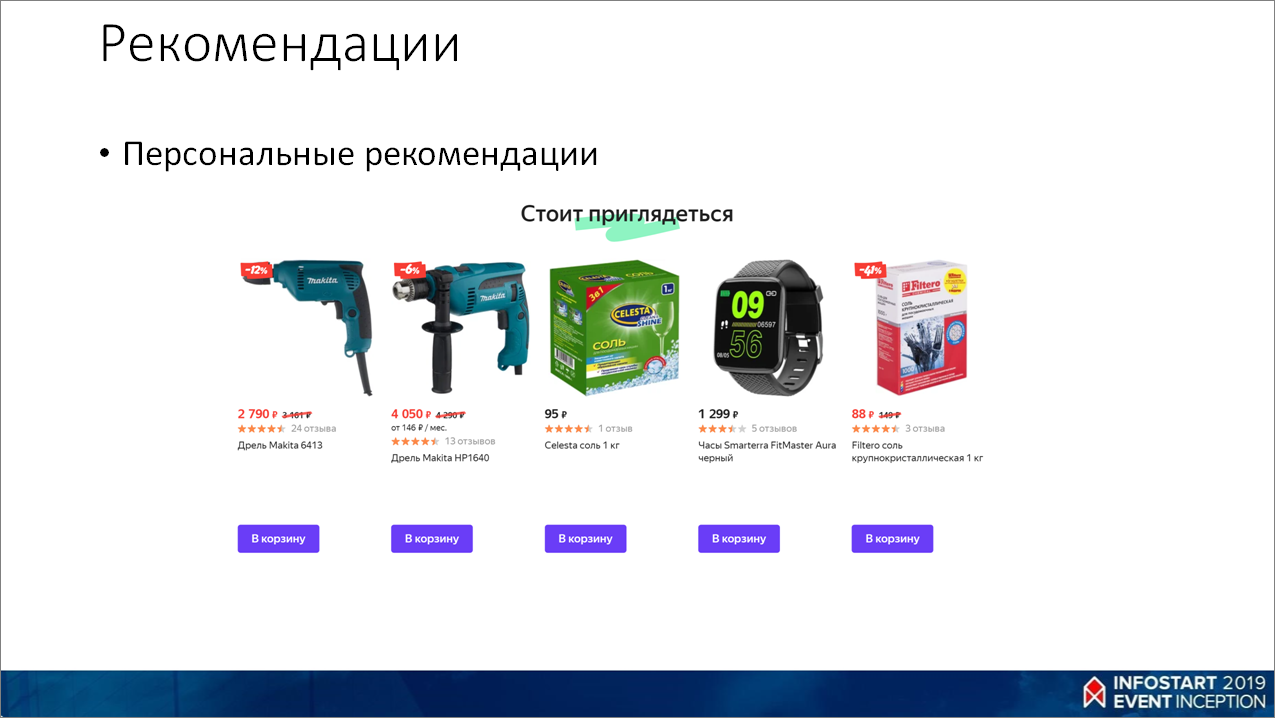
Мы делаем персональные рекомендации, то есть рекомендации, которые учитывают интересы пользователей, историю посещения ими сайтов и очень много всякой информации.
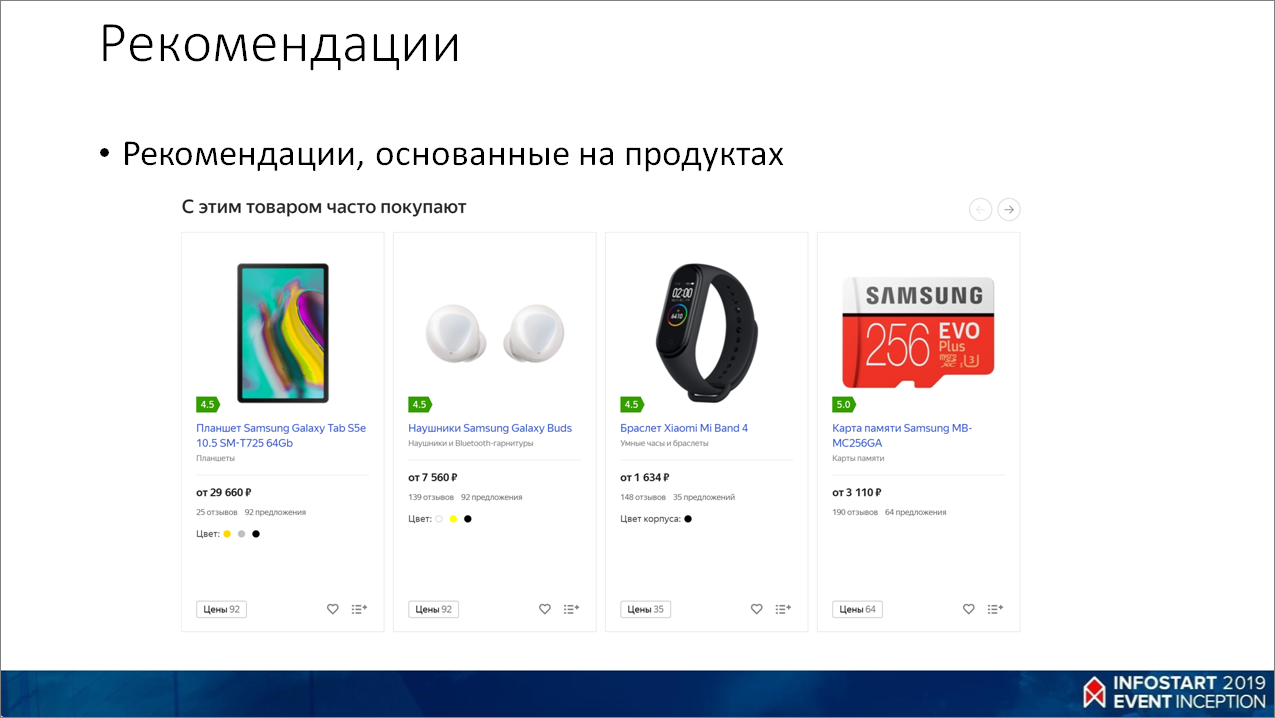
Также делаем рекомендации, которые можно порекомендовать какому-то определенному товару – например, при просмотре iPhone мы предлагаем купить к нему защитное стекло, чехол и что-то вроде этого.
В Яндекс.Маркете мы используем машинное обучение практически для всего:
- для ранжирования поисковой выдачи;
- для ранжирования товаров в категориях;
- для рекомендаций;
- для поиска похожих картинок;
- для поиска картинок по смыслу;
- для кластеризации одинаковых предложений от магазинов в одну карточку товара;
- для прогнозирования спроса;
- оптимизации рекламы и многого другого.
Если где-то в Яндекс.Маркете еще не используется машинное обучение – значит, просто руки еще не дошли.
И сегодня я как раз и хочу немного увести вас в тему машинного обучения, рассказать про то, как можно начать использовать его в своих задачах. Возможно, после моего доклада кто-то заинтересуется, и в мире 1С тоже что-то появится. Сейчас область интеграции машинного обучения и 1С достаточно свободная – бери и делай.
Искусственный интеллект vs Машинное обучение vs Нейросети vs Глубокое обучение
Наверное, многие из вас слышали фразы «Искусственный интеллект будет помогать прогнозировать затраты в ERP», «Нейросети обыграли человека в игру Го» и т.п. Так в чем же разница между этими понятиями?

Термин «искусственный интеллект», как правило, любят использовать маркетологи, журналисты и люди, которые мало понимают, о чем говорят.
В профессиональной среде используется термин «Машинное обучение», Machine Learning, просто ML.

Давайте разберемся:
- Искусственный интеллект – это область, которая занимается машинным обучением, такая же, как биология, химия, физика. Почему-то никто не говорит: «используя химию, мы что-то сделаем».
- Машинное обучение – это один из разделов искусственного интеллекта. Один, но при этом не единственный. Есть еще, например, экспертные системы и много-много других.
- Нейросети – это один из алгоритмов машинного обучения. Популярный, но есть и не хуже.
- Глубокое обучение – это архитектура сетей и подход к обучению. По факту, мало кто различает глубокие и неглубокие сети. Просто говорят – сеть такая-то, архитектура такая-то.
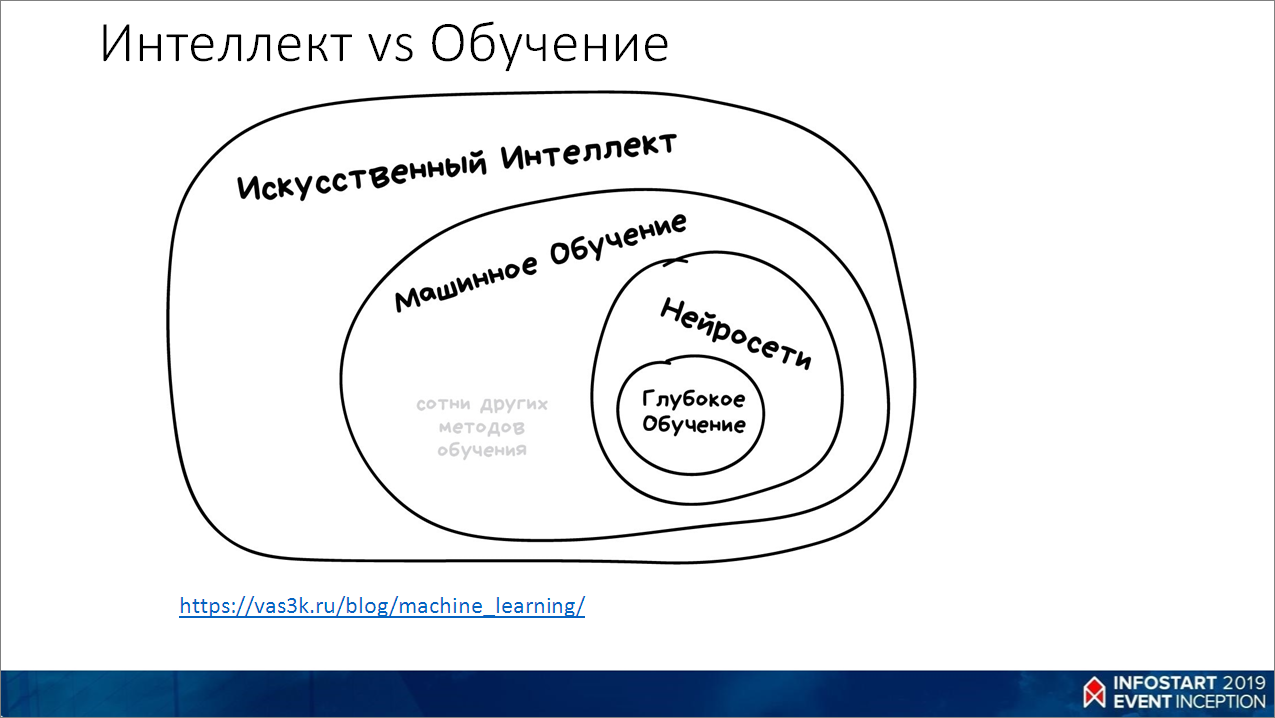
На этой картинке хорошо видно, как это все взаимосвязано.
Тут приведена ссылка https://vas3k.ru/blog/machine_learning/, очень рекомендую пройти по ней и прочитать статью про основы машинного обучения – доступным языком, очень легко читается.
Машинное обучение
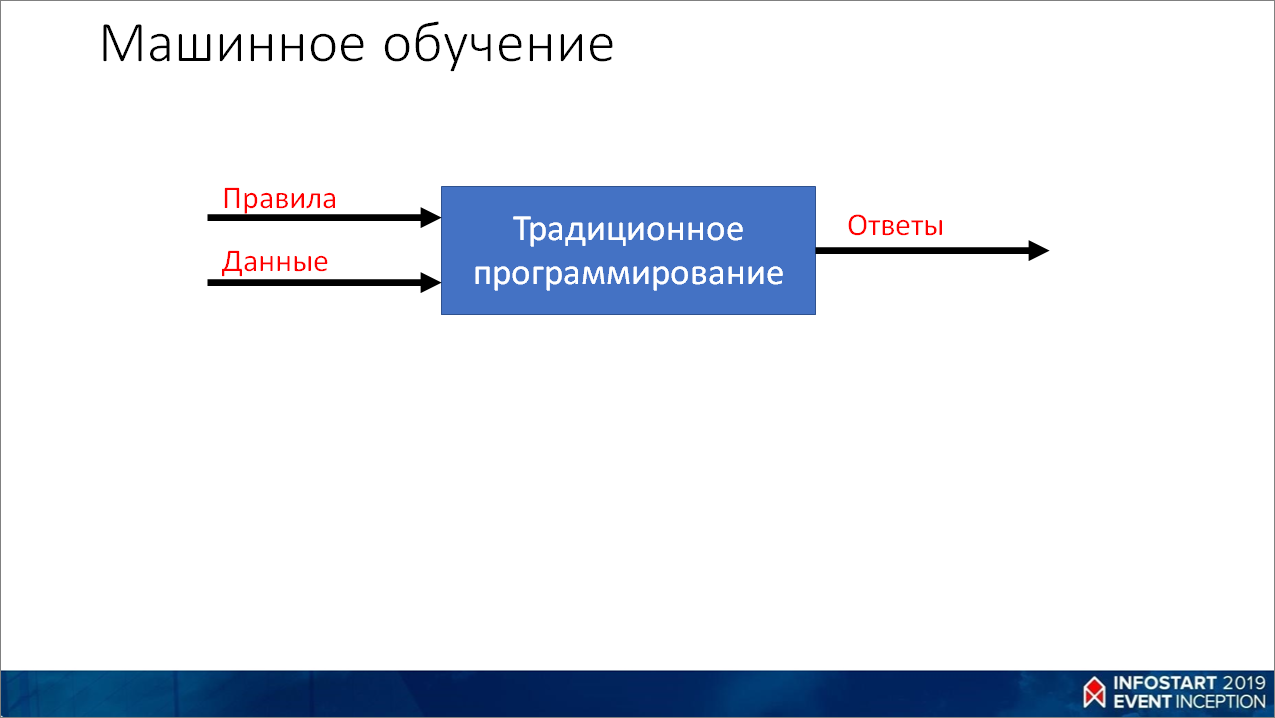
Так, собственно, что такое машинное обучение?
Для начала рассмотрим, как решаются задачи в традиционном программировании.
- Мы берем какую-то задачу, очень долго над ней думаем и, подумав, вырабатываем из нее какие-то правила;
- Потом берем эти правила, берем сами данные (переменные в программе, информацию из базы данных, веб-сервисов, файлов и пр.) – все это смешиваем;
- И на выходе получаем программу, которая может выдавать нужные нам ответы.

Допустим, у нас есть задача научиться определять вид активности человека в конкретный момент времени. Например, он носит фитнес-трекер, мы хотим знать, что в конкретный момент человек делает.
- Мы пишем условие – если скорость меньше 4, значит, это ходьба.
- Потом человек побежал, и мы добавляем ветку условия, которая тоже ориентируется на скорость.
- Потом наш человечек стал женщиной, сел на велосипед и поехал. Мы тоже хотим научиться понимать, что он едет на велосипеде – казалось бы, тут тоже все просто, добавили еще одну ветку.
- А потом человек снова стал мужчиной и полез в воду. Вроде он плывет, скорость у него что-то между ходьбой и бегом. При этом нагрузка гораздо сильнее. Как такую задачу решать? Сразу непонятно.
Причем, здесь в условии идет ориентир на скорость, а в реальности-то нет такого значения. Есть какие-то параметры с датчиков типа гироскопа, акселерометра, датчика температуры кожи и т.д. – много разных цифр, получаемых с этих датчиков.
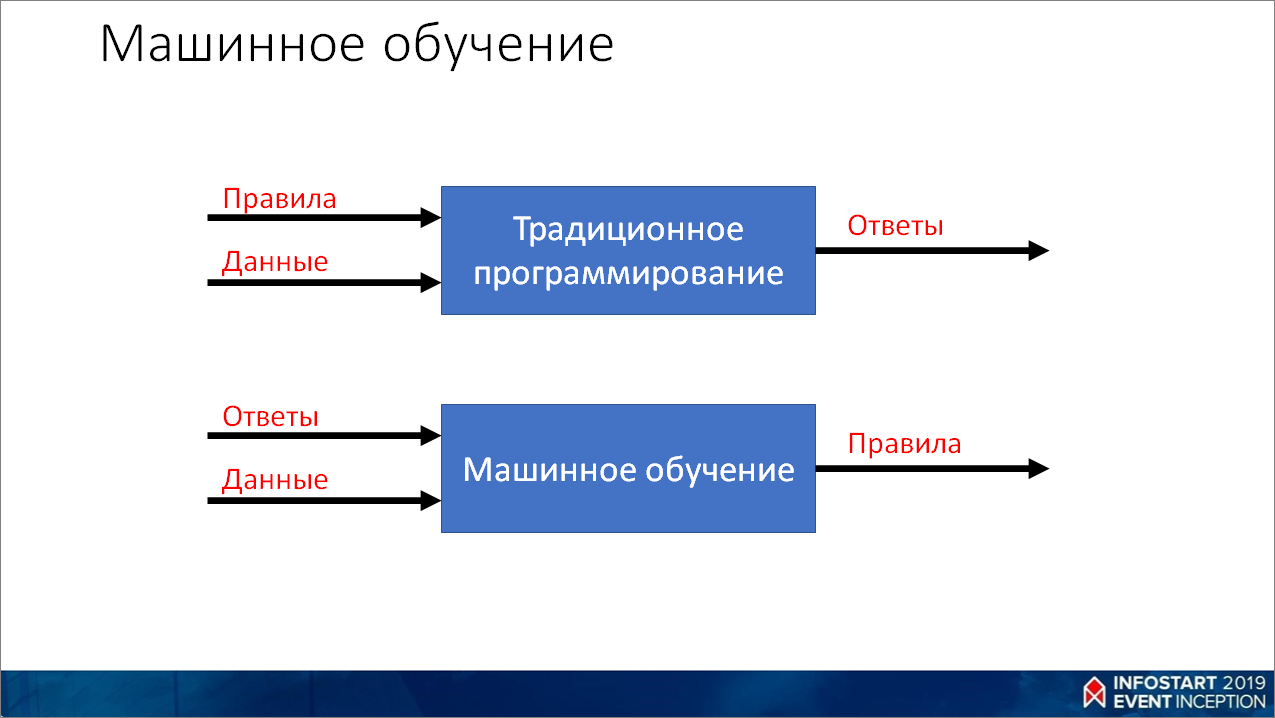
В этом случае нам как раз приходит на помощь машинное обучение.
- Мы берем все наши данные с датчиков и размечаем их конкретным видом деятельности.
- Мы смотрим на человека, видим, что он делает, и проставляем метки для наших показаний. В итоге у нас получается какой-то набор данных.
- Берем алгоритм машинного обучения и подаем ему на вход эти данные, чтобы он выработал какие-то паттерны – извлек правила из данных и ответов.
- И на выходе мы получаем какую-то систему, которая сама обучилась, нашла правила, закономерности. И мы можем ее использовать на новых данных, чтобы получать ответы.
При этом, если у нас человек захочет, например, играть в гольф, и мы тоже захотим понимать, что он это делает, достаточно добавить новых данных, переобучить, и опять все будет работать.
А если бы мы использовали традиционный подход, там надо было бы добавлять какие-то параметры в условия, что-то самим думать – достаточно сложно.

Главные вещи, на которых базируется машинное обучение – это:
- данные:
- как правило, чем больше данных, тем лучше.
- главное, чтобы данные были хорошими – если мы на вход будем подавать мусор, мы и на выходе получим мусор.
- признаки. Это некие независимые переменные, по которым мы будем предсказывать целевое значение. Это могут быть:
- пиксели в картинке;
- слова в тексте;
- числа – например, обороты с контрагентами и пр.
- и самое главное – это алгоритмы. Под разные задачи – разные алгоритмы. Не существует какого-то одного универсального алгоритма, который решил бы все задачи – взяли бы нейросеть, и она нам все смогла бы сделать. Под каждую конкретную задачу какие-то алгоритмы подходят лучше, какие-то – хуже. Какие-то работы в направлении того, чтобы сама нейросеть умела выбирать нужные алгоритмы для задачи, ведутся, но пока ничего хорошего нет.
Данные
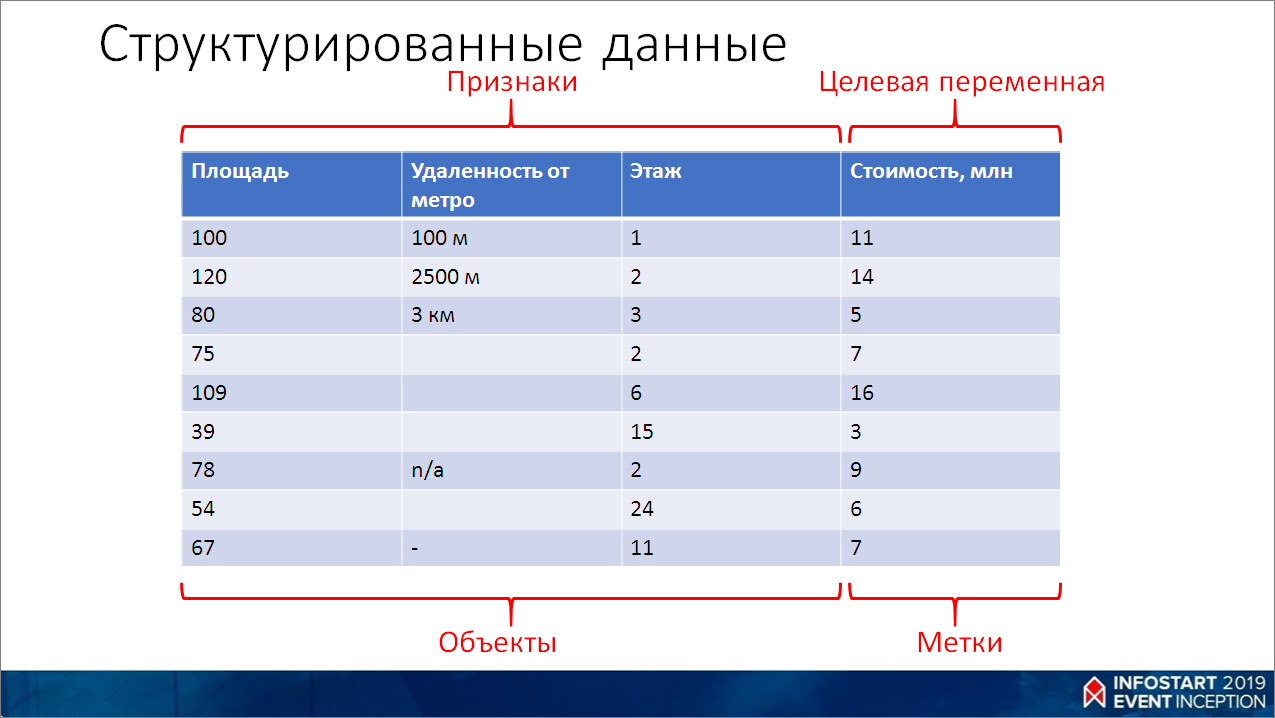
Немного подробнее про данные.
Данные бывают структурированными – например, таблицы в базе данных. С ними работать относительно просто.

Данные бывают в виде текста – сообщения, описания товаров, отзывы, комментарии и др.

Это тоже данные – картинки, видео, спектрограммы звука и пр.
Признаки

Немного про признаки.
До недавнего времени существовал, по сути, единственный вариант сформировать хорошие признаки: взять высококвалифицированного специалиста, чтобы он, путем анализа исходных данных, сформировал какие-то признаки, которые мы можем дальше использовать в обучении.
Например, мы хотим научить систему определять по письмам, спам это или не спам. У нас есть огромный исходный массив писем, которые наш человек проанализировал и сформировал признаки спама – это, как правило:
- много капслока;
- какие-то слова «Увеличить до 25 см», «Вы выиграли миллион долларов»;
- большое количество вхождений символа доллара в тексте письма и т.д.
Наш человек эти признаки сформировал, но это было долго, муторно, дорого и субъективно, потому что человек, который это делает, вносит какую-то составляющую предвзятости.

Но есть и другой способ – мы можем взять те же письма, разделить их на слова или даже на отдельные символы и подать это на вход нейросети. И пусть она сама найдет какие-то паттерны, которые будут говорить, спам в письме или нет.
Какой здесь плюс? Мы освобождаем человека от рутинной работы, просто грузим железо. Купили железо, загрузили в него данные, на выходе что-то получили.
При этом нейросеть видит в данных такие паттерны, которые люди, как правило, могут не увидеть – в силу своей предвзятости и незнания области, в которой они проводят этот анализ.
Алгоритмы

Теперь – самое главное, алгоритмы.
Как я уже говорил, не существует какого-то единого, универсального алгоритма, который подошел бы под все задачи. Нейросети – это круто, модно, но они – не единственные. И они не всегда работают хорошо.
- Если у нас данные простые, какие-то линейные зависимости – берем линейную регрессию. Она обучается мгновенно, результат тоже выдает очень быстро. Много где используется в силу своей простоты. Казалось бы, это – прошлый век (по сути, регрессия идет из 18 века). Но по факту – очень хороший алгоритм.
- Если у нас появляются какие-то нелинейные зависимости, мы берем деревья, ансамбли деревьев (случайные леса, градиентный бустинг поверх деревьев – главный конкурент нейросетей и т.п.).
- А если данных у нас очень много (миллионы примеров), а еще данные какие-то непонятные (признаки неочевидны), мы берем нейросети. И, как правило, это работает.
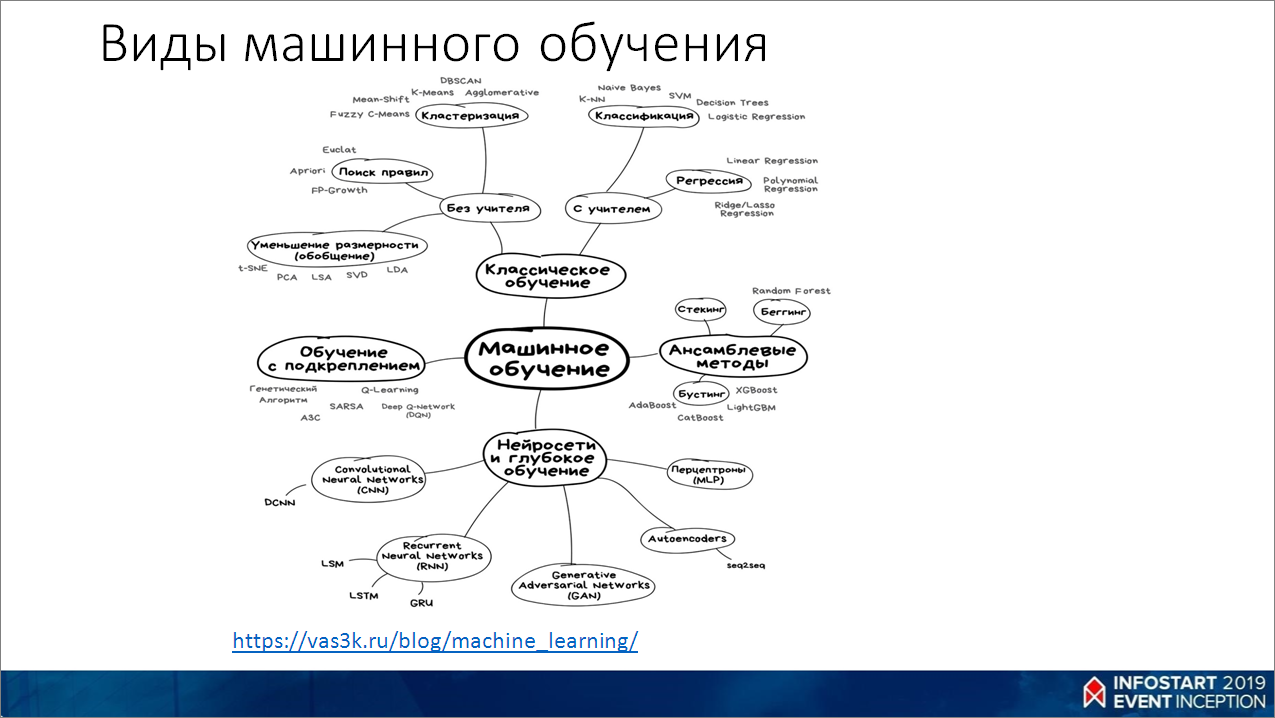
Опять же, я уже приводил ссылку https://vas3k.ru/blog/machine_learning/, там хорошо показано, какие бывают виды машинного обучения. Советую прочитать эту статью.
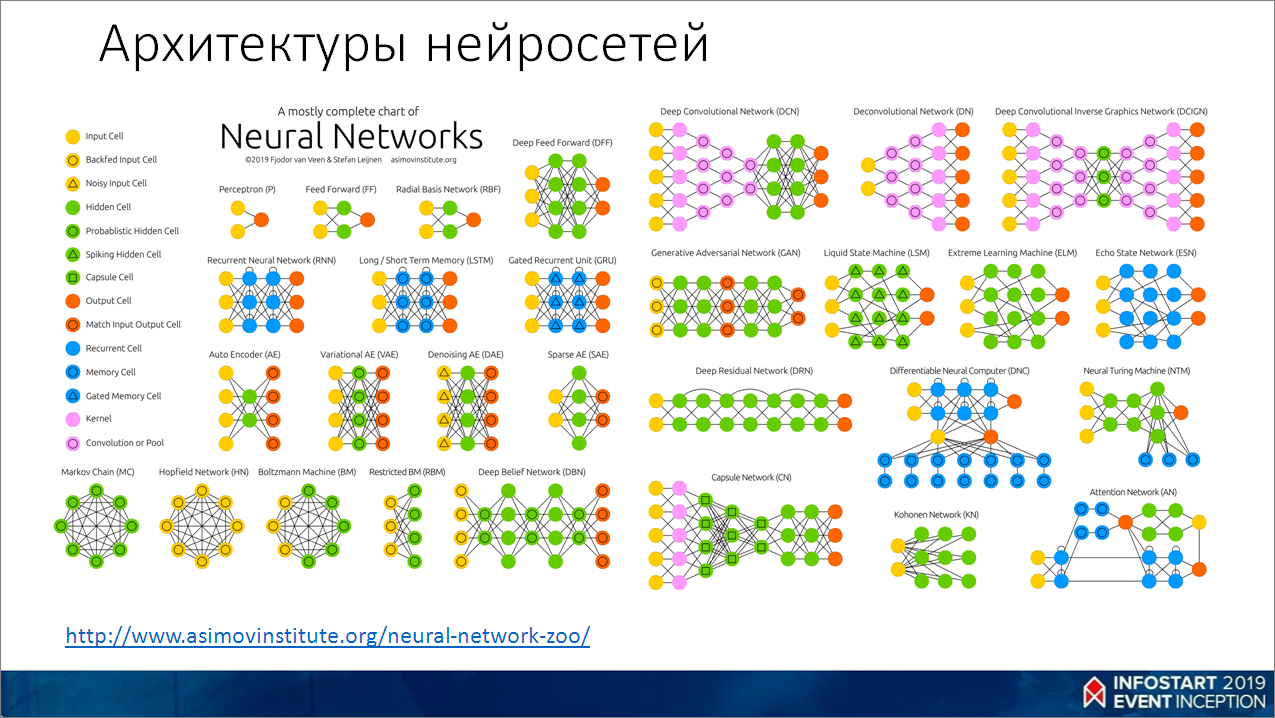
А вот такой ужас у нас с нейросетями.
Наверное, многие знают, что такое перцептрон, видели его классическую схему – вход, скрытые слои, выход. Но мир не стоит на месте, на слайде показаны даже не все архитектуры, которые сейчас есть. Это какое-то подмножество. Можно зайти по ссылке https://www.asimovinstitute.org/neural-network-zoo/ и там изучить подробнее.
Процесс обучения нейросети
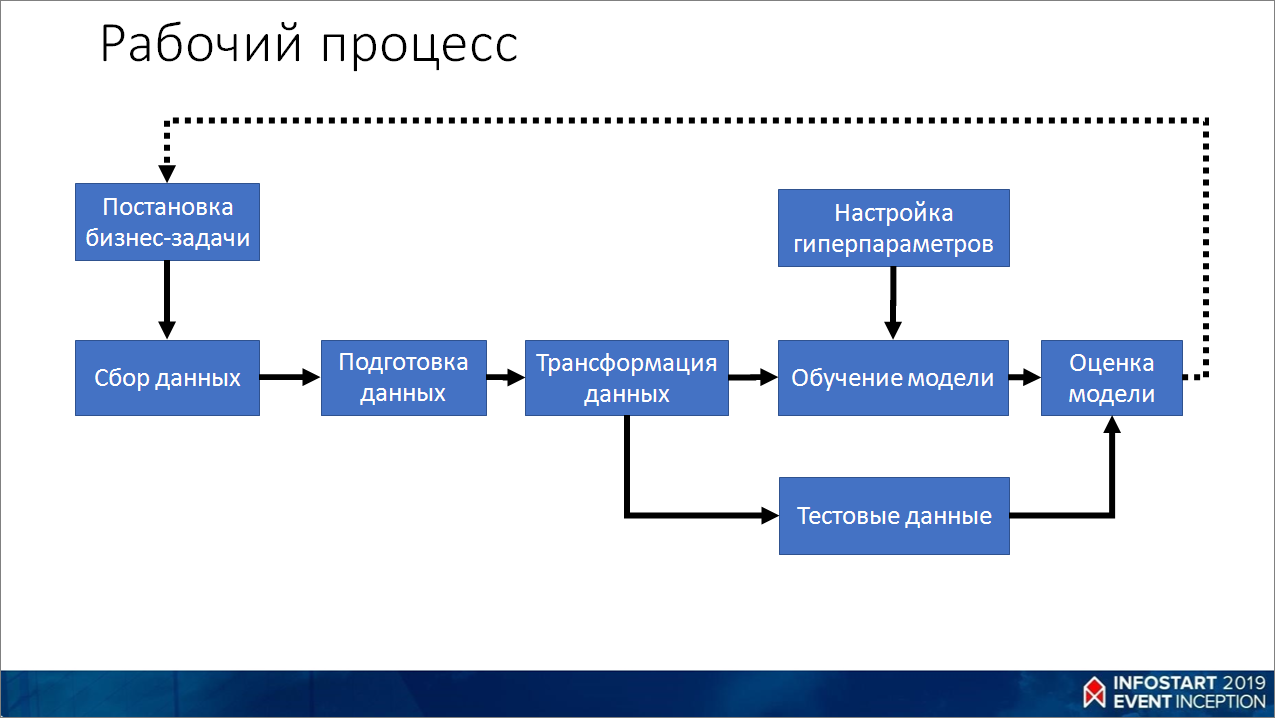
Расскажу немного про процесс, как мы обучаем.
- Формулируем задачу, проверяем ее адекватность и возможность реализации. Как можно быстро приближенно проверить адекватность? Если посадить человека и дать ему эту задачу, и он сможет, не задумываясь, ее решить за одну секунду, то, скорее всего, машинное обучение с этим тоже справится. И, как правило, оно потом будет делать это лучше, чем человек. И не уставать.
- В зависимости от задачи смотрим, есть ли у нас данные. Если нет – начинаем собирать. Либо где-то приобретаем.
- Данные нужно подготовить, убрать пропуски и преобразовать в какой-то структурированный вид.
- Дальше мы трансформируем наши данные. Практически все алгоритмы не умеют работать с данными и с текстом в прямом виде – необходимо преобразование в числовые значения. Трансформация заключается в том, что мы переводим:
- тексты – в векторы чисел;
- картинки – в пиксели;
- числовые значения приводим к шкале от -1 до 1 (или от 0 до 1).
- Делим эти данные на две части – тренировочные и тестовые.
- На тренировочных данных обучаем модель и оцениваем результаты.
- Если что-то не очень хорошо идет, подкручиваем гиперпараметры. Поясню, что такое гиперпараметры. Если вы вспомните слайд, где был показан нейрон, там были коэффициенты, которые мы умножаем на входящие значения. Во время обучения мы их подстраиваем. Это будут параметры – то, на что мы не можем влиять, оно само формируется в процессе обучения. Это некий «черный ящик». А гиперпараметры – это ручки к этому ящику, мы можем их подкрутить и как-то донастроить сеть в процессе обучения.
- После того, как мы модель обучили, проверяем ее на тестовых данных. Зачем вообще нужны тестовые данные? Они нужны, чтобы как-то сэмулировать появление новых данных, которых до этого не было, и избежать ситуации, когда при появлении новых данных в продакшен мы получим что-то неработающее. Самое главное – никогда не показывать тестовые данные во время обучения. То есть, мы забыли о них, отложили, получили какую-то модель в ходе обучения, а потом проверяем по тестовым данным.
- В результате получаем какую-то финальную оценку. Если она адекватная, то можно попробовать выкатить это в прод, посмотреть, как все это будет работать. Если нет, то возвращаемся в самое начало, возможно, даже придется переформулировать задачу, потому что она не реализуема в текущий момент. И так далее – все это в цикле может повторяться.
Недостатки встроенных средств для анализа данных в 1С

Какие средства можно использовать для работы с машинным обучением?
Так как у нас конференция по 1С, то в 1С, вы знаете, есть такой механизм «Анализ данных и прогнозирование», который был в платформе 8.0 с самого начала. Ему 17 лет. За это время он практически ни разу не менялся. Эта такая обнадеживающая штука, которая, по идее, должна работать. Этот механизм даже используется в паре конфигураций – в ERP, например, используются его составляющие (кластеризация и общая статистика).
Из чего состоит механизм «Анализ данных и прогнозирование»:
- Общая статистика – хорошая штука. Хотя сейчас, в принципе, общую статистику можно заменить механизмом СКД – там как раз добавили ковариации и прочие статистические методы.
- Кластерный анализ – механизм ограниченного действия, мало где можно применить.
- Дерево решений – результат, который сейчас выдается этим механизмом, очень плохого качества по сравнению с библиотеками на Python и никак не приближается к ним по качеству даже близко, я проверял.
- А поиск ассоциаций и поиск последовательностей – это вообще нежизнеспособные штуки, я про них даже говорить не буду.

Кроме этого, у нас в 1С банально нельзя поделить тренировочные и тестовые данные. В Python я вызову одну функцию, и она мне создаст эти два набора данных. Причем, в параметрах функции можно настроить случайный выбор и поддержку распределения целевой переменной. А в 1С все это надо самому делать.

А еще мы можем сделать механизм машинного обучения в 1С сами, средствами встроенного языка. Информации, как это реализовать, много, все достаточно просто.
Да, это обязательно стоит сделать в академических целях, а потом отложить и забыть, как о страшном сне.
Почему? Потому что решение, которое будет на встроенном языке, работает на три порядка медленнее, чем простой цикл на C++. И на четыре порядка медленнее, чем GPU.

Или мы можем написать на C++ штуку, которая умеет параллелиться, потому что используются в основном какие-то матричные операции, и это все очень хорошо параллелится.
Но самое главное – в своем решении вы будете что-то делать в одиночку. Вы потратите кучу времени на то, чтобы сделать обучение нейросети. Попробуйте, продайте это бизнесу. Я немного поковыряюсь, научусь обучать нейросеть, а на выходе ничего не получу, потому что я не знаю даже, как это будет работать – получится что-то или нет.
Готовые решения для работы с машинным обучением
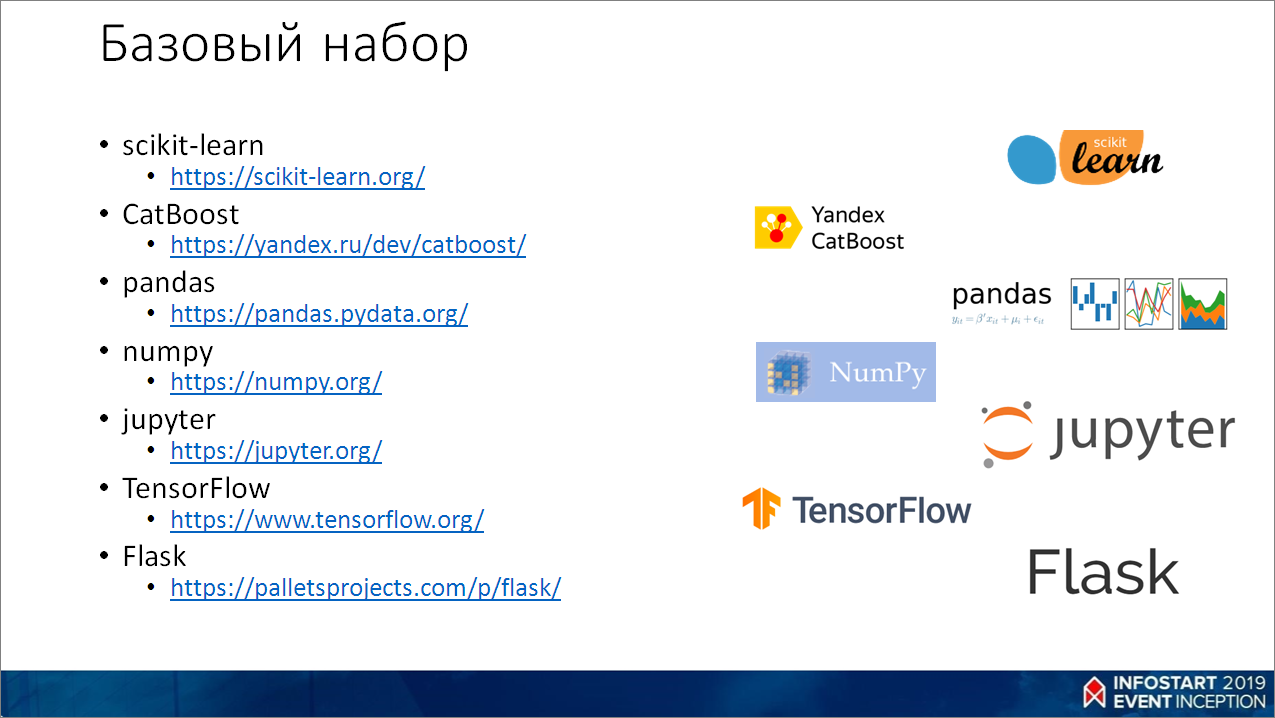
А сейчас уже есть множество популярных решений, используемых тысячами людей, которые в этом что-то понимают. Надо просто брать готовое решение и решать конкретную бизнес-задачу. А что внутри – воспринимайте это на первом этапе, как просто черный ящик. Какой-то алгоритм, у которого есть какие-то параметры, и это как-то работает. И с этим можно даже успешно жить.
Теперь кратко по этому набору – это все на Python, все бесплатное. По сути, все самое крутое.
- scikit-learn (https://scikit-learn.org/) – библиотека для машинного обучения, которая реализует классические алгоритмы (деревья, регрессии и прочие штуки). Очень много всяких вспомогательных средств для разбиения данных, кроссвалидации, оценок, метрик и пр.
- CatBoost (https://yandex.ru/dev/catboost/) – это реализация от Яндекса градиентного бустинга поверх деревьев решений. Эта библиотека совместима с scikit-learn по API. Очень крутая, по сути, в своем классе, лучшая (может быть, для каких-то конкретных задач будут другие победители). Очень активно используется в Яндексе.
- Pandas (https://pandas.pydata.org/) – это штука для работы с табличными данными. Там можно читать разные форматы, фильтровать, обрабатывать их как-то. Если откинуть в СКД визуальную составляющую, то pandas ее уделывает, как щенка какого-то.
- numpy (https://numpy.org/) – это библиотека для работы с векторами. По сути, это линейная алгебра. Работает очень быстро, на три порядка быстрее, чем код на 1С
- jupyter (https://jupyter.org/) – это некая IDE в браузере, в которой очень удобно писать построчно код, сразу видеть какой-то результат, сразу вставлять какие-то картинки, в результат выводить графики – все в одном документе. Очень круто.
- TensorFlow (https://www.tensorflow.org/) – библиотека от Google для обучения нейросетей.
- Flask (https://palletsprojects.com/p/flask/) – это некий веб-фреймворк, на котором можно буквально в две строчки взять готовую модель и сделать API, которое можно использовать в 1С.
Делаем свой классификатор и дружим его с 1С:Предприятие 8

Давайте рассмотрим небольшой практический пример. Сделаем свой текстовый классификатор и научим его дружить с 1С.
Задача такая – есть некий набор номенклатур, мы хотим его группировать по номенклатурным группам. Вот у нас категории – «Авто», «Товары для здоровья» и пр.
У меня в Маркете такие данные есть, я их для этого примера взял. А так, вы можете вместо текста номенклатуры взять письма на хотлайн, если они у вас есть. Или можете вместо групп взять, скажем, разделы – «Платформа», «Бухгалтерия предприятия», «Управление торговлей». Или «Срочно» и «Не срочно». То есть, этот пример подходит и для случая, если у нас будут письма или любые другие текстовые данные, которые мы хотим как-то классифицировать.
Трансформация данных
Как это все отдать в нейросеть, если она хочет цифры?
Мы пронумеровываем все категории от 1 до 15. Казалось бы, у нас уже есть числа, мы можем их подменить. Но при этом, у нас почему-то последняя категория «Товары для животных» будет иметь номер 15, а категория «Авто» будет иметь номер 1. То есть, мы уже вводим какое-то ранжирование. Почему-то животные у нас приоритетнее. Если мы умножим, то у нас получится какой-то перевес.

Поэтому мы количество категорий преобразуем в количество столбиков и для каждого значения мы вставляем одну единичку.
То есть, для пятнадцати категорий у нас будет 15 колонок с единичкой в каждой строчке – для соответствующего значения столбика. С этим уже можно работать.

С текстом сложнее. Текст сначала надо подготовить, а потом преобразовать в векторное преобразование, используя концепцию word2vec. Подробнее о концепции word2vec можно почитать в статье на Хабре https://habr.com/ru/post/446530/

Чтобы подготовить текст, его нужно очистить от цифр и спецсимволов, разбить на слова и построить по этим словам словарь.

Например, из нашего текста получится вот такой словарь – все слова в нем пронумерованы от 1 до количества слов.
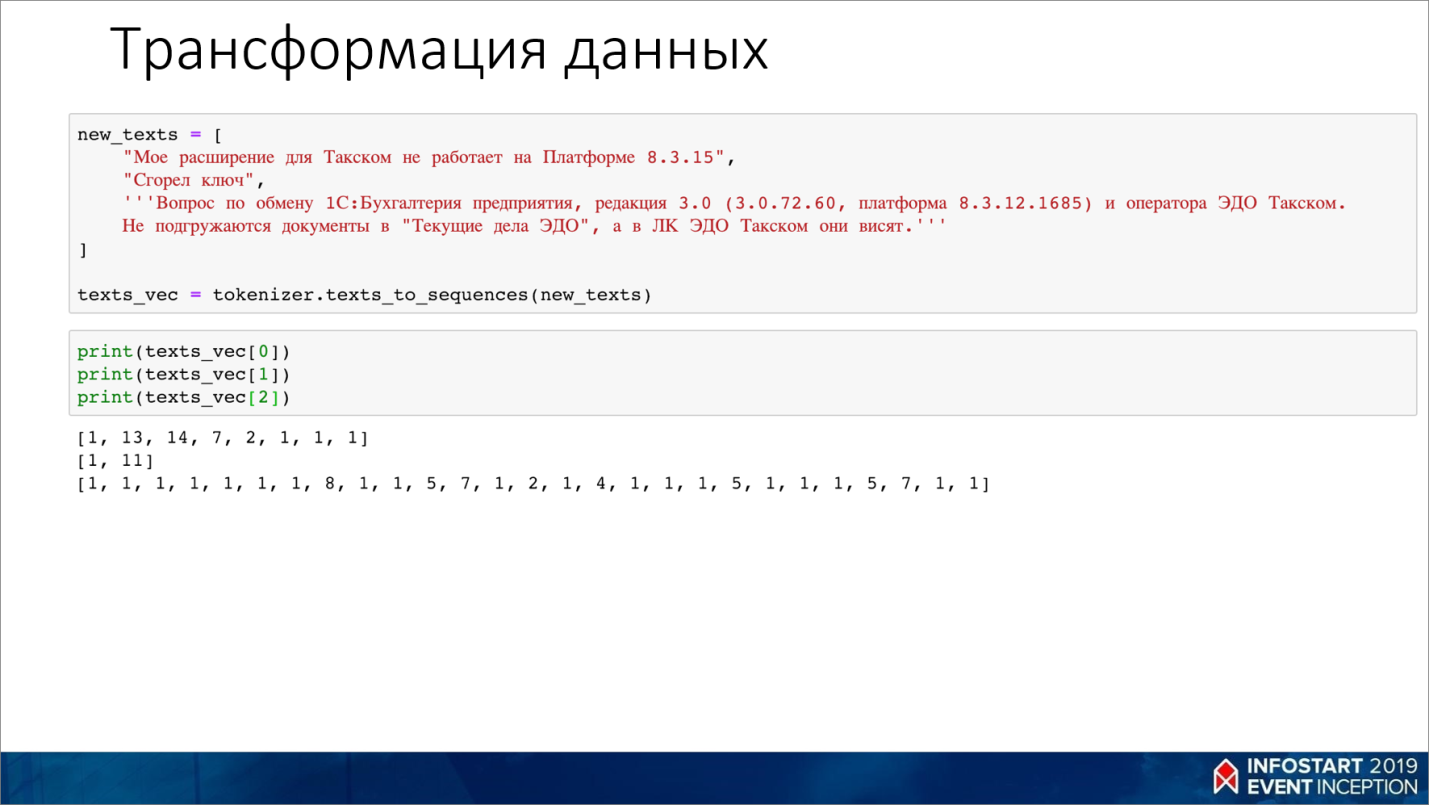
Потом мы подаем на вход этому словарю следующий текст, в который вместо слов подставляем их числовые значения из сформированного словаря.

Получившийся на основании второго текста массив мы подаем на вход функции word2vec. Она берет все эти многомерные разреженные вектора и преобразует их в сжатое пространство определенной размерности, при которой сохраняется какая-то семантическая связь.
Например, если у нас есть слова «кошка» и «собака», то они будут где-то в одном пространстве, близко друг к другу. А «кошка» и «карандаш» у нас будут иметь расстояние больше, потому что кошка и собака в текстовом контексте рядом встречаются чаще, нежели кошка и карандаш, или собака и карандаш.
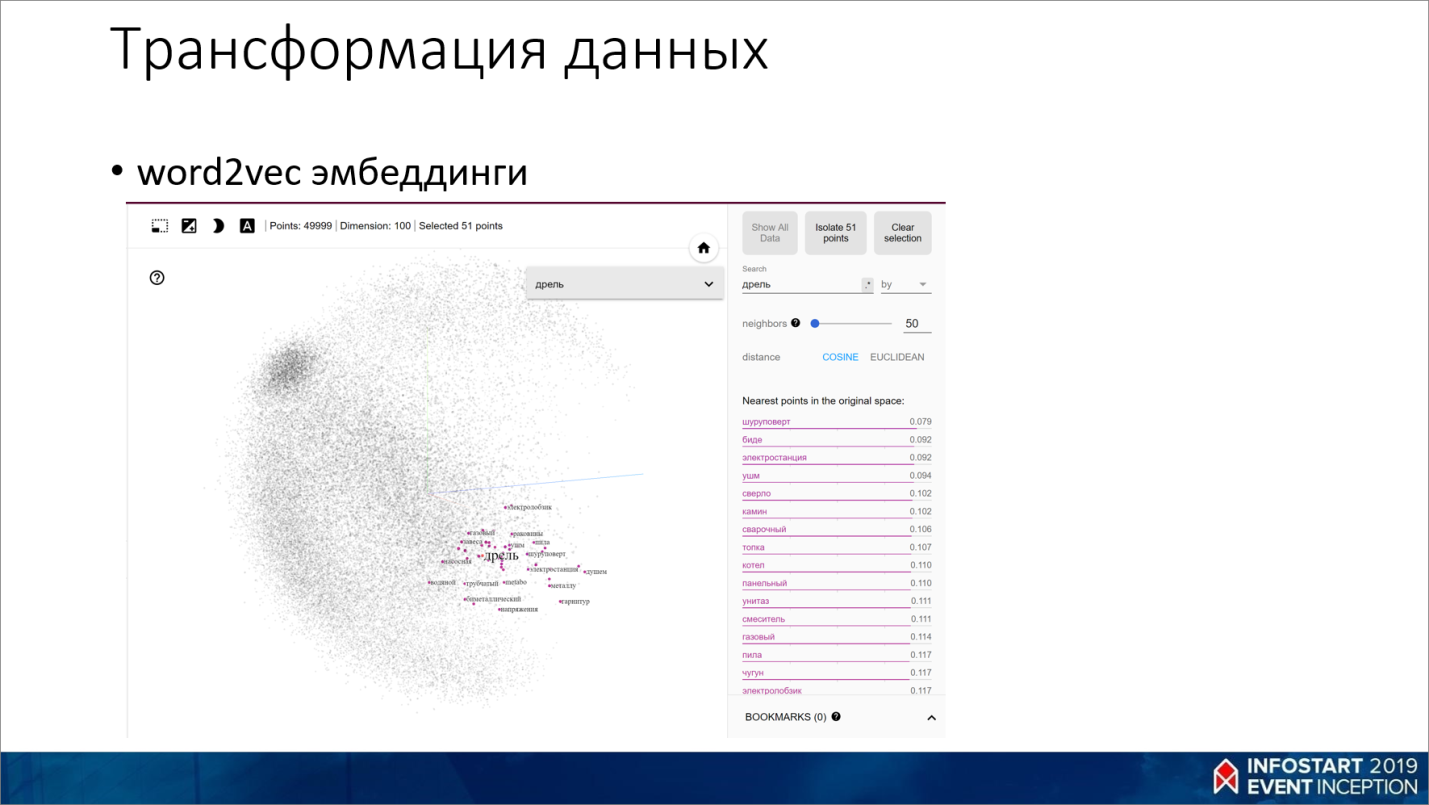
Такую штуку называют векторным представлением слов. Или чаще можно услышать «текстовые эмбеддинги».
С помощью методов снижения размерности (например, t-SNE, PCA) текстовые эмбеддинги легко визуализировать. Например, на сайте https://projector.tensorflow.org/ можно загрузить получившийся текстовый эмбеддинг, ввести слово и покрутить, посмотреть близкие семантически к нему слова. Там видно, например, «дрель», а рядом с ним «шуруповерт» и прочие близкие по смыслу слова.
Обучение модели

Здесь я показываю конкретный пример, как можно обучить модель для этого текстового классификатора.
Первым делом импортируем библиотеки.

На строке 14, используя pandas, загружаем данные из файла.
Далее заводим какой-то массив, в котором у нас будут метки, соответствующие категориям товара.

Разбиваем данные на тренировочные и тестовые. Из интересного:
- параметр stratify=y означает, что, если у нас эти категории как-то распределены в данных, мы хотим это же распределение сохранить и в тестовой, и в тренировочной выборке;
- shuffle=True означает, что мы как-то случайно набираем данные из этого набора;
- test_size=0.3 – это размер тестовой выборки.
С помощью метода to_categorical() мы переводим категории в числа (помните, на первом слайде, где я показывал, что мы для каждой категории делаем столбик и для каждого значения вставляем одну единичку – метод to_categorical() как раз для этого).
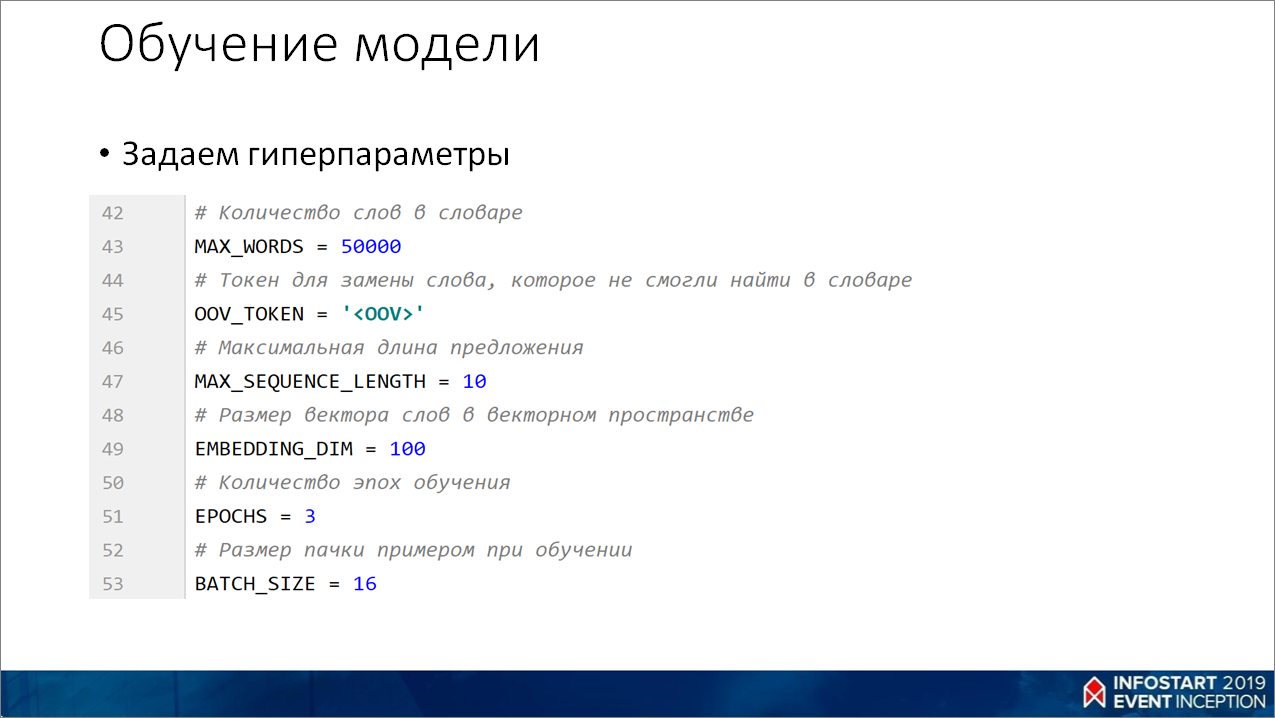
Дальше, задаем гиперпараметры:
- размер словаря MAX_WORDS;
- OOV_TOKEN – символ, который мы будем использовать, если слова нет в нашем словаре;
- MAX_SEQUENCE_LENGTH – размер предложения. Здесь у меня простые гиперпараметры – не больше 10 слов в названии товара, если вам нужно будет заголовки писем классифицировать, там можно 300-400 поставить;
- Размер вектора EMBEDDING_DIM, как правило, больше 300 не делают;
- Количество эпох EPOCHS – это сколько раз мы будем прогонять весь набор данных при обучении нейросети;
- И BATH_SIZE – сколько данных выбирать при обучении.
Все эти гиперпараметры, как правило, нужно настраивать.

Далее – создаем и обучаем токенизатор.
Токенизатор – это такая штука, которая переводит наши тексты в словарь, в котором к каждому уникальному слову проставлено число.
Строка 62 берет наши текстовые строки и по этому словарю переводит в векторы чисел.
Строка 70 – это на тот случай, если у нас максимальная строка – 10 слов, а у нас, скажем, 3, то все остальные 7 слов мы дополняем нулями. Причем можно выбрать – слева или справа дополнять.
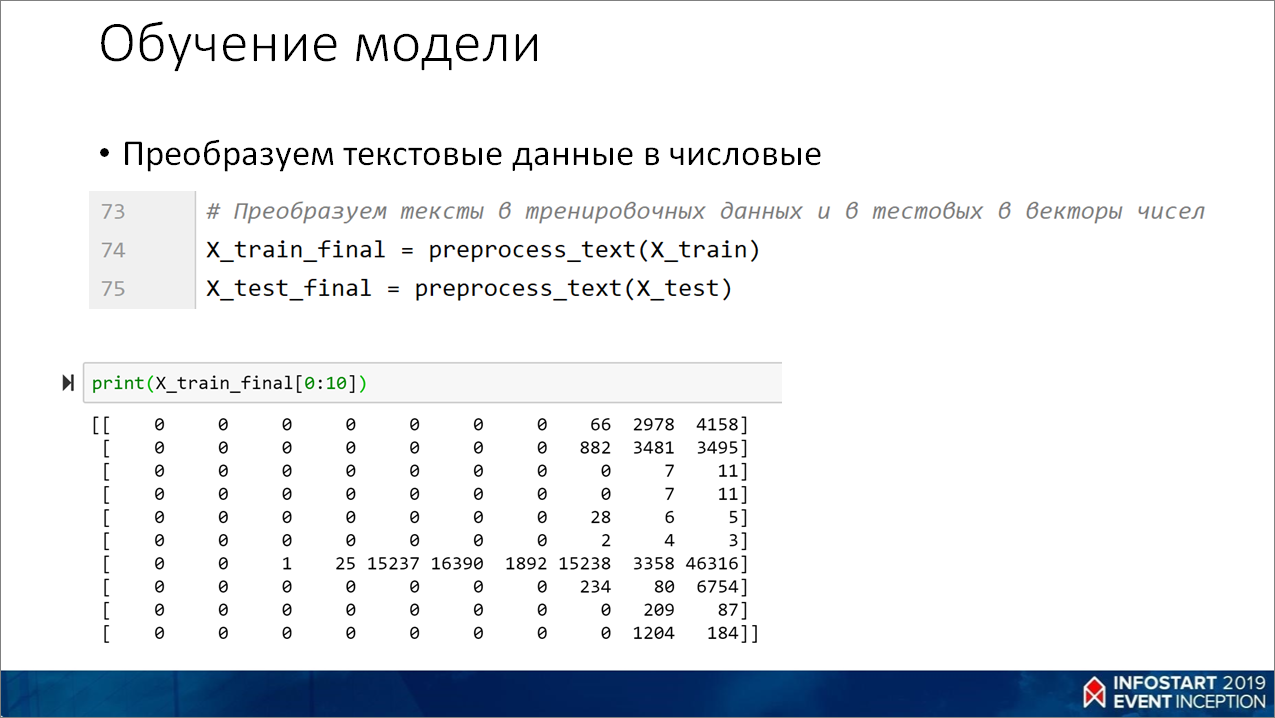
Далее – берем наши тексты, преобразуем в наборы чисел. Получаем вот такие вектора чисел.

Здесь мы создаем нейросеть. Видите, как просто – пара строчек кода, и у вас есть мощная нейросеть.
Sequential() – это такой режим, когда мы берем слои и в режиме стека сверху складываем новый слой.
- Здесь главное учесть, что первый слой должен соответствовать нашему входному вектору эмбеддинга (его измерение – это количество наших уникальных слов). Получаем слой с многомерным тензором, размер которого равен размеру эмбеддинга на количество слов в предложении.
- Дальше создается слой рекуррентной нейросети LSTM – это более продвинутая нейросеть, у которой есть память, и она умеет очень хорошо работать с последовательностями. Например, тексты – это последовательности, когда предыдущие предложения дополняют смысл следующего слова.
- На следующей строке Dense – это, по сути, наш перцептрон. Мы в нем задаем, что количество выходов будет равным количеству входных классов. Функция активации «softmax» приводит сумму всех значений к единице и, соответственно, тот класс, на выходе у которого будет большее значение – это, по сути, и будет тот класс, который мы хотим получить.
С помощью метода fit мы запускаем обучение нейросети.
Из интересного – я пробовал обучать на массиве из миллиона слов, на моем компьютере нейросеть обучается где-то 4 часа (32 Гб памяти, i7, NVidia видеокарта). Если вы будете писать такое средствами 1С, это будет обучаться от полугода до 4-х лет

И в конце мы сохраняем обученную модель и токенизатор в отдельные файлы, которые будем использовать в нашем веб-сервисе.

Подробнее об обучении нейросетей можно почитать на Хабре:
- Преимущества рекуррентных нейронных сетей долгой краткосрочной памяти LSTM https://habr.com/ru/company/wunderfund/blog/331310/;
- О переобучении нейронных сетей https://habr.com/ru/company/wunderfund/blog/330814/.
Веб-сервис классификатора

Это – API нашего веб-сервиса на flask. Тут в строчке 39 у нас будет некий HTTP-метод predict(), в который мы по POST будем отправлять текст в виде JSON.
Дальше мы преобразуем эти данные по такой же схеме, как и обучали. Отдаем в модель, получаем предсказание и возвращаем результат – значение категории и вероятность этого значения (уверенность, что эта категория подходит).
Интегрируем веб-сервис с 1С

В 1С это выглядит так.
Используется библиотека КоннекторHTTP (//infostart.ru/public/709325/), которую я написал – я за вас уже половину работы сделал.
Вы берете текст, передаете его в метод PostJson() и получаете ответ.
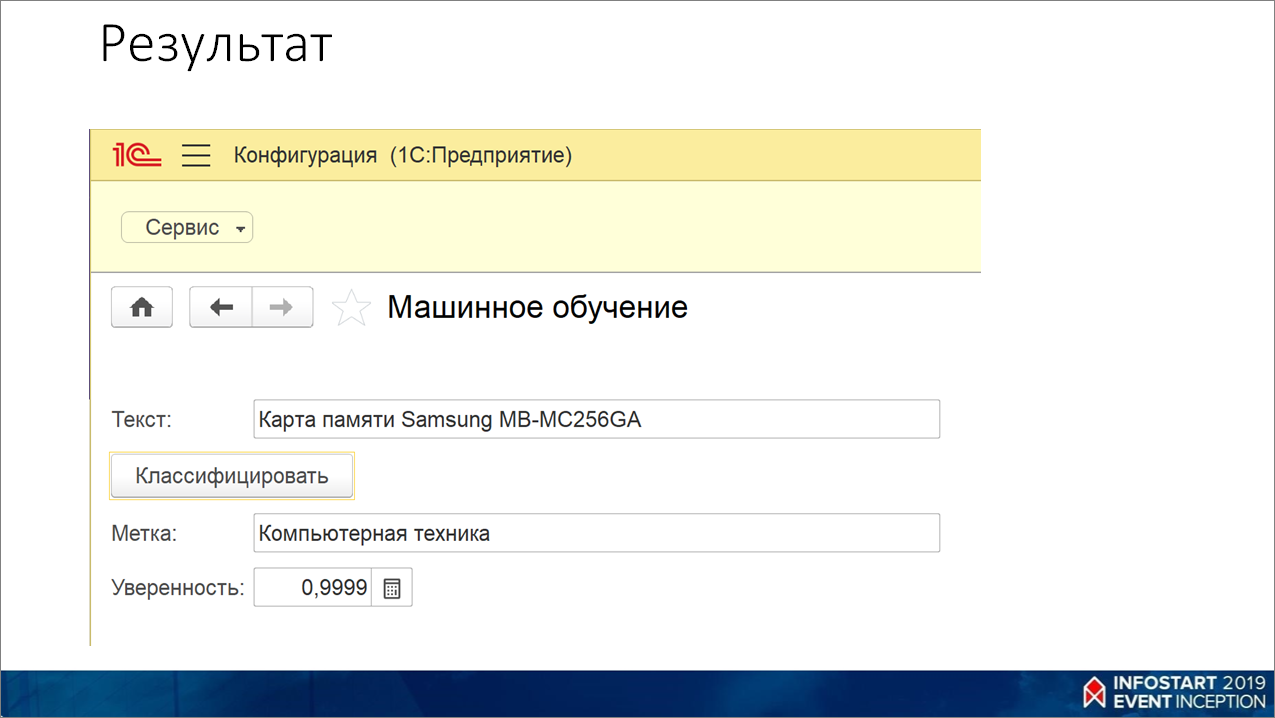
Вот так это приблизительно выглядит. Видно, что карта памяти – это у нас компьютерная техника с уверенностью практически 100% (от 0 до 1).
Например, если бы я убрал «памяти», убрал «Samsung», она бы все равно предсказывала, что это – компьютерная техника, просто уверенности было бы меньше.
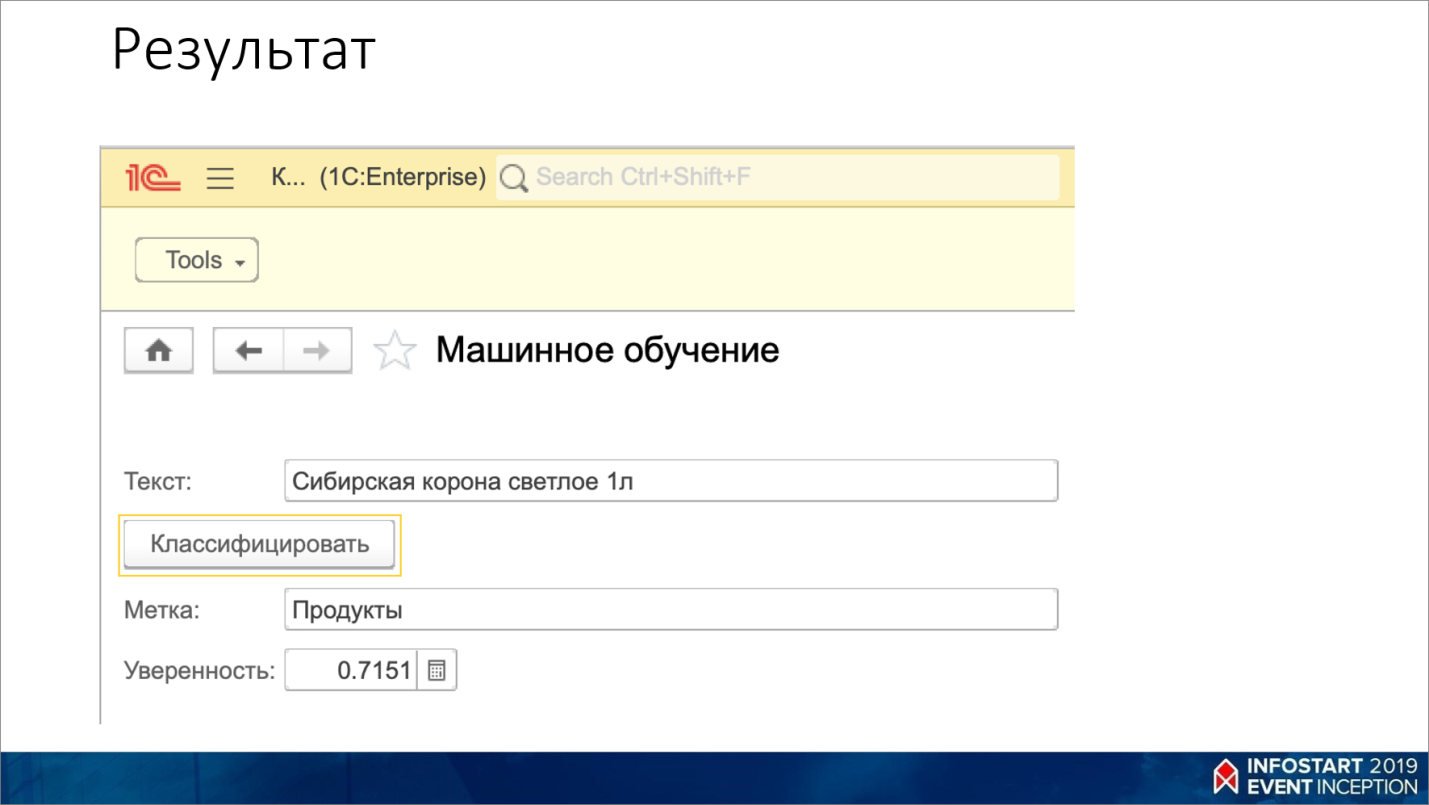
Например, я пробовал «Сибирская корона светлое 1л», и она уже понимает, что это – пиво.
Результат
Этот пример выложен на GitHub https://github.com/vbondarevsky/infostart_event_2019
Вы можете взять свои данные и сделать на их основании свой текстовый классификатор, чтобы как-то его использовать уже в 1С.
Точность, причем, у меня получилась хорошая, хотя для обучения я использовал порядка 1% своих данных. При этом она хорошо предсказывает и для других 99%.
****************
Данная статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART EVENT 2019.

Вступайте в нашу телеграмм-группу Инфостарт