Ожидаемая продолжительность жизни страницы - это счетчик производительности, который должен отслеживать, как долго страницы остаются в памяти, прежде чем они будут удалены, чтобы освободить место для других страниц.
Часть первая ( Paul Randal )
Что означает PLE?
В Интернете есть всевозможные неверные утверждения об ожидаемой продолжительности жизни страниц, и наиболее вопиющими являются те, в которых указывается, что значение 300 является порогом того, о чем вам следует беспокоиться.
Чтобы понять, почему это утверждение настолько вводит в заблуждение, вам нужно понять, что такое PLE на самом деле.
Определение PLE-это ожидаемое время в секундах, в течение которого страница файла данных, считанная в пул буферов (кэш в памяти страниц файлов данных), останется в памяти, прежде чем будет вытеснена из памяти, чтобы освободить место для другой страницы файла данных. Другой способ думать о PLE-это мгновенное измерение давления на пул буферов, чтобы освободить место для страниц, считываемых с диска. Для обоих этих определений лучше использовать большее число.
Что такое хороший порог PLE?
Число 300 означает, что весь ваш буферный пул эффективно очищается и перечитывается каждые пять минут. Когда Microsoft впервые указала пороговое значение для PLE 300 примерно в 2005/2006 году, это число, возможно, имело больше смысла, поскольку средний объем памяти на сервере был намного ниже.
В настоящее время, когда серверы обычно имеют 64 ГБ, 128 ГБ и более объем памяти, примерно такое количество данных, считываемых с диска каждые пять минут, скорее всего, станет причиной проблемы с производительностью
На самом деле, к тому времени, когда PLE находится на отметке 300 или ниже, ваш сервер уже находится в тяжелом положении. Вы бы начали беспокоиться задолго до того, как уровень PLE станет настолько низким.
Итак, какой порог следует использовать, когда вам следует беспокоиться?
Ну, в том-то и дело. Я не могу назвать вам порог, так как это число будет варьироваться для всех. Если вы действительно, действительно хотите использовать число, мой коллега Джонатан Кехайяс придумал формулу:
( Память буферного пула в ГБ / 4 ) x 300 (Но это очень приблизительно)
Я не люблю рекомендовать какие-либо цифры. Я советую вам измерять свой PLE, когда производительность находится на желаемом уровне – это пороговое значение, которое вы используете.
Итак, вы начинаете беспокоиться, как только PLE опускается ниже этого порога? Нет. Вы начинаете беспокоиться, когда PLE опускается ниже этого порога и остается ниже этого порога, или если он резко падает, и вы не знаете почему.
Это связано с тем, что существуют некоторые операции, которые могут привести к падению PLE (например, иногда это может сделать запуск DBCC CHECKDB или перестроение индекса), и они не вызывают беспокойства. Но если вы видите большое падение PLE и не знаете, что его вызывает, именно тогда вам следует беспокоиться.
Вам может быть интересно, как DBCC CHECKDB может вызвать падение PLE. Это связано с тем, что предоставление памяти для выполнения запроса для DBCC CHECKDB неправильно рассчитано оптимизатором запросов и может привести к значительному уменьшению размера буферного пула (память выделяется из буферного пула) и последующему снижению PLE.
Как Вы Контролируете PLE?
Это самая сложная часть. Большинство людей сразу перейдут к объекту производительности диспетчера буферов в PerfMon и будут отслеживать счетчик ожидаемой продолжительности жизни страницы. Является ли это правильным подходом? Скорее всего, нет.
Я бы сказал, что сегодня подавляющее большинство серверов используют архитектуру NUMA, и это оказывает глубокое влияние на то, как вы отслеживаете PLE.
Когда задействован NUMA, пул буферов разделяется на буферные узлы, с одним буферным узлом на узел NUMA, который может "видеть" SQL Server. Каждый узел буфера отслеживает PLE отдельно, а счетчик ожидаемой продолжительности жизни страницы-это среднее значение PLE узла буфера. Если вы просто отслеживаете общий объем буферного пула, то давление на один из буферных узлов может быть замаскировано усреднением (смотрите часть вторая).
Поэтому, если ваш сервер использует NUMA, вам необходимо отслеживать отдельные счетчики Buffer Node:Page life expectancy (для каждого узла NUMA будет один объект производительности буферного узла), в противном случае достаточно контролировать счетчик Buffer Manager:Page life expectancy.
Еще лучше использовать инструмент мониторинга, такой как SQL Sentry Performance Advisor, который покажет этот счетчик как часть панели мониторинга с учетом узлов NUMA на сервере и позволит вам легко настраивать оповещения.
Примеры использования Советника по производительности
Ниже приведен пример части снимка экрана из Performance Advisor для системы с одним узлом NUMA:
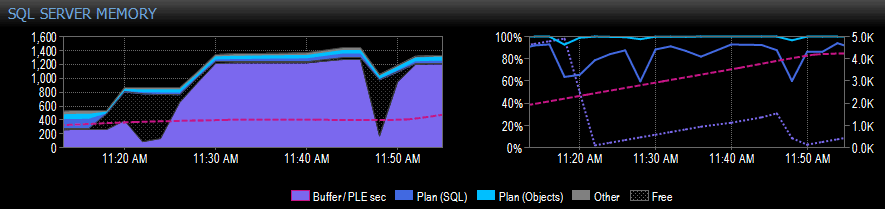
На правой стороне захвата розовая пунктирная линия-это число между 10.30 утра и примерно 11.20 утра-оно неуклонно растет до 5000 или около того, действительно здоровое число. Незадолго до 11.20 утра происходит огромное падение, а затем он снова начинает подниматься до 11.45 утра, где снова падает.
Обычно это то, что вы увидите, если пул буферов заполнен, все страницы используются, а затем выполняется запрос, который приводит к считыванию огромного количества различных данных с диска, вытесняя большую часть того, что уже находится в памяти, и вызывая резкое падение PLE. Если бы вы не знали, что вызвало нечто подобное, вы бы хотели провести расследование, как я опишу ниже.
В качестве второго примера, снимок экрана ниже сделан с одного из наших удаленных клиентов DBA, где на сервере есть два узла NUMA (вы можете видеть, что есть две фиолетовые строки PLE), и где мы широко используем Performance Advisor:

На сервере этого клиента каждое утро около 5 утра запускается задание по обслуживанию индекса и проверке согласованности, в результате чего PLE падает в обоих буферных узлах. Это ожидаемое поведение, поэтому нет необходимости расследовать, пока PLE снова поднимается в течение дня.
Что Вы можете сделать с падением PLE?
Если причина падения PLE неизвестна, вы можете сделать несколько вещей:
Если проблема возникает сейчас, выясните, какие запросы вызывают чтение, используя DMV sys.dm_os_waiting_tasks, чтобы узнать, какие потоки ожидают чтения страниц с диска (т. Е. Те, которые ожидают PAGEIOLATCH_SH), а затем исправьте эти запросы.
Если проблема возникла в прошлом, найдите в DMV sys.dm_exec_query_stats запросы с большим количеством физических считываний или используйте средство мониторинга, которое может предоставить вам эту информацию (например, представление верхнего SQL в Performance Advisor), а затем исправьте эти запросы.
Сопоставьте падение PLE с запланированными заданиями агента, которые выполняют обслуживание базы данных.
Найдите запросы с очень большой памятью для выполнения запросов, предоставляющей память, с помощью DMV sys.dm_exec_query_memory_grants, а затем исправьте эти запросы.
Резюме
Не попадайтесь в ловушку веры в какой-либо рекомендуемый порог, который вы можете прочитать в Интернете. Лучший способ реагировать на изменения PLE – это когда PLE опускается ниже вашего уровня комфорта и остается там-это признак проблемы с производительностью, которую вам следует изучить.
Часть вторая ( Paul Randal )
PLE - это не то, что вы думаете
Существует много споров по поводу ожидаемой продолжительности жизни страницы счетчика объектов производительности диспетчера буферов – в основном из-за того, что люди продолжают указывать 300 в качестве порога для того, чтобы начать беспокоиться о наличии проблемы (что в наши дни просто полная чушь). Это слишком *низко*, чтобы быть точкой, в которой можно начать беспокоиться, если ваш PLE упадет и останется там. Джонатан придумал лучший номер для использования – в зависимости от размера вашего буферного пула – см. Нижнюю часть его поста здесь.
Но я пишу сегодня не поэтому: я хочу объяснить, почему в большинстве случаев Ожидаемая продолжительность жизни страницы на самом деле не дает вам полезной информации.
Большинство новых систем сегодня используют NUMA, и поэтому пул буферов разделен и управляется для каждого узла NUMA, при этом каждый узел NUMA получает свой собственный поток lazy writer, управляет своим собственным списком свободных буферов и занимается распределением локальной памяти узла. Думайте о каждом из них как о мини-буферном пуле.
Счетчик Buffer Manager:Page Life Expectancy рассчитывается путем добавления PLE каждого мини-буферного пула, а затем вычисления среднего значения. Но это не среднее арифметическое, как мы все думали всегда, это среднее гармоническое (см. Википедию здесь), поэтому значение ниже среднего арифметического. (5/11/2015: Спасибо Мэтту Слокуму (b | t) за указание на расхождение со средним арифметическим в большой системе NUMA и за то, что заставил меня углубиться в это подробнее, и моему другу Бобу Дорру из CSS за то, что он углубился в код.)
Что это значит? Это означает, что общий PLE не дает вам истинного представления о том, что происходит на вашей машине, так как один узел NUMA может испытывать нехватку памяти, но *общий* PLE будет лишь незначительно снижаться. У одного из моих друзей, который является ведущим полевым инженером и MCM, только что была такая ситуация сегодня, что побудило к этому сообщению в блоге. Загадка заключалась в том, как может происходить более 100 ленивых записей в секунду, когда общий PLE относительно статичен – и в этом была проблема.
Например, для машины с 4 узлами NUMA, где PLE каждого составляет 4000, общий PLE составляет 4000.
Расчет таков: добавьте обратные числа (1000 x PLE) для каждого узла, разделите их на количество узлов, а затем разделите на 1000.
В моем примере это 4 / (1/(1000 x 4000) + 1/(1000 x 4000) + 1/(1000 x 4000) + 1/(1000 x 4000)) / 1000 = 4000.
Теперь, если один из них упадет до 2200, общий PLE снизится только до: 4 / (1/(1000 x 2200) + 1/(1000 x 4000) + 1/(1000 x 4000) + 1/(1000 x 4000)) / 1000 = 3321.
Если бы у вас было установлено оповещение о снижении PLE на 20%, оно бы не сработало, даже если бы один из буферных узлов находился под высоким давлением.
И вы тоже должны быть осторожны, чтобы не слишком остро реагировать. Если один из них снизится до 200, общий PLE снизится только до: 4 / (1/(1000 x 200) + 1/(1000 x 4000) + 1/(1000 x 4000) + 1/(1000 x 4000)) / 1000 = 695, что может заставить вас подумать, что сервер сильно страдает по всем направлениям.
На компьютерах NUMA вам необходимо просматривать счетчики Buffer Node:Page Life Expectancy для всех узлов NUMA, иначе вы не получите точного представления о нехватке памяти в буферном пуле и поэтому можете пропустить или чрезмерно реагировать на проблемы с производительностью. И отрегулируйте пороговое значение Джонатана в соответствии с количеством имеющихся у вас узлов NUMA.
Вы можете просмотреть активность lazywriter для каждого узла NUMA, выполнив поиск потоков lazywriter в файле sys.dm_exec_requests.
Надеюсь, это поможет!
Дополнение ( Brent Ozar )
PLE увеличивается на 1 секунду за каждую секунду, когда у вас нет недостатка в памяти. Перезапустите экземпляр SQL Server и посмотрите PLE: он начинается с 1 и увеличивается на 1 за каждую секунду времени безотказной работы. 5 минут безотказной работы = 300 пл. В течение первых 5 минут не похоже, что ваш сервер испытывает нехватку памяти – он просто проснулся, черт возьми. Дайте ему 15-20 минут. Думаю, PLE почти бесполезен в течение этого промежутка времени.
Снижение PLE может быть вызвано некоторыми операциями. По умолчанию любой выполняемый запрос может получить доступ к памяти размером 25% от вашего буферного пула. Выполните несколько таких запросов одновременно, и ваш пул буферов истощится, но PLE не обязательно упадет. Однако в тот момент, когда выполняется несвязанный запрос и требуется получить данные, которые не кэшируются в оперативной памяти, ваш PLE катастрофически упадет. Какие запросы являются причиной? Запросы, получающие большие гранты, или запросы, выполняющие чтение?
PLE - это запаздывающий показатель. Запаздывающие индикаторы-это то, что говорит вам о чрезвычайной ситуации спустя долгое время после того, как произошла чрезвычайная ситуация, а запаздывающие индикаторы не восстанавливаются быстро после того, как чрезвычайная ситуация закончилась. Если вы объедините две вышеперечисленные проблемы – увеличение PLE только на 1 в секунду и уменьшение PLE в моменты, которые не обязательно связаны с удалением буферного пула, – то, если вы предупреждаете на основе низких чисел PLE, вы, возможно, уже пропустили аварийную ситуацию. Когда вы входите в систему и смотрите, какие выполняются длительные запросы, уже слишком поздно. Вместо этого вы должны использовать опережающие индикаторы: то, что говорит вам о приближении проблемы.
Имея это в виду, я полностью удалил предупреждения о PLE из sp_BlitzFirst.
На сервере этот параметр получается запросом из представления sys.dm_os_performance_counters. Данные PLE группированы по нодам. Колонка cntr_type = 65792 - текущее значение счетчика. Смотрите подробнее в документации.
Переводчик выражает благодарность Виктору Богачеву – автору и ведущему «Подготовка к 1С:Эксперту по технологическим вопросам. Основной курс» за спонсорскую помощь.