


.png")







Источник https://www.alexdebrie.com/posts/dynamodb-single-table/.
Делаю для лучшего понимания применимости связки Yandex Serverless + Yandex Database (Document API, совместим с Amazon DynamoDB) для небольших проектов, которые попадают в бесплатную тарификацию.
За последние несколько лет я стал большим сторонником DynamoDB. DynamoDB предоставляет множество преимуществ, которых нет у других баз данных, таких как гибкая модель ценообразования, модель подключения без состояния, которая легко работает с бессерверными вычислениями, и постоянное время отклика, даже если ваша база данных масштабируется до огромных размеров.
Тем не менее, моделирование данных с помощью DynamoDB сложно для тех, кто привык к реляционным базам данных, которые доминировали в течение последних нескольких десятилетий. Существует ряд особенностей моделирования данных с помощью DynamoDB, но самой большой из них является рекомендация AWS использовать единую таблицу для всех ваших записей.
В этом посте мы подробно рассмотрим концепции, лежащие в основе дизайна с одной таблицей. Ты научишься:
- Что такое дизайн с одной таблицей
- Почему необходим дизайн с одной таблицей
- Недостатки дизайна с одной таблицей
- Два случая, когда недостатки дизайна с одной таблицей перевешивают преимущества
Что такое дизайн с одной таблицей
Прежде чем мы зайдем слишком далеко, давайте определим дизайн с одной таблицей. Чтобы сделать это, мы совершим краткое путешествие по истории баз данных. Мы рассмотрим некоторые основы моделирования в реляционных базах данных, а затем посмотрим, почему вам нужно моделировать по другому в DynamoDB. Таким образом, мы увидим ключевую причину использования дизайна с одной таблицей.
В конце этого раздела мы также кратко рассмотрим некоторые другие, меньшие преимущества дизайна с одной таблицей.
Общие сведения о SQL-моделировании и соединениях
Давайте начнем с нашего хорошего друга, реляционной базы данных.
С реляционными базами данных вы обычно нормализуете свои данные, создавая таблицу для каждого типа объектов в вашем приложении. Например, если вы создаете приложение для электронной коммерции, у вас будет одна таблица для клиентов и одна таблица для заказов.

Каждый Заказ принадлежит определенному Клиенту, и вы используете внешние ключи для перехода от записи в одной таблице к записи в другой. Эти внешние ключи действуют как указатели — если мне нужна дополнительная информация о Клиенте, который разместил определенный Заказ, я могу перейти по ссылке на внешний ключ, чтобы получить информацию о Клиенте.
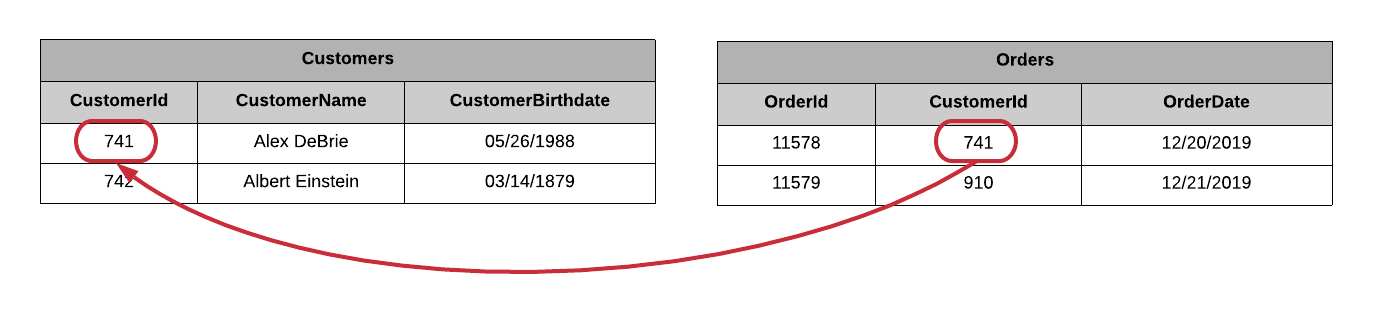
Чтобы следовать этим указателям, язык SQL для запросов к реляционным базам данных имеет концепцию объединений. Соединения позволяют объединять записи из двух или более таблиц во время чтения.
Проблема отсутствия соединений в DynamoDB
Несмотря на удобство, SQL-соединения также дороги. Они требуют сканирования больших фрагментов нескольких таблиц в вашей реляционной базе данных, сравнения различных значений и возврата результирующего набора.
DynamoDB был создан для огромных, высокоскоростных вариантов использования, таких как Amazon.com корзина для покупок. Эти варианты использования не могут мириться с несогласованностью и снижением производительности объединений по мере масштабирования набора данных.
DynamoDB тщательно защищает от любых операций, которые не будут масштабироваться, и нет хорошего способа масштабировать реляционные соединения. Вместо того, чтобы работать над улучшением масштабирования соединений, DynamoDB решает проблему, удаляя возможность использования соединений вообще.
Но как разработчик приложений, вы все еще нуждаетесь в некоторых преимуществах реляционных соединений. И одним из больших преимуществ объединений является возможность получать несколько разнородных элементов из вашей базы данных в одном запросе.
В нашем примере выше мы хотим получить как запись клиента, так и все заказы для клиента. Многие разработчики применяют шаблоны реляционного проектирования с помощью DynamoDB, даже если у них нет реляционных инструментов, таких как операция соединения. Это означает, что они помещают свои товары в разные таблицы в соответствии с их типом. Однако, поскольку в DynamoDB нет соединений, им потребуется выполнить несколько последовательных запросов для получения как Заказов, так и записи клиента.
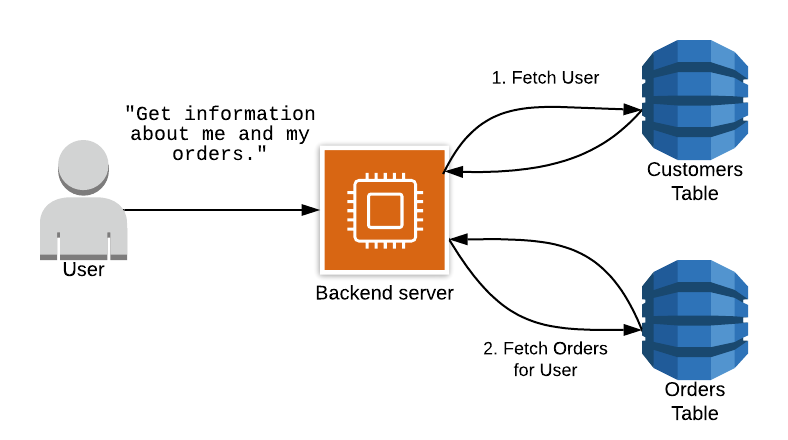
Это может стать большой проблемой в вашем приложении. Сетевой ввод-вывод, вероятно, является самой медленной частью вашего приложения, и вы выполняете несколько сетевых запросов каскадным способом, когда один запрос предоставляет данные, которые используются для последующих запросов. По мере масштабирования вашего приложения этот шаблон становится все медленнее и медленнее.
Решение: предварительно объедините ваши данные в коллекции товаров.
Примечание: автор сильно упростил модель перейдя от "Клиент Заказ" к "Фильм Актер"
Итак, как вы получаете быструю и стабильную производительность от DynamoDB, не делая многократных запросов к вашей базе данных? Путем предварительного объединения ваших данных с помощью коллекций элементов.
Коллекция элементов в DynamoDB ссылается на все элементы таблицы или индекса, которые совместно используют ключ раздела. В приведенном ниже примере у нас есть таблица DynamoDB, которая содержит актеров и фильмы, в которых они играли. Первичный ключ - это составной первичный ключ, где ключом раздела является имя актера, а ключом сортировки - название фильма.
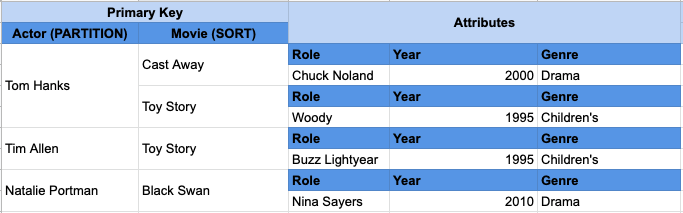
Вы можете видеть, что есть два предмета для Тома Хэнкса — "Изгнание" и "История игрушек". Поскольку у них один и тот же ключ раздела Тома Хэнкса, они находятся в одной и той же коллекции элементов.
Вы можете использовать операцию API запросов DynamoDB для чтения нескольких элементов с одним и тем же ключом раздела. Таким образом, если вам нужно получить несколько разнородных элементов в одном запросе, вы организуете эти элементы так, чтобы они находились в одной коллекции элементов.
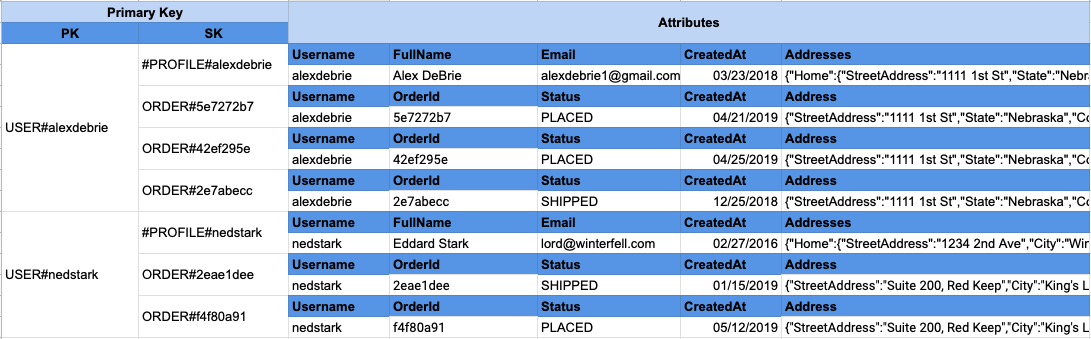
Давайте рассмотрим пример из моего выступления по моделированию данных DynamoDB на AWS re:Invent 2019. В этом примере используется приложение электронной коммерции, подобное тому, которое мы обсуждали, в котором участвуют пользователи и заказы. У нас есть шаблон доступа, в котором мы хотим получить запись пользователя и записи заказов. Чтобы сделать это возможным в одном запросе, мы следим за тем, чтобы все записи заказов находились в той же коллекции товаров, что и запись пользователя, к которой они принадлежат.
Теперь, когда мы хотим получить пользователя и заказы, мы можем сделать это в одном запросе без необходимости дорогостоящей операции соединения:
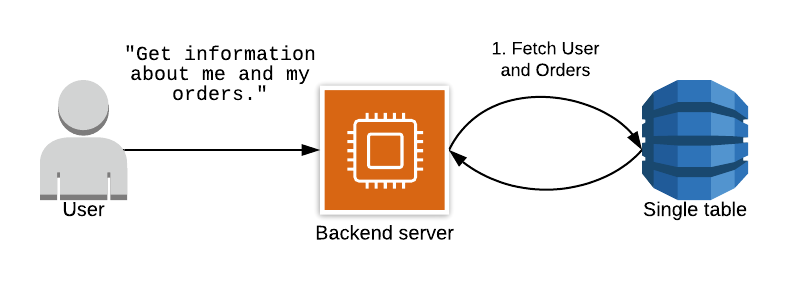
В этом и заключается суть дизайна с одной таблицей - настройка вашей таблицы таким образом, чтобы ваши шаблоны доступа могли обрабатываться как можно меньшим количеством запросов к DynamoDB, в идеале одним.
И поскольку в причудливых кавычках все выглядит лучше, давайте повторим это еще раз:
Основная причина использования одной таблицы в DynamoDB заключается в получении нескольких разнородных типов элементов с помощью одного запроса.
Другие преимущества конструкции с одной таблицы
Хотя сокращение количества запросов к шаблону доступа является основной причиной использования дизайна с одной таблицей с помощью DynamoDB, есть и некоторые другие преимущества. Я кратко остановлюсь на них.
Во-первых, с каждой таблицей, которая у вас есть в DynamoDB, возникают некоторые операционные издержки. Несмотря на то, что DynamoDB полностью управляется и довольно прост в использовании по сравнению с реляционной базой данных, вам все равно необходимо настраивать сигналы тревоги, отслеживать показатели и т.д. Если у вас есть одна таблица со всеми элементами в ней, а не восемь отдельных таблиц, вы уменьшаете количество сигналов тревоги и показателей для просмотра.
Во-вторых, наличие одной таблицы может сэкономить вам деньги по сравнению с наличием нескольких таблиц. Для каждой имеющейся у вас таблицы вам необходимо указать единицы емкости для чтения и записи. Часто вы выполняете некоторую математическую обработку ожидаемого трафика, увеличиваете его на X% и конвертируете в RCU и WCU. Если у вас есть один или два типа сущностей в вашей отдельной таблице, к которым обращаются гораздо чаще, чем к другим, вы можете скрыть часть дополнительной емкости для менее часто используемых элементов в буфере для других элементов.
Хотя эти два преимущества реальны, они довольно незначительны. Операционная нагрузка на DynamoDB довольно низкая, а цены позволят вам сэкономить немного денег на марже. Кроме того, если вы используете цены DynamoDB по запросу, вы не сэкономите никаких денег, перейдя к дизайну с одной таблицей.
В общем, когда вы думаете о дизайне с одной таблицей, вы должны учитывать, что основным преимуществом является повышение производительности за счет выполнения одного запроса для повторного поиска всех необходимых элементов.
Недостатки конструкции с одной таблицей
Несмотря на то, что шаблон с одной таблицей является мощным и хорошо масштабируемым, он не обходится без затрат. В этом разделе мы рассмотрим некоторые недостатки дизайна с одной таблицей.
На мой взгляд, у дизайна с одной таблицей в DynamoDB есть три недостатка:
- Крутая кривая обучения для понимания дизайна с одной таблицей;
- Негибкость добавления новых шаблонов доступа;
- Сложность экспорта ваших таблиц для аналитики.
Давайте рассмотрим каждый из них по очереди.
Крутая кривая обучения дизайну с одной таблицей
Самая большая жалоба, которую я получаю от членов сообщества, связана с трудностями изучения дизайна с одной таблицей в DynamoDB.
Одна перегруженная таблица DynamoDB выглядит действительно странно по сравнению с чистыми нормализованными таблицами вашей реляционной базы данных. Трудно забыть все уроки, которые вы усвоили за годы моделирования реляционных данных.
Для тех, кто избегает дизайна с одной таблицей из-за кривой обучения, мой ответ таков:
Жестко.
Разработка программного обеспечения - это непрерывный процесс обучения, и вы не можете использовать трудности изучения новых вещей в качестве оправдания для плохого использования новой вещи.
Позже в этом посте я опишу несколько случаев, когда, по моему мнению, можно отказаться от использования дизайна с одной таблицей. Однако вы должны полностью понять принципы, лежащие в основе дизайна с одной таблицей, прежде чем принимать это решение. Незнание не является причиной для того, чтобы избегать общих лучших практик.
Негибкость новых моделей доступа
Вторая жалоба на DynamoDB заключается в трудности размещения новых шаблонов доступа в конструкции с одной таблицей. Эта жалоба имеет гораздо больше оснований.
При моделировании дизайна с одной таблицей в DynamoDB вы сначала начинаете с шаблонов доступа. Подумайте хорошенько (и запишите!) как вы будете получать доступ к своим данным, затем тщательно смоделируйте свою таблицу, чтобы соответствовать этим шаблонам доступа. При этом вы организуете свои элементы в коллекции таким образом, чтобы каждый шаблон доступа можно было обрабатывать с помощью как можно меньшего количества запросов — в идеале с помощью одного запроса.
Как только вы смоделируете свою таблицу, вы приводите ее в действие и пишете код для ее реализации. И, если все сделано правильно, это будет отлично работать! Ваше приложение сможет масштабироваться бесконечно без снижения производительности.
Однако дизайн вашей таблицы точно соответствует той цели, для которой он был разработан. Если ваши шаблоны доступа меняются из-за добавления новых объектов или доступа к нескольким объектам разными способами, вам может потребоваться выполнить процесс ETL для сканирования каждого элемента в вашей таблице и обновления с новыми атрибутами. Этот процесс не является невозможным, но он добавляет дополнительные затраты в ваш процесс разработки.
Сложность аналитики
DynamoDB предназначен для случаев использования OLTP — высокоскоростной высокоскоростной доступ к данным, когда вы работаете с несколькими записями одновременно. Но пользователи также нуждаются в шаблонах доступа OLAP — больших аналитических запросах по всему набору данных для поиска популярных товаров, количества заказов за день или другой информации.
DynamoDB плохо справляется с OLAP-запросами. Это сделано намеренно. DynamoDB фокусируется на высокой производительности запросов OLTP и хочет, чтобы вы использовали другие специализированные базы данных для OLAP. Чтобы сделать это, вам нужно будет перенести ваши данные из DynamoDB в другую систему.
Если у вас есть единый дизайн таблицы, привести ее в надлежащий формат для системы аналитики может быть непросто. Вы денормализовали свои данные и скрутили их в крендель, предназначенный для обработки ваших конкретных вариантов использования. Теперь вам нужно развернуть эту таблицу и повторно нормализовать ее, чтобы она была полезна для аналитики.
Моя любимая цитата по этому поводу взята из превосходного пошагового руководства Форреста Бразила по дизайну одной таблицы:
[A] хорошо оптимизированный макет DynamoDB с одной таблицей больше похож на машинный код, чем на простую электронную таблицу
Электронные таблицы удобны для аналитики, в то время как для разработки дизайна с одной таблицей требуется определенная работа. В процессе разработки необходимо будет продвинуть работу над инфраструктурой данных, чтобы убедиться, что вы сможете воссоздать свою таблицу удобным для аналитики способом.
Когда не следует использовать дизайн с одной таблицей
На данный момент мы знаем плюсы и минусы дизайна с одной таблицей в DynamoDB. Теперь пришло время перейти к более спорной части — когда, если вообще когда-либо, вам не следует использовать дизайн с одной таблицей в DynamoDB?
На базовом уровне ответ таков: “всякий раз, когда выгоды не перевешивают затраты”. Но этот общий ответ нам мало чем помогает. Более конкретный ответ звучит так: “всякий раз, когда мне нужна гибкость запросов и / или более простая аналитика больше, чем мне нужна невероятно быстрая производительность”. И я думаю, что есть два случая, когда это наиболее вероятно:
- в новых приложениях, где гибкость разработчика важнее производительности приложения;
- в приложениях, использующих GraphQL.
Мы рассмотрим каждый из них ниже. Но сначала я хочу подчеркнуть, что это исключения, а не общие рекомендации. При моделировании с помощью DynamoDB вы должны следовать рекомендациям. Это включает в себя денормализацию, дизайн с одной таблицей и другие правильные принципы моделирования NoSQL. И даже если вы выберете дизайн с несколькими таблицами, вы должны понимать дизайн с одной таблицей, чтобы понять, почему он не подходит для вашего конкретного приложения.
Новые приложения, в которых приоритет отдается гибкости
В последние несколько лет многие стартапы и предприятия предпочитают использовать для своих приложений бессерверные вычисления, такие как AWS Lambda. Бессерверная модель обладает рядом преимуществ: от простоты развертывания до безболезненного масштабирования и модели ценообразования с оплатой за использование.
Многие из этих приложений используют DynamoDB в качестве своей базы данных из-за того, что он легко вписывается в бессерверную модель. Начиная с подготовки, ценообразования и заканчивая разрешениями для модели подключения, DynamoDB идеально подходит для бессерверных приложений, в то время как традиционные реляционные базы данных являются более проблематичными.
Однако важно помнить, что, хотя DynamoDB отлично работает с бессерверными, он не был создан для бессерверных.
DynamoDB был создан для крупномасштабных высокоскоростных приложений, которые превосходили возможности реляционных баз данных. А реляционные базы данных могут масштабироваться чертовски далеко! Если вы находитесь в ситуации, когда вы масштабируете реляционную базу данных, вы, вероятно, хорошо представляете, какие шаблоны доступа вам нужны. Но если вы создаете новое приложение при запуске, маловероятно, что вам абсолютно необходимы возможности масштабирования DynamoDB для запуска, и вы можете не знать, как ваше приложение будет развиваться с течением времени.
В этой ситуации вы можете решить, что характеристики производительности дизайна с одной таблицей не стоят потери гибкости и более сложной аналитики. Вы можете выбрать подход с использованием искусственного SQL, при котором вы используете DynamoDB, но реляционным способом, нормализуя свои данные в нескольких таблицах.
Это означает, что вам может потребоваться выполнить несколько последовательных вызовов DynamoDB, чтобы удовлетворить ваши шаблоны доступа. Ваше заявление может выглядеть следующим образом:

Обратите внимание, что есть два отдельных запроса к DynamoDB. Сначала есть запрос на получение пользователя, затем есть последующий запрос на получение заказов для данного пользователя. Поскольку необходимо выполнить несколько запросов, и эти запросы должны выполняться последовательно, время отклика клиентов вашего серверного приложения будет медленнее.
Для некоторых случаев использования это может быть приемлемо. Не все приложения должны иметь время отклика менее 30 мс. Если ваше приложение работает нормально со временем отклика 100 мс, повышенная гибкость и упрощенная аналитика для вариантов использования на ранних стадиях могут оправдать снижение производительности.
GraphQL и дизайн с одной таблицей
Второе место, где вы, возможно, захотите избежать разработки одной таблицы с помощью DynamoDB, - это приложения GraphQL.
Прежде чем я получу кучу возражений "Ну, на самом деле", я хочу уточнить, что да, я знаю, что GraphQL - это механизм выполнения, а не язык запросов для конкретной базы данных. И да, я знаю, что GraphQL не зависит от базы данных.
Я не хочу сказать, что вы не можете использовать дизайн с одной таблицей с GraphQL. Я говорю, что из-за того, как работает выполнение GraphQL, вы теряете большую часть преимуществ дизайна с одной таблицей, все еще наследуя все затраты.
Чтобы понять почему, давайте взглянем на то, как работает GraphQL, и на одну из основных проблем, которую он призван решить.
За последние несколько лет многие приложения выбрали API на основе REST в бэкэнде и одностраничное приложение во внешнем интерфейсе. Это может выглядеть следующим образом:
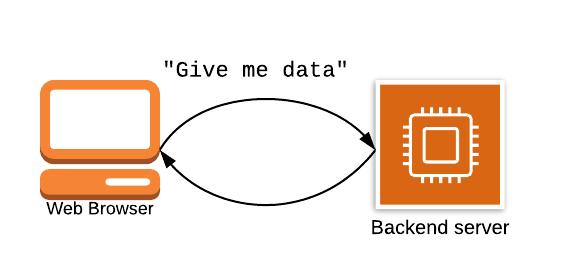
В API, основанном на REST, у вас есть различные ресурсы, которые обычно сопоставляются с объектом в вашем приложении, например Пользователями или Заказами. Вы можете выполнять операции, подобные CRUD, с этими ресурсами, используя различные HTTP-глаголы для указания операции, которую вы хотите выполнить.
Одним из распространенных источников разочарования для разработчиков интерфейсов при использовании API на основе REST является то, что им может потребоваться выполнить несколько запросов к разным конечным точкам для получения всех данных для данной страницы:
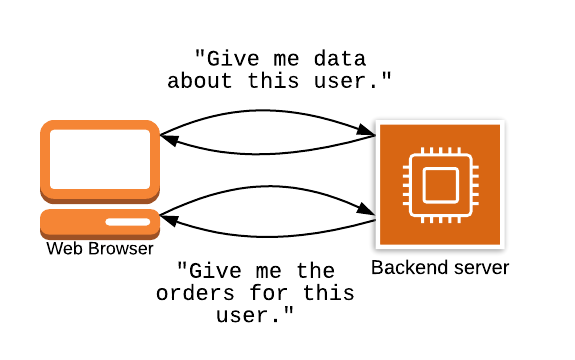
В приведенном выше примере клиент должен сделать два запроса — один, чтобы получить пользователя, и один, чтобы получить самые последние заказы для пользователя.
С помощью GraphQL вы можете получить все необходимые данные для страницы в одном запросе. Например, у вас может быть запрос GraphQL, который выглядит следующим образом:
query { User( id:112233 ){
firstName
lastName
addresses
orders {
orderDate
amount
status
}
}
}
В приведенном выше блоке мы выполняем запрос для получения пользователя с идентификатором 112233, затем мы извлекаем определенные атрибуты пользователя (включая имя, фамилию и адреса), а также все заказы, принадлежащие этому пользователю.
Теперь наш поток выглядит следующим образом:
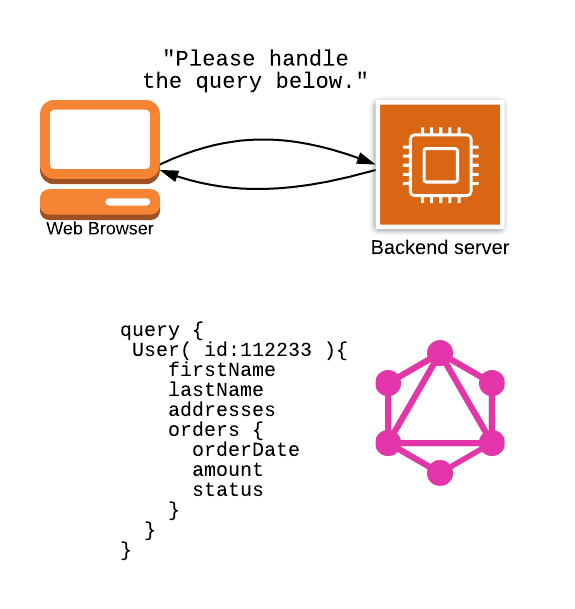
Веб-браузер отправляет один запрос на наш внутренний сервер. Содержимым этого запроса будет наш запрос GraphQL, как показано ниже сервера. Реализация GraphQL проанализирует запрос и обработает его.
Это выглядит как выигрыш — наш клиент делает только один запрос к серверной части! Ура!
В некотором смысле это отражает наше предыдущее обсуждение того, почему вы хотите использовать дизайн с одной таблицей в DynamoDB. Мы хотим сделать только один запрос к DynamoDB для извлечения разнородных элементов, точно так же, как интерфейс хочет сделать один запрос к серверной части для извлечения разнородных ресурсов. Это звучит как брак, заключенный на небесах!
Проблема заключается в том, как GraphQL обрабатывает эти ресурсы в серверной части. Каждое поле каждого типа в вашей схеме GraphQL обрабатывается распознавателем. Этот распознаватель понимает, как заполнять данные для поля.
Для различных типов в вашем запросе, таких как User и Order в нашем примере, у вас обычно будет распознаватель, который будет выполнять запрос к базе данных для разрешения значения. Распознавателю будут предоставлены некоторые аргументы, указывающие, какие экземпляры этого типа должны быть извлечены, а затем распознаватель извлечет и вернет данные.
Проблема в том, что распознаватели по существу независимы друг от друга. В приведенном выше примере сначала будет выполняться корневой распознаватель, чтобы найти пользователя с идентификатором 112233. Это будет включать запрос к базе данных. Затем, как только эти данные будут доступны, они будут переданы в распознаватель заказов, чтобы получить соответствующие заказы для этого пользователя. Это привело бы к последующим запросам к базе данных для разрешения этих объектов.
Теперь наш поток выглядит следующим образом:
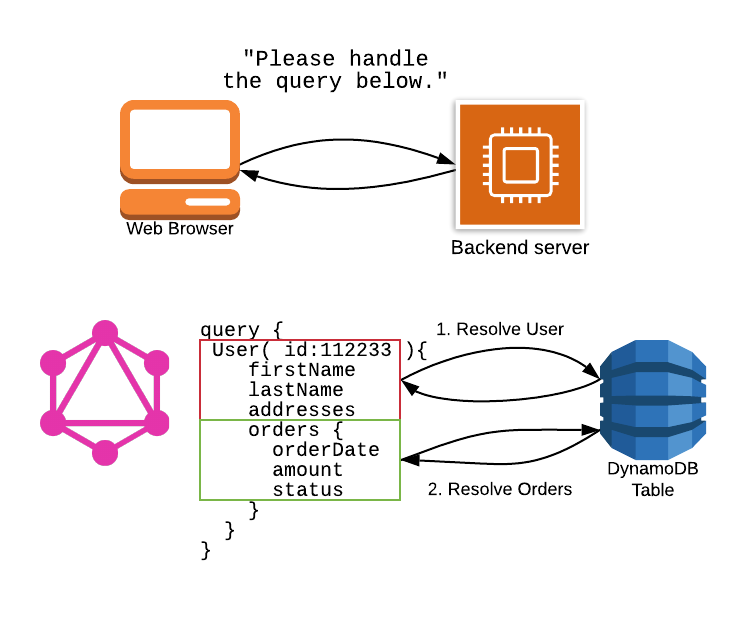
В этом потоке наш серверный сервер выполняет несколько последовательных запросов к DynamoDB для выполнения нашего шаблона доступа. Это именно то, чего мы пытаемся избежать с помощью дизайна с одной таблицей!
Ничто из этого не говорит о том, что вы не можете использовать DynamoDB с GraphQL — вы абсолютно можете. Я просто думаю, что тратить время на разработку одной таблицы при использовании GraphQL с DynamoDB - пустая трата времени. Поскольку сущности GraphQL разрешаются отдельно, я думаю, что неплохо смоделировать каждую сущность в отдельной таблице. Это обеспечит большую гибкость и упростит задачу аналитики в будущем.
Вывод
В этом посте мы рассмотрели концепцию проектирования с одной таблицей в DynamoDB. Во-первых, мы немного рассказали о том, как развивались NoSQL и DynamoDB и почему необходим дизайн с одной таблицей.
Во-вторых, мы рассмотрели некоторые недостатки дизайна с одной таблицей в DynamoDB. В частности, мы увидели, как дизайн с одной таблицей может затруднить разработку ваших шаблонов доступа и усложнить вашу аналитическую работу.
Наконец, мы рассмотрели две ситуации, в которых преимущества дизайна с одной таблицей в DynamoDB могут не перевешивать затраты. Первая ситуация возникает в новых, быстро развивающихся приложениях, использующих бессерверные вычисления, где гибкость разработчика имеет первостепенное значение. Вторая ситуация возникает при использовании GraphQL из-за того, как работает поток выполнения GraphQL.
Я по-прежнему являюсь убежденным сторонником дизайна с одной таблицей в DynamoDB в большинстве случаев использования. И даже если вы не считаете, что это подходит для вашей ситуации, я все равно думаю, что вам следует изучить и понять дизайн с одной таблицей, прежде чем отказаться от него. Базовые принципы проектирования NoSQL помогут вам, даже если вы не следуете лучшим практикам крупномасштабного проектирования.
Вступайте в нашу телеграмм-группу Инфостарт