Меня зовут Евгений Скребанов, я буду выступать вместе с Иваном Мищенко – мы с ним представляем компанию «Консон».
В ходе доклада мы планируем рассказать историческую справку о появлении систем бизнес-аналитики – Business Intelligence (BI), поговорим про стек технологий, рассмотрим, какие вообще в принципе BI-системы существуют.
Я сам – Qlik специалист с 2010 года, в 2014 году получил от вендора награду Qlik Luminary – по сути, это награда за евангелизм. На текущий момент мной реализовано более 70 различных проектов по QlikView в разных странах – это Россия, страны Скандинавии, СНГ, Латинская и Северная Америка. Соответственно, я расскажу про Qlik – какие у него принципиальные отличия от других систем.
А основной исторический экскурс вам сейчас организует Иван Мищенко – он с 2002 года работает руководителем проектов и архитектором систем, а также по совместительству является специалистом по искусственному интеллекту.
Развитие человечества неразрывно связано с освобождением, а история прогресса – это история освобождения
Иван: Несколько лет назад у нашей компании появился запрос на написание собственной BI-системы – этим мы до сих пор и занимаемся. Это нас подстегнуло к тому, чтобы всецело и всесторонне детально исследовать все, что происходит на рынке BI-аналитики, обработки данных – как и каким образом системы, технологии и бизнесы к этому пришли.
Мы решили изучить рынок и теоретические основания технологий, которые являются основанием для рынка BI, и вообще для рынка вычислительной техники.
Для этого нам пришлось зарыться достаточно глубоко. С самого начала мы зарылись очень глубоко – в какие-то доисторические времена, чтобы вообще разобраться, что такое числа, откуда они взялись, как они обрабатываются, почему именно десятичная запись, почему остальные виды записи оказались неудобны – разбирались, что такое арифметические операции, как происходило их усложнение, что такое множества и т.д.
С точки зрения нашей практики это нам действительно было интересно, но сегодня мы решили начать все-таки с 1900 года, потому что с этого момента начинается все то, что можно отнести к учету и к BI.
От вычислений к моделям
В 1900 году в мире происходили бурные события – шла Первая мировая война, за ней последовал большой экономический кризис, за этим последовали множество революций – в том числе, например, революция в Китае.
Именно в Китай в 1928 году был направлен Василий Леонтьев во главе американской делегации. Василий Леонтьев был выпускником российских университетов, перебравшийся после революции в Америку. И в Китае он организовывал и оптимизировал строительство железнодорожной сети. Америка – одна из тех стран, которая строила железные дороги у себя единым проектом. Они договорились с правительством Чан Кайши и послали туда делегацию. Почему я акцентирую внимание на Василии Леонтьеве? Потому что в конце 1920-х начале 1930-х годов Василий Леонтьев активно развивал различные макроэкономические и эконометрические модели – например, он разработал модель межотраслевого баланса и был одним из тех, кто приложил руку к появлению модели кейнсианства. С точки зрения BI это доказывает, что как раз в то время люди начали уже на все смотреть глобально, поэтому аналитические модели начали сильно усложняться.
Если же посмотреть на технику, в которой это все организовывалось, она на тот момент была еще механическая (даже не электромеханическая). И это, в свою очередь, натолкнуло группу ученых во главе с Гильбертом на мысль, что мы можем представить наше мышление, как набор каких-то кубиков, из которых потом можно найти решение любой задачи – если их правильно расположить один за другим, как в счетной машине. Одна шестеренка будет цепляться за другую, и будет имитировать или даже воспроизводить человеческое мышление и разум. На тот момент основным теоретическим основанием математики считалась теория множеств, считалось, что «математика = разум» (некоторые до сих пор так считают). Эта программа была предложена Гильбертом в 1915-м году – в хронологии на слайде ниже это показано.
Причем программой Гильберта занималась большая группа ученых – они тут же разделились. Одни считали, что свести мышление к математике можно, другие утверждали, что нельзя. В результате эта надежда не сбылась – через 15 лет исследований в 1930 году Гёдель вывел теорему, что из теории множеств нельзя построить всю математику, а, соответственно, и всю разумность. Вроде это и провал, но, с другой стороны, была проведена огромная работа по систематизации знаний – по тому, как устроены вычисления, какие методы вычислений существуют.
Механистический подход до сих пор никого не покидал, и к 1936-му году Тьюринг выдвинул свою вычислительную концепцию, которой мы пользуемся до сих пор. Это была математическая концепция абстрактной вычислительной машины, которую мы называем «машиной Тьюринга». С этого момента начинается бурное развитие теории вычислений – именно в это время сложилось понятие вычислимости. И почти весь инструмент, которым мы сегодня пользуемся, так или иначе получил толчок в развитии именно благодаря этому открытию.
Все это происходило на фоне неуспокаивающегося мира – это было время «Великой депрессии», когда на государственном уровне началось использование того же кейнсианства, которое требует использования больших вычислительных мощностей – это большие государственные инвестиции. Тут же началась еще и вторая мировая война, которая тоже потребовала больших вычислительных мощностей для расчетов баллистических траекторий и прочего. Запросы на вычислительную технику выросли.
Если говорить про рынок вычислительной техники, то ориентировочно можно сказать, что он появился в 1911 году, когда была основана компания IBM. Но сам рынок вычислений существовал и до этого – существовало множество компаний, которые занимались вычислениями, они все использовали примерно одни и те же технологии.
До того момента, пока ближе к 1944 году не был изобретен первый электронный компьютер ENIAC и была предложена концепция машины фон Неймана, которой мы все сегодня пользуемся. Получается, что математическая абстракция была дополнена уже некоей технологической концепцией, которая впоследствии уже нам создала все те продукты, которыми мы все сегодня пользуемся. Можно говорить, что ENIAС построен по архитектуре Мартина фон Неймана. После этого действительно начинается бурное развитие.
Очень важно еще отметить, что в 1953 году проблема неприменимости теории множеств для теоретического основания математики была решена после того, как Саундерс Маклейн создал теорию категорий.

Посмотрите на диаграмму на слайде – я объясню, что здесь значат стрелочки.
-
Наверху, на четвертом уровне, большими кружками – это основные теоретические фундаментальные открытия.
-
На третьем уровне – это прикладные открытия, которые здесь в хронологии отмечены.
-
На втором уровне у нас идут какие-то технологические прорывы.
-
И внизу – все, что связано уже непосредственно с продуктами и компаниями – с внедрением этих технологий.
Обратите внимание, что на этой схеме от большого кружка с появлением теории категорий в 1953 году никаких стрелочек не идет. Хотя это и мощный теоретический прорыв, который получил некоторое прикладное применение в языках Lisp, Haskel, Prolog, на текущий момент мне неизвестны продукты, которые бы хорошо этим пользовались. Позже это сыграет определенную роль.
Дальше у нас уже идет бурное развитие прикладного программного обеспечения:
-
В 1961 году мы получаем микросхемы, с которыми отправляются американцы на Луну в рамках программы «Аполлон». В том же году мы получаем компьютер Марк-1, в устройстве которого используются первые перцептроны. Напомню, что перцептрон – это первая модель формального нейрона, прародитель наших нейросетей сегодня.
-
В 1972 году группа ученых – Эдвард Лоренц и Бенуа Мандельброт начинают заниматься проблемами теории хаоса, выполняют исследования фракталов. Зачем это нужно? Потому что с помощью такого рода моделей мы начинаем отслеживать рынки, мы начинаем замечать там какие-то закономерности, и эта хаотичность, которая была у нас в начале века, перестает так пугать людей – люди понимают, что можно что-то брать под контроль, и вместе с этим пониманием начинается и рост бизнеса, рост капитала. Мы знаем, что у нас начинают увеличиваться наши корпорации, и они уже в свою очередь создают в мире потребность для рынка корпоративных систем.
-
Ответом на эту потребность, на этот спрос становится основание компаний SAP, Oracle и т.д. Нужно еще отметить, что подобными корпоративными системами и системами класса MRP занимались в том числе такие компании, как Siemens, потому что они были связаны непосредственно с теми промышленными датчиками, которые там использовались непосредственно в производстве – температура металла, количество выплавляемого металла. Очень много этим занимались, соответственно, придумывали для всего этого программно-аппаратное сопровождение. Но в отдельном виде этот рынок уже сформировался компаниями, которые с нами до сих пор. Где-то в это же время формируется концепция MRP2, которая нам показывает наше производство не только в количественном (натуральном), а еще и в денежном виде.
-
И дальше уже ничего сверхинтересного или того, что мы не знали, не происходит, но нужно отметить, что в 1993 году как ответ на увеличивающиеся потребности в аналитике баз данных появляется концепция OLAP – она тоже развивается.
-
После этого в 2000-х годах происходит бурное развитие интернета, вместе с развитием интернета появляется и понятие мобильных устройств, что для нас очень важно сегодня.
-
К 2010 году эти устройства из просто мобильных превращаются уже в носимые. И они помогают нам собирать данные – т.е. если в 1970-1980-1990-2000 годы нужно было заставлять пользователя какие-то данные о себе собирать, то сегодня эти данные пользователь отдает сам в виде наручных часов, в виде геолокации и прочего. Собственно, количество данных увеличивается, и появляется такой класс систем, как бизнес-аналитика.
И здесь мы переходим к современности, которая мне не сильно нравится.
Где мы оказались
Все развитие, о котором мы говорили, сопровождалось определенного рода специализацией систем.
Изначально была сделана попытка создать некую общую концепцию ERP, которая себя должна была обобщать все потребности предприятия, полностью покрыть цикл Деминга. Но это, к сожалению, не удалось – по крайней мере, наполовину. Поэтому где-то в 1970-1980-е годы произошло серьезное разделение систем – они в принципе разделились на некие инженерные системы и системы менеджмента и управления.
Многие из тех, кто занимался внедрением, сталкивались, что в инженерных или строительных CAD/CAМ-системах находится очень много полезных данных, и вытаскивать их – серьезная головная боль. Тем более, делать потом из них какие-то планы, шаблоны, спецификации, сметы и пр. – это всегда дополнительный отдельный подпроект или проект в программе проектов.
Поэтому, с одной стороны, мы получали все более и более развитую технику, а с другой стороны, мы получали такую проблему как гиперспециализация. И сегодня мы в принципе с этим сталкиваемся и работаем.
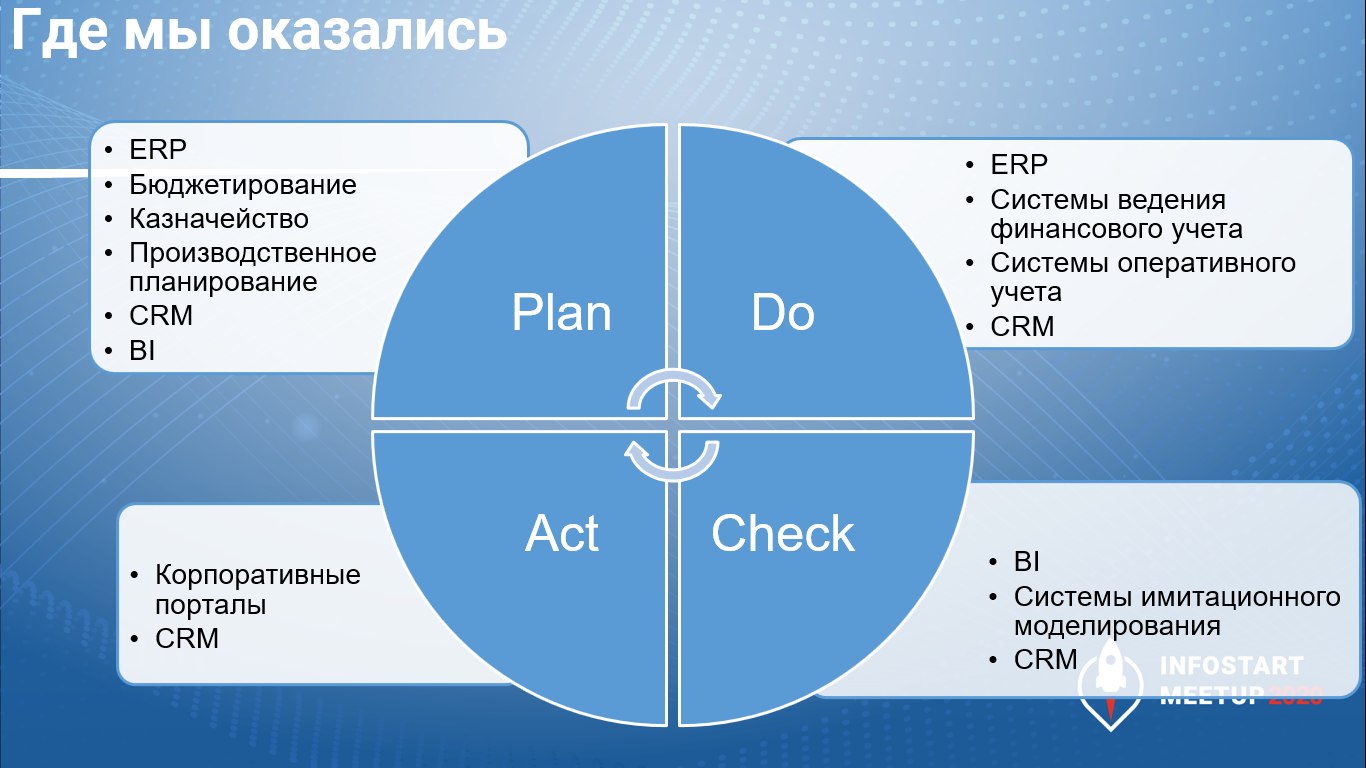
В общем, если посмотреть на рынок систем, связанных с менеджментом, сверху, то мы увидим здесь, что на каждую веху цикла Деминга у нас существуют свои отдельные системы.
-
Plan. Здесь могут быть ситуации, когда для планирования на предприятии используется одна ERP-система (например, Microsoft Dynamics), а рядом с ней живут SAP и БИТ.Финанс: в SAP организуется производственное планирование, а на БИТ.Финансе – казначейство. Я лично знаю два таких проекта.
-
Do. И, если говорить об учете, то точно так же, особенно, в начале 2000-х, пока не были развиты блоки регламентированного учета, рядом могут стоять совсем разные системы – оперативный учет ведется в какой-нибудь западной системе, а регламентированный фискальный учет ведется в 1С:Бухгалтерии – на 7.7 на 8-й платформе.
-
Check. Здесь BI стоит совсем особняком, потому что у него вообще другие задачи – под BI же был разработан целый OLAP. Это не транзакционная модель, это онлайн-модель для аналитики, и она требует больших скоростей. Это – совсем другая архитектура. И, естественно, эта архитектура никак не вписывалась в архитектуру всех прочих систем.
-
Act. Естественно, мы не увидим BI в этой итерации цикла Деминга, где мы применяем наши аналитические решения к действительности. На этапе какой-нибудь презентации BI-система еще как-то работает, но потом, когда дело доходит до непосредственного учета, переписки в каких-то чатах и прочего, здесь уже нет никакого BI. Поэтому все данные зависали на корпоративных порталах, туда нужно было, наверное, как-то заново подключаться, но это всегда была отдельная система.

И, самое главное, что на этом все не заканчивается, потому что под этим всем есть еще несколько других классных систем, которые обеспечивают вообще функционирование – хотя бы какое-то синхронизированное функционирование всего этого зоопарка.
-
ETL;
-
интеграционные шины;
-
хранилища данных;
-
озера данных.
Здесь я уступлю место Евгению, потому что он поможет нам сосредоточиться на том, как устроен рынок BI.
Рынок BI-систем
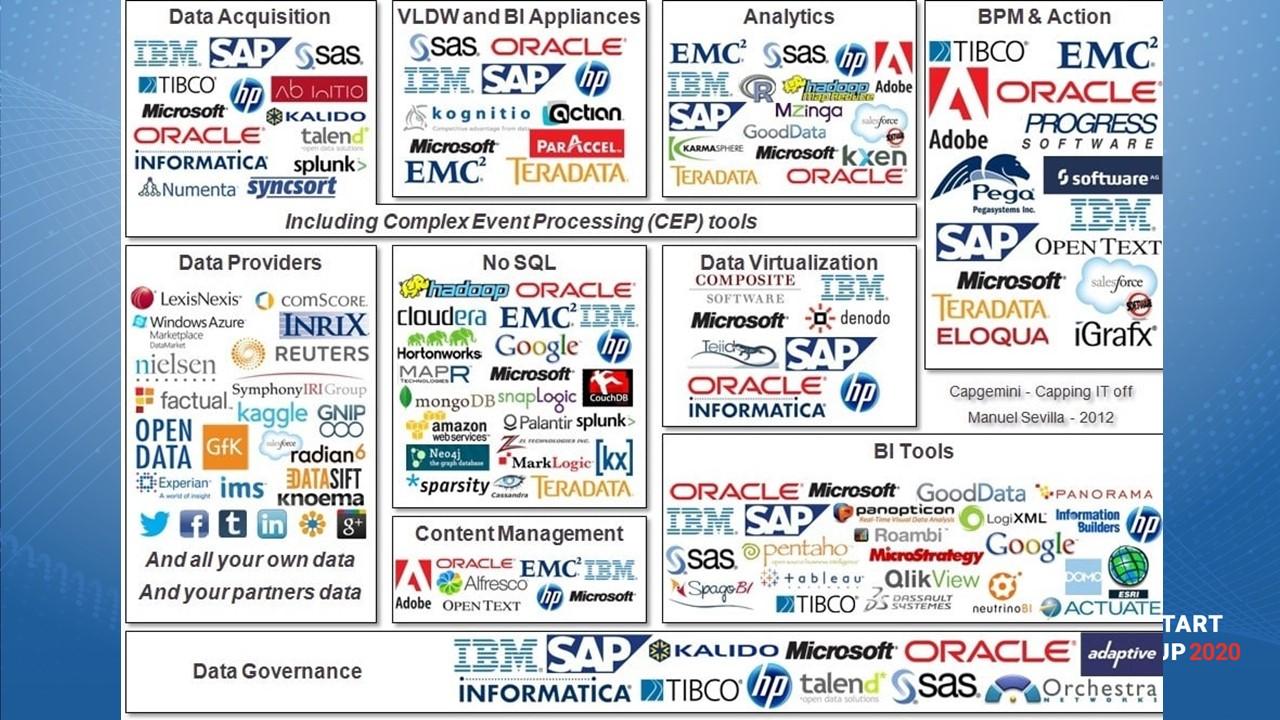
Евгений: перейдем от исторического вводного слова к современному рынку BI.
Начну с очень пестрой картинки, показывающей, насколько мир BI-систем разнообразен. Все, что здесь мы видим на слайде, это – функциональные блоки, которые так или иначе связаны с анализом данных и системами класса Business Intelligence, в частности, здесь мы можем увидеть классические стандартные сегменты сфер профилей обработки данных.
-
Первый сегмент слева – Data Acquisition – это как раз те системы, которые позволяют нам данные получать и каким-либо образом их преобразовывать.
-
Отдельно мы видим по центру выделен No SQL – это современный стек вендоров систем управления баз данных, систем класса софт-менеджеров, в том числе наблюдающих за данными, интеграциями, за синхронизацией данных.
-
Слева от него мы видим Data Providers – это вендоры, которые являются непосредственными провайдерами каких-либо аналитических данных для корпораций. Например. LexisNexis предоставляет юридические данные, а ряд других систем в этом же квадранте предоставляют очищенные статистические или финансовые данные за деньги.
-
Если мы посмотрим на сегменты Content Management, BI Tools, BPM & Action и остальное – это все опять же вендоры и системы, связанные с анализом данных и с представлением функциональности, связанной с обработкой данных.
Т.е. в любом случае, если мы говорим про BI-систему, все у нас основывается на:
-
получении данных;
-
обработке этих данных;
-
и непосредственно уже верхний уровень – анализ этих данных в каком-то виде совместном пользовательском расшаренном, переданном куда-то вовне третьим системам.
В любом случае, все крутится всегда вокруг того, чтобы эти данные получить, обработать и только потом мы уже анализируем.
И, как правило, вся суть решений, которые мы на этом слайде видим, заключается в обработке процессинга данных, какого-то технического или бизнес-технического взгляда на них для дальнейшей интерпретации.

Следующий слайд – более лаконичный. Это – рандомная выборка топ-30 систем, которые сейчас наиболее популярны в мире и, в частности, в России. Это все те вендоры, которые сейчас на слуху (кроме некоторых российских систем).
Почему я здесь в центре крупно указал 1С? Потому что система 1С генерирует данные, и эти данные нужно анализировать.
Здесь безусловными лидерами здесь являются Microsoft с их Excel и Power BI, которые по количеству внедрений исчисляются в миллионах – это доказывает, что потребность в анализе существует даже у самых небольших компаний.
У других лидеров рынка – Qlik, Tableau, того же SAP – количество проектов внедрений исчисляется в десятках-сотнях тысяч.
Причем проекты внедрения BI-систем могут быть представлены в классе от одного пользователя до огромных больших Enterprise-проектов – как правило, современные системы умеют в этом масштабироваться.
Если раньше, в конце 1990, начале 2000 вход в BI был достаточно тяжелый, и малый/средний бизнес вообще в принципе этого не мог себе никак позволить – ни с точки зрения финансов, ни с точки зрения даже технических ресурсов, чтобы внедрить какую-нибудь большую сложную систему в стиле Oracle или SAP BusinessObjects, или отдельных вендоров – например, MicroStrategy или TIBCO – элементарно даже таких специалистов практически не было на рынке – в частности, России. Если вы специалист MicroStrategy – у вас гарантированно была работа на десятилетия.
Десятилетие прошло, и сейчас появляется огромное количество мультифункциональных специалистов – таких, кто сразу может и в Qlik, и в 1С:Аналитику, и во что угодно.
Это доказывает, что в класс тяжелых BI-систем приходит консьюмеризация (от слова консьюмер – потребитель), и они становятся менее тяжелыми – превращаются в так называемые self-service BI.

Отдельно хотел показать основной топ российских производителей BI-систем. Все эти системы – очень интересные, и их имеет смысл рассмотреть. Они все имеют свои фишечки – и технические, и функциональные отличия, и плюсы, и минусы.
Экосистема Qlik
Расскажу подробнее про Qlik, при этом собираюсь немного пересечься с той исторической информацией, которую упоминал Иван в начале доклада.
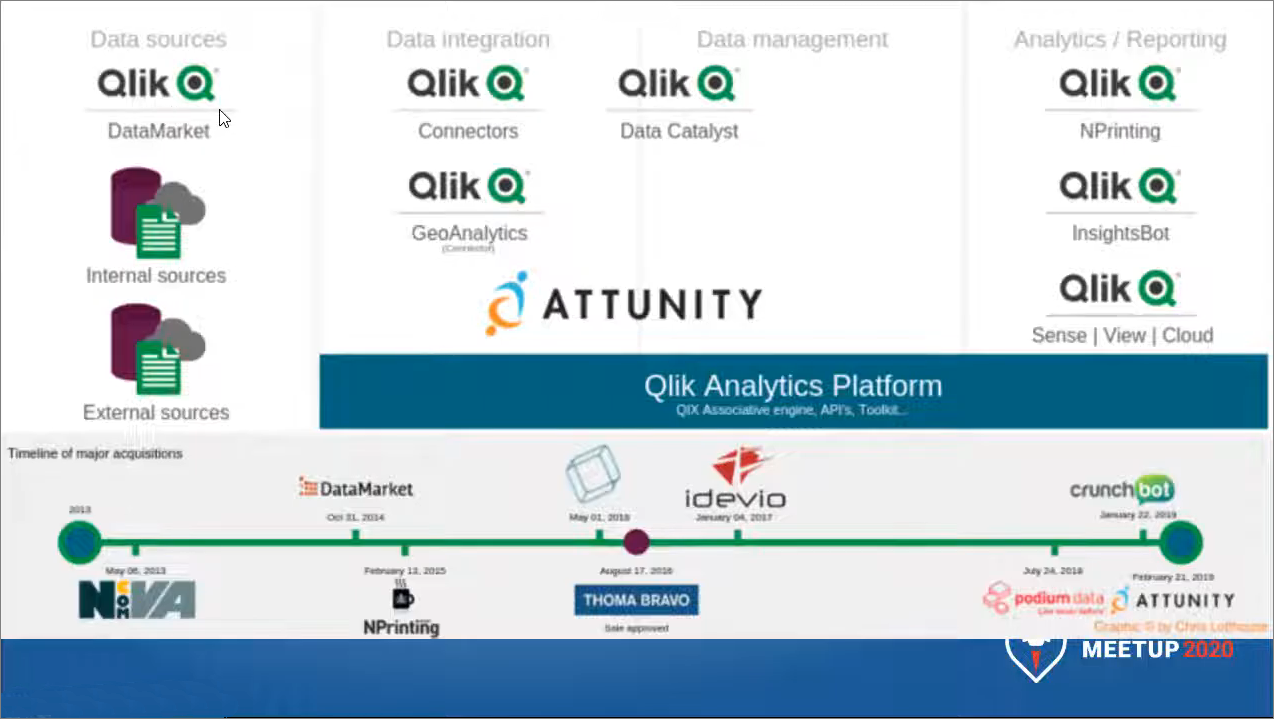
На слайде представлены продукты из экосистемы Qlik. Обратите внимание, Qlik – это не просто QlikView или Qlik Sense, которые на слуху. Это целый стек систем, который закрывает все, от создания хранилищ и озер данных до непосредственно аналитики, которая предоставляется конечным пользователям.
-
Например, в группе Data sources представлен дата-провайдер Qlik DataMarket. Я уже рассказывал, что появление таких провайдеров – современная тенденция, касающаяся и нашего рынка. У нас тоже уже появляются вендоры, которые продают непосредственно данные уже конечным пользователям даже самого небольшого корпоративного уровня.
-
Далее идут системы интеграции и управления данными – Data integration и Data management – сюда относятся Qlik Connectors, Qlik GeoAnalitycs и Qlik Catalyst – это все стек Qlik-продуктов, который позволяет практически с нуля создать свое озеро данных, и потом к нему обращаться.
-
И только потом идут непосредственно системы аналитики, куда входят QlikView и Qlik Sense наряду с другими продуктами стека.
Для чего я это показываю? Чтобы не складывалось впечатление, что Qlik – это какая-то маленькая системка. Это не системка, это не Tool – это целая огромная платформа, которая содержит в себе большое количество модулей.
Если сравнивать Qlik с тем же самым Power BI или Tableau, вход в Qlik тяжелее, потому что Qlik стоит денег. Даже один пользователь – все равно нужно будет какие-то средства платить.
И, в отличие от того же Power BI, Qlik нужно будет еще и дополнительно изучать пользователям. Но, когда пользователь его изучит, он получит довольно-таки мощные возможности самостоятельной настройки – так называемые Self-service capabilities.
Преимущества ассоциативных моделей перед традиционным OLAP
Как вы помните по исторической справке, в 1993 году появилась концепция OLAP (Online Analytical Processing) – концепция анализа данных на основе тех источников, которые в тот момент существовали. Эта концепция опиралась на онлайн-получение данных из СУБД с какими-то системами поверх них (из того же CRM, ERP и т.д.) – из этих систем мы средствами внешнего софта получаем данные и собираем их в хранилище, в базу данных, которая содержит подготовленные очищенные данные, чтобы их далее можно было анализировать.
В чем ключевое современное отличие систем BI друг от друга:
-
одни системы используют классическую традиционную OLAP-концепцию, на конец 2020 года доведенную до своего технического совершенства;
-
а другие – используют не OLAP, а какие-то гибриды, миксы, либо что-то абсолютно свое, какое-нибудь колоночное хранение данных в собственном хитром виде.
Но основное отличие заключается как раз в связанности этих данных и модели данных в ассоциации.
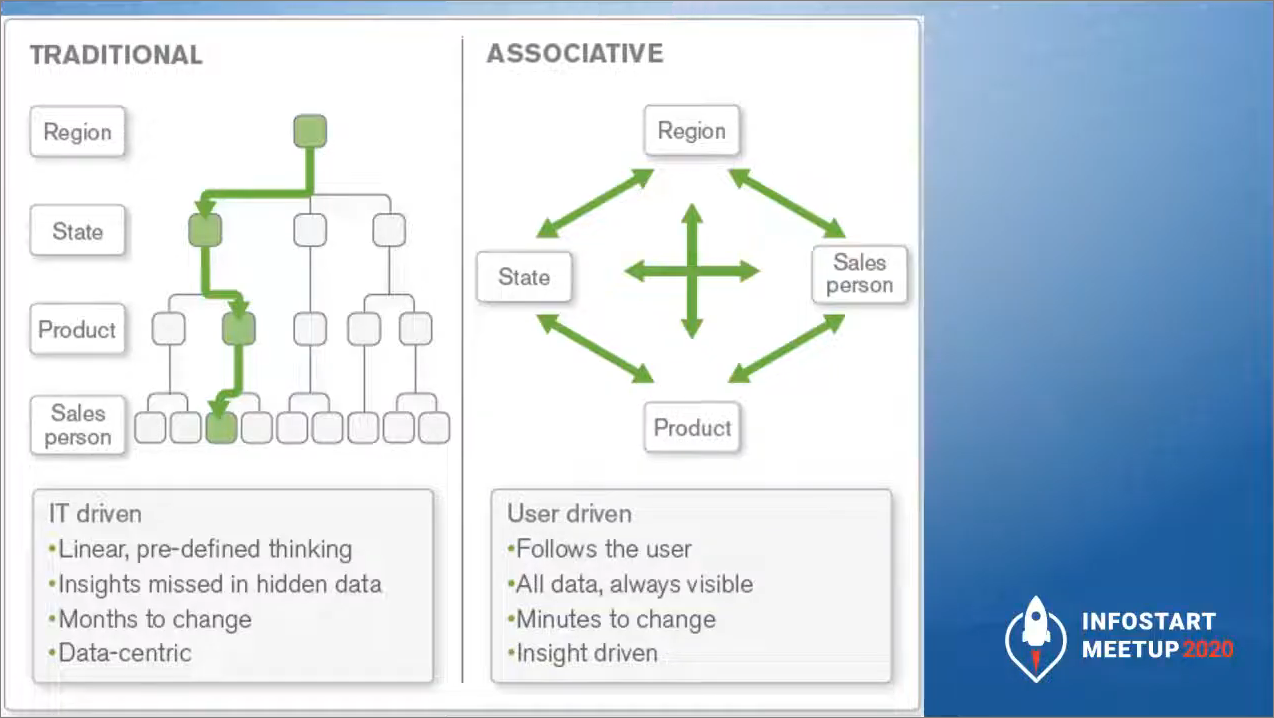
Если мы посмотрим на традиционную схему слева, мы увидим, как в традиционных любых BI-системах осуществляется запрос к данным – он идет иерархически и последовательно. Если мы выбрали страну Россия, регион Пермский край город Пермь – и все, что мы внутри этого города видим – это нам доступно. И обратно мы можем выйти такими же шагами – на уровень назад, и так дойти до верха.
Такая концепция в OLAP обозначает, что если данные у нас внутри этой таблицы (так называемого «куба») есть, то мы их сможем увидеть и проанализировать.
Приведу пример:
-
если нас интересуют продажи за два года по годам, то у нас внутри куба будет два числа;
-
если за два года по месяцам, то чисел будет 24 – это 2 года умножить на 12 месяцев. В целом, мы на каждый запрос можем получить определенное количество предрассчитанных чисел;
-
допустим, если мы добавим категорию «Менеджер», а менеджеров у нас пять, то чисел станет 120 (это 2 умножить на 12 умножить на 5).
Причем, все эти числа будут предрассчитаны – в этом и заключается ключевое отличие OLAP от современных in-memory ассоциативных NoSQL и прочих моделей. OLAP не позволяет увидеть то, чего в нем нет. Если мы в нем физически не учли какой-то конкретный запрос на отсутствие чего-то, мы этого никогда не увидим.
А в ассоциативной модели, которая есть в Qlik и в ряде других систем, мы задаем запрос: «Покажи мне только те города, в которых были продажи желтых футболок, но никогда не было продаж зеленых футболок и исключи продажи такого-то менеджера».
В ассоциативных системах мы работаем со всем массивом данных, который нам доступен – в том числе, работаем с исключениями. А в традиционных BI-системах такие исключения нужно заранее предусмотреть и заранее в данные вставить.
Практический пример работы с Qlik
На примере работы десктопной системы QlikView покажу, как работает ассоциация.
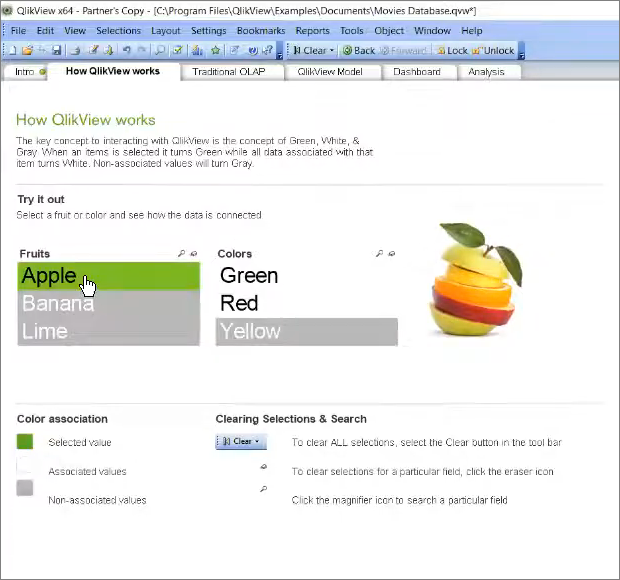
Самый простой пример – я выбрал яблоко:
-
зеленым в Qlik показывается то, что у нас выбрано;
-
белым – то, что с этой выборкой связано;
-
серым – то, что у нас исключено.
Здесь мы видим, что у нас в данных здесь присутствует зеленые и красные яблоки, но не желтые.
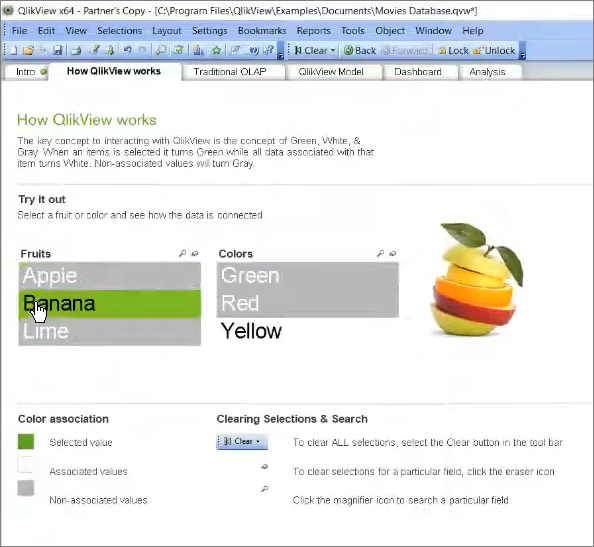
Если мы выберем банан – он желтый.

Когда ничего не выбрано, доступно все.
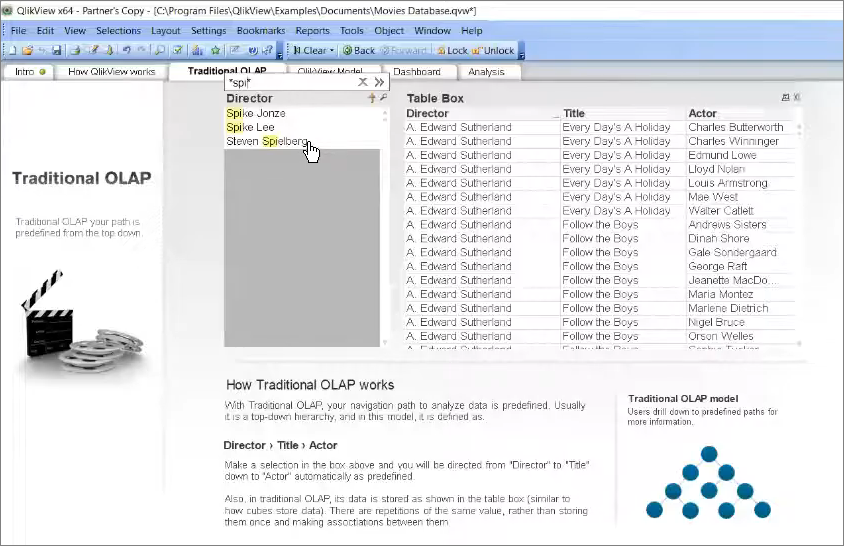
Здесь есть демо-база с данными фильмов, и если мы поищем Спилберга, то как происходит OLAP-запрос в традиционной концепции?

У нас выбран режиссер Стивен Спилберг, через drill down я вижу список доступных фильмов.
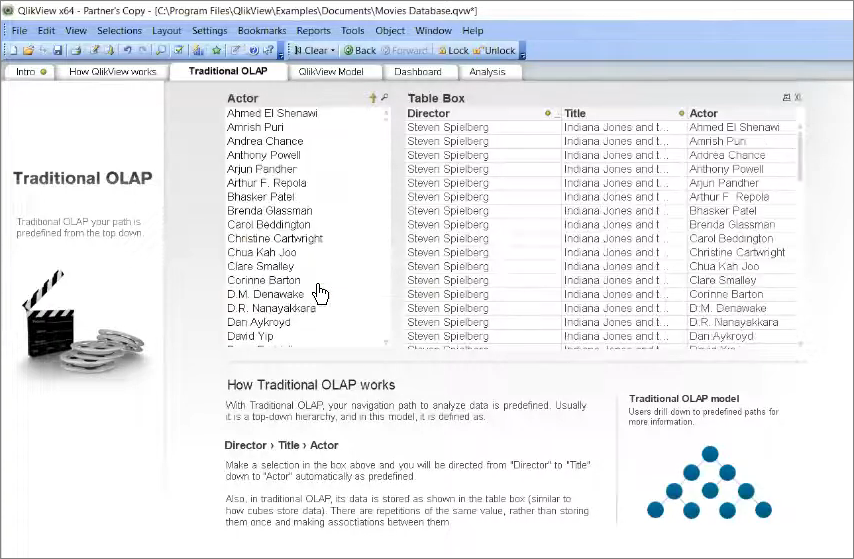
Выберу «Индиана Джонс и храм судьбы». Я провалился на уровень ниже и вижу белым всех актеров, которые с этим фильмом связаны.
Шагая по иерархии «Режиссер – Название фильма – Актер» я и получил вот эту конечную табличку со списком текущих актеров.
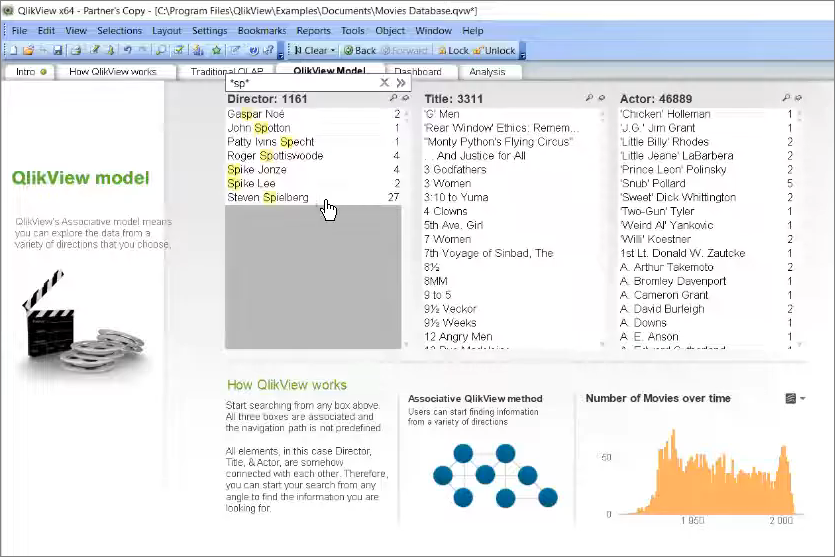
Как работает Qlik, если я в нем выберу Стивена Спилберга?
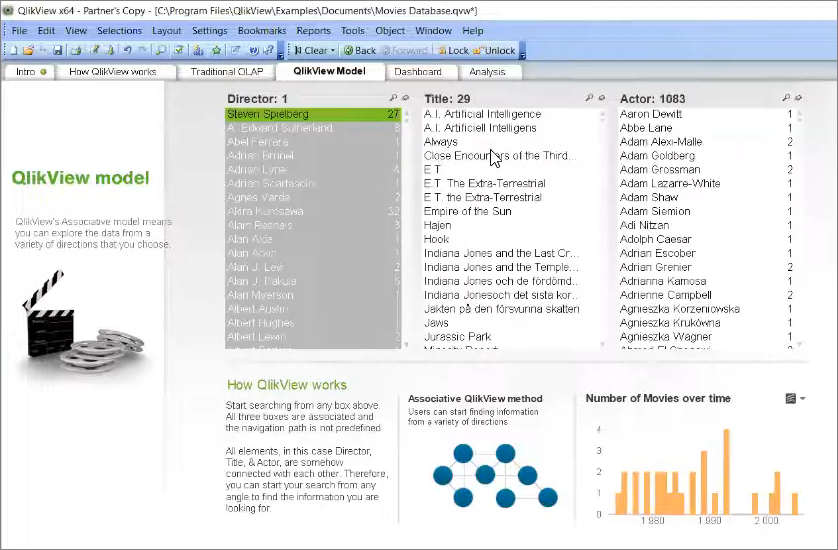
Я сразу же вижу все фильмы, которые с ним связаны, белым. И я вижу 1083 актера, которые с ним связаны.
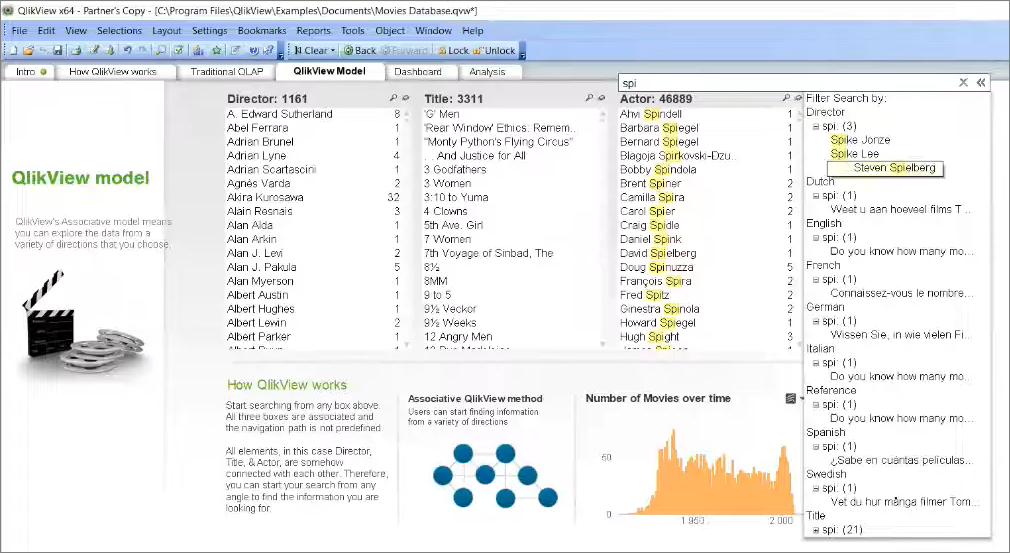
Но ассоциативная модель и запросы ассоциативного вида позволяют мне просто зайти в поле актер и написать – покажи мне всех актеров, которые связаны со Стивеном Спилбергом.
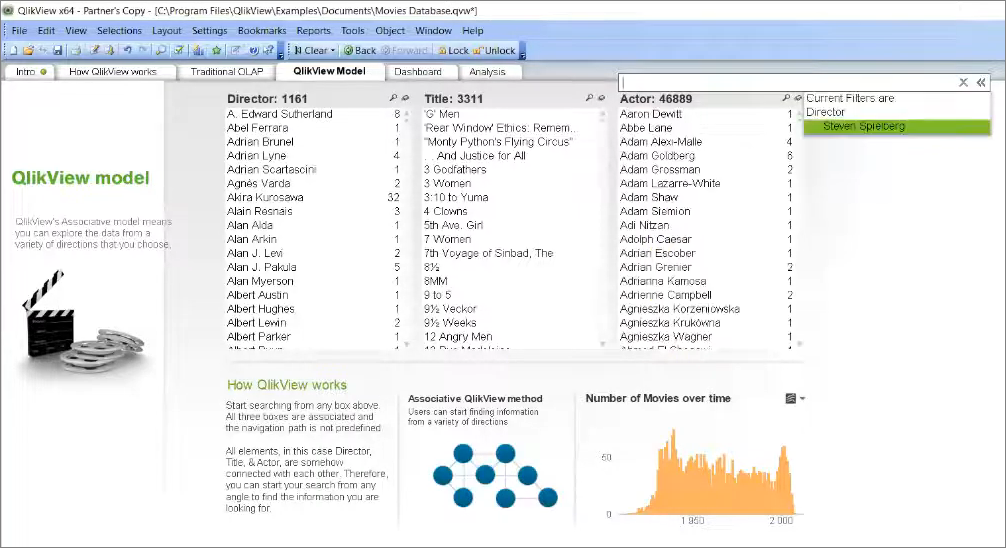
При этом я вижу не только тех актеров, которые связаны со Спилбергом, а я еще вижу и всех режиссеров, которые с этими актерами связаны, и все фильмы, которые с ними связаны. И это все – при том, что мой исходный запрос был «Я хочу выбрать всех актеров, кто был связан со Стивеном Спилбергом».
Фундаментальное отличие традиционных и ассоциативных систем
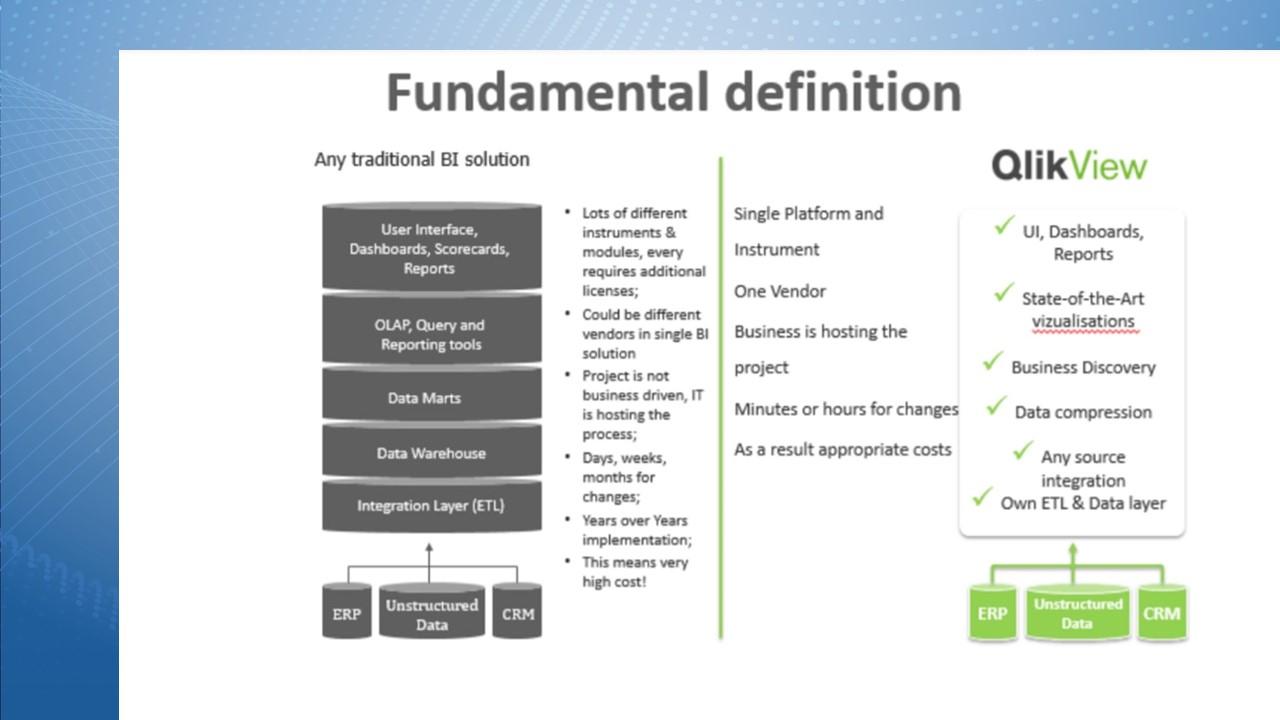
Как раз подобная возможность манипулировать с данными и есть фундаментальное отличие OLAP-систем и ассоциативных систем. Qlik – не единственная подобная система, на слайде вы видели и другие современные NoSQL-системы. Но ключевая особенность – та, которая показана здесь. В OLAP в том или ином виде все иерархично.
Современные OLAP-системы дошли до своего технического совершенства.
Это то же самое, что сравнить двигатель внутреннего сгорания и обычный бензиновый двигатель. Да, в «Формуле 1» сейчас бензиновый двигатель на один литр объема может выдавать около тысячи лошадиных сил, но работать при этом он будет недолго, потому что это его технический предел.
OLAP-системы точно так же дошли до своего технического совершенства – кубы не всегда нужно пересчитывать полностью, их можно подгружать по чуть-чуть, там есть навороченные гибридные схемы, когда одновременно делаются запросы в базу и происходит работа с метаданными и т.д. Но вся концепция работы с данными в OLAP реализована иерархично и последовательно.
А новый ассоциативный подход позволяет получать данные в свободном виде – мы можем переходить от одной сущности к другой, к третьей, к четвертой.
QlikView и Qlik Sense

Хочу остановиться на ключевой разнице QlikView и Qlik Sense.
QlikView – это десктопное приложение и целый стек десктопных компонентов, в том числе, сервер – то, что вы сейчас видели.
Qlik Sense – то же самое, но на веб-движке. Веб-движок – это ядро на C++ и сверху фронт на JavaScript и бэкендом на Node.js. За счет этого Qlik Sense можно очень удобно отдать на откуп пользователям.
По сути, все, что нужно сделать со стороны разработчика – это правильно настроить потоки данных и предоставить пользователю доступ к этим данным в рамках платформы, следить за метаданными, естественно.
А все остальное, по идее, может делать пользователь – он может перетаскиванием накидывать дашборды, а система сама будет ему предлагать графики на основе тех данных, которые она видит.
Например, Qlik Sense может анализировать структуру значений в полях таблиц, и, видя название городов, будет предлагать ассоциировать с каждым городом какой-то регион карты, преобразуя город в географические координаты.
Или, анализируя цифровые значения в каком-то поле, будет сразу предлагать построить график на основании этих данных.
Сравнение систем
Иван: как вы видели, в мире BI-систем тоже можно наблюдать наличие определенной специализации, которая, на наш взгляд уже имеет некие признаки гиперспециализации.
Причем к BI мы вполне можем относить даже системы Process Mining. Например, SAP сейчас купил себе такой проект как Celonis, который Gartner называет лидером рынка Process Mining. Если сравнивать BI и Process Mining, то для меня Process Mining – это уже следующая веха развития BI, это те методы изучения и совершенствования процессов, которые действительно интересно узнавать.
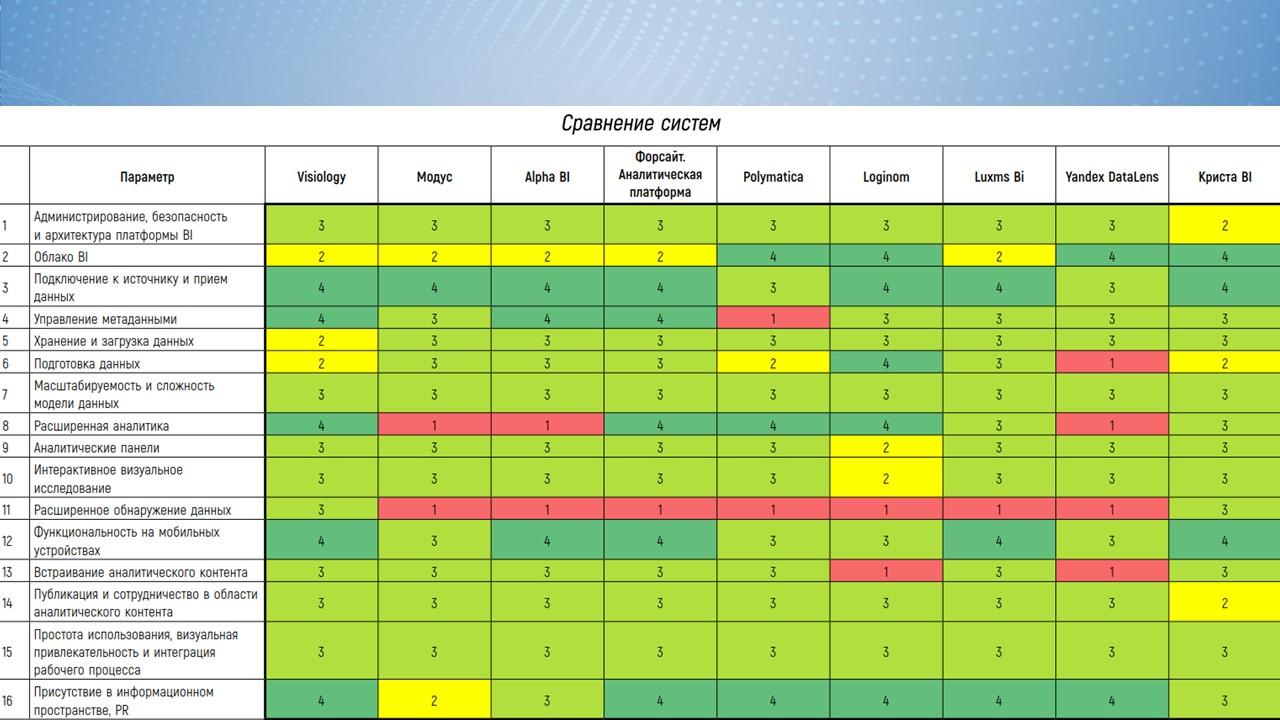
Вернемся к российскому рынку BI-систем – на слайде показано сравнение 8 продуктов, каждая система реализует какую-то свою фишку.
В целом, есть исследование группы Громова по поводу того, какие вообще BI-системы существуют на российском рынке с определенными интересными характеристиками.
Акценты поставщиков BI-систем

Нас же интересовало исследовать момент – как все эти системы себя вообще презентуют. Мы ожидали обнаружить какое-то разнообразие, но большого разнообразия мы не обнаружили:
-
Все вендоры заявляют о том, что их продукты имеют наглядную визуализацию;
-
О том, что все эти продукты замечательным образом обладают технологией in-memory;
-
Общаются с разными источниками – например, заявляют, что могут подключаться к каким-нибудь гугловским веб-сервисам или просто интегрироваться с какими-то системами. Причем здесь есть подозрение, что ребята просто способны подключиться к программе через какой-нибудь ODBC-шный драйвер или через ADO и забирать оттуда данные.
-
Гибкость и low code – тоже очень популярная штука. Разработчики говорят о том, что пользователям, чтобы как-то модернизировать стандартную модель, не нужно ничего программировать – чтобы улучшить ту модель данных, которая есть, достаточно немного ориентироваться в коде и в реляционной алгебре. Это действительно так. Но при этом проекты по внедрению получаются достаточно большие, и по разным причинам могут появляться какие-то специфические моменты, в которых требуется вмешательство специалиста – чаще всего из-за того, что у человека, для которого выполняется этот дашборд или модель, просто нет времени этим заниматься. Либо нет времени научиться для того, чтобы потом этим пользоваться.
-
И последнее, о чем говорят – это технологические преимущества. Qlik в свое время поступил довольно прозорливо, получив патент на свою ассоциативную модель данных, организованную на ассоциативных массивах – в принципе, он этим немного блокирует развитие. Но в целом, это ассоциативное хранение используется большинством систем. Насколько это делается осознанно и хорошо – сказать сложно.
Действительно, этот мощный инструмент ассоциации всего совсем, который показывал Евгений – это очень крутая штука, которая очень сильно отличается от обычных запросов и отчетов, к которым мы привыкли. Потому что для этого не нужно какую-то модель данных делать. Система сама распознает, где какие ассоциации вообще присутствуют – это очень важно. Эту предварительную ассоциативную подготовку система выполняет сама, это очень круто. Это позволяет вот такие запросы сразу строить.
Но этот механизм, на мой взгляд, используется очень плохо, потому что он используется в рамках теоретической концепции теории множеств, которая устарела еще в 1930-е годы. А какого-то развития, связанного с тем, чтобы оперировать более гибкими объектами, какими пользуется, например, теория категорий, которая бы позволила еще больше снизить количество кода, и обходиться лишь кружочками и стрелочками. Но до этого, почему-то еще руки у наших лидеров не дошли.
Перспективы

Gartner выдал обзор всех современных тенденций с 2020 по 2023 год.
В этой табличке используется терминология Gartner, она мне не нравится, потому что здесь все сформулировано обтекаемо и очень общо.
Мы это все перевели на язык требований, и вот что у нас получилось.

На этом слайде переформулированы исходные требования в том виде, в котором мы видим их уже не от крупного бизнеса, а от более мелких заказчиков, которые порой предъявляют очень резкие и радикальные требования в концепции «большой красной кнопки».
На самом деле, потребности малого бизнеса в развитой аналитике намного больше, чем у крупных корпораций, потому что малому бизнесу построить какую-то модель «что, если» и ориентироваться на нее – намного важнее, он рискует более существенными для себя суммами. Грубо говоря, вложить миллион или 10 миллионов куда-то для бизнеса, имеющего оборот 120 миллионов, – это намного более критичная проблема, чем какие-нибудь 100 миллионов для крупного бизнеса, имеющего оборот около 3 миллиардов. Это совершенно разные порядки, совершенно разные отношения. Поэтому даже от маленьких простых решений (таких, как Excel) бизнесу все равно нужны определенные аналитические модели.
Поэтому переформулированный список требований звучит так:
-
Чтобы принимать решения быстро, нужно иметь возможность быстро подключиться к какому-то источнику, быстро насобирать данные. Это некая бесшовная интеграция всего со всем – как подключение слота USB. Это требование существует, мы к нему идем, я думаю, что где-то к 2023 году появятся такие системы, подходы и стандарты, которые будут позволять такие вещи нам выполнять.
-
Модели и рекомендации вместо прогнозов. Сейчас активно развиваются системы имитационного моделирования, которые позволяют нам не только отслеживать какие-то показатели, а видеть, благодаря каким действиям эти показатели могут получаться. Это очень важно, потому что если мы нарисовали какую-то выручку, то все равно непонятно, как эта выручка будет получена, какой план действий для этой выручки – это всегда довольно сложно сказать. Что говорить, если не все рисуют у себя, например, даже такую расшифровку своих бюджетов, как прогнозный баланс. Поэтому говорить о каком-то плане действий и предсказании поведения продавцов или каких-то конечных пользователей – пока что сложно.
-
Полная интеграция индивида в рабочий процесс. С человека нужно снять всю работу по учету – все, что может делать система, должна делать система. Для этого она должна иметь некую бесшовную интеграцию с какими-то устройствами и прочее. Человек не должен заполнять свое рабочее время – это должна по каким-то внешним параметрам снимать система. И многие прочие вещи тоже должна подсказывать, дозаполнять система – это все то, что действительно относится к «красной кнопке».
-
Визуализация – тоже есть проблемы. Визуализация сейчас ориентирована на какие-то отдельные графики, отдельные диаграммы. В целом действительно есть такое понятие, как сторителлинг – рассказывание историй о том, почему эта диаграмма важна и пр. Но это – уже макроуровень. А на микроуровне все равно интересно отслеживать какие именно процессы с каких именно сторон – почему эти показатели описывают этот процесс, почему они его описывают в динамике и пр. Это как раз к вопросу о том, что мы хотим видеть все-таки рекомендации и модели, а не прогнозы.
-
Дальше – пластичность интерфейсов конечных пользователей. Это то, к чему мы тоже уже идем и приближаемся.
-
И репликативность.

Здесь на слайде представлены новые горизонты развития BI-систем – то, что возможно, ждет нас в будущем.
Планы на развитие собственной BI-системы
Евгений: Мы провели экскурс в историю и большой анализ рынка – теперь расскажем пару слов о своих разработках.
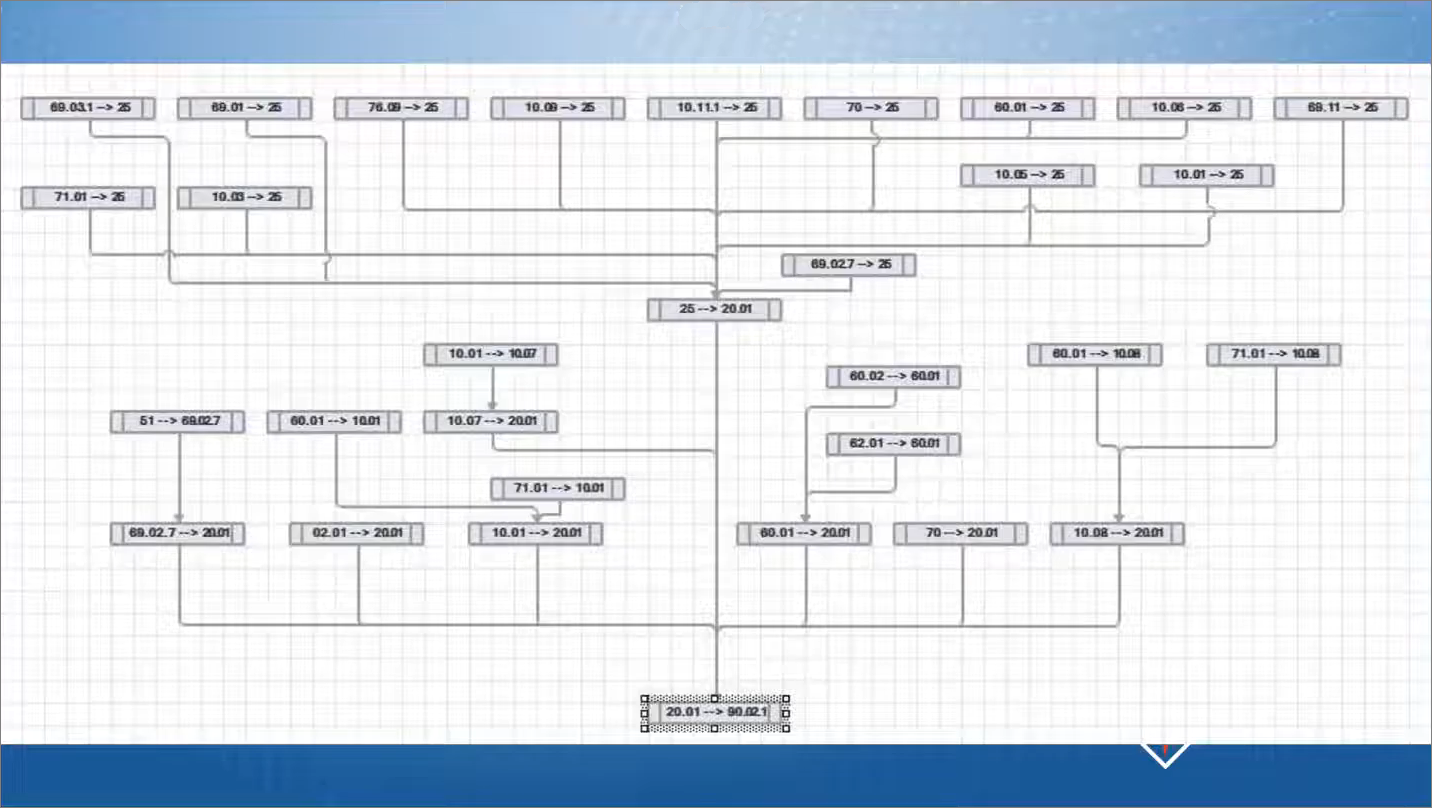
На этом слайде я хотел показать некие зачатки написания нашей системы – мы стали смотреть, какие прогнозы на основе данных системы 1С мы можем получить автоматически. И для начала создали некий движок, который позволял бы просто отслеживать связи на уровне данных. В данном случае вы видите связи счетов.
Мы хотели построить модель для целей бюджетирования на основании данных бухгалтерского учета – нам известна модель движения активов и пассивов, и по этой модели было бы неплохо построить какую-то бюджетную модель. Чтобы, заполняя один счет, потом по графу мы могли распространять то, как этот счет образовался.
Например, вводя 90 счет, мы знаем, какую себестоимость он получал на основании прошлых данных.
Соответственно, заполнив аналитику 62 счета, мы знали бы ритм оплаты от этого клиента и пр.
Построили вот такую связанную модель – система вырисовывала, как одни счета корреспондируют с другими, и какие параметры мы можем отследить на уровне денег.
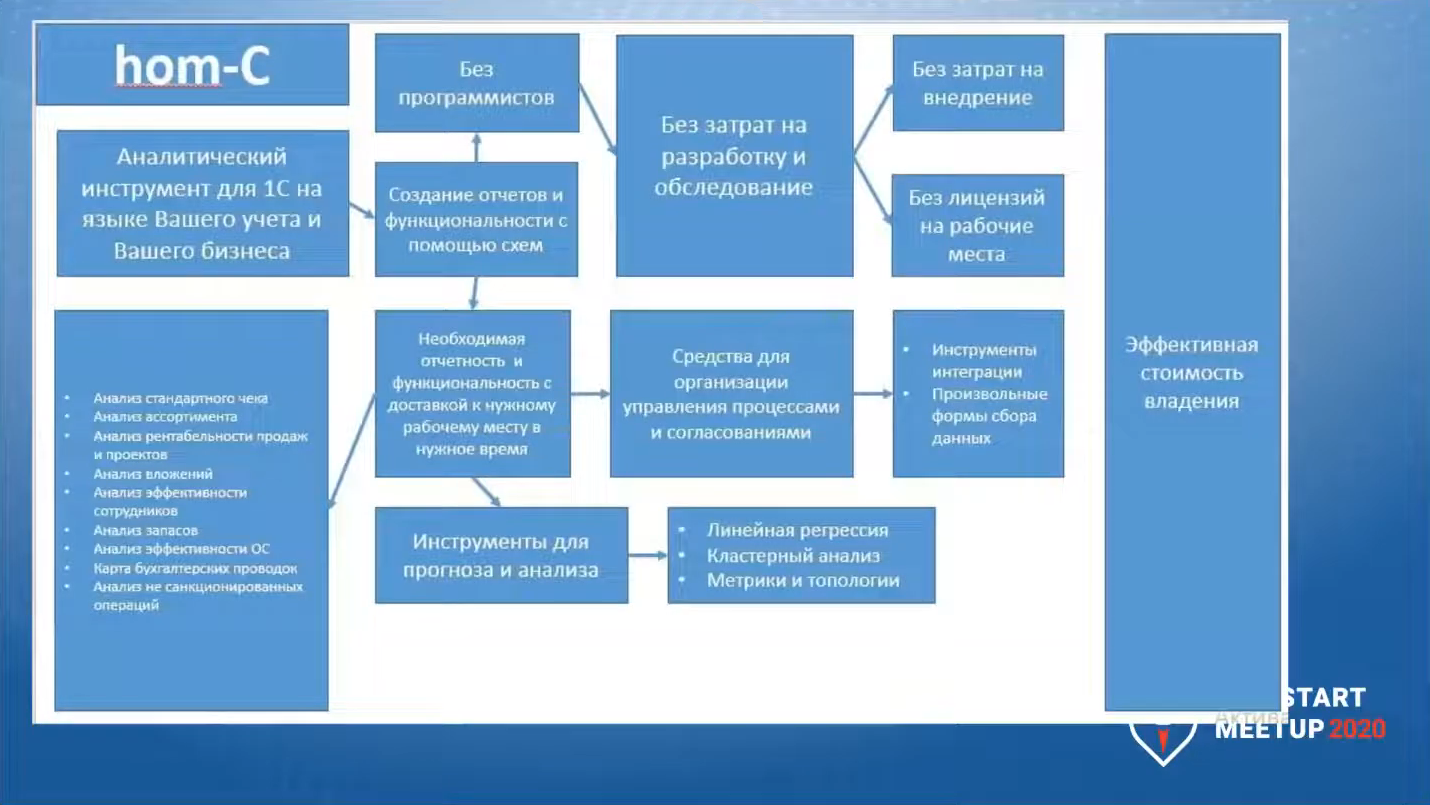
Но потом мы от этого отошли, и на текущий момент времени мы наполняем систему такой функциональностью, как можно увидеть на слайде.
Это чисто описательная модель функциональности, которой мы хотим добиться от системы. На уровне ядра она существует и работает:
-
мы добавили функции плюс, минус, делить, умножить,
-
добавили функции агрегирования,
-
добавили функции сохранения данных во внешние источники – например, в тот же Excel.
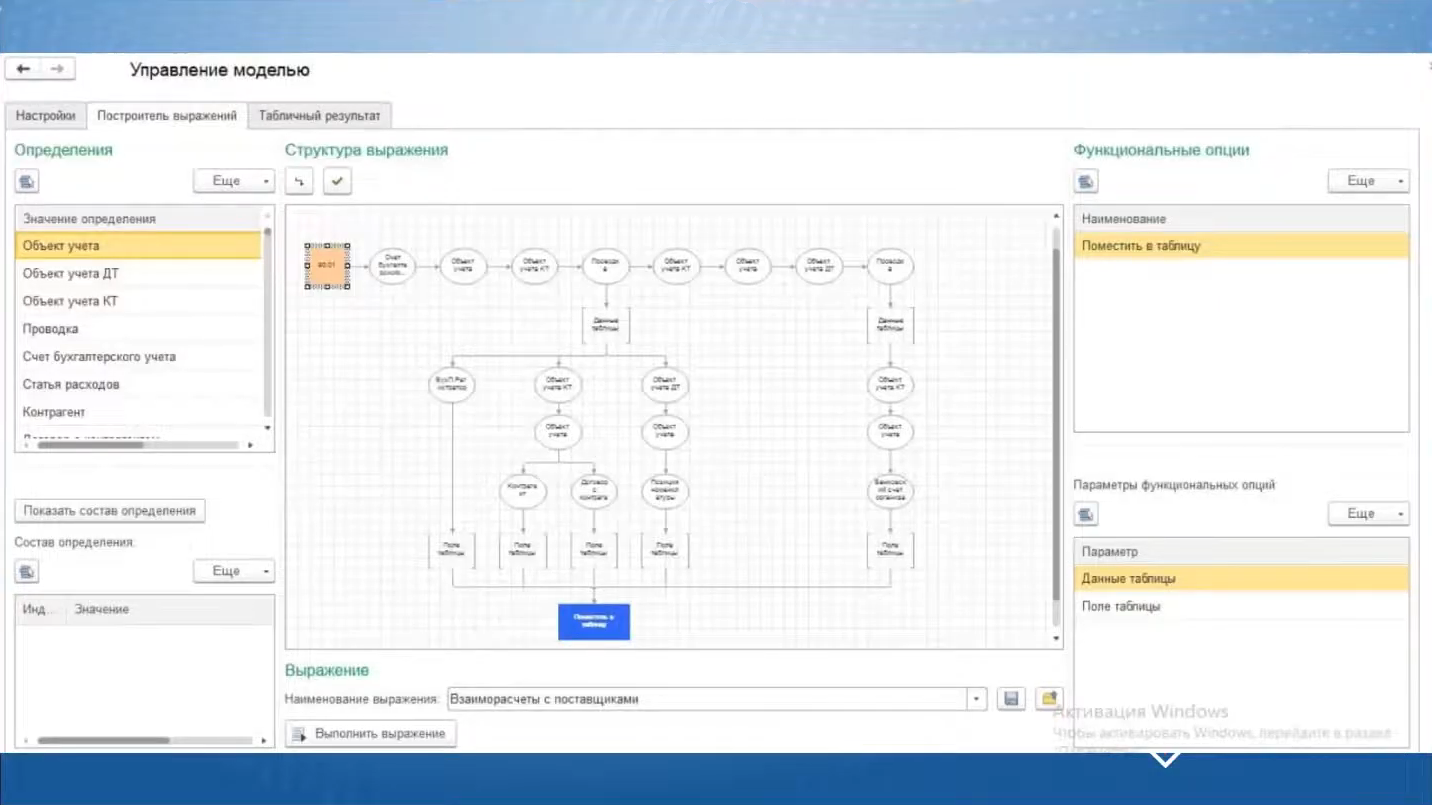
Текущий интерфейс системы внутри 1С выглядит примерно так – оперирование и работа с данными идет как раз за счет шариков и стрелочек – то, что упоминал Иван, что существует некая теория категорий, которая позволяет описывать все шариками и стрелочками.
Собственно говоря, здесь внутри системы 1С мы просто подключаемся к различным источникам, которые доступны в 1С, либо ко внешним – к тому же самому Excel.
Шариками и стрелочками мы рисуем логику разбора этих данных – не логику оперирования с полями (взять первое и второе поле, и сложить в таблицу № 3, а перед этим как-то агрегировать), нет.
Мы просто говорим, что нам нужны движения по счету учета, из этих движений мы берем контрагента, все это помещаем в таблицу и выводим ее на отдельной вкладке.
Пока система находится еще в процессе разработки, но мы готовы дискутировать по поводу текущей концепции, так как нам необходим реальный эмпирический опыт и обратная связь.
Вопросы
Какие вы можете дать ключевые рекомендации по выбору BI-системы – очень большой объем информации и много систем на рынке. Может быть, вы порекомендуете какой-то чек-лист при выборе систем – чем они могут руководствоваться.
Здесь мы можем порекомендовать познакомиться с исследованием нашего коллеги Сергея Леонидовича Громова. Там хорошо описаны все критерии разбора систем – отслеживается порядка 10 критериев.
Плюс дополнительно я бы все-таки порекомендовал отдельно высчитывать для каждой системы такой параметр как cost of ownership – какова для вас стоимость владения в соответствии с тем, как вы думаете, у вас должна развиваться BI в вашей компании. Например, какие дашборды вы себе представляете.
Потому что на изначальном исходном этапе, когда еще нет никакой системы, довольно сложно представить себе весь спектр и фронт дальнейших работ, которые нужно проделать, чтобы вообще дашборды внедрить, потому что как только вы начнете внедрение любой системы, у вас уже пойдут новые данные, инсайды из этих данных, потому что вы уже начали их анализировать, и у вас уже на ходу будут изменения и все остальное.
Я бы рекомендовал сформулировать любое техническое или функциональное задание хотя бы на уровне: «Нам требуется автоматизировать анализ отдела продаж целиком». И для каждой системы под эту задачу высчитать, сколько она вам будет стоить в периоде год, три года, пять лет. Дальше трех лет не имеет смысла рассчитывать. Стоимость владения и первоначальных инвестиций всем этим должна окупиться максимум на три года, минимум за год. Я бы порекомендовал всегда от этого отходить.
На любой современной BI-системе можно делать все. Но есть мнение, что красивая инженерная техника работает лучше, поэтому, возможно, такой субъективный элемент как красивый дашборд или красивые графики для вас точно так же будет работать лучше. Если при прочих равных одна система рисует красивее, а все остальное – одинаково, берите ту, где красивее.
*************
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "Бизнес-анализ по данным базы 1С. Интеграция c платформами BI".

