







В процессе работы с разными версиями конфигураций УТ 11, КА 2, ERP 2 накопилось определенное количество знаний в части различий их архитектуры. Что-то исчезало, что-то добавлялось, а что-то эволюционировало и улучшалось. В предыдущей статье (Исправляем проблемы производительности в конфигурации ERP - 7 примеров) мы останавливались на проблемных моментах. Однако, теперь рассмотрим положительные изменения - некоторые важные примеры, на наш взгляд. Постараемся говорить только про хорошее.
1) Проблема составного типа
Эта особенность, которая является преимуществом 1С и одновременно ее ахиллесовой пятой. Она позволяет быстро творить и создавать сложные механизмы. Но одновременно вынуждает четко следить за результатами использования и часто создает проблемы.
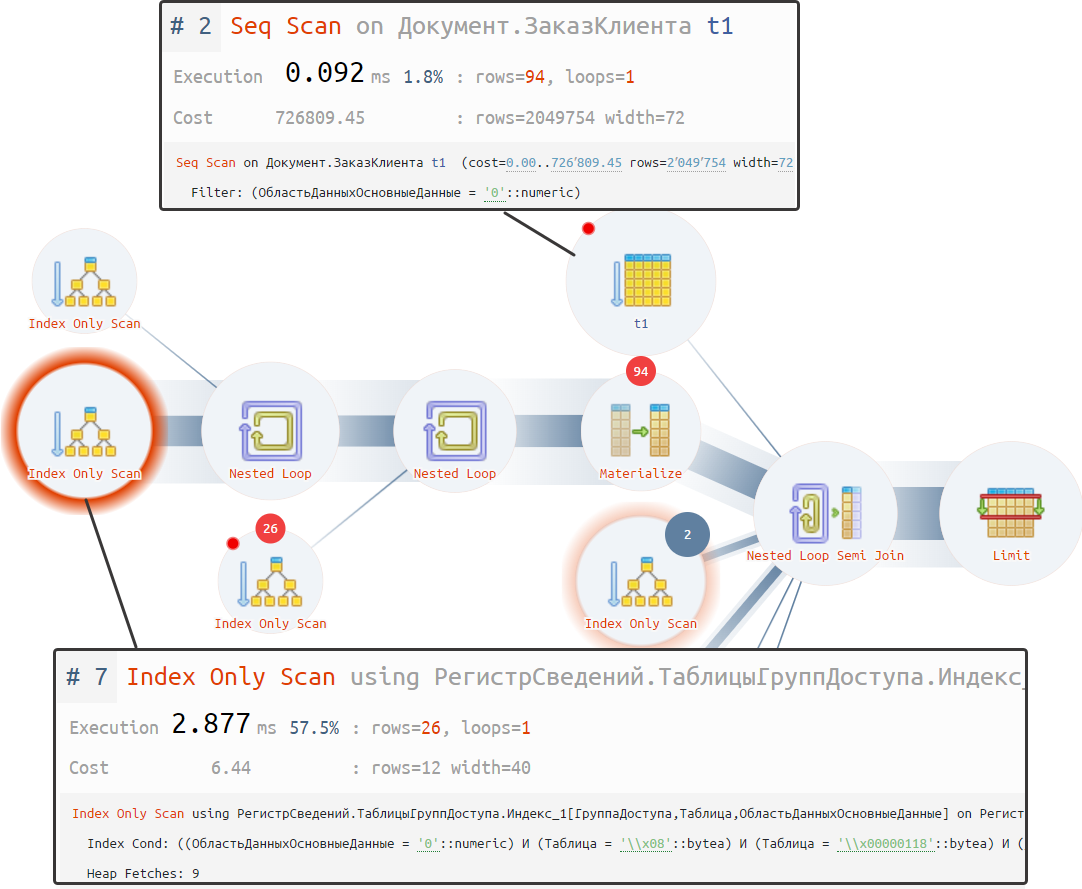
Смотрите как здорово выглядит сам регистр расчетов с клиентами. Он позволяет получать информацию по остаткам взаиморасчетов. И с точки зрения архитектуры с первого взгляда проблемы не видны.
Но мы же все знаем, что в основном пользователю нужны отчеты. И вот тут выходят на первый план эти скрытые проблемы.
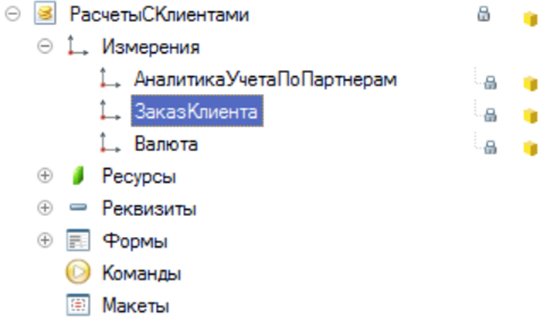
Пользователю не нужна ссылка на заказ клиента (который на самом деле "объект расчетов"), а ему нужны различные аналитики. Ему нужен контрагент, договор, группа финансового учета, соглашение и т.п.
При выборе этой дополнительной информации происходит обращение через две точки. И мы с Вами получаем проблему - платформа автоматически соединяет основной запрос с дополнительными таблицами. Поэтому к основным двум таблицам добавляются еще 24 таблицы из составного типа:
В результате отчет «Расчеты с клиентами» превращается в огромного страшного монстра. Для пользователей с RLS к каждой таблице будет еще добавлены таблицы RLS ограничения, что усугубляет ситуацию еще сильнее. Время выполнения запроса к базе данных увеличивается с 1 с до 100 с и более, зависит от настроек прав доступа конкретного пользовтеля.
Приводить план не буду, можете ради примера посмотреть тут: Смотрим запросы 1С через Microsoft SQL Profiler по следам ошибок разработчиков, приводящих к проблемам производительности
ВЫБРАТЬ РАЗРЕШЕННЫЕ
РасчетыСКлиентами.АналитикаУчетаПоПартнерам,
РегистрАналитикаУчетаПоПартнерам.Организация,
РегистрАналитикаУчетаПоПартнерам.Партнер,
РегистрАналитикаУчетаПоПартнерам.Контрагент,
РегистрАналитикаУчетаПоПартнерам.Договор,
РегистрАналитикаУчетаПоПартнерам.НаправлениеДеятельности,
РасчетыСКлиентами.ОбъектРасчетов КАК Заказ,
РасчетыСКлиентами.ОбъектРасчетов.ГруппаФинансовогоУчета КАК ГруппаФинансовогоУчета
// …
ИЗ
РегистрНакопления.РасчетыСКлиентами.ОстаткиИОбороты(
,
,
Авто
) КАК РасчетыСКлиентами
ГДЕ
РегистрАналитикаУчетаПоПартнерам.Партнер <> ЗНАЧЕНИЕ(Справочник.Партнеры.НашеПредприятие)
Как ее решить? Уйти от составного типа. Нет составного типа - нет проблемы (это архитектурный вариант оптимизации).
Вариант решения может быть следующим. Мы добавим новый объект, который будет сразу хранить эту дополнительную информацию для отчета в себе. Варианта два:
- регистр сведений
- справочник
1) В качестве примера реализации первого варианта, можно привести регистр сведений "Реестр документов". Запрос станет значительно проще. Но в текущей ситуации у нас есть несколько условий не позволяющих его использовать:
- Он ограничен количеством существующих вспомогательных полей в этом регистре. Поэтому придется добавлять новые.
- В нем много документов не относящихся на прямую к взаиморасчетам. В этом случае в таблице будут пустые записи.
2) Второй вариант – создание нового справочника «объект расчетов». На этом варианте разработчики и остановились. Хороший вариант.
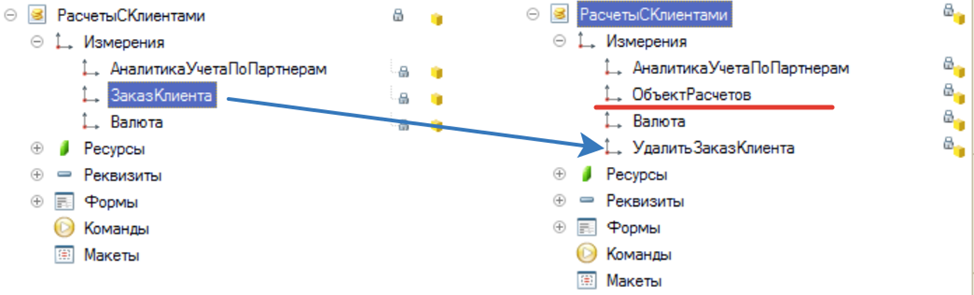
Вот он новый справочник с набором всех возможных желанных полей:

Теперь все ОК и запрос значительно упрощается, и мы можем наконец-то вздохнуть. Никаких лишних таблиц не нужно. И запрос выше будет содержать в себе всего лишь одно соединение с таблицей справочника, а учитывая огромный набор все возможных полей, то скорее всего пользователь не сможет найти и добавить чего-то лишнего (конечно же сможет, такие тоже бывают).
Данный справочник разработчики протащили во все подобные механизмы - различные расчеты с партнерами, расчеты с клиентами, расчеты по сомнительным резервам и т.д.
Также видно, то для регистра «Расчеты с клиентами» поле «Заказ клиента» наконец-то переименовали в «Объект расчетов». Но вот в регистре «Расчеты с клиентами по документам», оставили название измерения как «Заказ клиента». Но хотя-бы заменили тип на справочник. Видно, что объемная работа проведена, но не везде выполнено должным образом и мы встречаемся с недоделками.
2) Производительный механизм RLS
Типовой механизм RLS имеет очевидную проблему быстродействия. При большом количестве групп доступа с разными ограничениями на одну таблицу производительность сильно деградирует. Эту проблему разработчики попытались решить добавлением нового механизма, который назвали производительным. На сколько мне помнится, его ввели в последних версиях ERP 2.4. С точки зрения быстродействия данный механизм показывает определенный уровень стабильности. Однако проигрывает в некоторых случаях простым шаблонам RLS при канонических условиях – без кривых отборов и сортировок. Приведем результат небольшого расследования.
Мы провели эксперименты и специально наполнили демонстрационную базу ERP несколькими миллионами документов (чуть более 2х). Приведем пример на основе заказа клиента. В качестве ситуаций сравним поведение имитации динамического списка (в консоли запросов) с настройками по умолчанию и сортировкой по полю Организация (пользователь случайно или нет ткнул на эту колонку)
1) В первом случае выигрывает простой RLS. Разница с большим отрывом – более чем в 100 раз.
ВЫБРАТЬ РАЗРЕШЕННЫЕ ПЕРВЫЕ 45
заказклиента.Ссылка КАК Ссылка,
заказклиента.Организация КАК Организация,
заказклиента.Склад КАК Склад,
заказклиента.Партнер КАК Партнер
ИЗ
Документ.ЗаказКлиента КАК заказклиента
- Простой RLS - 5 мс
https://explain.tensor.ru/archive/explain/6ebe99d01c8f5a750153749a00ba6386:0:2022-09-14#visio

Схема плана запроса выше представляет собой обычную картинку и ничего особенного тут нет. Все быстро и оптимально, на сколько возможно. Так как общее время измеряется в единицах мс (все очень быстро), то можно не обращать внимания на красный круг.
- Производительный - 700 мс
https://explain.tensor.ru/archive/explain/a1677039e3b513e07541792a06b6ab22:0:2022-09-14#visio. Схема примера приведена ниже.
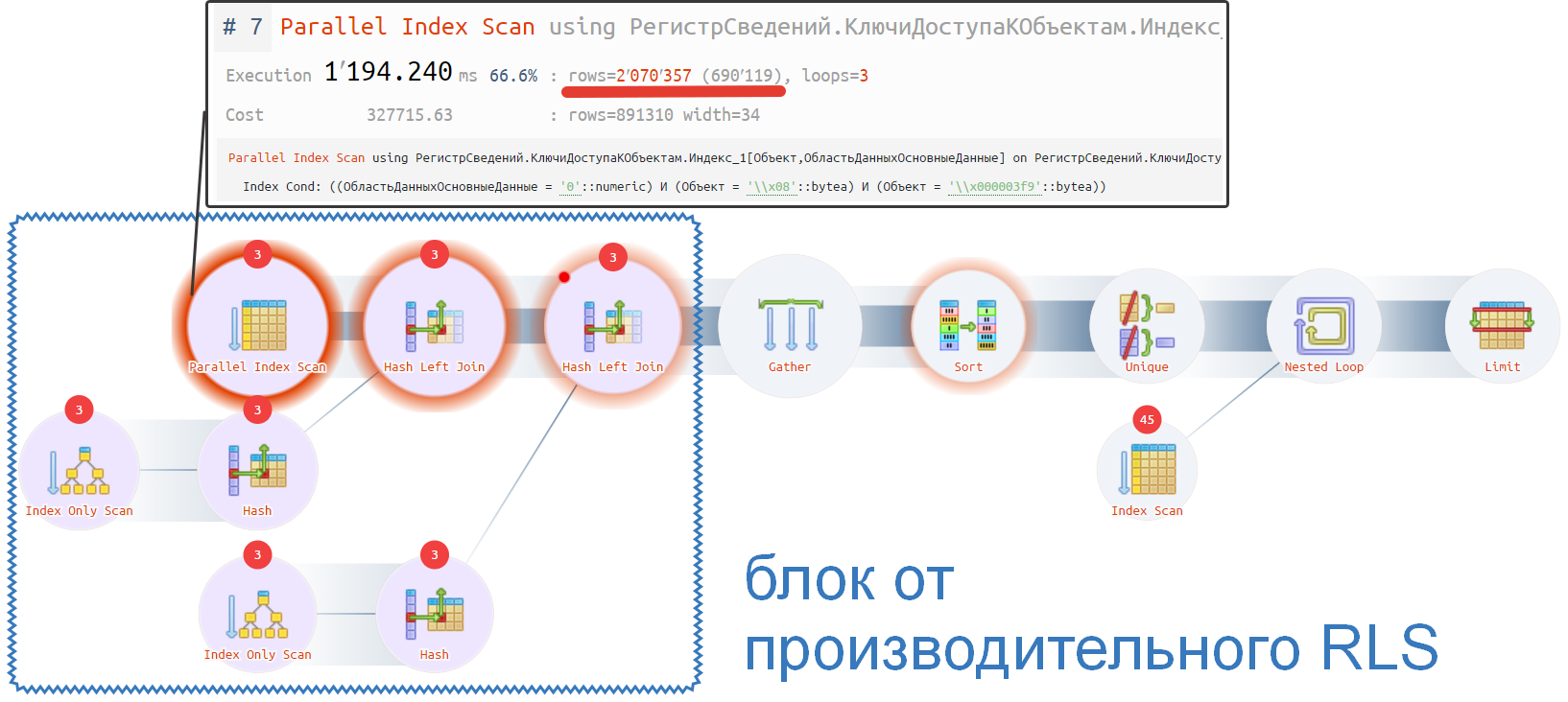
В этом запросе видно отличие. Объясним, почему так происходит:
Такое отставание происходит из-за того, что в таблице «ключи доступа к объектам» по индексу выбираются все записи с необходимым типом, а так как их много, то и процесс чтения длительный. Однако, данная операция очень хорошо параллелится, за счет этого вместо 1.5 с, мы получаем всего 0.7 с.
Подобное чтение всех записей таблицы одинакового типа будет выполняться практически для каждого запроса. И именно в этой части данный производительный механизм будет проигрывать обычному RLS и скорее всего произвольному запросу в ограничениях. Если данных в базе не много, то первый оператор не будет существенно влиять на общее время выполнения запроса.
2) Во втором случае с сортировкой по организации мы видим разницу чуть более чем в 2 раза в обратную сторону
ВЫБРАТЬ РАЗРЕШЕННЫЕ ПЕРВЫЕ 45
заказклиента.Ссылка КАК Ссылка,
заказклиента.Организация КАК Организация,
заказклиента.Склад КАК Склад,
заказклиента.Партнер КАК Партнер
ИЗ
Документ.ЗаказКлиента КАК заказклиента
упорядочить по
заказклиента.Организация
- Простой RLS - 14.3 c
https://explain.tensor.ru/archive/explain/9bf536f8068b689f20e0dc0408a23ec3:0:2022-09-14#visio
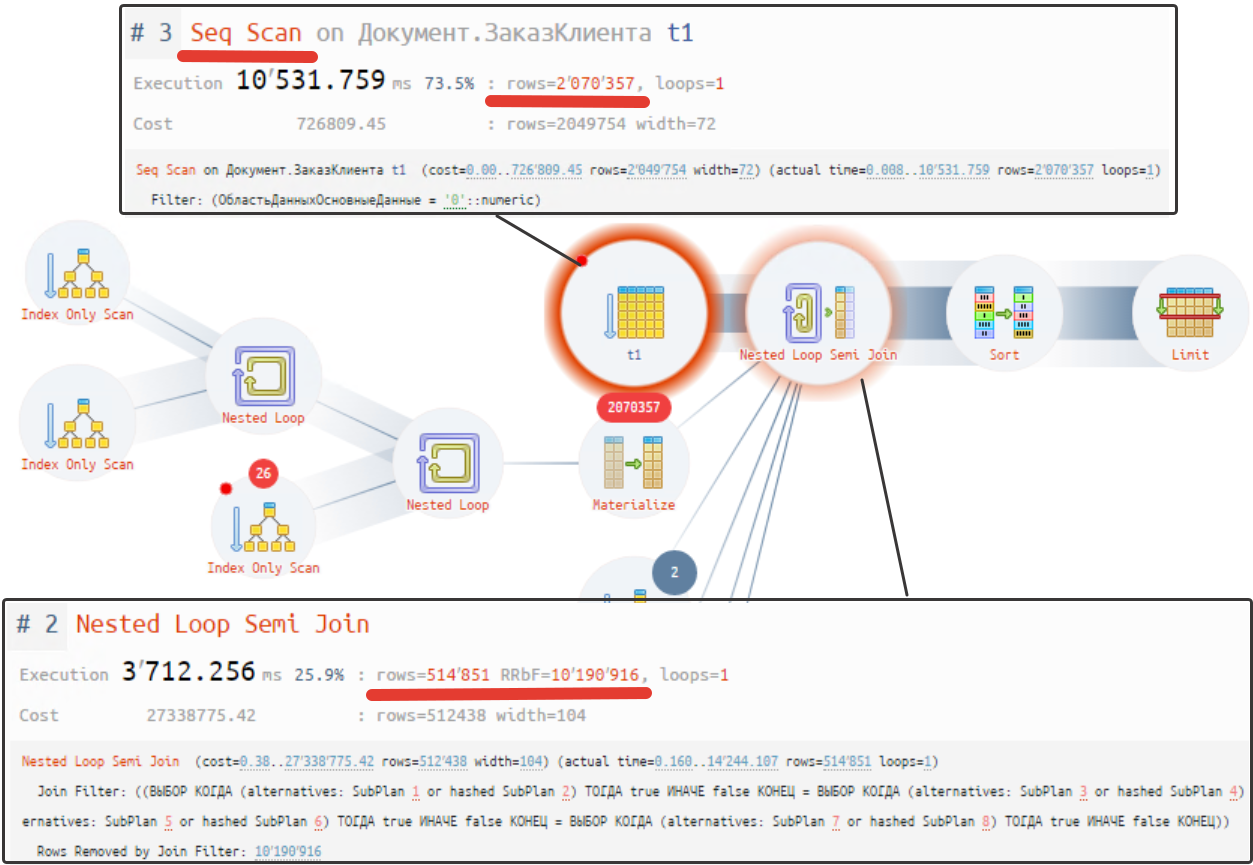
Давайте рассмотрим почему так получилось:
Схема плана запроса по структуре ничем не отличается от варианта 1, который мы рассмотрели выше. Но в таблице заказов клиента отсутствует индекс по организации. Поэтому появляется оператор последовательного сканирования "Seq Scan", который считывает 2 млн записей. Далее для каждой считываемой строки запрашивается право доступа - можно или нет показать эту строку. Слева набор операторов до кружка "Materialize" - это условие по RLS, которое возвращает 5 записей более 2 млн раз.
- Производительный - 6.2 с
https://explain.tensor.ru/archive/explain/ba24ddae1e4eac7cc8a74bd0e71a7b53:0:2022-09-14#visio

Схема запроса практически осталась как в первом варианте. Только в конце добавился оператор сортировки, который заставляет планировщик выполнять прогон по таблице основного ключа, который добавляет еще немного времени. Это происходит из-за того что в отличии от первого случая обрабатывается не 45 строк, а более чем 1.6 млн. Вот мы и увидели как влияют сортировки в таблицах.
3) Третий случай. Проиндексируем поле "Организация" в таблице "Заказ клиента" и выполним запрос еще раз.
- Простой RLS. Как видно, то теперь появился оператор получения данных по индексу и время выполнения запроса снизилась ниже 1 мс. Запрос похож на тот, что был в первом случае.
https://explain.tensor.ru/archive/explain/2b17253b099782026c075bf11237553b:0:2022-09-16#visio
- Производительный запрос - 5.9 с. Схема запроса не изменилась.
https://explain.tensor.ru/archive/explain/d1bb15773d3154bcfd5d68d126e5a6e7:0:2022-09-16#visio
С точки зрения производительного механизма в схеме плана запроса отличий нет.
В целом использование производительного режима позволяет получить меньшее среднее время и отсутствие сильных провалов из-за большого количества групп доступа на одного пользователя при различных "плохих" условиях. Однако, для маленьких таблиц и хорошо настроенных правах выгода нивелируется фактическим перебором всех значений одинакового типа из таблицы ключей объектов, ключей регистров.
Тут напрашивается один интересный и закономерный вывод: динамические списки - это зло для баз с большим количеством данных и пользователей.
Логическим выходом в данном случае является отключение возможности сортировки всех полей кроме даты, номера и ссылки (и возможно других проиндексированных полей). Такая программная возможность у платформы имеется. И мы ей в некоторых случаях пользуемся. Если же нужны сортировки, крутые отборы и т.п., то необходимо использовать отчеты.
3) Упрощение запросов
В качестве примера возьмем АРМ «подбор товаров в документы продажи». Он знаком практически каждому пользователю и разработчику. Таких форм больше двух - еще есть в документы закупок, на ответственное хранение и т.д. И на некотором протяжении развития конфигурации мы можем попробовать проследить как менялся этот АРМ.

В качестве примера возьмем запрос из конфигураций 2.4 и 2.5 и рассмотрим их отличия. Структуры запросов практические одинаковые в рамках выборки полей данных. Отличаются только источники (показано на рисунке ниже).
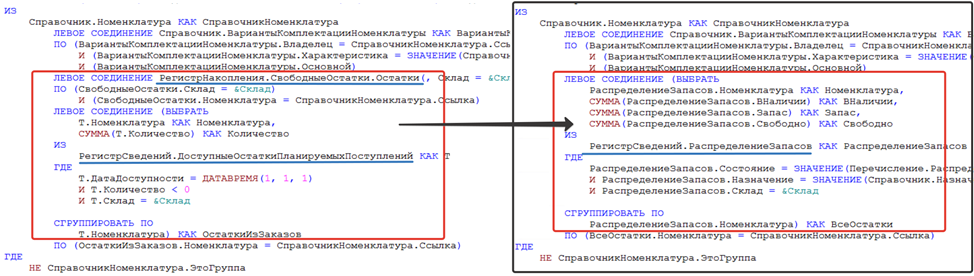
С источниками стало все выглядеть лучше. Исчезла из соединения одна виртуальная таблица «Свободные Остатки» и еще одна таблица "Доступные остатки планируемых поступлений". Их заменил регистр "Распределение запасов". Здорово было бы уйти еще от вложенного запроса, тогда схема начала бы "летать".
Новый механизм "работы с запасами" облегчил и другие формы - состояние обеспечения, управление перемещением и т.д.
Вроде бы все хорошо, но новый регистр «Распределение запасов» преподнес один сюрприз. Точнее реализация его логики заполнения. При большом количестве пользователей в базе и их активной работе при пересчете этого регистра могут происходить блокировки.
В следующей итерации (одном из последних релизов ,а может уже и не совсем последних) данную проблему должны были исправить с помощью запуска регламентного задания. Расчет логики в одном потоке позволяет избежать блокировок между пользователями.
Резюме
В новой версии ERP 2.5, как мне видится, разработчики местами поправили свои огрехи и местами вернулись на истинный путь следования рекомендациям:
- Поправили нехватку фильтров в виртуальных таблицах;
- Переписали часть архитектурных механизмов;
- Довели до ума производительный механизм;
- И другое.
И это не удивительно, т.к. позиционирование конфигурации ERP на замену SAP требует иного уровня качества работы с точки зрения производительности. Поэтому если у вас есть возможность, то стоит рассмотреть вариант обновления конфигурации на более новую версию. Ну или по крайней мере поискать исправления ошибок в новых версиях и попробовать перенести эти исправления (а не ошибки) к себе.
Однако, как всегда и везде, с разработкой автоматически добавляются новые вызовы. Это как с тем сусликом:
-Ты его видишь?
-Нет.
-И я не вижу. А он есть!
Вступайте в нашу телеграмм-группу Инфостарт