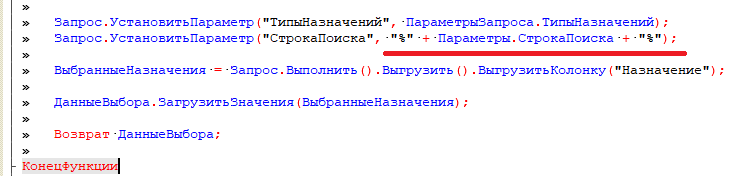
Продолжаем набор статей по вопросам проблем производительности. Это следующая часть разборов ситуаций после перевода большой базы ERP на Postgres. Помните мы писали в предыдущей статье "нагрузочное тестирования в 5000+ онлайн" что вы будьте заниматься вопросами оптимизации? Это то что мы делали и Вам предстоит, если соберетесь выполнять подобную процедуру.
Рассматриваемые вопросы и примеры решения ситуаций живые, интересные и злободневные, и до сих пор живут в актуальных конфигурациях ERP/УТ/КА. Мы рассмотрели 7 разных показательных ситуаций и соответствующие им пути решения, но по факту таких доработок было значительно больше. Скорее всего приведем еще подборку, но позже.
Структура статьи:
Вступление
1. Проблема быстродействия АРМ "Управление поступлением".
2. Опять 25. Получаем данные через две точки.
3. Плохой план Postgre SQL.
4. JIT оптимизация - это такая оптимизация!
5. Через две точки + плохие поля выбора и ужасные СКД отборы по ним.
6. Бесполезный индекс скан и отключенные итоги.
7. Нет отборов внутри виртуальных таблиц. Как так получилось?
Выводы
Вступление
О чем мы хотим рассказать?
Мы расскажем и покажем последовательность действий по выявлению проблемных мест производительности, а также реализацию исправлений на актуальных конфигурациях ERP/УТ/КА. Рассмотрим некоторые отличия в поведении MS SQL Server и PostgreSQL. Увидим, что если писать код в соответствии с рекомендациями, то система сможет относительно хорошо работать в любой СУБД.
Где-то мы будем более подробно рассказывать, где-то чуть более сжато. Но от этого ценность этого поста не снижается. Очень подробно про расследование проблемы производительности мы писали ранее в статье "Пример пошагового решения проблемы производительности на базе Postgres SQL с картинками", попробуйте ознакомиться с ней прежде.
Подробное описание рассматриваемых проблем приведено в статье "Распространенные ошибки разработчиков, приводящие к проблемам производительности", т.ч. для кого будет непонятно, почему, открывайте и ищите пример. А в статье Смотрим запросы и планы 1С по следам ошибок разработчиков, приводящих к проблемам производительности приведены картинки планов.
Краткое техническое вступление
Прежде чем вы начнете работать над вопросами мониторинга производительности, вам необходимо будет определиться с инструментами. Существует не так много инструментов, а хороших и удобных инструментов совсем мало. В нашем случае мы будем использовать конфигурацию (про которую я уже писал) "Мониторинг производительности" с широким набором плагинов. Нам понадобятся следующие плагины и функционал:
- Парсер технологического журнала (встроен в конфигурацию);
- Парсер метрик производительности performance monitor для windows (встроен в конфигурацию);
- Классификатор ошибок технологического журнала;
- Обработка получения данных RAS 1C (с возможностью получения данных через com соединение).
- И др.
На что смотрим и ищем в журнале мониторинга (кратко):
- Долгие запросы, те, которые сильно отклоняются от общей картины в 2,3 и больше раз. Если у вас в среднем 10 с, то запросы 20,30, 60, 200, 1000 с точки оптимизации. Находим наиболее критичные и начинаем с них.
- Частые запросы середнячки и трудяги. Те, которых очень много. Отбираем и смотрим, можно ли их оптимизировать.
- Запросы с большим количеством возвращаемых данных. Отчеты, которые возвращают десятки тысяч строк. Если на выходе пакета 10-15 записей, а промежуточные данные миллионы, то, возможно, не хватает фильтров.
На что смотрим в планах:
- Сканы таблиц, вместо них должны скорее всего быть индексы.
- Большие потоки данных, а на выходе 1-2 строки.
- Плохие отборы/фильтры.
- Множественные связи.
- Большое количество источников данных.
Что смотрим в запросах:
- Большой текст,
- Большое количество таблиц (тоже может быть через две точки от поля составного типа),
- Длинные строки содержащие CASE … THEN CASE …. (это оператор через две точки от поля составного типа)
- Операторы LIKE, ORDER по каким полям, большое количество полей у GROUP
- Большое количество данных.
Про то, как отлавливать план запроса, я рассказывал в предыдущей статье, к тому же на этом ресурсе полно других подобных статей.
Как улучшить понятность планов запросов в Postgres и MS SQL?
Для этого воспользуйтесь обработкой «Конвертация SQL в 1С». Она ищет таблицы и реквизиты, преобразует их в значения конфигурации. Запускать обработку необходимо в исследуемой конфигурации. Является частью Фреймворка «Мониторинг производительности».
Начинаем...5.4.3.2.1... поехали
1. Проблема быстродействия АРМ «Управление поступлением»
Начнем с довольно обидной ошибки в типовой конфигурации, которая заставила нас активизироваться в краткий промежуток времени. К нам обратились со срочной, критичной проблемой, которую требовалось решить незамедлительно, т.к. пользователи базы данных не могли выполнять свои операции. «Сегодня внезапно система при открытии рабочего места зависала и не позволяла выполнять требуемые операции по приемке товаров».
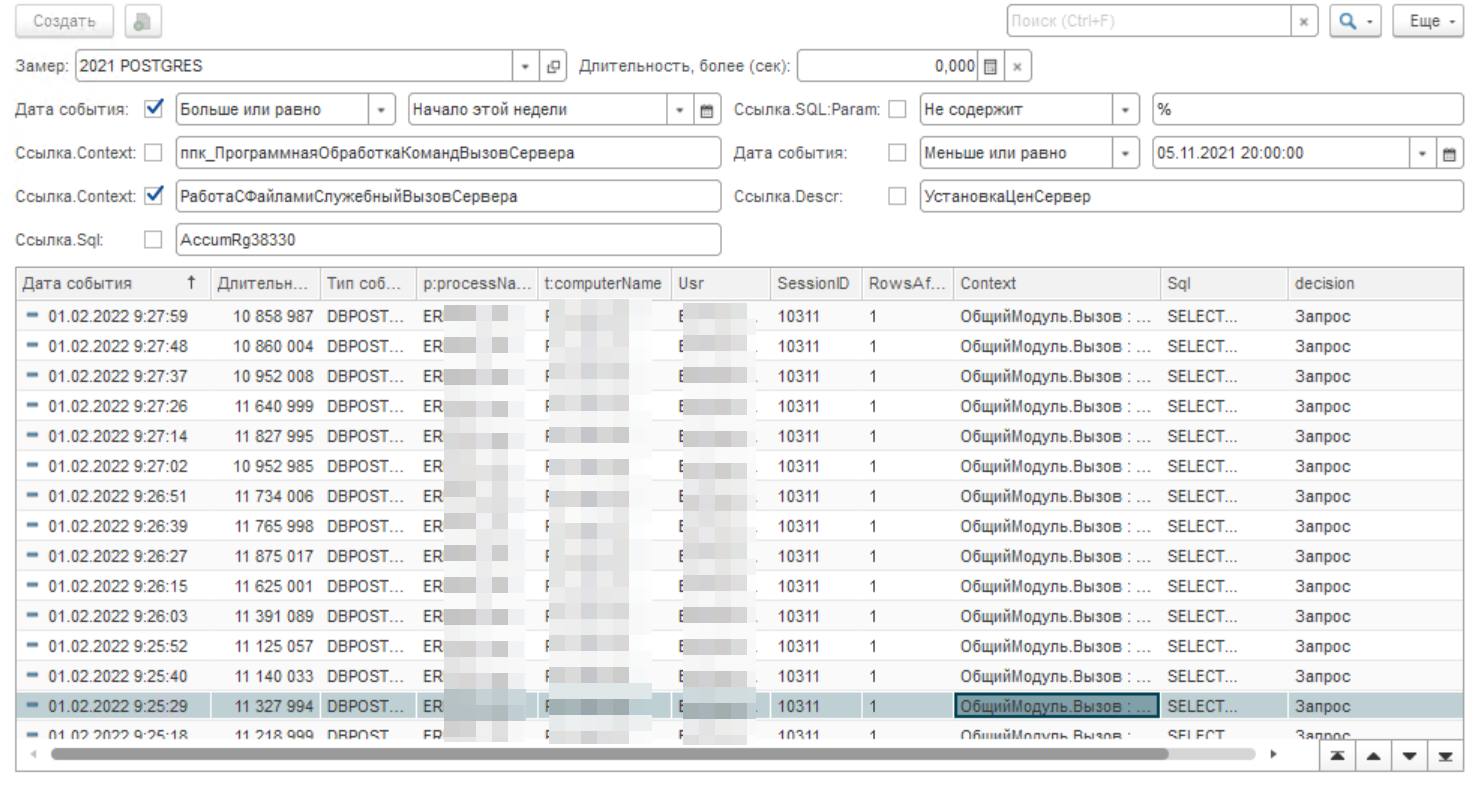
На решение проблемы отводилось довольно ограниченное время — пару часов. Получив фамилии пользователей мы погрузились в решение проблемы. Обратите внимание, что длительность в микро секундах, а если отбросить 6 нулей, то получим секунды. Время отработки запроса динамического списка на рисунке ниже от 100 до 4 000 с.

Теперь сделаем фильтр по одному пользователю:
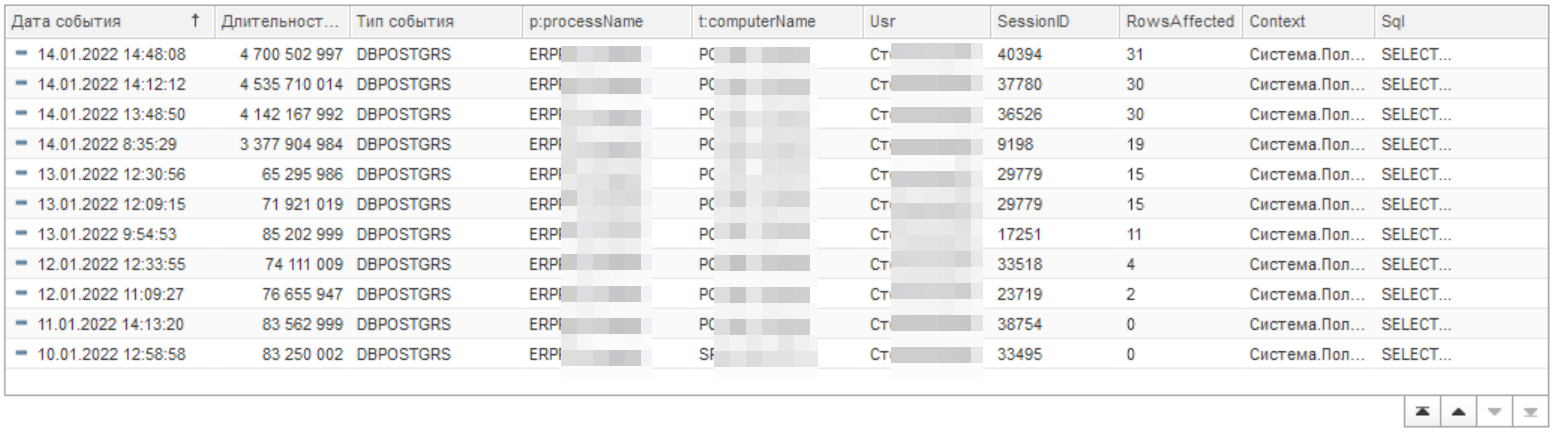
Мы видим, что что-то произошло с 13 на 14 число. Первым делом посмотрим тексты запросов и сравним их. Это поле SQL для двух замеров до и после. В результате сравнения мы определили, что они одинаковые, т.е. это один и тот же запрос. Поэтому работаем дальше и пытаемся понять, что тут не так.
Определяем и смотрим позицию возникновения проблемы по Context.

Открываем и видим, что на форме находится несколько динамических списков. Для того, чтобы понять, что это за список, возьмем текст запроса SQL и преобразуем его с помощью конвертора SQL в 1С.
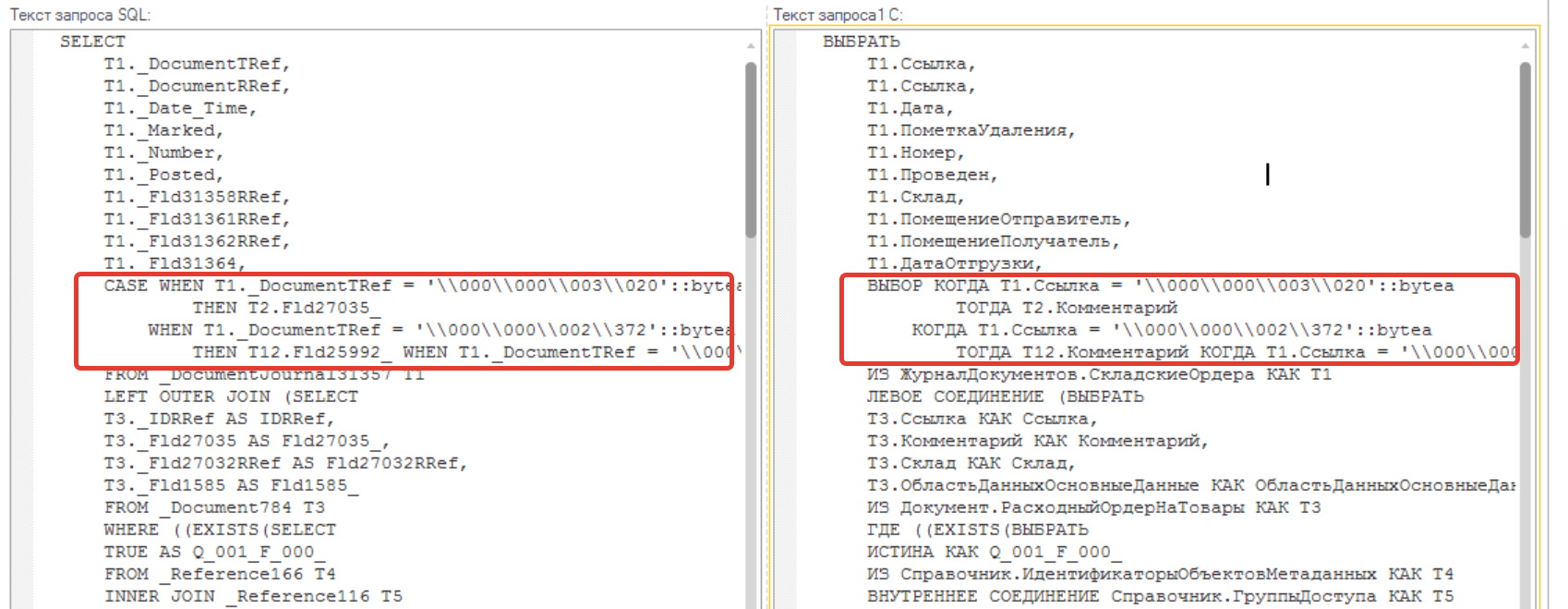
Обращаем внимание на относительно большое количество таблиц и наличие нескольких операторов "ВЫБОР" в поле "Комментарий" (выделено красной рамкой). Это выглядит как получение данных через две точки. Странно! Давайте смотреть дальше.
По тексту мы видим основную таблицу - "ЖурналДокументов.СкладскиеОрдера". Это второй динамический список, который расположен внизу формы.

Открываем форму и смотрим свойство поля "Комментарий" формы.
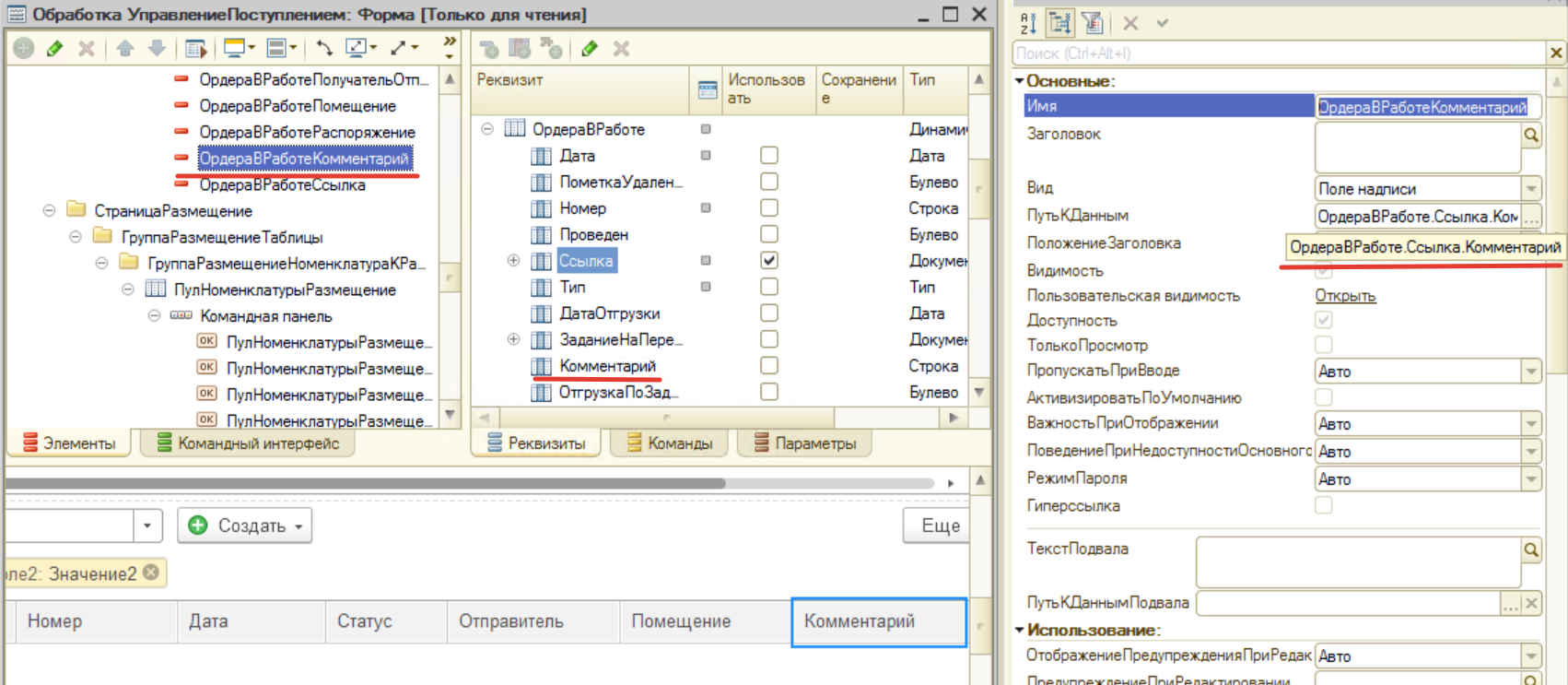
Тут мы с вами видим, что путь к данным ведет не к ожидаемому реквизиту «Комментарий» журнала «СкладскиеОрдера», а к реквизиту «Ссылка.Комментарий» - обращение через две точки. Вот такая мина подложена в одном из самых востребованных АРМ конфигурации. В итоге вместо как минимум одной RLS по журналу, будут добавляться платформой 1С еще три ограничения по всем ордерам. А может и больше, зависит от того, как группы доступа настроены администратором базы данных.
Решение: Требуется исправить данную оплошность и переуказать путь к данным на реквизит «Комментарий» журнала «Складские ордера». Первым шагом создаем патч и накатываем на конфигурацию по согласованию с заказчиком. После этого патча производительность проблемных пользователей вернулась и даже стала лучше, чем до этого момента. Пользователи уже довольны.
Итоги: Мы обнаружили и исправили одну грубейшую ошибку рабочего места «Управление поступлением», приводящую к непозволительным и чудовищным падениям производительности в некоторых случаях. Пользователи довольны, а мы продолжили далее расследовать причину резкого снижения производительности в рамках зависимостей данных и RLS.
P.S. Данная ошибка на момент решения проблемы не исправлена в типовых конфигурациях ERP/КА/УТ.
2. Опять 25. Получаем данные через две точки.
Решили посмотреть почему такое большое количество маленьких запросов 6-12 секунд. К тому же при выполнении анализа на глаза попался кластер содержащий вхождения слов «файл», «управление доступом» - мы воспользовались функционалом обработки из статьи "Автоматическая классификация технологического журнала" (подобный подход также применим к контекстам запросов, т.е. можем получить суждение, к какому кластеру относится подобный длительный запрос).
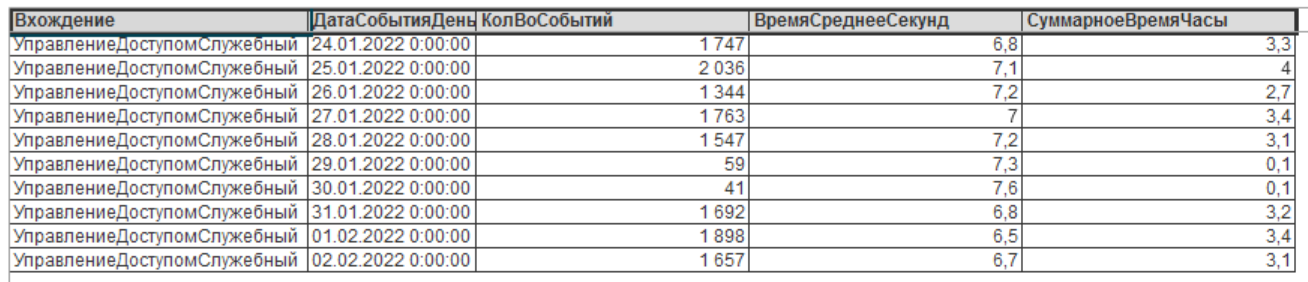
Ого. Достаточно много позиций. Иногда достигает 10-15 позиций в минуту при самом пике нагрузки. Давайте посмотрим на частоту появления данной проблемы по всей базе данных, сгруппированную по дням:
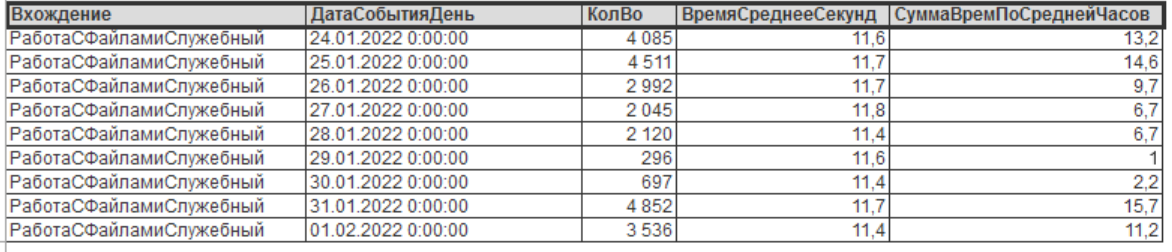
Как мы видим, это довольно частая операция. Из графика видно, что до 16 часов суммарно процессор на сервере занимается непонятно чем - фактически минус одно ядро!

Позиция выполнения запроса. Что же тут не так? Давайте глянем текст запроса в SQL. Он очень большой.
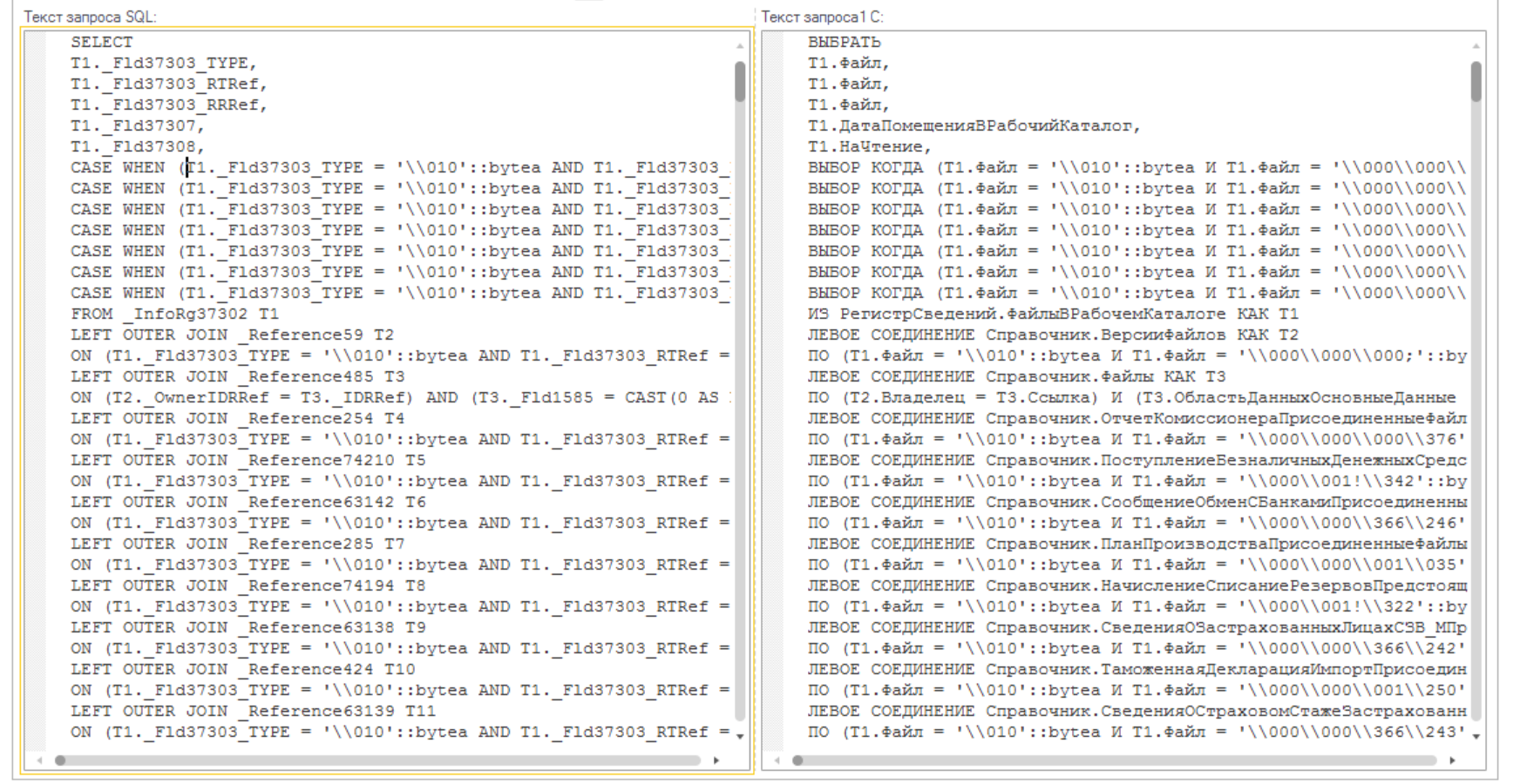
Код совсем небольшой, и в нем нет такой кучи таблиц! Но зато есть выбор через две точки. Который и выдает нам соединения. В запросе мы находим в самом низу таблицу со следующим индексом «T258». 258 соединений. Вот зачем так делать?
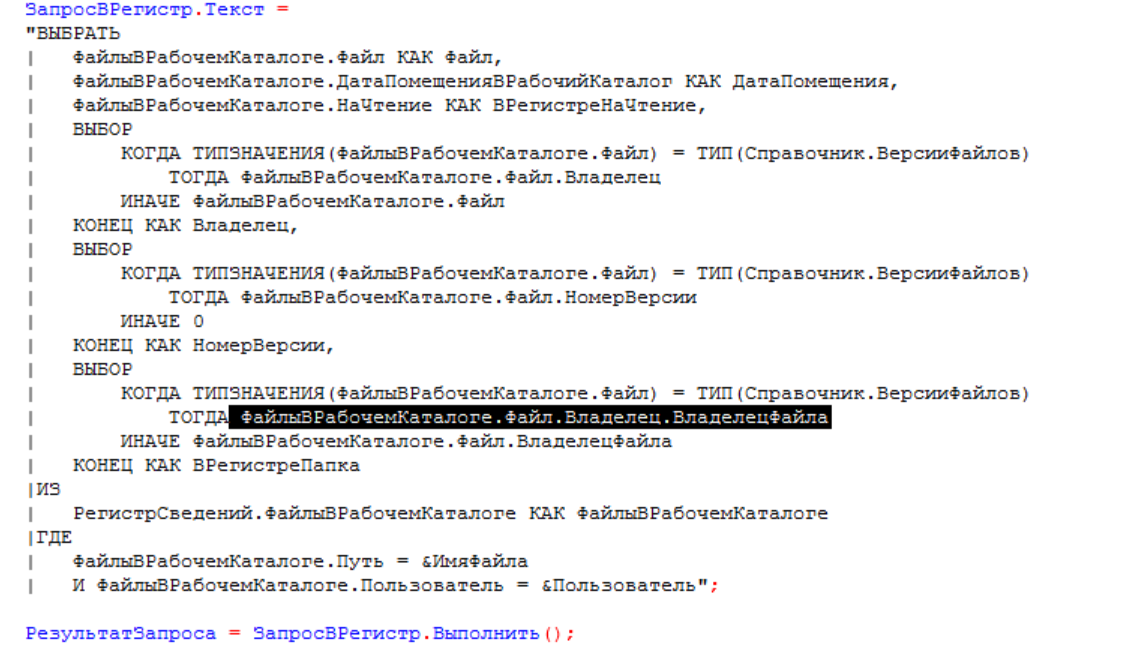
Решение:
Файл измерение составного типа. В первой части выбора используем выразить, а во второй воспользуемся регистром сведений «Сведения о файлах».

В результате время с 13 с на тесте снизилось до 1 мс. Отличное решение!
Итоги оптимизации: Мы фактически устранили ошибку в типовой конфигурации, которая при достаточно больших объемах базы данных приводила к неоптимальной работы системы на обоих базах СУБД.
3. Плохой план PostgreSQL
Смотрим дальше и находим следующую операцию, которая небольшая, но вызывает проблемы 6-12 с в зависимости от пользователя:
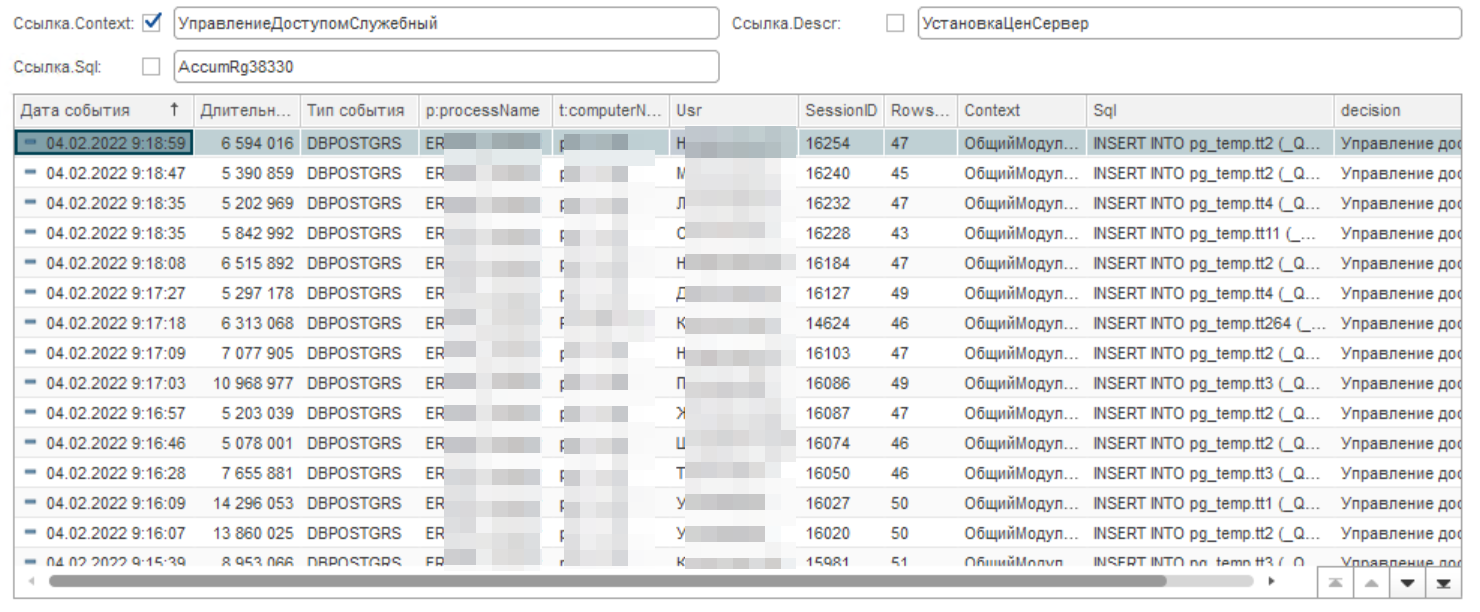
Оценка агрегированных событий по журналу показывает, что операция достаточно частая и хорошо поглощает ресурсы процессора и время пользователей:
Давайте посмотрим контекст:
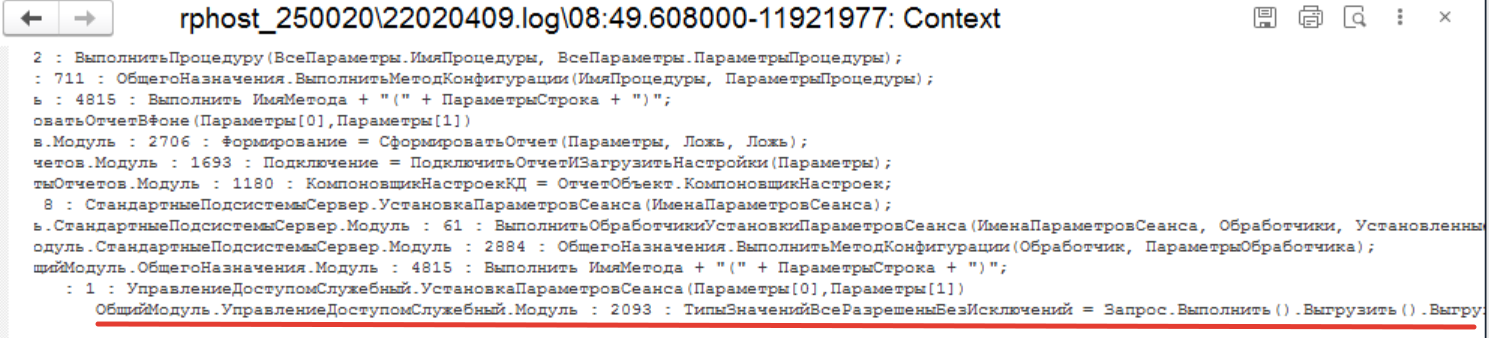
Как мы видим, общий модуль управления доступом и функция «Установить параметры сеанса». Идем в конфигурацию и ищем позицию в исходном коде.
Запрос представлен пакетом, нам нужен первая часть:
ВЫБРАТЬ РАЗЛИЧНЫЕ
ЗначенияПоУмолчанию.ТипЗначенийДоступа КАК ТипЗначений,
ЗначенияПоУмолчанию.ВсеРазрешеныБезИсключений КАК ВсеРазрешеныБезИсключений
ПОМЕСТИТЬ ЗначенияПоУмолчаниюДляПользователя
ИЗ
РегистрСведений.ЗначенияГруппДоступаПоУмолчанию КАК ЗначенияПоУмолчанию
ГДЕ
ИСТИНА В
(ВЫБРАТЬ ПЕРВЫЕ 1
ИСТИНА
ИЗ
Справочник.ГруппыДоступа.Пользователи КАК ГруппыДоступаПользователи
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.СоставыГруппПользователей КАК СоставыГруппПользователей
ПО
ГруппыДоступаПользователи.Ссылка = ЗначенияПоУмолчанию.ГруппаДоступа
И ГруппыДоступаПользователи.Пользователь = СоставыГруппПользователей.ГруппаПользователей
И СоставыГруппПользователей.Пользователь = &ТекущийПользователь)
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ РАЗЛИЧНЫЕ
ЗначенияПоУмолчанию.ТипЗначений КАК ТипЗначений
ИЗ
ЗначенияПоУмолчаниюДляПользователя КАК ЗначенияПоУмолчанию
СГРУППИРОВАТЬ ПО
ЗначенияПоУмолчанию.ТипЗначений
ИМЕЮЩИЕ
МИНИМУМ(ЗначенияПоУмолчанию.ВсеРазрешеныБезИсключений) = ИСТИНА
Как вы помните, проблемный кусок начинался с оператора «Insert», значит проблему вызывает первая часть. Запрос очень похож на использующиеся в RLS системы БСП.
Он не выглядит сложным, давайте взглянем на план запроса:
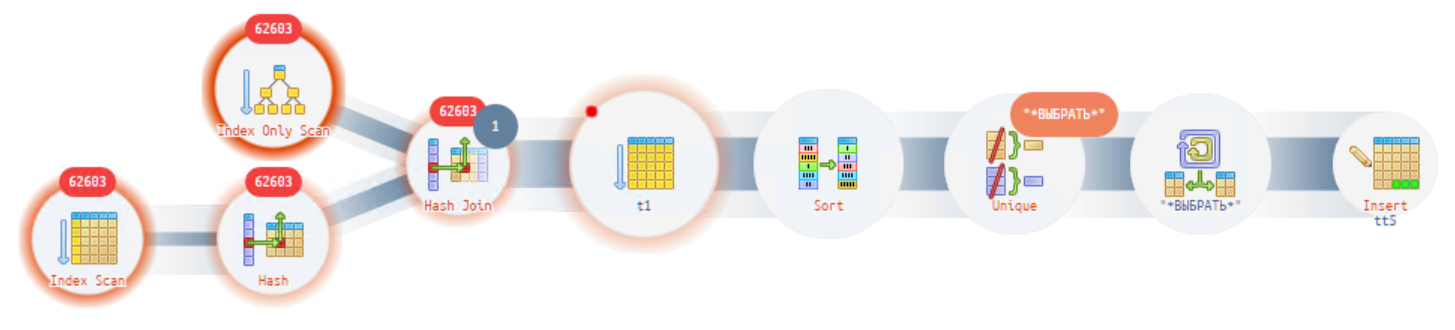
https://explain.tensor.ru/archive/explain/533c226e2a0008b2641ac0eb8ba205a2:0:2022-02-03#explain
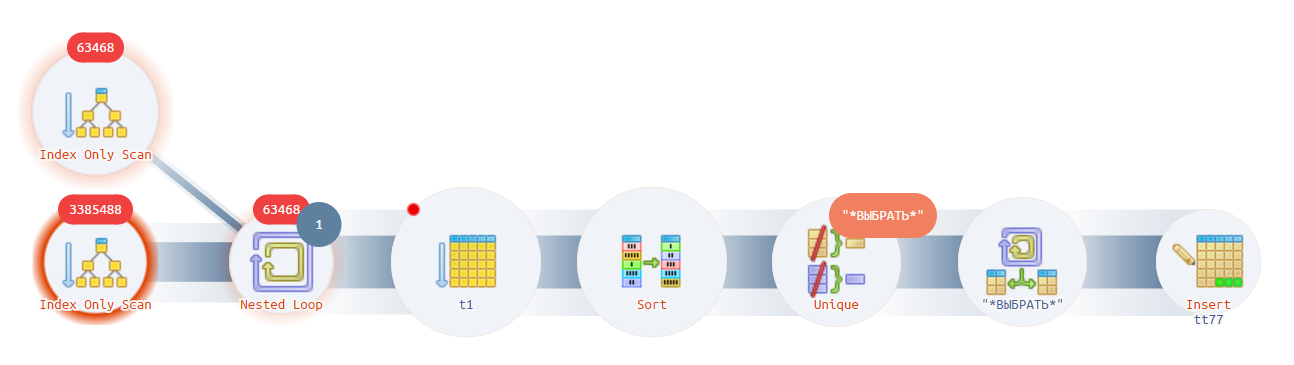
Как мы видим самый тяжелый блок — начальный. Используется оператор соединения циклом, выполняется сканирование более 3 млн раз (циферки на верху кружка).
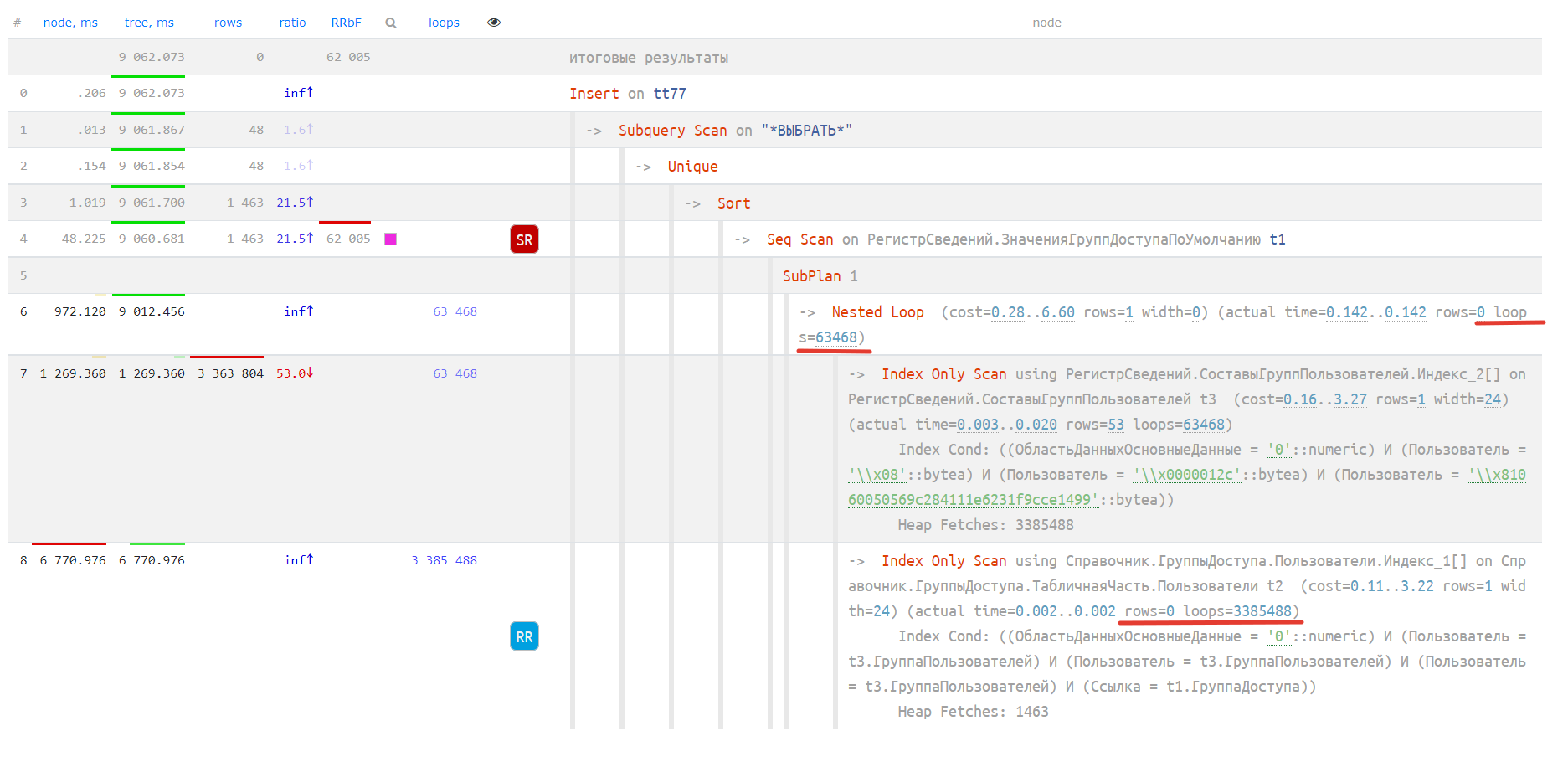
Давайте посмотрим как выглядит тот же план в базе СУБД MS SQL
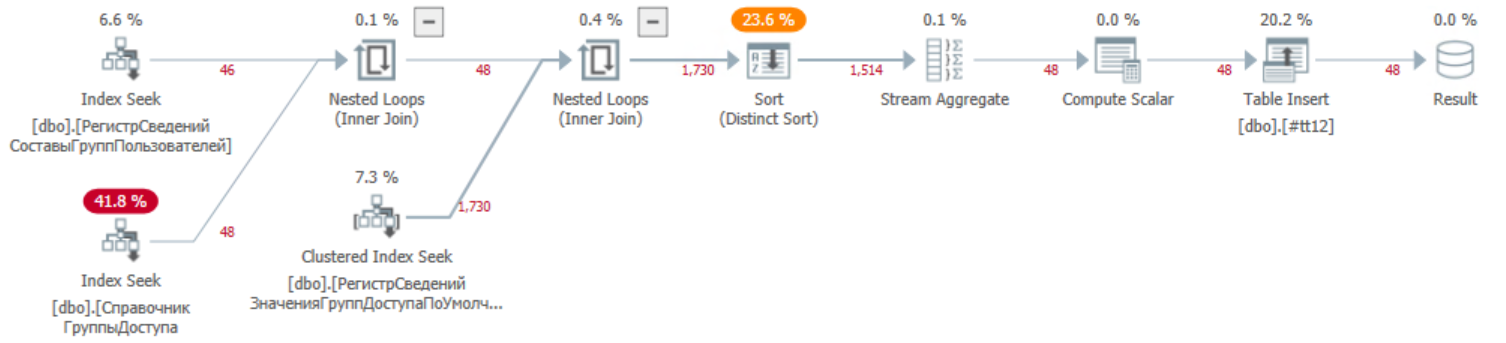
Планы довольно похожи, за исключением времени выполнения (около 10 мс) и количества считанных и обработанных данных.
Теперь выполним рефакторинг-оптимизацию. Вынесем соединение из оператора «В» в соединение таблиц следующим образом:
ВЫБРАТЬ РАЗЛИЧНЫЕ
ЗначенияПоУмолчанию.ТипЗначенийДоступа КАК ТипЗначений,
ЗначенияПоУмолчанию.ВсеРазрешеныБезИсключений КАК ВсеРазрешеныБезИсключений
ПОМЕСТИТЬ ЗначенияПоУмолчаниюДляПользователя
ИЗ
РегистрСведений.ЗначенияГруппДоступаПоУмолчанию КАК ЗначенияПоУмолчанию
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.ГруппыДоступа.Пользователи КАК ГруппыДоступаПользователи
ПО (ГруппыДоступаПользователи.Ссылка = ЗначенияПоУмолчанию.ГруппаДоступа)
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.СоставыГруппПользователей КАК СоставыГруппПользователей
ПО (ГруппыДоступаПользователи.Пользователь = СоставыГруппПользователей.ГруппаПользователей)
И (СоставыГруппПользователей.Пользователь = &ТекущийПользователь)
Запрос выполняется в консоли запросов менее чем за 10 мс. Время работы стало приемлемо. Посмотрим план выполнения:
https://explain.tensor.ru/archive/explain/947e585afc8fd23b64a7f9331d406320:0:2022-02-03#explain
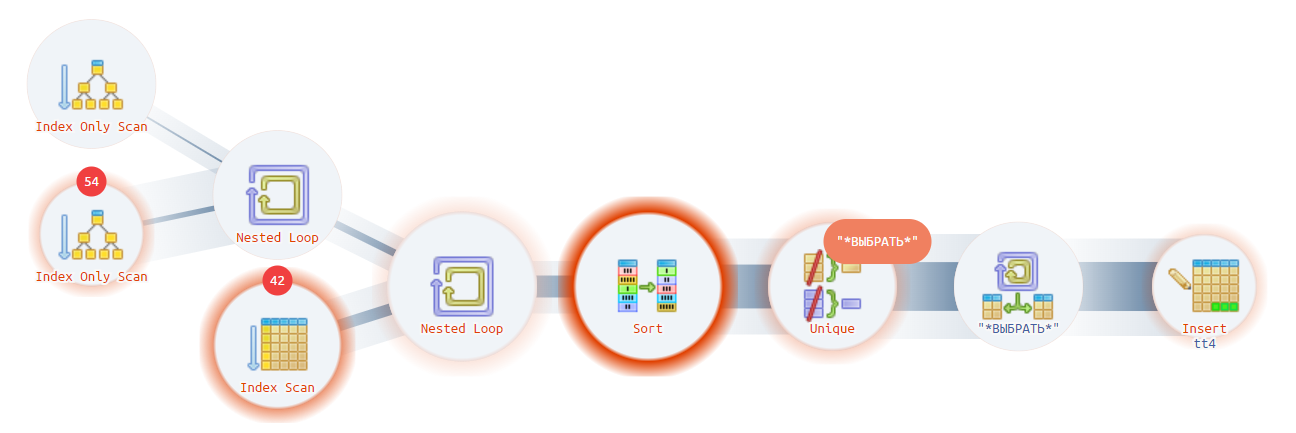
Проблема с блока сканирования ушла. Сканируется маленькое количество нужных записей, и это уже хорошо. Теперь проблема сдвинулась дальше на оператор сортировки, что вполне ожидаемо. План стал выглядеть оптимально и очень похоже на MS SQL.
Получим план исправленного запроса в базе MS SQL. Он практически не изменился. По времени выполнения и количеству считываемых и обрабатываемых записей остался на том же уровне.
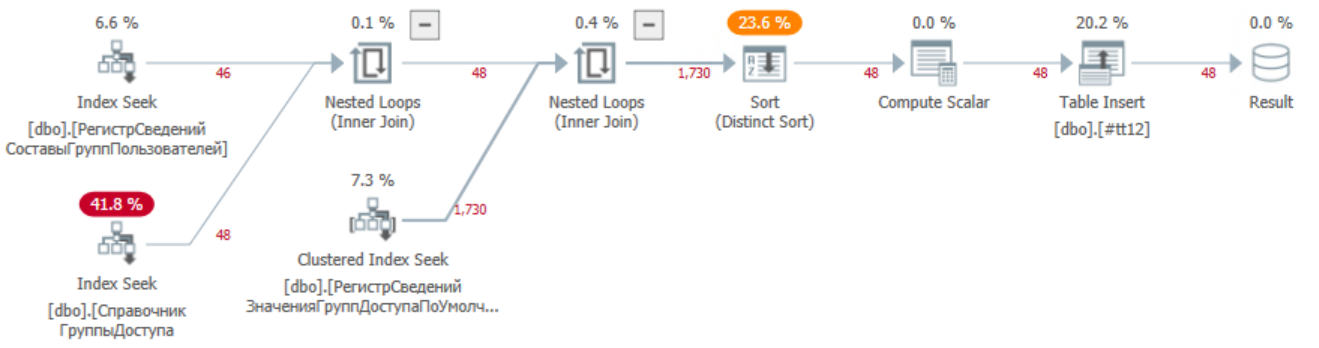
Итоги оптимизации: Успех! Мы фактически вернули быстродействие процедуры в целевые незначительные по времени рамки, избавив пользователей от проблемы ожидания лишних 5-12 с при запуске внешних обработок и отчетов. Быстродействие увеличилось в 5000 раз. Фактически мы выполнили оптимизацию под требования базы постгре, но также поведение базы MS SQL не изменилось. Данная процедура рефакторинга может быть применена в изначальной конфигурации вендора 1С для конфигураций ERP/УТ/КА.
P.S. Проверили на Postgres 13, тот же запрос выполняется гораздо лучше 500 мс (в 20 раз лучше), план более правильный, но все равно немного хуже оптимизированного:
https://explain.tensor.ru/archive/explain/613554aae7064b7e3d010e3b34f68d00:0:2022-04-01#visio
4. JIT оптимизация — это такая оптимизация!
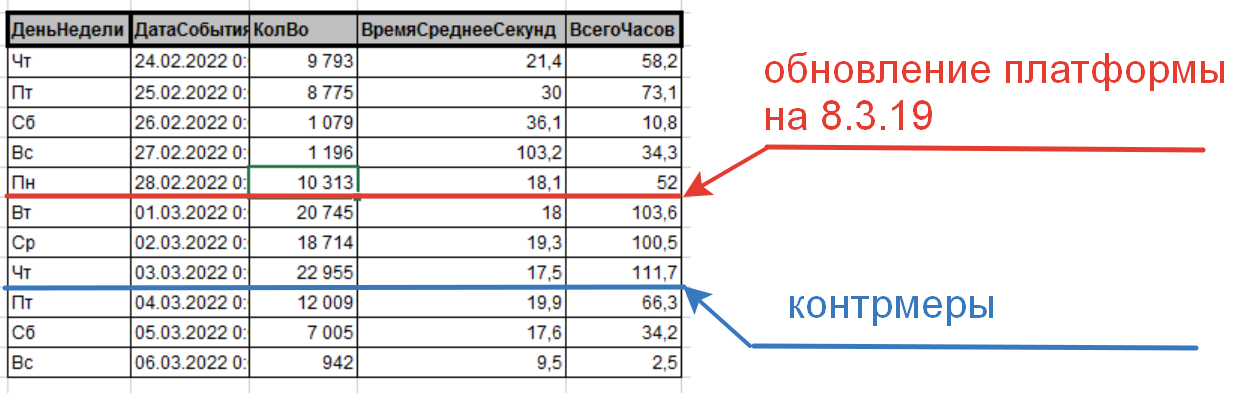
В данном примере речь пойдет об оптимизаторе Postgres. Мне давно эти всякие штучки-дрючки казались подозрительными, но все времени не было детально посмотреть. Ситуация проявилась после обновления платформы. Этот шаг был необходим в связи с ситуацией рассмотренной в примере «Пример расследования проблемы производительности по шагам с картинками». Согласно рекомендациям мы обновили платформу у заказчика и со спокойной совестью отправились спать, чтобы утром прикинуть, насколько эффективно работает новая платформа, но… Утро не было таким радостным, а скорее облило словно холодный душ, а к вечеру ситуация стала довольно очевидна — это выглядело как провал, а не успех. На рисунке красным показана дата обновления платформы с 8.3.16 на 8.3.19. Мы видим резкий рост проблемных запросов.
Контрмеры были предприняты — показано синим цветом.
Что могло пойти не так? Это была проблема, которую необходимо было срочно решать. Со стороны службы сопровождения пользователей пришли сообщения о проблемных ситуациях, основное недовольство пользователей было связано с поведением списка задач. Мы построили отчет и «бинго», таблица по задачам показывала именно то увеличение времени.
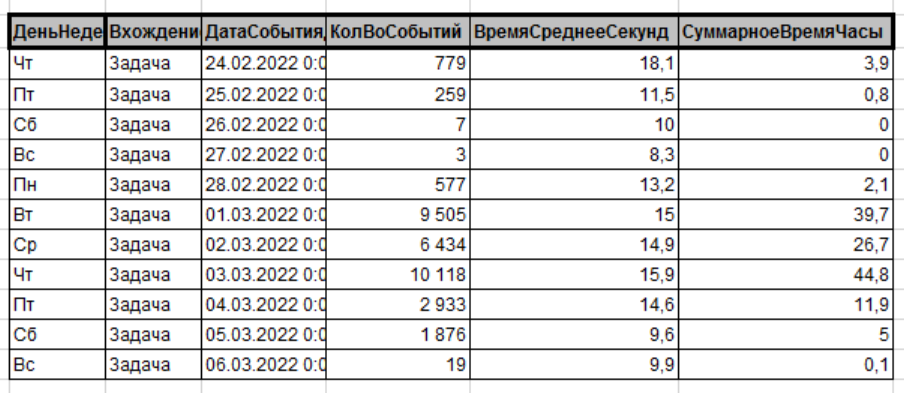
Начали смотреть по пользователям. Сложилась следующая картинка, время выполнения по пользователям не изменилось и осталось средним, но появилось много новых пользователей с временем более 5 с. Знаете почему такое критичное количество? Ответ довольно прост — форма мои задачи обычно находится на начальной странице и стоит авто обновление раз в минуту. Отключать авто обновление нельзя, т.к. новые задачи должны появляться без принудительного обновления списка пользователем. Удобно было бы, если бы появлялось уведомление о новых задачах, но, думаю, это будет в следующих релизах.
План запроса
https://explain.tensor.ru/archive/explain/50e1baada886a76571761e2d06468b05:0:2022-03-06#visio
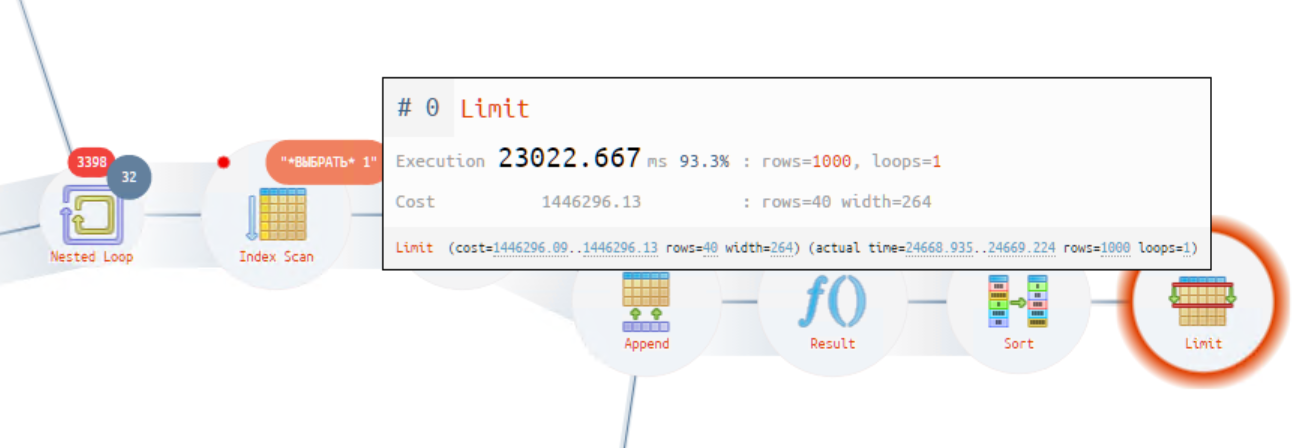
Удивила выделенная операция — оператор «Limit», которая занимает до 93.3%. Это довольно непонятное состояние. Общее время получилось в районе 25 с.

Обратите внимание, сколько времени занимает выполнение оптимизации оператором JIT.
Для того чтобы оценить, какую выгоду вносит сам jit, нам необходимо выполнить запрос с отключенным оптимизатором.
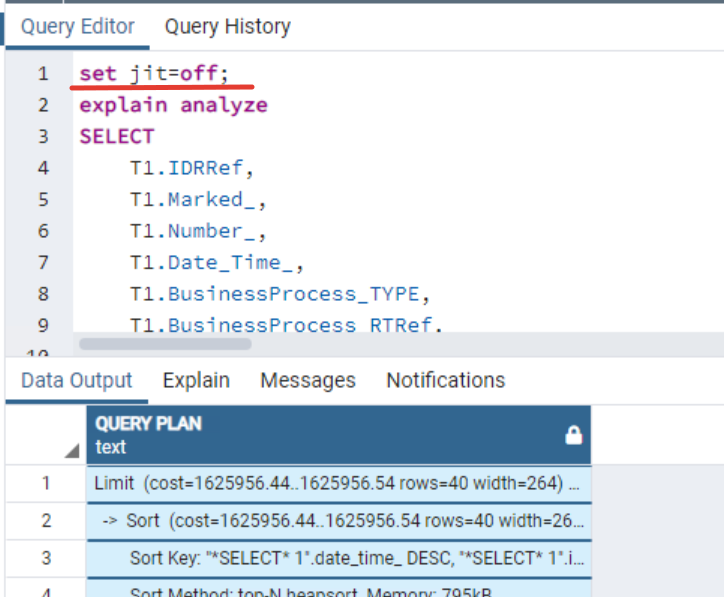
Для этого берем запрос и выполняем команду с отключенным оптимизатором. План выглядит следующим образом:
https://explain.tensor.ru/archive/explain/85975ea000377da98ffea641e1672d88:0:2022-03-07#visio
Общее время снизилось до 1,5 с. В данном случае использование оптимизатора значительно ухудшает время выполнения запроса. Почему так происходит? Не верно предсказывается сложность выполнения запроса. Думаю, что большой вклад в ошибку вносит наличие сложной RLS, накладываемой на таблицу платформой 1С. Выполнение обновления статистики в данном случае не помогает.
Решение:
Для дальнейших действий можно выделить несколько вариантов:
- отключить в настройках конфигурации JIT = off. Полностью отключаем.
- увеличить параметры срабатывания jit_optimize_above_cost, по умолчанию стоит 500 000.
- отключить использование оптимизатора jit_optimize_above_cost=-1.
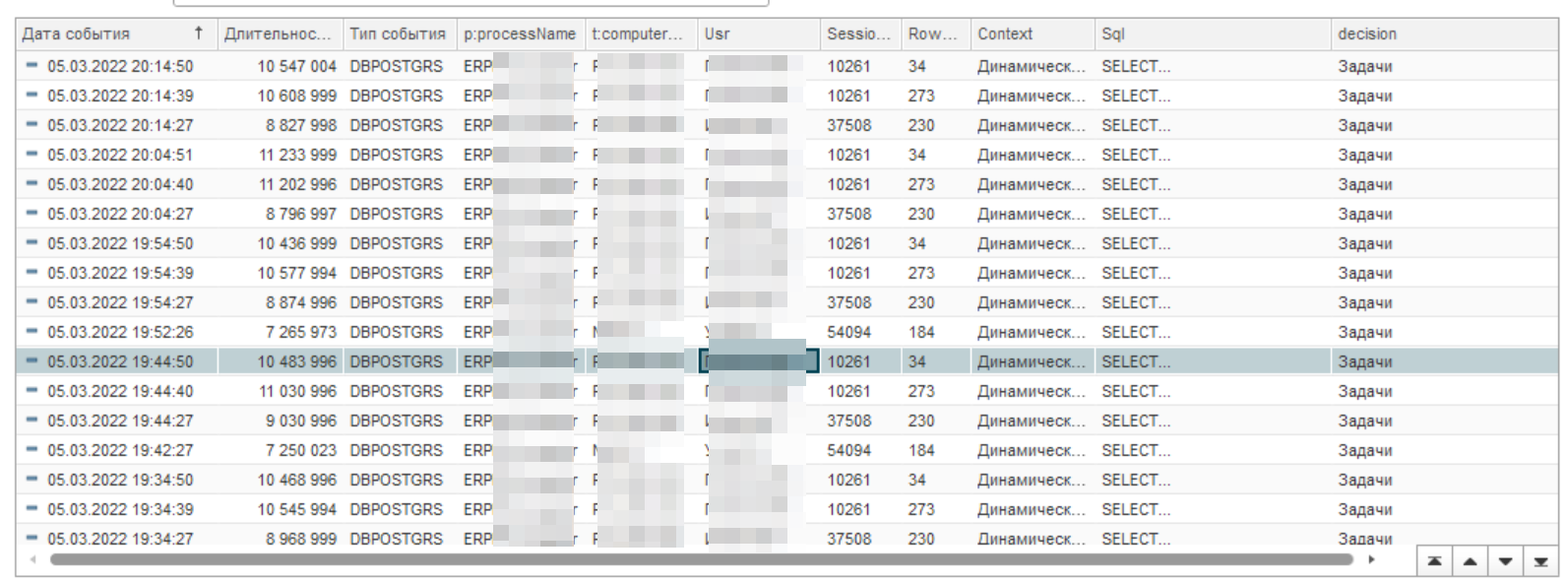
Первоначально было принято решение увеличить порог срабатывания до значения 1 500 000. Эффект получился практически мгновенным - более 70% запросов ушло. В таблице данное событие отражает пятница.
Хочу отметить тот факт, что сами разработчики постгрез и jit отмечают следующее: включать этот механизм для всех ситуаций не стоит, настраивайте под свою систему.
Но все равно остались некоторые запросы и был выполнен следующий шаг: jit_optimize_above_cost=-1.
Показатель рабочая суббота. Как видно из рисунка, снизилось не только количество событий, но и среднее время выполнения. Фактически исчезло большое добавочное время работы JIT.
https://explain.tensor.ru/archive/explain/9f366440c300acdd2ad6a83185761eaf:0:2022-03-07#visio
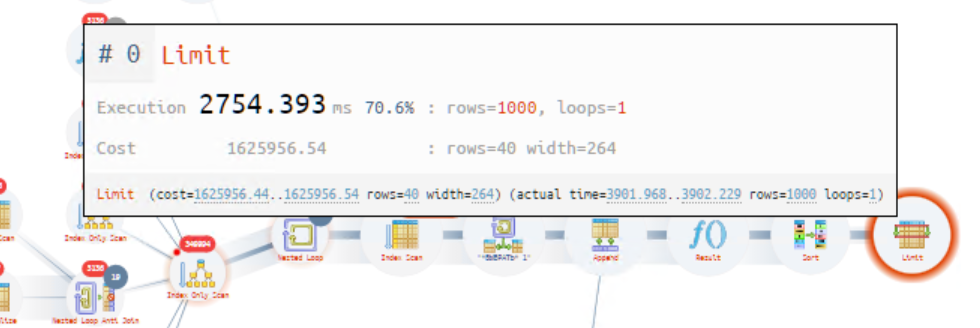
Время сократилось до 4 с. Но оптимизатор продолжает вносить лишнюю задержку.

Смотрим далее. Количество проблемных запросов уменьшилось, но не исчезло совсем.
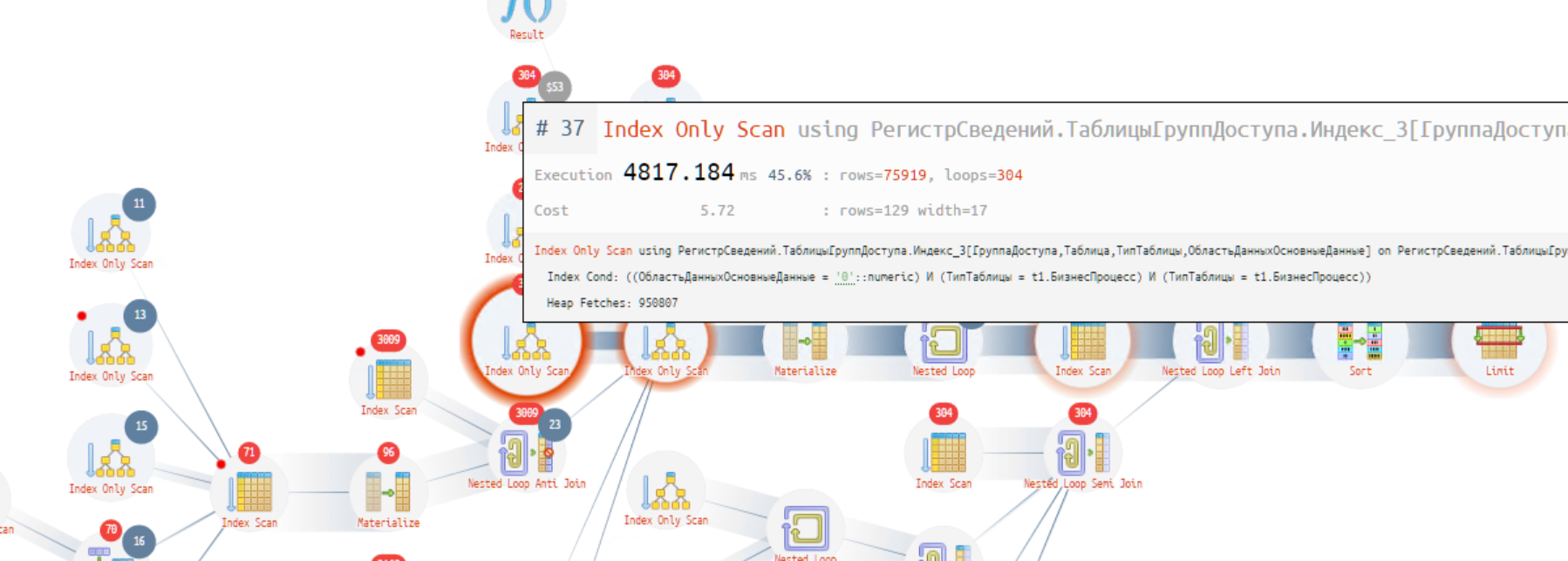
Проблема, которая осталась — это время на обработку RLS. Из картинки видно, что акцент на операторе сканирования таблицы «Группы доступа».
https://explain.tensor.ru/archive/explain/a41092a7a08caad8a7d7afc4393fab30:0:2022-03-07#visio
Решение данного вопроса может состоять в двух следующих частях:
- анализ текущих настроек прав доступа и удаление излишних
- использование другой модели RLS, к этому варианту мы вернемся в следующих статьях.
5. Через две точки + плохие поля выбора и ужасные СКД отборы по ним
Открыли список и поставили отбор на 1000 с. И немножко ужаснулись тому, что увидели. Но самое странное — это запросы длительностью в 20 000 -34 000 с.

План запроса искать бессмысленно, обычно на такую длительность они просто не сохраняются. Открываем контекст и смотрим где это.

Тут мы столкнулись с проблемой медленного открытия формы динамического списка в базе при подборе товаров в коммерческое предложение. Давайте посмотрим, что там такое, судя по всему ничего хорошего!

На форме динамический список и отбор по организации. Жмем открыть произвольный запрос и смотрим его внимательно. Список строится по справочнику назначения, много сложных полей для вывода. Текст приведен ниже:
Через пару минут, может кто-то быстрее, мы замечаем довольно очевидную и грубую ошибку - получение данных через две точки от составного типа.

Хотел выполнить запрос и посмотреть его план, но у меня не хватило терпения. Поэтому план запроса не привожу, если кто-то соберется духом, то пусть скинет ссылку.
Решение: Будем избавляться от получения данных через точку. Для этого воспользуемся реестром документов.
Ниже приведен оптимизированный запрос:
Выполняем запрос и смотрим его план:
https://explain.tensor.ru/archive/explain/bfb5890f29681376b39e60668b20b169:0:2022-03-29#visio
 \
\
Вроде все здорово. Вносим код в конфигурацию. Но на форме есть флажок фильтра "Только заказы по организации ...", и если мы его активируем, то быстродействие у нас опять приземляется. Не так сильно, но 60 с тоже много. Что за дела? Должно же быть еще быстрее, мы же добавили фильтр?
Смотрим план запроса для этой ситуации:
https://explain.tensor.ru/archive/explain/f1a39936379c9917f0f27972b3df5c5d:0:2022-03-29#visio
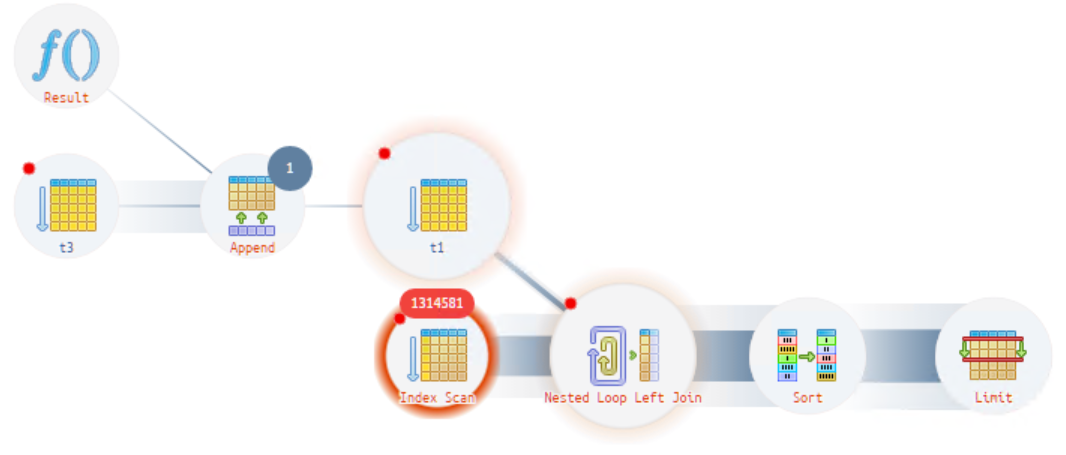
На рисунке ниже мы видим операцию сканирования, которая выполняется 1,3 млн раз (жирный красный кружок на рисунке выше и цифра в красном овале). В данном случае происходит перебор всех ссылок таблицы назначений, а их очень много. Давайте попробуем понять, из-за чего такое происходит.
Возьмем тексты запросов первого и второго случая, и их сравним. В результате увидим отличие в секции «ГДЕ» - вылезает наш отбор по организации. Но выглядит он странно, ужасно и непонятно, что это и как такое получилось?

Объясняем. Поле «Организация» у нас находится в выбранных на вывод полях.
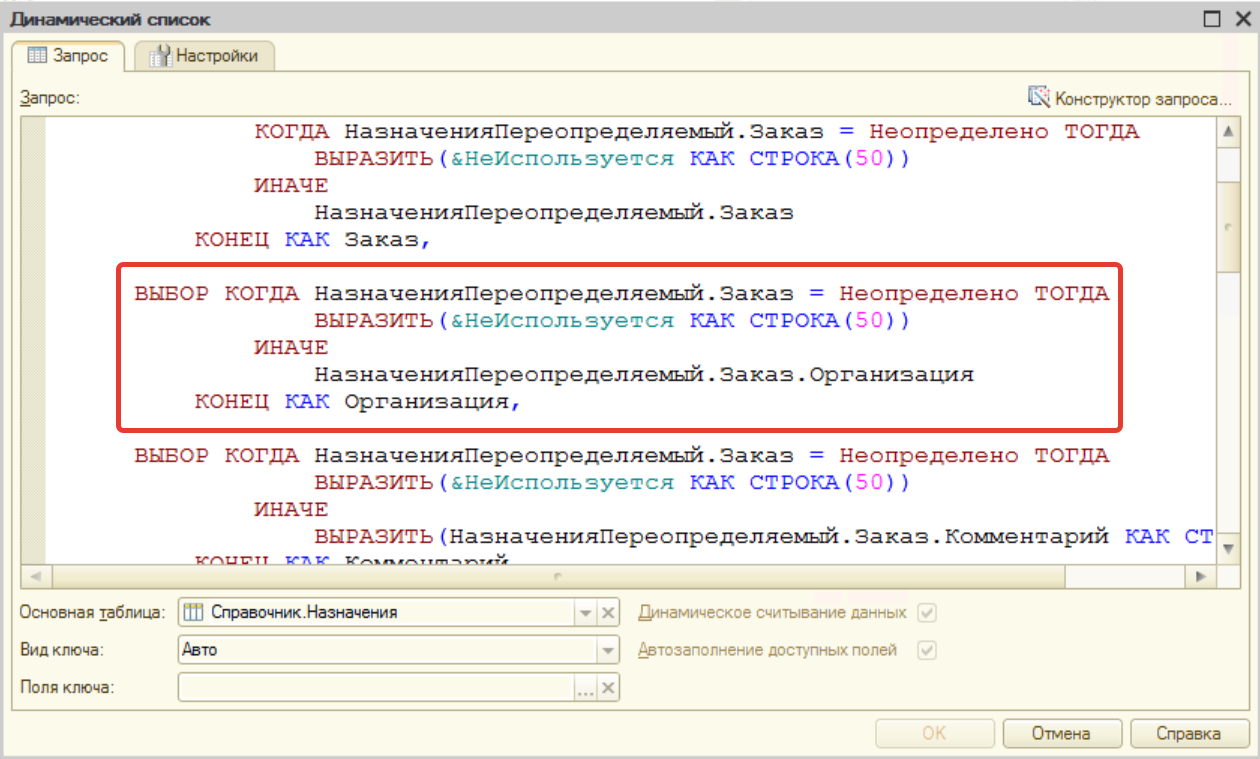
Далее в коде есть функция, которая добавляет по нему отбор СКД. А СКД накладывает отбор, взяв представление вывода поля и добавив его в условие примерно так:

И далее у планировщика нет такого индекса и он не понимает, как сделать правильно, и мы видим снижение быстродействия.
Зачем так сделано? Видимо, этот код пришел из глубокой древности, когда ничего про оформление динамических списков разработчику не было известно и такой возможности не было, возможно, с обычных форм. Цель - для того случая, когда отсутствует заказ, чтобы вместо демонстрации пустой ссылки выводился текст «не используется».
Убираем эту конструкцию для поля организация и переписываем запрос еще раз:
Наконец! Наш запрос начал летать:
https://explain.tensor.ru/archive/explain/1c2ce18da2cf7dc94e08fbe5bc0ecf45:0:2022-03-29#visio
Резюме: время выполнения мы снизили на просто космическую разницу с 34 000 с до 100 мс, это ускорение более чем в 340 000 раз. И запомните, что используем везде условное оформление для динамических списков, а всю ересь и подобные выкрутасы выше надо запрещать и бить по рукам!
P.S. Данная ошибка на момент решения проблемы не исправлена в типовых конфигурациях ERP/КА/УТ.
6. Бесполезный индекс скан и отключенные итоги
Продолжаем смотреть, что у нас еще "плохого" в базе данных. Ставим отбор в 300 сек и немного «ужасаемся» от такого количества проблемных ситуаций. Мы видим — ультра долгие запросы. Среди очень больших времен выполнения запросов в глаза сразу бросается проблема с пиком в 1400 секунд (это чуть больше 23 минут). Можно уже мысленно провести параллель с «эстонской» оперативной базой учета.
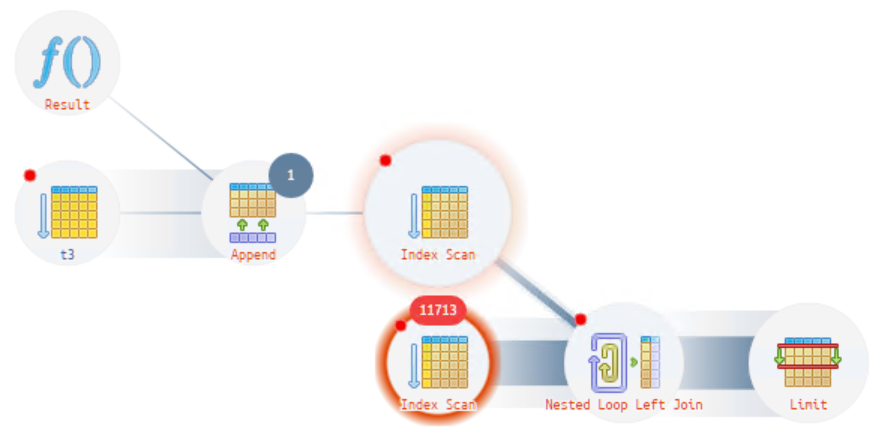
Посмотрим где это встречается.

Давайте посмотрим картинку с отбором по вхождению в контекст условия «РабочееМестоМенеджераПоДоставке». Что тут у нас единичный или закономерность?
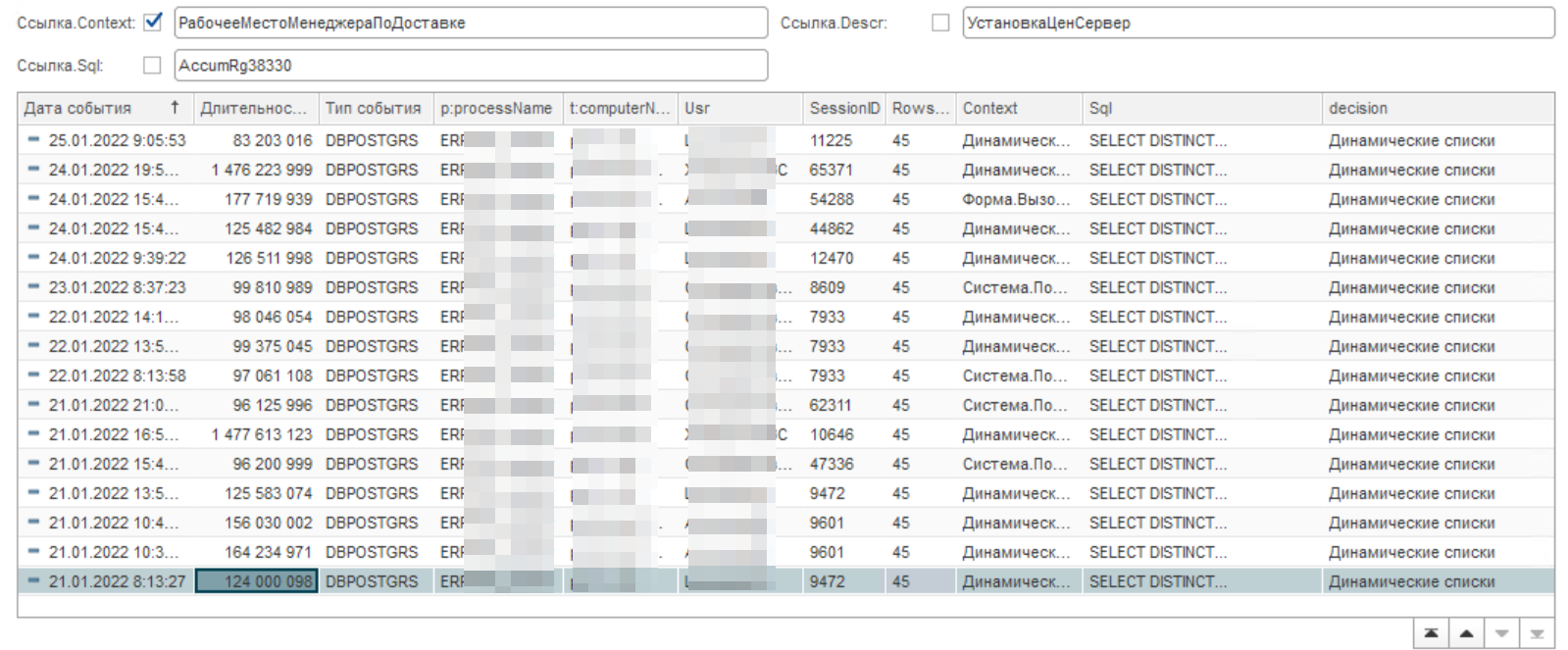
Как мы видим, то прослеживается закономерность. И подсказка нам сообщает, что это все происходит в динамических списках.
Запрос SQL очень большой и понять из него сходу что-то очень сложно, поэтому мы будем смотреть план запроса. Открываем файл лога базы и ищем по времени план соответствующего запроса.
Посмотрим план запроса, конечно, предварительно его преобразуем через конвертер SQL в 1С.
https://explain.tensor.ru/archive/explain/d676eebfb35e11e0379ae298b7d7607c:0:2022-01-22#visio
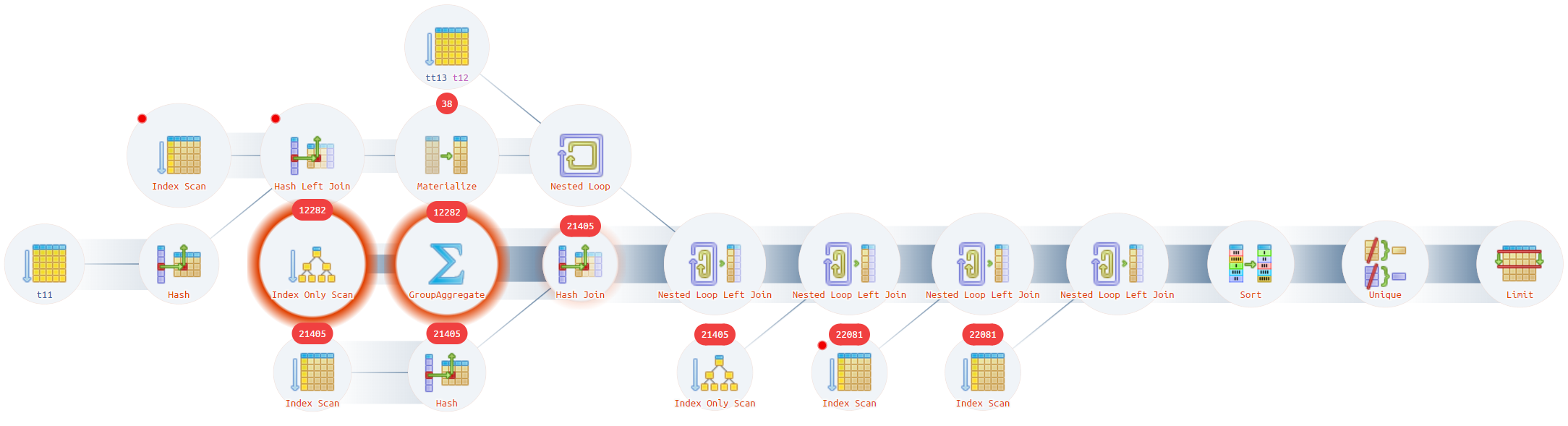
Как мы видим (два жирных красных кружка на рисунке выше), все основные ресурсы сжирает процедура Index Only Scan и группировка. Давайте глянем, что там такое. Суммарное время 1369 с (728 с + 641 с). Еще 111 с расходуются на соединение, идущее следом.
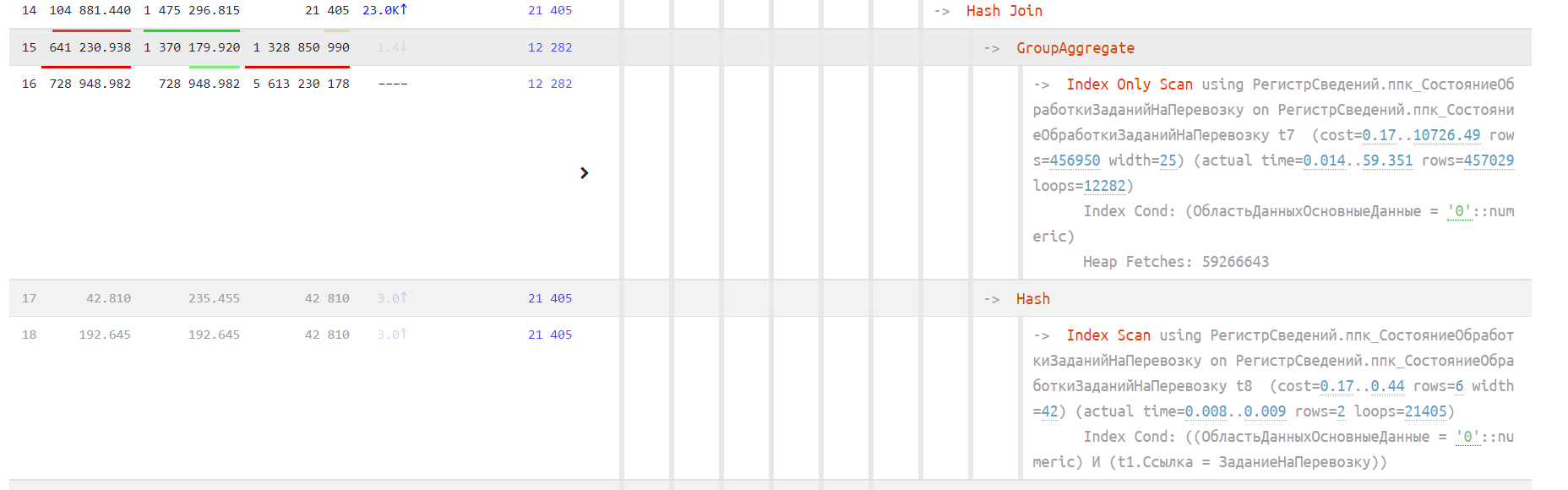
Наш Index Only Scan на самом деле выполняет лишнюю и ненужную работу, т.к. условие поиска по индексу «Index Cond» - «Область данных основные данные»=0 - фактически все записи таблицы - это бесполезные итоги! Много говорили про область данных и еще много скажут, но, на мой взгляд, это один из самых коварных элементов любой конфигурации БСП. По факту результат работы этого оператора похож на последовательное чтение (Seq Scan), но только по таблице индекса. Слишком много данных читается, чтобы потом пользователю вывести 45 записей.
Открываем целевую конфигурацию, открываем форму «РабочееМестоМенеджераПоДоставке» и ищем запрос. Смотрим и ….

Как видим, то запрос выглядит совсем ужасно. Но давайте взглянем на SQL код postgres, чтобы понять, что там еще есть такое. Он нам понадобится для дальнейшего анализа проблем.
И наш блок — это вот такой код:
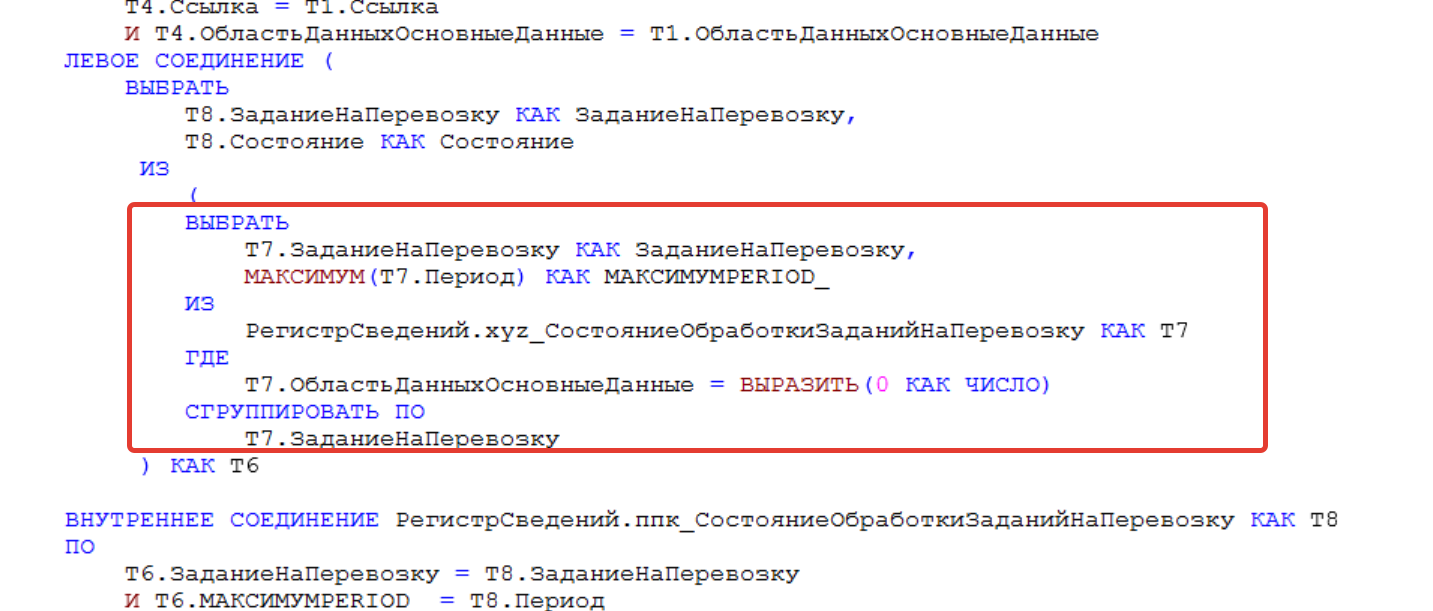
Система выполняет создание таблицы срез последних прямо в коде. Зачем она так делает?
Давайте проверим настройки этого регистра сведений. Открываем в конфигурации этот регистр сведений, переходим на вкладку прочее и смотрим позиции "Разрешить итоги".
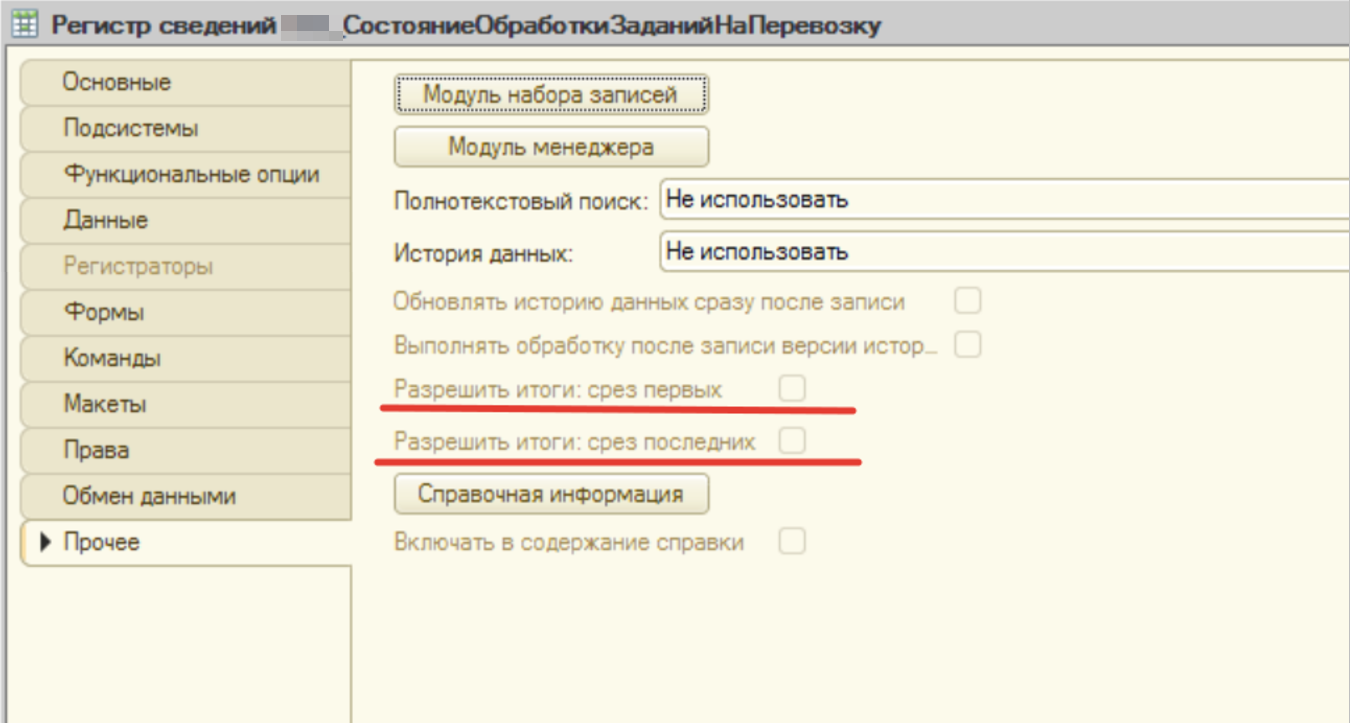
Как мы видим, то итоги отключены. Система каждый раз будет их высчитывать, чтобы использовать в работе.
Решение: Включаем итоги и упростим серверу и пользователям жизнь. После этой процедуры данные будут браться из итогового регистра, и вот те два красных кружка с плана запросов исчезнут.
Давайте возьмем еще один план запроса и посмотрим его. Вы, возможно, обратили внимание, что в запросе есть еще одно плохое решение - вывод и выбор количества точек погрузки и разгрузки во вложенной таблице. Смотрим оптимизированный план запросов еще раз:
https://explain.tensor.ru/archive/explain/bc39a18fd4de4601576b122332ffb35b:0:2022-01-22#visio
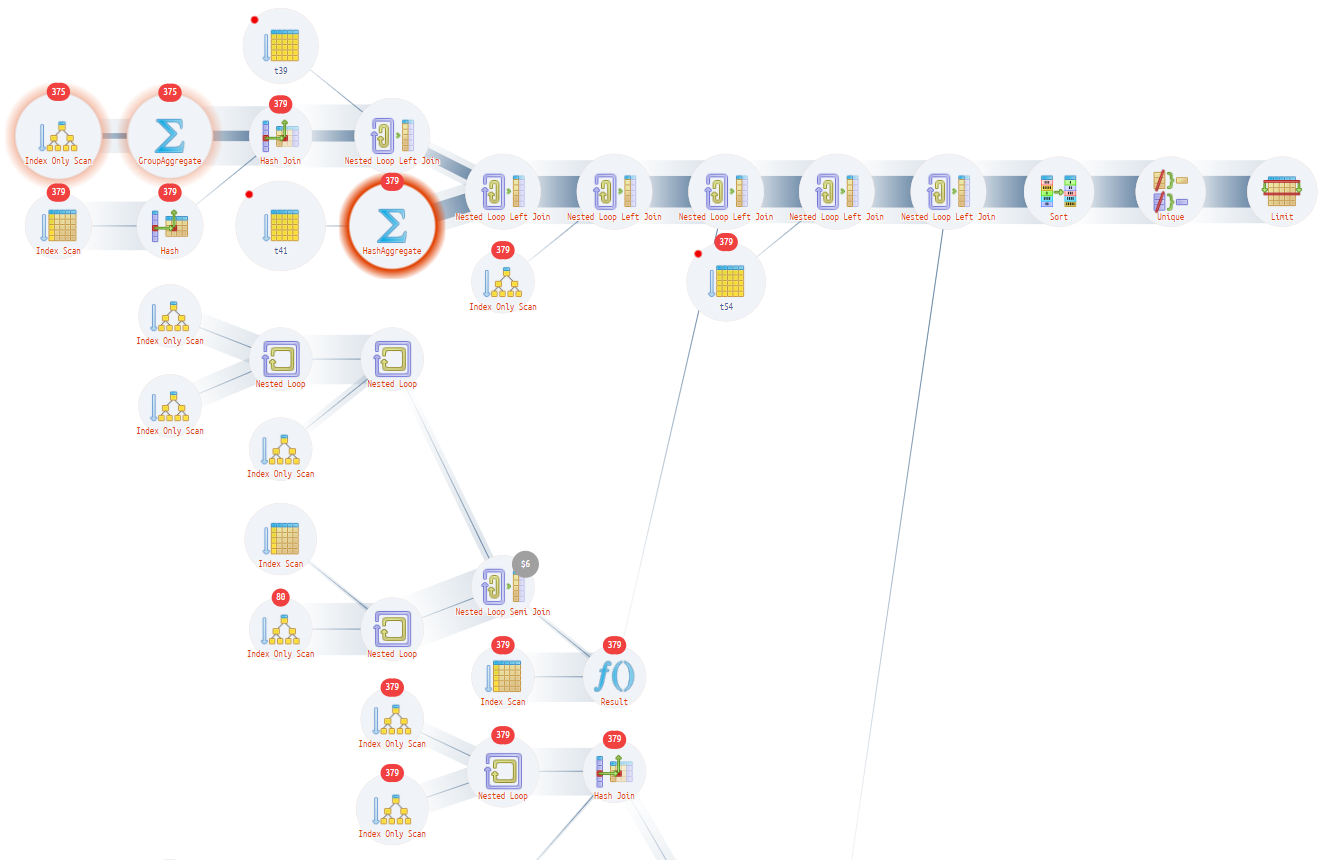
Позиция вхождения та же, но план запроса немного другой. Теперь проблема выглядит так:
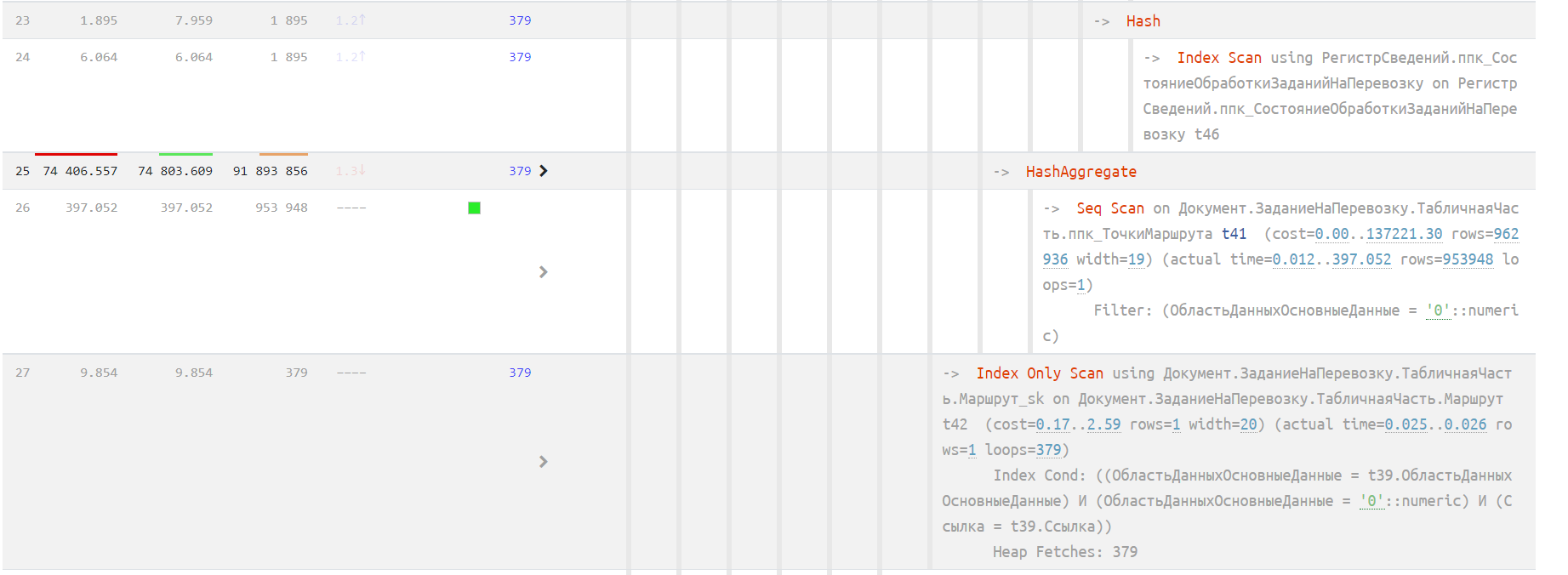
Тут уже сканирование таблицы точек погрузки и разгрузки. Давайте поищем в запросе таблицу с именем «T41».
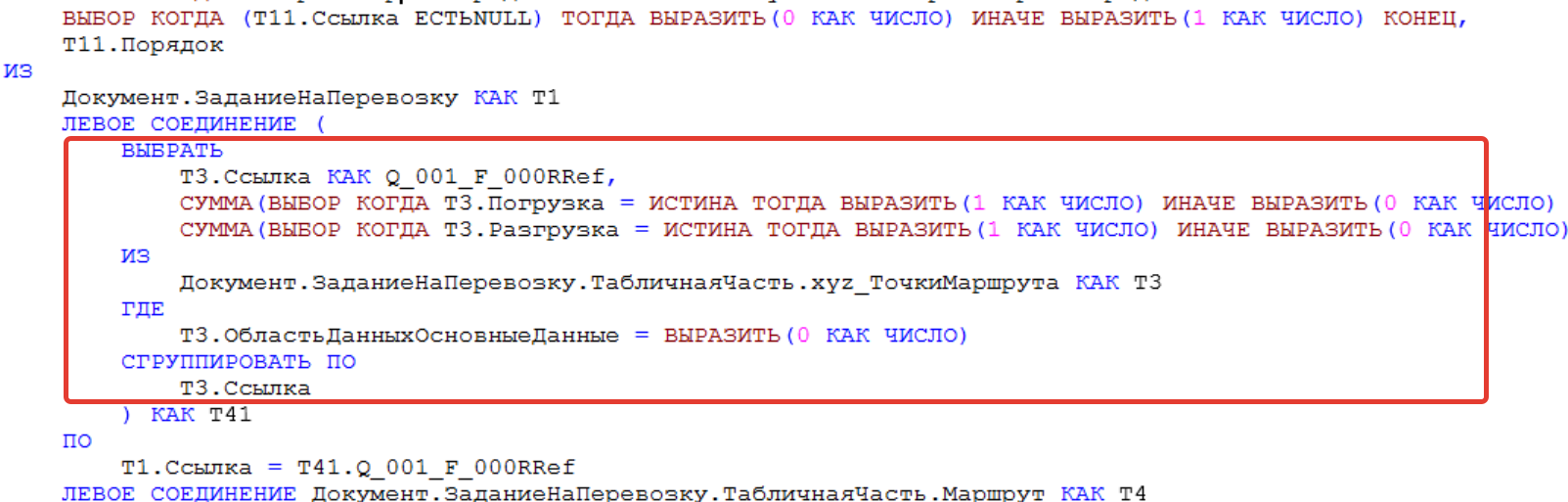
Вот этот кусок кода необходимо выносить в отдельный регистр сведений или шапку документа задания на перевозку. Дальнейший разбор этого случая и оптимизацию оставляем за кадром.
7. Нет отборов внутри виртуальных таблиц. Как так получилось?
Анализируем журнал длительных запросов и замечаем еще один запрос длительностью более 1000 секунд.
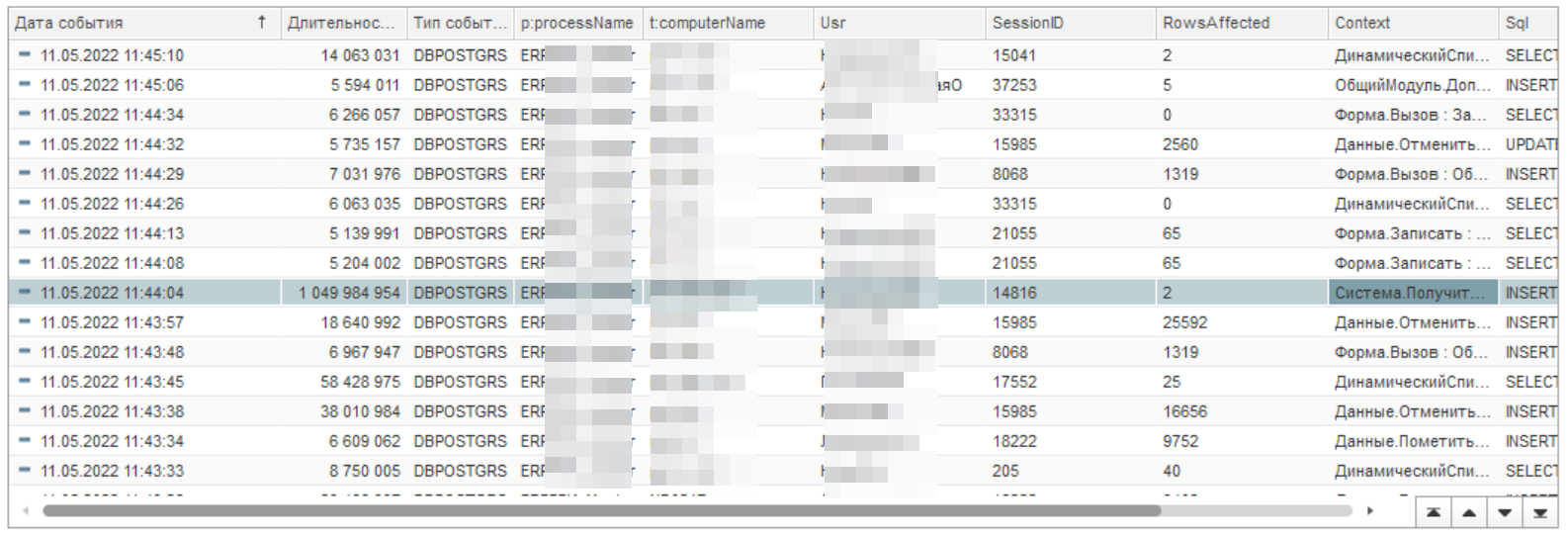
Контекст запроса выглядит следующим образом:

Давайте посмотрим, насколько часто встречается этот запрос. Для этого в фильтр списка добавим словосочетание из контекста. К примеру, вот так "ТоварыРазмещение.Загрузить(Запрос.Выполнить().Выгрузить())".
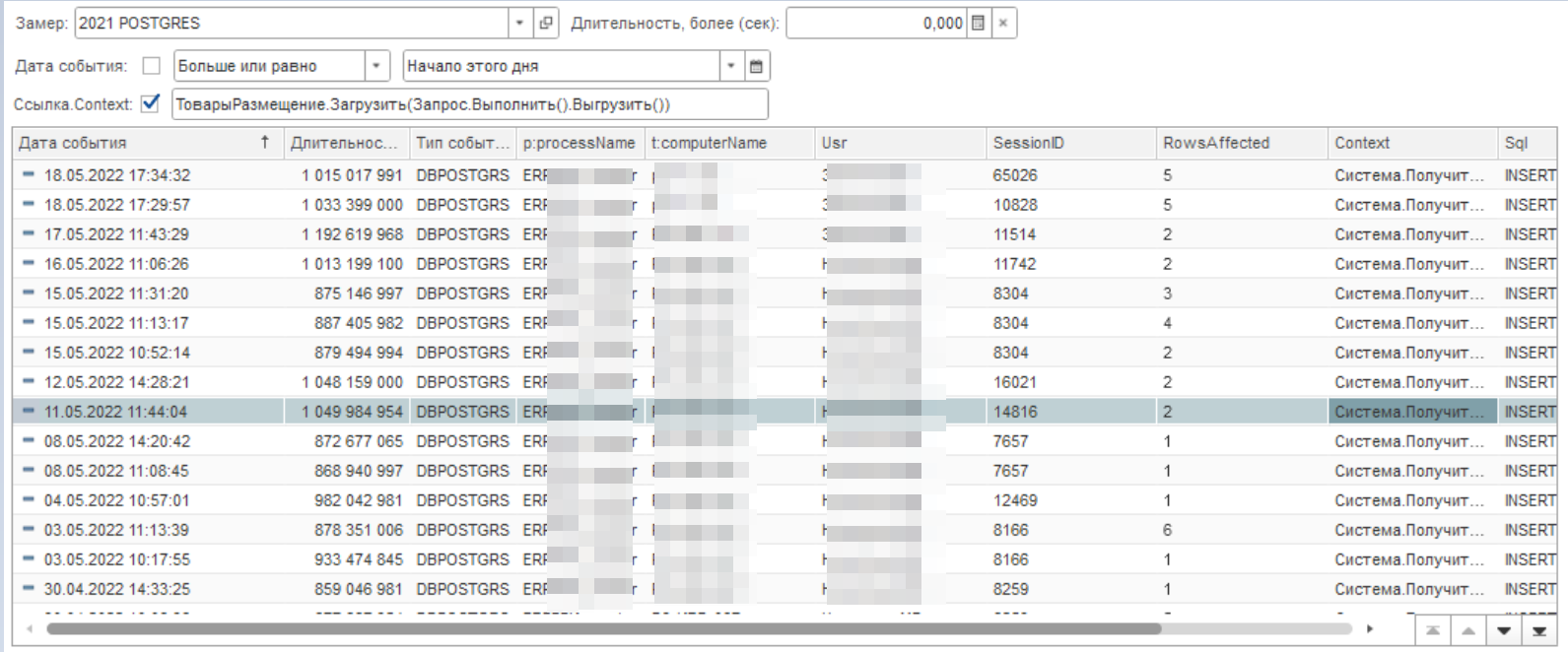
Событий достаточно много. Давайте откроем конфигурацию и посмотрим что там такое. Вспоминаем описание контекста и открываем модуль объекта документа "Отбор и размещение товаров". Далее жмем "Ctrl+G" и переходим к 581 строке. Следующим этапом находим запрос, который чуть выше.
Проблемный запрос приведен ниже. Обратите внимание на ту его часть, где используется соединение виртуальной таблицы без фильтров с временной таблицей. Видите ошибку или еще нет?
ВЫБРАТЬ
ТоварыВЯчейкахОбороты.Номенклатура КАК Номенклатура,
ТоварыВЯчейкахОбороты.Характеристика КАК Характеристика,
ТоварыВЯчейкахОбороты.Назначение КАК Назначение,
ТоварыВЯчейкахОбороты.Упаковка КАК Упаковка,
ТоварыВЯчейкахОбороты.Ячейка КАК Ячейка,
ТоварыВЯчейкахОбороты.Серия КАК Серия,
СУММА(ТоварыВЯчейкахОбороты.ВНаличииОборот) КАК ВНаличииОборот
ПОМЕСТИТЬ вт_КорректировкиНазначений
ИЗ
РегистрНакопления.ТоварыВЯчейках.Обороты(,,Авто,) КАК ТоварыВЯчейкахОбороты
ВНУТРЕННЕЕ СОЕДИНЕНИЕ вт_ДвиженияПоНазначению КАК вт_ДвиженияПоНазначению
ПО ТоварыВЯчейкахОбороты.Номенклатура = вт_ДвиженияПоНазначению.Номенклатура
И ТоварыВЯчейкахОбороты.Характеристика = вт_ДвиженияПоНазначению.Характеристика
И ТоварыВЯчейкахОбороты.Ячейка = вт_ДвиженияПоНазначению.Ячейка
И ТоварыВЯчейкахОбороты.Серия = вт_ДвиженияПоНазначению.Серия
И ТоварыВЯчейкахОбороты.Упаковка = вт_ДвиженияПоНазначению.Упаковка
И ТоварыВЯчейкахОбороты.Регистратор = вт_ДвиженияПоНазначению.Регистратор
СГРУППИРОВАТЬ ПО
ТоварыВЯчейкахОбороты.Номенклатура,
ТоварыВЯчейкахОбороты.Характеристика,
ТоварыВЯчейкахОбороты.Назначение,
ТоварыВЯчейкахОбороты.Упаковка,
ТоварыВЯчейкахОбороты.Ячейка,
ТоварыВЯчейкахОбороты.Серия
На рисунке ниже мы описали, как на плане запросов выглядит процедура формирования виртуальной таблицы "Обороты" и чуть ниже примерная последовательность выполнения.
https://explain.tensor.ru/archive/explain/1e16f485e815a9b4fcab27daf6e4db9e:0:2022-03-05#visio
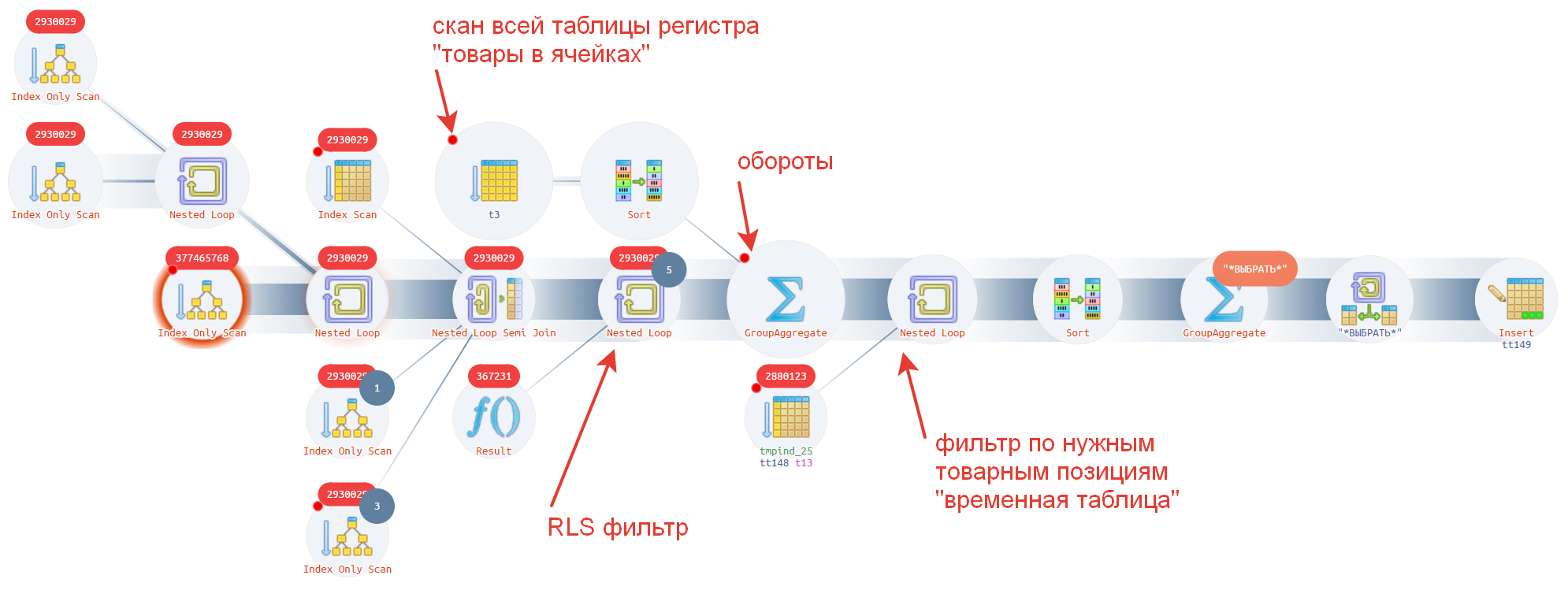
Давайте рассмотрим, что тут происходит и в какой последовательности.
- Первым делом выбираются записи из физической таблицы "Товары в ячейках". Обратите внимание на стрелку "товары в ячейках".
- Далее на каждую строку таблицы выше накладывается ограничение RLS. Позиция от левого края рисунка до стрелки "RLS фильтр".
- Следующим шагом происходит агрегация. Стрелочка "обороты".
- И в конечном шаге накладывается фильтр/отбор по тем позициям, которые нужны. Это позиция со стрелочкой "фильтр по нужным товарным позициям 'временная таблица'"
Согласитесь, агрегировать все записи (около 300 тыс.), чтобы потом взять 10-20 штук, это немного перебор? Вспоминаем рекомендации, которые написаны в желтой книжке: "Отборы делать необходимо внутри виртуальных таблиц".
Но почему же такую ошибку никто не заметил ранее? Все дело в том, что MS SQL выполняет данный запрос более умно и поднимает автоматически фильтр на уровень выше. Как мы увидим дальше, то план исходного запроса MS SQL похож на план оптимизированного запроса Postgres. Давайте посмотрим на картинку, как выглядит план запроса там:
- Из таблицы индекса "Товары в ячейках" выбираются сразу необходимые записи. Отражено красным текстом - "поиск по индексу в ячейках";
- Этот фильтр из временной таблицы применяется через Nested Loop. Позиция по тексту "фильтр по набору данных";
- Далее фильтруется по ограничению RLS - "отбор по RLS";
- И наконец формируется виртуальная таблица обороты в районе оператора "Stream Aggregate" - "обороты".
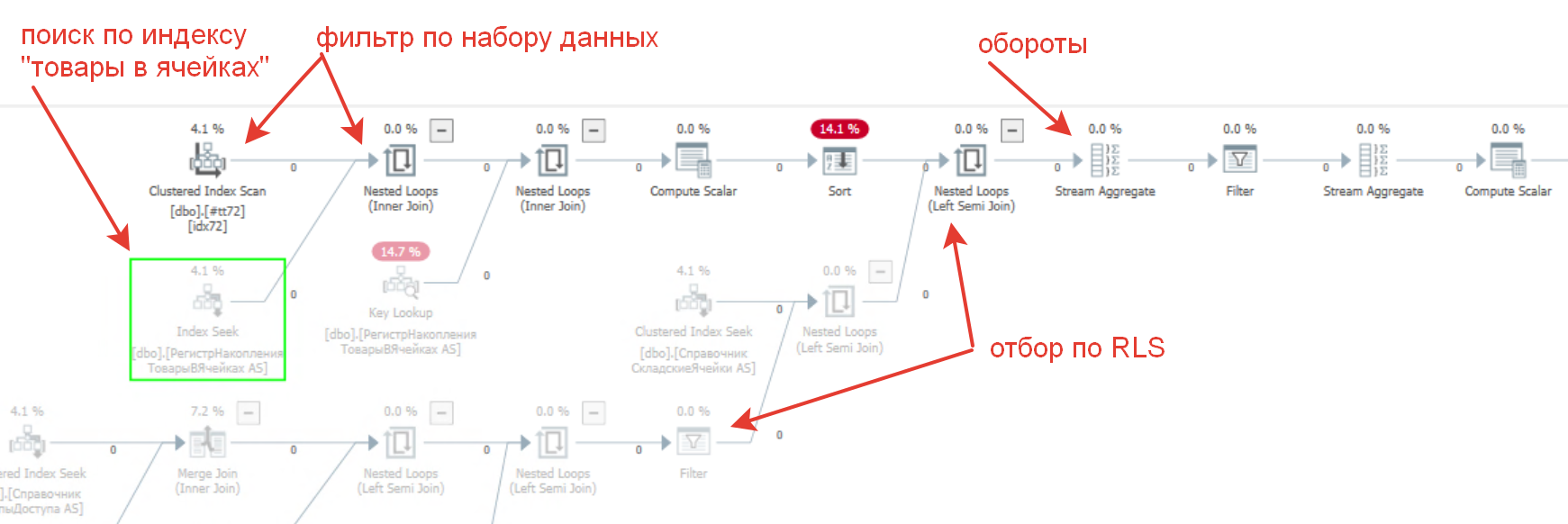
Решение: Оптимизируем запрос в соответствии с рекомендациями - добавляем отбор внутрь виртуальной таблицы "Обороты". Итоговый запрос приведен ниже:
ВЫБРАТЬ
ТоварыВЯчейкахОбороты.Номенклатура КАК Номенклатура,
ТоварыВЯчейкахОбороты.Характеристика КАК Характеристика,
ТоварыВЯчейкахОбороты.Назначение КАК Назначение,
ТоварыВЯчейкахОбороты.Упаковка КАК Упаковка,
ТоварыВЯчейкахОбороты.Ячейка КАК Ячейка,
ТоварыВЯчейкахОбороты.Серия КАК Серия,
СУММА(ТоварыВЯчейкахОбороты.ВНаличииОборот) КАК ВНаличииОборот
ПОМЕСТИТЬ вт_КорректировкиНазначений
ИЗ
РегистрНакопления.ТоварыВЯчейках.Обороты(
,
,
Авто,
(Номенклатура, Характеристика, Ячейка, Серия, Упаковка) В
(ВЫБРАТЬ
вт_ДвиженияПоНазначению.Номенклатура,
вт_ДвиженияПоНазначению.Характеристика,
вт_ДвиженияПоНазначению.Ячейка,
вт_ДвиженияПоНазначению.Серия,
вт_ДвиженияПоНазначению.Упаковка
ИЗ
вт_ДвиженияПоНазначению)) КАК ТоварыВЯчейкахОбороты
ВНУТРЕННЕЕ СОЕДИНЕНИЕ вт_ДвиженияПоНазначению КАК вт_ДвиженияПоНазначению
ПО ТоварыВЯчейкахОбороты.Номенклатура = вт_ДвиженияПоНазначению.Номенклатура
И ТоварыВЯчейкахОбороты.Характеристика = вт_ДвиженияПоНазначению.Характеристика
И ТоварыВЯчейкахОбороты.Ячейка = вт_ДвиженияПоНазначению.Ячейка
И ТоварыВЯчейкахОбороты.Серия = вт_ДвиженияПоНазначению.Серия
И ТоварыВЯчейкахОбороты.Упаковка = вт_ДвиженияПоНазначению.Упаковка
И ТоварыВЯчейкахОбороты.Регистратор = вт_ДвиженияПоНазначению.Регистратор
СГРУППИРОВАТЬ ПО
ТоварыВЯчейкахОбороты.Номенклатура,
ТоварыВЯчейкахОбороты.Характеристика,
ТоварыВЯчейкахОбороты.Назначение,
ТоварыВЯчейкахОбороты.Упаковка,
ТоварыВЯчейкахОбороты.Ячейка,
ТоварыВЯчейкахОбороты.Серия
Давайте посмотрим, что изменилось в плане, а изменилось многое:
https://explain.tensor.ru/archive/explain/3e0fa834b97e79002b47f3376ea812c2:0:2022-05-22#visio
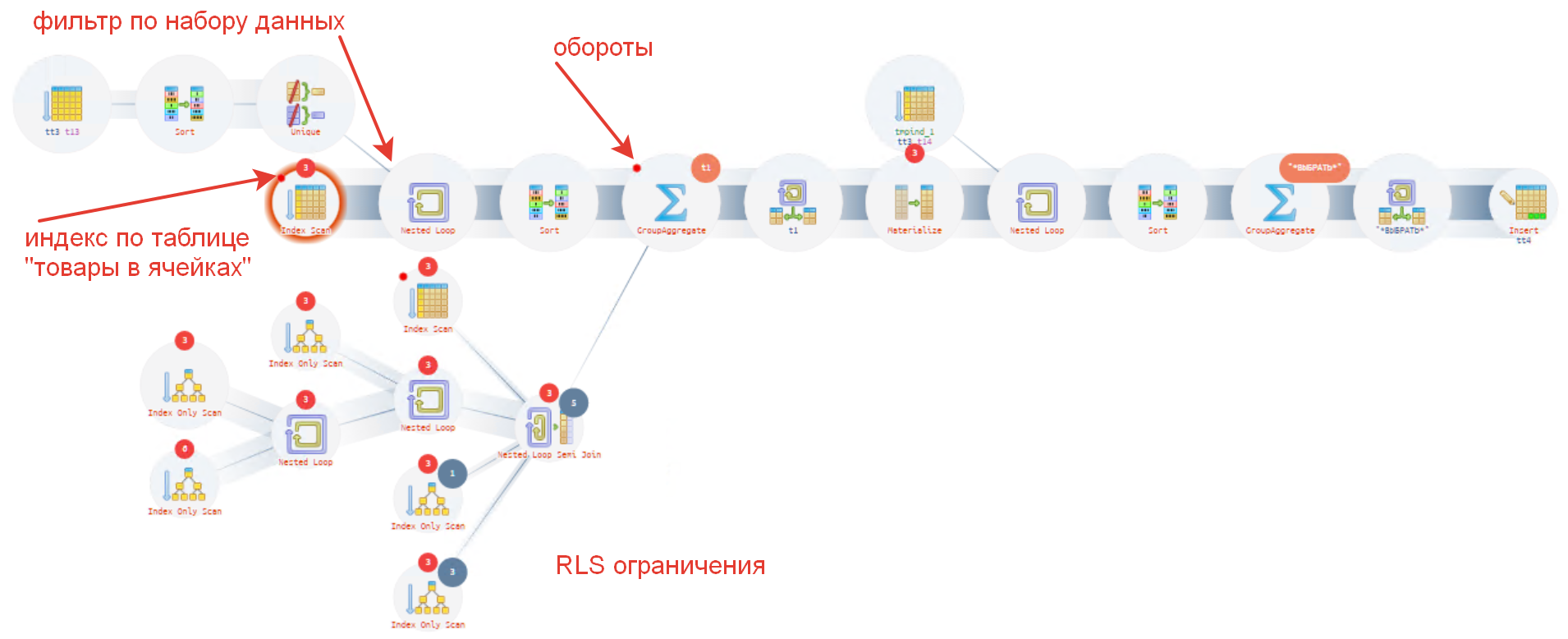
Порядок операций изменился, и время выполнения сократилось до 145 мс. Порядок действий примерно можно описать так:
- Теперь отбираются необходимые записи из индекса таблицы "Товары в ячейках". На рисунке отмечено "индекс по таблице 'товары в ячейках'";
- Фильтр для пункта 1 используется из временной таблицы. Отмечено "фильтр по набору данных";
- Следующим шагом выполняется проверка RLS - это "RLS ограничения";
- Последним шагом выполняется агрегация этих десятков записей, на рисунке "обороты" .
Резюме: В результате наших мероприятий время выполнения снизилось почти в ~7 000 раз, мы перестали обрабатывать лишние данные и сразу стало быстро. Поэтому - Пишите запросы согласно рекомендациям и не полагайтесь на умный планировщик.
Послесловие:
Приводите свои ситуации, нам будет интересно почитать, давайте советы. А также ожидайте, будут еще примеры в одной из последующих статей - декомпозиция запроса, ошибки оптимизатора постгрез, некоторые проблемы платформы 1С и многое другое, подписывайтесь, будет интересно и познавательно.
Выводы:
- В текущих типовых конфигурациях достаточно проблемных мест, которые серьезно снижают производительность высоконагруженных продуктовых баз.
- При переходе на СУБД Postgres с MS SQL будьте готовы вложить ресурсы (время, деньги, разработчиков) на доведение работы системы до приемлемого уровня, особенно в критичных местах для бизнеса. Будьте готовы к тому, что потребуется оптимизация запросов под целевую СУБД и в некоторых случаях под версию СУБД.
- Если вы задумаетесь над переходом на другую СУБД, то необходимо выявить ключевые точки в системе и выполнить нагрузочное тестирование. Про проведения нами такого тестирования мы рассказали в статье "Нагрузочное тестирование 5000+ онлайн".
- Ошибки, которые встречаются в конфигурации, фактически одни и те же (мы рассматривали тут - Распространенные ошибки разработчиков, приводящие к проблемам производительности):
- выбор полей через точку в составных типах;
- неоптимальные отборы;
- отсутствие индексов;
- сложные многоуровневые запросы;
- невнимательность;
- использование подхода - да и так сойдет;
- квалификация разработчиков;
- отсутствие нормального нагрузочного тестирования на больших базах под различными сложными RLS;
- встречающиеся ошибки платформы 1С;
- и другие.
- Следование стандартам разработки позволит избежать большинства проблем.
- Используйте подходящие инструменты мониторинга, держите руку на пульсе, чтобы по возможности заранее выявлять и устранять проблемные узкие места.