










Кто он – селективный индекс.
В предыдущей статье Партицированная дисциплина программиста был показан пример запроса на соединение двух таблиц для регистра сведений, и показано как MS SQL выбирает потоки данных для merge join с использованием стандартных индексов 1С. В частности было отмечено, что без дополнительных условий в Index seek, в поток для Megre join попадают все записи индекса и приходится указывать дополнительные фильтры для ограничения. Вопрос: почему так происходит? - остался открытым.
Все что описано ниже, это мои выводы на основании анализа поведения оптимизатора MS SQL 2019 в разных условиях. Официально изложенных алгоритмов, которые использует оптимизатор MS SQL я не нашел, если знаете ссылку пишите в комментариях.
Сначала вспомним понятие селективного индекса
Если сказать кратко – индекс для данного запроса является селективным, если при его использовании можно выбрать
- Больше уникальных строк
- С меньшим количеством дублей
- Наименьшее количество строк на каждую комбинацию ключевых значений
Про селективность хорошо написано тут (правда для Oracle, но это же общая концепция) Что такое селективный индекс
Возьмем оптимизированный запрос из предыдущей статьи
ВЫБРАТЬ РАЗЛИЧНЫЕ
СУУ_АгрегированныеДенежныеТранзакции.СвязаннаяОпИдИсхСистемы КАК СвязаннаяОпИдИсхСистемы
ПОМЕСТИТЬ Врем_ИдОперацийИзТранзакций
ИЗ
РегистрСведений.СУУ_АгрегированныеДенежныеТранзакции КАК СУУ_АгрегированныеДенежныеТранзакции
ГДЕ
СУУ_АгрегированныеДенежныеТранзакции.Период >= &ДатаНачала
ИНДЕКСИРОВАТЬ ПО
СвязаннаяОпИдИсхСистемы
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
СУУ_АгрегированнаяСделкаКП.Период,
СУУ_АгрегированнаяСделкаКП.ИсходнаяСистема,
СУУ_АгрегированнаяСделкаКП.ИдИсхСистемы КАК ИдИсхСистемы,
СУУ_АгрегированнаяСделкаКП.ОсновнойСчет,
СУУ_АгрегированнаяСделкаКП.НогаСделки
ПОМЕСТИТЬ РезультатВыбранныеВерсииСделок
ИЗ
РегистрСведений.СУУ_АгрегированнаяСделкаКП КАК СУУ_АгрегированнаяСделкаКП
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Врем_ИдОперацийИзТранзакций КАК Врем_ИдОперацийИзТранзакций
ПО СУУ_АгрегированнаяСделкаКП.ИдИсхСистемы = Врем_ИдОперацийИзТранзакций.СвязаннаяОпИдИсхСистемы
ГДЕ
СУУ_АгрегированнаяСделкаКП.Период >= ДОБАВИТЬКДАТЕ(&ДатаНачала, МЕСЯЦ, -3)
И опять его запустим со стандартными индексами 1С. MS SQL нас интересует последний запрос
INSERT INTO #tt3 WITH(TABLOCK) (_Q_001_F_000, _Q_001_F_001RRef, _Q_001_F_002, _Q_001_F_003RRef, _Q_001_F_004RRef) SELECT
T1._Period,
T1._Fld18861RRef,
T1._Fld18865,
T1._Fld18863RRef,
T1._Fld19363RRef
FROM dbo._InfoRg18860 T1 WITH(NOLOCK)
INNER JOIN #tt2 T2 WITH(NOLOCK)
ON (T1._Fld18865 = T2._Q_000_F_000)
WHERE ((T1._Fld628 = @P1)) AND ((T1._Period >= @P2))',N'@P1 numeric(10),@P2 datetime2(3)
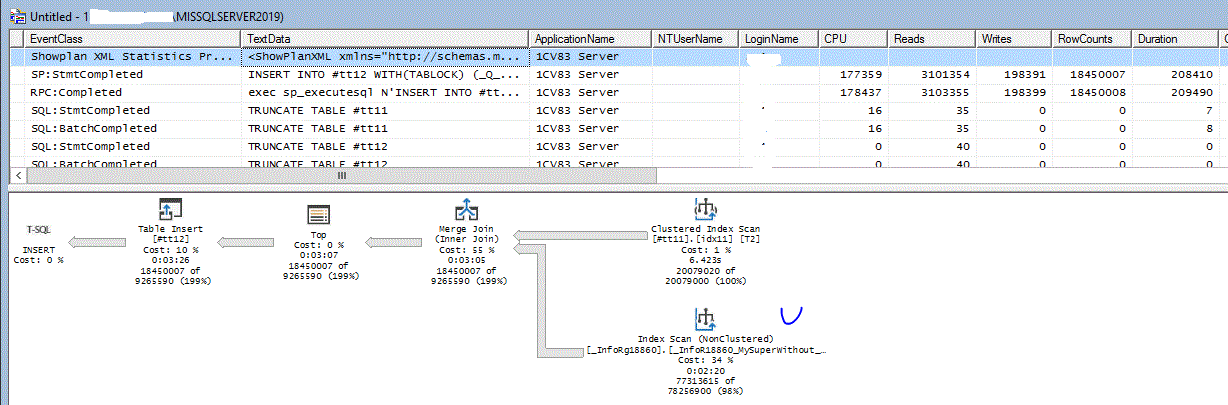
Смотрим общую цену, которую зафиксировал оптимизатор - в попугаях 7767
План получается с Index Seek по типовому индексу _InfoR18860_ByDims18897_STRRRR
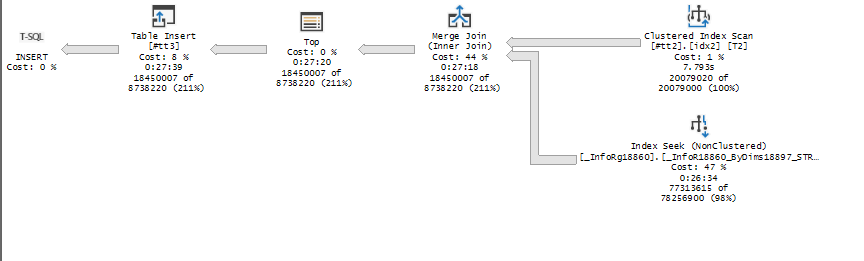
Структура индекса
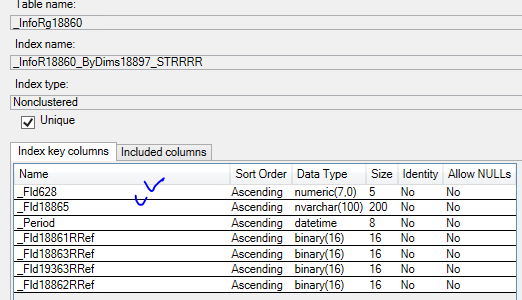
План запроса ниже, видно, что основная тяжесть ввода вывода идет на Index Seek и операции Merge

Вроде все хорошо, по правилам и предсказуемо, но давайте добавим ему другой индекс в котором, убрано поле _Fld628 . Это поле содержит 0 поскольку в типовой конфигурации есть, но не используются
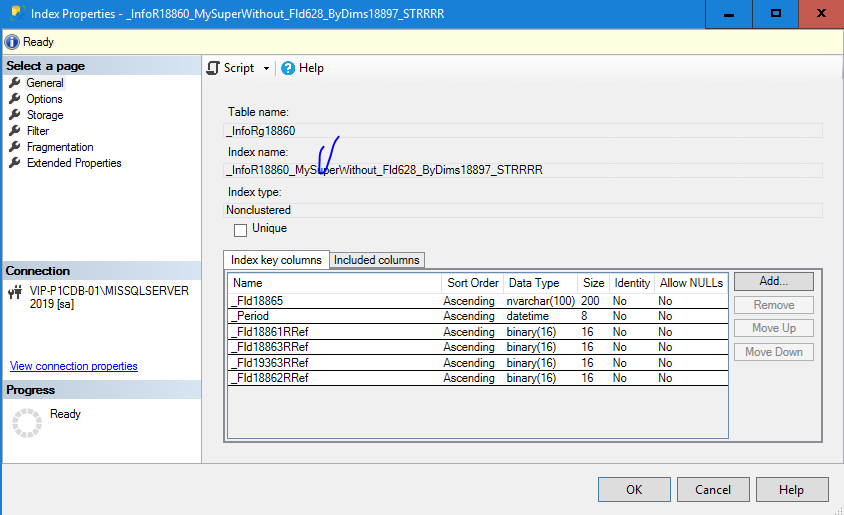
Смотрим результат. Неожиданно – SQL сервер выбрал новый индекс сам , даже при том что _Fld628 (разделителя) там вообще нет! Хотя есть индекс _InfoR18860_ByDims18897_STRRRR который формально удовлетворяет всем условиям.
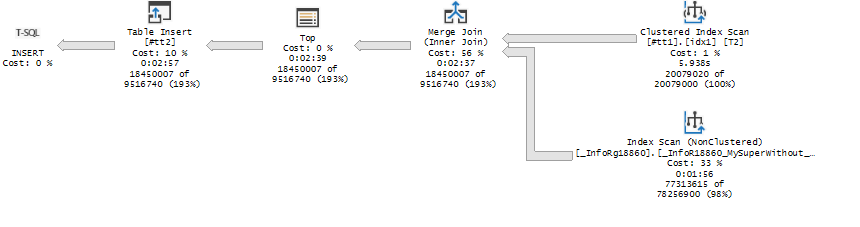
План при этом получился лучше, но ненамного

Разница
- По стандартному индексу идет |--Index Seek(OBJECT:([MIS_PROD2].[dbo].[_InfoRg18860].[_InfoR18860_ByDims18897_STRRRR] AS [T1]), SEEK:([T1].[_Fld628]=[@P1]), WHERE:([MIS_PROD2].[dbo].[_InfoRg18860].[_Period] as [T1].[_Period]>=[@P2]) ORDERED FORWARD)
- По нестандартному индексу идет скан с проверкой всех условий |--Index Scan(OBJECT:([MIS_PROD2].[dbo].[_InfoRg18860].[_InfoR18860_MySuperWithout_Fld628_ByDims18897_STRRRR] AS [T1]), WHERE:([MIS_PROD2].[dbo].[_InfoRg18860].[_Fld628] as [T1].[_Fld628]=[@P1] AND [MIS_PROD2].[dbo].[_InfoRg18860].[_Period] as [T1].[_Period]>=[@P2]) ORDERED FORWARD)
Мы выбираем селективный индекс, а оптимизатор выбирает …
Почему MS SQL так сделал?
Сначала я подумал так «Скорее всего поле, где _Fld628 = 0 в каждой записи, убивает всю селективность индекса и как только появляется достойная альтернатива, то MS SQL сам бежит к ней»
Но после обсуждения на Хабре и нескольких экспериментов выяснилось, что дело в количестве IO по индексу
Т.е. по индексу _InfoR18860_ByDims18897_STRRRR фактическая статистика показала почти 5 млн чтений
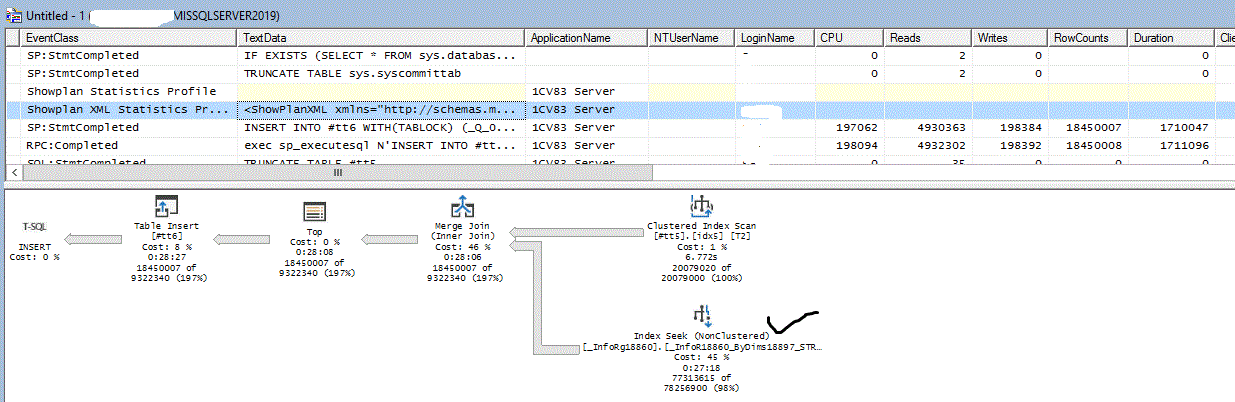
а по индексу _InfoR18860_MySuperWithoutFld628_ByDims18897_STRRRR около 3 млн чтений, причем через Index Scan. Индекс _InfoR18860_MySuperWithoutFld628_ByDims18897_STRRRR явно не укладывается в критерии селективности, но оптимизатор MS SQL видит, что по нему работать быстрее
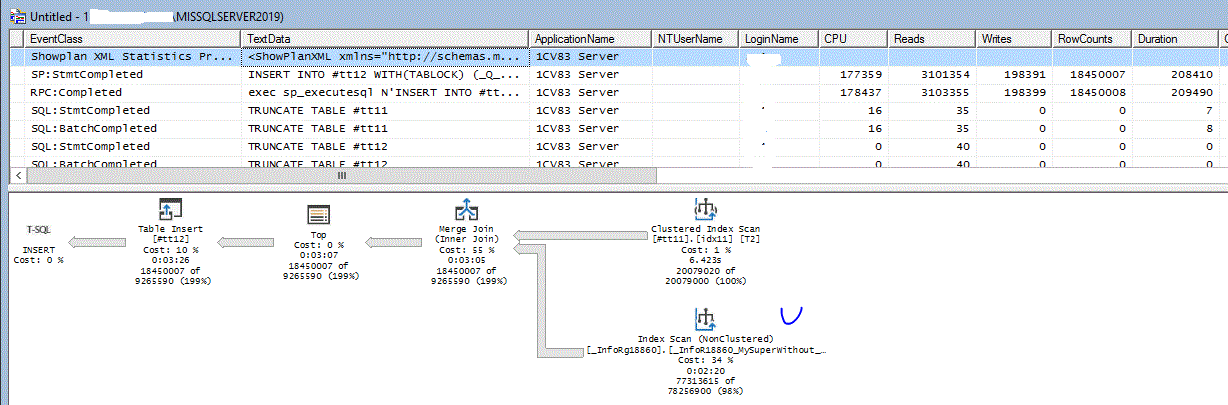
Фрагментация у стандартного индекса действительно была, и после Rebuild оптимизатор опять начал его выбирать как основной! Более того – посмотрите как уменьшилось количество чтений до 3.4 миллиона

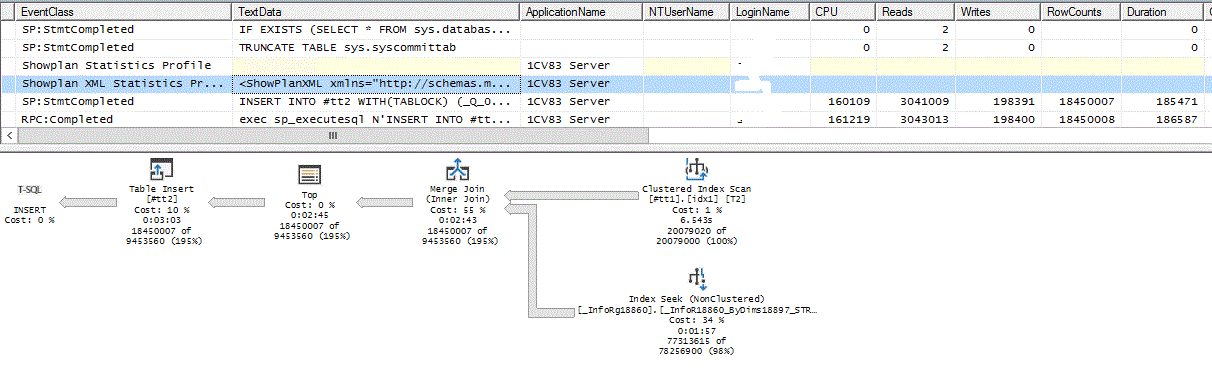
Вывод: Селективность для оптимизатора MS SQL это уже не основной показатель и как показано ниже для других СУБД тоже. Оптимизатор MS SQL может отказаться использовать селективный индекс даже при сильной фрагментации. Более того, в статье MS SQL Server: ваши статистики не работают! Так ли все плохо на самом деле? видно, что поле разделителя влияет на качество статистик MS SQL
Вопрос А в какое место индекса, тогда поставить это поле _Fld628 (ОбластьДанныхОсновныеДанные) , которое 1С по умолчанию ставит в начало (префикс) всех индексов?
Это сложный вопрос. Если ОбластьДанныхОсновныеДанные используется хотя бы с несколькими значениями, селективность повысится в стандартном индексе, учитывая условия на равенства которые добавляет 1С T1._Fld628 = @P1 (равенство всегда в приоритете у оптимизатора нежели >= <=)
Но все очень зависит от СУБД , например тут описаны мифы о селективных индексах причем с планами для разных СУБД
“The myth is extraordinarily persistent in the SQL Server environment and appears even in the official documentation. The reason is that SQL Server keeps a histogram for the first index column only. But that means that the recommendation should read like “uneven distributed columns first” because histograms are not very useful for evenly distributed columns anyway.”
Т.е. первая колонка в индексе решает все и ее количество уникальных значений. Если там один 0 работа с остальными полями идет уже менее эффективно. Если 0 1 2, то это тоже сильно ситуацию не исправляет, поскольку для Merge без доп условий пойдет поток данных по всему T1._Fld628 = @P1
В целом лучше жить без поля ОбластьДанныхОсновныеДанные, чем с ним, но если без него нельзя то улучшить ситуацию можно только альтернативным построением запроса самой платформы, а это уже другая история в следующей статье. Буду рад видеть Вас на нашем телеграм-канале 😊
Вступайте в нашу телеграмм-группу Инфостарт