












Думаю, что уже почти все в курсе насчет GPT, но все же начну с небольшой справки.
GPT расшифровывается как Generative pretrained transformers. Это языковая нейросеть, обученная по технологии transformer. Описание технологии появилось в общем доступе в 2020 году. Кому интересно, ссылка здесь https://arxiv.org/abs/2005.14165. История развивалась более или менее обычными темпами для ИТ, но в конце прошлого года произошло нечто, выходящее за привычные рамки. Компания OpenAI выложила в общий доступ версию языковой модели, взаимодействие с которой организовано в виде чата. Всего лишь за одну неделю этот чат преодолел отметку в миллион пользователей. Такого раньше не было. О chatGPT стали очень много говорить и писать. В том числе, совершенно фантастические вещи. Наиболее впечатлительные начали говорить, что скоро нам всем конец, потому что искусственный интеллект вот-вот захватит мир.
Если не терять голову и смотреть на вещи трезво, то надо понимать, что языковая модель, это достаточно простая, почти механическая, штука. Вся магия в объемах данных, использованных для обучения. Ответ на ваш вопрос формируется как результат компиляции из того, что было ранее сказано в интернете. Языковая модель не обладает сознанием, она не в состоянии делать элементарные логические выводы. Общаясь с ней не стоит забывать, что вы общаетесь не с каким-то неведомым существом, а с людьми, которые когда-то обсуждали ваш вопрос в интернете.
При всем при этом, языковая модель обладает одним чудесным качеством, которое, я уверен, произведет самую настоящую революцию в области взаимодействия людей с компьютерами вообще и с базами данных и учетными системами в частности.
Она вас понимает.
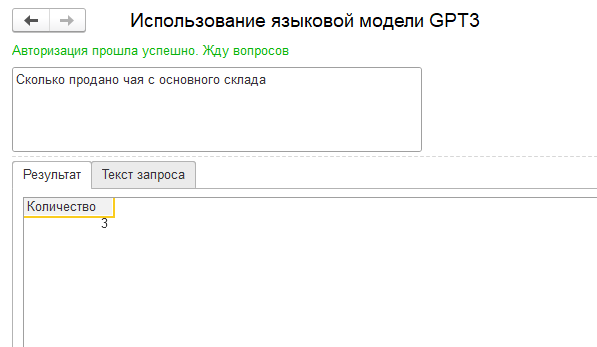
Что это означает, я вам сейчас продемонстрирую на примере работы с типовой конфигурацией УТ редакции 11.5.
Я написал небольшое дополнение, которое необходимо добавлять к каждому вопросу пользователя. В этом дополнении дается описание таблиц базы УТ. В силу ограничений, установленных OpenAI для работы в режиме бесплатного тестирования, я включил в это описание не всю конфигурацию, как есть, а ограничился некоторым более или менее содержательным подмножеством таблиц. В него вошли остатки на складе, продажи и взаиморасчеты. Кроме того, так как большинство 1с-ников привыкли читать запросы на русском языке, я сделал перевод выдаваемого языковой моделью текста запроса.
Также я написал простенькую обработку. Пользователь вводит свой вопрос на русском языке и получает ответ. При желании можно заглянуть в текст запроса.

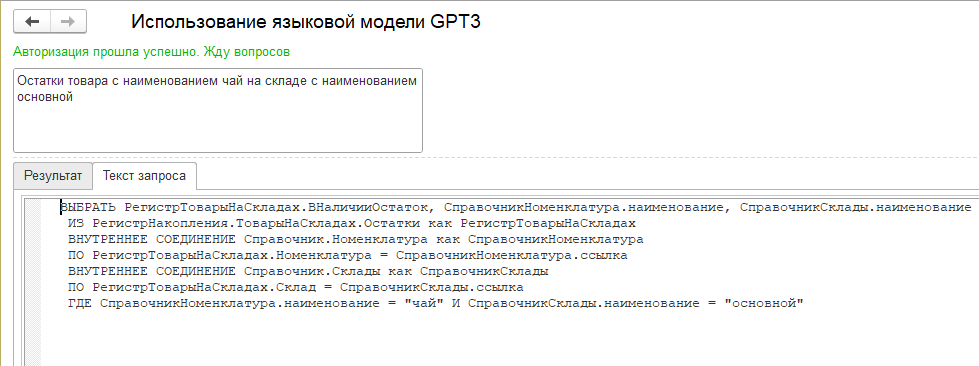
Можно сказать, что мой первый вопрос составлен не совсем на русском языке. Скорее на русско-программистском. Но я хотел для начала дать языковой модели наиболее легкое задание. В этом тексте вопроса уже содержатся готовые инструкции: какие таблицы с какими следует соединять и по каким условиям.
Зададим более непринужденный вопрос.
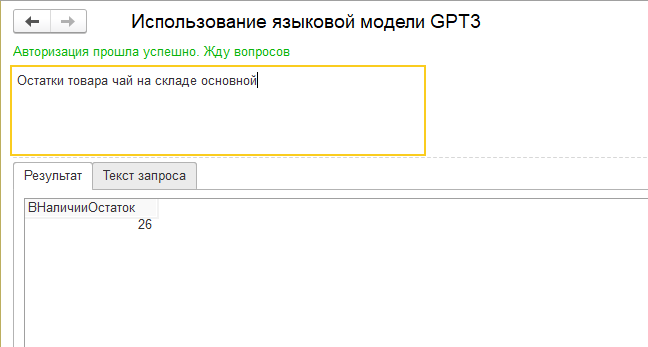
Текст запроса для этого вопроса почти такой же
ВЫБРАТЬ РегистрТоварыНаСкладах.ВНаличииОстаток
ИЗ РегистрНакопления.ТоварыНаСкладах.Остатки как РегистрТоварыНаСкладах
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Номенклатура как СправочникНоменклатура
ПО РегистрТоварыНаСкладах.Номенклатура = СправочникНоменклатура.ссылка
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Склады как СправочникСклады
ПО РегистрТоварыНаСкладах.Склад = СправочникСклады.ссылка
ГДЕ СправочникНоменклатура.наименование = "чай" И СправочникСклады.наименование = "основной"
Я зря старался в первом вопросе. Языковая модель и так понимает, что, с чем и как следует соединять.
Раз так, зададим вопрос совсем по-человечески

Ответ такой же. Текст запроса не имеет смысла приводить, потому что он полностью совпадает с предыдущим. И это прекрасный результат. Особенно с учетом того, что у нас есть не только регистр остатков но и регистр продаж. А там тоже есть товар и склад. Но языковая модель совершенно правильно понимает, что нам нужны остатки.
Попросим теперь показать продажи.

Текст запроса здесь такой:
ВЫБРАТЬ СУММА(РегистрВыручка.Количество)
ИЗ РегистрНакопления.ВыручкаИСебестоимостьПродаж как РегистрВыручка
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Номенклатура как СправочникНоменклатура
ПО РегистрВыручка.АналитикаУчетаНоменклатуры.Номенклатура = СправочникНоменклатура.ссылка
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Склады как СправочникСклады
ПО РегистрВыручка.Склад = СправочникСклады.ссылка
ГДЕ СправочникНоменклатура.наименование = "чай" И СправочникСклады.наименование = "основной"
Можно еще и так
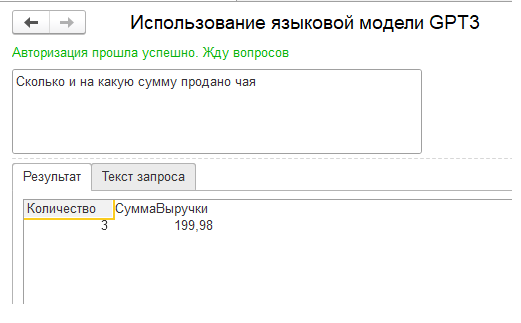
ВЫБРАТЬ СУММА(РегистрВыручка.Количество), СУММА(РегистрВыручка.СуммаВыручки)
ИЗ РегистрНакопления.ВыручкаИСебестоимостьПродаж как РегистрВыручка
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Номенклатура как СправочникНоменклатура
ПО РегистрВыручка.АналитикаУчетаНоменклатуры.Номенклатура = СправочникНоменклатура.ссылка
ГДЕ СправочникНоменклатура.наименование = "чай"
Или так

ВЫБРАТЬ СправочникНоменклатура.наименование, СУММА(РегистрВыручка.Количество)
ИЗ Справочник.Номенклатура как СправочникНоменклатура
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрНакопления.ВыручкаИСебестоимостьПродаж как РегистрВыручка
ПО СправочникНоменклатура.ссылка = РегистрВыручка.АналитикаУчетаНоменклатуры.Номенклатура
ГДЕ СправочникНоменклатура.наименование = "Чай" ИЛИ СправочникНоменклатура.наименование = "Сахар"
СГРУППИРОВАТЬ ПО СправочникНоменклатура.наименование
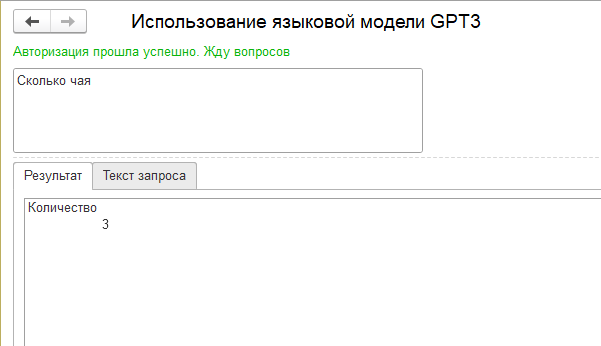
Попробуем поставить языковую модель в тупик. Зададим неоднозначный, расплывчатый вопрос: "Сколько чая?" Из самого вопроса сложно понять, что хочет узнать вопрошающий. Остатки на складе или объем продаж?
ВЫБРАТЬ СУММА(РегистрВыручка.Количество)
ИЗ РегистрНакопления.ВыручкаИСебестоимостьПродаж как РегистрВыручка
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Номенклатура как СправочникНоменклатура
ПО РегистрВыручка.АналитикаУчетаНоменклатуры.Номенклатура = СправочникНоменклатура.ссылка
ГДЕ СправочникНоменклатура.наименование = "чай"
Языковая модель не зависает и не ломается. Она просто решает, что в данном случае будет уместным выдать информацию о продажах.
Если пользователь все-таки хотел получить информацию об остатках, он может задать вопрос чуть иначе. Например, вот так.
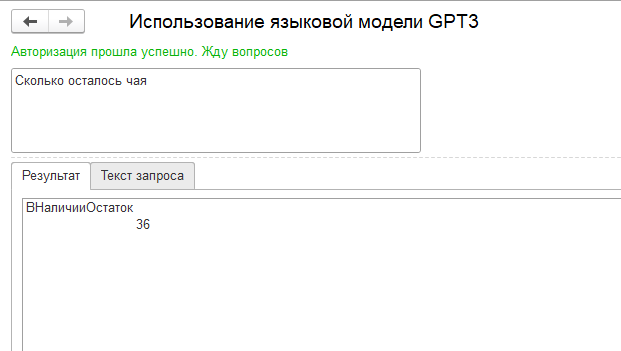
ВЫБРАТЬ РегистрТоварыНаСкладах.ВНаличииОстаток
ИЗ РегистрНакопления.ТоварыНаСкладах.Остатки как РегистрТоварыНаСкладах
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Номенклатура как СправочникНоменклатура
ПО РегистрТоварыНаСкладах.Номенклатура = СправочникНоменклатура.ссылка ГДЕ СправочникНоменклатура.наименование = "чай"
Или так.
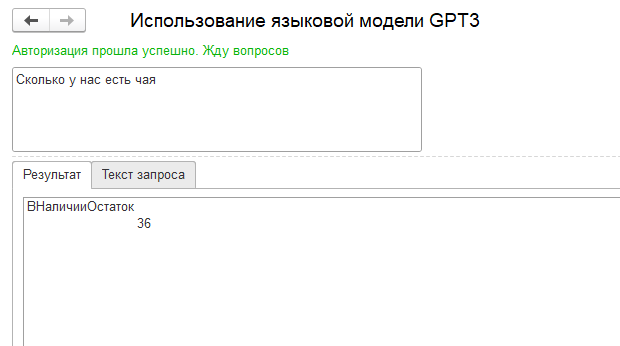
Текст запроса совпадает с предыдущим. Здесь важно то, что возникшее затруднение пользователь может решить так же, как он это привык делать при обычном общении.
Приведу еще несколько примеров.

ВЫБРАТЬ СУММА(РегистрВыручка.Количество)
ИЗ РегистрНакопления.ВыручкаИСебестоимостьПродаж как РегистрВыручка
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Номенклатура как СправочникНоменклатура
ПО РегистрВыручка.АналитикаУчетаНоменклатуры.Номенклатура = СправочникНоменклатура.ссылка
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Контрагенты как СправочникКонтрагенты
ПО РегистрВыручка.АналитикаУчетаПоПартнерам.Контрагент = СправочникКонтрагенты.ссылка
ГДЕ СправочникНоменклатура.наименование = "чай" И СправочникКонтрагенты.наименование = "Иванов"

ВЫБРАТЬ СУММА(РегистрВыручка.Количество)
ИЗ РегистрНакопления.ВыручкаИСебестоимостьПродаж как РегистрВыручка
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Номенклатура как СправочникНоменклатура
ПО РегистрВыручка.АналитикаУчетаНоменклатуры.Номенклатура = СправочникНоменклатура.ссылка
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Пользователи как СправочникПользователи
ПО РегистрВыручка.Менеджер = СправочникПользователи.ссылка
ГДЕ СправочникНоменклатура.наименование = "чай" И СправочникПользователи.наименование = "Иванов"
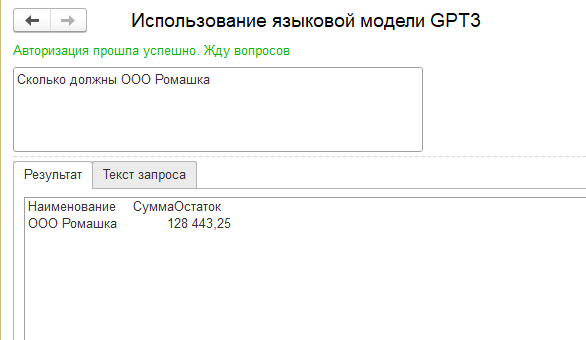
ВЫБРАТЬ СправочникКонтрагенты.наименование, РегистрВзаиморасчетов.СуммаОстаток
ИЗ РегистрНакопления.РасчетыСКлиентами.Остатки как РегистрВзаиморасчетов
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Контрагенты как СправочникКонтрагенты
ПО РегистрВзаиморасчетов.АналитикаУчетаПоПартнерам.Контрагент = СправочникКонтрагенты.ссылка
ГДЕ СправочникКонтрагенты.наименование = "ООО Ромашка"
Как видите, языковая модель прекрасно справляется с вопросами на естественном языке. Во всем этом есть только один досадный момент. На вопрос "Сколько продано чая Иванову в январе" будет получен вот такой текст запроса
ВЫБРАТЬ СУММА(РегистрВыручка.Количество) ИЗ РегистрНакопления.ВыручкаИСебестоимостьПродаж как РегистрВыручка
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Номенклатура как СправочникНоменклатура
ПО РегистрВыручка.АналитикаУчетаНоменклатуры.Номенклатура = СправочникНоменклатура.ссылка
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Контрагенты как СправочникКонтрагенты
ПО РегистрВыручка.АналитикаУчетаПоПартнерам.Контрагент = СправочникКонтрагенты.ссылка
ГДЕ СправочникНоменклатура.наименование = "чай"
И СправочникКонтрагенты.наименование = "Иванов"
И РегистрВыручка.период МЕЖДУ датавремя(2020,01,01) И датавремя(2020,01,31)
Когда мы говорим "в январе", мы имеем ввиду январь текущего года. Но в данном случае языковая модель нас не понимает. Более того, бесполезно пытаться уточнять "в январе 2023 года". Результат будет тот же. Здесь самое время вспомнить, что мы получаем ответы от людей, которые когда-то что-то писали в интернете. Обучение языковой модели происходило в 2021 году. И на тот момент в интернете не было (или почти не было, что одно и то же) текстов запросов, в которых упоминался бы 23 год. Время - это самое слабое место языковых моделей. Разработчик, OpenAI честно предупреждает об этом. Для учетных систем это реальная проблема. Но, к счастью, она решается путем относительно несложной доработки.
Подведем итоги. Использование языковой модели дает нам реальную возможность построения интерфейсов на естественном языке. Эффект усиливается еще и тем, что в недавно представленной платформе 8.3.23 уже присутствует сервис распознавания речи. Языковые модели и сервис распознавания речи приведут к революционным изменениям в способах взаимодействия пользователей с учетными системами и базами данных. Думаю, что каждому специалисту будет полезно узнать об этом и, по возможности, погрузиться в тему поглубже.
Если вас заинтересовал материал данной статьи и вы хотели бы поэкспериментировать с языковой моделью самостоятельно, тогда оставляйте заявку в произвольной форме на https://brainguard.ru
Если заявок наберется достаточное количество, я решу вопрос с корректной обработкой времени и открою доступ к тестовой площадке для зарегистрировавшихся.
Вступайте в нашу телеграмм-группу Инфостарт